https://github.com/apache/spark
- HEAD
- refs/heads/branch-0.5
- refs/heads/branch-0.6
- refs/heads/branch-0.7
- refs/heads/branch-0.8
- refs/heads/branch-0.9
- refs/heads/branch-1.0
- refs/heads/branch-1.0-jdbc
- refs/heads/branch-1.1
- refs/heads/branch-1.2
- refs/heads/branch-1.3
- refs/heads/branch-1.4
- refs/heads/branch-1.5
- refs/heads/branch-1.6
- refs/heads/branch-2.0
- refs/heads/branch-2.1
- refs/heads/branch-2.2
- refs/heads/branch-2.3
- refs/heads/branch-2.4
- refs/heads/branch-3.0
- refs/heads/branch-3.1
- refs/heads/branch-3.2
- refs/heads/branch-3.3
- refs/heads/branch-3.4
- refs/heads/branch-3.5
- refs/heads/master
- refs/remotes/origin/branch-0.8
- refs/remotes/origin/td-rdd-save
- refs/tags/0.3-scala-2.8
- refs/tags/0.3-scala-2.9
- refs/tags/2.0.0-preview
- refs/tags/alpha-0.1
- refs/tags/alpha-0.2
- refs/tags/v0.5.0
- refs/tags/v0.5.1
- refs/tags/v0.5.2
- refs/tags/v0.6.0
- refs/tags/v0.6.0-yarn
- refs/tags/v0.6.1
- refs/tags/v0.6.2
- refs/tags/v0.7.0
- refs/tags/v0.7.0-bizo-1
- refs/tags/v0.7.1
- refs/tags/v0.7.2
- refs/tags/v0.9.1
- refs/tags/v0.9.2
- refs/tags/v1.0.0
- refs/tags/v1.0.1
- refs/tags/v1.0.2
- refs/tags/v1.1.0
- refs/tags/v1.1.1
- refs/tags/v1.2.0
- refs/tags/v1.2.1
- refs/tags/v1.2.2
- refs/tags/v1.3.0
- refs/tags/v1.3.1
- refs/tags/v1.4.0
- refs/tags/v1.4.1
- refs/tags/v1.5.0-rc1
- refs/tags/v1.5.0-rc2
- refs/tags/v1.5.0-rc3
- refs/tags/v1.5.1
- refs/tags/v1.6.0
- refs/tags/v1.6.1
- refs/tags/v1.6.2
- refs/tags/v1.6.3
- refs/tags/v2.0.0
- refs/tags/v2.0.1
- refs/tags/v2.0.2
- refs/tags/v2.1.0
- refs/tags/v2.1.1
- refs/tags/v2.1.2
- refs/tags/v2.1.2-rc1
- refs/tags/v2.1.2-rc2
- refs/tags/v2.1.2-rc3
- refs/tags/v2.1.2-rc4
- refs/tags/v2.1.3
- refs/tags/v2.1.3-rc1
- refs/tags/v2.1.3-rc2
- refs/tags/v2.2.0
- refs/tags/v2.2.1
- refs/tags/v2.2.1-rc1
- refs/tags/v2.2.1-rc2
- refs/tags/v2.2.2
- refs/tags/v2.2.2-rc1
- refs/tags/v2.2.2-rc2
- refs/tags/v2.2.3
- refs/tags/v2.2.3-rc1
- refs/tags/v2.3.0
- refs/tags/v2.3.0-rc1
- refs/tags/v2.3.0-rc2
- refs/tags/v2.3.0-rc3
- refs/tags/v2.3.0-rc4
- refs/tags/v2.3.1
- refs/tags/v2.3.1-rc1
- refs/tags/v2.3.1-rc2
- refs/tags/v2.3.1-rc3
- refs/tags/v2.3.1-rc4
- refs/tags/v2.3.2
- refs/tags/v2.3.2-rc1
- refs/tags/v2.3.2-rc2
- refs/tags/v2.3.2-rc3
- refs/tags/v2.3.2-rc4
- refs/tags/v2.3.2-rc5
- refs/tags/v2.3.2-rc6
- refs/tags/v2.3.3
- refs/tags/v2.3.3-rc1
- refs/tags/v2.3.3-rc2
- refs/tags/v2.3.4
- refs/tags/v2.3.4-rc1
- refs/tags/v2.4.0
- refs/tags/v2.4.0-rc1
- refs/tags/v2.4.0-rc2
- refs/tags/v2.4.0-rc3
- refs/tags/v2.4.0-rc4
- refs/tags/v2.4.0-rc5
- refs/tags/v2.4.1
- refs/tags/v2.4.1-rc1
- refs/tags/v2.4.1-rc2
- refs/tags/v2.4.1-rc3
- refs/tags/v2.4.1-rc4
- refs/tags/v2.4.1-rc5
- refs/tags/v2.4.1-rc6
- refs/tags/v2.4.1-rc7
- refs/tags/v2.4.1-rc8
- refs/tags/v2.4.1-rc9
- refs/tags/v2.4.2
- refs/tags/v2.4.2-rc1
- refs/tags/v2.4.3
- refs/tags/v2.4.3-rc1
- refs/tags/v2.4.4
- refs/tags/v2.4.4-rc1
- refs/tags/v2.4.4-rc2
- refs/tags/v2.4.4-rc3
- refs/tags/v2.4.5
- refs/tags/v2.4.5-rc1
- refs/tags/v2.4.5-rc2
- refs/tags/v2.4.6
- refs/tags/v2.4.6-rc1
- refs/tags/v2.4.6-rc2
- refs/tags/v2.4.6-rc3
- refs/tags/v2.4.6-rc4
- refs/tags/v2.4.6-rc5
- refs/tags/v2.4.6-rc6
- refs/tags/v2.4.6-rc7
- refs/tags/v2.4.6-rc8
- refs/tags/v2.4.7
- refs/tags/v2.4.7-rc1
- refs/tags/v2.4.7-rc2
- refs/tags/v2.4.7-rc3
- refs/tags/v2.4.8
- refs/tags/v2.4.8-rc1
- refs/tags/v2.4.8-rc2
- refs/tags/v2.4.8-rc3
- refs/tags/v2.4.8-rc4
- refs/tags/v3.0.0
- refs/tags/v3.0.0-preview2
- refs/tags/v3.0.0-preview2-rc1
- refs/tags/v3.0.0-preview2-rc2
- refs/tags/v3.0.0-rc1
- refs/tags/v3.0.0-rc2
- refs/tags/v3.0.0-rc3
- refs/tags/v3.0.1
- refs/tags/v3.0.1-rc1
- refs/tags/v3.0.1-rc2
- refs/tags/v3.0.1-rc3
- refs/tags/v3.0.2
- refs/tags/v3.0.2-rc1
- refs/tags/v3.0.3
- refs/tags/v3.0.3-rc1
- refs/tags/v3.1.0-rc1
- refs/tags/v3.1.1
- refs/tags/v3.1.1-rc1
- refs/tags/v3.1.1-rc2
- refs/tags/v3.1.1-rc3
- refs/tags/v3.1.2
- refs/tags/v3.1.2-rc1
- refs/tags/v3.1.3
- refs/tags/v3.1.3-rc1
- refs/tags/v3.1.3-rc2
- refs/tags/v3.1.3-rc3
- refs/tags/v3.1.3-rc4
- refs/tags/v3.2.0
- refs/tags/v3.2.0-rc1
- refs/tags/v3.2.0-rc2
- refs/tags/v3.2.0-rc3
- refs/tags/v3.2.0-rc4
- refs/tags/v3.2.0-rc5
- refs/tags/v3.2.0-rc6
- refs/tags/v3.2.0-rc7
- refs/tags/v3.2.1
- refs/tags/v3.2.1-rc1
- refs/tags/v3.2.1-rc2
- refs/tags/v3.2.2
- refs/tags/v3.2.2-rc1
- refs/tags/v3.2.3
- refs/tags/v3.2.3-rc1
- refs/tags/v3.2.4
- refs/tags/v3.2.4-rc1
- refs/tags/v3.3.0
- refs/tags/v3.3.0-rc1
- refs/tags/v3.3.0-rc2
- refs/tags/v3.3.0-rc3
- refs/tags/v3.3.0-rc4
- refs/tags/v3.3.0-rc5
- refs/tags/v3.3.0-rc6
- refs/tags/v3.3.1
- refs/tags/v3.3.1-rc1
- refs/tags/v3.3.1-rc2
- refs/tags/v3.3.1-rc3
- refs/tags/v3.3.1-rc4
- refs/tags/v3.3.2
- refs/tags/v3.3.2-rc1
- refs/tags/v3.3.3
- refs/tags/v3.3.3-rc1
- refs/tags/v3.3.4
- refs/tags/v3.3.4-rc1
- refs/tags/v3.4.0
- refs/tags/v3.4.0-rc1
- refs/tags/v3.4.0-rc2
- refs/tags/v3.4.0-rc3
- refs/tags/v3.4.0-rc4
- refs/tags/v3.4.0-rc5
- refs/tags/v3.4.0-rc6
- refs/tags/v3.4.0-rc7
- refs/tags/v3.4.1
- refs/tags/v3.4.1-rc1
- refs/tags/v3.4.2
- refs/tags/v3.4.2-rc1
- refs/tags/v3.4.3
- refs/tags/v3.4.3-rc1
- refs/tags/v3.4.3-rc2
- refs/tags/v3.5.0
- refs/tags/v3.5.0-rc1
- refs/tags/v3.5.0-rc2
- refs/tags/v3.5.0-rc3
- refs/tags/v3.5.0-rc4
- refs/tags/v3.5.0-rc5
- refs/tags/v3.5.1
- refs/tags/v3.5.1-rc1
- refs/tags/v3.5.1-rc2
- refs/tags/v4.0.0-preview1
- refs/tags/v4.0.0-preview1-rc1
- refs/tags/v4.0.0-preview1-rc2
- refs/tags/v4.0.0-preview1-rc3
Take a new snapshot of a software origin
If the archived software origin currently browsed is not synchronized with its upstream version (for instance when new commits have been issued), you can explicitly request Software Heritage to take a new snapshot of it.
Use the form below to proceed. Once a request has been submitted and accepted, it will be processed as soon as possible. You can then check its processing state by visiting this dedicated page.
Processing "take a new snapshot" request ...
Permalinks
To reference or cite the objects present in the Software Heritage archive, permalinks based on SoftWare Hash IDentifiers (SWHIDs) must be used.
Select below a type of object currently browsed in order to display its associated SWHID and permalink.
| Revision | Author | Date | Message | Commit Date |
|---|---|---|---|---|
| 4be5660 | Sean Owen | 11 August 2021, 23:04:55 UTC | Update Spark key negotiation protocol | 21 August 2021, 03:29:51 UTC |
| 163fbd2 | Liang-Chi Hsieh | 09 May 2021, 17:45:27 UTC | Preparing Spark release v2.4.8-rc4 | 09 May 2021, 17:45:27 UTC |
| 7733510 | Liang-Chi Hsieh | 07 May 2021, 16:07:57 UTC | [SPARK-35288][SQL] StaticInvoke should find the method without exact argument classes match ### What changes were proposed in this pull request? This patch proposes to make StaticInvoke able to find method with given method name even the parameter types do not exactly match to argument classes. ### Why are the changes needed? Unlike `Invoke`, `StaticInvoke` only tries to get the method with exact argument classes. If the calling method's parameter types are not exactly matched with the argument classes, `StaticInvoke` cannot find the method. `StaticInvoke` should be able to find the method under the cases too. ### Does this PR introduce _any_ user-facing change? Yes. `StaticInvoke` can find a method even the argument classes are not exactly matched. ### How was this patch tested? Unit test. Closes #32413 from viirya/static-invoke. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> (cherry picked from commit 33fbf5647b4a5587c78ac51339c0cbc9d70547a4) Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 07 May 2021, 16:09:25 UTC |
| eaf0553 | Liang-Chi Hsieh | 02 May 2021, 00:47:05 UTC | Preparing development version 2.4.9-SNAPSHOT Closes #32414 from viirya/prepare-rc4. Authored-by: Liang-Chi Hsieh <viirya@apache.org> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 02 May 2021, 00:47:05 UTC |
| e41f3c1 | Liang-Chi Hsieh | 01 May 2021, 21:58:25 UTC | [SPARK-35278][SQL][2.4] Invoke should find the method with correct number of parameters ### What changes were proposed in this pull request? This patch fixes `Invoke` expression when the target object has more than one method with the given method name. This is 2.4 backport of #32404. ### Why are the changes needed? `Invoke` will find out the method on the target object with given method name. If there are more than one method with the name, currently it is undeterministic which method will be used. We should add the condition of parameter number when finding the method. ### Does this PR introduce _any_ user-facing change? Yes, fixed a bug when using `Invoke` on a object where more than one method with the given method name. ### How was this patch tested? Unit test. Closes #32412 from viirya/SPARK-35278-2.4. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 01 May 2021, 21:58:25 UTC |
| e89526d | Liang-Chi Hsieh | 28 April 2021, 08:22:14 UTC | Preparing Spark release v2.4.8-rc3 | 28 April 2021, 08:22:14 UTC |
| 183eb75 | Bo Zhang | 27 April 2021, 01:59:30 UTC | [SPARK-35227][BUILD] Update the resolver for spark-packages in SparkSubmit This change is to use repos.spark-packages.org instead of Bintray as the repository service for spark-packages. The change is needed because Bintray will no longer be available from May 1st. This should be transparent for users who use SparkSubmit. Tested running spark-shell with --packages manually. Closes #32346 from bozhang2820/replace-bintray. Authored-by: Bo Zhang <bo.zhang@databricks.com> Signed-off-by: hyukjinkwon <gurwls223@apache.org> (cherry picked from commit f738fe07b6fc85c880b64a1cc2f6c7cc1cc1379b) Signed-off-by: hyukjinkwon <gurwls223@apache.org> | 27 April 2021, 02:02:42 UTC |
| 101c9e7 | Chao Sun | 26 April 2021, 20:48:49 UTC | [SPARK-35233][2.4][BUILD] Switch from bintray to scala.jfrog.io for SBT download in branch 2.4 and 3.0 ### What changes were proposed in this pull request? Move SBT download URL from `https://dl.bintray.com/typesafe` to `https://scala.jfrog.io/artifactory`. ### Why are the changes needed? As [bintray is sunsetting](https://jfrog.com/blog/into-the-sunset-bintray-jcenter-gocenter-and-chartcenter/), we should migrate SBT download location away from it. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Tested manually and it is working, while previously it was failing because SBT 0.13.17 can't be found: ``` Attempting to fetch sbt Our attempt to download sbt locally to build/sbt-launch-0.13.17.jar failed. Please install sbt manually from http://www.scala-sbt.org/ ``` Closes #32352 from sunchao/SPARK-35233. Authored-by: Chao Sun <sunchao@apple.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 26 April 2021, 20:48:49 UTC |
| 67aad59 | Kousuke Saruta | 25 April 2021, 05:46:35 UTC | [SPARK-35210][BUILD][2.4] Upgrade Jetty to 9.4.40 to fix ERR_CONNECTION_RESET issue ### What changes were proposed in this pull request? This PR backports SPARK-35210 (#32318). This PR proposes to upgrade Jetty to 9.4.40. ### Why are the changes needed? SPARK-34988 (#32091) upgraded Jetty to 9.4.39 for CVE-2021-28165. But after the upgrade, Jetty 9.4.40 was released to fix the ERR_CONNECTION_RESET issue (https://github.com/eclipse/jetty.project/issues/6152). This issue seems to affect Jetty 9.4.39 when POST method is used with SSL. For Spark, job submission using REST and ThriftServer with HTTPS protocol can be affected. ### Does this PR introduce _any_ user-facing change? No. No released version uses Jetty 9.3.39. ### How was this patch tested? CI. Closes #32322 from sarutak/backport-SPARK-35210. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 25 April 2021, 05:46:35 UTC |
| bec7389 | Liang-Chi Hsieh | 22 April 2021, 16:20:59 UTC | Preparing development version 2.4.9-SNAPSHOT Closes #32293 from viirya/prepare-rc3. Authored-by: Liang-Chi Hsieh <viirya@apache.org> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 22 April 2021, 16:20:59 UTC |
| 1630d64 | Kent Yao | 21 April 2021, 07:22:51 UTC | [SPARK-31225][SQL][2.4] Override sql method of OuterReference ### What changes were proposed in this pull request? Per https://github.com/apache/spark/pull/32179#issuecomment-822954063 's request to backport SPARK-31225 to branch 2.4 ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? Closes #32256 from yaooqinn/SPARK-31225. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 21 April 2021, 07:22:51 UTC |
| c438f5f | allisonwang-db | 20 April 2021, 03:11:40 UTC | [SPARK-35080][SQL] Only allow a subset of correlated equality predicates when a subquery is aggregated This PR updated the `foundNonEqualCorrelatedPred` logic for correlated subqueries in `CheckAnalysis` to only allow correlated equality predicates that guarantee one-to-one mapping between inner and outer attributes, instead of all equality predicates. To fix correctness bugs. Before this fix Spark can give wrong results for certain correlated subqueries that pass CheckAnalysis: Example 1: ```sql create or replace view t1(c) as values ('a'), ('b') create or replace view t2(c) as values ('ab'), ('abc'), ('bc') select c, (select count(*) from t2 where t1.c = substring(t2.c, 1, 1)) from t1 ``` Correct results: [(a, 2), (b, 1)] Spark results: ``` +---+-----------------+ |c |scalarsubquery(c)| +---+-----------------+ |a |1 | |a |1 | |b |1 | +---+-----------------+ ``` Example 2: ```sql create or replace view t1(a, b) as values (0, 6), (1, 5), (2, 4), (3, 3); create or replace view t2(c) as values (6); select c, (select count(*) from t1 where a + b = c) from t2; ``` Correct results: [(6, 4)] Spark results: ``` +---+-----------------+ |c |scalarsubquery(c)| +---+-----------------+ |6 |1 | |6 |1 | |6 |1 | |6 |1 | +---+-----------------+ ``` Yes. Users will not be able to run queries that contain unsupported correlated equality predicates. Added unit tests. Closes #32179 from allisonwang-db/spark-35080-subquery-bug. Lead-authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com> Co-authored-by: Wenchen Fan <cloud0fan@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit bad4b6f025de4946112a0897892a97d5ae6822cf) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 20 April 2021, 03:51:15 UTC |
| d4b9719 | weixiuli | 14 April 2021, 16:44:48 UTC | [SPARK-34834][NETWORK] Fix a potential Netty memory leak in TransportResponseHandler ### What changes were proposed in this pull request? There is a potential Netty memory leak in TransportResponseHandler. ### Why are the changes needed? Fix a potential Netty memory leak in TransportResponseHandler. ### Does this PR introduce _any_ user-facing change? NO ### How was this patch tested? NO Closes #31942 from weixiuli/SPARK-34834. Authored-by: weixiuli <weixiuli@jd.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit bf9f3b884fcd6bd3428898581d4b5dca9bae6538) Signed-off-by: Sean Owen <srowen@gmail.com> | 14 April 2021, 16:45:31 UTC |
| 63ebabb | Yuming Wang | 13 April 2021, 09:04:47 UTC | [SPARK-34212][SQL][FOLLOWUP] Move the added test to ParquetQuerySuite This pr moves the added test from `SQLQuerySuite` to `ParquetQuerySuite`. 1. It can be tested by `ParquetV1QuerySuite` and `ParquetV2QuerySuite`. 2. Reduce the testing time of `SQLQuerySuite`(SQLQuerySuite ~ 3 min 17 sec, ParquetV1QuerySuite ~ 27 sec). No. Unit test. Closes #32090 from wangyum/SPARK-34212. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 13 April 2021, 09:34:30 UTC |
| a0ab27c | Liang-Chi Hsieh | 11 April 2021, 23:55:04 UTC | Preparing Spark release v2.4.8-rc2 | 11 April 2021, 23:55:04 UTC |
| ae5568e | Liang-Chi Hsieh | 10 April 2021, 00:19:14 UTC | [SPARK-34963][SQL][2.4] Fix nested column pruning for extracting case-insensitive struct field from array of struct ### What changes were proposed in this pull request? This patch proposes a fix of nested column pruning for extracting case-insensitive struct field from array of struct. This is the backport of #32059 to branch-2.4. ### Why are the changes needed? Under case-insensitive mode, nested column pruning rule cannot correctly push down extractor of a struct field of an array of struct, e.g., ```scala val query = spark.table("contacts").select("friends.First", "friends.MiDDle") ``` Error stack: ``` [info] java.lang.IllegalArgumentException: Field "First" does not exist. [info] Available fields: [info] at org.apache.spark.sql.types.StructType$$anonfun$apply$1.apply(StructType.scala:274) [info] at org.apache.spark.sql.types.StructType$$anonfun$apply$1.apply(StructType.scala:274) [info] at scala.collection.MapLike$class.getOrElse(MapLike.scala:128) [info] at scala.collection.AbstractMap.getOrElse(Map.scala:59) [info] at org.apache.spark.sql.types.StructType.apply(StructType.scala:273) [info] at org.apache.spark.sql.execution.ProjectionOverSchema$$anonfun$getProjection$3.apply(ProjectionOverSchema.scala:44) [info] at org.apache.spark.sql.execution.ProjectionOverSchema$$anonfun$getProjection$3.apply(ProjectionOverSchema.scala:41) ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test Closes #32112 from viirya/fix-array-nested-pruning-2.4. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 10 April 2021, 00:19:14 UTC |
| b4d9d4a | Liang-Chi Hsieh | 08 April 2021, 23:26:23 UTC | [SPARK-34994][BUILD][2.4] Fix git error when pushing the tag after release script succeeds ### What changes were proposed in this pull request? This patch proposes to fix an error when running release-script in 2.4 branch. ### Why are the changes needed? When I ran release script for cutting 2.4.8 RC1, either in dry-run or normal run at the last step "push the tag after success", I encounter the following error: ``` fatal: Not a git repository (or any parent up to mount parent ....) Stopping at filesystem boundary (GIT_DISCOVERY_ACROSS_FILESYSTEM not set). ``` ### Does this PR introduce _any_ user-facing change? No, dev only. ### How was this patch tested? Manual test. Closes #32100 from viirya/fix-release-script-2. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 08 April 2021, 23:26:23 UTC |
| f7ac0db | Kousuke Saruta | 08 April 2021, 15:42:12 UTC | [SPARK-34988][CORE][2.4] Upgrade Jetty for CVE-2021-28165 ### What changes were proposed in this pull request? This PR backports #32091. This PR upgrades the version of Jetty to 9.4.39. ### Why are the changes needed? CVE-2021-28165 affects the version of Jetty that Spark uses and it seems to be a little bit serious. https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-28165 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes #32093 from sarutak/backport-SPARK-34988. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Sean Owen <srowen@gmail.com> | 08 April 2021, 15:42:12 UTC |
| c36cea9 | Liang-Chi Hsieh | 07 April 2021, 03:59:51 UTC | Preparing development version 2.4.9-SNAPSHOT | 07 April 2021, 03:59:51 UTC |
| 53d37e4 | Liang-Chi Hsieh | 07 April 2021, 03:59:43 UTC | Preparing Spark release v2.4.8-rc1 | 07 April 2021, 03:59:43 UTC |
| 30436b5 | Liang-Chi Hsieh | 04 April 2021, 01:36:38 UTC | [SPARK-34939][CORE][2.4] Throw fetch failure exception when unable to deserialize broadcasted map statuses ### What changes were proposed in this pull request? This patch catches `IOException`, which is possibly thrown due to unable to deserialize map statuses (e.g., broadcasted value is destroyed), when deserilizing map statuses. Once `IOException` is caught, `MetadataFetchFailedException` is thrown to let Spark handle it. This is a backport of #32033 to branch-2.4. ### Why are the changes needed? One customer encountered application error. From the log, it is caused by accessing non-existing broadcasted value. The broadcasted value is map statuses. E.g., ``` [info] Cause: java.io.IOException: org.apache.spark.SparkException: Failed to get broadcast_0_piece0 of broadcast_0 [info] at org.apache.spark.util.Utils$.tryOrIOException(Utils.scala:1410) [info] at org.apache.spark.broadcast.TorrentBroadcast.readBroadcastBlock(TorrentBroadcast.scala:226) [info] at org.apache.spark.broadcast.TorrentBroadcast.getValue(TorrentBroadcast.scala:103) [info] at org.apache.spark.broadcast.Broadcast.value(Broadcast.scala:70) [info] at org.apache.spark.MapOutputTracker$.$anonfun$deserializeMapStatuses$3(MapOutputTracker.scala:967) [info] at org.apache.spark.internal.Logging.logInfo(Logging.scala:57) [info] at org.apache.spark.internal.Logging.logInfo$(Logging.scala:56) [info] at org.apache.spark.MapOutputTracker$.logInfo(MapOutputTracker.scala:887) [info] at org.apache.spark.MapOutputTracker$.deserializeMapStatuses(MapOutputTracker.scala:967) ``` There is a race-condition. After map statuses are broadcasted and the executors obtain serialized broadcasted map statuses. If any fetch failure happens after, Spark scheduler invalidates cached map statuses and destroy broadcasted value of the map statuses. Then any executor trying to deserialize serialized broadcasted map statuses and access broadcasted value, `IOException` will be thrown. Currently we don't catch it in `MapOutputTrackerWorker` and above exception will fail the application. Normally we should throw a fetch failure exception for such case. Spark scheduler will handle this. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test. Closes #32045 from viirya/fix-broadcast. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 04 April 2021, 01:36:38 UTC |
| 04485fe | Kousuke Saruta | 01 April 2021, 22:12:49 UTC | [SPARK-24931][INFRA][2.4] Fix the GA failure related to R linter ### What changes were proposed in this pull request? This PR backports the change of #32028 . This PR fixes the GA failure related to R linter which happens on some PRs (e.g. #32023, #32025). The reason seems `Rscript -e "devtools::install_github('jimhester/lintrv2.0.0')"` fails to download `lintrv2.0.0`. I don't know why but I confirmed we can download `v2.0.1`. ### Why are the changes needed? To keep GA healthy. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? GA itself. Closes #32029 from sarutak/backport-SPARK-24931. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Sean Owen <srowen@gmail.com> | 01 April 2021, 22:12:49 UTC |
| 58a859a | Liang-Chi Hsieh | 01 April 2021, 08:36:48 UTC | Revert "[SPARK-33935][SQL][2.4] Fix CBO cost function" This reverts commit 3e6a6b76ef1b25f80133e6cb8561ba943f3b29de per the discussion at https://github.com/apache/spark/pull/30965#discussion_r605396265. Closes #32020 from viirya/revert-SPARK-33935. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 01 April 2021, 08:36:48 UTC |
| f2ddbab | Tim Armstrong | 31 March 2021, 04:58:29 UTC | [SPARK-34909][SQL] Fix conversion of negative to unsigned in conv() Use `java.lang.Long.divideUnsigned()` to do integer division in `NumberConverter` to avoid a bug in `unsignedLongDiv` that produced invalid results. The previous results are incorrect, the result of the below query should be 45012021522523134134555 ``` scala> spark.sql("select conv('-10', 11, 7)").show(20, 150) +-----------------------+ | conv(-10, 11, 7)| +-----------------------+ |4501202152252313413456| +-----------------------+ scala> spark.sql("select hex(conv('-10', 11, 7))").show(20, 150) +----------------------------------------------+ | hex(conv(-10, 11, 7))| +----------------------------------------------+ |3435303132303231353232353233313334313334353600| +----------------------------------------------+ ``` `conv()` will produce different results because the bug is fixed. Added a simple unit test. Closes #32006 from timarmstrong/conv-unsigned. Authored-by: Tim Armstrong <tim.armstrong@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 13b255fefd881beb68fd8bb6741c7f88318baf9b) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 31 March 2021, 05:01:21 UTC |
| 38238d5 | Tanel Kiis | 29 March 2021, 11:14:35 UTC | [SPARK-34876][SQL][2.4] Fill defaultResult of non-nullable aggregates ### What changes were proposed in this pull request? Filled the `defaultResult` field on non-nullable aggregates ### Why are the changes needed? The `defaultResult` defaults to `None` and in some situations (like correlated scalar subqueries) it is used for the value of the aggregation. The UT result before the fix: ``` -- !query SELECT t1a, (SELECT count(t2d) FROM t2 WHERE t2a = t1a) count_t2, (SELECT approx_count_distinct(t2d) FROM t2 WHERE t2a = t1a) approx_count_distinct_t2, (SELECT collect_list(t2d) FROM t2 WHERE t2a = t1a) collect_list_t2, (SELECT collect_set(t2d) FROM t2 WHERE t2a = t1a) collect_set_t2, (SELECT hex(count_min_sketch(t2d, 0.5d, 0.5d, 1)) FROM t2 WHERE t2a = t1a) collect_set_t2 FROM t1 -- !query schema struct<t1a:string,count_t2:bigint,approx_count_distinct_t2:bigint,collect_list_t2:array<bigint>,collect_set_t2:array<bigint>,collect_set_t2:string> -- !query output val1a 0 NULL NULL NULL NULL val1a 0 NULL NULL NULL NULL val1a 0 NULL NULL NULL NULL val1a 0 NULL NULL NULL NULL val1b 6 3 [19,119,319,19,19,19] [19,119,319] 0000000100000000000000060000000100000004000000005D8D6AB90000000000000000000000000000000400000000000000010000000000000001 val1c 2 2 [219,19] [219,19] 0000000100000000000000020000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000001 val1d 0 NULL NULL NULL NULL val1d 0 NULL NULL NULL NULL val1d 0 NULL NULL NULL NULL val1e 1 1 [19] [19] 0000000100000000000000010000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000000 val1e 1 1 [19] [19] 0000000100000000000000010000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000000 val1e 1 1 [19] [19] 0000000100000000000000010000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000000 ``` ### Does this PR introduce _any_ user-facing change? Bugfix ### How was this patch tested? UT Closes #31991 from tanelk/SPARK-34876_non_nullable_agg_subquery_2.4. Authored-by: Tanel Kiis <tanel.kiis@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 29 March 2021, 11:14:35 UTC |
| 3e65ba9 | Liang-Chi Hsieh | 29 March 2021, 11:12:47 UTC | [SPARK-34855][CORE] Avoid local lazy variable in SparkContext.getCallSite ### What changes were proposed in this pull request? `SparkContext.getCallSite` uses local lazy variable. In Scala 2.11, local lazy val requires synchronization so for large number of job submissions in the same context, it will be a bottleneck. This only for branch-2.4 as we drop Scala 2.11 support at SPARK-26132. ### Why are the changes needed? To avoid possible bottleneck for large number of job submissions in the same context. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests. Closes #31988 from viirya/SPARK-34855. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 29 March 2021, 11:12:47 UTC |
| 102b723 | HyukjinKwon | 29 March 2021, 07:05:02 UTC | Revert "[SPARK-34876][SQL] Fill defaultResult of non-nullable aggregates" This reverts commit b83ab63384e4a6f235f7d3c7a53ed098b8e1b87e. | 29 March 2021, 07:05:02 UTC |
| b83ab63 | Tanel Kiis | 29 March 2021, 02:47:08 UTC | [SPARK-34876][SQL] Fill defaultResult of non-nullable aggregates ### What changes were proposed in this pull request? Filled the `defaultResult` field on non-nullable aggregates ### Why are the changes needed? The `defaultResult` defaults to `None` and in some situations (like correlated scalar subqueries) it is used for the value of the aggregation. The UT result before the fix: ``` -- !query SELECT t1a, (SELECT count(t2d) FROM t2 WHERE t2a = t1a) count_t2, (SELECT count_if(t2d > 0) FROM t2 WHERE t2a = t1a) count_if_t2, (SELECT approx_count_distinct(t2d) FROM t2 WHERE t2a = t1a) approx_count_distinct_t2, (SELECT collect_list(t2d) FROM t2 WHERE t2a = t1a) collect_list_t2, (SELECT collect_set(t2d) FROM t2 WHERE t2a = t1a) collect_set_t2, (SELECT hex(count_min_sketch(t2d, 0.5d, 0.5d, 1)) FROM t2 WHERE t2a = t1a) collect_set_t2 FROM t1 -- !query schema struct<t1a:string,count_t2:bigint,count_if_t2:bigint,approx_count_distinct_t2:bigint,collect_list_t2:array<bigint>,collect_set_t2:array<bigint>,collect_set_t2:string> -- !query output val1a 0 0 NULL NULL NULL NULL val1a 0 0 NULL NULL NULL NULL val1a 0 0 NULL NULL NULL NULL val1a 0 0 NULL NULL NULL NULL val1b 6 6 3 [19,119,319,19,19,19] [19,119,319] 0000000100000000000000060000000100000004000000005D8D6AB90000000000000000000000000000000400000000000000010000000000000001 val1c 2 2 2 [219,19] [219,19] 0000000100000000000000020000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000001 val1d 0 0 NULL NULL NULL NULL val1d 0 0 NULL NULL NULL NULL val1d 0 0 NULL NULL NULL NULL val1e 1 1 1 [19] [19] 0000000100000000000000010000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000000 val1e 1 1 1 [19] [19] 0000000100000000000000010000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000000 val1e 1 1 1 [19] [19] 0000000100000000000000010000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000000 ``` ### Does this PR introduce _any_ user-facing change? Bugfix ### How was this patch tested? UT Closes #31973 from tanelk/SPARK-34876_non_nullable_agg_subquery. Authored-by: Tanel Kiis <tanel.kiis@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 4b9e94c44412f399ba19e0ea90525d346942bf71) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 29 March 2021, 02:47:46 UTC |
| 8062ab0 | HyukjinKwon | 26 March 2021, 09:12:28 UTC | [SPARK-34874][INFRA] Recover test reports for failed GA builds ### What changes were proposed in this pull request? https://github.com/dawidd6/action-download-artifact/commit/621becc6d7c440318382ce6f4cb776f27dd3fef3#r48726074 there was a behaviour change in the download artifact plugin and it disabled the test reporting in failed builds. This PR recovers it by explicitly setting the conclusion from the workflow runs to search for the artifacts to download. ### Why are the changes needed? In order to properly report the failed test cases. ### Does this PR introduce _any_ user-facing change? No, it's dev only. ### How was this patch tested? Manually tested at https://github.com/HyukjinKwon/spark/pull/30 Before: 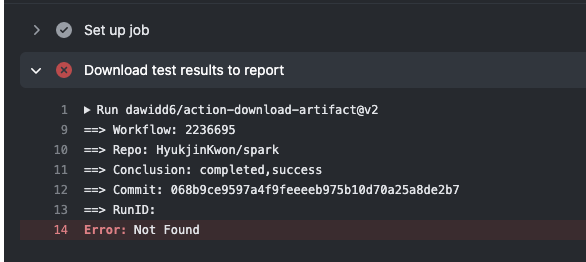 After:  Closes #31970 from HyukjinKwon/SPARK-34874. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit c8233f1be5c2f853f42cda367475eb135a83afd5) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 26 March 2021, 09:13:06 UTC |
| 615dbe1 | Takeshi Yamamuro | 26 March 2021, 02:20:19 UTC | [SPARK-34607][SQL][2.4] Add `Utils.isMemberClass` to fix a malformed class name error on jdk8u ### What changes were proposed in this pull request? This PR intends to fix a bug of `objects.NewInstance` if a user runs Spark on jdk8u and a given `cls` in `NewInstance` is a deeply-nested inner class, e.g.,. ``` object OuterLevelWithVeryVeryVeryLongClassName1 { object OuterLevelWithVeryVeryVeryLongClassName2 { object OuterLevelWithVeryVeryVeryLongClassName3 { object OuterLevelWithVeryVeryVeryLongClassName4 { object OuterLevelWithVeryVeryVeryLongClassName5 { object OuterLevelWithVeryVeryVeryLongClassName6 { object OuterLevelWithVeryVeryVeryLongClassName7 { object OuterLevelWithVeryVeryVeryLongClassName8 { object OuterLevelWithVeryVeryVeryLongClassName9 { object OuterLevelWithVeryVeryVeryLongClassName10 { object OuterLevelWithVeryVeryVeryLongClassName11 { object OuterLevelWithVeryVeryVeryLongClassName12 { object OuterLevelWithVeryVeryVeryLongClassName13 { object OuterLevelWithVeryVeryVeryLongClassName14 { object OuterLevelWithVeryVeryVeryLongClassName15 { object OuterLevelWithVeryVeryVeryLongClassName16 { object OuterLevelWithVeryVeryVeryLongClassName17 { object OuterLevelWithVeryVeryVeryLongClassName18 { object OuterLevelWithVeryVeryVeryLongClassName19 { object OuterLevelWithVeryVeryVeryLongClassName20 { case class MalformedNameExample2(x: Int) }}}}}}}}}}}}}}}}}}}} ``` The root cause that Kris (rednaxelafx) investigated is as follows (Kudos to Kris); The reason why the test case above is so convoluted is in the way Scala generates the class name for nested classes. In general, Scala generates a class name for a nested class by inserting the dollar-sign ( `$` ) in between each level of class nesting. The problem is that this format can concatenate into a very long string that goes beyond certain limits, so Scala will change the class name format beyond certain length threshold. For the example above, we can see that the first two levels of class nesting have class names that look like this: ``` org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassName1$ org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassName1$OuterLevelWithVeryVeryVeryLongClassName2$ ``` If we leave out the fact that Scala uses a dollar-sign ( `$` ) suffix for the class name of the companion object, `OuterLevelWithVeryVeryVeryLongClassName1`'s full name is a prefix (substring) of `OuterLevelWithVeryVeryVeryLongClassName2`. But if we keep going deeper into the levels of nesting, you'll find names that look like: ``` org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$2a1321b953c615695d7442b2adb1$$$$ryVeryLongClassName8$OuterLevelWithVeryVeryVeryLongClassName9$OuterLevelWithVeryVeryVeryLongClassName10$ org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$2a1321b953c615695d7442b2adb1$$$$ryVeryLongClassName8$OuterLevelWithVeryVeryVeryLongClassName9$OuterLevelWithVeryVeryVeryLongClassName10$OuterLevelWithVeryVeryVeryLongClassName11$ org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$85f068777e7ecf112afcbe997d461b$$$$VeryLongClassName11$OuterLevelWithVeryVeryVeryLongClassName12$ org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$85f068777e7ecf112afcbe997d461b$$$$VeryLongClassName11$OuterLevelWithVeryVeryVeryLongClassName12$OuterLevelWithVeryVeryVeryLongClassName13$ org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$85f068777e7ecf112afcbe997d461b$$$$VeryLongClassName11$OuterLevelWithVeryVeryVeryLongClassName12$OuterLevelWithVeryVeryVeryLongClassName13$OuterLevelWithVeryVeryVeryLongClassName14$ org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$5f7ad51804cb1be53938ea804699fa$$$$VeryLongClassName14$OuterLevelWithVeryVeryVeryLongClassName15$ org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$5f7ad51804cb1be53938ea804699fa$$$$VeryLongClassName14$OuterLevelWithVeryVeryVeryLongClassName15$OuterLevelWithVeryVeryVeryLongClassName16$ org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$5f7ad51804cb1be53938ea804699fa$$$$VeryLongClassName14$OuterLevelWithVeryVeryVeryLongClassName15$OuterLevelWithVeryVeryVeryLongClassName16$OuterLevelWithVeryVeryVeryLongClassName17$ org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$69b54f16b1965a31e88968df1a58d8$$$$VeryLongClassName17$OuterLevelWithVeryVeryVeryLongClassName18$ org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$69b54f16b1965a31e88968df1a58d8$$$$VeryLongClassName17$OuterLevelWithVeryVeryVeryLongClassName18$OuterLevelWithVeryVeryVeryLongClassName19$ org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$69b54f16b1965a31e88968df1a58d8$$$$VeryLongClassName17$OuterLevelWithVeryVeryVeryLongClassName18$OuterLevelWithVeryVeryVeryLongClassName19$OuterLevelWithVeryVeryVeryLongClassName20$ ``` with a hash code in the middle and various levels of nesting omitted. The `java.lang.Class.isMemberClass` method is implemented in JDK8u as: http://hg.openjdk.java.net/jdk8u/jdk8u/jdk/file/tip/src/share/classes/java/lang/Class.java#l1425 ``` /** * Returns {code true} if and only if the underlying class * is a member class. * * return {code true} if and only if this class is a member class. * since 1.5 */ public boolean isMemberClass() { return getSimpleBinaryName() != null && !isLocalOrAnonymousClass(); } /** * Returns the "simple binary name" of the underlying class, i.e., * the binary name without the leading enclosing class name. * Returns {code null} if the underlying class is a top level * class. */ private String getSimpleBinaryName() { Class<?> enclosingClass = getEnclosingClass(); if (enclosingClass == null) // top level class return null; // Otherwise, strip the enclosing class' name try { return getName().substring(enclosingClass.getName().length()); } catch (IndexOutOfBoundsException ex) { throw new InternalError("Malformed class name", ex); } } ``` and the problematic code is `getName().substring(enclosingClass.getName().length())` -- if a class's enclosing class's full name is *longer* than the nested class's full name, this logic would end up going out of bounds. The bug has been fixed in JDK9 by https://bugs.java.com/bugdatabase/view_bug.do?bug_id=8057919 , but still exists in the latest JDK8u release. So from the Spark side we'd need to do something to avoid hitting this problem. This is the backport of #31733. ### Why are the changes needed? Bugfix on jdk8u. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Added tests. Closes #31747 from maropu/SPARK34607-BRANCH2.4. Authored-by: Takeshi Yamamuro <yamamuro@apache.org> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 26 March 2021, 02:20:19 UTC |
| 6ee1c08 | Takeshi Yamamuro | 24 March 2021, 17:37:32 UTC | [SPARK-34596][SQL][2.4] Use Utils.getSimpleName to avoid hitting Malformed class name in NewInstance.doGenCode ### What changes were proposed in this pull request? Use `Utils.getSimpleName` to avoid hitting `Malformed class name` error in `NewInstance.doGenCode`. NOTE: branch-2.4 does not have the interpreted implementation of `SafeProjection`, so it does not fall back into the interpreted mode if the compilation fails. Therefore, the test in this PR just checks that the compilation error happens instead of checking that the interpreted mode works well. This is the backport PR of #31709 and the credit should be rednaxelafx . ### Why are the changes needed? On older JDK versions (e.g. JDK8u), nested Scala classes may trigger `java.lang.Class.getSimpleName` to throw an `java.lang.InternalError: Malformed class name` error. In this particular case, creating an `ExpressionEncoder` on such a nested Scala class would create a `NewInstance` expression under the hood, which will trigger the problem during codegen. Similar to https://github.com/apache/spark/pull/29050, we should use Spark's `Utils.getSimpleName` utility function in place of `Class.getSimpleName` to avoid hitting the issue. There are two other occurrences of `java.lang.Class.getSimpleName` in the same file, but they're safe because they're only guaranteed to be only used on Java classes, which don't have this problem, e.g.: ```scala // Make a copy of the data if it's unsafe-backed def makeCopyIfInstanceOf(clazz: Class[_ <: Any], value: String) = s"$value instanceof ${clazz.getSimpleName}? ${value}.copy() : $value" val genFunctionValue: String = lambdaFunction.dataType match { case StructType(_) => makeCopyIfInstanceOf(classOf[UnsafeRow], genFunction.value) case ArrayType(_, _) => makeCopyIfInstanceOf(classOf[UnsafeArrayData], genFunction.value) case MapType(_, _, _) => makeCopyIfInstanceOf(classOf[UnsafeMapData], genFunction.value) case _ => genFunction.value } ``` The Unsafe-* family of types are all Java types, so they're okay. ### Does this PR introduce _any_ user-facing change? Fixes a bug that throws an error when using `ExpressionEncoder` on some nested Scala types, otherwise no changes. ### How was this patch tested? Added a test case to `org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite`. It'll fail on JDK8u before the fix, and pass after the fix. Closes #31888 from maropu/SPARK-34596-BRANCH2.4. Lead-authored-by: Takeshi Yamamuro <yamamuro@apache.org> Co-authored-by: Kris Mok <kris.mok@databricks.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 24 March 2021, 17:37:32 UTC |
| e756130 | Lena | 23 March 2021, 07:13:32 UTC | [MINOR][DOCS] Updating the link for Azure Data Lake Gen 2 in docs Current link for `Azure Blob Storage and Azure Datalake Gen 2` leads to AWS information. Replacing the link to point to the right page. For users to access to the correct link. Yes, it fixes the link correctly. N/A Closes #31938 from lenadroid/patch-1. Authored-by: Lena <alehall@microsoft.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> (cherry picked from commit d32bb4e5ee4718741252c46c50a40810b722f12d) Signed-off-by: Max Gekk <max.gekk@gmail.com> | 23 March 2021, 07:18:00 UTC |
| 5685d84 | Peter Toth | 22 March 2021, 16:28:05 UTC | [SPARK-34726][SQL][2.4] Fix collectToPython timeouts ### What changes were proposed in this pull request? One of our customers frequently encounters `"serve-DataFrame" java.net.SocketTimeoutException: Accept timed` errors in PySpark because `DataSet.collectToPython()` in Spark 2.4 does the following: 1. Collects the results 2. Opens up a socket server that is then listening to the connection from Python side 3. Runs the event listeners as part of `withAction` on the same thread as SPARK-25680 is not available in Spark 2.4 4. Returns the address of the socket server to Python 5. The Python side connects to the socket server and fetches the data As the customer has a custom, long running event listener the time between 2. and 5. is frequently longer than the default connection timeout and increasing the connect timeout is not a good solution as we don't know how long running the listeners can take. ### Why are the changes needed? This PR simply moves the socket server creation (2.) after running the listeners (3.). I think this approach has has a minor side effect that errors in socket server creation are not reported as `onFailure` events, but currently errors happening during opening the connection from Python side or data transfer from JVM to Python are also not reported as events so IMO this is not a big change. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Added new UT + manual test. Closes #31818 from peter-toth/SPARK-34726-fix-collectToPython-timeouts-2.4. Lead-authored-by: Peter Toth <ptoth@cloudera.com> Co-authored-by: Peter Toth <peter.toth@gmail.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 22 March 2021, 16:28:05 UTC |
| ce58e05 | Wenchen Fan | 20 March 2021, 02:09:50 UTC | [SPARK-34719][SQL][2.4] Correctly resolve the view query with duplicated column names backport https://github.com/apache/spark/pull/31811 to 2.4 For permanent views (and the new SQL temp view in Spark 3.1), we store the view SQL text and re-parse/analyze the view SQL text when reading the view. In the case of `SELECT * FROM ...`, we want to avoid view schema change (e.g. the referenced table changes its schema) and will record the view query output column names when creating the view, so that when reading the view we can add a `SELECT recorded_column_names FROM ...` to retain the original view query schema. In Spark 3.1 and before, the final SELECT is added after the analysis phase: https://github.com/apache/spark/blob/branch-3.1/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/view.scala#L67 If the view query has duplicated output column names, we always pick the first column when reading a view. A simple repro: ``` scala> sql("create view c(x, y) as select 1 a, 2 a") res0: org.apache.spark.sql.DataFrame = [] scala> sql("select * from c").show +---+---+ | x| y| +---+---+ | 1| 1| +---+---+ ``` In the master branch, we will fail at the view reading time due to https://github.com/apache/spark/commit/b891862fb6b740b103d5a09530626ee4e0e8f6e3 , which adds the final SELECT during analysis, so that the query fails with `Reference 'a' is ambiguous` This PR proposes to resolve the view query output column names from the matching attributes by ordinal. For example, `create view c(x, y) as select 1 a, 2 a`, the view query output column names are `[a, a]`. When we reading the view, there are 2 matching attributes (e.g.`[a#1, a#2]`) and we can simply match them by ordinal. A negative example is ``` create table t(a int) create view v as select *, 1 as col from t replace table t(a int, col int) ``` When reading the view, the view query output column names are `[a, col]`, and there are two matching attributes of `col`, and we should fail the query. See the tests for details. bug fix yes new test Closes #31894 from cloud-fan/backport. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org> | 22 March 2021, 15:52:02 UTC |
| 29b981b | Dongjoon Hyun | 21 March 2021, 21:08:34 UTC | [SPARK-34811][CORE] Redact fs.s3a.access.key like secret and token ### What changes were proposed in this pull request? Like we redact secrets and tokens, this PR aims to redact access key. ### Why are the changes needed? Access key is also worth to hide. ### Does this PR introduce _any_ user-facing change? This will hide this information from SparkUI (`Spark Properties` and `Hadoop Properties` and logs). ### How was this patch tested? Pass the newly updated UT. Closes #31912 from dongjoon-hyun/SPARK-34811. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 3c32b54a0fbdc55c503bc72a3d39d58bf99e3bfa) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 21 March 2021, 21:09:13 UTC |
| 7879a0c | Vinoo Ganesh | 16 January 2019, 19:43:10 UTC | [SPARK-26625] Add oauthToken to spark.redaction.regex ## What changes were proposed in this pull request? The regex (spark.redaction.regex) that is used to decide which config properties or environment settings are sensitive should also include oauthToken to match spark.kubernetes.authenticate.submission.oauthToken ## How was this patch tested? Simple regex addition - happy to add a test if needed. Author: Vinoo Ganesh <vganesh@palantir.com> Closes #23555 from vinooganesh/vinooganesh/SPARK-26625. (cherry picked from commit 01301d09721cc12f1cc66ab52de3da117f5d33e6) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 21 March 2021, 07:01:20 UTC |
| 59e4ae4 | Liang-Chi Hsieh | 20 March 2021, 02:26:01 UTC | [SPARK-34776][SQL][3.0][2.4] Window class should override producedAttributes ### What changes were proposed in this pull request? This patch proposes to override `producedAttributes` of `Window` class. ### Why are the changes needed? This is a backport of #31897 to branch-3.0/2.4. Unlike original PR, nested column pruning does not allow pushing through `Window` in branch-3.0/2.4 yet. But `Window` doesn't override `producedAttributes`. It's wrong and could cause potential issue. So backport `Window` related change. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests. Closes #31904 from viirya/SPARK-34776-3.0. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org> (cherry picked from commit 828cf76bced1b70769b0453f3e9ba95faaa84e39) Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org> | 20 March 2021, 02:26:24 UTC |
| c5d81cb | yangjie01 | 19 March 2021, 21:12:51 UTC | [SPARK-34774][BUILD][2.4] Ensure change-scala-version.sh update scala.version in parent POM correctly ### What changes were proposed in this pull request? After SPARK-34507, execute` change-scala-version.sh` script will update `scala.version` in parent pom, but if we execute the following commands in order: ``` dev/change-scala-version.sh 2.12 dev/change-scala-version.sh 2.11 git status ``` there will generate git diff as follow: ``` diff --git a/pom.xml b/pom.xml index f4a50dc5c1..89fd7d88af 100644 --- a/pom.xml +++ b/pom.xml -155,7 +155,7 <commons.math3.version>3.4.1</commons.math3.version> <commons.collections.version>3.2.2</commons.collections.version> - <scala.version>2.11.12</scala.version> + <scala.version>2.12.10</scala.version> <scala.binary.version>2.11</scala.binary.version> <codehaus.jackson.version>1.9.13</codehaus.jackson.version> <fasterxml.jackson.version>2.6.7</fasterxml.jackson.version> ``` seem 'scala.version' property was not update correctly. So this pr add an extra 'scala.version' to scala-2.11 profile to ensure change-scala-version.sh can update the public `scala.version` property correctly. ### Why are the changes needed? Bug fix. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? **Manual test** Execute the following commands in order: ``` dev/change-scala-version.sh 2.12 dev/change-scala-version.sh 2.11 git status ``` **Before** ``` diff --git a/pom.xml b/pom.xml index f4a50dc5c1..89fd7d88af 100644 --- a/pom.xml +++ b/pom.xml -155,7 +155,7 <commons.math3.version>3.4.1</commons.math3.version> <commons.collections.version>3.2.2</commons.collections.version> - <scala.version>2.11.12</scala.version> + <scala.version>2.12.10</scala.version> <scala.binary.version>2.11</scala.binary.version> <codehaus.jackson.version>1.9.13</codehaus.jackson.version> <fasterxml.jackson.version>2.6.7</fasterxml.jackson.version> ``` **After** No git diff. Closes #31893 from LuciferYang/SPARK-34774-24. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Sean Owen <srowen@gmail.com> | 19 March 2021, 21:12:51 UTC |
| 3c627ad | Dongjoon Hyun | 16 March 2021, 01:49:54 UTC | [MINOR][SQL] Remove unused variable in NewInstance.constructor ### What changes were proposed in this pull request? This PR removes one unused variable in `NewInstance.constructor`. ### Why are the changes needed? This looks like a variable for debugging at the initial commit of SPARK-23584 . - https://github.com/apache/spark/commit/1b08c4393cf48e21fea9914d130d8d3bf544061d#diff-2a36e31684505fd22e2d12a864ce89fd350656d716a3f2d7789d2cdbe38e15fbR461 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass the CIs. Closes #31838 from dongjoon-hyun/minor-object. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 0a70dff0663320cabdbf4e4ecb771071582f9417) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 16 March 2021, 01:50:43 UTC |
| 7b7a8fe | Dongjoon Hyun | 15 March 2021, 09:30:54 UTC | [SPARK-34743][SQL][TESTS] ExpressionEncoderSuite should use deepEquals when we expect `array of array` ### What changes were proposed in this pull request? This PR aims to make `ExpressionEncoderSuite` to use `deepEquals` instead of `equals` when `input` is `array of array`. This comparison code itself was added by SPARK-11727 at Apache Spark 1.6.0. ### Why are the changes needed? Currently, the interpreted mode fails for `array of array` because the following line is used. ``` Arrays.equals(b1.asInstanceOf[Array[AnyRef]], b2.asInstanceOf[Array[AnyRef]]) ``` ### Does this PR introduce _any_ user-facing change? No. This is a test-only PR. ### How was this patch tested? Pass the existing CIs. Closes #31837 from dongjoon-hyun/SPARK-34743. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 363a7f0722522898337b926224bf46bb9c32176c) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 15 March 2021, 09:38:52 UTC |
| 41f46cf | Dongjoon Hyun | 12 March 2021, 12:30:46 UTC | [SPARK-34724][SQL] Fix Interpreted evaluation by using getMethod instead of getDeclaredMethod This bug was introduced by SPARK-23583 at Apache Spark 2.4.0. This PR aims to use `getMethod` instead of `getDeclaredMethod`. ```scala - obj.getClass.getDeclaredMethod(functionName, argClasses: _*) + obj.getClass.getMethod(functionName, argClasses: _*) ``` `getDeclaredMethod` does not search the super class's method. To invoke `GenericArrayData.toIntArray`, we need to use `getMethod` because it's declared at the super class `ArrayData`. ``` [info] - encode/decode for array of int: [I74655d03 (interpreted path) *** FAILED *** (14 milliseconds) [info] Exception thrown while decoding [info] Converted: [0,1000000020,3,0,ffffff850000001f,4] [info] Schema: value#680 [info] root [info] -- value: array (nullable = true) [info] |-- element: integer (containsNull = false) [info] [info] [info] Encoder: [info] class[value[0]: array<int>] (ExpressionEncoderSuite.scala:578) [info] org.scalatest.exceptions.TestFailedException: [info] at org.scalatest.Assertions.newAssertionFailedException(Assertions.scala:472) [info] at org.scalatest.Assertions.newAssertionFailedException$(Assertions.scala:471) [info] at org.scalatest.funsuite.AnyFunSuite.newAssertionFailedException(AnyFunSuite.scala:1563) [info] at org.scalatest.Assertions.fail(Assertions.scala:949) [info] at org.scalatest.Assertions.fail$(Assertions.scala:945) [info] at org.scalatest.funsuite.AnyFunSuite.fail(AnyFunSuite.scala:1563) [info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.$anonfun$encodeDecodeTest$1(ExpressionEncoderSuite.scala:578) [info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.verifyNotLeakingReflectionObjects(ExpressionEncoderSuite.scala:656) [info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.$anonfun$testAndVerifyNotLeakingReflectionObjects$2(ExpressionEncoderSuite.scala:669) [info] at org.apache.spark.sql.catalyst.plans.CodegenInterpretedPlanTest.$anonfun$test$4(PlanTest.scala:50) [info] at org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf(SQLHelper.scala:54) [info] at org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf$(SQLHelper.scala:38) [info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.withSQLConf(ExpressionEncoderSuite.scala:118) [info] at org.apache.spark.sql.catalyst.plans.CodegenInterpretedPlanTest.$anonfun$test$3(PlanTest.scala:50) ... [info] Cause: java.lang.RuntimeException: Error while decoding: java.lang.NoSuchMethodException: org.apache.spark.sql.catalyst.util.GenericArrayData.toIntArray() [info] mapobjects(lambdavariable(MapObject, IntegerType, false, -1), assertnotnull(lambdavariable(MapObject, IntegerType, false, -1)), input[0, array<int>, true], None).toIntArray [info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoder$Deserializer.apply(ExpressionEncoder.scala:186) [info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.$anonfun$encodeDecodeTest$1(ExpressionEncoderSuite.scala:576) [info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.verifyNotLeakingReflectionObjects(ExpressionEncoderSuite.scala:656) [info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.$anonfun$testAndVerifyNotLeakingReflectionObjects$2(ExpressionEncoderSuite.scala:669) ``` This causes a runtime exception when we use the interpreted mode. Pass the modified unit test case. Closes #31816 from dongjoon-hyun/SPARK-34724. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 9a7977933fd08d0e95ffa59161bed3b10bc9ca61) Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 99a6a1af6d3f2c28eb65decc17ee1a015f89f0d2) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 12 March 2021, 12:32:42 UTC |
| 7e0fbe0 | William Hyun | 25 May 2020, 01:25:43 UTC | [SPARK-31807][INFRA] Use python 3 style in release-build.sh ### What changes were proposed in this pull request? This PR aims to use the style that is compatible with both python 2 and 3. ### Why are the changes needed? This will help python 3 migration. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manual. Closes #28632 from williamhyun/use_python3_style. Authored-by: William Hyun <williamhyun3@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 753636e86b1989a9b43ec691de5136a70d11f323) Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 40e5de54e6109762d3ee85197da4fa1a8b20e13b) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 12 March 2021, 00:32:16 UTC |
| 6ec74e2 | Dongjoon Hyun | 11 March 2021, 07:41:49 UTC | [SPARK-34696][SQL][TESTS] Fix CodegenInterpretedPlanTest to generate correct test cases SPARK-23596 added `CodegenInterpretedPlanTest` at Apache Spark 2.4.0 in a wrong way because `withSQLConf` depends on the execution time `SQLConf.get` instead of `test` function declaration time. So, the following code executes the test twice without controlling the `CodegenObjectFactoryMode`. This PR aims to fix it correct and introduce a new function `testFallback`. ```scala trait CodegenInterpretedPlanTest extends PlanTest { override protected def test( testName: String, testTags: Tag*)(testFun: => Any)(implicit pos: source.Position): Unit = { val codegenMode = CodegenObjectFactoryMode.CODEGEN_ONLY.toString val interpretedMode = CodegenObjectFactoryMode.NO_CODEGEN.toString withSQLConf(SQLConf.CODEGEN_FACTORY_MODE.key -> codegenMode) { super.test(testName + " (codegen path)", testTags: _*)(testFun)(pos) } withSQLConf(SQLConf.CODEGEN_FACTORY_MODE.key -> interpretedMode) { super.test(testName + " (interpreted path)", testTags: _*)(testFun)(pos) } } } ``` 1. We need to use like the following. ```scala super.test(testName + " (codegen path)", testTags: _*)( withSQLConf(SQLConf.CODEGEN_FACTORY_MODE.key -> codegenMode) { testFun })(pos) super.test(testName + " (interpreted path)", testTags: _*)( withSQLConf(SQLConf.CODEGEN_FACTORY_MODE.key -> interpretedMode) { testFun })(pos) ``` 2. After we fix this behavior with the above code, several test cases including SPARK-34596 and SPARK-34607 fail because they didn't work at both `CODEGEN` and `INTERPRETED` mode. Those test cases only work at `FALLBACK` mode. So, inevitably, we need to introduce `testFallback`. No. Pass the CIs. Closes #31766 from dongjoon-hyun/SPARK-34596-SPARK-34607. Lead-authored-by: Dongjoon Hyun <dhyun@apple.com> Co-authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 5c4d8f95385ac97a66e5b491b5883ec770ae85bd) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 11 March 2021, 07:51:45 UTC |
| 906df15 | Liang-Chi Hsieh | 11 March 2021, 02:42:11 UTC | [SPARK-34703][PYSPARK][2.4] Fix pyspark test when using sort_values on Pandas ### What changes were proposed in this pull request? This patch fixes a few PySpark test error related to Pandas, in order to restore 2.4 Jenkins builds. ### Why are the changes needed? There are APIs changed since Pandas 0.24. If there are index and column name are the same, `sort_values` will throw error. Three PySpark tests are currently failed in Jenkins 2.4 build: `test_column_order`, `test_complex_groupby`, `test_udf_with_key`: ``` ====================================================================== ERROR: test_column_order (pyspark.sql.tests.GroupedMapPandasUDFTests) ---------------------------------------------------------------------- Traceback (most recent call last): File "/spark/python/pyspark/sql/tests.py", line 5996, in test_column_order expected = pd_result.sort_values(['id', 'v']).reset_index(drop=True) File "/usr/local/lib/python2.7/dist-packages/pandas/core/frame.py", line 4711, in sort_values for x in by] File "/usr/local/lib/python2.7/dist-packages/pandas/core/generic.py", line 1702, in _get_label_or_level_values self._check_label_or_level_ambiguity(key, axis=axis) File "/usr/local/lib/python2.7/dist-packages/pandas/core/generic.py", line 1656, in _check_label_or_level_ambiguity raise ValueError(msg) ValueError: 'id' is both an index level and a column label, which is ambiguous. ====================================================================== ERROR: test_complex_groupby (pyspark.sql.tests.GroupedMapPandasUDFTests) ---------------------------------------------------------------------- Traceback (most recent call last): File "/spark/python/pyspark/sql/tests.py", line 5765, in test_complex_groupby expected = expected.sort_values(['id', 'v']).reset_index(drop=True) File "/usr/local/lib/python2.7/dist-packages/pandas/core/frame.py", line 4711, in sort_values for x in by] File "/usr/local/lib/python2.7/dist-packages/pandas/core/generic.py", line 1702, in _get_label_or_level_values self._check_label_or_level_ambiguity(key, axis=axis) File "/usr/local/lib/python2.7/dist-packages/pandas/core/generic.py", line 1656, in _check_label_or_level_ambiguity raise ValueError(msg) ValueError: 'id' is both an index level and a column label, which is ambiguous. ====================================================================== ERROR: test_udf_with_key (pyspark.sql.tests.GroupedMapPandasUDFTests) ---------------------------------------------------------------------- Traceback (most recent call last): File "/spark/python/pyspark/sql/tests.py", line 5922, in test_udf_with_key .sort_values(['id', 'v']).reset_index(drop=True) File "/usr/local/lib/python2.7/dist-packages/pandas/core/frame.py", line 4711, in sort_values for x in by] File "/usr/local/lib/python2.7/dist-packages/pandas/core/generic.py", line 1702, in _get_label_or_level_values self._check_label_or_level_ambiguity(key, axis=axis) File "/usr/local/lib/python2.7/dist-packages/pandas/core/generic.py", line 1656, in _check_label_or_level_ambiguity raise ValueError(msg) ValueError: 'id' is both an index level and a column label, which is ambiguous. ``` ### Does this PR introduce _any_ user-facing change? No, dev only. ### How was this patch tested? Verified by running the tests locally. Closes #31803 from viirya/SPARK-34703. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 11 March 2021, 02:42:11 UTC |
| 7985360 | Sean Owen | 11 March 2021, 01:02:24 UTC | [SPARK-34507][BUILD] Update scala.version in parent POM when changing Scala version for cross-build ### What changes were proposed in this pull request? The `change-scala-version.sh` script updates Scala versions across the build for cross-build purposes. It manually changes `scala.binary.version` but not `scala.version`. ### Why are the changes needed? It seems that this has always been an oversight, and the cross-built builds of Spark have an incorrect scala.version. See 2.4.5's 2.12 POM for example, which shows a Scala 2.11 version. https://search.maven.org/artifact/org.apache.spark/spark-core_2.12/2.4.5/pom More comments in the JIRA. ### Does this PR introduce _any_ user-facing change? Should be a build-only bug fix. ### How was this patch tested? Existing tests, but really N/A Closes #31801 from srowen/SPARK-34507. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 11 March 2021, 01:39:32 UTC |
| 191b24c | Liang-Chi Hsieh | 09 March 2021, 12:30:42 UTC | [SPARK-34672][BUILD][2.4] Fix docker file for creating release ### What changes were proposed in this pull request? This patch pins the pip and setuptools versions during building docker image of `spark-rm`. ### Why are the changes needed? The `Dockerfile` of `spark-rm` in `branch-2.4` seems not working for now. It tries to install latest `pip` and `setuptools` which are not compatible with Python2. So it fails the docker image building. ### Does this PR introduce _any_ user-facing change? No, dev only. ### How was this patch tested? Ran release script locally. Closes #31787 from viirya/fix-release-script. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 09 March 2021, 12:30:42 UTC |
| eb4601e | Baohe Zhang | 04 March 2021, 23:37:33 UTC | [SPARK-32924][WEBUI] Make duration column in master UI sorted in the correct order ### What changes were proposed in this pull request? Make the "duration" column in standalone mode master UI sorted by numeric duration, hence the column can be sorted by the correct order. Before changes:  After changes:  ### Why are the changes needed? Fix a UI bug to make the sorting consistent across different pages. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Ran several apps with different durations and verified the duration column on the master page can be sorted correctly. Closes #31743 from baohe-zhang/SPARK-32924. Authored-by: Baohe Zhang <baohe.zhang@verizonmedia.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 9ac5ee2e17ca491eabf2e6e7d33ce7cfb5a002a7) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 04 March 2021, 23:38:10 UTC |
| 96f5137 | yuhaiyang | 25 February 2021, 19:00:51 UTC | [SPARK-30228][BUILD][2.4] Update zstd-jni to 1.4.4-3 ### What changes were proposed in this pull request? Change zstd-jni version to version 1.4.4-3 ### Why are the changes needed? This old zstd-jni(tag 1.3.3-2) has probability to read less data when shuffle read. The `ZstdInputStream` in zstd-jni(tag 1.3.3-2) maybe return 0 after a read function call, this doesn't meet the standard of `InputStream` and the `InputStream` will not return 0 unless len is 0; Spark will use a BufferedInputStream wrapped to ZstdInputStream, when ZstdInputStream read call return 0, BufferedInputStream will consider the 0 as the end of read and exit, this can lead data loss. zstd-jni issues: https://github.com/luben/zstd-jni/issues/159 zstd-jni commits: https://github.com/luben/zstd-jni/commit/7eec5581b8ccb0d98350ad5ba422337eebbbe70e ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? Closes #31645 from seayoun/yuhaiyang_update_zstd_jni. Authored-by: yuhaiyang <yuhaiyang@yuhaiyangs-MacBook-Pro.local> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 25 February 2021, 19:00:51 UTC |
| 9807250 | Kousuke Saruta | 20 February 2021, 03:43:18 UTC | [SPARK-34449][BUILD][2.4] Upgrade Jetty to fix CVE-2020-27218 ### What changes were proposed in this pull request? This PR backports #31574 (SPARK-34449) for `branch-2.4`, upgrading Jetty from `9.4.34` to `9.4.36`. ### Why are the changes needed? CVE-2020-27218 affects currently used Jetty 9.4.34. https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-27218 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Jenkins and GA. Closes #31583 from sarutak/SPARK-34449-branch-2.4. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 20 February 2021, 03:43:18 UTC |
| c9683be | yzjg | 19 February 2021, 01:45:21 UTC | [MINOR][SQL][DOCS] Fix the comments in the example at window function `functions.scala` window function has an comment error in the field name. The column should be `time` per `timestamp:TimestampType`. To deliver the correct documentation and examples. Yes, it fixes the user-facing docs. CI builds in this PR should test the documentation build. Closes #31582 from yzjg/yzjg-patch-1. Authored-by: yzjg <785246661@qq.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 26548edfa2445b009f63bbdbe810cdb6c289c18d) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 19 February 2021, 01:46:40 UTC |
| fa78e68 | Dongjoon Hyun | 09 February 2021, 05:47:23 UTC | [SPARK-34407][K8S] KubernetesClusterSchedulerBackend.stop should clean up K8s resources This PR aims to fix `KubernetesClusterSchedulerBackend.stop` to wrap `super.stop` with `Utils.tryLogNonFatalError`. [CoarseGrainedSchedulerBackend.stop](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/scheduler/cluster/CoarseGrainedSchedulerBackend.scala#L559) may throw `SparkException` and this causes K8s resource (pod and configmap) leakage. No. This is a bug fix. Pass the CI with the newly added test case. Closes #31533 from dongjoon-hyun/SPARK-34407. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit ea339c38b43c59931257386efdd490507f7de64d) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 09 February 2021, 05:53:26 UTC |
| e7acca2 | Kousuke Saruta | 04 February 2021, 01:51:56 UTC | [SPARK-34318][SQL][2.4] Dataset.colRegex should work with column names and qualifiers which contain newlines ### What changes were proposed in this pull request? Backport of #31426 for the record. This PR fixes an issue that `Dataset.colRegex` doesn't work with column names or qualifiers which contain newlines. In the current master, if column names or qualifiers passed to `colRegex` contain newlines, it throws exception. ``` val df = Seq(1, 2, 3).toDF("test\n_column").as("test\n_table") val col1 = df.colRegex("`tes.*\n.*mn`") org.apache.spark.sql.AnalysisException: Cannot resolve column name "`tes.* .*mn`" among (test _column) at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$resolveException(Dataset.scala:272) at org.apache.spark.sql.Dataset.$anonfun$resolve$1(Dataset.scala:263) at scala.Option.getOrElse(Option.scala:189) at org.apache.spark.sql.Dataset.resolve(Dataset.scala:263) at org.apache.spark.sql.Dataset.colRegex(Dataset.scala:1407) ... 47 elided val col2 = df.colRegex("test\n_table.`tes.*\n.*mn`") org.apache.spark.sql.AnalysisException: Cannot resolve column name "test _table.`tes.* .*mn`" among (test _column) at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$resolveException(Dataset.scala:272) at org.apache.spark.sql.Dataset.$anonfun$resolve$1(Dataset.scala:263) at scala.Option.getOrElse(Option.scala:189) at org.apache.spark.sql.Dataset.resolve(Dataset.scala:263) at org.apache.spark.sql.Dataset.colRegex(Dataset.scala:1407) ... 47 elided ``` ### Why are the changes needed? Column names and qualifiers can contain newlines but `colRegex` can't work with them, so it's a bug. ### Does this PR introduce _any_ user-facing change? Yes. users can pass column names and qualifiers even though they contain newlines. ### How was this patch tested? New test. Closes #31459 from sarutak/SPARK-34318-branch-2.4. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 04 February 2021, 01:51:56 UTC |
| 90db0ab | Prashant Sharma | 03 February 2021, 06:02:35 UTC | [SPARK-34327][BUILD] Strip passwords from inlining into build information while releasing ### What changes were proposed in this pull request? Strip passwords from getting inlined into build information, inadvertently. ` https://user:passdomain/foo -> https://domain/foo` ### Why are the changes needed? This can be a serious security issue, esp. during a release. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Tested by executing the following command on both Mac OSX and Ubuntu. ``` echo url=$(git config --get remote.origin.url | sed 's|https://\(.*\)\(.*\)|https://\2|') ``` Closes #31436 from ScrapCodes/strip_pass. Authored-by: Prashant Sharma <prashsh1@in.ibm.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 89bf2afb3337a44f34009a36cae16dd0ff86b353) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 03 February 2021, 06:03:23 UTC |
| 5f4e9ea | Wenchen Fan | 03 February 2021, 00:26:36 UTC | [SPARK-34212][SQL][FOLLOWUP] Parquet vectorized reader can read decimal fields with a larger precision ### What changes were proposed in this pull request? This is a followup of https://github.com/apache/spark/pull/31357 #31357 added a very strong restriction to the vectorized parquet reader, that the spark data type must exactly match the physical parquet type, when reading decimal fields. This restriction is actually not necessary, as we can safely read parquet decimals with a larger precision. This PR releases this restriction a little bit. ### Why are the changes needed? To not fail queries unnecessarily. ### Does this PR introduce _any_ user-facing change? Yes, now users can read parquet decimals with mismatched `DecimalType` as long as the scale is the same and precision is larger. ### How was this patch tested? updated test. Closes #31443 from cloud-fan/improve. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 00120ea53748d84976e549969f43cf2a50778c1c) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 03 February 2021, 00:27:36 UTC |
| 3696ba8 | yangjie01 | 02 February 2021, 00:26:36 UTC | [SPARK-34310][CORE][SQL][2.4] Replaces map and flatten with flatMap ### What changes were proposed in this pull request? Replaces `collection.map(f1).flatten(f2)` with `collection.flatMap` if possible. it's semantically consistent, but looks simpler. ### Why are the changes needed? Code Simpilefications. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass the Jenkins or GitHub Action Closes #31417 from LuciferYang/SPARK-34310-24. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 02 February 2021, 00:26:36 UTC |
| da3ccab | Liang-Chi Hsieh | 30 January 2021, 04:50:39 UTC | [SPARK-34270][SS] Combine StateStoreMetrics should not override StateStoreCustomMetric This patch proposes to sum up custom metric values instead of taking arbitrary one when combining `StateStoreMetrics`. For stateful join in structured streaming, we need to combine `StateStoreMetrics` from both left and right side. Currently we simply take arbitrary one from custom metrics with same name from left and right. By doing this we miss half of metric number. Yes, this corrects metrics collected for stateful join. Unit test. Closes #31369 from viirya/SPARK-34270. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 50d14c98c3828d8d9cc62ebc61ad4d20398ee6c6) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 30 January 2021, 05:16:54 UTC |
| 6c8bc7c | Linhong Liu | 29 January 2021, 03:28:44 UTC | [SPARK-34260][SQL][2.4] Fix UnresolvedException when creating temp view twice ### What changes were proposed in this pull request? In PR #30140, it will compare new and old plans when replacing view and uncache data if the view has changed. But the compared new plan is not analyzed which will cause `UnresolvedException` when calling `sameResult`. So in this PR, we use the analyzed plan to compare to fix this problem. ### Why are the changes needed? bug fix ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? newly added tests Closes #31388 from linhongliu-db/SPARK-34260-2.4. Authored-by: Linhong Liu <linhong.liu@databricks.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 29 January 2021, 03:28:44 UTC |
| 953cc1c | Dongjoon Hyun | 28 January 2021, 21:06:42 UTC | [SPARK-34273][CORE] Do not reregister BlockManager when SparkContext is stopped This PR aims to prevent `HeartbeatReceiver` asks `Executor` to re-register blocker manager when the SparkContext is already stopped. Currently, `HeartbeatReceiver` blindly asks re-registration for the new heartbeat message. However, when SparkContext is stopped, we don't need to re-register new block manager. Re-registration causes unnecessary executors' logs and and a delay on job termination. No. Pass the CIs with the newly added test case. Closes #31373 from dongjoon-hyun/SPARK-34273. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit bc41c5a0e598e6b697ed61c33e1bea629dabfc57) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 28 January 2021, 21:14:35 UTC |
| 78bf448 | yangjie01 | 28 January 2021, 10:01:45 UTC | [SPARK-34275][CORE][SQL][MLLIB][2.4] Replaces filter and size with count ### What changes were proposed in this pull request? Use `count` to simplify `find + size(or length)` operation, it's semantically consistent, but looks simpler. **Before** ``` seq.filter(p).size ``` **After** ``` seq.count(p) ``` ### Why are the changes needed? Code Simpilefications. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass the Jenkins or GitHub Action Closes #31376 from LuciferYang/SPARK-34275-24. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 28 January 2021, 10:01:45 UTC |
| 86eb199 | Yuming Wang | 28 January 2021, 05:06:36 UTC | [SPARK-34268][SQL][DOCS] Correct the documentation of the concat_ws function ### What changes were proposed in this pull request? This pr correct the documentation of the `concat_ws` function. ### Why are the changes needed? `concat_ws` doesn't need any str or array(str) arguments: ``` scala> sql("""select concat_ws("s")""").show +------------+ |concat_ws(s)| +------------+ | | +------------+ ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? ``` build/sbt "sql/testOnly *.ExpressionInfoSuite" ``` Closes #31370 from wangyum/SPARK-34268. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 01d11da84ef7c3abbfd1072c421505589ac1e9b2) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 28 January 2021, 05:07:27 UTC |
| 6bc088f | Wenchen Fan | 27 January 2021, 17:34:31 UTC | [SPARK-34212][SQL][FOLLOWUP] Refine the behavior of reading parquet non-decimal fields as decimal This is a followup of https://github.com/apache/spark/pull/31319 . When reading parquet int/long as decimal, the behavior should be the same as reading int/long and then cast to the decimal type. This PR changes to the expected behavior. When reading parquet binary as decimal, we don't really know how to interpret the binary (it may from a string), and should fail. This PR changes to the expected behavior. To make the behavior more sane. Yes, but it's a followup. updated test Closes #31357 from cloud-fan/bug. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 2dbb7d5af8f498e49488cd8876bd3d0b083723b7) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 27 January 2021, 17:41:59 UTC |
| 33bdbf8 | Erik Krogen | 27 January 2021, 07:16:33 UTC | [SPARK-34231][AVRO][TEST] Make proper use of resource file within AvroSuite test case Change `AvroSuite."Ignore corrupt Avro file if flag IGNORE_CORRUPT_FILES"` to use `episodesAvro`, which is loaded as a resource using the classloader, instead of trying to read `episodes.avro` directly from a relative file path. This is the proper way to read resource files, and currently this test will fail when called from my IntelliJ IDE, though it will succeed when called from Maven/sbt, presumably due to different working directory handling. No, unit test only. Previous failure from IntelliJ: ``` Source 'src/test/resources/episodes.avro' does not exist java.io.FileNotFoundException: Source 'src/test/resources/episodes.avro' does not exist at org.apache.commons.io.FileUtils.checkFileRequirements(FileUtils.java:1405) at org.apache.commons.io.FileUtils.copyFile(FileUtils.java:1072) at org.apache.commons.io.FileUtils.copyFile(FileUtils.java:1040) at org.apache.spark.sql.avro.AvroSuite.$anonfun$new$34(AvroSuite.scala:397) at org.apache.spark.sql.avro.AvroSuite.$anonfun$new$34$adapted(AvroSuite.scala:388) ``` Now it succeeds. Closes #31332 from xkrogen/xkrogen-SPARK-34231-avrosuite-testfix. Authored-by: Erik Krogen <xkrogen@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit b2c104bd87361e5d85f7c227c60419af16b718f2) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 27 January 2021, 07:18:34 UTC |
| 6519a7e | Dongjoon Hyun | 26 January 2021, 23:13:39 UTC | [SPARK-34212][SQL] Fix incorrect decimal reading from Parquet files This PR aims to the correctness issues during reading decimal values from Parquet files. - For **MR** code path, `ParquetRowConverter` can read Parquet's decimal values with the original precision and scale written in the corresponding footer. - For **Vectorized** code path, `VectorizedColumnReader` throws `SchemaColumnConvertNotSupportedException`. Currently, Spark returns incorrect results when the Parquet file's decimal precision and scale are different from the Spark's schema. This happens when there is multiple files with different decimal schema or HiveMetastore has a new schema. **BEFORE (Simplified example for correctness)** ```scala scala> sql("SELECT 1.0 a").write.parquet("/tmp/decimal") scala> spark.read.schema("a DECIMAL(3,2)").parquet("/tmp/decimal").show +----+ | a| +----+ |0.10| +----+ ``` This works correctly in the other data sources, `ORC/JSON/CSV`, like the following. ```scala scala> sql("SELECT 1.0 a").write.orc("/tmp/decimal_orc") scala> spark.read.schema("a DECIMAL(3,2)").orc("/tmp/decimal_orc").show +----+ | a| +----+ |1.00| +----+ ``` **AFTER** 1. **Vectorized** path: Instead of incorrect result, we will raise an explicit exception. ```scala scala> spark.read.schema("a DECIMAL(3,2)").parquet("/tmp/decimal").show java.lang.UnsupportedOperationException: Schema evolution not supported. ``` 2. **MR** path (complex schema or explicit configuration): Spark returns correct results. ```scala scala> spark.read.schema("a DECIMAL(3,2), b DECIMAL(18, 3), c MAP<INT,INT>").parquet("/tmp/decimal").show +----+-------+--------+ | a| b| c| +----+-------+--------+ |1.00|100.000|{1 -> 2}| +----+-------+--------+ scala> spark.read.schema("a DECIMAL(3,2), b DECIMAL(18, 3), c MAP<INT,INT>").parquet("/tmp/decimal").printSchema root |-- a: decimal(3,2) (nullable = true) |-- b: decimal(18,3) (nullable = true) |-- c: map (nullable = true) | |-- key: integer | |-- value: integer (valueContainsNull = true) ``` Yes. This fixes the correctness issue. Pass with the newly added test case. Closes #31319 from dongjoon-hyun/SPARK-34212. Lead-authored-by: Dongjoon Hyun <dhyun@apple.com> Co-authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit dbf051c50a17d644ecc1823e96eede4a5a6437fd) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 26 January 2021, 23:31:40 UTC |
| a5f844b | yliou | 26 January 2021, 16:38:20 UTC | [SPARK-33726][SQL][2.4] Fix for Duplicate field names during Aggregation ### What changes were proposed in this pull request? The `RowBasedKeyValueBatch` has two different implementations depending on whether the aggregation key and value uses only fixed length data types (`FixedLengthRowBasedKeyValueBatch`) or not (`VariableLengthRowBasedKeyValueBatch`). Before this PR the decision about the used implementation was based on by accessing the schema fields by their name. But if two fields has the same name and one with variable length and the other with fixed length type (and all the other fields are with fixed length types) a bad decision could be made. When `FixedLengthRowBasedKeyValueBatch` is chosen but there is a variable length field then an aggregation function could calculate with invalid values. This case is illustrated by the example used in the unit test: `with T as (select id as a, -id as x from range(3)), U as (select id as b, cast(id as string) as x from range(3)) select T.x, U.x, min(a) as ma, min(b) as mb from T join U on a=b group by U.x, T.x` where the 'x' column in the left side of the join is a Long but on the right side is a String. ### Why are the changes needed? Fixes the issue where duplicate field name aggregation has null values in the dataframe. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added UT, tested manually on spark shell. Closes #31327 from yliou/SPARK-33726_2.4. Authored-by: yliou <yliou@berkeley.edu> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 26 January 2021, 16:38:20 UTC |
| a194eab | Dongjoon Hyun | 26 January 2021, 05:23:54 UTC | [SPARK-34229][SQL] Avro should read decimal values with the file schema ### What changes were proposed in this pull request? This PR aims to fix Avro data source to use the decimal precision and scale of file schema. ### Why are the changes needed? The decimal value should be interpreted with its original precision and scale. Otherwise, it returns incorrect result like the following. The schema mismatch happens when we use `userSpecifiedSchema` or there are multiple files with inconsistent schema or HiveMetastore schema is updated by the user. ```scala scala> sql("SELECT 3.14 a").write.format("avro").save("/tmp/avro") scala> spark.read.schema("a DECIMAL(4, 3)").format("avro").load("/tmp/avro").show +-----+ | a| +-----+ |0.314| +-----+ ``` ### Does this PR introduce _any_ user-facing change? Yes, this will return correct result. ### How was this patch tested? Pass the CI with the newly added test case. Closes #31329 from dongjoon-hyun/SPARK-34229. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 7d09eac1ccb6a14a36fce30ae7cda575c29e1974) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 26 January 2021, 05:30:12 UTC |
| d910643 | Liang-Chi Hsieh | 25 January 2021, 22:30:07 UTC | [SPARK-34187][SS][2.4] Use available offset range obtained during polling when checking offset validation ### What changes were proposed in this pull request? This patch uses the available offset range obtained during polling Kafka records to do offset validation check. ### Why are the changes needed? We support non-consecutive offsets for Kafka since 2.4.0. In `fetchRecord`, we do offset validation by checking if the offset is in available offset range. But currently we obtain latest available offset range to do the check. It looks not correct as the available offset range could be changed during the batch, so the available offset range is different than the one when we polling the records from Kafka. It is possible that an offset is valid when polling, but at the time we do the above check, it is out of latest available offset range. We will wrongly consider it as data loss case and fail the query or drop the record. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? This should pass existing unit tests. This is hard to have unit test as the Kafka producer and the consumer is asynchronous. Further, we also need to make the offset out of new available offset range. Closes #31330 from viirya/SPARK-34187-2.4. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 25 January 2021, 22:30:07 UTC |
| 96d2533 | Max Gekk | 19 January 2021, 09:10:20 UTC | [SPARK-34153][SQL][2.4] Remove unused `getRawTable()` from `HiveExternalCatalog.alterPartitions()` ### What changes were proposed in this pull request? Remove unused call of `getRawTable()` from `HiveExternalCatalog.alterPartitions()`. ### Why are the changes needed? It reduces the number of calls to Hive External catalog. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? By existing test suites. Authored-by: Max Gekk <max.gekkgmail.com> Signed-off-by: HyukjinKwon <gurwls223apache.org> (cherry picked from commit bea10a6274df939e518a931dba4e6e0ae1fa6d01) Signed-off-by: Max Gekk <max.gekkgmail.com> Closes #31242 from MaxGekk/remove-getRawTable-from-alterPartitions-2.4. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 19 January 2021, 09:10:20 UTC |
| e0e1e21 | sychen | 18 January 2021, 00:04:09 UTC | [SPARK-34125][CORE][2.4] Make EventLoggingListener.codecMap thread-safe ### What changes were proposed in this pull request? `EventLoggingListener.codecMap` change `mutable.HashMap` to `ConcurrentHashMap` ### Why are the changes needed? 2.x version of history server `EventLoggingListener.codecMap` is of type mutable.HashMap, which is not thread safe. This will cause the history server to suddenly get stuck and not work. The 3.x version was changed to `EventLogFileReader.codecMap` to `ConcurrentHashMap` type, so there is no such problem.(SPARK-28869) Multiple threads call `openEventLog`, `codecMap` is updated by multiple threads, `mutable.HashMap` may fall into an infinite loop during `resize`, resulting in history server not working. https://github.com/scala/bug/issues/10436 PID 117049 0x1c939   ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? exist ut Closes #31194 from cxzl25/SPARK-34125. Authored-by: sychen <sychen@ctrip.com> Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com> | 18 January 2021, 00:04:09 UTC |
| 7ae6c8d | yangjie01 | 15 January 2021, 11:18:38 UTC | [SPARK-34118][CORE][SQL][2.4] Replaces filter and check for emptiness with exists or forall ### What changes were proposed in this pull request? This pr use `exists` or `forall` to simplify `filter + emptiness check`, it's semantically consistent, but looks simpler. The rule as follow: - `seq.filter(p).size == 0)` -> `!seq.exists(p)` - `seq.filter(p).length > 0` -> `seq.exists(p)` - `seq.filterNot(p).isEmpty` -> `seq.forall(p)` - `seq.filterNot(p).nonEmpty` -> `!seq.forall(p)` ### Why are the changes needed? Code Simpilefications. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass the Jenkins or GitHub Action Closes #31192 from LuciferYang/SPARK-34118-24. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 15 January 2021, 11:18:38 UTC |
| 63e93a5 | HyukjinKwon | 12 January 2021, 04:03:12 UTC | [SPARK-34059][SQL][CORE][2.4] Use for/foreach rather than map to make sure execute it eagerly ### What changes were proposed in this pull request? This is a backport of https://github.com/apache/spark/pull/31110. I ran intelliJ inspection again in this branch. This PR is basically a followup of https://github.com/apache/spark/pull/14332. Calling `map` alone might leave it not executed due to lazy evaluation, e.g.) ``` scala> val foo = Seq(1,2,3) foo: Seq[Int] = List(1, 2, 3) scala> foo.map(println) 1 2 3 res0: Seq[Unit] = List((), (), ()) scala> foo.view.map(println) res1: scala.collection.SeqView[Unit,Seq[_]] = SeqViewM(...) scala> foo.view.foreach(println) 1 2 3 ``` We should better use `foreach` to make sure it's executed where the output is unused or `Unit`. ### Why are the changes needed? To prevent the potential issues by not executing `map`. ### Does this PR introduce _any_ user-facing change? No, the current codes look not causing any problem for now. ### How was this patch tested? I found these item by running IntelliJ inspection, double checked one by one, and fixed them. These should be all instances across the codebase ideally. Closes #31139 from HyukjinKwon/SPARK-34059-2.4. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 12 January 2021, 04:03:12 UTC |
| d442146 | angerszhu | 06 January 2021, 11:54:47 UTC | [SPARK-34012][SQL][2.4] Keep behavior consistent when conf `spark.sqllegacy.parser.havingWithoutGroupByAsWhere` is true with migration guide ### What changes were proposed in this pull request? In https://github.com/apache/spark/pull/22696 we support HAVING without GROUP BY means global aggregate But since we treat having as Filter before, in this way will cause a lot of analyze error, after https://github.com/apache/spark/pull/28294 we use `UnresolvedHaving` to instead `Filter` to solve such problem, but break origin logical about treat `SELECT 1 FROM range(10) HAVING true` as `SELECT 1 FROM range(10) WHERE true` . This PR fix this issue and add UT. NOTE: This backport comes from #31039 ### Why are the changes needed? Keep consistent behavior of migration guide. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? added UT Closes #31050 from AngersZhuuuu/SPARK-34012-2.4. Authored-by: angerszhu <angers.zhu@gmail.com> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org> | 06 January 2021, 11:54:47 UTC |
| 3e6a6b7 | Tanel Kiis | 06 January 2021, 00:05:10 UTC | [SPARK-33935][SQL][2.4] Fix CBO cost function ### What changes were proposed in this pull request? Changed the cost function in CBO to match documentation. ### Why are the changes needed? The parameter `spark.sql.cbo.joinReorder.card.weight` is documented as: ``` The weight of cardinality (number of rows) for plan cost comparison in join reorder: rows * weight + size * (1 - weight). ``` The implementation in `JoinReorderDP.betterThan` does not match this documentaiton: ``` def betterThan(other: JoinPlan, conf: SQLConf): Boolean = { if (other.planCost.card == 0 || other.planCost.size == 0) { false } else { val relativeRows = BigDecimal(this.planCost.card) / BigDecimal(other.planCost.card) val relativeSize = BigDecimal(this.planCost.size) / BigDecimal(other.planCost.size) relativeRows * conf.joinReorderCardWeight + relativeSize * (1 - conf.joinReorderCardWeight) < 1 } } ``` This different implementation has an unfortunate consequence: given two plans A and B, both A betterThan B and B betterThan A might give the same results. This happes when one has many rows with small sizes and other has few rows with large sizes. A example values, that have this fenomen with the default weight value (0.7): A.card = 500, B.card = 300 A.size = 30, B.size = 80 Both A betterThan B and B betterThan A would have score above 1 and would return false. This happens with several of the TPCDS queries. The new implementation does not have this behavior. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? New and existing UTs Closes #31043 from tanelk/SPARK-33935_cbo_cost_function_2.4. Authored-by: Tanel Kiis <tanel.kiis@reach-u.com> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org> | 06 January 2021, 00:05:10 UTC |
| 45e19bb | Max Gekk | 27 December 2020, 08:59:38 UTC | [SPARK-33911][SQL][DOCS][2.4] Update the SQL migration guide about changes in `HiveClientImpl` ### What changes were proposed in this pull request? Update the SQL migration guide about the changes made by: - https://github.com/apache/spark/pull/30778 - https://github.com/apache/spark/pull/30711 ### Why are the changes needed? To inform users about the recent changes in the upcoming releases. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? N/A Closes #30933 from MaxGekk/sql-migr-guide-hiveclientimpl-2.4. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 27 December 2020, 08:59:38 UTC |
| afd219f | Takuya UESHIN | 24 December 2020, 01:40:59 UTC | [SPARK-33277][PYSPARK][SQL][2.4] Use ContextAwareIterator to stop consuming after the task ends ### What changes were proposed in this pull request? This is a backport of #30899. This is not a complete fix, but it would take long time to complete (#30242). As discussed offline, at least using `ContextAwareIterator` should be helpful enough for many cases. As the Python evaluation consumes the parent iterator in a separate thread, it could consume more data from the parent even after the task ends and the parent is closed. Thus, we should use `ContextAwareIterator` to stop consuming after the task ends. ### Why are the changes needed? Python/Pandas UDF right after off-heap vectorized reader could cause executor crash. E.g.,: ```py spark.range(0, 100000, 1, 1).write.parquet(path) spark.conf.set("spark.sql.columnVector.offheap.enabled", True) def f(x): return 0 fUdf = udf(f, LongType()) spark.read.parquet(path).select(fUdf('id')).head() ``` This is because, the Python evaluation consumes the parent iterator in a separate thread and it consumes more data from the parent even after the task ends and the parent is closed. If an off-heap column vector exists in the parent iterator, it could cause segmentation fault which crashes the executor. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Added tests, and manually. Closes #30913 from ueshin/issues/SPARK-33277/2.4/context_aware_iterator. Authored-by: Takuya UESHIN <ueshin@databricks.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 24 December 2020, 01:40:59 UTC |
| 1a153da | Jungtaek Lim (HeartSaVioR) | 23 December 2020, 01:06:08 UTC | [SPARK-27575][CORE][YARN][2.4] Yarn file-related confs should merge new value with existing value ### What changes were proposed in this pull request? This patch is cherry-pick of https://github.com/apache/spark/pull/24465 This patch fixes a bug which YARN file-related configurations are being overwritten when there're some values to assign - e.g. if `--file` is specified as an argument, `spark.yarn.dist.files` is overwritten with the value of argument. After this patch the existing value and new value will be merged before assigning to the value of configuration. ### How was this patch tested? **Original patch test:** Added UT, and manually tested with below command: > ./bin/spark-submit --verbose --files /etc/spark2/conf/spark-defaults.conf.template --master yarn-cluster --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.0.jar 10 where the spark conf file has `spark.yarn.dist.files=file:/etc/spark2/conf/atlas-application.properties.yarn#atlas-application.properties` ``` Spark config: ... (spark.yarn.dist.files,file:/etc/spark2/conf/atlas-application.properties.yarn#atlas-application.properties,file:///etc/spark2/conf/spark-defaults.conf.template) ... ``` **Backport test:** Ran the original UT on `branch-2.4` after backporting: ```build/sbt -Phive -Phive-thriftserver -Pyarn "core/testOnly *SparkSubmitSuite -- -z SPARK-27575"``` Closes #30895 from anuragmantri/SPARK-27575. Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 23 December 2020, 01:06:08 UTC |
| a21625f | Dongjoon Hyun | 22 December 2020, 22:17:25 UTC | [SPARK-33831][UI][FOLLOWUP] Update spark-deps-hadoop-3.1 for jetty 9.4.34 | 22 December 2020, 22:17:25 UTC |
| 377ad9a | Enrico Minack | 22 December 2020, 15:22:42 UTC | [BUILD][MINOR] Do not publish snapshots from forks ### What changes were proposed in this pull request? The GitHub workflow `Publish Snapshot` publishes master and 3.1 branch via Nexus. For this, the workflow uses `secrets.NEXUS_USER` and `secrets.NEXUS_PW` secrets. These are not available in forks where this workflow fails every day: - https://github.com/G-Research/spark/actions/runs/431626797 - https://github.com/G-Research/spark/actions/runs/433153049 - https://github.com/G-Research/spark/actions/runs/434680048 - https://github.com/G-Research/spark/actions/runs/436958780 ### Why are the changes needed? Avoid attempting to publish snapshots from forked repositories. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Code review only. Closes #30884 from EnricoMi/branch-do-not-publish-snapshots-from-forks. Authored-by: Enrico Minack <github@enrico.minack.dev> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 1d450250eb1db7e4f40451f369db830a8f01ec15) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 22 December 2020, 15:23:45 UTC |
| b25f208 | HyukjinKwon | 21 December 2020, 19:11:25 UTC | [SPARK-33869][PYTHON][SQL][TESTS] Have a separate metastore directory for each PySpark test job This PR proposes to have its own metastore directory to avoid potential conflict in catalog operations. To make PySpark tests less flaky. No, dev-only. Manually tested by trying some sleeps in https://github.com/apache/spark/pull/30873. Closes #30875 from HyukjinKwon/SPARK-33869. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 38bbccab7560f2cfd00f9f85ca800434efe950b4) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 21 December 2020, 19:13:44 UTC |
| 59cee43 | angerszhu | 21 December 2020, 11:27:17 UTC | [SPARK-33593][SQL][2.4] Vector reader got incorrect data with binary partition value ### What changes were proposed in this pull request? Currently when enable parquet vectorized reader, use binary type as partition col will return incorrect value as below UT ```scala test("Parquet vector reader incorrect with binary partition value") { Seq(false, true).foreach(tag => { withSQLConf("spark.sql.parquet.enableVectorizedReader" -> tag.toString) { withTable("t1") { sql( """CREATE TABLE t1(name STRING, id BINARY, part BINARY) | USING PARQUET PARTITIONED BY (part)""".stripMargin) sql(s"INSERT INTO t1 PARTITION(part = 'Spark SQL') VALUES('a', X'537061726B2053514C')") if (tag) { checkAnswer(sql("SELECT name, cast(id as string), cast(part as string) FROM t1"), Row("a", "Spark SQL", "")) } else { checkAnswer(sql("SELECT name, cast(id as string), cast(part as string) FROM t1"), Row("a", "Spark SQL", "Spark SQL")) } } } }) } ``` ### Why are the changes needed? Fix data incorrect issue ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added UT Closes #30840 from AngersZhuuuu/spark-33593-2.4. Authored-by: angerszhu <angers.zhu@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 21 December 2020, 11:27:17 UTC |
| 9b8c193 | Xianjin YE | 20 December 2020, 14:51:17 UTC | [SPARK-33756][SQL] Make BytesToBytesMap's MapIterator idempotent ### What changes were proposed in this pull request? Make MapIterator of BytesToBytesMap `hasNext` method idempotent ### Why are the changes needed? The `hasNext` maybe called multiple times, if not guarded, second call of hasNext method after reaching the end of iterator will throw NoSuchElement exception. ### Does this PR introduce _any_ user-facing change? NO. ### How was this patch tested? Update a unit test to cover this case. Closes #30728 from advancedxy/SPARK-33756. Authored-by: Xianjin YE <advancedxy@gmail.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 13391683e7a863671d3d719dc81e20ec2a870725) Signed-off-by: Sean Owen <srowen@gmail.com> | 20 December 2020, 14:51:55 UTC |
| 7e98ade | Sean Owen | 18 December 2020, 03:09:57 UTC | [SPARK-33831][UI] Update to jetty 9.4.34 Update Jetty to 9.4.34 Picks up fixes and improvements, including a possible CVE fix. https://github.com/eclipse/jetty.project/releases/tag/jetty-9.4.33.v20201020 https://github.com/eclipse/jetty.project/releases/tag/jetty-9.4.34.v20201102 No. Existing tests. Closes #30828 from srowen/SPARK-33831. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 131a23d88a56280d47584aed93bc8fb617550717) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 18 December 2020, 03:13:53 UTC |
| 399b2ca | ulysses-you | 17 December 2020, 08:43:43 UTC | [SPARK-33733][SQL][2.4] PullOutNondeterministic should check and collect deterministic field backport [#30703](https://github.com/apache/spark/pull/30703) for branch-2.4. ### What changes were proposed in this pull request? The deterministic field is wider than `NonDerterministic`, we should keep same range between pull out and check analysis. ### Why are the changes needed? For example ``` select * from values(1), (4) as t(c1) order by java_method('java.lang.Math', 'abs', c1) ``` We will get exception since `java_method` deterministic field is false but not a `NonDeterministic` ``` Exception in thread "main" org.apache.spark.sql.AnalysisException: nondeterministic expressions are only allowed in Project, Filter, Aggregate or Window, found: java_method('java.lang.Math', 'abs', t.`c1`) ASC NULLS FIRST in operator Sort [java_method(java.lang.Math, abs, c1#1) ASC NULLS FIRST], true ;; ``` ### Does this PR introduce _any_ user-facing change? Yes. ### How was this patch tested? Add test. Closes #30772 from ulysses-you/SPARK-33733-branch-2.4. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 17 December 2020, 08:43:43 UTC |
| 029d577 | Max Gekk | 16 December 2020, 14:30:47 UTC | [SPARK-33788][SQL][3.1][3.0][2.4] Throw NoSuchPartitionsException from HiveExternalCatalog.dropPartitions() ### What changes were proposed in this pull request? Throw `NoSuchPartitionsException` from `ALTER TABLE .. DROP TABLE` for not existing partitions of a table in V1 Hive external catalog. ### Why are the changes needed? The behaviour of Hive external catalog deviates from V1/V2 in-memory catalogs that throw `NoSuchPartitionsException`. To improve user experience with Spark SQL, it would be better to throw the same exception. ### Does this PR introduce _any_ user-facing change? Yes, the command throws `NoSuchPartitionsException` instead of the general exception `AnalysisException`. ### How was this patch tested? By running new UT via: ``` $ build/sbt -Phive -Phive-thriftserver "test:testOnly *HiveDDLSuite" ``` Authored-by: Max Gekk <max.gekkgmail.com> Signed-off-by: HyukjinKwon <gurwls223apache.org> (cherry picked from commit 3dfdcf4f92ef5e739f15c22c93d673bb2233e617) Signed-off-by: Max Gekk <max.gekkgmail.com> Closes #30802 from MaxGekk/hive-drop-partition-exception-3.1. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 16 December 2020, 14:32:08 UTC |
| 2964626 | Max Gekk | 14 December 2020, 10:50:07 UTC | [SPARK-33770][SQL][TESTS][2.4] Fix the `ALTER TABLE .. DROP PARTITION` tests that delete files out of partition path ### What changes were proposed in this pull request? Modify the tests that add partitions with `LOCATION`, and where the number of nested folders in `LOCATION` doesn't match to the number of partitioned columns. In that case, `ALTER TABLE .. DROP PARTITION` tries to access (delete) folder out of the "base" path in `LOCATION`. The problem belongs to Hive's MetaStore method `drop_partition_common`: https://github.com/apache/hive/blob/8696c82d07d303b6dbb69b4d443ab6f2b241b251/standalone-metastore/metastore-server/src/main/java/org/apache/hadoop/hive/metastore/HiveMetaStore.java#L4876 which tries to delete empty partition sub-folders recursively starting from the most deeper partition sub-folder up to the base folder. In the case when the number of sub-folder is not equal to the number of partitioned columns `part_vals.size()`, the method will try to list and delete folders out of the base path. ### Why are the changes needed? To fix test failures like https://github.com/apache/spark/pull/30643#issuecomment-743774733: ``` org.apache.spark.sql.hive.execution.command.AlterTableAddPartitionSuite.ALTER TABLE .. ADD PARTITION Hive V1: SPARK-33521: universal type conversions of partition values sbt.ForkMain$ForkError: org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: File file:/home/jenkins/workspace/SparkPullRequestBuilder/target/tmp/spark-832cb19c-65fd-41f3-ae0b-937d76c07897 does not exist; at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:112) at org.apache.spark.sql.hive.HiveExternalCatalog.dropPartitions(HiveExternalCatalog.scala:1014) ... Caused by: sbt.ForkMain$ForkError: org.apache.hadoop.hive.metastore.api.MetaException: File file:/home/jenkins/workspace/SparkPullRequestBuilder/target/tmp/spark-832cb19c-65fd-41f3-ae0b-937d76c07897 does not exist at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.drop_partition_with_environment_context(HiveMetaStore.java:3381) at sun.reflect.GeneratedMethodAccessor304.invoke(Unknown Source) ``` The issue can be reproduced by the following steps: 1. Create a base folder, for example: `/Users/maximgekk/tmp/part-location` 2. Create a sub-folder in the base folder and drop permissions for it: ``` $ mkdir /Users/maximgekk/tmp/part-location/aaa $ chmod a-rwx chmod a-rwx /Users/maximgekk/tmp/part-location/aaa $ ls -al /Users/maximgekk/tmp/part-location total 0 drwxr-xr-x 3 maximgekk staff 96 Dec 13 18:42 . drwxr-xr-x 33 maximgekk staff 1056 Dec 13 18:32 .. d--------- 2 maximgekk staff 64 Dec 13 18:42 aaa ``` 3. Create a table with a partition folder in the base folder: ```sql spark-sql> create table tbl (id int) partitioned by (part0 int, part1 int); spark-sql> alter table tbl add partition (part0=1,part1=2) location '/Users/maximgekk/tmp/part-location/tbl'; ``` 4. Try to drop this partition: ``` spark-sql> alter table tbl drop partition (part0=1,part1=2); 20/12/13 18:46:07 ERROR HiveClientImpl: ====================== Attempt to drop the partition specs in table 'tbl' database 'default': Map(part0 -> 1, part1 -> 2) In this attempt, the following partitions have been dropped successfully: The remaining partitions have not been dropped: [1, 2] ====================== Error in query: org.apache.hadoop.hive.ql.metadata.HiveException: Error accessing file:/Users/maximgekk/tmp/part-location/aaa; org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: Error accessing file:/Users/maximgekk/tmp/part-location/aaa; ``` The command fails because it tries to access to the sub-folder `aaa` that is out of the partition path `/Users/maximgekk/tmp/part-location/tbl`. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? By running the affected tests from local IDEA which does not have access to folders out of partition paths. Lead-authored-by: Max Gekk <max.gekkgmail.com> Co-authored-by: Maxim Gekk <max.gekkgmail.com> Signed-off-by: HyukjinKwon <gurwls223apache.org> (cherry picked from commit 9160d59ae379910ca3bbd04ee25d336afff28abd) Signed-off-by: Max Gekk <max.gekkgmail.com> Closes #30757 from MaxGekk/fix-drop-partition-location-2.4. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 14 December 2020, 10:50:07 UTC |
| 88c3649 | Kousuke Saruta | 14 December 2020, 01:27:39 UTC | [SPARK-33757][INFRA][R][FOLLOWUP] Provide more simple solution ### What changes were proposed in this pull request? This PR proposes a better solution for the R build failure on GitHub Actions. The issue is solved in #30737 but I noticed the following two things. * We can use the latest `usethis` if we install additional libraries on the GitHub Actions environment. * For tests on AppVeyor, `usethis` is not necessary, so I partially revert the previous change. ### Why are the changes needed? For more simple solution. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Confirmed on GitHub Actions and AppVeyor on my account. Closes #30753 from sarutak/followup-SPARK-33757. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit b135db3b1a5c0b2170e98b97f6160bcf55903799) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 14 December 2020, 01:28:27 UTC |
| abded89 | linzebing | 13 December 2020, 13:00:05 UTC | [MINOR][UI] Correct JobPage's skipped/pending tableHeaderId ### What changes were proposed in this pull request? Current Spark Web UI job page's header link of pending/skipped stages is inconsistent with their statuses. See the picture below:  ### Why are the changes needed? The code determining the `pendingOrSkippedTableId` has the wrong logic. As explained in the code: > If the job is completed, then any pending stages are displayed as "skipped" [code pointer](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/ui/jobs/JobPage.scala#L266) This PR fixes the logic for `pendingOrSkippedTableId` which aligns with the stage statuses. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Verified that header link is consistent with stage status with the fix. Closes #30749 from linzebing/ui_bug. Authored-by: linzebing <linzebing1995@gmail.com> Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com> (cherry picked from commit 0277fddaef17b615354c735a2c89cdced5f1d8f6) Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com> | 13 December 2020, 13:08:42 UTC |
| 3e64795 | Max Gekk | 11 December 2020, 17:56:46 UTC | [SPARK-33742][SQL][2.4] Throw PartitionsAlreadyExistException from HiveExternalCatalog.createPartitions() ### What changes were proposed in this pull request? Throw `PartitionsAlreadyExistException` from `createPartitions()` in Hive external catalog when a partition exists. Currently, `HiveExternalCatalog.createPartitions()` throws `AlreadyExistsException` wrapped by `AnalysisException`. In the PR, I propose to catch `AlreadyExistsException` in `HiveClientImpl` and replace it by `PartitionsAlreadyExistException`. ### Why are the changes needed? The behaviour of Hive external catalog deviates from V1/V2 in-memory catalogs that throw `PartitionsAlreadyExistException`. To improve user experience with Spark SQL, it would be better to throw the same exception. ### Does this PR introduce _any_ user-facing change? Yes ### How was this patch tested? By running existing test suites: ``` $ build/sbt -Phive -Phive-thriftserver "hive/test:testOnly org.apache.spark.sql.hive.client.VersionsSuite" $ build/sbt -Phive -Phive-thriftserver "hive/test:testOnly org.apache.spark.sql.hive.execution.HiveDDLSuite" ``` Authored-by: Max Gekk <max.gekkgmail.com> Signed-off-by: Dongjoon Hyun <dongjoonapache.org> (cherry picked from commit fab2995972761503563fa2aa547c67047c51bd33) Signed-off-by: Max Gekk <max.gekkgmail.com> Closes #30732 from MaxGekk/hive-partition-exception-2.4. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 11 December 2020, 17:56:46 UTC |
| d34bc2a | Kousuke Saruta | 11 December 2020, 15:54:40 UTC | [SPARK-33757][INFRA][R] Fix the R dependencies build error on GitHub Actions and AppVeyor ### What changes were proposed in this pull request? This PR fixes the R dependencies build error on GitHub Actions and AppVeyor. The reason seems that `usethis` package is updated 2020/12/10. https://cran.r-project.org/web/packages/usethis/index.html ### Why are the changes needed? To keep the build clean. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Should be done by GitHub Actions. Closes #30737 from sarutak/fix-r-dependencies-build-error. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit fb2e3af4b5d92398d57e61b766466cc7efd9d7cb) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 11 December 2020, 15:55:26 UTC |
| 1261e13 | HyukjinKwon | 11 December 2020, 05:15:56 UTC | [SPARK-33749][BUILD][PYTHON] Exclude target directory in pycodestyle and flake8 Once you build and ran K8S tests, Python lint fails as below: ```bash $ ./dev/lint-python ``` Before this PR: ``` starting python compilation test... python compilation succeeded. downloading pycodestyle from https://raw.githubusercontent.com/PyCQA/pycodestyle/2.6.0/pycodestyle.py... starting pycodestyle test... pycodestyle checks failed: ./resource-managers/kubernetes/integration-tests/target/spark-dist-unpacked/python/pyspark/cloudpickle/cloudpickle.py:15:101: E501 line too long (105 > 100 characters) ./resource-managers/kubernetes/integration-tests/target/spark-dist-unpacked/python/docs/source/conf.py:60:101: E501 line too long (124 > 100 characters) ... ``` After this PR: ``` starting python compilation test... python compilation succeeded. downloading pycodestyle from https://raw.githubusercontent.com/PyCQA/pycodestyle/2.6.0/pycodestyle.py... starting pycodestyle test... pycodestyle checks passed. starting flake8 test... flake8 checks passed. starting mypy test... mypy checks passed. starting sphinx-build tests... sphinx-build checks passed. ``` This PR excludes target directory to avoid such cases in the future. To make it easier to run linters No, dev-only. Manually tested va running `./dev/lint-python`. Closes #30718 from HyukjinKwon/SPARK-33749. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit cd7a30641f25f99452b7eb46ee2b3c5d59b2c542) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 11 December 2020, 05:19:43 UTC |
| 7f2320e | Kousuke Saruta | 10 December 2020, 15:07:12 UTC | [SPARK-33732][K8S][TESTS][2.4] Kubernetes integration tests doesn't work with Minikube 1.9+ #30702 ### What changes were proposed in this pull request? This is a backport of #30700 . This PR changes `Minikube.scala` for Kubernetes integration tests to work with Minikube 1.9+. `Minikube.scala` assumes that `apiserver.key` and `apiserver.crt` are in `~/.minikube/`. But as of Minikube 1.9, they are in `~/.minikube/profiles/<profile>`. ### Why are the changes needed? Currently, Kubernetes integration tests doesn't work with Minikube 1.9+. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? I confirmed the following test passes. ``` $ build/sbt -Pkubernetes -Pkubernetes-integration-tests package 'kubernetes-integration-tests/testOnly -- -z "SparkPi with no"' ``` Closes #30704 from sarutak/minikube-1.9-branch-2.4. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com> | 10 December 2020, 15:07:12 UTC |
| e961cb7 | Liang-Chi Hsieh | 10 December 2020, 02:16:30 UTC | [SPARK-33725][BUILD][2.4] Upgrade snappy-java to 1.1.8.2 ### What changes were proposed in this pull request? This upgrades snappy-java to 1.1.8.2. ### Why are the changes needed? Minor version upgrade that includes: - [Fixed](https://github.com/xerial/snappy-java/pull/265) an initialization issue when using a recent Mac OS X version - Support Apple Silicon (M1, Mac-aarch64) - Fixed the pure-java Snappy fallback logic when no native library for your platform is found. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test. Closes #30697 from viirya/upgrade-snappy-2.4. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 10 December 2020, 02:16:30 UTC |
| 78fade3 | Max Gekk | 07 December 2020, 12:23:11 UTC | [SPARK-33670][SQL][2.4] Verify the partition provider is Hive in v1 SHOW TABLE EXTENDED ### What changes were proposed in this pull request? Invoke the check `DDLUtils.verifyPartitionProviderIsHive()` from V1 implementation of `SHOW TABLE EXTENDED` when partition specs are specified. This PR is some kind of follow up https://github.com/apache/spark/pull/16373 and https://github.com/apache/spark/pull/15515. ### Why are the changes needed? To output an user friendly error with recommendation like **" ... partition metadata is not stored in the Hive metastore. To import this information into the metastore, run `msck repair table tableName` "** instead of silently output an empty result. ### Does this PR introduce _any_ user-facing change? Yes. ### How was this patch tested? By running the affected test suites, in particular: ``` $ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *HiveCatalogedDDLSuite" $ build/sbt -Phive-2.3 -Phive-thriftserver "hive/test:testOnly *PartitionProviderCompatibilitySuite" ``` Authored-by: Max Gekk <max.gekkgmail.com> Signed-off-by: HyukjinKwon <gurwls223apache.org> (cherry picked from commit 29096a8869c95221dc75ce7fd3d098680bef4f55) Signed-off-by: Max Gekk <max.gekkgmail.com> Closes #30641 from MaxGekk/show-table-extended-verifyPartitionProviderIsHive-2.4. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 07 December 2020, 12:23:11 UTC |
| 9ca324a | Dongjoon Hyun | 07 December 2020, 02:16:45 UTC | [SPARK-33675][INFRA][2.4][FOLLOWUP] Set GIT_REF to branch-2.4 | 07 December 2020, 02:35:42 UTC |
| 61a6b47 | Dongjoon Hyun | 07 December 2020, 01:13:22 UTC | [SPARK-33681][K8S][TESTS][3.0] Increase K8s IT timeout to 3 minutes ### What changes were proposed in this pull request? This PR aims to increase the timeout of K8s integration test of `branch-3.0/2.4` from 2 minutes to 3 minutes which is consistent with `master/branch-3.1`. ### Why are the changes needed? This will reduce the chance of this kind of failures. - https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36905/console ``` ... 20/12/07 00:11:23 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 20/12/07 00:11:38 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources " did not contain "PySpark Worker Memory Check is: True" The application did not complete.. (KubernetesSuite.scala:249) ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass the K8s IT Jenkins job. Closes #30632 from dongjoon-hyun/SPARK-33681. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 313a460a0ef5f528dce4da51ed60664a721238ca) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 07 December 2020, 01:13:42 UTC |
| 955033a | Dongjoon Hyun | 07 December 2020, 01:08:28 UTC | [SPARK-33675][INFRA][2.4] Add GitHub Action job to publish snapshot ### What changes were proposed in this pull request? This PR aims to add `GitHub Action` job to publish snapshot from `branch-2.4`. ### Why are the changes needed? This will remove our maintenance burden for `branch-2.4` LTS and will stop automatically when we don't have any commit on `branch-2.4`. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? N/A Closes #30629 from dongjoon-hyun/SPARK-33675-2.4. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 07 December 2020, 01:08:28 UTC |
| 3ab2936 | Max Gekk | 06 December 2020, 22:23:54 UTC | [SPARK-33667][SQL][2.4] Respect the `spark.sql.caseSensitive` config while resolving partition spec in v1 `SHOW PARTITIONS` ### What changes were proposed in this pull request? Preprocess the partition spec passed to the V1 SHOW PARTITIONS implementation `ShowPartitionsCommand`, and normalize the passed spec according to the partition columns w.r.t the case sensitivity flag **spark.sql.caseSensitive**. ### Why are the changes needed? V1 SHOW PARTITIONS is case sensitive in fact, and doesn't respect the SQL config **spark.sql.caseSensitive** which is false by default, for instance: ```sql spark-sql> CREATE TABLE tbl1 (price int, qty int, year int, month int) > USING parquet > PARTITIONED BY (year, month); spark-sql> INSERT INTO tbl1 PARTITION(year = 2015, month = 1) SELECT 1, 1; spark-sql> SHOW PARTITIONS tbl1 PARTITION(YEAR = 2015, Month = 1); Error in query: Non-partitioning column(s) [YEAR, Month] are specified for SHOW PARTITIONS; ``` The `SHOW PARTITIONS` command must show the partition `year = 2015, month = 1` specified by `YEAR = 2015, Month = 1`. ### Does this PR introduce _any_ user-facing change? Yes. After the changes, the command above works as expected: ```sql spark-sql> SHOW PARTITIONS tbl1 PARTITION(YEAR = 2015, Month = 1); year=2015/month=1 ``` ### How was this patch tested? By running the affected test suites: ``` $ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly org.apache.spark.sql.hive.execution.HiveCatalogedDDLSuite" ``` Closes #30627 from MaxGekk/show-partitions-case-sensitivity-test-2.4. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 06 December 2020, 22:23:54 UTC |
| 7a8af18 | yangjie01 | 02 December 2020, 20:58:41 UTC | [SPARK-33631][DOCS][TEST] Clean up spark.core.connection.ack.wait.timeout from configuration.md SPARK-9767 remove `ConnectionManager` and related files, the configuration `spark.core.connection.ack.wait.timeout` previously used by `ConnectionManager` is no longer used by other Spark code, but it still exists in the `configuration.md`. So this pr cleans up the useless configuration item spark.core.connection.ack.wait.timeout` from `configuration.md`. Clean up useless configuration from `configuration.md`. No Pass the Jenkins or GitHub Action Closes #30569 from LuciferYang/SPARK-33631. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 92bfbcb2e372e8fecfe65bc582c779d9df4036bb) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 02 December 2020, 21:01:39 UTC |
| 7b68757 | Max Gekk | 30 November 2020, 16:39:31 UTC | [SPARK-33588][SQL][2.4] Respect the `spark.sql.caseSensitive` config while resolving partition spec in v1 `SHOW TABLE EXTENDED` ### What changes were proposed in this pull request? Perform partition spec normalization in `ShowTablesCommand` according to the table schema before getting partitions from the catalog. The normalization via `PartitioningUtils.normalizePartitionSpec()` adjusts the column names in partition specification, w.r.t. the real partition column names and case sensitivity. ### Why are the changes needed? Even when `spark.sql.caseSensitive` is `false` which is the default value, v1 `SHOW TABLE EXTENDED` is case sensitive: ```sql spark-sql> CREATE TABLE tbl1 (price int, qty int, year int, month int) > USING parquet > partitioned by (year, month); spark-sql> INSERT INTO tbl1 PARTITION(year = 2015, month = 1) SELECT 1, 1; spark-sql> SHOW TABLE EXTENDED LIKE 'tbl1' PARTITION(YEAR = 2015, Month = 1); Error in query: Partition spec is invalid. The spec (YEAR, Month) must match the partition spec (year, month) defined in table '`default`.`tbl1`'; ``` ### Does this PR introduce _any_ user-facing change? Yes. After the changes, the `SHOW TABLE EXTENDED` command respects the SQL config. And for example above, it returns correct result: ```sql spark-sql> SHOW TABLE EXTENDED LIKE 'tbl1' PARTITION(YEAR = 2015, Month = 1); default tbl1 false Partition Values: [year=2015, month=1] Location: file:/Users/maximgekk/spark-warehouse/tbl1/year=2015/month=1 Serde Library: org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe InputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat OutputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat Storage Properties: [serialization.format=1, path=file:/Users/maximgekk/spark-warehouse/tbl1] Partition Parameters: {transient_lastDdlTime=1606595118, totalSize=623, numFiles=1} Created Time: Sat Nov 28 23:25:18 MSK 2020 Last Access: UNKNOWN Partition Statistics: 623 bytes ``` ### How was this patch tested? By running the modified test suite via: ``` $ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *DDLSuite" ``` Closes #30551 from MaxGekk/show-table-case-sensitive-spec-2.4. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 30 November 2020, 16:39:31 UTC |
| 1a0283b | Max Gekk | 29 November 2020, 20:18:07 UTC | [SPARK-33585][SQL][DOCS] Fix the comment for `SQLContext.tables()` and mention the `database` column ### What changes were proposed in this pull request? Change the comments for `SQLContext.tables()` to "The returned DataFrame has three columns, database, tableName and isTemporary". ### Why are the changes needed? Currently, the comment mentions only 2 columns but `tables()` returns 3 columns actually: ```scala scala> spark.range(10).createOrReplaceTempView("view1") scala> val tables = spark.sqlContext.tables() tables: org.apache.spark.sql.DataFrame = [database: string, tableName: string ... 1 more field] scala> tables.printSchema root |-- database: string (nullable = false) |-- tableName: string (nullable = false) |-- isTemporary: boolean (nullable = false) scala> tables.show +--------+---------+-----------+ |database|tableName|isTemporary| +--------+---------+-----------+ | default| t1| false| | default| t2| false| | default| ymd| false| | | view1| true| +--------+---------+-----------+ ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? By running `./dev/scalastyle` Closes #30526 from MaxGekk/sqlcontext-tables-doc. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit a088a801ed8c17171545c196a3f26ce415de0cd1) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 29 November 2020, 20:18:42 UTC |
| 3eb6e38 | Marco Gaido | 25 November 2020, 23:00:39 UTC | [SPARK-26645][PYTHON][2.4] Support decimals with negative scale when parsing datatype ## What changes were proposed in this pull request? This is a backport of #23575 When parsing datatypes from the json internal representation, PySpark doesn't support decimals with negative scales. Since they are allowed and can actually happen, PySpark should be able to successfully parse them. ## How was this patch tested? added test Closes #30503 from dongjoon-hyun/SPARK-26645. Authored-by: Marco Gaido <marcogaido91@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 25 November 2020, 23:00:39 UTC |