https://github.com/apache/spark
- HEAD
- refs/heads/branch-0.5
- refs/heads/branch-0.6
- refs/heads/branch-0.7
- refs/heads/branch-0.8
- refs/heads/branch-0.9
- refs/heads/branch-1.0
- refs/heads/branch-1.0-jdbc
- refs/heads/branch-1.1
- refs/heads/branch-1.2
- refs/heads/branch-1.3
- refs/heads/branch-1.4
- refs/heads/branch-1.5
- refs/heads/branch-1.6
- refs/heads/branch-2.0
- refs/heads/branch-2.1
- refs/heads/branch-2.2
- refs/heads/branch-2.3
- refs/heads/branch-2.4
- refs/heads/branch-3.0
- refs/heads/branch-3.1
- refs/heads/branch-3.2
- refs/heads/branch-3.3
- refs/heads/branch-3.4
- refs/heads/branch-3.5
- refs/heads/master
- refs/remotes/origin/branch-0.8
- refs/remotes/origin/td-rdd-save
- refs/tags/0.3-scala-2.8
- refs/tags/0.3-scala-2.9
- refs/tags/2.0.0-preview
- refs/tags/alpha-0.1
- refs/tags/alpha-0.2
- refs/tags/v0.5.0
- refs/tags/v0.5.1
- refs/tags/v0.5.2
- refs/tags/v0.6.0
- refs/tags/v0.6.0-yarn
- refs/tags/v0.6.1
- refs/tags/v0.6.2
- refs/tags/v0.7.0
- refs/tags/v0.7.0-bizo-1
- refs/tags/v0.7.1
- refs/tags/v0.7.2
- refs/tags/v0.9.1
- refs/tags/v0.9.2
- refs/tags/v1.0.0
- refs/tags/v1.0.1
- refs/tags/v1.0.2
- refs/tags/v1.1.0
- refs/tags/v1.1.1
- refs/tags/v1.2.0
- refs/tags/v1.2.1
- refs/tags/v1.2.2
- refs/tags/v1.3.0
- refs/tags/v1.3.1
- refs/tags/v1.4.0
- refs/tags/v1.4.1
- refs/tags/v1.5.0-rc1
- refs/tags/v1.5.0-rc2
- refs/tags/v1.5.0-rc3
- refs/tags/v1.5.1
- refs/tags/v1.6.0
- refs/tags/v1.6.1
- refs/tags/v1.6.2
- refs/tags/v1.6.3
- refs/tags/v2.0.0
- refs/tags/v2.0.1
- refs/tags/v2.0.2
- refs/tags/v2.1.0
- refs/tags/v2.1.1
- refs/tags/v2.1.2
- refs/tags/v2.1.2-rc1
- refs/tags/v2.1.2-rc2
- refs/tags/v2.1.2-rc3
- refs/tags/v2.1.2-rc4
- refs/tags/v2.1.3
- refs/tags/v2.1.3-rc1
- refs/tags/v2.1.3-rc2
- refs/tags/v2.2.0
- refs/tags/v2.2.1
- refs/tags/v2.2.1-rc1
- refs/tags/v2.2.1-rc2
- refs/tags/v2.2.2
- refs/tags/v2.2.2-rc1
- refs/tags/v2.2.2-rc2
- refs/tags/v2.2.3
- refs/tags/v2.2.3-rc1
- refs/tags/v2.3.0
- refs/tags/v2.3.0-rc1
- refs/tags/v2.3.0-rc2
- refs/tags/v2.3.0-rc3
- refs/tags/v2.3.0-rc4
- refs/tags/v2.3.1
- refs/tags/v2.3.1-rc1
- refs/tags/v2.3.1-rc2
- refs/tags/v2.3.1-rc3
- refs/tags/v2.3.1-rc4
- refs/tags/v2.3.2
- refs/tags/v2.3.2-rc1
- refs/tags/v2.3.2-rc2
- refs/tags/v2.3.2-rc3
- refs/tags/v2.3.2-rc4
- refs/tags/v2.3.2-rc5
- refs/tags/v2.3.2-rc6
- refs/tags/v2.3.3
- refs/tags/v2.3.3-rc1
- refs/tags/v2.3.3-rc2
- refs/tags/v2.3.4
- refs/tags/v2.3.4-rc1
- refs/tags/v2.4.0
- refs/tags/v2.4.0-rc1
- refs/tags/v2.4.0-rc2
- refs/tags/v2.4.0-rc3
- refs/tags/v2.4.0-rc4
- refs/tags/v2.4.0-rc5
- refs/tags/v2.4.1
- refs/tags/v2.4.1-rc1
- refs/tags/v2.4.1-rc2
- refs/tags/v2.4.1-rc3
- refs/tags/v2.4.1-rc4
- refs/tags/v2.4.1-rc5
- refs/tags/v2.4.1-rc6
- refs/tags/v2.4.1-rc7
- refs/tags/v2.4.1-rc8
- refs/tags/v2.4.1-rc9
- refs/tags/v2.4.2
- refs/tags/v2.4.2-rc1
- refs/tags/v2.4.3
- refs/tags/v2.4.3-rc1
- refs/tags/v2.4.4
- refs/tags/v2.4.4-rc1
- refs/tags/v2.4.4-rc2
- refs/tags/v2.4.4-rc3
- refs/tags/v2.4.5
- refs/tags/v2.4.5-rc1
- refs/tags/v2.4.5-rc2
- refs/tags/v2.4.6
- refs/tags/v2.4.6-rc1
- refs/tags/v2.4.6-rc2
- refs/tags/v2.4.6-rc3
- refs/tags/v2.4.6-rc4
- refs/tags/v2.4.6-rc5
- refs/tags/v2.4.6-rc6
- refs/tags/v2.4.6-rc7
- refs/tags/v2.4.6-rc8
- refs/tags/v2.4.7
- refs/tags/v2.4.7-rc1
- refs/tags/v2.4.7-rc2
- refs/tags/v2.4.7-rc3
- refs/tags/v2.4.8
- refs/tags/v2.4.8-rc1
- refs/tags/v2.4.8-rc2
- refs/tags/v2.4.8-rc3
- refs/tags/v2.4.8-rc4
- refs/tags/v3.0.0
- refs/tags/v3.0.0-preview2
- refs/tags/v3.0.0-preview2-rc1
- refs/tags/v3.0.0-preview2-rc2
- refs/tags/v3.0.0-rc1
- refs/tags/v3.0.0-rc2
- refs/tags/v3.0.0-rc3
- refs/tags/v3.0.1
- refs/tags/v3.0.1-rc1
- refs/tags/v3.0.1-rc2
- refs/tags/v3.0.1-rc3
- refs/tags/v3.0.2
- refs/tags/v3.0.2-rc1
- refs/tags/v3.0.3
- refs/tags/v3.0.3-rc1
- refs/tags/v3.1.0-rc1
- refs/tags/v3.1.1
- refs/tags/v3.1.1-rc1
- refs/tags/v3.1.1-rc2
- refs/tags/v3.1.1-rc3
- refs/tags/v3.1.2
- refs/tags/v3.1.2-rc1
- refs/tags/v3.1.3
- refs/tags/v3.1.3-rc1
- refs/tags/v3.1.3-rc2
- refs/tags/v3.1.3-rc3
- refs/tags/v3.1.3-rc4
- refs/tags/v3.2.0
- refs/tags/v3.2.0-rc1
- refs/tags/v3.2.0-rc2
- refs/tags/v3.2.0-rc3
- refs/tags/v3.2.0-rc4
- refs/tags/v3.2.0-rc5
- refs/tags/v3.2.0-rc6
- refs/tags/v3.2.0-rc7
- refs/tags/v3.2.1
- refs/tags/v3.2.1-rc1
- refs/tags/v3.2.1-rc2
- refs/tags/v3.2.2
- refs/tags/v3.2.2-rc1
- refs/tags/v3.2.3
- refs/tags/v3.2.3-rc1
- refs/tags/v3.2.4
- refs/tags/v3.2.4-rc1
- refs/tags/v3.3.0
- refs/tags/v3.3.0-rc1
- refs/tags/v3.3.0-rc2
- refs/tags/v3.3.0-rc3
- refs/tags/v3.3.0-rc4
- refs/tags/v3.3.0-rc5
- refs/tags/v3.3.0-rc6
- refs/tags/v3.3.1
- refs/tags/v3.3.1-rc1
- refs/tags/v3.3.1-rc2
- refs/tags/v3.3.1-rc3
- refs/tags/v3.3.1-rc4
- refs/tags/v3.3.2
- refs/tags/v3.3.2-rc1
- refs/tags/v3.3.3
- refs/tags/v3.3.3-rc1
- refs/tags/v3.3.4
- refs/tags/v3.3.4-rc1
- refs/tags/v3.4.0
- refs/tags/v3.4.0-rc1
- refs/tags/v3.4.0-rc2
- refs/tags/v3.4.0-rc3
- refs/tags/v3.4.0-rc4
- refs/tags/v3.4.0-rc5
- refs/tags/v3.4.0-rc6
- refs/tags/v3.4.0-rc7
- refs/tags/v3.4.1
- refs/tags/v3.4.1-rc1
- refs/tags/v3.4.2
- refs/tags/v3.4.2-rc1
- refs/tags/v3.5.0
- refs/tags/v3.5.0-rc1
- refs/tags/v3.5.0-rc2
- refs/tags/v3.5.0-rc3
- refs/tags/v3.5.0-rc4
- refs/tags/v3.5.0-rc5
- refs/tags/v3.5.1
- refs/tags/v3.5.1-rc1
- refs/tags/v3.5.1-rc2
Take a new snapshot of a software origin
If the archived software origin currently browsed is not synchronized with its upstream version (for instance when new commits have been issued), you can explicitly request Software Heritage to take a new snapshot of it.
Use the form below to proceed. Once a request has been submitted and accepted, it will be processed as soon as possible. You can then check its processing state by visiting this dedicated page.
Processing "take a new snapshot" request ...
Permalinks
To reference or cite the objects present in the Software Heritage archive, permalinks based on SoftWare Hash IDentifiers (SWHIDs) must be used.
Select below a type of object currently browsed in order to display its associated SWHID and permalink.
| Revision | Author | Date | Message | Commit Date |
|---|---|---|---|---|
| 2f3e4e3 | ulysses-you | 02 August 2022, 09:05:48 UTC | [SPARK-39932][SQL] WindowExec should clear the final partition buffer ### What changes were proposed in this pull request? Explicitly clear final partition buffer if can not find next in `WindowExec`. The same fix in `WindowInPandasExec` ### Why are the changes needed? We do a repartition after a window, then we need do a local sort after window due to RoundRobinPartitioning shuffle. The error stack: ```java ExternalAppendOnlyUnsafeRowArray INFO - Reached spill threshold of 4096 rows, switching to org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter org.apache.spark.memory.SparkOutOfMemoryError: Unable to acquire 65536 bytes of memory, got 0 at org.apache.spark.memory.MemoryConsumer.throwOom(MemoryConsumer.java:157) at org.apache.spark.memory.MemoryConsumer.allocateArray(MemoryConsumer.java:97) at org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter.growPointerArrayIfNecessary(UnsafeExternalSorter.java:352) at org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter.allocateMemoryForRecordIfNecessary(UnsafeExternalSorter.java:435) at org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter.insertRecord(UnsafeExternalSorter.java:455) at org.apache.spark.sql.execution.UnsafeExternalRowSorter.insertRow(UnsafeExternalRowSorter.java:138) at org.apache.spark.sql.execution.UnsafeExternalRowSorter.sort(UnsafeExternalRowSorter.java:226) at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec$.$anonfun$prepareShuffleDependency$10(ShuffleExchangeExec.scala:355) ``` `WindowExec` only clear buffer in `fetchNextPartition` so the final partition buffer miss to clear. It is not a big problem since we have task completion listener. ```scala taskContext.addTaskCompletionListener(context -> { cleanupResources(); }); ``` This bug only affects if the window is not the last operator for this task and the follow operator like sort. ### Does this PR introduce _any_ user-facing change? yes, bug fix ### How was this patch tested? N/A Closes #37358 from ulysses-you/window. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 1fac870126c289a7ec75f45b6b61c93b9a4965d4) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 02 August 2022, 09:06:54 UTC |
| f7a9409 | yangjie01 | 27 July 2022, 00:26:47 UTC | [SPARK-39879][SQL][TESTS] Reduce local-cluster maximum memory size in `BroadcastJoinSuite*` and `HiveSparkSubmitSuite` ### What changes were proposed in this pull request? This pr change `local-cluster[2, 1, 1024]` in `BroadcastJoinSuite*` and `HiveSparkSubmitSuite` to `local-cluster[2, 1, 512]` to reduce test maximum memory usage. ### Why are the changes needed? Reduce the maximum memory usage of test cases. ### Does this PR introduce _any_ user-facing change? No, test-only. ### How was this patch tested? Should monitor CI Closes #37298 from LuciferYang/reduce-local-cluster-memory. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 01d41e7de418d0a40db7b16ddd0d8546f0794d17) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 27 July 2022, 00:27:39 UTC |
| ea05c33 | Hyukjin Kwon | 25 July 2022, 06:56:34 UTC | Revert "[SPARK-39856][SQL][TESTS] Increase the number of partitions in TPC-DS build to avoid out-of-memory" This reverts commit 0a27d0c6e8e705176f0f245794bc8361860ac680. | 25 July 2022, 06:56:34 UTC |
| 0a27d0c | Hyukjin Kwon | 25 July 2022, 03:44:54 UTC | [SPARK-39856][SQL][TESTS] Increase the number of partitions in TPC-DS build to avoid out-of-memory This PR proposes to avoid out-of-memory in TPC-DS build at GitHub Actions CI by: - Increasing the number of partitions being used in shuffle. - Truncating precisions after 10th in floats. The number of partitions was previously set to 1 because of different results in precisions that generally we can just ignore. - Sort the results regardless of join type since Apache Spark does not guarantee the order of results One of the reasons for the large memory usage seems to be single partition that's being used in the shuffle. No, test-only. GitHub Actions in this CI will test it out. Closes #37270 from HyukjinKwon/deflake-tpcds. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 7358253755762f9bfe6cedc1a50ec14616cfeace) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 25 July 2022, 03:51:19 UTC |
| c653d28 | sandeepvinayak | 31 May 2022, 22:28:07 UTC | [SPARK-39283][CORE] Fix deadlock between TaskMemoryManager and UnsafeExternalSorter.SpillableIterator ### What changes were proposed in this pull request? This PR fixes a deadlock between TaskMemoryManager and UnsafeExternalSorter.SpillableIterator. ### Why are the changes needed? We are facing the deadlock issue b/w TaskMemoryManager and UnsafeExternalSorter.SpillableIterator during the join. It turns out that in UnsafeExternalSorter.SpillableIterator#spill() function, it tries to get lock on UnsafeExternalSorter`SpillableIterator` and UnsafeExternalSorter and call `freePage` to free all allocated pages except the last one which takes the lock on TaskMemoryManager. At the same time, there can be another `MemoryConsumer` using `UnsafeExternalSorter` as part of sorting can try to allocatePage needs to get lock on `TaskMemoryManager` which can cause spill to happen which requires lock on `UnsafeExternalSorter` again causing deadlock. There is a similar fix here as well: https://issues.apache.org/jira/browse/SPARK-27338 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing unit tests. Closes #36680 from sandeepvinayak/SPARK-39283. Authored-by: sandeepvinayak <sandeep.pal@outlook.com> Signed-off-by: Josh Rosen <joshrosen@databricks.com> | 31 May 2022, 22:51:40 UTC |
| 02488e0 | Tom van Bussel | 18 September 2020, 11:49:26 UTC | [SPARK-32911][CORE] Free memory in UnsafeExternalSorter.SpillableIterator.spill() when all records have been read ### What changes were proposed in this pull request? This PR changes `UnsafeExternalSorter.SpillableIterator` to free its memory (except for the page holding the last record) if it is forced to spill after all of its records have been read. It also makes sure that `lastPage` is freed if `loadNext` is never called the again. The latter was necessary to get my test case to succeed (otherwise it would complain about a leak). ### Why are the changes needed? No memory is freed after calling `UnsafeExternalSorter.SpillableIterator.spill()` when all records have been read, even though it is still holding onto some memory. This may cause a `SparkOutOfMemoryError` to be thrown, even though we could have just freed the memory instead. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? A test was added to `UnsafeExternalSorterSuite`. Closes #29787 from tomvanbussel/SPARK-32911. Authored-by: Tom van Bussel <tom.vanbussel@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 31 May 2022, 22:50:52 UTC |
| 9b26812 | Takuya UESHIN | 26 May 2022, 01:36:03 UTC | [SPARK-39293][SQL] Fix the accumulator of ArrayAggregate to handle complex types properly Fix the accumulator of `ArrayAggregate` to handle complex types properly. The accumulator of `ArrayAggregate` should copy the intermediate result if string, struct, array, or map. If the intermediate data of `ArrayAggregate` holds reusable data, the result will be duplicated. ```scala import org.apache.spark.sql.functions._ val reverse = udf((s: String) => s.reverse) val df = Seq(Array("abc", "def")).toDF("array") val testArray = df.withColumn( "agg", aggregate( col("array"), array().cast("array<string>"), (acc, s) => concat(acc, array(reverse(s))))) aggArray.show(truncate=false) ``` should be: ``` +----------+----------+ |array |agg | +----------+----------+ |[abc, def]|[cba, fed]| +----------+----------+ ``` but: ``` +----------+----------+ |array |agg | +----------+----------+ |[abc, def]|[fed, fed]| +----------+----------+ ``` Yes, this fixes the correctness issue. Added a test. Closes #36674 from ueshin/issues/SPARK-39293/array_aggregate. Authored-by: Takuya UESHIN <ueshin@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit d6a11cb4b411c8136eb241aac167bc96990f5421) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 92e82fdf8e2faec5add61e2448f11272dfb19c6e) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 68d69501576ba21e182791aad91b82a1e7282d11) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 26 May 2022, 01:40:16 UTC |
| 19942e7 | Vitalii Li | 06 May 2022, 09:04:28 UTC | [SPARK-39060][SQL][3.0] Typo in error messages of decimal overflow ### What changes were proposed in this pull request? This PR removes extra curly bracket from debug string for Decimal type in SQL. This is a backport from master branch. Commit: https://github.com/apache/spark/commit/165ce4eb7d6d75201beb1bff879efa99fde24f94 ### Why are the changes needed? Typo in error messages of decimal overflow. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? By running updated test: ``` $ build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite -- -z decimalArithmeticOperations.sql" ``` Closes #36460 from vli-databricks/SPARK-39060-3.0. Authored-by: Vitalii Li <vitalii.li@databricks.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 06 May 2022, 09:04:28 UTC |
| 4e38563 | allisonwang-db | 01 May 2022, 19:32:28 UTC | [SPARK-38918][SQL][3.0] Nested column pruning should filter out attributes that do not belong to the current relation ### What changes were proposed in this pull request? Backport https://github.com/apache/spark/pull/36216 to branch-3.0. ### Why are the changes needed? To fix a bug in `SchemaPruning`. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test Closes #36388 from allisonwang-db/spark-38918-branch-3.0. Authored-by: allisonwang-db <allison.wang@databricks.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 01 May 2022, 19:32:28 UTC |
| 46fa499 | Hyukjin Kwon | 27 April 2022, 07:59:34 UTC | Revert "[SPARK-39032][PYTHON][DOCS] Examples' tag for pyspark.sql.functions.when()" This reverts commit 821a348ae7f9cd5958d29ccf342719f5d753ae28. | 27 April 2022, 07:59:34 UTC |
| 821a348 | vadim | 27 April 2022, 07:56:18 UTC | [SPARK-39032][PYTHON][DOCS] Examples' tag for pyspark.sql.functions.when() ### What changes were proposed in this pull request? Fix missing keyword for `pyspark.sql.functions.when()` documentation. ### Why are the changes needed? [Documentation](https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.sql.functions.when.html) is not formatted correctly ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? All tests passed. Closes #36369 from vadim/SPARK-39032. Authored-by: vadim <86705+vadim@users.noreply.github.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 5b53bdfa83061c160652e07b999f996fc8bd2ece) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 27 April 2022, 07:57:26 UTC |
| aeea56d | Hyukjin Kwon | 22 April 2022, 10:01:05 UTC | [SPARK-38992][CORE] Avoid using bash -c in ShellBasedGroupsMappingProvider ### What changes were proposed in this pull request? This PR proposes to avoid using `bash -c` in `ShellBasedGroupsMappingProvider`. This could allow users a command injection. ### Why are the changes needed? For a security purpose. ### Does this PR introduce _any_ user-facing change? Virtually no. ### How was this patch tested? Manually tested. Closes #36315 from HyukjinKwon/SPARK-38992. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit c83618e4e5fc092829a1f2a726f12fb832e802cc) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 22 April 2022, 10:02:25 UTC |
| ac58f88 | Bruce Robbins | 22 April 2022, 03:30:34 UTC | [SPARK-38990][SQL] Avoid `NullPointerException` when evaluating date_trunc/trunc format as a bound reference ### What changes were proposed in this pull request? Change `TruncInstant.evalHelper` to pass the input row to `format.eval` when `format` is a not a literal (and therefore might be a bound reference). ### Why are the changes needed? This query fails with a `java.lang.NullPointerException`: ``` select date_trunc(col1, col2) from values ('week', timestamp'2012-01-01') as data(col1, col2); ``` This only happens if the data comes from an inline table. When the source is an inline table, `ConvertToLocalRelation` attempts to evaluate the function against the data in interpreted mode. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Update to unit tests. Closes #36312 from bersprockets/date_trunc_issue. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 2e4f4abf553cedec1fa8611b9494a01d24e6238a) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 22 April 2022, 03:31:43 UTC |
| 156d1aa | Kent Yao | 20 April 2022, 06:38:26 UTC | [SPARK-38922][CORE] TaskLocation.apply throw NullPointerException ### What changes were proposed in this pull request? TaskLocation.apply w/o NULL check may throw NPE and fail job scheduling ``` Caused by: java.lang.NullPointerException at scala.collection.immutable.StringLike$class.stripPrefix(StringLike.scala:155) at scala.collection.immutable.StringOps.stripPrefix(StringOps.scala:29) at org.apache.spark.scheduler.TaskLocation$.apply(TaskLocation.scala:71) at org.apache.spark.scheduler.DAGScheduler$$anonfun$org$apache$spark$scheduler$DAGScheduler$$getPreferredLocsInternal ``` For instance, `org.apache.spark.rdd.HadoopRDD#convertSplitLocationInfo` might generate unexpected `Some(null)` elements where should be replace by `Option.apply` ### Why are the changes needed? fix NPE ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? new tests Closes #36222 from yaooqinn/SPARK-38922. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Kent Yao <yao@apache.org> (cherry picked from commit 33e07f3cd926105c6d28986eb6218f237505549e) Signed-off-by: Kent Yao <yao@apache.org> | 20 April 2022, 06:39:57 UTC |
| 5f90203 | fhygh | 15 April 2022, 11:42:18 UTC | [SPARK-38892][SQL][TESTS] Fix a test case schema assertion of ParquetPartitionDiscoverySuite ### What changes were proposed in this pull request? in ParquetPartitionDiscoverySuite, thare are some assert have no parctical significance. `assert(input.schema.sameType(input.schema))` ### Why are the changes needed? fix this to assert the actual result. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? updated testsuites Closes #36189 from fhygh/assertutfix. Authored-by: fhygh <283452027@qq.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 4835946de2ef71b176da5106e9b6c2706e182722) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 15 April 2022, 11:43:25 UTC |
| beb64fa | Hyukjin Kwon | 07 April 2022, 00:45:02 UTC | Revert "[MINOR][SQL][SS][DOCS] Add varargs to Dataset.observe(String, ..) with a documentation fix" This reverts commit 952d476786ff7e2f5216094b272d46a253891358. | 07 April 2022, 00:45:02 UTC |
| 952d476 | Hyukjin Kwon | 06 April 2022, 08:26:17 UTC | [MINOR][SQL][SS][DOCS] Add varargs to Dataset.observe(String, ..) with a documentation fix ### What changes were proposed in this pull request? This PR proposes two minor changes: - Fixes the example at `Dataset.observe(String, ...)` - Adds `varargs` to be consistent with another overloaded version: `Dataset.observe(Observation, ..)` ### Why are the changes needed? To provide a correct example, support Java APIs properly with `varargs` and API consistency. ### Does this PR introduce _any_ user-facing change? Yes, the example is fixed in the documentation. Additionally Java users should be able to use `Dataset.observe(String, ..)` per `varargs`. ### How was this patch tested? Manually tested. CI should verify the changes too. Closes #36084 from HyukjinKwon/minor-docs. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit fb3f380b3834ca24947a82cb8d87efeae6487664) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 06 April 2022, 08:27:13 UTC |
| dd54888 | Dongjoon Hyun | 30 March 2022, 15:26:41 UTC | [SPARK-38652][K8S] `uploadFileUri` should preserve file scheme ### What changes were proposed in this pull request? This PR replaces `new Path(fileUri.getPath)` with `new Path(fileUri)`. By using `Path` class constructor with URI parameter, we can preserve file scheme. ### Why are the changes needed? If we use, `Path` class constructor with `String` parameter, it loses file scheme information. Although the original code works so far, it fails at Apache Hadoop 3.3.2 and breaks dependency upload feature which is covered by K8s Minikube integration tests. ```scala test("uploadFileUri") { val fileUri = org.apache.spark.util.Utils.resolveURI("/tmp/1.txt") assert(new Path(fileUri).toString == "file:/private/tmp/1.txt") assert(new Path(fileUri.getPath).toString == "/private/tmp/1.txt") } ``` ### Does this PR introduce _any_ user-facing change? No, this will prevent a regression at Apache Spark 3.3.0 instead. ### How was this patch tested? Pass the CIs. In addition, this PR and #36009 will recover K8s IT `DepsTestsSuite`. Closes #36010 from dongjoon-hyun/SPARK-38652. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit cab8aa1c4fe66c4cb1b69112094a203a04758f76) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 30 March 2022, 15:27:46 UTC |
| 2ac7872 | Yuming Wang | 27 March 2022, 00:45:26 UTC | [SPARK-38663][TESTS][3.0] Remove inaccessible repository: https://dl.bintray.com ### What changes were proposed in this pull request? This pr removes the resolver of https://dl.bintray.com/typesafe/sbt-plugins. ### Why are the changes needed? https://dl.bintray.com/typesafe/sbt-plugins is invalid: ``` Run ./dev/lint-scala Scalastyle checks failed at following occurrences: [error] SERVER ERROR: Bad Gateway url=https://dl.bintray.com/typesafe/sbt-plugins/com.etsy/sbt-checkstyle-plugin/3.1.1/jars/sbt-checkstyle-plugin.jar [error] SERVER ERROR: Bad Gateway url=https://dl.bintray.com/typesafe/sbt-plugins/org.sonatype.oss/oss-parent/7/jars/oss-parent.jar [error] SERVER ERROR: Bad Gateway url=https://dl.bintray.com/typesafe/sbt-plugins/org.antlr/antlr4-master/4.7.2/jars/antlr4-master.jar [error] SERVER ERROR: Bad Gateway url=https://dl.bintray.com/typesafe/sbt-plugins/org.apache/apache/1[9](https://github.com/apache/spark/runs/5657909908?check_suite_focus=true#step:11:9)/jars/apache.jar ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Local test: ``` rm -rf ~/.ivy2/ build/sbt scalastyle test:scalastyle ... [info] downloading https://repo.scala-sbt.org/scalasbt/sbt-plugin-releases/com.typesafe/sbt-mima-plugin/scala_2.10/sbt_0.13/0.3.0/jars/sbt-mima-plugin.jar ... [info] [SUCCESSFUL ] com.typesafe#sbt-mima-plugin;0.3.0!sbt-mima-plugin.jar (4989ms) ... ``` Closes #35978 from wangyum/SPARK-38663. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 27 March 2022, 00:45:26 UTC |
| 4fc718f | mcdull-zhang | 26 March 2022, 04:48:08 UTC | [SPARK-38570][SQL][3.0] Incorrect DynamicPartitionPruning caused by Literal This is a backport of #35878 to branch 3.0. The return value of Literal.references is an empty AttributeSet, so Literal is mistaken for a partition column. For example, the sql in the test case will generate such a physical plan when the adaptive is closed: ```tex *(4) Project [store_id#5281, date_id#5283, state_province#5292] +- *(4) BroadcastHashJoin [store_id#5281], [store_id#5291], Inner, BuildRight, false :- Union : :- *(1) Project [4 AS store_id#5281, date_id#5283] : : +- *(1) Filter ((isnotnull(date_id#5283) AND (date_id#5283 >= 1300)) AND dynamicpruningexpression(4 IN dynamicpruning#5300)) : : : +- ReusedSubquery SubqueryBroadcast dynamicpruning#5300, 0, [store_id#5291], [id=#336] : : +- *(1) ColumnarToRow : : +- FileScan parquet default.fact_sk[date_id#5283,store_id#5286] Batched: true, DataFilters: [isnotnull(date_id#5283), (date_id#5283 >= 1300)], Format: Parquet, Location: CatalogFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache.s..., PartitionFilters: [dynamicpruningexpression(4 IN dynamicpruning#5300)], PushedFilters: [IsNotNull(date_id), GreaterThanOrEqual(date_id,1300)], ReadSchema: struct<date_id:int> : : +- SubqueryBroadcast dynamicpruning#5300, 0, [store_id#5291], [id=#336] : : +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)),false), [id=#335] : : +- *(1) Project [store_id#5291, state_province#5292] : : +- *(1) Filter (((isnotnull(country#5293) AND (country#5293 = US)) AND ((store_id#5291 <=> 4) OR (store_id#5291 <=> 5))) AND isnotnull(store_id#5291)) : : +- *(1) ColumnarToRow : : +- FileScan parquet default.dim_store[store_id#5291,state_province#5292,country#5293] Batched: true, DataFilters: [isnotnull(country#5293), (country#5293 = US), ((store_id#5291 <=> 4) OR (store_id#5291 <=> 5)), ..., Format: Parquet, Location: InMemoryFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache...., PartitionFilters: [], PushedFilters: [IsNotNull(country), EqualTo(country,US), Or(EqualNullSafe(store_id,4),EqualNullSafe(store_id,5))..., ReadSchema: struct<store_id:int,state_province:string,country:string> : +- *(2) Project [5 AS store_id#5282, date_id#5287] : +- *(2) Filter ((isnotnull(date_id#5287) AND (date_id#5287 <= 1000)) AND dynamicpruningexpression(5 IN dynamicpruning#5300)) : : +- ReusedSubquery SubqueryBroadcast dynamicpruning#5300, 0, [store_id#5291], [id=#336] : +- *(2) ColumnarToRow : +- FileScan parquet default.fact_stats[date_id#5287,store_id#5290] Batched: true, DataFilters: [isnotnull(date_id#5287), (date_id#5287 <= 1000)], Format: Parquet, Location: CatalogFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache.s..., PartitionFilters: [dynamicpruningexpression(5 IN dynamicpruning#5300)], PushedFilters: [IsNotNull(date_id), LessThanOrEqual(date_id,1000)], ReadSchema: struct<date_id:int> : +- ReusedSubquery SubqueryBroadcast dynamicpruning#5300, 0, [store_id#5291], [id=#336] +- ReusedExchange [store_id#5291, state_province#5292], BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)),false), [id=#335] ``` after this pr: ```tex *(4) Project [store_id#5281, date_id#5283, state_province#5292] +- *(4) BroadcastHashJoin [store_id#5281], [store_id#5291], Inner, BuildRight, false :- Union : :- *(1) Project [4 AS store_id#5281, date_id#5283] : : +- *(1) Filter (isnotnull(date_id#5283) AND (date_id#5283 >= 1300)) : : +- *(1) ColumnarToRow : : +- FileScan parquet default.fact_sk[date_id#5283,store_id#5286] Batched: true, DataFilters: [isnotnull(date_id#5283), (date_id#5283 >= 1300)], Format: Parquet, Location: CatalogFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache.s..., PartitionFilters: [], PushedFilters: [IsNotNull(date_id), GreaterThanOrEqual(date_id,1300)], ReadSchema: struct<date_id:int> : +- *(2) Project [5 AS store_id#5282, date_id#5287] : +- *(2) Filter (isnotnull(date_id#5287) AND (date_id#5287 <= 1000)) : +- *(2) ColumnarToRow : +- FileScan parquet default.fact_stats[date_id#5287,store_id#5290] Batched: true, DataFilters: [isnotnull(date_id#5287), (date_id#5287 <= 1000)], Format: Parquet, Location: CatalogFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache.s..., PartitionFilters: [], PushedFilters: [IsNotNull(date_id), LessThanOrEqual(date_id,1000)], ReadSchema: struct<date_id:int> +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)),false), [id=#326] +- *(3) Project [store_id#5291, state_province#5292] +- *(3) Filter (((isnotnull(country#5293) AND (country#5293 = US)) AND ((store_id#5291 <=> 4) OR (store_id#5291 <=> 5))) AND isnotnull(store_id#5291)) +- *(3) ColumnarToRow +- FileScan parquet default.dim_store[store_id#5291,state_province#5292,country#5293] Batched: true, DataFilters: [isnotnull(country#5293), (country#5293 = US), ((store_id#5291 <=> 4) OR (store_id#5291 <=> 5)), ..., Format: Parquet, Location: InMemoryFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache...., PartitionFilters: [], PushedFilters: [IsNotNull(country), EqualTo(country,US), Or(EqualNullSafe(store_id,4),EqualNullSafe(store_id,5))..., ReadSchema: struct<store_id:int,state_province:string,country:string> ``` Execution performance improvement No Added unit test Closes #35967 from mcdull-zhang/spark_38570_3.2. Authored-by: mcdull-zhang <work4dong@163.com> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit 8621914e2052eeab25e6ac4e7d5f48b5570c71f7) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 26 March 2022, 05:47:28 UTC |
| 914b2ff | Kent Yao | 23 March 2022, 09:25:47 UTC | resolve conflicts | 23 March 2022, 09:34:49 UTC |
| f7bf0fe | huangmaoyang2 | 23 March 2022, 06:06:58 UTC | [SPARK-38629][SQL][DOCS] Two links beneath Spark SQL Guide/Data Sources do not work properly SPARK-38629 Two links beneath Spark SQL Guide/Data Sources do not work properly ### What changes were proposed in this pull request? Two typos have been corrected in sql-data-sources.md under Spark's docs directory. ### Why are the changes needed? Two links under latest documentation [Spark SQL Guide/Data Sources](https://spark.apache.org/docs/latest/sql-data-sources.html) do not work properly, when click 'Ignore Corrupt File' or 'Ignore Missing Files', it does redirect me to the right page, but does not scroll to the right section. This issue actually has been there since v3.0.0. ### Does this PR introduce _any_ user-facing change? Yes ### How was this patch tested? I've built the documentation locally and tested my change. Closes #35944 from morvenhuang/SPARK-38629. Authored-by: huangmaoyang2 <huangmaoyang1@jd.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit ac9ae98011424a030a6ef264caf077b8873e251d) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 23 March 2022, 06:07:50 UTC |
| e8310ea | Karen Feng | 14 March 2022, 05:55:44 UTC | [SPARK-37865][SQL][FOLLOWUP] Fix compilation error for union deduplication correctness bug fixup ### What changes were proposed in this pull request? Fixes compilation error following https://github.com/apache/spark/pull/35760. ### Why are the changes needed? Compilation error: https://github.com/apache/spark/runs/5473941519?check_suite_focus=true ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit tests Closes #35842 from karenfeng/SPARK-37865-branch-3.0. Authored-by: Karen Feng <karen.feng@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 14 March 2022, 05:55:44 UTC |
| b26ac3f | Dongjoon Hyun | 13 March 2022, 03:33:23 UTC | [SPARK-38538][K8S][TESTS] Fix driver environment verification in BasicDriverFeatureStepSuite ### What changes were proposed in this pull request? This PR aims to fix the driver environment verification logic in `BasicDriverFeatureStepSuite`. ### Why are the changes needed? When SPARK-25876 added a test logic at Apache Spark 3.0.0, it used `envs(v) === v` instead of `envs(k) === v`. https://github.com/apache/spark/blob/c032928515e74367137c668ce692d8fd53696485/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/deploy/k8s/features/BasicDriverFeatureStepSuite.scala#L94-L96 This bug was hidden because the test key-value pairs have identical set. If we have different strings for keys and values, the test case fails. https://github.com/apache/spark/blob/c032928515e74367137c668ce692d8fd53696485/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/deploy/k8s/features/BasicDriverFeatureStepSuite.scala#L42-L44 ### Does this PR introduce _any_ user-facing change? To have a correct test coverage. ### How was this patch tested? Pass the CIs. Closes #35828 from dongjoon-hyun/SPARK-38538. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit 6becf4e93e68e36fbcdc82768de497d86072abeb) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 13 March 2022, 03:34:49 UTC |
| 3eb7264 | Karen Feng | 09 March 2022, 01:34:01 UTC | [SPARK-37865][SQL] Fix union deduplication correctness bug Fixes a correctness bug in `Union` in the case that there are duplicate output columns. Previously, duplicate columns on one side of the union would result in a duplicate column being output on the other side of the union. To do so, we go through the union’s child’s output and find the duplicates. For each duplicate set, there is a first duplicate: this one is left alone. All following duplicates are aliased and given a tag; this tag is used to remove ambiguity during resolution. As the first duplicate is left alone, the user can still select it, avoiding a breaking change. As the later duplicates are given new expression IDs, this fixes the correctness bug. Output of union with duplicate columns in the children was incorrect Example query: ``` SELECT a, a FROM VALUES (1, 1), (1, 2) AS t1(a, b) UNION ALL SELECT c, d FROM VALUES (2, 2), (2, 3) AS t2(c, d) ``` Result before: ``` a | a _ | _ 1 | 1 1 | 1 2 | 2 2 | 2 ``` Result after: ``` a | a _ | _ 1 | 1 1 | 1 2 | 2 2 | 3 ``` Unit tests Closes #35760 from karenfeng/spark-37865. Authored-by: Karen Feng <karen.feng@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 59ce0a706cb52a54244a747d0a070b61f5cddd1c) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 09 March 2022, 01:38:01 UTC |
| e036de3 | Cheng Pan | 06 March 2022, 23:41:20 UTC | [SPARK-38411][CORE] Use `UTF-8` when `doMergeApplicationListingInternal` reads event logs ### What changes were proposed in this pull request? Use UTF-8 instead of system default encoding to read event log ### Why are the changes needed? After SPARK-29160, we should always use UTF-8 to read event log, otherwise, if Spark History Server run with different default charset than "UTF-8", will encounter such error. ``` 2022-03-04 12:16:00,143 [3752440] - INFO [log-replay-executor-19:Logging57] - Parsing hdfs://hz-cluster11/spark2-history/application_1640597251469_2453817_1.lz4 for listing data... 2022-03-04 12:16:00,145 [3752442] - ERROR [log-replay-executor-18:Logging94] - Exception while merging application listings java.nio.charset.MalformedInputException: Input length = 1 at java.nio.charset.CoderResult.throwException(CoderResult.java:281) at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:339) at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:178) at java.io.InputStreamReader.read(InputStreamReader.java:184) at java.io.BufferedReader.fill(BufferedReader.java:161) at java.io.BufferedReader.readLine(BufferedReader.java:324) at java.io.BufferedReader.readLine(BufferedReader.java:389) at scala.io.BufferedSource$BufferedLineIterator.hasNext(BufferedSource.scala:74) at scala.collection.Iterator$$anon$20.hasNext(Iterator.scala:884) at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:511) at org.apache.spark.scheduler.ReplayListenerBus.replay(ReplayListenerBus.scala:82) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$doMergeApplicationListing$4(FsHistoryProvider.scala:819) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$doMergeApplicationListing$4$adapted(FsHistoryProvider.scala:801) at org.apache.spark.util.Utils$.tryWithResource(Utils.scala:2626) at org.apache.spark.deploy.history.FsHistoryProvider.doMergeApplicationListing(FsHistoryProvider.scala:801) at org.apache.spark.deploy.history.FsHistoryProvider.mergeApplicationListing(FsHistoryProvider.scala:715) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$checkForLogs$15(FsHistoryProvider.scala:581) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) ``` ### Does this PR introduce _any_ user-facing change? Yes, bug fix. ### How was this patch tested? Verification steps in ubuntu:20.04 1. build `spark-3.3.0-SNAPSHOT-bin-master.tgz` on commit `34618a7ef6` using `dev/make-distribution.sh --tgz --name master` 2. build `spark-3.3.0-SNAPSHOT-bin-SPARK-38411.tgz` on commit `2a8f56038b` using `dev/make-distribution.sh --tgz --name SPARK-38411` 3. switch to UTF-8 using `export LC_ALL=C.UTF-8 && bash` 4. generate event log contains no-ASCII chars. ``` bin/spark-submit \ --master local[*] \ --class org.apache.spark.examples.SparkPi \ --conf spark.eventLog.enabled=true \ --conf spark.user.key='计算圆周率' \ examples/jars/spark-examples_2.12-3.3.0-SNAPSHOT.jar ``` 5. switch to POSIX using `export LC_ALL=POSIX && bash` 6. run `spark-3.3.0-SNAPSHOT-bin-master/sbin/start-history-server.sh` and watch logs <details> ``` Spark Command: /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java -cp /spark-3.3.0-SNAPSHOT-bin-master/conf/:/spark-3.3.0-SNAPSHOT-bin-master/jars/* -Xmx1g org.apache.spark.deploy.history.HistoryServer ======================================== Using Spark's default log4j profile: org/apache/spark/log4j2-defaults.properties 22/03/06 13:37:19 INFO HistoryServer: Started daemon with process name: 48729c3ffc10aa9 22/03/06 13:37:19 INFO SignalUtils: Registering signal handler for TERM 22/03/06 13:37:19 INFO SignalUtils: Registering signal handler for HUP 22/03/06 13:37:19 INFO SignalUtils: Registering signal handler for INT 22/03/06 13:37:21 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 22/03/06 13:37:21 INFO SecurityManager: Changing view acls to: root 22/03/06 13:37:21 INFO SecurityManager: Changing modify acls to: root 22/03/06 13:37:21 INFO SecurityManager: Changing view acls groups to: 22/03/06 13:37:21 INFO SecurityManager: Changing modify acls groups to: 22/03/06 13:37:21 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set() 22/03/06 13:37:21 INFO FsHistoryProvider: History server ui acls disabled; users with admin permissions: ; groups with admin permissions: 22/03/06 13:37:22 INFO Utils: Successfully started service 'HistoryServerUI' on port 18080. 22/03/06 13:37:23 INFO HistoryServer: Bound HistoryServer to 0.0.0.0, and started at http://29c3ffc10aa9:18080 22/03/06 13:37:23 INFO FsHistoryProvider: Parsing file:/tmp/spark-events/local-1646573251839 for listing data... 22/03/06 13:37:25 ERROR FsHistoryProvider: Exception while merging application listings java.nio.charset.MalformedInputException: Input length = 1 at java.nio.charset.CoderResult.throwException(CoderResult.java:281) ~[?:1.8.0_312] at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:339) ~[?:1.8.0_312] at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:178) ~[?:1.8.0_312] at java.io.InputStreamReader.read(InputStreamReader.java:184) ~[?:1.8.0_312] at java.io.BufferedReader.fill(BufferedReader.java:161) ~[?:1.8.0_312] at java.io.BufferedReader.readLine(BufferedReader.java:324) ~[?:1.8.0_312] at java.io.BufferedReader.readLine(BufferedReader.java:389) ~[?:1.8.0_312] at scala.io.BufferedSource$BufferedLineIterator.hasNext(BufferedSource.scala:74) ~[scala-library-2.12.15.jar:?] at scala.collection.Iterator$$anon$20.hasNext(Iterator.scala:886) ~[scala-library-2.12.15.jar:?] at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:513) ~[scala-library-2.12.15.jar:?] at org.apache.spark.scheduler.ReplayListenerBus.replay(ReplayListenerBus.scala:82) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$doMergeApplicationListingInternal$4(FsHistoryProvider.scala:830) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$doMergeApplicationListingInternal$4$adapted(FsHistoryProvider.scala:812) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.util.Utils$.tryWithResource(Utils.scala:2738) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.doMergeApplicationListingInternal(FsHistoryProvider.scala:812) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.doMergeApplicationListing(FsHistoryProvider.scala:758) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.mergeApplicationListing(FsHistoryProvider.scala:718) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$checkForLogs$15(FsHistoryProvider.scala:584) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) [?:1.8.0_312] at java.util.concurrent.FutureTask.run(FutureTask.java:266) [?:1.8.0_312] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_312] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_312] at java.lang.Thread.run(Thread.java:748) [?:1.8.0_312] ``` </details> 7. run `spark-3.3.0-SNAPSHOT-bin-master/sbin/stop-history-server.sh` 8. run `spark-3.3.0-SNAPSHOT-bin-SPARK-38411/sbin/stop-history-server.sh` and watch logs <details> ``` Spark Command: /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java -cp /spark-3.3.0-SNAPSHOT-bin-SPARK-38411/conf/:/spark-3.3.0-SNAPSHOT-bin-SPARK-38411/jars/* -Xmx1g org.apache.spark.deploy.history.HistoryServer ======================================== Using Spark's default log4j profile: org/apache/spark/log4j2-defaults.properties 22/03/06 13:30:54 INFO HistoryServer: Started daemon with process name: 34729c3ffc10aa9 22/03/06 13:30:54 INFO SignalUtils: Registering signal handler for TERM 22/03/06 13:30:54 INFO SignalUtils: Registering signal handler for HUP 22/03/06 13:30:54 INFO SignalUtils: Registering signal handler for INT 22/03/06 13:30:55 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 22/03/06 13:30:56 INFO SecurityManager: Changing view acls to: root 22/03/06 13:30:56 INFO SecurityManager: Changing modify acls to: root 22/03/06 13:30:56 INFO SecurityManager: Changing view acls groups to: 22/03/06 13:30:56 INFO SecurityManager: Changing modify acls groups to: 22/03/06 13:30:56 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set() 22/03/06 13:30:56 INFO FsHistoryProvider: History server ui acls disabled; users with admin permissions: ; groups with admin permissions: 22/03/06 13:30:57 INFO Utils: Successfully started service 'HistoryServerUI' on port 18080. 22/03/06 13:30:57 INFO HistoryServer: Bound HistoryServer to 0.0.0.0, and started at http://29c3ffc10aa9:18080 22/03/06 13:30:57 INFO FsHistoryProvider: Parsing file:/tmp/spark-events/local-1646573251839 for listing data... 22/03/06 13:30:59 INFO FsHistoryProvider: Finished parsing file:/tmp/spark-events/local-1646573251839 ``` </details> Closes #35730 from pan3793/SPARK-38411. Authored-by: Cheng Pan <chengpan@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 135841f257fbb008aef211a5e38222940849cb26) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 06 March 2022, 23:45:36 UTC |
| f125600 | attilapiros | 04 March 2022, 18:52:49 UTC | [SPARK-33206][CORE][3.0] Fix shuffle index cache weight calculation for small index files ### What changes were proposed in this pull request? Increasing the shuffle index weight with a constant number to avoid underestimating retained memory size caused by the bookkeeping objects: the `java.io.File` (depending on the path ~ 960 bytes) object and the `ShuffleIndexInformation` object (~180 bytes). ### Why are the changes needed? Underestimating cache entry size easily can cause OOM in the Yarn NodeManager. In the following analyses of a prod issue (HPROF file) we can see the leak suspect Guava's `LocalCache$Segment` objects: <img width="943" alt="Screenshot 2022-02-17 at 18 55 40" src="https://user-images.githubusercontent.com/2017933/154541995-44014212-2046-41d6-ba7f-99369ca7d739.png"> Going further we can see a `ShuffleIndexInformation` for a small index file (16 bytes) but the retained heap memory is 1192 bytes: <img width="1351" alt="image" src="https://user-images.githubusercontent.com/2017933/154645212-e0318d0f-cefa-4ae3-8a3b-97d2b506757d.png"> Finally we can see this is very common within this heap dump (using MAT's Object Query Language): <img width="1418" alt="image" src="https://user-images.githubusercontent.com/2017933/154547678-44c8af34-1765-4e14-b71a-dc03d1a304aa.png"> I have even exported the data to a CSV and done some calculations with `awk`: ``` $ tail -n+2 export.csv | awk -F, 'BEGIN { numUnderEstimated=0; } { sumOldSize += $1; corrected=$1 + 1176; sumCorrectedSize += corrected; sumRetainedMem += $2; if (corrected < $2) numUnderEstimated+=1; } END { print "sum old size: " sumOldSize / 1024 / 1024 " MB, sum corrected size: " sumCorrectedSize / 1024 / 1024 " MB, sum retained memory:" sumRetainedMem / 1024 / 1024 " MB, num under estimated: " numUnderEstimated }' ``` It gives the followings: ``` sum old size: 76.8785 MB, sum corrected size: 1066.93 MB, sum retained memory:1064.47 MB, num under estimated: 0 ``` So using the old calculation we were at 7.6.8 MB way under the default cache limit (100 MB). Using the correction (applying 1176 as increment to the size) we are at 1066.93 MB (~1GB) which is close to the real retained sum heap: 1064.47 MB (~1GB) and there is no entry which was underestimated. But we can go further and get rid of `java.io.File` completely and store the `ShuffleIndexInformation` for the file path. This way not only the cache size estimate is improved but the its size is decreased as well. Here the path size is not counted into the cache size as that string is interned. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? With the calculations above. Closes #35723 from attilapiros/SPARK-33206-3.0. Authored-by: attilapiros <piros.attila.zsolt@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 04 March 2022, 18:52:49 UTC |
| 5b3f567 | allisonwang-db | 01 March 2022, 07:13:50 UTC | [SPARK-38180][SQL][3.1] Allow safe up-cast expressions in correlated equality predicates Backport https://github.com/apache/spark/pull/35486 to branch-3.1. ### What changes were proposed in this pull request? This PR relaxes the constraint added in [SPARK-35080](https://issues.apache.org/jira/browse/SPARK-35080) by allowing safe up-cast expressions in correlated equality predicates. ### Why are the changes needed? Cast expressions are often added by the compiler during query analysis. Correlated equality predicates can be less restrictive to support this common pattern if a cast expression guarantees one-to-one mapping between the child expression and the output datatype (safe up-cast). ### Does this PR introduce _any_ user-facing change? Yes. Safe up-cast expressions are allowed in correlated equality predicates: ```sql SELECT (SELECT SUM(b) FROM VALUES (1, 1), (1, 2) t(a, b) WHERE CAST(a AS STRING) = x) FROM VALUES ('1'), ('2') t(x) ``` Before this change, this query will throw AnalysisException "Correlated column is not allowed in predicate...", and after this change, this query can run successfully. ### How was this patch tested? Unit tests. Closes #35689 from allisonwang-db/spark-38180-3.1. Authored-by: allisonwang-db <allison.wang@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 1e1f6b2aac5091343d572fb2472f46fa574882eb) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 01 March 2022, 07:14:28 UTC |
| 9d54a95 | Ruifeng Zheng | 24 February 2022, 02:49:52 UTC | [SPARK-38286][SQL] Union's maxRows and maxRowsPerPartition may overflow check Union's maxRows and maxRowsPerPartition Union's maxRows and maxRowsPerPartition may overflow: case 1: ``` scala> val df1 = spark.range(0, Long.MaxValue, 1, 1) df1: org.apache.spark.sql.Dataset[Long] = [id: bigint] scala> val df2 = spark.range(0, 100, 1, 10) df2: org.apache.spark.sql.Dataset[Long] = [id: bigint] scala> val union = df1.union(df2) union: org.apache.spark.sql.Dataset[Long] = [id: bigint] scala> union.queryExecution.logical.maxRowsPerPartition res19: Option[Long] = Some(-9223372036854775799) scala> union.queryExecution.logical.maxRows res20: Option[Long] = Some(-9223372036854775709) ``` case 2: ``` scala> val n = 2000000 n: Int = 2000000 scala> val df1 = spark.range(0, n, 1, 1).selectExpr("id % 5 as key1", "id as value1") df1: org.apache.spark.sql.DataFrame = [key1: bigint, value1: bigint] scala> val df2 = spark.range(0, n, 1, 2).selectExpr("id % 3 as key2", "id as value2") df2: org.apache.spark.sql.DataFrame = [key2: bigint, value2: bigint] scala> val df3 = spark.range(0, n, 1, 3).selectExpr("id % 4 as key3", "id as value3") df3: org.apache.spark.sql.DataFrame = [key3: bigint, value3: bigint] scala> val joined = df1.join(df2, col("key1") === col("key2")).join(df3, col("key1") === col("key3")) joined: org.apache.spark.sql.DataFrame = [key1: bigint, value1: bigint ... 4 more fields] scala> val unioned = joined.select(col("key1"), col("value3")).union(joined.select(col("key1"), col("value2"))) unioned: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [key1: bigint, value3: bigint] scala> unioned.queryExecution.optimizedPlan.maxRows res32: Option[Long] = Some(-2446744073709551616) scala> unioned.queryExecution.optimizedPlan.maxRows res33: Option[Long] = Some(-2446744073709551616) ``` No added testsuite Closes #35609 from zhengruifeng/union_maxRows_validate. Authored-by: Ruifeng Zheng <ruifengz@foxmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 683bc46ff9a791ab6b9cd3cb95be6bbc368121e0) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 24 February 2022, 02:54:42 UTC |
| 679a7e1 | itholic | 22 February 2022, 07:41:16 UTC | [SPARK-38279][TESTS][3.2] Pin MarkupSafe to 2.0.1 fix linter failure This PR proposes to pin the Python package `markupsafe` to 2.0.1 to fix the CI failure as below. ``` ImportError: cannot import name 'soft_unicode' from 'markupsafe' (/home/runner/work/_temp/setup-sam-43osIE/.venv/lib/python3.10/site-packages/markupsafe/__init__.py) ``` Since `markupsafe==2.1.0` has removed `soft_unicode`, `from markupsafe import soft_unicode` no longer working properly. See https://github.com/aws/aws-sam-cli/issues/3661 for more detail. To fix the CI failure on branch-3.2 No. The existing tests are should be passed Closes #35602 from itholic/SPARK-38279. Authored-by: itholic <haejoon.lee@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 79099cf7baf6e094884b5f77e82a4915272f15c5) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 22 February 2022, 07:48:49 UTC |
| 32e7e7b | Itay Bittan | 20 February 2022, 02:51:53 UTC | [MINOR][DOCS] fix default value of history server ### What changes were proposed in this pull request? Alignment between the documentation and the code. ### Why are the changes needed? The [actual default value ](https://github.com/apache/spark/blame/master/core/src/main/scala/org/apache/spark/internal/config/History.scala#L198) for `spark.history.custom.executor.log.url.applyIncompleteApplication` is `true` and not `false` as stated in the documentation. ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? Closes #35577 from itayB/doc. Authored-by: Itay Bittan <itay.bittan@gmail.com> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit ae67adde4d2dc0a75e03710fc3e66ea253feeda3) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 20 February 2022, 02:53:48 UTC |
| bbbcb66 | Karthik Subramanian | 18 February 2022, 03:52:11 UTC | [MINOR][DOC] Fix documentation for structured streaming - addListener ### What changes were proposed in this pull request? This PR fixes the incorrect documentation in Structured Streaming Guide where it says `sparkSession.streams.attachListener()` instead of `sparkSession.streams.addListener()` which is the correct usage as mentioned in the code snippet below in the same doc. 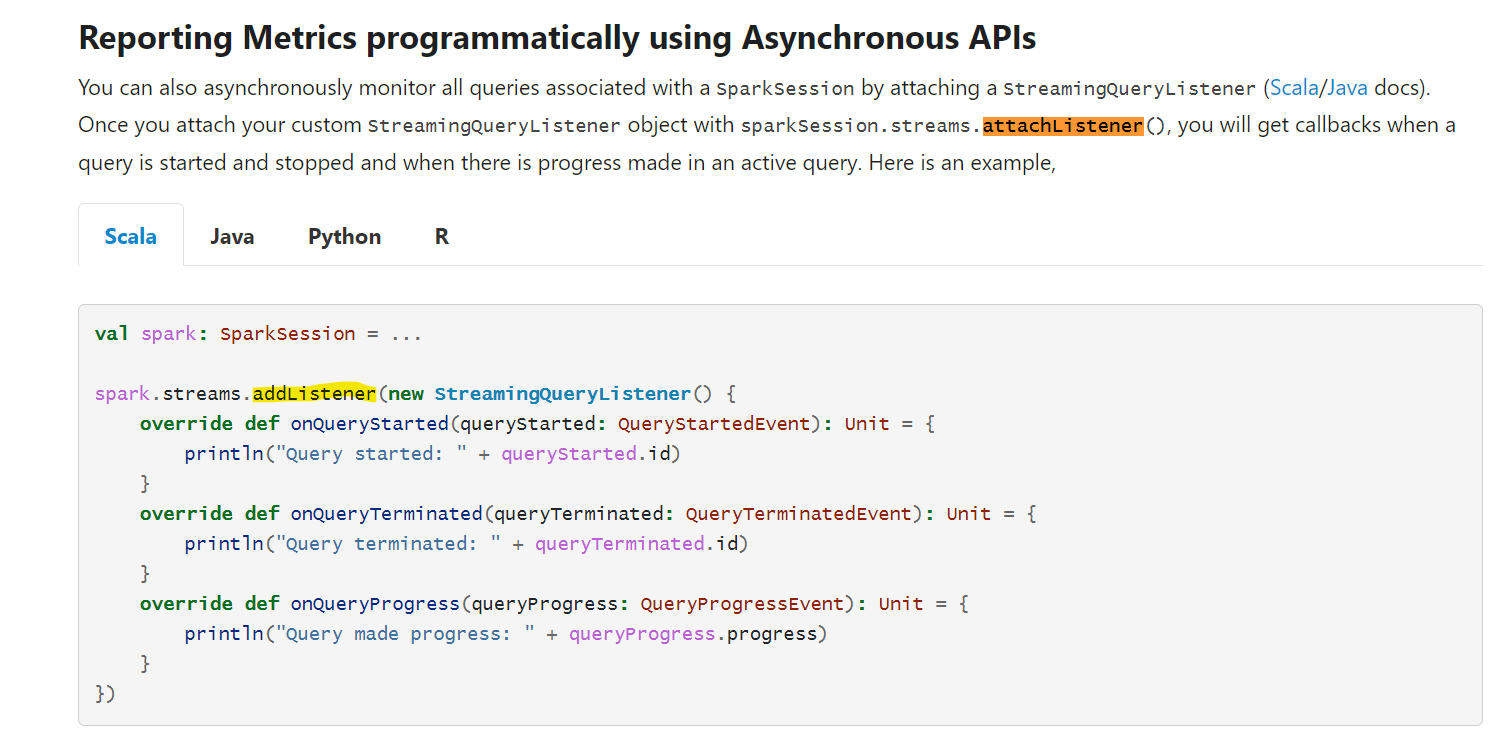 ### Why are the changes needed? The documentation was erroneous, and needs to be fixed to avoid confusion by readers ### Does this PR introduce _any_ user-facing change? Yes, since it's a doc fix. This fix needs to be applied to previous versions retro-actively as well. ### How was this patch tested? Not necessary Closes #35562 from yeskarthik/fix-structured-streaming-docs-1. Authored-by: Karthik Subramanian <karsubr@microsoft.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 837248a0c42d55ad48240647d503ad544e64f016) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 18 February 2022, 03:53:55 UTC |
| 3945792 | tianlzhang | 15 February 2022, 03:52:37 UTC | [SPARK-38211][SQL][DOCS] Add SQL migration guide on restoring loose upcast from string to other types ### What changes were proposed in this pull request? Add doc on restoring loose upcast from string to other types (behavior before 2.4.1) to SQL migration guide. ### Why are the changes needed? After [SPARK-24586](https://issues.apache.org/jira/browse/SPARK-24586), loose upcasting from string to other types are not allowed by default. User can still set `spark.sql.legacy.looseUpcast=true` to restore old behavior but it's not documented. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Only doc change. Closes #35519 from manuzhang/spark-38211. Authored-by: tianlzhang <tianlzhang@ebay.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 78514e3149bc43b2485e4be0ab982601a842600b) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 15 February 2022, 03:53:20 UTC |
| 755d11d | stczwd | 11 January 2022, 06:23:12 UTC | [SPARK-37860][UI] Fix taskindex in the stage page task event timeline ### What changes were proposed in this pull request? This reverts commit 450b415028c3b00f3a002126cd11318d3932e28f. ### Why are the changes needed? In #32888, shahidki31 change taskInfo.index to taskInfo.taskId. However, we generally use `index.attempt` or `taskId` to distinguish tasks within a stage, not `taskId.attempt`. Thus #32888 was a wrong fix issue, we should revert it. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? origin test suites Closes #35160 from stczwd/SPARK-37860. Authored-by: stczwd <qcsd2011@163.com> Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com> (cherry picked from commit 3d2fde5242c8989688c176b8ed5eb0bff5e1f17f) Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com> | 11 January 2022, 06:24:11 UTC |
| 2fbf969 | Hyukjin Kwon | 05 January 2022, 08:51:30 UTC | Revert "[SPARK-37779][SQL] Make ColumnarToRowExec plan canonicalizable after (de)serialization" This reverts commit 8ab7cd3ca7e828e114218ae811a9afebb5c9bcc7. | 05 January 2022, 08:51:30 UTC |
| be441e8 | yi.wu | 05 January 2022, 02:48:16 UTC | [SPARK-35714][FOLLOW-UP][CORE] WorkerWatcher should run System.exit in a thread out of RpcEnv ### What changes were proposed in this pull request? This PR proposes to let `WorkerWatcher` run `System.exit` in a separate thread instead of some thread of `RpcEnv`. ### Why are the changes needed? `System.exit` will trigger the shutdown hook to run `executor.stop`, which will result in the same deadlock issue with SPARK-14180. But note that since Spark upgrades to Hadoop 3 recently, each hook now will have a [timeout threshold](https://github.com/apache/hadoop/blob/d4794dd3b2ba365a9d95ad6aafcf43a1ea40f777/hadoop-common-project/hadoop-common/src/main/java/org/apache/hadoop/util/ShutdownHookManager.java#L205-L209) which forcibly interrupt the hook execution once reaches timeout. So, the deadlock issue doesn't really exist in the master branch. However, it's still critical for previous releases and is a wrong behavior that should be fixed. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Tested manually. Closes #35069 from Ngone51/fix-workerwatcher-exit. Authored-by: yi.wu <yi.wu@databricks.com> Signed-off-by: yi.wu <yi.wu@databricks.com> (cherry picked from commit 639d6f40e597d79c680084376ece87e40f4d2366) Signed-off-by: yi.wu <yi.wu@databricks.com> | 05 January 2022, 02:49:51 UTC |
| 3aaf722 | Josh Rosen | 04 January 2022, 18:59:53 UTC | [SPARK-37784][SQL] Correctly handle UDTs in CodeGenerator.addBufferedState() ### What changes were proposed in this pull request? This PR fixes a correctness issue in the CodeGenerator.addBufferedState() helper method (which is used by the SortMergeJoinExec operator). The addBufferedState() method generates code for buffering values that come from a row in an operator's input iterator, performing any necessary copying so that the buffered values remain correct after the input iterator advances to the next row. The current logic does not correctly handle UDTs: these fall through to the match statement's default branch, causing UDT values to be buffered without copying. This is problematic if the UDT's underlying SQL type is an array, map, struct, or string type (since those types require copying). Failing to copy values can lead to correctness issues or crashes. This patch's fix is simple: when the dataType is a UDT, use its underlying sqlType for determining whether values need to be copied. I used an existing helper function to perform this type unwrapping. ### Why are the changes needed? Fix a correctness issue. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? I manually tested this change by re-running a workload which failed with a segfault prior to this patch. See JIRA for more details: https://issues.apache.org/jira/browse/SPARK-37784 So far I have been unable to come up with a CI-runnable regression test which would have failed prior to this change (my only working reproduction runs in a pre-production environment and does not fail in my development environment). Closes #35066 from JoshRosen/SPARK-37784. Authored-by: Josh Rosen <joshrosen@databricks.com> Signed-off-by: Josh Rosen <joshrosen@databricks.com> (cherry picked from commit eeef48fac412a57382b02ba3f39456d96379b5f5) Signed-off-by: Josh Rosen <joshrosen@databricks.com> | 04 January 2022, 19:03:20 UTC |
| 8ab7cd3 | Hyukjin Kwon | 30 December 2021, 03:38:37 UTC | [SPARK-37779][SQL] Make ColumnarToRowExec plan canonicalizable after (de)serialization This PR proposes to add a driver-side check on `supportsColumnar` sanity check at `ColumnarToRowExec`. SPARK-23731 fixed the plans to be serializable by leveraging lazy but SPARK-28213 happened to refer to the lazy variable at: https://github.com/apache/spark/blob/77b164aac9764049a4820064421ef82ec0bc14fb/sql/core/src/main/scala/org/apache/spark/sql/execution/Columnar.scala#L68 This can fail during canonicalization during, for example, eliminating sub common expressions (on executor side): ``` java.lang.NullPointerException at org.apache.spark.sql.execution.FileSourceScanExec.supportsColumnar$lzycompute(DataSourceScanExec.scala:280) at org.apache.spark.sql.execution.FileSourceScanExec.supportsColumnar(DataSourceScanExec.scala:279) at org.apache.spark.sql.execution.InputAdapter.supportsColumnar(WholeStageCodegenExec.scala:509) at org.apache.spark.sql.execution.ColumnarToRowExec.<init>(Columnar.scala:67) ... at org.apache.spark.sql.catalyst.plans.QueryPlan.canonicalized$lzycompute(QueryPlan.scala:581) at org.apache.spark.sql.catalyst.plans.QueryPlan.canonicalized(QueryPlan.scala:580) at org.apache.spark.sql.execution.ScalarSubquery.canonicalized$lzycompute(subquery.scala:110) ... at org.apache.spark.sql.catalyst.expressions.ExpressionEquals.hashCode(EquivalentExpressions.scala:275) ... at scala.collection.mutable.HashTable.findEntry$(HashTable.scala:135) at scala.collection.mutable.HashMap.findEntry(HashMap.scala:44) at scala.collection.mutable.HashMap.get(HashMap.scala:74) at org.apache.spark.sql.catalyst.expressions.EquivalentExpressions.addExpr(EquivalentExpressions.scala:46) at org.apache.spark.sql.catalyst.expressions.EquivalentExpressions.addExprTreeHelper$1(EquivalentExpressions.scala:147) at org.apache.spark.sql.catalyst.expressions.EquivalentExpressions.addExprTree(EquivalentExpressions.scala:170) at org.apache.spark.sql.catalyst.expressions.SubExprEvaluationRuntime.$anonfun$proxyExpressions$1(SubExprEvaluationRuntime.scala:89) at org.apache.spark.sql.catalyst.expressions.SubExprEvaluationRuntime.$anonfun$proxyExpressions$1$adapted(SubExprEvaluationRuntime.scala:89) at scala.collection.immutable.List.foreach(List.scala:392) ``` This fix is still a bandaid fix but at least addresses the issue with minimized change - this fix should ideally be backported too. Pretty unlikely - when `ColumnarToRowExec` has to be canonicalized on the executor side (see the stacktrace), but yes. it would fix a bug. Unittest was added. Closes #35058 from HyukjinKwon/SPARK-37779. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 195f1aaf4361fb8f5f31ef7f5c63464767ad88bd) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 30 December 2021, 03:42:24 UTC |
| 85a8f70 | Alex Ott | 19 December 2021, 08:02:40 UTC | [MINOR][PYTHON][DOCS] Fix documentation for Python's recentProgress & lastProgress This small PR fixes incorrect documentation in Structured Streaming Guide where Python's `recentProgress` & `lastProgress` where shown as functions although they are [properties](https://github.com/apache/spark/blob/master/python/pyspark/sql/streaming.py#L117), so if they are called as functions it generates error: ``` >>> query.lastProgress() Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'dict' object is not callable ``` The documentation was erroneous, and needs to be fixed to avoid confusion by readers yes, it's a fix of the documentation Not necessary Closes #34947 from alexott/fix-python-recent-progress-docs. Authored-by: Alex Ott <alexott@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit bad96e6d029dff5be9efaf99f388cd9436741b6f) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 19 December 2021, 08:04:03 UTC |
| 113f750 | Daniel Dai | 07 December 2021, 14:48:23 UTC | [SPARK-37556][SQL] Deser void class fail with Java serialization **What changes were proposed in this pull request?** Change the deserialization mapping for primitive type void. **Why are the changes needed?** The void primitive type in Scala should be classOf[Unit] not classOf[Void]. Spark erroneously [map it](https://github.com/apache/spark/blob/v3.2.0/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala#L80) differently than all other primitive types. Here is the code: ``` private object JavaDeserializationStream { val primitiveMappings = Map[String, Class[_]]( "boolean" -> classOf[Boolean], "byte" -> classOf[Byte], "char" -> classOf[Char], "short" -> classOf[Short], "int" -> classOf[Int], "long" -> classOf[Long], "float" -> classOf[Float], "double" -> classOf[Double], "void" -> classOf[Void] ) } ``` Spark code is Here is the demonstration: ``` scala> classOf[Long] val res0: Class[Long] = long scala> classOf[Double] val res1: Class[Double] = double scala> classOf[Byte] val res2: Class[Byte] = byte scala> classOf[Void] val res3: Class[Void] = class java.lang.Void <--- this is wrong scala> classOf[Unit] val res4: Class[Unit] = void <---- this is right ``` It will result in Spark deserialization error if the Spark code contains void primitive type: `java.io.InvalidClassException: java.lang.Void; local class name incompatible with stream class name "void"` **Does this PR introduce any user-facing change?** no **How was this patch tested?** Changed test, also tested e2e with the code results deserialization error and it pass now. Closes #34816 from daijyc/voidtype. Authored-by: Daniel Dai <jdai@pinterest.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit fb40c0e19f84f2de9a3d69d809e9e4031f76ef90) Signed-off-by: Sean Owen <srowen@gmail.com> | 07 December 2021, 15:30:57 UTC |
| 8fb3e39 | weixiuli | 03 December 2021, 03:34:36 UTC | [SPARK-37524][SQL] We should drop all tables after testing dynamic partition pruning ### What changes were proposed in this pull request? Drop all tables after testing dynamic partition pruning. ### Why are the changes needed? We should drop all tables after testing dynamic partition pruning. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Exist unittests Closes #34768 from weixiuli/SPARK-11150-fix. Authored-by: weixiuli <weixiuli@jd.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 2433c942ca39b948efe804aeab0185a3f37f3eea) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 03 December 2021, 03:35:30 UTC |
| 7ba340c | yangjie01 | 22 November 2021, 01:11:40 UTC | [SPARK-37209][YARN][TESTS] Fix `YarnShuffleIntegrationSuite` releated UTs when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars` ### What changes were proposed in this pull request? `YarnShuffleIntegrationSuite`, `YarnShuffleAuthSuite` and `YarnShuffleAlternateNameConfigSuite` will failed when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars`, the fail reason is `java.lang.NoClassDefFoundError: breeze/linalg/Matrix`. The above UTS can succeed when using `hadoop-2.7` profile without `assembly/target/scala-%s/jars` because `KryoSerializer.loadableSparkClasses` can workaroud when `Utils.isTesting` is true, but `Utils.isTesting` is false when using `hadoop-3.2` profile. After investigated, I found that when `hadoop-2.7` profile is used, `SPARK_TESTING` will be propagated to AM and Executor, but when `hadoop-3.2` profile is used, `SPARK_TESTING` will not be propagated to AM and Executor. In order to ensure the consistent behavior of using `hadoop-2.7` and ``hadoop-3.2``, this pr change to manually propagate `SPARK_TESTING` environment variable if it exists to ensure `Utils.isTesting` is true in above test scenario. ### Why are the changes needed? Ensure `YarnShuffleIntegrationSuite` releated UTs can succeed when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass the Jenkins or GitHub Action - Manual test `YarnShuffleIntegrationSuite`. `YarnShuffleAuthSuite` and `YarnShuffleAlternateNameConfigSuite` can be verified in the same way. Please ensure that the `assembly/target/scala-%s/jars` directory does not exist before executing the test command, we can clean up the whole project by executing follow command or clone a new local code repo. 1. run with `hadoop-3.2` profile ``` mvn clean install -Phadoop-3.2 -Pyarn -Dtest=none -DwildcardSuites=org.apache.spark.deploy.yarn.YarnShuffleIntegrationSuite ``` **Before** ``` YarnShuffleIntegrationSuite: - external shuffle service *** FAILED *** FAILED did not equal FINISHED (stdout/stderr was not captured) (BaseYarnClusterSuite.scala:227) Run completed in 48 seconds, 137 milliseconds. Total number of tests run: 1 Suites: completed 2, aborted 0 Tests: succeeded 0, failed 1, canceled 0, ignored 0, pending 0 *** 1 TEST FAILED *** ``` Error stack as follows: ``` 21/11/20 23:00:09.682 main ERROR Client: Application diagnostics message: User class threw exception: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 6) (localhost executor 1): java.lang.NoClassDefFoundError: breeze/linalg/Matrix at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:348) at org.apache.spark.util.Utils$.classForName(Utils.scala:216) at org.apache.spark.serializer.KryoSerializer$.$anonfun$loadableSparkClasses$1(KryoSerializer.scala:537) at scala.collection.immutable.List.flatMap(List.scala:366) at org.apache.spark.serializer.KryoSerializer$.loadableSparkClasses$lzycompute(KryoSerializer.scala:535) at org.apache.spark.serializer.KryoSerializer$.org$apache$spark$serializer$KryoSerializer$$loadableSparkClasses(KryoSerializer.scala:502) at org.apache.spark.serializer.KryoSerializer.newKryo(KryoSerializer.scala:226) at org.apache.spark.serializer.KryoSerializer$$anon$1.create(KryoSerializer.scala:102) at com.esotericsoftware.kryo.pool.KryoPoolQueueImpl.borrow(KryoPoolQueueImpl.java:48) at org.apache.spark.serializer.KryoSerializer$PoolWrapper.borrow(KryoSerializer.scala:109) at org.apache.spark.serializer.KryoSerializerInstance.borrowKryo(KryoSerializer.scala:346) at org.apache.spark.serializer.KryoSerializationStream.<init>(KryoSerializer.scala:266) at org.apache.spark.serializer.KryoSerializerInstance.serializeStream(KryoSerializer.scala:432) at org.apache.spark.shuffle.ShufflePartitionPairsWriter.open(ShufflePartitionPairsWriter.scala:76) at org.apache.spark.shuffle.ShufflePartitionPairsWriter.write(ShufflePartitionPairsWriter.scala:59) at org.apache.spark.util.collection.WritablePartitionedIterator.writeNext(WritablePartitionedPairCollection.scala:83) at org.apache.spark.util.collection.ExternalSorter.$anonfun$writePartitionedMapOutput$1(ExternalSorter.scala:772) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1468) at org.apache.spark.util.collection.ExternalSorter.writePartitionedMapOutput(ExternalSorter.scala:775) at org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:70) at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52) at org.apache.spark.scheduler.Task.run(Task.scala:136) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:507) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1468) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:510) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.lang.ClassNotFoundException: breeze.linalg.Matrix at java.net.URLClassLoader.findClass(URLClassLoader.java:382) at java.lang.ClassLoader.loadClass(ClassLoader.java:419) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352) at java.lang.ClassLoader.loadClass(ClassLoader.java:352) ... 32 more ``` **After** ``` YarnShuffleIntegrationSuite: - external shuffle service Run completed in 35 seconds, 188 milliseconds. Total number of tests run: 1 Suites: completed 2, aborted 0 Tests: succeeded 1, failed 0, canceled 0, ignored 0, pending 0 All tests passed. ``` 2. run with `hadoop-2.7` profile ``` mvn clean install -Phadoop-2.7 -Pyarn -Dtest=none -DwildcardSuites=org.apache.spark.deploy.yarn.YarnShuffleIntegrationSuite ``` **Before** ``` YarnShuffleIntegrationSuite: - external shuffle service Run completed in 30 seconds, 828 milliseconds. Total number of tests run: 1 Suites: completed 2, aborted 0 Tests: succeeded 1, failed 0, canceled 0, ignored 0, pending 0 All tests passed. ``` **After** ``` YarnShuffleIntegrationSuite: - external shuffle service Run completed in 30 seconds, 967 milliseconds. Total number of tests run: 1 Suites: completed 2, aborted 0 Tests: succeeded 1, failed 0, canceled 0, ignored 0, pending 0 All tests passed. ``` Closes #34620 from LuciferYang/SPARK-37209. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit a7b3fc7cef4c5df0254b945fe9f6815b072b31dd) Signed-off-by: Sean Owen <srowen@gmail.com> | 22 November 2021, 01:12:25 UTC |
| 45c84ca | zero323 | 19 November 2021, 00:47:17 UTC | [MINOR][R][DOCS] Fix minor issues in SparkR docs examples ### What changes were proposed in this pull request? This PR fixes two minor problems in SpakR `examples` - Replace misplaced standard comment (`#`) with roxygen comment (`#'`) in `sparkR.session` `examples` - Add missing comma in `write.stream` examples. ### Why are the changes needed? - `sparkR.session` examples are not fully rendered. - `write.stream` example is not syntactically valid. ### Does this PR introduce _any_ user-facing change? Docs only. ### How was this patch tested? Manual inspection of build docs. Closes #34654 from zero323/sparkr-docs-fixes. Authored-by: zero323 <mszymkiewicz@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 207dd4ce72a5566c554f224edb046106cf97b952) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 19 November 2021, 00:48:10 UTC |
| aa4ef0e | Angerszhuuuu | 08 November 2021, 20:08:32 UTC | [SPARK-37196][SQL] HiveDecimal enforcePrecisionScale failed return null For case ``` withTempDir { dir => withSQLConf(HiveUtils.CONVERT_METASTORE_PARQUET.key -> "false") { withTable("test_precision") { val df = sql("SELECT 'dummy' AS name, 1000000000000000000010.7000000000000010 AS value") df.write.mode("Overwrite").parquet(dir.getAbsolutePath) sql( s""" |CREATE EXTERNAL TABLE test_precision(name STRING, value DECIMAL(18,6)) |STORED AS PARQUET LOCATION '${dir.getAbsolutePath}' |""".stripMargin) checkAnswer(sql("SELECT * FROM test_precision"), Row("dummy", null)) } } } ``` We write a data with schema It's caused by you create a df with ``` root |-- name: string (nullable = false) |-- value: decimal(38,16) (nullable = false) ``` but create table schema ``` root |-- name: string (nullable = false) |-- value: decimal(18,6) (nullable = false) ``` This will cause enforcePrecisionScale return `null` ``` public HiveDecimal getPrimitiveJavaObject(Object o) { return o == null ? null : this.enforcePrecisionScale(((HiveDecimalWritable)o).getHiveDecimal()); } ``` Then throw NPE when call `toCatalystDecimal ` We should judge if the return value is `null` to avoid throw NPE Fix bug No Added UT Closes #34519 from AngersZhuuuu/SPARK-37196. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit a4f8ffbbfb0158a03ff52f1ed0dde75241c3a90e) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 08 November 2021, 20:20:53 UTC |
| 615e525 | mans2singh | 02 November 2021, 02:01:57 UTC | [MINOR][DOCS] Corrected spacing in structured streaming programming ### What changes were proposed in this pull request? There is no space between `with` and `<code>` as shown below: `... configured with<code>spark.sql.streaming.fileSource.cleaner.numThreads</code> ...` ### Why are the changes needed? Added space ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Only documentation was changed and no code was change. Closes #34458 from mans2singh/structured_streaming_programming_guide_space. Authored-by: mans2singh <mans2singh@yahoo.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 675071a38e47dc2c55cf4f71de7ad0bebc1b4f2b) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 02 November 2021, 02:03:09 UTC |
| 2186295 | ulysses-you | 26 October 2021, 20:29:15 UTC | [SPARK-37098][SQL][3.0] Alter table properties should invalidate cache This PR backport https://github.com/apache/spark/pull/34365 to branch-3.0 ### What changes were proposed in this pull request? Invalidate the table cache after alter table properties (set and unset). ### Why are the changes needed? The table properties can change the behavior of wriing. e.g. the parquet table with `parquet.compression`. If you execute the following SQL, we will get the file with snappy compression rather than zstd. ``` CREATE TABLE t (c int) STORED AS PARQUET; // cache table metadata SELECT * FROM t; ALTER TABLE t SET TBLPROPERTIES('parquet.compression'='zstd'); INSERT INTO TABLE t values(1); ``` So we should invalidate the table cache after alter table properties. ### Does this PR introduce _any_ user-facing change? yes, bug fix ### How was this patch tested? Add test Closes #34379 from ulysses-you/SPARK-37098-3.0. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 26 October 2021, 20:29:15 UTC |
| 1709265 | Josh Rosen | 14 October 2021, 21:34:24 UTC | [SPARK-23626][CORE] Eagerly compute RDD.partitions on entire DAG when submitting job to DAGScheduler ### What changes were proposed in this pull request? This PR fixes a longstanding issue where the `DAGScheduler'`s single-threaded event processing loop could become blocked by slow `RDD.getPartitions()` calls, preventing other events (like task completions and concurrent job submissions) from being processed in a timely manner. With this patch's change, Spark will now call `.partitions` on every RDD in the DAG before submitting a job to the scheduler, ensuring that the expensive `getPartitions()` calls occur outside of the scheduler event loop. #### Background The `RDD.partitions` method lazily computes an RDD's partitions by calling `RDD.getPartitions()`. The `getPartitions()` method is invoked only once per RDD and its result is cached in the `RDD.partitions_` private field. Sometimes the `getPartitions()` call can be expensive: for example, `HadoopRDD.getPartitions()` performs file listing operations. The `.partitions` method is invoked at many different places in Spark's code, including many existing call sites that are outside of the scheduler event loop. As a result, it's _often_ the case that an RDD's partitions will have been computed before the RDD is submitted to the DAGScheduler. For example, [`submitJob` calls `rdd.partitions.length`](https://github.com/apache/spark/blob/3ba57f5edc5594ee676249cd309b8f0d8248462e/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala#L837), so the DAG root's partitions will be computed outside of the scheduler event loop. However, there's still some cases where `partitions` gets evaluated for the first time inside of the `DAGScheduler` internals. For example, [`ShuffledRDD.getPartitions`](https://github.com/apache/spark/blob/3ba57f5edc5594ee676249cd309b8f0d8248462e/core/src/main/scala/org/apache/spark/rdd/ShuffledRDD.scala#L92-L94) doesn't call `.partitions` on the RDD being shuffled, so a plan with a ShuffledRDD at the root won't necessarily result in `.partitions` having been called on all RDDs prior to scheduler job submission. #### Correctness: proving that we make no excess `.partitions` calls This PR adds code to traverse the DAG prior to job submission and call `.partitions` on every RDD encountered. I'd like to argue that this results in no _excess_ `.partitions` calls: in every case where the new code calls `.partitions` there is existing code which would have called `.partitions` at some point during a successful job execution: - Assume that this is the first time we are computing every RDD in the DAG. - Every RDD appears in some stage. - [`submitStage` will call `submitMissingTasks`](https://github.com/databricks/runtime/blob/1e83dfe4f685bad7f260621e77282b1b4cf9bca4/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala#L1438) on every stage root RDD. - [`submitStage` calls `getPreferredLocsInternal`](https://github.com/databricks/runtime/blob/1e83dfe4f685bad7f260621e77282b1b4cf9bca4/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala#L1687-L1696) on every stage root RDD. - [`getPreferredLocsInternal`](https://github.com/databricks/runtime/blob/1e83dfe4f685bad7f260621e77282b1b4cf9bca4/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala#L2995-L3043) visits the RDD and all of its parents RDDs that are computed in the same stage (via narrow dependencies) and calls `.partitions` on each RDD visited. - Therefore `.partitions` is invoked on every RDD in the DAG by the time the job has successfully completed. - Therefore this patch's change does not introduce any new calls to `.partitions` which would not have otherwise occurred (assuming the job succeeded). #### Ordering of `.partitions` calls I don't think the order in which `.partitions` calls occur matters for correctness: the DAGScheduler happens to invoke `.partitions` in a particular order today (defined by the DAG traversal order in internal scheduler methods), but there's many lots of out-of-order `.partition` calls occurring elsewhere in the codebase. #### Handling of exceptions in `.partitions` I've chosen **not** to add special error-handling for the new `.partitions` calls: if exceptions occur then they'll bubble up, unwrapped, to the user code submitting the Spark job. It's sometimes important to preserve exception wrapping behavior, but I don't think that concern is warranted in this particular case: whether `getPartitions` occurred inside or outside of the scheduler (impacting whether exceptions manifest in wrapped or unwrapped form, and impacting whether failed jobs appear in the Spark UI) was not crisply defined (and in some rare cases could even be [influenced by Spark settings in non-obvious ways](https://github.com/apache/spark/blob/10d5303174bf4a47508f6227bbdb1eaf4c92fcdb/core/src/main/scala/org/apache/spark/Partitioner.scala#L75-L79)), so I think it's both unlikely that users were relying on the old behavior and very difficult to preserve it. #### Should this have a configuration flag? Per discussion from a previous PR trying to solve this problem (https://github.com/apache/spark/pull/24438#pullrequestreview-232692586), I've decided to skip adding a configuration flag for this. ### Why are the changes needed? This fixes a longstanding scheduler performance problem which has been reported by multiple users. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? I added a regression test in `BasicSchedulerIntegrationSuite` to cover the regular job submission codepath (`DAGScheduler.submitJob`)This test uses CountDownLatches to simulate the submission of a job containing an RDD with a slow `getPartitions()` call and checks that a concurrently-submitted job is not blocked. I have **not** added separate integration tests for the `runApproximateJob` and `submitMapStage` codepaths (both of which also received the same fix). Closes #34265 from JoshRosen/SPARK-23626. Authored-by: Josh Rosen <joshrosen@databricks.com> Signed-off-by: Josh Rosen <joshrosen@databricks.com> (cherry picked from commit c4e975e175c01f67ece7ae492a79554ad1b44106) Signed-off-by: Josh Rosen <joshrosen@databricks.com> | 14 October 2021, 21:36:25 UTC |
| 86bf5d3 | ulysses-you | 14 October 2021, 07:00:01 UTC | [SPARK-36993][SQL][3.0] Fix json_tuple throw NPE if fields exist no foldable null value backport https://github.com/apache/spark/pull/34268 for branch-3.0 ### What changes were proposed in this pull request? Wrap `expr.eval(input)` with Option in `json_tuple`. ### Why are the changes needed? If json_tuple exists no foldable null field, Spark would throw NPE during eval field.toString. e.g. the query will fail with: ```SQL SELECT json_tuple('{"a":"1"}', if(c1 < 1, null, 'a')) FROM ( SELECT rand() AS c1 ); ``` ``` Caused by: java.lang.NullPointerException at org.apache.spark.sql.catalyst.expressions.JsonTuple.$anonfun$parseRow$2(jsonExpressions.scala:435) at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:286) at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62) at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49) at scala.collection.TraversableLike.map(TraversableLike.scala:286) at scala.collection.TraversableLike.map$(TraversableLike.scala:279) at scala.collection.AbstractTraversable.map(Traversable.scala:108) at org.apache.spark.sql.catalyst.expressions.JsonTuple.parseRow(jsonExpressions.scala:435) at org.apache.spark.sql.catalyst.expressions.JsonTuple.$anonfun$eval$6(jsonExpressions.scala:413) ``` ### Does this PR introduce _any_ user-facing change? yes, bug fix. ### How was this patch tested? add test in `json-functions.sql`. Closes #34279 from ulysses-you/SPARK-36993-3-0. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 14 October 2021, 07:00:01 UTC |
| 74fddec | daugraph | 08 October 2021, 12:11:26 UTC | [SPARK-36717][CORE] Incorrect order of variable initialization may lead incorrect behavior ### What changes were proposed in this pull request? Incorrect order of variable initialization may lead to incorrect behavior, related code: TorrentBroadcast.scala , TorrentBroadCast will get wrong checksumEnabled value after initialization, this may not be what we need, we can move L94 front of setConf(SparkEnv.get.conf) to avoid this. Supplement: Snippet 1 ```scala class Broadcast { def setConf(): Unit = { checksumEnabled = true } setConf() var checksumEnabled = false } println(new Broadcast().checksumEnabled) ``` output: ```scala false ``` Snippet 2 ```scala class Broadcast { var checksumEnabled = false def setConf(): Unit = { checksumEnabled = true } setConf() } println(new Broadcast().checksumEnabled) ``` output: ```scala true ``` ### Why are the changes needed? we can move L94 front of setConf(SparkEnv.get.conf) to avoid this. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? No Closes #33957 from daugraph/branch0. Authored-by: daugraph <daugraph@qq.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 65f6a7c1ecdcf7d6df798e30c9fc03a5dbe0b047) Signed-off-by: Sean Owen <srowen@gmail.com> | 08 October 2021, 12:12:02 UTC |
| d454d4e | tianhanhu | 06 October 2021, 10:06:09 UTC | [SPARK-36919][SQL] Make BadRecordException fields transient ### What changes were proposed in this pull request? Migrating a Spark application from 2.4.x to 3.1.x and finding a difference in the exception chaining behavior. In a case of parsing a malformed CSV, where the root cause exception should be Caused by: java.lang.RuntimeException: Malformed CSV record, only the top level exception is kept, and all lower level exceptions and root cause are lost. Thus, when we call ExceptionUtils.getRootCause on the exception, we still get itself. The reason for the difference is that RuntimeException is wrapped in BadRecordException, which has unserializable fields. When we try to serialize the exception from tasks and deserialize from scheduler, the exception is lost. This PR makes unserializable fields of BadRecordException transient, so the rest of the exception could be serialized and deserialized properly. ### Why are the changes needed? Make BadRecordException serializable ### Does this PR introduce _any_ user-facing change? User could get root cause of BadRecordException ### How was this patch tested? Unit testing Closes #34167 from tianhanhu/master. Authored-by: tianhanhu <adrianhu96@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit aed977c4682b6f378a26050ffab51b9b2075cae4) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 06 October 2021, 10:06:52 UTC |
| f8287e2 | Angerszhuuuu | 24 September 2021, 08:19:36 UTC | [SPARK-36792][SQL] InSet should handle NaN ### What changes were proposed in this pull request? InSet should handle NaN ``` InSet(Literal(Double.NaN), Set(Double.NaN, 1d)) should return true, but return false. ``` ### Why are the changes needed? InSet should handle NaN ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added UT Closes #34033 from AngersZhuuuu/SPARK-36792. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 64f4bf47af2412811ff2843cd363ce883a604ce7) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 24 September 2021, 08:20:30 UTC |
| f4d83b3 | jiaoqb | 23 September 2021, 03:47:38 UTC | [SPARK-36791][DOCS] Fix spelling mistakes in running-on-yarn.md file where JHS_POST should be JHS_HOST ### What changes were proposed in this pull request? The PR fixes SPARK-36791 by replacing JHS_POST with JHS_HOST ### Why are the changes needed? There are spelling mistakes in running-on-yarn.md file where JHS_POST should be JHS_HOST ### Does this PR introduce any user-facing change? No ### How was this patch tested? Not needed for docs Closes #34031 from jiaoqingbo/jiaoqingbo. Authored-by: jiaoqb <jiaoqb@asiainfo.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 8a1a91bd71218ef0eee9c4eac175134b62ba362a) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 23 September 2021, 03:48:46 UTC |
| 97aabe2 | Wenchen Fan | 22 September 2021, 16:32:50 UTC | [SPARK-33272][SPARK-36815][3.0][SQL] prune the attributes mapping in QueryPlan.transformUpWithNewOutput ### What changes were proposed in this pull request? This is a backport PR of #30173. For complex query plans, `QueryPlan.transformUpWithNewOutput` will keep accumulating the attributes mapping to be propagated, which may hurt performance. This PR prunes the attributes mapping before propagating. ### Why are the changes needed? A simple perf improvement. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? existing tests Closes #34068 from gaoyajun02/SPARK-33272. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 22 September 2021, 16:32:50 UTC |
| b96cbfb | Angerszhuuuu | 22 September 2021, 15:51:41 UTC | [SPARK-36753][SQL] ArrayExcept handle duplicated Double.NaN and Float.NaN ### What changes were proposed in this pull request? For query ``` select array_except(array(cast('nan' as double), 1d), array(cast('nan' as double))) ``` This returns [NaN, 1d], but it should return [1d]. This issue is caused by `OpenHashSet` can't handle `Double.NaN` and `Float.NaN` too. In this pr fix this based on https://github.com/apache/spark/pull/33955 ### Why are the changes needed? Fix bug ### Does this PR introduce _any_ user-facing change? ArrayExcept won't show handle equal `NaN` value ### How was this patch tested? Added UT Closes #33994 from AngersZhuuuu/SPARK-36753. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit a7cbe699863a6b68d27bdf3934dda7d396d80404) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 22 September 2021, 15:53:35 UTC |
| 41b5441 | Ivan Sadikov | 22 September 2021, 09:40:39 UTC | [SPARK-36803][SQL] Fix ArrayType conversion when reading Parquet files written in legacy mode ### What changes were proposed in this pull request? This PR fixes an issue when reading of a Parquet file written with legacy mode would fail due to incorrect Parquet LIST to ArrayType conversion. The issue arises when using schema evolution and utilising the parquet-mr reader. 2-level LIST annotated types could be parsed incorrectly as 3-level LIST annotated types because their underlying element type does not match the full inferred Catalyst schema. ### Why are the changes needed? It appears to be a long-standing issue with the legacy mode due to the imprecise check in ParquetRowConverter that was trying to determine Parquet backward compatibility using Catalyst schema: `DataType.equalsIgnoreCompatibleNullability(guessedElementType, elementType)` in https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetRowConverter.scala#L606. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added a new test case in ParquetInteroperabilitySuite.scala. Closes #34044 from sadikovi/parquet-legacy-write-mode-list-issue. Authored-by: Ivan Sadikov <ivan.sadikov@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit ec26d94eacb22562b8f5d60d12cf153d8ef3fd50) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 22 September 2021, 09:41:43 UTC |
| 016eeaf | Angerszhuuuu | 20 September 2021, 08:48:59 UTC | [SPARK-36754][SQL] ArrayIntersect handle duplicated Double.NaN and Float.NaN ### What changes were proposed in this pull request? For query ``` select array_intersect(array(cast('nan' as double), 1d), array(cast('nan' as double))) ``` This returns [NaN], but it should return []. This issue is caused by `OpenHashSet` can't handle `Double.NaN` and `Float.NaN` too. In this pr fix this based on https://github.com/apache/spark/pull/33955 ### Why are the changes needed? Fix bug ### Does this PR introduce _any_ user-facing change? ArrayIntersect won't show equal `NaN` value ### How was this patch tested? Added UT Closes #33995 from AngersZhuuuu/SPARK-36754. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 2fc7f2f702c6c08d9c76332f45e2902728ba2ee3) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 20 September 2021, 08:52:37 UTC |
| 026dd2f | Angerszhuuuu | 17 September 2021, 12:48:17 UTC | [SPARK-36741][SQL] ArrayDistinct handle duplicated Double.NaN and Float.Nan For query ``` select array_distinct(array(cast('nan' as double), cast('nan' as double))) ``` This returns [NaN, NaN], but it should return [NaN]. This issue is caused by `OpenHashSet` can't handle `Double.NaN` and `Float.NaN` too. In this pr fix this based on https://github.com/apache/spark/pull/33955 Fix bug ArrayDistinct won't show duplicated `NaN` value Added UT Closes #33993 from AngersZhuuuu/SPARK-36741. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit e356f6aa1119f4ceeafc7bcdea5f7b8f1f010638) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 17 September 2021, 12:52:13 UTC |
| 1b03949 | Wenchen Fan | 17 September 2021, 07:49:54 UTC | [SPARK-36789][SQL] Use the correct constant type as the null value holder in array functions In array functions, we use constant 0 as the placeholder when adding a null value to an array buffer. This PR makes sure the constant 0 matches the type of the array element. Fix a potential bug. Somehow we can hit this bug sometimes after https://github.com/apache/spark/pull/33955 . No existing tests Closes #34029 from cloud-fan/minor. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 4145498826f288e610b00033d9fc2063fd1acc9f) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 17 September 2021, 07:53:28 UTC |
| 24cdf7b | Wenchen Fan | 17 September 2021, 02:51:15 UTC | [SPARK-36783][SQL] ScanOperation should not push Filter through nondeterministic Project `ScanOperation` collects adjacent Projects and Filters. The caller side always assume that the collected Filters should run before collected Projects, which means `ScanOperation` effectively pushes Filter through Project. Following `PushPredicateThroughNonJoin`, we should not push Filter through nondeterministic Project. This PR fixes `ScanOperation` to follow this rule. Fix a bug that violates the semantic of nondeterministic expressions. Most likely no change, but in some cases, this is a correctness bug fix which changes the query result. existing tests Closes #34023 from cloud-fan/scan. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit dfd5237c0cd6e3024032b371f0182d2af691af7d) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 17 September 2021, 02:53:43 UTC |
| c0c121d | Angerszhuuuu | 15 September 2021, 14:31:46 UTC | [SPARK-36755][SQL] ArraysOverlap should handle duplicated Double.NaN and Float.NaN ### What changes were proposed in this pull request? For query ``` select arrays_overlap(array(cast('nan' as double), 1d), array(cast('nan' as double))) ``` This returns [false], but it should return [true]. This issue is caused by `scala.mutable.HashSet` can't handle `Double.NaN` and `Float.NaN`. ### Why are the changes needed? Fix bug ### Does this PR introduce _any_ user-facing change? arrays_overlap won't handle equal `NaN` value ### How was this patch tested? Added UT Closes #34006 from AngersZhuuuu/SPARK-36755. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 16 September 2021, 04:39:01 UTC |
| 46c5def | Angerszhuuuu | 16 September 2021, 04:37:02 UTC | [SPARK-36702][SQL][3.0] ArrayUnion handle duplicated Double.NaN and F… ### What changes were proposed in this pull request? For query ``` select array_union(array(cast('nan' as double), cast('nan' as double)), array()) ``` This returns [NaN, NaN], but it should return [NaN]. This issue is caused by `OpenHashSet` can't handle `Double.NaN` and `Float.NaN` too. In this pr we add a wrap for OpenHashSet that can handle `null`, `Double.NaN`, `Float.NaN` together ### Why are the changes needed? Fix bug ### Does this PR introduce _any_ user-facing change? ArrayUnion won't show duplicated `NaN` value ### How was this patch tested? Added UT Closes #34011 from AngersZhuuuu/SPARK-36702-3.0. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 16 September 2021, 04:37:02 UTC |
| 540937f | Yuto Akutsu | 13 September 2021, 12:51:29 UTC | [SPARK-36738][SQL][DOC] Fixed the wrong documentation on Cot API Fixed wrong documentation on Cot API [Doc](https://spark.apache.org/docs/latest/api/sql/index.html#cot) says `1/java.lang.Math.cot` but it should be `1/java.lang.Math.tan`. No. Manual check. Closes #33978 from yutoacts/SPARK-36738. Authored-by: Yuto Akutsu <yuto.akutsu@nttdata.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 3747cfdb402955cc19c9a383713b569fc010db70) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 13 September 2021, 12:52:49 UTC |
| 6b804c7 | yangjie01 | 12 September 2021, 14:57:06 UTC | [SPARK-36636][CORE][TEST] LocalSparkCluster change to use tmp workdir in test to avoid directory name collision ### What changes were proposed in this pull request? As described in SPARK-36636,if the test cases with config `local-cluster[n, c, m]` are run continuously within 1 second, the workdir name collision will occur because appid use format as `app-yyyyMMddHHmmss-0000` and workdir name associated with it in test now, the related logs are as follows: ``` java.io.IOException: Failed to create directory /spark-mine/work/app-20210908074432-0000/1 at org.apache.spark.deploy.worker.Worker$$anonfun$receive$1.applyOrElse(Worker.scala:578) at org.apache.spark.rpc.netty.Inbox.$anonfun$process$1(Inbox.scala:115) at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:213) at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100) at org.apache.spark.rpc.netty.MessageLoop.org$apache$spark$rpc$netty$MessageLoop$$receiveLoop(MessageLoop.scala:75) at org.apache.spark.rpc.netty.MessageLoop$$anon$1.run(MessageLoop.scala:41) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) 21/09/08 22:44:32.266 dispatcher-event-loop-0 INFO Worker: Asked to launch executor app-20210908074432-0000/0 for test 21/09/08 22:44:32.266 dispatcher-event-loop-0 ERROR Worker: Failed to launch executor app-20210908074432-0000/0 for test. java.io.IOException: Failed to create directory /spark-mine/work/app-20210908074432-0000/0 at org.apache.spark.deploy.worker.Worker$$anonfun$receive$1.applyOrElse(Worker.scala:578) at org.apache.spark.rpc.netty.Inbox.$anonfun$process$1(Inbox.scala:115) at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:213) at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100) at org.apache.spark.rpc.netty.MessageLoop.org$apache$spark$rpc$netty$MessageLoop$$receiveLoop(MessageLoop.scala:75) at org.apache.spark.rpc.netty.MessageLoop$$anon$1.run(MessageLoop.scala:41) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) ``` Since the default value of s`park.deploy.maxExecutorRetries` is 10, the test failed will occur when 5 consecutive cases with local-cluster[3, 1, 1024] are completed within 1 second: 1. case 1: use worker directories: `/app-202109102324-0000/0`, `/app-202109102324-0000/1`, `/app-202109102324-0000/2` 2. case 2: retry 3 times then use worker directories: `/app-202109102324-0000/3`, `/app-202109102324-0000/4`, `/app-202109102324-0000/5` 3. case 3: retry 6 times then use worker directories: `/app-202109102324-0000/6`, `/app-202109102324-0000/7`, `/app-202109102324-0000/8` 4. case 4: retry 9 times then use worker directories: `/app-202109102324-0000/9`, `/app-202109102324-0000/10`, `/app-202109102324-0000/11` 5. case 5: retry more than **10** times then **failed** To avoid this issue, this pr change to use tmp workdir in test with config `local-cluster[n, c, m]`. ### Why are the changes needed? Avoid UT failures caused by continuous workdir name collision. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass GA or Jenkins Tests. - Manual test: `build/mvn clean install -Pscala-2.13 -pl core -am` or `build/mvn clean install -pl core -am`, with Scala 2.13 is easier to reproduce this problem **Before** The test failed error logs as follows and randomness in test failure: ``` - SPARK-33084: Add jar support Ivy URI -- test exclude param when transitive=true *** FAILED *** org.apache.spark.SparkException: Only one SparkContext should be running in this JVM (see SPARK-2243).The currently running SparkContext was created at: org.apache.spark.SparkContextSuite.$anonfun$new$134(SparkContextSuite.scala:1101) org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85) org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83) org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104) org.scalatest.Transformer.apply(Transformer.scala:22) org.scalatest.Transformer.apply(Transformer.scala:20) org.scalatest.funsuite.AnyFunSuiteLike$$anon$1.apply(AnyFunSuiteLike.scala:226) org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:190) org.scalatest.funsuite.AnyFunSuiteLike.invokeWithFixture$1(AnyFunSuiteLike.scala:224) org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTest$1(AnyFunSuiteLike.scala:236) org.scalatest.SuperEngine.runTestImpl(Engine.scala:306) org.scalatest.funsuite.AnyFunSuiteLike.runTest(AnyFunSuiteLike.scala:236) org.scalatest.funsuite.AnyFunSuiteLike.runTest$(AnyFunSuiteLike.scala:218) org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterEach$$super$runTest(SparkFunSuite.scala:62) org.scalatest.BeforeAndAfterEach.runTest(BeforeAndAfterEach.scala:234) org.scalatest.BeforeAndAfterEach.runTest$(BeforeAndAfterEach.scala:227) org.apache.spark.SparkFunSuite.runTest(SparkFunSuite.scala:62) org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTests$1(AnyFunSuiteLike.scala:269) org.scalatest.SuperEngine.$anonfun$runTestsInBranch$1(Engine.scala:413) scala.collection.immutable.List.foreach(List.scala:333) at org.apache.spark.SparkContext$.$anonfun$assertNoOtherContextIsRunning$2(SparkContext.scala:2647) at scala.Option.foreach(Option.scala:437) at org.apache.spark.SparkContext$.assertNoOtherContextIsRunning(SparkContext.scala:2644) at org.apache.spark.SparkContext$.markPartiallyConstructed(SparkContext.scala:2734) at org.apache.spark.SparkContext.<init>(SparkContext.scala:95) at org.apache.spark.SparkContextSuite.$anonfun$new$138(SparkContextSuite.scala:1109) at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85) at org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83) at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104) at org.scalatest.Transformer.apply(Transformer.scala:22) ... - SPARK-33084: Add jar support Ivy URI -- test different version *** FAILED *** org.apache.spark.SparkException: Only one SparkContext should be running in this JVM (see SPARK-2243).The currently running SparkContext was created at: org.apache.spark.SparkContextSuite.$anonfun$new$134(SparkContextSuite.scala:1101) org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85) org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83) org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104) org.scalatest.Transformer.apply(Transformer.scala:22) org.scalatest.Transformer.apply(Transformer.scala:20) org.scalatest.funsuite.AnyFunSuiteLike$$anon$1.apply(AnyFunSuiteLike.scala:226) org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:190) org.scalatest.funsuite.AnyFunSuiteLike.invokeWithFixture$1(AnyFunSuiteLike.scala:224) org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTest$1(AnyFunSuiteLike.scala:236) org.scalatest.SuperEngine.runTestImpl(Engine.scala:306) org.scalatest.funsuite.AnyFunSuiteLike.runTest(AnyFunSuiteLike.scala:236) org.scalatest.funsuite.AnyFunSuiteLike.runTest$(AnyFunSuiteLike.scala:218) org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterEach$$super$runTest(SparkFunSuite.scala:62) org.scalatest.BeforeAndAfterEach.runTest(BeforeAndAfterEach.scala:234) org.scalatest.BeforeAndAfterEach.runTest$(BeforeAndAfterEach.scala:227) org.apache.spark.SparkFunSuite.runTest(SparkFunSuite.scala:62) org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTests$1(AnyFunSuiteLike.scala:269) org.scalatest.SuperEngine.$anonfun$runTestsInBranch$1(Engine.scala:413) scala.collection.immutable.List.foreach(List.scala:333) at org.apache.spark.SparkContext$.$anonfun$assertNoOtherContextIsRunning$2(SparkContext.scala:2647) at scala.Option.foreach(Option.scala:437) at org.apache.spark.SparkContext$.assertNoOtherContextIsRunning(SparkContext.scala:2644) at org.apache.spark.SparkContext$.markPartiallyConstructed(SparkContext.scala:2734) at org.apache.spark.SparkContext.<init>(SparkContext.scala:95) at org.apache.spark.SparkContextSuite.$anonfun$new$142(SparkContextSuite.scala:1118) at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85) at org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83) at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104) at org.scalatest.Transformer.apply(Transformer.scala:22) ... - SPARK-33084: Add jar support Ivy URI -- test invalid param *** FAILED *** org.apache.spark.SparkException: Only one SparkContext should be running in this JVM (see SPARK-2243).The currently running SparkContext was created at: org.apache.spark.SparkContextSuite.$anonfun$new$134(SparkContextSuite.scala:1101) org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85) org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83) org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104) org.scalatest.Transformer.apply(Transformer.scala:22) org.scalatest.Transformer.apply(Transformer.scala:20) org.scalatest.funsuite.AnyFunSuiteLike$$anon$1.apply(AnyFunSuiteLike.scala:226) org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:190) org.scalatest.funsuite.AnyFunSuiteLike.invokeWithFixture$1(AnyFunSuiteLike.scala:224) org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTest$1(AnyFunSuiteLike.scala:236) org.scalatest.SuperEngine.runTestImpl(Engine.scala:306) org.scalatest.funsuite.AnyFunSuiteLike.runTest(AnyFunSuiteLike.scala:236) org.scalatest.funsuite.AnyFunSuiteLike.runTest$(AnyFunSuiteLike.scala:218) org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterEach$$super$runTest(SparkFunSuite.scala:62) org.scalatest.BeforeAndAfterEach.runTest(BeforeAndAfterEach.scala:234) org.scalatest.BeforeAndAfterEach.runTest$(BeforeAndAfterEach.scala:227) org.apache.spark.SparkFunSuite.runTest(SparkFunSuite.scala:62) org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTests$1(AnyFunSuiteLike.scala:269) org.scalatest.SuperEngine.$anonfun$runTestsInBranch$1(Engine.scala:413) scala.collection.immutable.List.foreach(List.scala:333) at org.apache.spark.SparkContext$.$anonfun$assertNoOtherContextIsRunning$2(SparkContext.scala:2647) at scala.Option.foreach(Option.scala:437) at org.apache.spark.SparkContext$.assertNoOtherContextIsRunning(SparkContext.scala:2644) at org.apache.spark.SparkContext$.markPartiallyConstructed(SparkContext.scala:2734) at org.apache.spark.SparkContext.<init>(SparkContext.scala:95) at org.apache.spark.SparkContextSuite.$anonfun$new$146(SparkContextSuite.scala:1129) at org.apache.spark.SparkFunSuite.withLogAppender(SparkFunSuite.scala:235) at org.apache.spark.SparkContextSuite.$anonfun$new$145(SparkContextSuite.scala:1127) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.scala:18) at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85) ... - SPARK-33084: Add jar support Ivy URI -- test multiple transitive params *** FAILED *** org.apache.spark.SparkException: Only one SparkContext should be running in this JVM (see SPARK-2243).The currently running SparkContext was created at: org.apache.spark.SparkContextSuite.$anonfun$new$134(SparkContextSuite.scala:1101) org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85) org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83) org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104) org.scalatest.Transformer.apply(Transformer.scala:22) org.scalatest.Transformer.apply(Transformer.scala:20) org.scalatest.funsuite.AnyFunSuiteLike$$anon$1.apply(AnyFunSuiteLike.scala:226) org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:190) org.scalatest.funsuite.AnyFunSuiteLike.invokeWithFixture$1(AnyFunSuiteLike.scala:224) org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTest$1(AnyFunSuiteLike.scala:236) org.scalatest.SuperEngine.runTestImpl(Engine.scala:306) org.scalatest.funsuite.AnyFunSuiteLike.runTest(AnyFunSuiteLike.scala:236) org.scalatest.funsuite.AnyFunSuiteLike.runTest$(AnyFunSuiteLike.scala:218) org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterEach$$super$runTest(SparkFunSuite.scala:62) org.scalatest.BeforeAndAfterEach.runTest(BeforeAndAfterEach.scala:234) org.scalatest.BeforeAndAfterEach.runTest$(BeforeAndAfterEach.scala:227) org.apache.spark.SparkFunSuite.runTest(SparkFunSuite.scala:62) org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTests$1(AnyFunSuiteLike.scala:269) org.scalatest.SuperEngine.$anonfun$runTestsInBranch$1(Engine.scala:413) scala.collection.immutable.List.foreach(List.scala:333) at org.apache.spark.SparkContext$.$anonfun$assertNoOtherContextIsRunning$2(SparkContext.scala:2647) at scala.Option.foreach(Option.scala:437) at org.apache.spark.SparkContext$.assertNoOtherContextIsRunning(SparkContext.scala:2644) at org.apache.spark.SparkContext$.markPartiallyConstructed(SparkContext.scala:2734) at org.apache.spark.SparkContext.<init>(SparkContext.scala:95) at org.apache.spark.SparkContextSuite.$anonfun$new$149(SparkContextSuite.scala:1140) at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85) at org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83) at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104) at org.scalatest.Transformer.apply(Transformer.scala:22) ... - SPARK-33084: Add jar support Ivy URI -- test param key case sensitive *** FAILED *** org.apache.spark.SparkException: Only one SparkContext should be running in this JVM (see SPARK-2243).The currently running SparkContext was created at: org.apache.spark.SparkContextSuite.$anonfun$new$134(SparkContextSuite.scala:1101) org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85) org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83) org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104) org.scalatest.Transformer.apply(Transformer.scala:22) org.scalatest.Transformer.apply(Transformer.scala:20) org.scalatest.funsuite.AnyFunSuiteLike$$anon$1.apply(AnyFunSuiteLike.scala:226) org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:190) org.scalatest.funsuite.AnyFunSuiteLike.invokeWithFixture$1(AnyFunSuiteLike.scala:224) org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTest$1(AnyFunSuiteLike.scala:236) org.scalatest.SuperEngine.runTestImpl(Engine.scala:306) org.scalatest.funsuite.AnyFunSuiteLike.runTest(AnyFunSuiteLike.scala:236) org.scalatest.funsuite.AnyFunSuiteLike.runTest$(AnyFunSuiteLike.scala:218) org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterEach$$super$runTest(SparkFunSuite.scala:62) org.scalatest.BeforeAndAfterEach.runTest(BeforeAndAfterEach.scala:234) org.scalatest.BeforeAndAfterEach.runTest$(BeforeAndAfterEach.scala:227) org.apache.spark.SparkFunSuite.runTest(SparkFunSuite.scala:62) org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTests$1(AnyFunSuiteLike.scala:269) org.scalatest.SuperEngine.$anonfun$runTestsInBranch$1(Engine.scala:413) scala.collection.immutable.List.foreach(List.scala:333) at org.apache.spark.SparkContext$.$anonfun$assertNoOtherContextIsRunning$2(SparkContext.scala:2647) at scala.Option.foreach(Option.scala:437) at org.apache.spark.SparkContext$.assertNoOtherContextIsRunning(SparkContext.scala:2644) at org.apache.spark.SparkContext$.markPartiallyConstructed(SparkContext.scala:2734) at org.apache.spark.SparkContext.<init>(SparkContext.scala:95) at org.apache.spark.SparkContextSuite.$anonfun$new$154(SparkContextSuite.scala:1155) at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85) at org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83) at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104) at org.scalatest.Transformer.apply(Transformer.scala:22) ... - SPARK-33084: Add jar support Ivy URI -- test transitive value case insensitive *** FAILED *** org.apache.spark.SparkException: Only one SparkContext should be running in this JVM (see SPARK-2243).The currently running SparkContext was created at: org.apache.spark.SparkContextSuite.$anonfun$new$134(SparkContextSuite.scala:1101) org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85) org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83) org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104) org.scalatest.Transformer.apply(Transformer.scala:22) org.scalatest.Transformer.apply(Transformer.scala:20) org.scalatest.funsuite.AnyFunSuiteLike$$anon$1.apply(AnyFunSuiteLike.scala:226) org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:190) org.scalatest.funsuite.AnyFunSuiteLike.invokeWithFixture$1(AnyFunSuiteLike.scala:224) org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTest$1(AnyFunSuiteLike.scala:236) org.scalatest.SuperEngine.runTestImpl(Engine.scala:306) org.scalatest.funsuite.AnyFunSuiteLike.runTest(AnyFunSuiteLike.scala:236) org.scalatest.funsuite.AnyFunSuiteLike.runTest$(AnyFunSuiteLike.scala:218) org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterEach$$super$runTest(SparkFunSuite.scala:62) org.scalatest.BeforeAndAfterEach.runTest(BeforeAndAfterEach.scala:234) org.scalatest.BeforeAndAfterEach.runTest$(BeforeAndAfterEach.scala:227) org.apache.spark.SparkFunSuite.runTest(SparkFunSuite.scala:62) org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTests$1(AnyFunSuiteLike.scala:269) org.scalatest.SuperEngine.$anonfun$runTestsInBranch$1(Engine.scala:413) scala.collection.immutable.List.foreach(List.scala:333) at org.apache.spark.SparkContext$.$anonfun$assertNoOtherContextIsRunning$2(SparkContext.scala:2647) at scala.Option.foreach(Option.scala:437) at org.apache.spark.SparkContext$.assertNoOtherContextIsRunning(SparkContext.scala:2644) at org.apache.spark.SparkContext$.markPartiallyConstructed(SparkContext.scala:2734) at org.apache.spark.SparkContext.<init>(SparkContext.scala:95) at org.apache.spark.SparkContextSuite.$anonfun$new$159(SparkContextSuite.scala:1166) at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85) at org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83) at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104) at org.scalatest.Transformer.apply(Transformer.scala:22) ``` **After** ``` Run completed in 26 minutes, 38 seconds. Total number of tests run: 2863 Suites: completed 276, aborted 0 Tests: succeeded 2863, failed 0, canceled 4, ignored 8, pending 0 All tests passed. ``` Closes #33963 from LuciferYang/SPARK-36636. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 0e1157df06ba6364ca57be846194996327801ded) Signed-off-by: Sean Owen <srowen@gmail.com> | 12 September 2021, 14:57:39 UTC |
| 72e48d2 | dgd-contributor | 11 September 2021, 21:39:42 UTC | [SPARK-36685][ML][MLLIB] Fix wrong assert messages ### What changes were proposed in this pull request? Fix wrong assert statement, a mistake when coding ### Why are the changes needed? wrong assert statement ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests Closes #33953 from dgd-contributor/SPARK-36685. Authored-by: dgd-contributor <dgd_contributor@viettel.com.vn> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 9af01325164c9ea49d70be3716b2c74d4aaf7522) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 11 September 2021, 21:40:20 UTC |
| 55f050c | Sean Owen | 11 September 2021, 18:38:10 UTC | [SPARK-36704][CORE] Expand exception handling to more Java 9 cases where reflection is limited at runtime, when reflecting to manage DirectByteBuffer settings ### What changes were proposed in this pull request? Improve exception handling in the Platform initialization, where it attempts to assess whether reflection is possible to modify DirectByteBuffer. This can apparently fail in more cases on Java 9+ than are currently handled, whereas Spark can continue without reflection if needed. More detailed comments on the change inline. ### Why are the changes needed? This exception seems to be possible and fails startup: ``` Caused by: java.lang.reflect.InaccessibleObjectException: Unable to make private java.nio.DirectByteBuffer(long,int) accessible: module java.base does not "opens java.nio" to unnamed module 71e9ddb4 at java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:357) at java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:297) at java.base/java.lang.reflect.Constructor.checkCanSetAccessible(Constructor.java:188) at java.base/java.lang.reflect.Constructor.setAccessible(Constructor.java:181) at org.apache.spark.unsafe.Platform.<clinit>(Platform.java:56) ``` ### Does this PR introduce _any_ user-facing change? Should strictly allow Spark to continue in more cases. ### How was this patch tested? Existing tests. Closes #33947 from srowen/SPARK-36704. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit e5283f5ed5efa5bf3652c3959166f59dc5b5daaa) Signed-off-by: Sean Owen <srowen@gmail.com> | 11 September 2021, 18:39:00 UTC |
| 35caf2d | yi.wu | 10 September 2021, 16:32:49 UTC | Revert "[SPARK-35011][CORE][3.0] Avoid Block Manager registrations when StopExecutor msg is in-flight" This reverts commit 0a31f1f03ef071f199c8693cd080df8fa85a2315. ### What changes were proposed in this pull request? Revert https://github.com/apache/spark/pull/33782 ### Why are the changes needed? It breaks the expected `BlockManager` re-registration (e.g., heartbeat loss of an active executor) due to deferred removal of `BlockManager`, see the check: https://github.com/apache/spark/blob/9cefde8db373a3433b7e3ce328e4a2ce83b1aca2/core/src/main/scala/org/apache/spark/storage/BlockManagerMasterEndpoint.scala#L551 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass existing tests. Closes #33961 from Ngone51/revert-35011-3.0. Authored-by: yi.wu <yi.wu@databricks.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 10 September 2021, 16:32:49 UTC |
| 8c00df3 | Kousuke Saruta | 06 September 2021, 20:23:12 UTC | [SPARK-36639][SQL][3.0] Fix an issue that sequence builtin function causes ArrayIndexOutOfBoundsException if the arguments are under the condition of start == stop && step < 0 ### What changes were proposed in this pull request? This PR backports the change of SPARK-36639 (#33895) for `branch-3.0`. This PR fixes an issue that `sequence` builtin function causes `ArrayIndexOutOfBoundsException` if the arguments are under the condition of `start == stop && step < 0`. This is an example. ``` SELECT sequence(timestamp'2021-08-31', timestamp'2021-08-31', -INTERVAL 1 month); 21/09/02 04:14:42 ERROR SparkSQLDriver: Failed in [SELECT sequence(timestamp'2021-08-31', timestamp'2021-08-31', -INTERVAL 1 month)] java.lang.ArrayIndexOutOfBoundsException: 1 ``` Actually, this example succeeded before SPARK-31980 (#28819) was merged. ### Why are the changes needed? Bug fix. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? New tests. ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? Closes #33909 from sarutak/backport-SPARK-36639-branch-3.0. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 06 September 2021, 20:23:12 UTC |
| 068465d | Kousuke Saruta | 28 August 2021, 09:01:55 UTC | [SPARK-36509][CORE] Fix the issue that executors are never re-scheduled if the worker stops with standalone cluster ### What changes were proposed in this pull request? This PR fixes an issue that executors are never re-scheduled if the worker which the executors run on stops. As a result, the application stucks. You can easily reproduce this issue by the following procedures. ``` # Run master $ sbin/start-master.sh # Run worker 1 $ SPARK_LOG_DIR=/tmp/worker1 SPARK_PID_DIR=/tmp/worker1/ sbin/start-worker.sh -c 1 -h localhost -d /tmp/worker1 --webui-port 8081 spark://<hostname>:7077 # Run worker 2 $ SPARK_LOG_DIR=/tmp/worker2 SPARK_PID_DIR=/tmp/worker2/ sbin/start-worker.sh -c 1 -h localhost -d /tmp/worker2 --webui-port 8082 spark://<hostname>:7077 # Run Spark Shell $ bin/spark-shell --master spark://<hostname>:7077 --executor-cores 1 --total-executor-cores 1 # Check which worker the executor runs on and then kill the worker. $ kill <worker pid> ``` With the procedure above, we will expect that the executor is re-scheduled on the other worker but it won't. The reason seems that `Master.schedule` cannot be called after the worker is marked as `WorkerState.DEAD`. So, the solution this PR proposes is to call `Master.schedule` whenever `Master.removeWorker` is called. This PR also fixes an issue that `ExecutorRunner` can send `ExecutorStateChanged` message without changing its state. This issue causes assertion error. ``` 2021-08-13 14:05:37,991 [dispatcher-event-loop-9] ERROR: Ignoring errorjava.lang.AssertionError: assertion failed: executor 0 state transfer from RUNNING to RUNNING is illegal ``` ### Why are the changes needed? It's a critical bug. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manually tested with the procedure shown above and confirmed the executor is re-scheduled. Closes #33818 from sarutak/fix-scheduling-stuck. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com> (cherry picked from commit ea8c31e5ea233da4407f6821b2d6dd7f3c88f8d9) Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com> | 28 August 2021, 09:04:17 UTC |
| c420149 | Angerszhuuuu | 26 August 2021, 14:09:08 UTC | [SPARK-36352][SQL][3.0] Spark should check result plan's output schema name ### What changes were proposed in this pull request? Spark should check result plan's output schema name ### Why are the changes needed? In current code, some optimizer rule may change plan's output schema, since in the code we always use semantic equal to check output, but it may change the plan's output schema. For example, for SchemaPruning, if we have a plan ``` Project[a, B] |--Scan[A, b, c] ``` the origin output schema is `a, B`, after SchemaPruning. it become ``` Project[A, b] |--Scan[A, b] ``` It change the plan's schema. when we use CTAS, the schema is same as query plan's output. Then since we change the schema, it not consistent with origin SQL. So we need to check final result plan's schema with origin plan's schema ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? existed UT Closes #33764 from AngersZhuuuu/SPARK-36352-3.0. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 26 August 2021, 14:09:08 UTC |
| ce90ba0 | yi.wu | 24 August 2021, 20:33:42 UTC | [SPARK-36564][CORE] Fix NullPointerException in LiveRDDDistribution.toApi ### What changes were proposed in this pull request? This PR fixes `NullPointerException` in `LiveRDDDistribution.toApi`. ### Why are the changes needed? Looking at the stack trace, the NPE is caused by the null `exec.hostPort`. I can't get the complete log to take a close look but only guess that it might be due to the event `SparkListenerBlockManagerAdded` is dropped or out of order. ``` 21/08/23 12:26:29 ERROR AsyncEventQueue: Listener AppStatusListener threw an exception java.lang.NullPointerException at com.google.common.base.Preconditions.checkNotNull(Preconditions.java:192) at com.google.common.collect.MapMakerInternalMap.putIfAbsent(MapMakerInternalMap.java:3507) at com.google.common.collect.Interners$WeakInterner.intern(Interners.java:85) at org.apache.spark.status.LiveEntityHelpers$.weakIntern(LiveEntity.scala:696) at org.apache.spark.status.LiveRDDDistribution.toApi(LiveEntity.scala:563) at org.apache.spark.status.LiveRDD.$anonfun$doUpdate$4(LiveEntity.scala:629) at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238) at scala.collection.mutable.HashMap$$anon$2.$anonfun$foreach$3(HashMap.scala:158) at scala.collection.mutable.HashTable.foreachEntry(HashTable.scala:237) at scala.collection.mutable.HashTable.foreachEntry$(HashTable.scala:230) at scala.collection.mutable.HashMap.foreachEntry(HashMap.scala:44) at scala.collection.mutable.HashMap$$anon$2.foreach(HashMap.scala:158) at scala.collection.TraversableLike.map(TraversableLike.scala:238) at scala.collection.TraversableLike.map$(TraversableLike.scala:231) at scala.collection.AbstractTraversable.map(Traversable.scala:108) at org.apache.spark.status.LiveRDD.doUpdate(LiveEntity.scala:629) at org.apache.spark.status.LiveEntity.write(LiveEntity.scala:51) at org.apache.spark.status.AppStatusListener.update(AppStatusListener.scala:1206) at org.apache.spark.status.AppStatusListener.maybeUpdate(AppStatusListener.scala:1212) at org.apache.spark.status.AppStatusListener.$anonfun$onExecutorMetricsUpdate$6(AppStatusListener.scala:956) ... ``` ### Does this PR introduce _any_ user-facing change? Yes, users will see the expected RDD info in UI instead of the NPE error. ### How was this patch tested? Pass existing tests. Closes #33812 from Ngone51/fix-hostport-npe. Authored-by: yi.wu <yi.wu@databricks.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit d6c453aaea06327b37ab13b03a35a23a8225f010) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 24 August 2021, 20:34:24 UTC |
| 4f83417 | Angerszhuuuu | 24 August 2021, 15:33:00 UTC | [SPARK-35876][SQL][3.1] ArraysZip should retain field names to avoid being re-written by analyzer/optimizer #### What changes were proposed in this pull request? This PR fixes an issue that field names of structs generated by arrays_zip function could be unexpectedly re-written by analyzer/optimizer. Here is an example. ``` val df = sc.parallelize(Seq((Array(1, 2), Array(3, 4)))).toDF("a1", "b1").selectExpr("arrays_zip(a1, b1) as zipped") df.printSchema root |-- zipped: array (nullable = true) | |-- element: struct (containsNull = false) | | |-- a1: integer (nullable = true) // OK. a1 is expected name | | |-- b1: integer (nullable = true) // OK. b1 is expected name df.explain == Physical Plan == *(1) Project [arrays_zip(_1#3, _2#4) AS zipped#12] // Not OK. field names are re-written as _1 and _2 respectively df.write.parquet("/tmp/test.parquet") val df2 = spark.read.parquet("/tmp/test.parquet") df2.printSchema root |-- zipped: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- _1: integer (nullable = true) // Not OK. a1 is expected but got _1 | | |-- _2: integer (nullable = true) // Not OK. b1 is expected but got _2 ``` This issue happens when aliases are eliminated by AliasHelper.replaceAliasButKeepName or AliasHelper.trimNonTopLevelAliases called via analyzer/optimizer spark/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala Line 883 in b89cd8d upper.map(replaceAliasButKeepName(_, aliases)) spark/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala Line 3759 in b89cd8d val cleanedProjectList = projectList.map(trimNonTopLevelAliases) I investigated functions which can be affected this issue but I found only arrays_zip so far. To fix this issue, this PR changes the definition of ArraysZip to retain field names to avoid being re-written by analyzer/optimizer. ### Why are the changes needed? This is apparently a bug. ### Does this PR introduce any user-facing change? No. After this change, the field names are no longer re-written but it should be expected behavior for users. #### How was this patch tested? New tests. Closes #33810 from AngersZhuuuu/SPARK-35876-3.1. Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com> Co-authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 644cad26f489b3c1e8210245f1d958d05c208e53) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 24 August 2021, 15:33:23 UTC |
| 74d0115 | sweisdb | 20 August 2021, 13:31:39 UTC | Updates AuthEngine to pass the correct SecretKeySpec format AuthEngineSuite was passing on some platforms (MacOS), but failing on others (Linux) with an InvalidKeyException stemming from this line. We should explicitly pass AES as the key format. ### What changes were proposed in this pull request? Changes the AuthEngine SecretKeySpec from "RAW" to "AES". ### Why are the changes needed? Unit tests were failing on some platforms with InvalidKeyExceptions when this key was used to instantiate a Cipher. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Unit tests on a MacOS and Linux platform. Closes #33790 from sweisdb/patch-1. Authored-by: sweisdb <60895808+sweisdb@users.noreply.github.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit c441c7e365cdbed4bae55e9bfdf94fa4a118fb21) Signed-off-by: Sean Owen <srowen@gmail.com> | 20 August 2021, 13:32:15 UTC |
| 95ae41e | yi.wu | 20 August 2021, 12:04:09 UTC | [SPARK-36532][CORE][3.1] Fix deadlock in CoarseGrainedExecutorBackend.onDisconnected to avoid executorsconnected to avoid executor shutdown hang shutdown hang ### What changes were proposed in this pull request? Instead of exiting the executor within the RpcEnv's thread, exit the executor in a separate thread. ### Why are the changes needed? The current exit way in `onDisconnected` can cause the deadlock, which has the exact same root cause with https://github.com/apache/spark/pull/12012: * `onDisconnected` -> `System.exit` are called in sequence in the thread of `MessageLoop.threadpool` * `System.exit` triggers shutdown hooks and `executor.stop` is one of the hooks. * `executor.stop` stops the `Dispatcher`, which waits for the `MessageLoop.threadpool` to shutdown further. * Thus, the thread which runs `System.exit` waits for hooks to be done, but the `MessageLoop.threadpool` in the hook waits that thread to finish. Finally, this mutual dependence results in the deadlock. ### Does this PR introduce _any_ user-facing change? Yes, the executor shutdown won't hang. ### How was this patch tested? Pass existing tests. Closes #33759 from Ngone51/fix-executor-shutdown-hang. Authored-by: yi.wu <yi.wudatabricks.com> Signed-off-by: Wenchen Fan <wenchendatabricks.com> ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? Closes #33795 from Ngone51/cherry-pick-spark-36532. Authored-by: yi.wu <yi.wu@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit bdccbe4841e1a34a116ff2aa86063e0a64d45022) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 20 August 2021, 12:04:32 UTC |
| 0a31f1f | Sumeet Gajjar | 20 August 2021, 06:42:05 UTC | [SPARK-35011][CORE][3.0] Avoid Block Manager registrations when StopExecutor msg is in-flight This PR backports #32114 to 3.0 <hr> <!-- Thanks for sending a pull request! Here are some tips for you: 1. If this is your first time, please read our contributor guidelines: https://spark.apache.org/contributing.html 2. Ensure you have added or run the appropriate tests for your PR: https://spark.apache.org/developer-tools.html 3. If the PR is unfinished, add '[WIP]' in your PR title, e.g., '[WIP][SPARK-XXXX] Your PR title ...'. 4. Be sure to keep the PR description updated to reflect all changes. 5. Please write your PR title to summarize what this PR proposes. 6. If possible, provide a concise example to reproduce the issue for a faster review. 7. If you want to add a new configuration, please read the guideline first for naming configurations in 'core/src/main/scala/org/apache/spark/internal/config/ConfigEntry.scala'. --> ### What changes were proposed in this pull request? <!-- Please clarify what changes you are proposing. The purpose of this section is to outline the changes and how this PR fixes the issue. If possible, please consider writing useful notes for better and faster reviews in your PR. See the examples below. 1. If you refactor some codes with changing classes, showing the class hierarchy will help reviewers. 2. If you fix some SQL features, you can provide some references of other DBMSes. 3. If there is design documentation, please add the link. 4. If there is a discussion in the mailing list, please add the link. --> This patch proposes a fix to prevent triggering BlockManager reregistration while `StopExecutor` msg is in-flight. Here on receiving `StopExecutor` msg, we do not remove the corresponding `BlockManagerInfo` from `blockManagerInfo` map, instead we mark it as dead by updating the corresponding `executorRemovalTs`. There's a separate cleanup thread running to periodically remove the stale `BlockManagerInfo` from `blockManangerInfo` map. Now if a recently removed `BlockManager` tries to register, the driver simply ignores it since the `blockManagerInfo` map already contains an entry for it. The same applies to `BlockManagerHeartbeat`, if the BlockManager belongs to a recently removed executor, the `blockManagerInfo` map would contain an entry and we shall not ask the corresponding `BlockManager` to re-register. ### Why are the changes needed? <!-- Please clarify why the changes are needed. For instance, 1. If you propose a new API, clarify the use case for a new API. 2. If you fix a bug, you can clarify why it is a bug. --> This changes are needed since BlockManager reregistration while executor is shutting down causes inconsistent bookkeeping of executors in Spark. Consider the following scenario: - `CoarseGrainedSchedulerBackend` issues async `StopExecutor` on executorEndpoint - `CoarseGrainedSchedulerBackend` removes that executor from Driver's internal data structures and publishes `SparkListenerExecutorRemoved` on the `listenerBus`. - Executor has still not processed `StopExecutor` from the Driver - Driver receives heartbeat from the Executor, since it cannot find the `executorId` in its data structures, it responds with `HeartbeatResponse(reregisterBlockManager = true)` - `BlockManager` on the Executor reregisters with the `BlockManagerMaster` and `SparkListenerBlockManagerAdded` is published on the `listenerBus` - Executor starts processing the `StopExecutor` and exits - `AppStatusListener` picks the `SparkListenerBlockManagerAdded` event and updates `AppStatusStore` - `statusTracker.getExecutorInfos` refers `AppStatusStore` to get the list of executors which returns the dead executor as alive. ### Does this PR introduce _any_ user-facing change? <!-- Note that it means *any* user-facing change including all aspects such as the documentation fix. If yes, please clarify the previous behavior and the change this PR proposes - provide the console output, description and/or an example to show the behavior difference if possible. If possible, please also clarify if this is a user-facing change compared to the released Spark versions or within the unreleased branches such as master. If no, write 'No'. --> No ### How was this patch tested? <!-- If tests were added, say they were added here. Please make sure to add some test cases that check the changes thoroughly including negative and positive cases if possible. If it was tested in a way different from regular unit tests, please clarify how you tested step by step, ideally copy and paste-able, so that other reviewers can test and check, and descendants can verify in the future. If tests were not added, please describe why they were not added and/or why it was difficult to add. --> - Modified the existing unittests. - Ran a simple test application on minikube that asserts on number of executors are zero once the executor idle timeout is reached. Closes #33782 from sumeetgajjar/SPARK-35011-br-3.0. Authored-by: Sumeet Gajjar <sumeetgajjar93@gmail.com> Signed-off-by: yi.wu <yi.wu@databricks.com> | 20 August 2021, 06:42:05 UTC |
| 8862657 | Sumeet Gajjar | 18 August 2021, 23:23:35 UTC | [SPARK-34949][CORE][3.0] Prevent BlockManager reregister when Executor is shutting down This PR backports #32043 to branch-3.0 <hr> ### What changes were proposed in this pull request? This PR prevents reregistering BlockManager when a Executor is shutting down. It is achieved by checking `executorShutdown` before calling `env.blockManager.reregister()`. ### Why are the changes needed? This change is required since Spark reports executors as active, even they are removed. I was testing Dynamic Allocation on K8s with about 300 executors. While doing so, when the executors were torn down due to `spark.dynamicAllocation.executorIdleTimeout`, I noticed all the executor pods being removed from K8s, however, under the "Executors" tab in SparkUI, I could see some executors listed as alive. [spark.sparkContext.statusTracker.getExecutorInfos.length](https://github.com/apache/spark/blob/65da9287bc5112564836a555cd2967fc6b05856f/core/src/main/scala/org/apache/spark/SparkStatusTracker.scala#L105) also returned a value greater than 1. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added a new test. ## Logs Following are the logs of the executor(Id:303) which re-registers `BlockManager` ``` 21/04/02 21:33:28 INFO CoarseGrainedExecutorBackend: Got assigned task 1076 21/04/02 21:33:28 INFO Executor: Running task 4.0 in stage 3.0 (TID 1076) 21/04/02 21:33:28 INFO MapOutputTrackerWorker: Updating epoch to 302 and clearing cache 21/04/02 21:33:28 INFO TorrentBroadcast: Started reading broadcast variable 3 21/04/02 21:33:28 INFO TransportClientFactory: Successfully created connection to /100.100.195.227:33703 after 76 ms (62 ms spent in bootstraps) 21/04/02 21:33:28 INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 2.4 KB, free 168.0 MB) 21/04/02 21:33:28 INFO TorrentBroadcast: Reading broadcast variable 3 took 168 ms 21/04/02 21:33:28 INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 3.9 KB, free 168.0 MB) 21/04/02 21:33:29 INFO MapOutputTrackerWorker: Don't have map outputs for shuffle 1, fetching them 21/04/02 21:33:29 INFO MapOutputTrackerWorker: Doing the fetch; tracker endpoint = NettyRpcEndpointRef(spark://MapOutputTrackerda-lite-test-4-7a57e478947d206d-driver-svc.dex-app-n5ttnbmg.svc:7078) 21/04/02 21:33:29 INFO MapOutputTrackerWorker: Got the output locations 21/04/02 21:33:29 INFO ShuffleBlockFetcherIterator: Getting 2 non-empty blocks including 1 local blocks and 1 remote blocks 21/04/02 21:33:30 INFO TransportClientFactory: Successfully created connection to /100.100.80.103:40971 after 660 ms (528 ms spent in bootstraps) 21/04/02 21:33:30 INFO ShuffleBlockFetcherIterator: Started 1 remote fetches in 1042 ms 21/04/02 21:33:31 INFO Executor: Finished task 4.0 in stage 3.0 (TID 1076). 1276 bytes result sent to driver . . . 21/04/02 21:34:16 INFO CoarseGrainedExecutorBackend: Driver commanded a shutdown 21/04/02 21:34:16 INFO Executor: Told to re-register on heartbeat 21/04/02 21:34:16 INFO BlockManager: BlockManager BlockManagerId(303, 100.100.122.34, 41265, None) re-registering with master 21/04/02 21:34:16 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(303, 100.100.122.34, 41265, None) 21/04/02 21:34:16 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(303, 100.100.122.34, 41265, None) 21/04/02 21:34:16 INFO BlockManager: Reporting 0 blocks to the master. 21/04/02 21:34:16 INFO MemoryStore: MemoryStore cleared 21/04/02 21:34:16 INFO BlockManager: BlockManager stopped 21/04/02 21:34:16 INFO FileDataSink: Closing sink with output file = /tmp/safari-events/.des_analysis/safari-events/hdp_spark_monitoring_random-container-037caf27-6c77-433f-820f-03cd9c7d9b6e-spark-8a492407d60b401bbf4309a14ea02ca2_events.tsv 21/04/02 21:34:16 INFO HonestProfilerBasedThreadSnapshotProvider: Stopping agent 21/04/02 21:34:16 INFO HonestProfilerHandler: Stopping honest profiler agent 21/04/02 21:34:17 INFO ShutdownHookManager: Shutdown hook called 21/04/02 21:34:17 INFO ShutdownHookManager: Deleting directory /var/data/spark-d886588c-2a7e-491d-bbcb-4f58b3e31001/spark-4aa337a0-60c0-45da-9562-8c50eaff3cea ``` Closes #33770 from sumeetgajjar/SPARK-34949-br-3.0. Authored-by: Sumeet Gajjar <sumeetgajjar93@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 18 August 2021, 23:23:35 UTC |
| ae07b63 | Sean Owen | 16 August 2021, 22:13:33 UTC | [HOTFIX] Add missing deps update for commit protocol change | 16 August 2021, 22:13:33 UTC |
| 763a25a | Sean Owen | 11 August 2021, 23:04:55 UTC | Update Spark key negotiation protocol | 16 August 2021, 20:00:54 UTC |
| dc0f1e5 | Xingbo Jiang | 13 August 2021, 10:25:20 UTC | [SPARK-36500][CORE] Fix temp_shuffle file leaking when a task is interrupted ### What changes were proposed in this pull request? When a task thread is interrupted, the underlying output stream referred by `DiskBlockObjectWriter.mcs` may have been closed, then we get IOException when flushing the buffered data. This breaks the assumption that `revertPartialWritesAndClose()` should not throw exceptions. To fix the issue, we can catch the IOException in `ManualCloseOutputStream.manualClose()`. ### Why are the changes needed? Previously the IOException was not captured, thus `revertPartialWritesAndClose()` threw an exception. When this happens, `BypassMergeSortShuffleWriter.stop()` would stop deleting the temp_shuffle files tracked by `partitionWriters`, hens lead to temp_shuffle file leak issues. ### Does this PR introduce _any_ user-facing change? No, this is an internal bug fix. ### How was this patch tested? Tested by running a longevity stress test. After the fix, there is no more leaked temp_shuffle files. Closes #33731 from jiangxb1987/temp_shuffle. Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit ec5f3a17e33f7afe03e48f8b7690a8b18ae0c058) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 13 August 2021, 10:25:57 UTC |
| 9716ec6 | Angerszhuuuu | 13 August 2021, 08:44:25 UTC | [SPARK-36353][SQL][3.0] RemoveNoopOperators should keep output schema ### What changes were proposed in this pull request? RemoveNoopOperators should keep output schema ### Why are the changes needed? Expand function ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Not need Closes #33705 from AngersZhuuuu/SPARK-36353-3.0. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 13 August 2021, 08:44:25 UTC |
| a65e463 | Kazuyuki Tanimura | 10 August 2021, 17:29:54 UTC | [SPARK-36464][CORE] Fix Underlying Size Variable Initialization in ChunkedByteBufferOutputStream for Writing Over 2GB Data ### What changes were proposed in this pull request? The `size` method of `ChunkedByteBufferOutputStream` returns a `Long` value; however, the underlying `_size` variable is initialized as `Int`. That causes an overflow and returns a negative size when over 2GB data is written into `ChunkedByteBufferOutputStream` This PR proposes to change the underlying `_size` variable from `Int` to `Long` at the initialization ### Why are the changes needed? Be cause the `size` method of `ChunkedByteBufferOutputStream` incorrectly returns a negative value when over 2GB data is written. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Passed existing tests ``` build/sbt "core/testOnly *ChunkedByteBufferOutputStreamSuite" ``` Also added a new unit test ``` build/sbt "core/testOnly *ChunkedByteBufferOutputStreamSuite – -z SPARK-36464" ``` Closes #33690 from kazuyukitanimura/SPARK-36464. Authored-by: Kazuyuki Tanimura <ktanimura@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit c888bad6a12b45f3eda8d898bdd90405985ee05c) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 10 August 2021, 17:33:46 UTC |
| e2e8e4b | Angerszhuuuu | 10 August 2021, 12:55:53 UTC | [SPARK-36086][SQL][3.0] CollapseProject project replace alias should use origin column name ### What changes were proposed in this pull request? For added UT, without this patch will failed as below ``` [info] - SHOW TABLES V2: SPARK-36086: CollapseProject project replace alias should use origin column name *** FAILED *** (4 seconds, 935 milliseconds) [info] java.lang.RuntimeException: After applying rule org.apache.spark.sql.catalyst.optimizer.CollapseProject in batch Operator Optimization before Inferring Filters, the structural integrity of the plan is broken. [info] at org.apache.spark.sql.errors.QueryExecutionErrors$.structuralIntegrityIsBrokenAfterApplyingRuleError(QueryExecutionErrors.scala:1217) [info] at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$2(RuleExecutor.scala:229) [info] at scala.collection.LinearSeqOptimized.foldLeft(LinearSeqOptimized.scala:126) [info] at scala.collection.LinearSeqOptimized.foldLeft$(LinearSeqOptimized.scala:122) [info] at scala.collection.immutable.List.foldLeft(List.scala:91) [info] at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1(RuleExecutor.scala:208) [info] at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1$adapted(RuleExecutor.scala:200) [info] at scala.collection.immutable.List.foreach(List.scala:431) [info] at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:200) [info] at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$executeAndTrack$1(RuleExecutor.scala:179) [info] at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:88) ``` CollapseProject project replace alias should use origin column name ### Why are the changes needed? Fix bug ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added UT Closes #33686 from AngersZhuuuu/SPARK-36086-3.0. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 10 August 2021, 12:55:53 UTC |
| e10cc78 | gaoyajun02 | 09 August 2021, 08:53:27 UTC | [SPARK-36339][SQL][3.0] References to grouping that not part of aggregation should be replaced ### What changes were proposed in this pull request? Currently, references to grouping sets are reported as errors after aggregated expressions, e.g. ``` SELECT count(name) c, name FROM VALUES ('Alice'), ('Bob') people(name) GROUP BY name GROUPING SETS(name); ``` Error in query: expression 'people.`name`' is neither present in the group by, nor is it an aggregate function. Add to group by or wrap in first() (or first_value) if you don't care which value you get.;; ### Why are the changes needed? Fix the map anonymous function in the constructAggregateExprs function does not use underscores to avoid ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit tests. Closes #33669 from gaoyajun02/branch-3.0. Authored-by: gaoyajun02 <gaoyajun02@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 09 August 2021, 08:53:27 UTC |
| c73c5b3 | Kousuke Saruta | 06 August 2021, 01:49:27 UTC | [SPARK-36441][INFRA] Fix GA failure related to downloading lintr dependencies ### What changes were proposed in this pull request? This PR fixes a GA failure which is related to downloading lintr dependencies. ``` * installing *source* package ‘devtools’ ... ** package ‘devtools’ successfully unpacked and MD5 sums checked ** using staged installation ** R ** inst ** byte-compile and prepare package for lazy loading ** help *** installing help indices *** copying figures ** building package indices ** installing vignettes ** testing if installed package can be loaded from temporary location ** testing if installed package can be loaded from final location ** testing if installed package keeps a record of temporary installation path * DONE (devtools) The downloaded source packages are in ‘/tmp/Rtmpv53Ix4/downloaded_packages’ Using bundled GitHub PAT. Please add your own PAT to the env var `GITHUB_PAT` Error: Failed to install 'unknown package' from GitHub: HTTP error 401. Bad credentials ``` I re-triggered the GA job but it still fail with the same error. https://github.com/apache/spark/runs/3257853825 The issue seems to happen when downloading lintr dependencies from GitHub. So, the solution is to change the way to download them. ### Why are the changes needed? To recover GA. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? GA itself. Closes #33660 from sarutak/fix-r-package-issue. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit e13bd586f1854df872f32ebd3c7686fc4013e06e) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 06 August 2021, 01:50:08 UTC |
| 1061c9f | yangjie01 | 27 July 2021, 17:19:41 UTC | [SPARK-36242][CORE][3.0] Ensure spill file closed before set success = true in ExternalSorter.spillMemoryIteratorToDisk method ### What changes were proposed in this pull request? The main change of this pr is move `writer.close()` before `success = true` to ensure spill file closed before set `success = true` in `ExternalSorter.spillMemoryIteratorToDisk` method. ### Why are the changes needed? Avoid setting `success = true` first and then failure of close spill file ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass the Jenkins or GitHub Action - Add a new Test case to check `The spill file should not exists if writer close fails` Closes #33514 from LuciferYang/SPARK-36242-30. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 27 July 2021, 17:19:41 UTC |
| 6740d07 | Cheng Su | 26 July 2021, 10:48:06 UTC | [SPARK-36269][SQL] Fix only set data columns to Hive column names config ### What changes were proposed in this pull request? When reading Hive table, we set the Hive column id and column name configs (`hive.io.file.readcolumn.ids` and `hive.io.file.readcolumn.names`). We should set non-partition columns (data columns) for both configs, as Spark always [appends partition columns in its own Hive reader](https://github.com/apache/spark/blob/master/sql/hive/src/main/scala/org/apache/spark/sql/hive/TableReader.scala#L240). The column id config has only non-partition columns, but column name config has both partition and non-partition columns. We should keep them to be consistent with only non-partition columns. This does not cause issue for public OSS Hive file format for now. But for customized internal Hive file format, it causes the issue as we are expecting these two configs to be same. ### Why are the changes needed? Fix the code logic to be more consistent. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing Hive tests. Closes #33489 from c21/hive-col. Authored-by: Cheng Su <chengsu@fb.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit e5616e32eecb516a6b46ae9bc5c2c850c18210a2) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 26 July 2021, 10:49:16 UTC |
| d44120d | Liang-Chi Hsieh | 23 July 2021, 23:47:12 UTC | [SPARK-36213][SQL][FOLLOWUP][3.0] Fix compilation error due to type mismatch ### What changes were proposed in this pull request? This patch fixes a compilation error of backported PR of SPARK-36213. ### Why are the changes needed? To fix compilation error: ``` [error] /spark/sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala:695: type mismatch; [error] found : org.apache.spark.sql.types.StructType [error] required: Seq[String] [error] Error occurred in an application involving default arguments. [error] metadata.partitionSchema, [error] ^ ``` `PartitioningUtils.normalizePartitionSpec`'s `partColNames` is `Seq[String]` in 3.0. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test Closes #33504 from viirya/SPARK-36213-followup. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 23 July 2021, 23:47:12 UTC |
| 0cfea30 | Kent Yao | 21 July 2021, 16:52:31 UTC | [SPARK-36213][SQL] Normalize PartitionSpec for Describe Table Command with PartitionSpec ### What changes were proposed in this pull request? This fixes a case sensitivity issue for desc table commands with partition specified. ### Why are the changes needed? bugfix ### Does this PR introduce _any_ user-facing change? yes, but it's a bugfix ### How was this patch tested? new tests #### before ``` +-- !query +DESC EXTENDED t PARTITION (C='Us', D=1) +-- !query schema +struct<> +-- !query output +org.apache.spark.sql.AnalysisException +Partition spec is invalid. The spec (C, D) must match the partition spec (c, d) defined in table '`default`.`t`' + ``` #### after https://github.com/apache/spark/pull/33424/files#diff-554189c49950974a948f99fa9b7436f615052511660c6a0ae3062fa8ca0a327cR328 Closes #33424 from yaooqinn/SPARK-36213. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Kent Yao <yao@apache.org> (cherry picked from commit 4cd6cfc773da726a90d41bfc590ea9188c17d5ae) Signed-off-by: Kent Yao <yao@apache.org> | 21 July 2021, 16:54:32 UTC |
| 78ec701 | Shardul Mahadik | 21 July 2021, 14:40:39 UTC | [SPARK-28266][SQL] convertToLogicalRelation should not interpret `path` property when reading Hive tables ### What changes were proposed in this pull request? For non-datasource Hive tables, e.g. tables written outside of Spark (through Hive or Trino), we have certain optimzations in Spark where we use Spark ORC and Parquet datasources to read these tables ([Ref](https://github.com/apache/spark/blob/fbf53dee37129a493a4e5d5a007625b35f44fbda/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveMetastoreCatalog.scala#L128)) rather than using the Hive serde. If such a table contains a `path` property, Spark will try to list this path property in addition to the table location when creating an `InMemoryFileIndex`. ([Ref](https://github.com/apache/spark/blob/fbf53dee37129a493a4e5d5a007625b35f44fbda/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSource.scala#L575)) This can lead to wrong data if `path` property points to a directory location or an error if `path` is not a location. A concrete example is provided in [SPARK-28266 (comment)](https://issues.apache.org/jira/browse/SPARK-28266?focusedCommentId=17380170&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-17380170). Since these tables were not written through Spark, Spark should not interpret this `path` property as it can be set by an external system with a different meaning. ### Why are the changes needed? For better compatibility with Hive tables generated by other platforms (non-Spark) ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added unit test Closes #33328 from shardulm94/spark-28266. Authored-by: Shardul Mahadik <smahadik@linkedin.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 685c3fd05bf8e9d85ea9b33d4e28807d436cd5ca) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 21 July 2021, 14:42:01 UTC |
| 25caec4 | Jie | 21 July 2021, 02:23:51 UTC | [SPARK-35027][CORE] Close the inputStream in FileAppender when writin… ### What changes were proposed in this pull request? 1. add "closeStreams" to FileAppender and RollingFileAppender 2. set "closeStreams" to "true" in ExecutorRunner ### Why are the changes needed? The executor will hang when due disk full or other exceptions which happened in writting to outputStream: the root cause is the "inputStream" is not closed after the error happens: 1. ExecutorRunner creates two files appenders for pipe: one for stdout, one for stderr 2. FileAppender.appendStreamToFile exits the loop when writing to outputStream 3. FileAppender closes the outputStream, but left the inputStream which refers the pipe's stdout and stderr opened 4. The executor will hang when printing the log message if the pipe is full (no one consume the outputs) 5. From the driver side, you can see the task can't be completed for ever With this fix, the step 4 will throw an exception, the driver can catch up the exception and reschedule the failed task to other executors. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Add new tests for the "closeStreams" in FileAppenderSuite Closes #33263 from jhu-chang/SPARK-35027. Authored-by: Jie <gt.hu.chang@gmail.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 1a8c6755a1802afdb9a73793e9348d322176125a) Signed-off-by: Sean Owen <srowen@gmail.com> | 21 July 2021, 02:25:02 UTC |
| 73645d4 | Koert Kuipers | 20 July 2021, 16:09:22 UTC | [SPARK-36210][SQL] Preserve column insertion order in Dataset.withColumns ### What changes were proposed in this pull request? Preserve the insertion order of columns in Dataset.withColumns ### Why are the changes needed? It is the expected behavior. We preserve insertion order in all other places. ### Does this PR introduce _any_ user-facing change? No. Currently Dataset.withColumns is not actually used anywhere to insert more than one column. This change is to make sure it behaves as expected when it is used for that purpose in future. ### How was this patch tested? Added test in DatasetSuite Closes #33423 from koertkuipers/feat-withcolumns-preserve-order. Authored-by: Koert Kuipers <koert@tresata.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> (cherry picked from commit bf680bf25aae9619d462caee05c41cc33909338a) Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 20 July 2021, 16:11:24 UTC |
| 5565d1c | Karen Feng | 20 July 2021, 13:32:13 UTC | [SPARK-36079][SQL] Null-based filter estimate should always be in the range [0, 1] Forces the selectivity estimate for null-based filters to be in the range `[0,1]`. I noticed in a few TPC-DS query tests that the column statistic null count can be higher than the table statistic row count. In the current implementation, the selectivity estimate for `IsNotNull` is negative. No Unit test Closes #33286 from karenfeng/bound-selectivity-est. Authored-by: Karen Feng <karen.feng@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit ddc61e62b9af5deff1b93e22f466f2a13f281155) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 20 July 2021, 13:45:27 UTC |
| 7588b46 | Hyukjin Kwon | 20 July 2021, 04:17:05 UTC | [SPARK-36216][PYTHON][TESTS] Increase timeout for StreamingLinearRegressionWithTests. test_parameter_convergence ### What changes were proposed in this pull request? Test is flaky (https://github.com/apache/spark/runs/3109815586): ``` Traceback (most recent call last): File "/__w/spark/spark/python/pyspark/mllib/tests/test_streaming_algorithms.py", line 391, in test_parameter_convergence eventually(condition, catch_assertions=True) File "/__w/spark/spark/python/pyspark/testing/utils.py", line 91, in eventually raise lastValue File "/__w/spark/spark/python/pyspark/testing/utils.py", line 82, in eventually lastValue = condition() File "/__w/spark/spark/python/pyspark/mllib/tests/test_streaming_algorithms.py", line 387, in condition self.assertEqual(len(model_weights), len(batches)) AssertionError: 9 != 10 ``` Should probably increase timeout ### Why are the changes needed? To avoid flakiness in the test. ### Does this PR introduce _any_ user-facing change? Nope, dev-only. ### How was this patch tested? CI should test it out. Closes #33427 from HyukjinKwon/SPARK-36216. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit d6b974f8ceb5383e5f01cf87a267b7580f992ac1) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 20 July 2021, 04:17:44 UTC |
| e5c8fa0 | Angerszhuuuu | 20 July 2021, 03:14:36 UTC | [SPARK-36093][SQL][3.0] RemoveRedundantAliases should not change Command's parameter's expression's name ### What changes were proposed in this pull request? RemoveRedundantAliases may change DataWritingCommand's parameter's attribute name. In the UT's case before RemoveRedundantAliases the partitionColumns is `CAL_DT`, and change by RemoveRedundantAliases and change to `cal_dt` then case the error case ### Why are the changes needed? Fix bug ### Does this PR introduce _any_ user-facing change? For below SQL case ``` sql("create table t1(cal_dt date) using parquet") sql("insert into t1 values (date'2021-06-27'),(date'2021-06-28'),(date'2021-06-29'),(date'2021-06-30')") sql("create view t1_v as select * from t1") sql("CREATE TABLE t2 USING PARQUET PARTITIONED BY (CAL_DT) AS SELECT 1 AS FLAG,CAL_DT FROM t1_v WHERE CAL_DT BETWEEN '2021-06-27' AND '2021-06-28'") sql("INSERT INTO t2 SELECT 2 AS FLAG,CAL_DT FROM t1_v WHERE CAL_DT BETWEEN '2021-06-29' AND '2021-06-30'") ``` Before this pr ``` sql("SELECT * FROM t2 WHERE CAL_DT BETWEEN '2021-06-29' AND '2021-06-30'").show +----+------+ |FLAG|CAL_DT| +----+------+ +----+------+ sql("SELECT * FROM t2 ").show +----+----------+ |FLAG| CAL_DT| +----+----------+ | 1|2021-06-27| | 1|2021-06-28| +----+----------+ ``` After this pr ``` sql("SELECT * FROM t2 WHERE CAL_DT BETWEEN '2021-06-29' AND '2021-06-30'").show +----+------+ |FLAG|CAL_DT| +----+------+ | 2|2021-06-29| | 2|2021-06-30| +----+------+ sql("SELECT * FROM t2 ").show +----+----------+ |FLAG| CAL_DT| +----+----------+ | 1|2021-06-27| | 1|2021-06-28| | 2|2021-06-29| | 2|2021-06-30| +----+----------+ ``` ### How was this patch tested? Added UT Closes #33418 from AngersZhuuuu/SPARK-36093-3.0. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 20 July 2021, 03:14:36 UTC |
| b4439d2 | Hyukjin Kwon | 16 July 2021, 13:08:50 UTC | [SPARK-36177][R][TESTS][3.0] Disable CRAN in branches lower than the latest version uploaded ### What changes were proposed in this pull request? This PR proposes to skip the CRAN check in old branches (than the latest version uploaded to CRAN) ### Why are the changes needed? CRAN check in branch-3.0 fails as below: ``` Insufficient package version (submitted: 3.0.4, existing: 3.1.2) ``` This is because CRAN doesn't allow lower version then the latest version. We can't upload so should better just skip the CRAN check. ### Does this PR introduce _any_ user-facing change? No, dev-only. ### How was this patch tested? It will be tested in the CI at this PR. Closes #33390 from HyukjinKwon/sparkr-cran. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 16 July 2021, 13:08:50 UTC |
| e41ecef | Max Gekk | 16 July 2021, 12:29:43 UTC | [SPARK-36034][SQL][3.0] Rebase datetime in pushed down filters to parquet ### What changes were proposed in this pull request? In the PR, I propose to propagate either the SQL config `spark.sql.parquet.datetimeRebaseModeInRead` or/and Parquet option `datetimeRebaseMode` to `ParquetFilters`. The `ParquetFilters` class uses the settings in conversions of dates/timestamps instances from datasource filters to values pushed via `FilterApi` to the `parquet-column` lib. Before the changes, date/timestamp values expressed as days/microseconds/milliseconds are interpreted as offsets in Proleptic Gregorian calendar, and pushed to the parquet library as is. That works fine if timestamp/dates values in parquet files were saved in the `CORRECTED` mode but in the `LEGACY` mode, filter's values could not match to actual values. After the changes, timestamp/dates values of filters pushed down to parquet libs such as `FilterApi.eq(col1, -719162)` are rebased according the rebase settings. For the example, if the rebase mode is `CORRECTED`, **-719162** is pushed down as is but if the current rebase mode is `LEGACY`, the number of days is rebased to **-719164**. For more context, the PR description https://github.com/apache/spark/pull/28067 shows the diffs between two calendars. ### Why are the changes needed? The changes fix the bug portrayed by the following example from SPARK-36034: ```scala In [27]: spark.conf.set("spark.sql.legacy.parquet.datetimeRebaseModeInWrite", "LEGACY") >>> spark.sql("SELECT DATE '0001-01-01' AS date").write.mode("overwrite").parquet("date_written_by_spark3_legacy") >>> spark.read.parquet("date_written_by_spark3_legacy").where("date = '0001-01-01'").show() +----+ |date| +----+ +----+ ``` The result must have the date value `0001-01-01`. ### Does this PR introduce _any_ user-facing change? In some sense, yes. Query results can be different in some cases. For the example above: ```scala scala> spark.conf.set("spark.sql.parquet.datetimeRebaseModeInWrite", "LEGACY") scala> spark.sql("SELECT DATE '0001-01-01' AS date").write.mode("overwrite").parquet("date_written_by_spark3_legacy") scala> spark.read.parquet("date_written_by_spark3_legacy").where("date = '0001-01-01'").show(false) +----------+ |date | +----------+ |0001-01-01| +----------+ ``` ### How was this patch tested? By running the modified test suite `ParquetFilterSuite`: ``` $ build/sbt "test:testOnly *ParquetV1FilterSuite" $ build/sbt "test:testOnly *ParquetV2FilterSuite" ``` Authored-by: Max Gekk <max.gekkgmail.com> Signed-off-by: Hyukjin Kwon <gurwls223apache.org> (cherry picked from commit b09b7f7cc024d3054debd7bdb51caec3b53764d7) (cherry picked from commit ba7117224c797e3ade64a281b1a165cf5040c541) Closes #33387 from MaxGekk/fix-parquet-ts-filter-pushdown-3.0. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 16 July 2021, 12:29:43 UTC |
| 86a9059 | Hyukjin Kwon | 15 July 2021, 14:58:18 UTC | [SPARK-36159][BUILD] Replace 'python' to 'python3' in dev/test-dependencies.sh ### What changes were proposed in this pull request? This PR is a followup of https://github.com/apache/spark/pull/26330. There is the last place to fix in `dev/test-dependencies.sh` ### Why are the changes needed? To stick to Python 3 instead of using Python 2 mistakenly. ### Does this PR introduce _any_ user-facing change? No, dev-only. ### How was this patch tested? Manually tested. Closes #33368 from HyukjinKwon/change-python-3. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 6bd385f1e34a03507dd59a6fa02aab976547614b) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 15 July 2021, 14:58:54 UTC |
| 43b683b | dgd-contributor | 15 July 2021, 04:16:16 UTC | [SPARK-36076][SQL][3.0] ArrayIndexOutOfBounds in Cast string to timestamp ### What changes were proposed in this pull request? Casting string to timestamp might throw ArrayIndexOutOfBounds in certain cases This error only occur in branch 3.0, 3.1 and previous, it's not present on 3.2 or master Code to reproduce: ``` val df = Seq(":8:434421+ 98:38").toDF("c0") val df2 = df.withColumn("c1", col("c0").cast(DataTypes.TimestampType)) df2.show() ``` Error: ``` java.lang.ArrayIndexOutOfBoundsException: 9 at org.apache.spark.sql.catalyst.util.DateTimeUtils$.stringToTimestamp(DateTimeUtils.scala:328) at org.apache.spark.sql.catalyst.expressions.CastBase.$anonfun$castToTimestamp$2(Cast.scala:455) at org.apache.spark.sql.catalyst.expressions.CastBase.buildCast(Cast.scala:295) at org.apache.spark.sql.catalyst.expressions.CastBase.$anonfun$castToTimestamp$1(Cast.scala:451) at org.apache.spark.sql.catalyst.expressions.CastBase.nullSafeEval(Cast.scala:840) at org.apache.spark.sql.catalyst.expressions.UnaryExpression.eval(Expression.scala:476) ``` ### Why are the changes needed? Cast String to timestamp shouldn't throw error, it should return Null instead. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Add test in DateTimeUtilsSuite Closes #33325 from dgd-contributor/SPARK-36076_branch3.0. Authored-by: dgd-contributor <dgd_contributor@viettel.com.vn> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 15 July 2021, 04:16:16 UTC |
| c65ff15 | Kousuke Saruta | 14 July 2021, 14:02:09 UTC | [SPARK-36129][BUILD][3.0] Upgrade commons-compress to 1.21 to deal with CVEs ### What changes were proposed in this pull request? This PR backports the change of SPARK-36129 (#33333) which upgrades `commons-compress` from `1.20` to `1.21` to deal with CVEs. ### Why are the changes needed? Some CVEs which affect `commons-compress 1.20` are reported and fixed in `1.21`. https://commons.apache.org/proper/commons-compress/security-reports.html * CVE-2021-35515 * CVE-2021-35516 * CVE-2021-35517 * CVE-2021-36090 The severities are reported as low for all the CVEs but it would be better to deal with them just in case. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? CI. Closes #33337 from sarutak/backport-SPARK-36129-branch-3.0. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 14 July 2021, 14:02:09 UTC |
| 5e7ddaa | Liang-Chi Hsieh | 13 July 2021, 21:29:09 UTC | [SPARK-36109][SS][TEST][3.0] Check data after adding data to topic in KafkaSourceStressSuite ### What changes were proposed in this pull request? This patch proposes to check data after adding data to topic in `KafkaSourceStressSuite`. ### Why are the changes needed? The test logic in `KafkaSourceStressSuite` is not stable. For example, https://github.com/apache/spark/runs/3049244904. Once we add data to a topic and then delete the topic before checking data, the expected answer is different to retrieved data from the sink. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests. Closes #33326 from viirya/stream-assert-3.0. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 13 July 2021, 21:29:09 UTC |
| da8943b | Kousuke Saruta | 13 July 2021, 12:28:47 UTC | [SPARK-36081][SPARK-36066][SQL] Update the document about the behavior change of trimming characters for cast ### What changes were proposed in this pull request? This PR modifies comment for `UTF8String.trimAll` and`sql-migration-guide.mld`. The comment for `UTF8String.trimAll` says like as follows. ``` Trims whitespaces ({literal <=} ASCII 32) from both ends of this string. ``` Similarly, `sql-migration-guide.md` mentions about the behavior of `cast` like as follows. ``` In Spark 3.0, when casting string value to integral types(tinyint, smallint, int and bigint), datetime types(date, timestamp and interval) and boolean type, the leading and trailing whitespaces (<= ASCII 32) will be trimmed before converted to these type values, for example, `cast(' 1\t' as int)` results `1`, `cast(' 1\t' as boolean)` results `true`, `cast('2019-10-10\t as date)` results the date value `2019-10-10`. In Spark version 2.4 and below, when casting string to integrals and booleans, it does not trim the whitespaces from both ends; the foregoing results is `null`, while to datetimes, only the trailing spaces (= ASCII 32) are removed. ``` But SPARK-32559 (#29375) changed the behavior and only whitespace ASCII characters will be trimmed since Spark 3.0.1. ### Why are the changes needed? To follow the previous change. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Confirmed the document built by the following command. ``` SKIP_API=1 bundle exec jekyll build ``` Closes #33287 from sarutak/fix-utf8string-trim-issue. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 57a4f310df30257c5d7e545c962b59767807d0c7) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 13 July 2021, 12:29:55 UTC |