https://github.com/apache/spark
- HEAD
- refs/heads/branch-0.5
- refs/heads/branch-0.6
- refs/heads/branch-0.7
- refs/heads/branch-0.8
- refs/heads/branch-0.9
- refs/heads/branch-1.0
- refs/heads/branch-1.0-jdbc
- refs/heads/branch-1.1
- refs/heads/branch-1.2
- refs/heads/branch-1.3
- refs/heads/branch-1.4
- refs/heads/branch-1.5
- refs/heads/branch-1.6
- refs/heads/branch-2.0
- refs/heads/branch-2.1
- refs/heads/branch-2.2
- refs/heads/branch-2.3
- refs/heads/branch-2.4
- refs/heads/branch-3.0
- refs/heads/branch-3.1
- refs/heads/branch-3.2
- refs/heads/branch-3.3
- refs/heads/branch-3.4
- refs/heads/branch-3.5
- refs/heads/master
- refs/remotes/origin/branch-0.8
- refs/remotes/origin/td-rdd-save
- refs/tags/0.3-scala-2.8
- refs/tags/0.3-scala-2.9
- refs/tags/2.0.0-preview
- refs/tags/alpha-0.1
- refs/tags/alpha-0.2
- refs/tags/v0.5.0
- refs/tags/v0.5.1
- refs/tags/v0.5.2
- refs/tags/v0.6.0
- refs/tags/v0.6.0-yarn
- refs/tags/v0.6.1
- refs/tags/v0.6.2
- refs/tags/v0.7.0
- refs/tags/v0.7.0-bizo-1
- refs/tags/v0.7.1
- refs/tags/v0.7.2
- refs/tags/v0.9.1
- refs/tags/v0.9.2
- refs/tags/v1.0.0
- refs/tags/v1.0.1
- refs/tags/v1.0.2
- refs/tags/v1.1.0
- refs/tags/v1.1.1
- refs/tags/v1.2.0
- refs/tags/v1.2.1
- refs/tags/v1.2.2
- refs/tags/v1.3.0
- refs/tags/v1.3.1
- refs/tags/v1.4.0
- refs/tags/v1.4.1
- refs/tags/v1.5.0-rc1
- refs/tags/v1.5.0-rc2
- refs/tags/v1.5.0-rc3
- refs/tags/v1.5.1
- refs/tags/v1.6.0
- refs/tags/v1.6.1
- refs/tags/v1.6.2
- refs/tags/v1.6.3
- refs/tags/v2.0.0
- refs/tags/v2.0.1
- refs/tags/v2.0.2
- refs/tags/v2.1.0
- refs/tags/v2.1.1
- refs/tags/v2.1.2
- refs/tags/v2.1.2-rc1
- refs/tags/v2.1.2-rc2
- refs/tags/v2.1.2-rc3
- refs/tags/v2.1.2-rc4
- refs/tags/v2.1.3
- refs/tags/v2.1.3-rc1
- refs/tags/v2.1.3-rc2
- refs/tags/v2.2.0
- refs/tags/v2.2.1
- refs/tags/v2.2.1-rc1
- refs/tags/v2.2.1-rc2
- refs/tags/v2.2.2
- refs/tags/v2.2.2-rc1
- refs/tags/v2.2.2-rc2
- refs/tags/v2.2.3
- refs/tags/v2.2.3-rc1
- refs/tags/v2.3.0
- refs/tags/v2.3.0-rc1
- refs/tags/v2.3.0-rc2
- refs/tags/v2.3.0-rc3
- refs/tags/v2.3.0-rc4
- refs/tags/v2.3.1
- refs/tags/v2.3.1-rc1
- refs/tags/v2.3.1-rc2
- refs/tags/v2.3.1-rc3
- refs/tags/v2.3.1-rc4
- refs/tags/v2.3.2
- refs/tags/v2.3.2-rc1
- refs/tags/v2.3.2-rc2
- refs/tags/v2.3.2-rc3
- refs/tags/v2.3.2-rc4
- refs/tags/v2.3.2-rc5
- refs/tags/v2.3.2-rc6
- refs/tags/v2.3.3
- refs/tags/v2.3.3-rc1
- refs/tags/v2.3.3-rc2
- refs/tags/v2.3.4
- refs/tags/v2.3.4-rc1
- refs/tags/v2.4.0
- refs/tags/v2.4.0-rc1
- refs/tags/v2.4.0-rc2
- refs/tags/v2.4.0-rc3
- refs/tags/v2.4.0-rc4
- refs/tags/v2.4.0-rc5
- refs/tags/v2.4.1
- refs/tags/v2.4.1-rc1
- refs/tags/v2.4.1-rc2
- refs/tags/v2.4.1-rc3
- refs/tags/v2.4.1-rc4
- refs/tags/v2.4.1-rc5
- refs/tags/v2.4.1-rc6
- refs/tags/v2.4.1-rc7
- refs/tags/v2.4.1-rc8
- refs/tags/v2.4.1-rc9
- refs/tags/v2.4.2
- refs/tags/v2.4.2-rc1
- refs/tags/v2.4.3
- refs/tags/v2.4.3-rc1
- refs/tags/v2.4.4
- refs/tags/v2.4.4-rc1
- refs/tags/v2.4.4-rc2
- refs/tags/v2.4.4-rc3
- refs/tags/v2.4.5
- refs/tags/v2.4.5-rc1
- refs/tags/v2.4.5-rc2
- refs/tags/v2.4.6
- refs/tags/v2.4.6-rc1
- refs/tags/v2.4.6-rc2
- refs/tags/v2.4.6-rc3
- refs/tags/v2.4.6-rc4
- refs/tags/v2.4.6-rc5
- refs/tags/v2.4.6-rc6
- refs/tags/v2.4.6-rc7
- refs/tags/v2.4.6-rc8
- refs/tags/v2.4.7
- refs/tags/v2.4.7-rc1
- refs/tags/v2.4.7-rc2
- refs/tags/v2.4.7-rc3
- refs/tags/v2.4.8
- refs/tags/v2.4.8-rc1
- refs/tags/v2.4.8-rc2
- refs/tags/v2.4.8-rc3
- refs/tags/v2.4.8-rc4
- refs/tags/v3.0.0
- refs/tags/v3.0.0-preview2
- refs/tags/v3.0.0-preview2-rc1
- refs/tags/v3.0.0-preview2-rc2
- refs/tags/v3.0.0-rc1
- refs/tags/v3.0.0-rc2
- refs/tags/v3.0.0-rc3
- refs/tags/v3.0.1
- refs/tags/v3.0.1-rc1
- refs/tags/v3.0.1-rc2
- refs/tags/v3.0.1-rc3
- refs/tags/v3.0.2
- refs/tags/v3.0.2-rc1
- refs/tags/v3.0.3
- refs/tags/v3.0.3-rc1
- refs/tags/v3.1.0-rc1
- refs/tags/v3.1.1
- refs/tags/v3.1.1-rc1
- refs/tags/v3.1.1-rc2
- refs/tags/v3.1.1-rc3
- refs/tags/v3.1.2
- refs/tags/v3.1.2-rc1
- refs/tags/v3.1.3
- refs/tags/v3.1.3-rc1
- refs/tags/v3.1.3-rc2
- refs/tags/v3.1.3-rc3
- refs/tags/v3.1.3-rc4
- refs/tags/v3.2.0
- refs/tags/v3.2.0-rc1
- refs/tags/v3.2.0-rc2
- refs/tags/v3.2.0-rc3
- refs/tags/v3.2.0-rc4
- refs/tags/v3.2.0-rc5
- refs/tags/v3.2.0-rc6
- refs/tags/v3.2.0-rc7
- refs/tags/v3.2.1
- refs/tags/v3.2.1-rc1
- refs/tags/v3.2.1-rc2
- refs/tags/v3.2.2
- refs/tags/v3.2.2-rc1
- refs/tags/v3.2.3
- refs/tags/v3.2.3-rc1
- refs/tags/v3.2.4
- refs/tags/v3.2.4-rc1
- refs/tags/v3.3.0
- refs/tags/v3.3.0-rc1
- refs/tags/v3.3.0-rc2
- refs/tags/v3.3.0-rc3
- refs/tags/v3.3.0-rc4
- refs/tags/v3.3.0-rc5
- refs/tags/v3.3.0-rc6
- refs/tags/v3.3.1
- refs/tags/v3.3.1-rc1
- refs/tags/v3.3.1-rc2
- refs/tags/v3.3.1-rc3
- refs/tags/v3.3.1-rc4
- refs/tags/v3.3.2
- refs/tags/v3.3.2-rc1
- refs/tags/v3.3.3
- refs/tags/v3.3.3-rc1
- refs/tags/v3.3.4
- refs/tags/v3.3.4-rc1
- refs/tags/v3.4.0
- refs/tags/v3.4.0-rc1
- refs/tags/v3.4.0-rc2
- refs/tags/v3.4.0-rc3
- refs/tags/v3.4.0-rc4
- refs/tags/v3.4.0-rc5
- refs/tags/v3.4.0-rc6
- refs/tags/v3.4.0-rc7
- refs/tags/v3.4.1
- refs/tags/v3.4.1-rc1
- refs/tags/v3.4.2
- refs/tags/v3.4.2-rc1
- refs/tags/v3.5.0
- refs/tags/v3.5.0-rc1
- refs/tags/v3.5.0-rc2
- refs/tags/v3.5.0-rc3
- refs/tags/v3.5.0-rc4
- refs/tags/v3.5.0-rc5
- refs/tags/v3.5.1
- refs/tags/v3.5.1-rc1
- refs/tags/v3.5.1-rc2
- c7733d35c35748f0953ab371f515619c2db420ef
Take a new snapshot of a software origin
If the archived software origin currently browsed is not synchronized with its upstream version (for instance when new commits have been issued), you can explicitly request Software Heritage to take a new snapshot of it.
Use the form below to proceed. Once a request has been submitted and accepted, it will be processed as soon as possible. You can then check its processing state by visiting this dedicated page.
Processing "take a new snapshot" request ...
Permalinks
To reference or cite the objects present in the Software Heritage archive, permalinks based on SoftWare Hash IDentifiers (SWHIDs) must be used.
Select below a type of object currently browsed in order to display its associated SWHID and permalink.
| Revision | Author | Date | Message | Commit Date |
|---|---|---|---|---|
| c7733d3 | fhygh | 18 April 2022, 15:11:32 UTC | [SPARK-37643][SQL] when charVarcharAsString is true, for char datatype predicate query should skip rpadding rule after add ApplyCharTypePadding rule, when predicate query column data type is char, if column value length is less then defined, will be right-padding, then query will get incorrect result fix query incorrect issue when predicate column data type is char, so in this case when charVarcharAsString is true, we should skip the rpadding rule. before this fix, if we query with char data type for predicate, then we should be careful to set charVarcharAsString to true. add new UT. Closes #36187 from fhygh/charpredicatequery. Authored-by: fhygh <283452027@qq.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit c1ea8b446d00dd0123a0fad93a3e143933419a76) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 18 April 2022, 15:19:33 UTC |
| 95fb780 | Sean Owen | 17 April 2022, 23:54:45 UTC | [SPARK-38816][ML][DOCS] Fix comment about choice of initial factors in ALS ### What changes were proposed in this pull request? Change a comment in ALS code to match impl. The comment refers to taking the absolute value of a Normal(0,1) value, but it doesn't. ### Why are the changes needed? The docs and impl are inconsistent. The current behavior actually seems fine, desirable, so, change the comments. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests Closes #36228 from srowen/SPARK-38816. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit b2b350b1566b8b45c6dba2f79ccbc2dc4e95816d) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 17 April 2022, 23:55:29 UTC |
| 21c7abc | fhygh | 15 April 2022, 11:42:18 UTC | [SPARK-38892][SQL][TESTS] Fix a test case schema assertion of ParquetPartitionDiscoverySuite ### What changes were proposed in this pull request? in ParquetPartitionDiscoverySuite, thare are some assert have no parctical significance. `assert(input.schema.sameType(input.schema))` ### Why are the changes needed? fix this to assert the actual result. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? updated testsuites Closes #36189 from fhygh/assertutfix. Authored-by: fhygh <283452027@qq.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 4835946de2ef71b176da5106e9b6c2706e182722) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 15 April 2022, 11:43:07 UTC |
| 2684762 | Hyukjin Kwon | 07 April 2022, 00:44:36 UTC | Revert "[MINOR][SQL][SS][DOCS] Add varargs to Dataset.observe(String, ..) with a documentation fix" This reverts commit dea607fc6040fc9f252632b6c73d5948ada02a98. | 07 April 2022, 00:44:36 UTC |
| dea607f | Hyukjin Kwon | 06 April 2022, 08:26:17 UTC | [MINOR][SQL][SS][DOCS] Add varargs to Dataset.observe(String, ..) with a documentation fix ### What changes were proposed in this pull request? This PR proposes two minor changes: - Fixes the example at `Dataset.observe(String, ...)` - Adds `varargs` to be consistent with another overloaded version: `Dataset.observe(Observation, ..)` ### Why are the changes needed? To provide a correct example, support Java APIs properly with `varargs` and API consistency. ### Does this PR introduce _any_ user-facing change? Yes, the example is fixed in the documentation. Additionally Java users should be able to use `Dataset.observe(String, ..)` per `varargs`. ### How was this patch tested? Manually tested. CI should verify the changes too. Closes #36084 from HyukjinKwon/minor-docs. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit fb3f380b3834ca24947a82cb8d87efeae6487664) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 06 April 2022, 08:26:56 UTC |
| 1a7b3a4 | Kent Yao | 03 April 2022, 17:30:38 UTC | [SPARK-38446][CORE] Fix deadlock between ExecutorClassLoader and FileDownloadCallback caused by Log4j ### What changes were proposed in this pull request? While `log4j.ignoreTCL/log4j2.ignoreTCL` is false, which is the default, it uses the context ClassLoader for the current Thread, see `org.apache.logging.log4j.util.LoaderUtil.loadClass`. While ExecutorClassLoader try to loadClass through remotely though the FileDownload, if error occurs, we will long on debug level, and `log4j...LoaderUtil` will be blocked by ExecutorClassLoader acquired classloading lock. Fortunately, it only happens when ThresholdFilter's level is `debug`. or we can set `log4j.ignoreTCL/log4j2.ignoreTCL` to true, but I don't know what else it will cause. So in this PR, I simply remove the debug log which cause this deadlock ### Why are the changes needed? fix deadlock ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? https://github.com/apache/incubator-kyuubi/pull/2046#discussion_r821414439, with a ut in kyuubi project, resolved(https://github.com/apache/incubator-kyuubi/actions/runs/1950222737) ### Additional Resources [ut.jstack.txt](https://github.com/apache/spark/files/8206457/ut.jstack.txt) Closes #35765 from yaooqinn/SPARK-38446. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit aef674564ff12e78bd2f30846e3dcb69988249ae) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 03 April 2022, 17:31:10 UTC |
| f677272 | Dereck Li | 01 April 2022, 14:54:11 UTC | [SPARK-38754][SQL][TEST][3.1] Using EquivalentExpressions getEquivalentExprs function instead of getExprState at SubexpressionEliminationSuite ### What changes were proposed in this pull request? This pr use EquivalentExpressions getEquivalentExprs function instead of getExprState at SubexpressionEliminationSuite, and remove cpus paramter. ### Why are the changes needed? Fixes build error ### Does this PR introduce _any_ user-facing change? NO ### How was this patch tested? CI Tests Closes #36033 from monkeyboy123/SPARK-38754. Authored-by: Dereck Li <monkeyboy.ljh@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 01 April 2022, 14:54:11 UTC |
| e12c9e7 | Dereck Li | 31 March 2022, 13:33:08 UTC | [SPARK-38333][SQL] PlanExpression expression should skip addExprTree function in Executor It is master branch pr [SPARK-38333](https://github.com/apache/spark/pull/35662) Bug fix, it is potential issue. No UT Closes #36012 from monkeyboy123/spark-38333. Authored-by: Dereck Li <monkeyboy.ljh@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit a40acd4392a8611062763ce6ec7bc853d401c646) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 31 March 2022, 13:37:22 UTC |
| 4b3f8d4 | Dongjoon Hyun | 30 March 2022, 15:26:41 UTC | [SPARK-38652][K8S] `uploadFileUri` should preserve file scheme ### What changes were proposed in this pull request? This PR replaces `new Path(fileUri.getPath)` with `new Path(fileUri)`. By using `Path` class constructor with URI parameter, we can preserve file scheme. ### Why are the changes needed? If we use, `Path` class constructor with `String` parameter, it loses file scheme information. Although the original code works so far, it fails at Apache Hadoop 3.3.2 and breaks dependency upload feature which is covered by K8s Minikube integration tests. ```scala test("uploadFileUri") { val fileUri = org.apache.spark.util.Utils.resolveURI("/tmp/1.txt") assert(new Path(fileUri).toString == "file:/private/tmp/1.txt") assert(new Path(fileUri.getPath).toString == "/private/tmp/1.txt") } ``` ### Does this PR introduce _any_ user-facing change? No, this will prevent a regression at Apache Spark 3.3.0 instead. ### How was this patch tested? Pass the CIs. In addition, this PR and #36009 will recover K8s IT `DepsTestsSuite`. Closes #36010 from dongjoon-hyun/SPARK-38652. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit cab8aa1c4fe66c4cb1b69112094a203a04758f76) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 30 March 2022, 15:27:20 UTC |
| b3e3110 | Bruce Robbins | 27 March 2022, 00:31:49 UTC | [SPARK-38528][SQL][3.2] Eagerly iterate over aggregate sequence when building project list in `ExtractGenerator` Backport of #35837. When building the project list from an aggregate sequence in `ExtractGenerator`, convert the aggregate sequence to an `IndexedSeq` before performing the flatMap operation. This query fails with a `NullPointerException`: ``` val df = Seq(1, 2, 3).toDF("v") df.select(Stream(explode(array(min($"v"), max($"v"))), sum($"v")): _*).collect ``` If you change `Stream` to `Seq`, then it succeeds. `ExtractGenerator` uses a flatMap operation over `aggList` for two purposes: - To produce a new aggregate list - to update `projectExprs` (which is initialized as an array of nulls). When `aggList` is a `Stream`, the flatMap operation evaluates lazily, so all entries in `projectExprs` after the first will still be null when the rule completes. Changing `aggList` to an `IndexedSeq` forces the flatMap to evaluate eagerly. No New unit test Closes #35851 from bersprockets/generator_aggregate_issue_32. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 7842621ff50001e1cde8e2e6a2fc48c2cdcaf3d4) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 27 March 2022, 00:32:55 UTC |
| 789ec13 | mcdull-zhang | 26 March 2022, 04:48:08 UTC | [SPARK-38570][SQL][3.1] Incorrect DynamicPartitionPruning caused by Literal This is a backport of #35878 to branch 3.1. The return value of Literal.references is an empty AttributeSet, so Literal is mistaken for a partition column. For example, the sql in the test case will generate such a physical plan when the adaptive is closed: ```tex *(4) Project [store_id#5281, date_id#5283, state_province#5292] +- *(4) BroadcastHashJoin [store_id#5281], [store_id#5291], Inner, BuildRight, false :- Union : :- *(1) Project [4 AS store_id#5281, date_id#5283] : : +- *(1) Filter ((isnotnull(date_id#5283) AND (date_id#5283 >= 1300)) AND dynamicpruningexpression(4 IN dynamicpruning#5300)) : : : +- ReusedSubquery SubqueryBroadcast dynamicpruning#5300, 0, [store_id#5291], [id=#336] : : +- *(1) ColumnarToRow : : +- FileScan parquet default.fact_sk[date_id#5283,store_id#5286] Batched: true, DataFilters: [isnotnull(date_id#5283), (date_id#5283 >= 1300)], Format: Parquet, Location: CatalogFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache.s..., PartitionFilters: [dynamicpruningexpression(4 IN dynamicpruning#5300)], PushedFilters: [IsNotNull(date_id), GreaterThanOrEqual(date_id,1300)], ReadSchema: struct<date_id:int> : : +- SubqueryBroadcast dynamicpruning#5300, 0, [store_id#5291], [id=#336] : : +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)),false), [id=#335] : : +- *(1) Project [store_id#5291, state_province#5292] : : +- *(1) Filter (((isnotnull(country#5293) AND (country#5293 = US)) AND ((store_id#5291 <=> 4) OR (store_id#5291 <=> 5))) AND isnotnull(store_id#5291)) : : +- *(1) ColumnarToRow : : +- FileScan parquet default.dim_store[store_id#5291,state_province#5292,country#5293] Batched: true, DataFilters: [isnotnull(country#5293), (country#5293 = US), ((store_id#5291 <=> 4) OR (store_id#5291 <=> 5)), ..., Format: Parquet, Location: InMemoryFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache...., PartitionFilters: [], PushedFilters: [IsNotNull(country), EqualTo(country,US), Or(EqualNullSafe(store_id,4),EqualNullSafe(store_id,5))..., ReadSchema: struct<store_id:int,state_province:string,country:string> : +- *(2) Project [5 AS store_id#5282, date_id#5287] : +- *(2) Filter ((isnotnull(date_id#5287) AND (date_id#5287 <= 1000)) AND dynamicpruningexpression(5 IN dynamicpruning#5300)) : : +- ReusedSubquery SubqueryBroadcast dynamicpruning#5300, 0, [store_id#5291], [id=#336] : +- *(2) ColumnarToRow : +- FileScan parquet default.fact_stats[date_id#5287,store_id#5290] Batched: true, DataFilters: [isnotnull(date_id#5287), (date_id#5287 <= 1000)], Format: Parquet, Location: CatalogFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache.s..., PartitionFilters: [dynamicpruningexpression(5 IN dynamicpruning#5300)], PushedFilters: [IsNotNull(date_id), LessThanOrEqual(date_id,1000)], ReadSchema: struct<date_id:int> : +- ReusedSubquery SubqueryBroadcast dynamicpruning#5300, 0, [store_id#5291], [id=#336] +- ReusedExchange [store_id#5291, state_province#5292], BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)),false), [id=#335] ``` after this pr: ```tex *(4) Project [store_id#5281, date_id#5283, state_province#5292] +- *(4) BroadcastHashJoin [store_id#5281], [store_id#5291], Inner, BuildRight, false :- Union : :- *(1) Project [4 AS store_id#5281, date_id#5283] : : +- *(1) Filter (isnotnull(date_id#5283) AND (date_id#5283 >= 1300)) : : +- *(1) ColumnarToRow : : +- FileScan parquet default.fact_sk[date_id#5283,store_id#5286] Batched: true, DataFilters: [isnotnull(date_id#5283), (date_id#5283 >= 1300)], Format: Parquet, Location: CatalogFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache.s..., PartitionFilters: [], PushedFilters: [IsNotNull(date_id), GreaterThanOrEqual(date_id,1300)], ReadSchema: struct<date_id:int> : +- *(2) Project [5 AS store_id#5282, date_id#5287] : +- *(2) Filter (isnotnull(date_id#5287) AND (date_id#5287 <= 1000)) : +- *(2) ColumnarToRow : +- FileScan parquet default.fact_stats[date_id#5287,store_id#5290] Batched: true, DataFilters: [isnotnull(date_id#5287), (date_id#5287 <= 1000)], Format: Parquet, Location: CatalogFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache.s..., PartitionFilters: [], PushedFilters: [IsNotNull(date_id), LessThanOrEqual(date_id,1000)], ReadSchema: struct<date_id:int> +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)),false), [id=#326] +- *(3) Project [store_id#5291, state_province#5292] +- *(3) Filter (((isnotnull(country#5293) AND (country#5293 = US)) AND ((store_id#5291 <=> 4) OR (store_id#5291 <=> 5))) AND isnotnull(store_id#5291)) +- *(3) ColumnarToRow +- FileScan parquet default.dim_store[store_id#5291,state_province#5292,country#5293] Batched: true, DataFilters: [isnotnull(country#5293), (country#5293 = US), ((store_id#5291 <=> 4) OR (store_id#5291 <=> 5)), ..., Format: Parquet, Location: InMemoryFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache...., PartitionFilters: [], PushedFilters: [IsNotNull(country), EqualTo(country,US), Or(EqualNullSafe(store_id,4),EqualNullSafe(store_id,5))..., ReadSchema: struct<store_id:int,state_province:string,country:string> ``` Execution performance improvement No Added unit test Closes #35967 from mcdull-zhang/spark_38570_3.2. Authored-by: mcdull-zhang <work4dong@163.com> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit 8621914e2052eeab25e6ac4e7d5f48b5570c71f7) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 26 March 2022, 05:27:25 UTC |
| b0b226e | Hyukjin Kwon | 24 March 2022, 03:12:38 UTC | [SPARK-38631][CORE] Uses Java-based implementation for un-tarring at Utils.unpack ### What changes were proposed in this pull request? This PR proposes to use `FileUtil.unTarUsingJava` that is a Java implementation for un-tar `.tar` files. `unTarUsingJava` is not public but it exists in all Hadoop versions from 2.1+, see HADOOP-9264. The security issue reproduction requires a non-Windows platform, and a non-gzipped TAR archive file name (contents don't matter). ### Why are the changes needed? There is a risk for arbitrary shell command injection via `Utils.unpack` when the filename is controlled by a malicious user. This is due to an issue in Hadoop's `unTar`, that is not properly escaping the filename before passing to a shell command:https://github.com/apache/hadoop/blob/trunk/hadoop-common-project/hadoop-common/src/main/java/org/apache/hadoop/fs/FileUtil.java#L904 ### Does this PR introduce _any_ user-facing change? Yes, it prevents a security issue that, previously, allowed users to execute arbitrary shall command. ### How was this patch tested? Manually tested in local, and existing test cases should cover. Closes #35946 from HyukjinKwon/SPARK-38631. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 057c051285ec32c665fb458d0670c1c16ba536b2) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 24 March 2022, 03:13:11 UTC |
| 43c6b91 | Kent Yao | 23 March 2022, 09:25:47 UTC | resolve conflicts | 23 March 2022, 09:31:06 UTC |
| 25ac5fc | huangmaoyang2 | 23 March 2022, 06:06:58 UTC | [SPARK-38629][SQL][DOCS] Two links beneath Spark SQL Guide/Data Sources do not work properly SPARK-38629 Two links beneath Spark SQL Guide/Data Sources do not work properly ### What changes were proposed in this pull request? Two typos have been corrected in sql-data-sources.md under Spark's docs directory. ### Why are the changes needed? Two links under latest documentation [Spark SQL Guide/Data Sources](https://spark.apache.org/docs/latest/sql-data-sources.html) do not work properly, when click 'Ignore Corrupt File' or 'Ignore Missing Files', it does redirect me to the right page, but does not scroll to the right section. This issue actually has been there since v3.0.0. ### Does this PR introduce _any_ user-facing change? Yes ### How was this patch tested? I've built the documentation locally and tested my change. Closes #35944 from morvenhuang/SPARK-38629. Authored-by: huangmaoyang2 <huangmaoyang1@jd.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit ac9ae98011424a030a6ef264caf077b8873e251d) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 23 March 2022, 06:07:34 UTC |
| 674feec | Yimin | 22 March 2022, 10:24:12 UTC | [SPARK-38579][SQL][WEBUI] Requesting Restful API can cause NullPointerException ### What changes were proposed in this pull request? Added null check for `exec.metricValues`. ### Why are the changes needed? When requesting Restful API {baseURL}/api/v1/applications/$appId/sql/$executionId which is introduced by this PR https://github.com/apache/spark/pull/28208, it can cause NullPointerException. The root cause is, when calling method doUpdate() of `LiveExecutionData`, `metricsValues` can be null. Then, when statement `printableMetrics(graph.allNodes, exec.metricValues)` is executed, it will throw NullPointerException. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Tested manually. Closes #35884 from yym1995/fix-npe. Lead-authored-by: Yimin <yimin.y@outlook.com> Co-authored-by: Yimin Yang <26797163+yym1995@users.noreply.github.com> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit 99992a4e050a00564049be6938f5734876c17518) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 22 March 2022, 10:25:33 UTC |
| 7a607b7 | Dongjoon Hyun | 13 March 2022, 03:33:23 UTC | [SPARK-38538][K8S][TESTS] Fix driver environment verification in BasicDriverFeatureStepSuite ### What changes were proposed in this pull request? This PR aims to fix the driver environment verification logic in `BasicDriverFeatureStepSuite`. ### Why are the changes needed? When SPARK-25876 added a test logic at Apache Spark 3.0.0, it used `envs(v) === v` instead of `envs(k) === v`. https://github.com/apache/spark/blob/c032928515e74367137c668ce692d8fd53696485/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/deploy/k8s/features/BasicDriverFeatureStepSuite.scala#L94-L96 This bug was hidden because the test key-value pairs have identical set. If we have different strings for keys and values, the test case fails. https://github.com/apache/spark/blob/c032928515e74367137c668ce692d8fd53696485/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/deploy/k8s/features/BasicDriverFeatureStepSuite.scala#L42-L44 ### Does this PR introduce _any_ user-facing change? To have a correct test coverage. ### How was this patch tested? Pass the CIs. Closes #35828 from dongjoon-hyun/SPARK-38538. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit 6becf4e93e68e36fbcdc82768de497d86072abeb) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 13 March 2022, 03:34:22 UTC |
| 968dd47 | Jungtaek Lim | 09 March 2022, 02:03:57 UTC | [SPARK-38412][SS] Fix the swapped sequence of from and to in StateSchemaCompatibilityChecker ### What changes were proposed in this pull request? This PR fixes the StateSchemaCompatibilityChecker which mistakenly swapped `from` (should be provided schema) and `to` (should be existing schema). ### Why are the changes needed? The bug mistakenly allows the case where it should not be allowed, and disallows the case where it should be allowed. That allows nullable column to be stored into non-nullable column, which should be prohibited. This is less likely making runtime problem since state schema is conceptual one and row can be stored even not respecting the state schema. The opposite case is worse, that disallows non-nullable column to be stored into nullable column, which should be allowed. Spark fails the query for this case. ### Does this PR introduce _any_ user-facing change? Yes, after the fix, storing non-nullable column into nullable column for state will be allowed, which should have been allowed. ### How was this patch tested? Modified UTs. Closes #35731 from HeartSaVioR/SPARK-38412. Authored-by: Jungtaek Lim <kabhwan.opensource@gmail.com> Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com> (cherry picked from commit 43c7824bba40ebfb64dcd50d8d0e84b5a4d3c8c7) Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com> | 09 March 2022, 02:22:22 UTC |
| 0496173 | Karen Feng | 09 March 2022, 01:34:01 UTC | [SPARK-37865][SQL] Fix union deduplication correctness bug Fixes a correctness bug in `Union` in the case that there are duplicate output columns. Previously, duplicate columns on one side of the union would result in a duplicate column being output on the other side of the union. To do so, we go through the union’s child’s output and find the duplicates. For each duplicate set, there is a first duplicate: this one is left alone. All following duplicates are aliased and given a tag; this tag is used to remove ambiguity during resolution. As the first duplicate is left alone, the user can still select it, avoiding a breaking change. As the later duplicates are given new expression IDs, this fixes the correctness bug. Output of union with duplicate columns in the children was incorrect Example query: ``` SELECT a, a FROM VALUES (1, 1), (1, 2) AS t1(a, b) UNION ALL SELECT c, d FROM VALUES (2, 2), (2, 3) AS t2(c, d) ``` Result before: ``` a | a _ | _ 1 | 1 1 | 1 2 | 2 2 | 2 ``` Result after: ``` a | a _ | _ 1 | 1 1 | 1 2 | 2 2 | 3 ``` Unit tests Closes #35760 from karenfeng/spark-37865. Authored-by: Karen Feng <karen.feng@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 59ce0a706cb52a54244a747d0a070b61f5cddd1c) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 09 March 2022, 01:36:41 UTC |
| 0277139 | Rob Reeves | 08 March 2022, 18:20:43 UTC | [SPARK-38309][CORE] Fix SHS `shuffleTotalReads` and `shuffleTotalBlocks` percentile metrics ### What changes were proposed in this pull request? #### Background In PR #26508 (SPARK-26260) the SHS stage metric percentiles were updated to only include successful tasks when using disk storage. It did this by making the values for each metric negative when the task is not in a successful state. This approach was chosen to avoid breaking changes to disk storage. See [this comment](https://github.com/apache/spark/pull/26508#issuecomment-554540314) for context. To get the percentiles, it reads the metric values, starting at 0, in ascending order. This filters out all tasks that are not successful because the values are less than 0. To get the percentile values it scales the percentiles to the list index of successful tasks. For example if there are 200 tasks and you want percentiles [0, 25, 50, 75, 100] the lookup indexes in the task collection are [0, 50, 100, 150, 199]. #### Issue For metrics 1) shuffle total reads and 2) shuffle total blocks, PR #26508 incorrectly makes the metric indices positive. This means tasks that are not successful are included in the percentile calculations. The percentile lookup index calculation is still based on the number of successful task so the wrong task metric is returned for a given percentile. This was not caught because the unit test only verified values for one metric, `executorRunTime`. #### Fix The index values for `SHUFFLE_TOTAL_READS` and `SHUFFLE_TOTAL_BLOCKS` should not convert back to positive metric values for tasks that are not successful. I believe this was done because the metrics values are summed from two other metrics. Using the raw values still creates the desired outcome. `negative + negative = negative` and `positive + positive = positive`. There is no case where one metric will be negative and one will be positive. I also verified that these two metrics are only used in the percentile calculations where only successful tasks are used. ### Why are the changes needed? This change is required so that the SHS stage percentile metrics for shuffle read bytes and shuffle total blocks are correct. ### Does this PR introduce _any_ user-facing change? Yes. The user will see the correct percentile values for the stage summary shuffle read bytes. ### How was this patch tested? I updated the unit test to verify the percentile values for every task metric. I also modified the unit test to have unique values for every metric. Previously the test had the same metrics for every field. This would not catch bugs like the wrong field being read by accident. I manually validated the fix in the UI. **BEFORE**  **AFTER**  I manually validated the fix in the task summary API (`/api/v1/applications/application_123/1/stages/14/0/taskSummary\?quantiles\=0,0.25,0.5,0.75,1.0`). See `shuffleReadMetrics.readBytes` and `shuffleReadMetrics.totalBlocksFetched`. Before: ```json { "quantiles":[ 0.0, 0.25, 0.5, 0.75, 1.0 ], "shuffleReadMetrics":{ "readBytes":[ -2.0, -2.0, -2.0, -2.0, 5.63718681E8 ], "totalBlocksFetched":[ -2.0, -2.0, -2.0, -2.0, 2.0 ], ... }, ... } ``` After: ```json { "quantiles":[ 0.0, 0.25, 0.5, 0.75, 1.0 ], "shuffleReadMetrics":{ "readBytes":[ 5.62865286E8, 5.63779421E8, 5.63941681E8, 5.64327925E8, 5.7674183E8 ], "totalBlocksFetched":[ 2.0, 2.0, 2.0, 2.0, 2.0 ], ... } ... } ``` Closes #35637 from robreeves/SPARK-38309. Authored-by: Rob Reeves <roreeves@linkedin.com> Signed-off-by: Mridul Muralidharan <mridul<at>gmail.com> (cherry picked from commit 0ad76777e76f60d1aea0eed0a2a7bff20c7567d3) Signed-off-by: Mridul Muralidharan <mridulatgmail.com> | 08 March 2022, 18:24:12 UTC |
| 8d70d5d | Cheng Pan | 06 March 2022, 23:41:20 UTC | [SPARK-38411][CORE] Use `UTF-8` when `doMergeApplicationListingInternal` reads event logs ### What changes were proposed in this pull request? Use UTF-8 instead of system default encoding to read event log ### Why are the changes needed? After SPARK-29160, we should always use UTF-8 to read event log, otherwise, if Spark History Server run with different default charset than "UTF-8", will encounter such error. ``` 2022-03-04 12:16:00,143 [3752440] - INFO [log-replay-executor-19:Logging57] - Parsing hdfs://hz-cluster11/spark2-history/application_1640597251469_2453817_1.lz4 for listing data... 2022-03-04 12:16:00,145 [3752442] - ERROR [log-replay-executor-18:Logging94] - Exception while merging application listings java.nio.charset.MalformedInputException: Input length = 1 at java.nio.charset.CoderResult.throwException(CoderResult.java:281) at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:339) at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:178) at java.io.InputStreamReader.read(InputStreamReader.java:184) at java.io.BufferedReader.fill(BufferedReader.java:161) at java.io.BufferedReader.readLine(BufferedReader.java:324) at java.io.BufferedReader.readLine(BufferedReader.java:389) at scala.io.BufferedSource$BufferedLineIterator.hasNext(BufferedSource.scala:74) at scala.collection.Iterator$$anon$20.hasNext(Iterator.scala:884) at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:511) at org.apache.spark.scheduler.ReplayListenerBus.replay(ReplayListenerBus.scala:82) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$doMergeApplicationListing$4(FsHistoryProvider.scala:819) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$doMergeApplicationListing$4$adapted(FsHistoryProvider.scala:801) at org.apache.spark.util.Utils$.tryWithResource(Utils.scala:2626) at org.apache.spark.deploy.history.FsHistoryProvider.doMergeApplicationListing(FsHistoryProvider.scala:801) at org.apache.spark.deploy.history.FsHistoryProvider.mergeApplicationListing(FsHistoryProvider.scala:715) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$checkForLogs$15(FsHistoryProvider.scala:581) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) ``` ### Does this PR introduce _any_ user-facing change? Yes, bug fix. ### How was this patch tested? Verification steps in ubuntu:20.04 1. build `spark-3.3.0-SNAPSHOT-bin-master.tgz` on commit `34618a7ef6` using `dev/make-distribution.sh --tgz --name master` 2. build `spark-3.3.0-SNAPSHOT-bin-SPARK-38411.tgz` on commit `2a8f56038b` using `dev/make-distribution.sh --tgz --name SPARK-38411` 3. switch to UTF-8 using `export LC_ALL=C.UTF-8 && bash` 4. generate event log contains no-ASCII chars. ``` bin/spark-submit \ --master local[*] \ --class org.apache.spark.examples.SparkPi \ --conf spark.eventLog.enabled=true \ --conf spark.user.key='计算圆周率' \ examples/jars/spark-examples_2.12-3.3.0-SNAPSHOT.jar ``` 5. switch to POSIX using `export LC_ALL=POSIX && bash` 6. run `spark-3.3.0-SNAPSHOT-bin-master/sbin/start-history-server.sh` and watch logs <details> ``` Spark Command: /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java -cp /spark-3.3.0-SNAPSHOT-bin-master/conf/:/spark-3.3.0-SNAPSHOT-bin-master/jars/* -Xmx1g org.apache.spark.deploy.history.HistoryServer ======================================== Using Spark's default log4j profile: org/apache/spark/log4j2-defaults.properties 22/03/06 13:37:19 INFO HistoryServer: Started daemon with process name: 48729c3ffc10aa9 22/03/06 13:37:19 INFO SignalUtils: Registering signal handler for TERM 22/03/06 13:37:19 INFO SignalUtils: Registering signal handler for HUP 22/03/06 13:37:19 INFO SignalUtils: Registering signal handler for INT 22/03/06 13:37:21 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 22/03/06 13:37:21 INFO SecurityManager: Changing view acls to: root 22/03/06 13:37:21 INFO SecurityManager: Changing modify acls to: root 22/03/06 13:37:21 INFO SecurityManager: Changing view acls groups to: 22/03/06 13:37:21 INFO SecurityManager: Changing modify acls groups to: 22/03/06 13:37:21 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set() 22/03/06 13:37:21 INFO FsHistoryProvider: History server ui acls disabled; users with admin permissions: ; groups with admin permissions: 22/03/06 13:37:22 INFO Utils: Successfully started service 'HistoryServerUI' on port 18080. 22/03/06 13:37:23 INFO HistoryServer: Bound HistoryServer to 0.0.0.0, and started at http://29c3ffc10aa9:18080 22/03/06 13:37:23 INFO FsHistoryProvider: Parsing file:/tmp/spark-events/local-1646573251839 for listing data... 22/03/06 13:37:25 ERROR FsHistoryProvider: Exception while merging application listings java.nio.charset.MalformedInputException: Input length = 1 at java.nio.charset.CoderResult.throwException(CoderResult.java:281) ~[?:1.8.0_312] at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:339) ~[?:1.8.0_312] at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:178) ~[?:1.8.0_312] at java.io.InputStreamReader.read(InputStreamReader.java:184) ~[?:1.8.0_312] at java.io.BufferedReader.fill(BufferedReader.java:161) ~[?:1.8.0_312] at java.io.BufferedReader.readLine(BufferedReader.java:324) ~[?:1.8.0_312] at java.io.BufferedReader.readLine(BufferedReader.java:389) ~[?:1.8.0_312] at scala.io.BufferedSource$BufferedLineIterator.hasNext(BufferedSource.scala:74) ~[scala-library-2.12.15.jar:?] at scala.collection.Iterator$$anon$20.hasNext(Iterator.scala:886) ~[scala-library-2.12.15.jar:?] at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:513) ~[scala-library-2.12.15.jar:?] at org.apache.spark.scheduler.ReplayListenerBus.replay(ReplayListenerBus.scala:82) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$doMergeApplicationListingInternal$4(FsHistoryProvider.scala:830) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$doMergeApplicationListingInternal$4$adapted(FsHistoryProvider.scala:812) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.util.Utils$.tryWithResource(Utils.scala:2738) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.doMergeApplicationListingInternal(FsHistoryProvider.scala:812) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.doMergeApplicationListing(FsHistoryProvider.scala:758) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.mergeApplicationListing(FsHistoryProvider.scala:718) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$checkForLogs$15(FsHistoryProvider.scala:584) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) [?:1.8.0_312] at java.util.concurrent.FutureTask.run(FutureTask.java:266) [?:1.8.0_312] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_312] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_312] at java.lang.Thread.run(Thread.java:748) [?:1.8.0_312] ``` </details> 7. run `spark-3.3.0-SNAPSHOT-bin-master/sbin/stop-history-server.sh` 8. run `spark-3.3.0-SNAPSHOT-bin-SPARK-38411/sbin/stop-history-server.sh` and watch logs <details> ``` Spark Command: /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java -cp /spark-3.3.0-SNAPSHOT-bin-SPARK-38411/conf/:/spark-3.3.0-SNAPSHOT-bin-SPARK-38411/jars/* -Xmx1g org.apache.spark.deploy.history.HistoryServer ======================================== Using Spark's default log4j profile: org/apache/spark/log4j2-defaults.properties 22/03/06 13:30:54 INFO HistoryServer: Started daemon with process name: 34729c3ffc10aa9 22/03/06 13:30:54 INFO SignalUtils: Registering signal handler for TERM 22/03/06 13:30:54 INFO SignalUtils: Registering signal handler for HUP 22/03/06 13:30:54 INFO SignalUtils: Registering signal handler for INT 22/03/06 13:30:55 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 22/03/06 13:30:56 INFO SecurityManager: Changing view acls to: root 22/03/06 13:30:56 INFO SecurityManager: Changing modify acls to: root 22/03/06 13:30:56 INFO SecurityManager: Changing view acls groups to: 22/03/06 13:30:56 INFO SecurityManager: Changing modify acls groups to: 22/03/06 13:30:56 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set() 22/03/06 13:30:56 INFO FsHistoryProvider: History server ui acls disabled; users with admin permissions: ; groups with admin permissions: 22/03/06 13:30:57 INFO Utils: Successfully started service 'HistoryServerUI' on port 18080. 22/03/06 13:30:57 INFO HistoryServer: Bound HistoryServer to 0.0.0.0, and started at http://29c3ffc10aa9:18080 22/03/06 13:30:57 INFO FsHistoryProvider: Parsing file:/tmp/spark-events/local-1646573251839 for listing data... 22/03/06 13:30:59 INFO FsHistoryProvider: Finished parsing file:/tmp/spark-events/local-1646573251839 ``` </details> Closes #35730 from pan3793/SPARK-38411. Authored-by: Cheng Pan <chengpan@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 135841f257fbb008aef211a5e38222940849cb26) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 06 March 2022, 23:41:47 UTC |
| 8889bf0 | attilapiros | 03 March 2022, 18:37:54 UTC | [SPARK-33206][CORE][3.1] Fix shuffle index cache weight calculation for small index files ### What changes were proposed in this pull request? Increasing the shuffle index weight with a constant number to avoid underestimating retained memory size caused by the bookkeeping objects: the `java.io.File` (depending on the path ~ 960 bytes) object and the `ShuffleIndexInformation` object (~180 bytes). ### Why are the changes needed? Underestimating cache entry size easily can cause OOM in the Yarn NodeManager. In the following analyses of a prod issue (HPROF file) we can see the leak suspect Guava's `LocalCache$Segment` objects: <img width="943" alt="Screenshot 2022-02-17 at 18 55 40" src="https://user-images.githubusercontent.com/2017933/154541995-44014212-2046-41d6-ba7f-99369ca7d739.png"> Going further we can see a `ShuffleIndexInformation` for a small index file (16 bytes) but the retained heap memory is 1192 bytes: <img width="1351" alt="image" src="https://user-images.githubusercontent.com/2017933/154645212-e0318d0f-cefa-4ae3-8a3b-97d2b506757d.png"> Finally we can see this is very common within this heap dump (using MAT's Object Query Language): <img width="1418" alt="image" src="https://user-images.githubusercontent.com/2017933/154547678-44c8af34-1765-4e14-b71a-dc03d1a304aa.png"> I have even exported the data to a CSV and done some calculations with `awk`: ``` $ tail -n+2 export.csv | awk -F, 'BEGIN { numUnderEstimated=0; } { sumOldSize += $1; corrected=$1 + 1176; sumCorrectedSize += corrected; sumRetainedMem += $2; if (corrected < $2) numUnderEstimated+=1; } END { print "sum old size: " sumOldSize / 1024 / 1024 " MB, sum corrected size: " sumCorrectedSize / 1024 / 1024 " MB, sum retained memory:" sumRetainedMem / 1024 / 1024 " MB, num under estimated: " numUnderEstimated }' ``` It gives the followings: ``` sum old size: 76.8785 MB, sum corrected size: 1066.93 MB, sum retained memory:1064.47 MB, num under estimated: 0 ``` So using the old calculation we were at 7.6.8 MB way under the default cache limit (100 MB). Using the correction (applying 1176 as increment to the size) we are at 1066.93 MB (~1GB) which is close to the real retained sum heap: 1064.47 MB (~1GB) and there is no entry which was underestimated. But we can go further and get rid of `java.io.File` completely and store the `ShuffleIndexInformation` for the file path. This way not only the cache size estimate is improved but the its size is decreased as well. Here the path size is not counted into the cache size as that string is interned. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? With the calculations above. Closes #35720 from attilapiros/SPARK-33206-3.1. Authored-by: attilapiros <piros.attila.zsolt@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 03 March 2022, 18:37:54 UTC |
| 6ec3045 | Yuming Wang | 02 March 2022, 19:57:38 UTC | [MINOR][SQL][DOCS] Add more examples to sql-ref-syntax-ddl-create-table-datasource ### What changes were proposed in this pull request? Add more examples to sql-ref-syntax-ddl-create-table-datasource: 1. Create partitioned and bucketed table through CTAS. 2. Create bucketed table through CTAS and CTE ### Why are the changes needed? Improve doc. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manual test. Closes #35712 from wangyum/sql-ref-syntax-ddl-create-table-datasource. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: huaxingao <huaxin_gao@apple.com> (cherry picked from commit 829d7fb045e47f1ddd43f2645949ea8257ca330d) Signed-off-by: huaxingao <huaxin_gao@apple.com> | 02 March 2022, 19:58:30 UTC |
| 357d3b2 | Ruifeng Zheng | 02 March 2022, 19:51:06 UTC | [SPARK-36553][ML] KMeans avoid compute auxiliary statistics for large K ### What changes were proposed in this pull request? SPARK-31007 introduce an auxiliary statistics to speed up computation in KMeasn. However, it needs a array of size `k * (k + 1) / 2`, which may cause overflow or OOM when k is too large. So we should skip this optimization in this case. ### Why are the changes needed? avoid overflow or OOM when k is too large (like 50,000) ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? existing testsuites Closes #35457 from zhengruifeng/kmean_k_limit. Authored-by: Ruifeng Zheng <ruifengz@foxmail.com> Signed-off-by: huaxingao <huaxin_gao@apple.com> (cherry picked from commit ad5427ebe644fc01a9b4c19a48f902f584245edf) Signed-off-by: huaxingao <huaxin_gao@apple.com> | 02 March 2022, 19:52:19 UTC |
| 3b1bdeb | Dongjoon Hyun | 02 March 2022, 06:27:18 UTC | Revert "[SPARK-37090][BUILD][3.1] Upgrade libthrift to 0.16.0 to avoid security vulnerabilities" This reverts commit d7b0567d40e040d3c49089d88f635d66c06adbe0. | 02 March 2022, 06:27:18 UTC |
| 1e1f6b2 | allisonwang-db | 01 March 2022, 07:13:50 UTC | [SPARK-38180][SQL][3.1] Allow safe up-cast expressions in correlated equality predicates Backport https://github.com/apache/spark/pull/35486 to branch-3.1. ### What changes were proposed in this pull request? This PR relaxes the constraint added in [SPARK-35080](https://issues.apache.org/jira/browse/SPARK-35080) by allowing safe up-cast expressions in correlated equality predicates. ### Why are the changes needed? Cast expressions are often added by the compiler during query analysis. Correlated equality predicates can be less restrictive to support this common pattern if a cast expression guarantees one-to-one mapping between the child expression and the output datatype (safe up-cast). ### Does this PR introduce _any_ user-facing change? Yes. Safe up-cast expressions are allowed in correlated equality predicates: ```sql SELECT (SELECT SUM(b) FROM VALUES (1, 1), (1, 2) t(a, b) WHERE CAST(a AS STRING) = x) FROM VALUES ('1'), ('2') t(x) ``` Before this change, this query will throw AnalysisException "Correlated column is not allowed in predicate...", and after this change, this query can run successfully. ### How was this patch tested? Unit tests. Closes #35689 from allisonwang-db/spark-38180-3.1. Authored-by: allisonwang-db <allison.wang@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 01 March 2022, 07:13:50 UTC |
| d7b0567 | Yuming Wang | 26 February 2022, 15:26:11 UTC | [SPARK-37090][BUILD][3.1] Upgrade libthrift to 0.16.0 to avoid security vulnerabilities This is a backport of https://github.com/apache/spark/pull/34362 to branch 3.1. ### What changes were proposed in this pull request? This PR ported HIVE-21498, HIVE-25098 and upgraded libthrift to 0.16.0. The CHANGES list for libthrift 0.16.0 is available at: https://github.com/apache/thrift/blob/v0.16.0/CHANGES.md ### Why are the changes needed? To address [CVE-2020-13949](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-13949). ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing test. Closes #35647 from wangyum/SPARK-37090-branch-3.1. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Sean Owen <srowen@gmail.com> | 26 February 2022, 15:26:11 UTC |
| b98dc38 | Alfonso | 25 February 2022, 14:38:51 UTC | [MINOR][DOCS] Fix missing field in query ### What changes were proposed in this pull request? This PR fixes sql query in doc, let the query confrom to the query result in the following ### Why are the changes needed? Just a fix to doc ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? use project test Closes #35624 from redsnow1992/patch-1. Authored-by: Alfonso <alfonso_men@yahoo.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit daa5f9df4a1c8b3cf5db7142e54b765272c1f24c) Signed-off-by: Sean Owen <srowen@gmail.com> | 25 February 2022, 14:39:09 UTC |
| 82765a8 | Sean Owen | 25 February 2022, 14:34:04 UTC | [SPARK-38305][CORE] Explicitly check if source exists in unpack() before calling FileUtil methods ### What changes were proposed in this pull request? Explicitly check existence of source file in Utils.unpack before calling Hadoop FileUtil methods ### Why are the changes needed? A discussion from the Hadoop community raised a potential issue in calling these methods when a file doesn't exist. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests Closes #35632 from srowen/SPARK-38305. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 64e1f28f1626247cc1361dcb395288227454ca8f) Signed-off-by: Sean Owen <srowen@gmail.com> | 25 February 2022, 14:34:31 UTC |
| 35953cd | Bo Zhang | 24 February 2022, 07:07:38 UTC | [SPARK-38236][SQL][3.2][3.1] Check if table location is absolute by "new Path(locationUri).isAbsolute" in create/alter table ### What changes were proposed in this pull request? After https://github.com/apache/spark/pull/28527, we change to create table under the database location when the table location is relative. However the criteria to determine if a table location is relative/absolute is `URI.isAbsolute`, which basically checks if the table location URI has a scheme defined. So table URIs like `/table/path` are treated as relative and the scheme and authority of the database location URI are used to create the table. For example, when the database location URI is `s3a://bucket/db`, the table will be created at `s3a://bucket/table/path`, while it should be created under the file system defined in `SessionCatalog.hadoopConf` instead. This change fixes that by treating table location as absolute when the first letter of its path is slash. This also applies to alter table. ### Why are the changes needed? This is to fix the behavior described above. ### Does this PR introduce _any_ user-facing change? Yes. When users try to create/alter a table with a location that starts with a slash but without a scheme defined, the table will be created under/altered to the file system defined in `SessionCatalog.hadoopConf`, instead of the one defined in the database location URI. ### How was this patch tested? Updated unit tests. Closes #35591 from bozhang2820/spark-31709-3.2. Authored-by: Bo Zhang <bo.zhang@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 915f0cc5a594da567b9e83fba05a3eb7897c739c) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 24 February 2022, 07:08:08 UTC |
| 687494a | Ruifeng Zheng | 24 February 2022, 02:49:52 UTC | [SPARK-38286][SQL] Union's maxRows and maxRowsPerPartition may overflow check Union's maxRows and maxRowsPerPartition Union's maxRows and maxRowsPerPartition may overflow: case 1: ``` scala> val df1 = spark.range(0, Long.MaxValue, 1, 1) df1: org.apache.spark.sql.Dataset[Long] = [id: bigint] scala> val df2 = spark.range(0, 100, 1, 10) df2: org.apache.spark.sql.Dataset[Long] = [id: bigint] scala> val union = df1.union(df2) union: org.apache.spark.sql.Dataset[Long] = [id: bigint] scala> union.queryExecution.logical.maxRowsPerPartition res19: Option[Long] = Some(-9223372036854775799) scala> union.queryExecution.logical.maxRows res20: Option[Long] = Some(-9223372036854775709) ``` case 2: ``` scala> val n = 2000000 n: Int = 2000000 scala> val df1 = spark.range(0, n, 1, 1).selectExpr("id % 5 as key1", "id as value1") df1: org.apache.spark.sql.DataFrame = [key1: bigint, value1: bigint] scala> val df2 = spark.range(0, n, 1, 2).selectExpr("id % 3 as key2", "id as value2") df2: org.apache.spark.sql.DataFrame = [key2: bigint, value2: bigint] scala> val df3 = spark.range(0, n, 1, 3).selectExpr("id % 4 as key3", "id as value3") df3: org.apache.spark.sql.DataFrame = [key3: bigint, value3: bigint] scala> val joined = df1.join(df2, col("key1") === col("key2")).join(df3, col("key1") === col("key3")) joined: org.apache.spark.sql.DataFrame = [key1: bigint, value1: bigint ... 4 more fields] scala> val unioned = joined.select(col("key1"), col("value3")).union(joined.select(col("key1"), col("value2"))) unioned: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [key1: bigint, value3: bigint] scala> unioned.queryExecution.optimizedPlan.maxRows res32: Option[Long] = Some(-2446744073709551616) scala> unioned.queryExecution.optimizedPlan.maxRows res33: Option[Long] = Some(-2446744073709551616) ``` No added testsuite Closes #35609 from zhengruifeng/union_maxRows_validate. Authored-by: Ruifeng Zheng <ruifengz@foxmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 683bc46ff9a791ab6b9cd3cb95be6bbc368121e0) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 24 February 2022, 02:52:48 UTC |
| 337bc56 | itholic | 22 February 2022, 07:41:16 UTC | [SPARK-38279][TESTS][3.2] Pin MarkupSafe to 2.0.1 fix linter failure This PR proposes to pin the Python package `markupsafe` to 2.0.1 to fix the CI failure as below. ``` ImportError: cannot import name 'soft_unicode' from 'markupsafe' (/home/runner/work/_temp/setup-sam-43osIE/.venv/lib/python3.10/site-packages/markupsafe/__init__.py) ``` Since `markupsafe==2.1.0` has removed `soft_unicode`, `from markupsafe import soft_unicode` no longer working properly. See https://github.com/aws/aws-sam-cli/issues/3661 for more detail. To fix the CI failure on branch-3.2 No. The existing tests are should be passed Closes #35602 from itholic/SPARK-38279. Authored-by: itholic <haejoon.lee@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 79099cf7baf6e094884b5f77e82a4915272f15c5) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 22 February 2022, 07:47:40 UTC |
| adc9c82 | Franck Thang | 22 February 2022, 05:49:32 UTC | [SPARK-37290][SQL] - Exponential planning time in case of non-deterministic function ### What changes were proposed in this pull request? When using non-deterministic function, the method getAllValidConstraints can throw an OOM ``` protected def getAllValidConstraints(projectList: Seq[NamedExpression]): ExpressionSet = { var allConstraints = child.constraints projectList.foreach { case a Alias(l: Literal, _) => allConstraints += EqualNullSafe(a.toAttribute, l) case a Alias(e, _) => // For every alias in `projectList`, replace the reference in constraints by its attribute. allConstraints ++= allConstraints.map(_ transform { case expr: Expression if expr.semanticEquals(e) => a.toAttribute }) allConstraints += EqualNullSafe(e, a.toAttribute) case _ => // Don't change. } allConstraints } ``` In particular, this line `allConstraints ++= allConstraints.map(...)` can generate an exponential number of expressions This is because non deterministic functions are considered unique in a ExpressionSet Therefore, the number of non-deterministic expressions double every time we go through this line We can filter and keep only deterministic expression because 1 - the `semanticEquals` automatically discard non deterministic expressions 2 - this method is only used in one code path, and we keep only determinic expressions ``` lazy val constraints: ExpressionSet = { if (conf.constraintPropagationEnabled) { validConstraints .union(inferAdditionalConstraints(validConstraints)) .union(constructIsNotNullConstraints(validConstraints, output)) .filter { c => c.references.nonEmpty && c.references.subsetOf(outputSet) && c.deterministic } } else { ExpressionSet() } } ``` ### Why are the changes needed? It can lead to an exponential number of expressions and / or OOM ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Local test Closes #35233 from Stelyus/SPARK-37290. Authored-by: Franck Thang <stelyus@outlook.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 881f562f7b6a2bed76b01f956bc02c4b87ad6b80) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 22 February 2022, 05:52:12 UTC |
| ac69643 | Itay Bittan | 20 February 2022, 02:51:53 UTC | [MINOR][DOCS] fix default value of history server ### What changes were proposed in this pull request? Alignment between the documentation and the code. ### Why are the changes needed? The [actual default value ](https://github.com/apache/spark/blame/master/core/src/main/scala/org/apache/spark/internal/config/History.scala#L198) for `spark.history.custom.executor.log.url.applyIncompleteApplication` is `true` and not `false` as stated in the documentation. ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? Closes #35577 from itayB/doc. Authored-by: Itay Bittan <itay.bittan@gmail.com> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit ae67adde4d2dc0a75e03710fc3e66ea253feeda3) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 20 February 2022, 02:53:11 UTC |
| 5dd54f9 | Karthik Subramanian | 18 February 2022, 03:52:11 UTC | [MINOR][DOC] Fix documentation for structured streaming - addListener ### What changes were proposed in this pull request? This PR fixes the incorrect documentation in Structured Streaming Guide where it says `sparkSession.streams.attachListener()` instead of `sparkSession.streams.addListener()` which is the correct usage as mentioned in the code snippet below in the same doc. 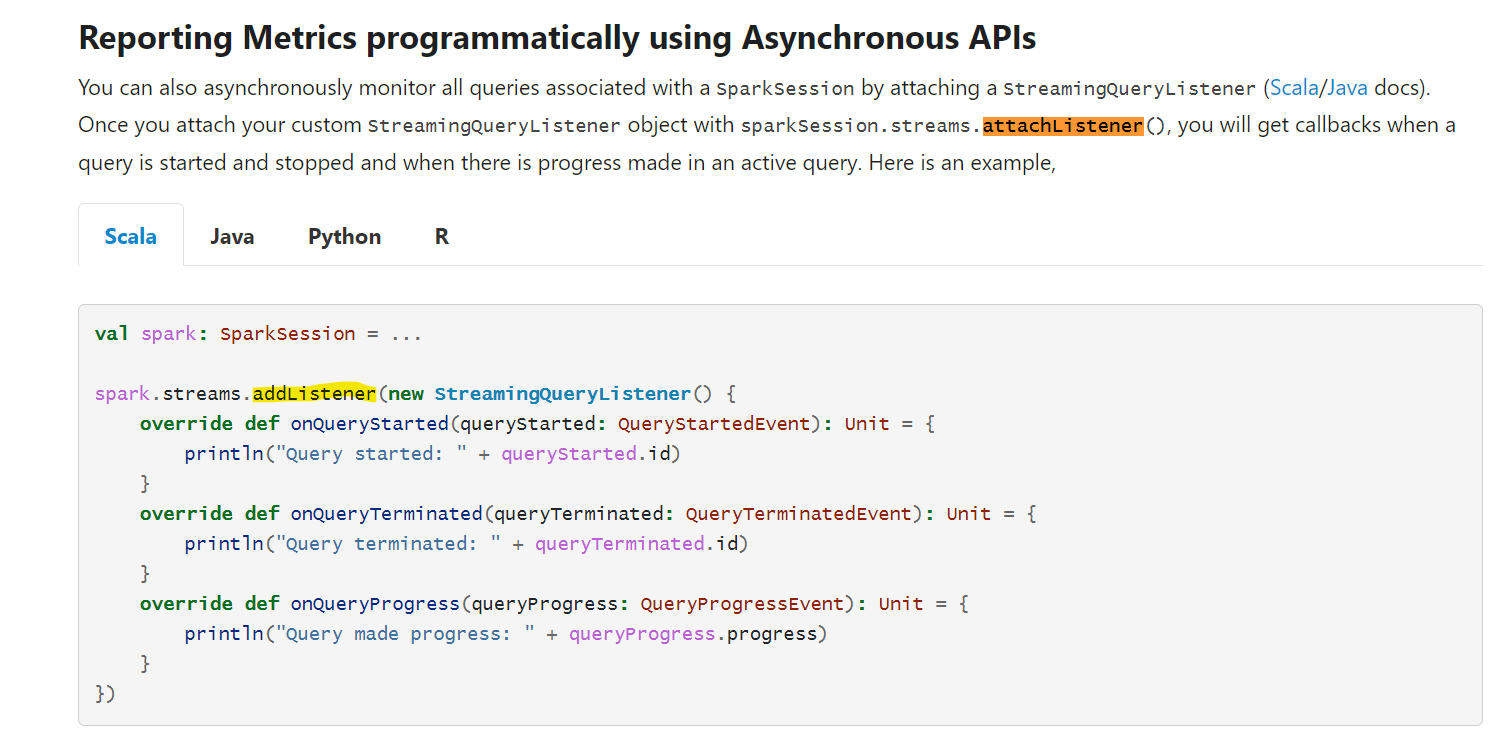 ### Why are the changes needed? The documentation was erroneous, and needs to be fixed to avoid confusion by readers ### Does this PR introduce _any_ user-facing change? Yes, since it's a doc fix. This fix needs to be applied to previous versions retro-actively as well. ### How was this patch tested? Not necessary Closes #35562 from yeskarthik/fix-structured-streaming-docs-1. Authored-by: Karthik Subramanian <karsubr@microsoft.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 837248a0c42d55ad48240647d503ad544e64f016) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 18 February 2022, 03:53:18 UTC |
| d1ca91c | tianlzhang | 15 February 2022, 03:52:37 UTC | [SPARK-38211][SQL][DOCS] Add SQL migration guide on restoring loose upcast from string to other types ### What changes were proposed in this pull request? Add doc on restoring loose upcast from string to other types (behavior before 2.4.1) to SQL migration guide. ### Why are the changes needed? After [SPARK-24586](https://issues.apache.org/jira/browse/SPARK-24586), loose upcasting from string to other types are not allowed by default. User can still set `spark.sql.legacy.looseUpcast=true` to restore old behavior but it's not documented. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Only doc change. Closes #35519 from manuzhang/spark-38211. Authored-by: tianlzhang <tianlzhang@ebay.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 78514e3149bc43b2485e4be0ab982601a842600b) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 15 February 2022, 03:53:04 UTC |
| 4098d26 | Angerszhuuuu | 10 February 2022, 13:55:58 UTC | [SPARK-35531][SQL][3.1] Directly pass hive Table to HiveClient when call getPartitions to avoid unnecessary convert from HiveTable -> CatalogTable -> HiveTable ### What changes were proposed in this pull request? In current `HiveexternalCatalog.listpartitions`, it use ``` final def getPartitions( db: String, table: String, partialSpec: Option[TablePartitionSpec]): Seq[CatalogTablePartition] = { getPartitions(getTable(db, table), partialSpec) } ``` It call `geTables` to get a raw HiveTable then convert it to a CatalogTable, in `getPartitions` it re-convert it to a HiveTable. This cause a conflicts since in HiveTable we store schema as lowercase but for bucket cols and sort cols it didn't convert it to lowercase. In this pr, we directly pass raw HiveTable to HiveClient's request to avoid unnecessary convert and potential conflicts, also respect case sensitivity. ### Why are the changes needed? When user create a hive bucket table with upper case schema, the table schema will be stored as lower cases while bucket column info will stay the same with user input. if we try to insert into this table, an HiveException reports bucket column is not in table schema. here is a simple repro ``` spark.sql(""" CREATE TABLE TEST1( V1 BIGINT, S1 INT) PARTITIONED BY (PK BIGINT) CLUSTERED BY (V1) SORTED BY (S1) INTO 200 BUCKETS STORED AS PARQUET """).show spark.sql("INSERT INTO TEST1 SELECT * FROM VALUES(1,1,1)").show ``` Error message: ``` scala> spark.sql("INSERT INTO TEST1 SELECT * FROM VALUES(1,1,1)").show org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: Bucket columns V1 is not part of the table columns ([FieldSchema(name:v1, type:bigint, comment:null), FieldSchema(name:s1, type:int, comment:null)] at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:112) at org.apache.spark.sql.hive.HiveExternalCatalog.listPartitions(HiveExternalCatalog.scala:1242) at org.apache.spark.sql.catalyst.catalog.ExternalCatalogWithListener.listPartitions(ExternalCatalogWithListener.scala:254) at org.apache.spark.sql.catalyst.catalog.SessionCatalog.listPartitions(SessionCatalog.scala:1166) at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.run(InsertIntoHadoopFsRelationCommand.scala:103) at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:108) at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:106) at org.apache.spark.sql.execution.command.DataWritingCommandExec.executeCollect(commands.scala:120) at org.apache.spark.sql.Dataset.$anonfun$logicalPlan$1(Dataset.scala:228) at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3687) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:103) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64) at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3685) at org.apache.spark.sql.Dataset.<init>(Dataset.scala:228) at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:99) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772) at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:96) at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:615) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772) at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:610) ... 47 elided Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: Bucket columns V1 is not part of the table columns ([FieldSchema(name:v1, type:bigint, comment:null), FieldSchema(name:s1, type:int, comment:null)] at org.apache.hadoop.hive.ql.metadata.Table.setBucketCols(Table.java:552) at org.apache.spark.sql.hive.client.HiveClientImpl$.toHiveTable(HiveClientImpl.scala:1082) at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$getPartitions$1(HiveClientImpl.scala:732) at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$withHiveState$1(HiveClientImpl.scala:291) at org.apache.spark.sql.hive.client.HiveClientImpl.liftedTree1$1(HiveClientImpl.scala:224) at org.apache.spark.sql.hive.client.HiveClientImpl.retryLocked(HiveClientImpl.scala:223) at org.apache.spark.sql.hive.client.HiveClientImpl.withHiveState(HiveClientImpl.scala:273) at org.apache.spark.sql.hive.client.HiveClientImpl.getPartitions(HiveClientImpl.scala:731) at org.apache.spark.sql.hive.client.HiveClient.getPartitions(HiveClient.scala:222) at org.apache.spark.sql.hive.client.HiveClient.getPartitions$(HiveClient.scala:218) at org.apache.spark.sql.hive.client.HiveClientImpl.getPartitions(HiveClientImpl.scala:91) at org.apache.spark.sql.hive.HiveExternalCatalog.$anonfun$listPartitions$1(HiveExternalCatalog.scala:1245) at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:102) ... 69 more ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? UT Closes #35475 from AngersZhuuuu/SPARK-35531-3.1. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 10 February 2022, 13:55:58 UTC |
| 851ebad | Dongjoon Hyun | 09 February 2022, 21:20:46 UTC | [SPARK-38151][SQL][TESTS] Handle `Pacific/Kanton` in DateTimeUtilsSuite ### What changes were proposed in this pull request? This PR aims to fix the flaky UT failures due to https://bugs.openjdk.java.net/browse/JDK-8274407 (`Update Timezone Data to 2021c`) and its backport commits that renamed 'Pacific/Enderbury' to 'Pacific/Kanton' in the latest Java `17.0.2`, `11.0.14`, and `8u311`. ``` Rename Pacific/Enderbury to Pacific/Kanton. ``` ### Why are the changes needed? The flaky failures were observed twice in `GitHub Action` environment like the following. **MASTER** - https://github.com/dongjoon-hyun/spark/runs/5119322349?check_suite_focus=true ``` [info] - daysToMicros and microsToDays *** FAILED *** (620 milliseconds) [info] 9131 did not equal 9130 Round trip of 9130 did not work in tz Pacific/Kanton (DateTimeUtilsSuite.scala:783) ``` **BRANCH-3.2** - https://github.com/apache/spark/runs/5122380604?check_suite_focus=true ``` [info] - daysToMicros and microsToDays *** FAILED *** (643 milliseconds) [info] 9131 did not equal 9130 Round trip of 9130 did not work in tz Pacific/Kanton (DateTimeUtilsSuite.scala:771) ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass the CIs Closes #35468 from dongjoon-hyun/SPARK-38151. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 4dde01fc5b0ed44fd6c5ad8da093650931e4dcd4) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 09 February 2022, 21:21:05 UTC |
| 47de971 | kuwii | 09 February 2022, 17:53:11 UTC | [SPARK-38056][WEB UI][3.1] Fix issue of Structured streaming not working in history server when using LevelDB ### What changes were proposed in this pull request? Change type of `org.apache.spark.sql.streaming.ui.StreamingQueryData.runId` from `UUID` to `String`. ### Why are the changes needed? In [SPARK-31953](https://github.com/apache/spark/commit/4f9667035886a67e6c9a4e8fad2efa390e87ca68), structured streaming support is added in history server. However this does not work when history server is using LevelDB instead of in-memory KV store. - Level DB does not support `UUID` as key. - If `spark.history.store.path` is set in history server to use Level DB, when writing info to the store during replaying events, error will occur. - `StreamingQueryStatusListener` will throw exceptions when writing info, saying `java.lang.IllegalArgumentException: Type java.util.UUID not allowed as key.`. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Added tests in `StreamingQueryStatusListenerSuite` to test whether `StreamingQueryData` can be successfully written to in-memory store and LevelDB. Closes #35463 from kuwii/hs-streaming-fix-3.1. Authored-by: kuwii <kuwii.someone@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 09 February 2022, 17:53:11 UTC |
| e120a53 | khalidmammadov | 09 February 2022, 08:54:31 UTC | [SPARK-38120][SQL] Fix HiveExternalCatalog.listPartitions when partition column name is upper case and dot in partition value ### What changes were proposed in this pull request? HiveExternalCatalog.listPartitions method call is failing when a partition column name is upper case and partition value contains dot. It's related to this change https://github.com/apache/spark/commit/f18b905f6cace7686ef169fda7de474079d0af23 The test case in that PR does not produce the issue as partition column name is lower case. This change will lowercase the partition column name during comparison to produce expected result, it's is inline with the actual spec transformation i.e. making it lower case for Hive and using the same function Below how to reproduce the issue: ``` Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 1.8.0_312) Type in expressions to have them evaluated. Type :help for more information. scala> import org.apache.spark.sql.catalyst.TableIdentifier import org.apache.spark.sql.catalyst.TableIdentifier scala> spark.sql("CREATE TABLE customer(id INT, name STRING) PARTITIONED BY (partCol1 STRING, partCol2 STRING)") 22/02/06 21:10:45 WARN ResolveSessionCatalog: A Hive serde table will be created as there is no table provider specified. You can set spark.sql.legacy.createHiveTableByDefault to false so that native data source table will be created instead. res0: org.apache.spark.sql.DataFrame = [] scala> spark.sql("INSERT INTO customer PARTITION (partCol1 = 'CA', partCol2 = 'i.j') VALUES (100, 'John')") res1: org.apache.spark.sql.DataFrame = [] scala> spark.sessionState.catalog.listPartitions(TableIdentifier("customer"), Some(Map("partCol2" -> "i.j"))).foreach(println) java.util.NoSuchElementException: key not found: partcol2 at scala.collection.immutable.Map$Map2.apply(Map.scala:227) at org.apache.spark.sql.catalyst.catalog.ExternalCatalogUtils$.$anonfun$isPartialPartitionSpec$1(ExternalCatalogUtils.scala:205) at org.apache.spark.sql.catalyst.catalog.ExternalCatalogUtils$.$anonfun$isPartialPartitionSpec$1$adapted(ExternalCatalogUtils.scala:202) at scala.collection.immutable.Map$Map1.forall(Map.scala:196) at org.apache.spark.sql.catalyst.catalog.ExternalCatalogUtils$.isPartialPartitionSpec(ExternalCatalogUtils.scala:202) at org.apache.spark.sql.hive.HiveExternalCatalog.$anonfun$listPartitions$6(HiveExternalCatalog.scala:1312) at org.apache.spark.sql.hive.HiveExternalCatalog.$anonfun$listPartitions$6$adapted(HiveExternalCatalog.scala:1312) at scala.collection.TraversableLike.$anonfun$filterImpl$1(TraversableLike.scala:304) at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62) at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49) at scala.collection.TraversableLike.filterImpl(TraversableLike.scala:303) at scala.collection.TraversableLike.filterImpl$(TraversableLike.scala:297) at scala.collection.AbstractTraversable.filterImpl(Traversable.scala:108) at scala.collection.TraversableLike.filter(TraversableLike.scala:395) at scala.collection.TraversableLike.filter$(TraversableLike.scala:395) at scala.collection.AbstractTraversable.filter(Traversable.scala:108) at org.apache.spark.sql.hive.HiveExternalCatalog.$anonfun$listPartitions$1(HiveExternalCatalog.scala:1312) at org.apache.spark.sql.hive.HiveExternalCatalog.withClientWrappingException(HiveExternalCatalog.scala:114) at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:103) at org.apache.spark.sql.hive.HiveExternalCatalog.listPartitions(HiveExternalCatalog.scala:1296) at org.apache.spark.sql.catalyst.catalog.ExternalCatalogWithListener.listPartitions(ExternalCatalogWithListener.scala:254) at org.apache.spark.sql.catalyst.catalog.SessionCatalog.listPartitions(SessionCatalog.scala:1251) ... 47 elided *******AFTER FIX********* scala> import org.apache.spark.sql.catalyst.TableIdentifier import org.apache.spark.sql.catalyst.TableIdentifier scala> spark.sql("CREATE TABLE customer(id INT, name STRING) PARTITIONED BY (partCol1 STRING, partCol2 STRING)") 22/02/06 22:08:11 WARN ResolveSessionCatalog: A Hive serde table will be created as there is no table provider specified. You can set spark.sql.legacy.createHiveTableByDefault to false so that native data source table will be created instead. res1: org.apache.spark.sql.DataFrame = [] scala> spark.sql("INSERT INTO customer PARTITION (partCol1 = 'CA', partCol2 = 'i.j') VALUES (100, 'John')") res2: org.apache.spark.sql.DataFrame = [] scala> spark.sessionState.catalog.listPartitions(TableIdentifier("customer"), Some(Map("partCol2" -> "i.j"))).foreach(println) CatalogPartition( Partition Values: [partCol1=CA, partCol2=i.j] Location: file:/home/khalid/dev/oss/test/spark-warehouse/customer/partcol1=CA/partcol2=i.j Serde Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe InputFormat: org.apache.hadoop.mapred.TextInputFormat OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat Storage Properties: [serialization.format=1] Partition Parameters: {rawDataSize=0, numFiles=1, transient_lastDdlTime=1644185314, totalSize=9, COLUMN_STATS_ACCURATE={"BASIC_STATS":"true"}, numRows=0} Created Time: Sun Feb 06 22:08:34 GMT 2022 Last Access: UNKNOWN Partition Statistics: 9 bytes) ``` ### Why are the changes needed? It fixes the bug ### Does this PR introduce _any_ user-facing change? Yes ### How was this patch tested? `build/sbt -v -d "test:testOnly *CatalogSuite"` Closes #35409 from khalidmammadov/fix_list_partitions_bug2. Authored-by: khalidmammadov <xmamedov@hotmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 2ba8a4e263933e7500cbc7c38badb6cb059803c9) Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 4b1ff1180c740294d834e829451f8e4fc78668d6) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 09 February 2022, 17:30:18 UTC |
| 66e73c4 | Shardul Mahadik | 09 February 2022, 03:20:24 UTC | [SPARK-38030][SQL][3.1] Canonicalization should not remove nullability of AttributeReference dataType This is a backport of https://github.com/apache/spark/pull/35332 to branch 3.1 ### What changes were proposed in this pull request? Canonicalization of AttributeReference should not remove nullability information of its dataType. ### Why are the changes needed? SPARK-38030 lists an issue where canonicalization of cast resulted in an unresolved expression, thus causing query failure. The issue was that the child AttributeReference's dataType was converted to nullable during canonicalization and hence the Cast's `checkInputDataTypes` fails. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added unit test to ensure that canonicalization preserves nullability of AttributeReference and does not result in an unresolved cast. Also added a test to ensure that the issue observed in SPARK-38030 (interaction of this bug with AQE) is fixed. This test/repro only works on 3.1 because the code which triggers access on an unresolved object is [lazy](https://github.com/apache/spark/blob/7e5c3b216431b6a5e9a0786bf7cded694228cdee/sql/core/src/main/scala/org/apache/spark/sql/execution/exchange/ShuffleExchangeExec.scala#L132) in 3.2+ and hence does not trigger the issue in 3.2+. Closes #35444 from shardulm94/SPARK-38030-3.1. Authored-by: Shardul Mahadik <smahadik@linkedin.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 09 February 2022, 03:20:24 UTC |
| 1aa9ef0 | Dongjoon Hyun | 08 February 2022, 23:35:54 UTC | [SPARK-38144][CORE] Remove unused `spark.storage.safetyFraction` config ### What changes were proposed in this pull request? This PR aims to remove the unused `spark.storage.safetyFraction`. ### Why are the changes needed? Apache Spark 3.0.0 deleted `StaticMemoryManager` and its `spark.storage.safetyFraction` usage via SPARK-26539. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass the CIs. Closes #35447 from dongjoon-hyun/SPARK-38144. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit cc53a0e0734cf56711667b65cfbaf5684fc06923) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 08 February 2022, 23:36:19 UTC |
| 0b35c24 | Holden Karau | 06 February 2022, 22:17:37 UTC | Preparing development version 3.1.4-SNAPSHOT | 06 February 2022, 22:17:37 UTC |
| d1f8a50 | Holden Karau | 06 February 2022, 22:17:33 UTC | Preparing Spark release v3.1.3-rc4 | 06 February 2022, 22:17:33 UTC |
| 7540421 | Holden Karau | 01 February 2022, 21:15:31 UTC | Preparing development version 3.1.4-SNAPSHOT | 01 February 2022, 21:15:31 UTC |
| b8c0799 | Holden Karau | 01 February 2022, 21:15:27 UTC | Preparing Spark release v3.1.3-rc3 | 01 February 2022, 21:15:27 UTC |
| 0a7eda3 | Bruce Robbins | 01 February 2022, 02:50:19 UTC | [SPARK-38075][SQL][3.1] Fix `hasNext` in `HiveScriptTransformationExec`'s process output iterator Backport #35368 to 3.1. ### What changes were proposed in this pull request? Fix hasNext in HiveScriptTransformationExec's process output iterator to always return false if it had previously returned false. ### Why are the changes needed? When hasNext on the process output iterator returns false, it leaves the iterator in a state (i.e., scriptOutputWritable is not null) such that the next call returns true. The Guava Ordering used in TakeOrderedAndProjectExec will call hasNext on the process output iterator even after an earlier call had returned false. This results in fake rows when script transform is used with `order by` and `limit`. For example: ``` create or replace temp view t as select * from values (1), (2), (3) as t(a); select transform(a) USING 'cat' AS (a int) FROM t order by a limit 10; ``` This returns: ``` NULL NULL NULL 1 2 3 ``` ### Does this PR introduce _any_ user-facing change? No, other than removing the correctness issue. ### How was this patch tested? New unit test. Closes #35375 from bersprockets/SPARK-38075_3.1. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 01 February 2022, 02:50:19 UTC |
| 91db9a3 | Holden Karau | 13 January 2022, 17:42:17 UTC | Preparing development version 3.1.4-SNAPSHOT | 13 January 2022, 17:42:17 UTC |
| fd2d694 | Holden Karau | 13 January 2022, 17:42:13 UTC | Preparing Spark release v3.1.3-rc2 | 13 January 2022, 17:42:13 UTC |
| 830d5b6 | stczwd | 11 January 2022, 06:23:12 UTC | [SPARK-37860][UI] Fix taskindex in the stage page task event timeline ### What changes were proposed in this pull request? This reverts commit 450b415028c3b00f3a002126cd11318d3932e28f. ### Why are the changes needed? In #32888, shahidki31 change taskInfo.index to taskInfo.taskId. However, we generally use `index.attempt` or `taskId` to distinguish tasks within a stage, not `taskId.attempt`. Thus #32888 was a wrong fix issue, we should revert it. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? origin test suites Closes #35160 from stczwd/SPARK-37860. Authored-by: stczwd <qcsd2011@163.com> Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com> (cherry picked from commit 3d2fde5242c8989688c176b8ed5eb0bff5e1f17f) Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com> | 11 January 2022, 06:23:54 UTC |
| 1a27539 | Holden Karau | 10 January 2022, 21:23:44 UTC | Preparing development version 3.1.4-SNAPSHOT | 10 January 2022, 21:23:44 UTC |
| df89eb2 | Holden Karau | 10 January 2022, 21:23:40 UTC | Preparing Spark release v3.1.3-rc1 | 10 January 2022, 21:23:40 UTC |
| 94a69ff | Dongjoon Hyun | 05 January 2022, 07:59:16 UTC | Revert "[SPARK-37779][SQL] Make ColumnarToRowExec plan canonicalizable after (de)serialization" This reverts commit e17ab6e995a213e442e91df168e87fb724672613. | 05 January 2022, 07:59:16 UTC |
| 3bcd036 | Chilaka Ramakrishna | 05 January 2022, 07:30:20 UTC | [SPARK-37807][SQL] Fix a typo in HttpAuthenticationException message ### What changes were proposed in this pull request? The error message is not correct, So we update the error message. ### Why are the changes needed? The exception message when password is left empty in HTTP mode of hive thrift server is not correct.. Updated the text to reflect it. Please check JIRA ISSUE: https://issues.apache.org/jira/browse/SPARK-37807 ### Does this PR introduce _any_ user-facing change? Yes, The exception messages in HiveServer2 is changed. ### How was this patch tested? This was tested manually Closes #35097 from RamakrishnaChilaka/feature/error_string_fix. Authored-by: Chilaka Ramakrishna <ramakrishna@nference.net> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 27d5575f13fe69459d7fa72cee11d4166c9e1a10) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 05 January 2022, 07:31:13 UTC |
| 70d4fb1 | yi.wu | 05 January 2022, 02:48:16 UTC | [SPARK-35714][FOLLOW-UP][CORE] WorkerWatcher should run System.exit in a thread out of RpcEnv ### What changes were proposed in this pull request? This PR proposes to let `WorkerWatcher` run `System.exit` in a separate thread instead of some thread of `RpcEnv`. ### Why are the changes needed? `System.exit` will trigger the shutdown hook to run `executor.stop`, which will result in the same deadlock issue with SPARK-14180. But note that since Spark upgrades to Hadoop 3 recently, each hook now will have a [timeout threshold](https://github.com/apache/hadoop/blob/d4794dd3b2ba365a9d95ad6aafcf43a1ea40f777/hadoop-common-project/hadoop-common/src/main/java/org/apache/hadoop/util/ShutdownHookManager.java#L205-L209) which forcibly interrupt the hook execution once reaches timeout. So, the deadlock issue doesn't really exist in the master branch. However, it's still critical for previous releases and is a wrong behavior that should be fixed. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Tested manually. Closes #35069 from Ngone51/fix-workerwatcher-exit. Authored-by: yi.wu <yi.wu@databricks.com> Signed-off-by: yi.wu <yi.wu@databricks.com> (cherry picked from commit 639d6f40e597d79c680084376ece87e40f4d2366) Signed-off-by: yi.wu <yi.wu@databricks.com> | 05 January 2022, 02:49:16 UTC |
| 5cc8b39 | Josh Rosen | 04 January 2022, 18:59:53 UTC | [SPARK-37784][SQL] Correctly handle UDTs in CodeGenerator.addBufferedState() ### What changes were proposed in this pull request? This PR fixes a correctness issue in the CodeGenerator.addBufferedState() helper method (which is used by the SortMergeJoinExec operator). The addBufferedState() method generates code for buffering values that come from a row in an operator's input iterator, performing any necessary copying so that the buffered values remain correct after the input iterator advances to the next row. The current logic does not correctly handle UDTs: these fall through to the match statement's default branch, causing UDT values to be buffered without copying. This is problematic if the UDT's underlying SQL type is an array, map, struct, or string type (since those types require copying). Failing to copy values can lead to correctness issues or crashes. This patch's fix is simple: when the dataType is a UDT, use its underlying sqlType for determining whether values need to be copied. I used an existing helper function to perform this type unwrapping. ### Why are the changes needed? Fix a correctness issue. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? I manually tested this change by re-running a workload which failed with a segfault prior to this patch. See JIRA for more details: https://issues.apache.org/jira/browse/SPARK-37784 So far I have been unable to come up with a CI-runnable regression test which would have failed prior to this change (my only working reproduction runs in a pre-production environment and does not fail in my development environment). Closes #35066 from JoshRosen/SPARK-37784. Authored-by: Josh Rosen <joshrosen@databricks.com> Signed-off-by: Josh Rosen <joshrosen@databricks.com> (cherry picked from commit eeef48fac412a57382b02ba3f39456d96379b5f5) Signed-off-by: Josh Rosen <joshrosen@databricks.com> | 04 January 2022, 19:02:47 UTC |
| e17ab6e | Hyukjin Kwon | 30 December 2021, 03:38:37 UTC | [SPARK-37779][SQL] Make ColumnarToRowExec plan canonicalizable after (de)serialization This PR proposes to add a driver-side check on `supportsColumnar` sanity check at `ColumnarToRowExec`. SPARK-23731 fixed the plans to be serializable by leveraging lazy but SPARK-28213 happened to refer to the lazy variable at: https://github.com/apache/spark/blob/77b164aac9764049a4820064421ef82ec0bc14fb/sql/core/src/main/scala/org/apache/spark/sql/execution/Columnar.scala#L68 This can fail during canonicalization during, for example, eliminating sub common expressions (on executor side): ``` java.lang.NullPointerException at org.apache.spark.sql.execution.FileSourceScanExec.supportsColumnar$lzycompute(DataSourceScanExec.scala:280) at org.apache.spark.sql.execution.FileSourceScanExec.supportsColumnar(DataSourceScanExec.scala:279) at org.apache.spark.sql.execution.InputAdapter.supportsColumnar(WholeStageCodegenExec.scala:509) at org.apache.spark.sql.execution.ColumnarToRowExec.<init>(Columnar.scala:67) ... at org.apache.spark.sql.catalyst.plans.QueryPlan.canonicalized$lzycompute(QueryPlan.scala:581) at org.apache.spark.sql.catalyst.plans.QueryPlan.canonicalized(QueryPlan.scala:580) at org.apache.spark.sql.execution.ScalarSubquery.canonicalized$lzycompute(subquery.scala:110) ... at org.apache.spark.sql.catalyst.expressions.ExpressionEquals.hashCode(EquivalentExpressions.scala:275) ... at scala.collection.mutable.HashTable.findEntry$(HashTable.scala:135) at scala.collection.mutable.HashMap.findEntry(HashMap.scala:44) at scala.collection.mutable.HashMap.get(HashMap.scala:74) at org.apache.spark.sql.catalyst.expressions.EquivalentExpressions.addExpr(EquivalentExpressions.scala:46) at org.apache.spark.sql.catalyst.expressions.EquivalentExpressions.addExprTreeHelper$1(EquivalentExpressions.scala:147) at org.apache.spark.sql.catalyst.expressions.EquivalentExpressions.addExprTree(EquivalentExpressions.scala:170) at org.apache.spark.sql.catalyst.expressions.SubExprEvaluationRuntime.$anonfun$proxyExpressions$1(SubExprEvaluationRuntime.scala:89) at org.apache.spark.sql.catalyst.expressions.SubExprEvaluationRuntime.$anonfun$proxyExpressions$1$adapted(SubExprEvaluationRuntime.scala:89) at scala.collection.immutable.List.foreach(List.scala:392) ``` This fix is still a bandaid fix but at least addresses the issue with minimized change - this fix should ideally be backported too. Pretty unlikely - when `ColumnarToRowExec` has to be canonicalized on the executor side (see the stacktrace), but yes. it would fix a bug. Unittest was added. Closes #35058 from HyukjinKwon/SPARK-37779. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 195f1aaf4361fb8f5f31ef7f5c63464767ad88bd) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 30 December 2021, 03:41:11 UTC |
| 5e0f0da | Danny Guinther | 24 December 2021, 01:48:04 UTC | [SPARK-37391][SQL] JdbcConnectionProvider tells if it modifies security context # branch-3.1 version! For master version see : https://github.com/apache/spark/pull/34745 Augments the JdbcConnectionProvider API such that a provider can indicate that it will need to modify the global security configuration when establishing a connection, and as such, if access to the global security configuration should be synchronized to prevent races. ### What changes were proposed in this pull request? As suggested by gaborgsomogyi [here](https://github.com/apache/spark/pull/29024/files#r755788709), augments the `JdbcConnectionProvider` API to include a `modifiesSecurityContext` method that can be used by `ConnectionProvider` to determine when `SecurityConfigurationLock.synchronized` is required to avoid race conditions when establishing a JDBC connection. ### Why are the changes needed? Provides a path forward for working around a significant bottleneck introduced by synchronizing `SecurityConfigurationLock` every time a connection is established. The synchronization isn't always needed and it should be at the discretion of the `JdbcConnectionProvider` to determine when locking is necessary. See [SPARK-37391](https://issues.apache.org/jira/browse/SPARK-37391) or [this thread](https://github.com/apache/spark/pull/29024/files#r754441783). ### Does this PR introduce _any_ user-facing change? Any existing implementations of `JdbcConnectionProvider` will need to add a definition of `modifiesSecurityContext`. I'm also open to adding a default implementation, but it seemed to me that requiring an explicit implementation of the method was preferable. A drop-in implementation that would continue the existing behavior is: ```scala override def modifiesSecurityContext( driver: Driver, options: Map[String, String] ): Boolean = true ``` ### How was this patch tested? Unit tests. Also ran a real workflow by swapping in a locally published version of `spark-sql` into my local spark 3.1.2 installation's jars. Closes #34988 from tdg5/SPARK-37391-opt-in-security-configuration-sync-branch-3.1. Authored-by: Danny Guinther <dguinther@seismic.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 24 December 2021, 01:48:04 UTC |
| 0f6cafe | Max Gekk | 22 December 2021, 00:29:02 UTC | [MINOR][SQL] Fix the typo in function names: crete ### What changes were proposed in this pull request? Fix the typo: crete -> create. ### Why are the changes needed? To improve code maintenance. Find the functions by names should be easer after the changes. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? By compiling and running related test suites: ``` $ build/sbt "test:testOnly *ParquetRebaseDatetimeV2Suite" $ build/sbt "test:testOnly *AvroV1Suite" ``` Closes #34978 from MaxGekk/fix-typo-crete. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 72c278a4bb906cd7c500d223f80bc83e0f5c1ef0) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 22 December 2021, 00:29:29 UTC |
| 07e1411 | Alex Ott | 19 December 2021, 08:02:40 UTC | [MINOR][PYTHON][DOCS] Fix documentation for Python's recentProgress & lastProgress This small PR fixes incorrect documentation in Structured Streaming Guide where Python's `recentProgress` & `lastProgress` where shown as functions although they are [properties](https://github.com/apache/spark/blob/master/python/pyspark/sql/streaming.py#L117), so if they are called as functions it generates error: ``` >>> query.lastProgress() Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'dict' object is not callable ``` The documentation was erroneous, and needs to be fixed to avoid confusion by readers yes, it's a fix of the documentation Not necessary Closes #34947 from alexott/fix-python-recent-progress-docs. Authored-by: Alex Ott <alexott@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit bad96e6d029dff5be9efaf99f388cd9436741b6f) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 19 December 2021, 08:03:37 UTC |
| 1706ccc | Huaxin Gao | 17 December 2021, 04:43:24 UTC | [SPARK-37654][SQL] Fix NPE in Row.getSeq when field is Null ### What changes were proposed in this pull request? Fix NPE ``` scala> Row(null).getSeq(0) java.lang.NullPointerException at org.apache.spark.sql.Row.getSeq(Row.scala:319) at org.apache.spark.sql.Row.getSeq$(Row.scala:319) at org.apache.spark.sql.catalyst.expressions.GenericRow.getSeq(rows.scala:166) ``` ### Why are the changes needed? bug fixing ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? new UT Closes #34928 from huaxingao/npe. Authored-by: Huaxin Gao <huaxin_gao@apple.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit fcf636d9eb8d645c24be3db2d599aba2d7e2955a) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 17 December 2021, 04:43:47 UTC |
| e3d868b | Mohamadreza Rostami | 16 December 2021, 07:21:45 UTC | [SPARK-37060][CORE][3.1] Handle driver status response from backup masters ### What changes were proposed in this pull request? After an improvement in SPARK-31486, contributor uses 'asyncSendToMasterAndForwardReply' method instead of 'activeMasterEndpoint.askSync' to get the status of driver. Since the driver's status is only available in active master and the 'asyncSendToMasterAndForwardReply' method iterate over all of the masters, we have to handle the response from the backup masters in the client, which the developer did not consider in the SPARK-31486 change. So drivers running in cluster mode and on a cluster with multi masters affected by this bug. ### Why are the changes needed? We need to find if the response received from a backup master client must ignore it. ### Does this PR introduce _any_ user-facing change? No, It's only fixed a bug and brings back the ability to deploy in cluster mode on multi-master clusters. ### How was this patch tested? Closes #34911 from mohamadrezarostami/fix-a-bug-in-report-driver-status. Authored-by: Mohamadreza Rostami <mohamadrezarostami2@gmail.com> Signed-off-by: yi.wu <yi.wu@databricks.com> | 16 December 2021, 07:21:45 UTC |
| 8216457 | Yuming Wang | 09 December 2021, 17:17:25 UTC | [SPARK-37451][3.1][SQL] Fix cast string type to decimal type if spark.sql.legacy.allowNegativeScaleOfDecimal is enabled Backport #34811 ### What changes were proposed in this pull request? Fix cast string type to decimal type only if `spark.sql.legacy.allowNegativeScaleOfDecimal` is enabled. For example: ```scala import org.apache.spark.sql.types._ import org.apache.spark.sql.Row spark.conf.set("spark.sql.legacy.allowNegativeScaleOfDecimal", true) val data = Seq(Row("7.836725755512218E38")) val schema = StructType(Array(StructField("a", StringType, false))) val df =spark.createDataFrame(spark.sparkContext.parallelize(data), schema) df.select(col("a").cast(DecimalType(37,-17))).show ``` The result is null since [SPARK-32706](https://issues.apache.org/jira/browse/SPARK-32706). ### Why are the changes needed? Fix regression bug. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Unit test. Closes #34851 from wangyum/SPARK-37451-branch-3.1. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 09 December 2021, 17:17:25 UTC |
| c51f644 | Wenchen Fan | 08 December 2021, 05:04:40 UTC | [SPARK-37392][SQL] Fix the performance bug when inferring constraints for Generate This is a performance regression since Spark 3.1, caused by https://issues.apache.org/jira/browse/SPARK-32295 If you run the query in the JIRA ticket ``` Seq( (1, "x", "x", "x", "x", "x", "x", "x", "x", "x", "x", "x", "x", "x", "x", "x", "x", "x", "x", "x", "x") ).toDF() .checkpoint() // or save and reload to truncate lineage .createOrReplaceTempView("sub") session.sql(""" SELECT * FROM ( SELECT EXPLODE( ARRAY( * ) ) result FROM ( SELECT _1 a, _2 b, _3 c, _4 d, _5 e, _6 f, _7 g, _8 h, _9 i, _10 j, _11 k, _12 l, _13 m, _14 n, _15 o, _16 p, _17 q, _18 r, _19 s, _20 t, _21 u FROM sub ) ) WHERE result != '' """).show() ``` You will hit OOM. The reason is that: 1. We infer additional predicates with `Generate`. In this case, it's `size(array(cast(_1#21 as string), _2#22, _3#23, ...) > 0` 2. Because of the cast, the `ConstantFolding` rule can't optimize this `size(array(...))`. 3. We end up with a plan containing this part ``` +- Project [_1#21 AS a#106, _2#22 AS b#107, _3#23 AS c#108, _4#24 AS d#109, _5#25 AS e#110, _6#26 AS f#111, _7#27 AS g#112, _8#28 AS h#113, _9#29 AS i#114, _10#30 AS j#115, _11#31 AS k#116, _12#32 AS l#117, _13#33 AS m#118, _14#34 AS n#119, _15#35 AS o#120, _16#36 AS p#121, _17#37 AS q#122, _18#38 AS r#123, _19#39 AS s#124, _20#40 AS t#125, _21#41 AS u#126] +- Filter (size(array(cast(_1#21 as string), _2#22, _3#23, _4#24, _5#25, _6#26, _7#27, _8#28, _9#29, _10#30, _11#31, _12#32, _13#33, _14#34, _15#35, _16#36, _17#37, _18#38, _19#39, _20#40, _21#41), true) > 0) +- LogicalRDD [_1#21, _2#22, _3#23, _4#24, _5#25, _6#26, _7#27, _8#28, _9#29, _10#30, _11#31, _12#32, _13#33, _14#34, _15#35, _16#36, _17#37, _18#38, _19#39, _20#40, _21#41] ``` When calculating the constraints of the `Project`, we generate around 2^20 expressions, due to this code ``` var allConstraints = child.constraints projectList.foreach { case a Alias(l: Literal, _) => allConstraints += EqualNullSafe(a.toAttribute, l) case a Alias(e, _) => // For every alias in `projectList`, replace the reference in constraints by its attribute. allConstraints ++= allConstraints.map(_ transform { case expr: Expression if expr.semanticEquals(e) => a.toAttribute }) allConstraints += EqualNullSafe(e, a.toAttribute) case _ => // Don't change. } ``` There are 3 issues here: 1. We may infer complicated predicates from `Generate` 2. `ConstanFolding` rule is too conservative. At least `Cast` has no side effect with ANSI-off. 3. When calculating constraints, we should have a upper bound to avoid generating too many expressions. This fixes the first 2 issues, and leaves the third one for the future. fix a performance issue no new tests, and run the query in JIRA ticket locally. Closes #34823 from cloud-fan/perf. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 1fac7a9d9992b7c120f325cdfa6a935b52c7f3bc) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 08 December 2021, 05:06:25 UTC |
| 2816017 | Daniel Dai | 07 December 2021, 14:48:23 UTC | [SPARK-37556][SQL] Deser void class fail with Java serialization **What changes were proposed in this pull request?** Change the deserialization mapping for primitive type void. **Why are the changes needed?** The void primitive type in Scala should be classOf[Unit] not classOf[Void]. Spark erroneously [map it](https://github.com/apache/spark/blob/v3.2.0/core/src/main/scala/org/apache/spark/serializer/JavaSerializer.scala#L80) differently than all other primitive types. Here is the code: ``` private object JavaDeserializationStream { val primitiveMappings = Map[String, Class[_]]( "boolean" -> classOf[Boolean], "byte" -> classOf[Byte], "char" -> classOf[Char], "short" -> classOf[Short], "int" -> classOf[Int], "long" -> classOf[Long], "float" -> classOf[Float], "double" -> classOf[Double], "void" -> classOf[Void] ) } ``` Spark code is Here is the demonstration: ``` scala> classOf[Long] val res0: Class[Long] = long scala> classOf[Double] val res1: Class[Double] = double scala> classOf[Byte] val res2: Class[Byte] = byte scala> classOf[Void] val res3: Class[Void] = class java.lang.Void <--- this is wrong scala> classOf[Unit] val res4: Class[Unit] = void <---- this is right ``` It will result in Spark deserialization error if the Spark code contains void primitive type: `java.io.InvalidClassException: java.lang.Void; local class name incompatible with stream class name "void"` **Does this PR introduce any user-facing change?** no **How was this patch tested?** Changed test, also tested e2e with the code results deserialization error and it pass now. Closes #34816 from daijyc/voidtype. Authored-by: Daniel Dai <jdai@pinterest.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit fb40c0e19f84f2de9a3d69d809e9e4031f76ef90) Signed-off-by: Sean Owen <srowen@gmail.com> | 07 December 2021, 15:25:24 UTC |
| 3bc3b13 | weixiuli | 03 December 2021, 03:34:36 UTC | [SPARK-37524][SQL] We should drop all tables after testing dynamic partition pruning ### What changes were proposed in this pull request? Drop all tables after testing dynamic partition pruning. ### Why are the changes needed? We should drop all tables after testing dynamic partition pruning. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Exist unittests Closes #34768 from weixiuli/SPARK-11150-fix. Authored-by: weixiuli <weixiuli@jd.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 2433c942ca39b948efe804aeab0185a3f37f3eea) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 03 December 2021, 03:35:14 UTC |
| 17c36a0 | Wenchen Fan | 01 December 2021, 08:33:52 UTC | [SPARK-37389][SQL][FOLLOWUP] SET command shuold not parse comments This PR is a followup of https://github.com/apache/spark/pull/34668 , to fix a breaking change. The SET command uses wildcard which may contain unclosed comment, e.g. `/path/to/*`, and we shouldn't fail it. This PR fixes it by skipping the unclosed comment check if we are parsing SET command. fix a breaking change no, the breaking change is not released yet. new tests Closes #34763 from cloud-fan/set. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit eaa135870a30fb89c2f1087991328a6f72a1860c) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 01 December 2021, 08:39:34 UTC |
| 75cac1f | Dongjoon Hyun | 01 December 2021, 02:41:18 UTC | [SPARK-37497][K8S] Promote `ExecutorPods[PollingSnapshot|WatchSnapshot]Source` to DeveloperApi ### What changes were proposed in this pull request? This PR aims to promote `ExecutorPodsWatchSnapshotSource` and `ExecutorPodsPollingSnapshotSource` as **stable** `DeveloperApi` in order to maintain it officially in a backward compatible way at Apache Spark 3.3.0. ### Why are the changes needed? - Since SPARK-24248 at Apache Spark 2.4.0, `ExecutorPodsWatchSnapshotSource` and `ExecutorPodsPollingSnapshotSource` have been used to monitor executor pods without any interface changes for over 3 years. - Apache Spark 3.1.1 makes `Kubernetes` module GA and provides an extensible external cluster manager framework. New `ExternalClusterManager` for K8s environment need to depend on this to monitor pods. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manual review. Closes #34751 from dongjoon-hyun/SPARK-37497. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 2b044962cd6eff5a3a76f2808ee93b40bdf931df) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 01 December 2021, 02:41:56 UTC |
| b8b5f94 | yangjie01 | 30 November 2021, 22:40:54 UTC | [SPARK-37505][MESOS][TESTS] Add a log4j.properties for `mesos` module UT ### What changes were proposed in this pull request? `scalatest-maven-plugin` configure `file:src/test/resources/log4j.properties` as the UT log configuration, so this PR adds this `log4j.properties` file to the mesos module for UT. ### Why are the changes needed? Supplement missing log4j configuration file for mesos module . ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? - Pass the Jenkins or GitHub Action - Manual test **Before** Run ``` mvn clean install -pl resource-managers/mesos -Pmesos -am -DskipTests mvn test -pl resource-managers/mesos -Pmesos ``` will print the following log: ``` log4j:ERROR Could not read configuration file from URL [file:src/test/resources/log4j.properties]. java.io.FileNotFoundException: src/test/resources/log4j.properties (No such file or directory) at java.io.FileInputStream.open0(Native Method) at java.io.FileInputStream.open(FileInputStream.java:195) at java.io.FileInputStream.<init>(FileInputStream.java:138) at java.io.FileInputStream.<init>(FileInputStream.java:93) at sun.net.www.protocol.file.FileURLConnection.connect(FileURLConnection.java:90) at sun.net.www.protocol.file.FileURLConnection.getInputStream(FileURLConnection.java:188) at org.apache.log4j.PropertyConfigurator.doConfigure(PropertyConfigurator.java:557) at org.apache.log4j.helpers.OptionConverter.selectAndConfigure(OptionConverter.java:526) at org.apache.log4j.LogManager.<clinit>(LogManager.java:127) at org.slf4j.impl.Log4jLoggerFactory.<init>(Log4jLoggerFactory.java:66) at org.slf4j.impl.StaticLoggerBinder.<init>(StaticLoggerBinder.java:72) at org.slf4j.impl.StaticLoggerBinder.<clinit>(StaticLoggerBinder.java:45) at org.apache.spark.internal.Logging$.org$apache$spark$internal$Logging$$isLog4j12(Logging.scala:222) at org.apache.spark.internal.Logging.initializeLogging(Logging.scala:127) at org.apache.spark.internal.Logging.initializeLogIfNecessary(Logging.scala:111) at org.apache.spark.internal.Logging.initializeLogIfNecessary$(Logging.scala:105) at org.apache.spark.SparkFunSuite.initializeLogIfNecessary(SparkFunSuite.scala:62) at org.apache.spark.internal.Logging.initializeLogIfNecessary(Logging.scala:102) at org.apache.spark.internal.Logging.initializeLogIfNecessary$(Logging.scala:101) at org.apache.spark.SparkFunSuite.initializeLogIfNecessary(SparkFunSuite.scala:62) at org.apache.spark.internal.Logging.log(Logging.scala:49) at org.apache.spark.internal.Logging.log$(Logging.scala:47) at org.apache.spark.SparkFunSuite.log(SparkFunSuite.scala:62) at org.apache.spark.SparkFunSuite.<init>(SparkFunSuite.scala:74) at org.apache.spark.scheduler.cluster.mesos.MesosCoarseGrainedSchedulerBackendSuite.<init>(MesosCoarseGrainedSchedulerBackendSuite.scala:43) at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at java.lang.Class.newInstance(Class.java:442) at org.scalatest.tools.DiscoverySuite$.getSuiteInstance(DiscoverySuite.scala:66) at org.scalatest.tools.DiscoverySuite.$anonfun$nestedSuites$1(DiscoverySuite.scala:38) at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:286) at scala.collection.Iterator.foreach(Iterator.scala:943) at scala.collection.Iterator.foreach$(Iterator.scala:943) at scala.collection.AbstractIterator.foreach(Iterator.scala:1431) at scala.collection.IterableLike.foreach(IterableLike.scala:74) at scala.collection.IterableLike.foreach$(IterableLike.scala:73) at scala.collection.AbstractIterable.foreach(Iterable.scala:56) at scala.collection.TraversableLike.map(TraversableLike.scala:286) at scala.collection.TraversableLike.map$(TraversableLike.scala:279) at scala.collection.AbstractTraversable.map(Traversable.scala:108) at org.scalatest.tools.DiscoverySuite.<init>(DiscoverySuite.scala:37) at org.scalatest.tools.Runner$.genDiscoSuites$1(Runner.scala:1132) at org.scalatest.tools.Runner$.doRunRunRunDaDoRunRun(Runner.scala:1226) at org.scalatest.tools.Runner$.$anonfun$runOptionallyWithPassFailReporter$24(Runner.scala:993) at org.scalatest.tools.Runner$.$anonfun$runOptionallyWithPassFailReporter$24$adapted(Runner.scala:971) at org.scalatest.tools.Runner$.withClassLoaderAndDispatchReporter(Runner.scala:1482) at org.scalatest.tools.Runner$.runOptionallyWithPassFailReporter(Runner.scala:971) at org.scalatest.tools.Runner$.main(Runner.scala:775) at org.scalatest.tools.Runner.main(Runner.scala) log4j:ERROR Ignoring configuration file [file:src/test/resources/log4j.properties]. Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties ``` and test log will print to console. **After** No above log in console and test log will print to `resource-managers/mesos/target/unit-tests.log` as other module. Closes #34759 from LuciferYang/SPARK-37505. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit fdb33dd9e27ac5d69ea875ca5bb85dfd369e71f1) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 30 November 2021, 22:41:16 UTC |
| 4aac443 | Kent Yao | 30 November 2021, 04:26:43 UTC | [SPARK-37452][SQL][3.1] Char and Varchar break backward compatibility between v3.1 and v2 This backports https://github.com/apache/spark/pull/34697 to 3.1 ### What changes were proposed in this pull request? We will store table schema in table properties for the read-side to restore. In Spark 3.1, we add char/varchar support natively. In some commands like `create table`, `alter table` with these types, the `char(x)` or `varchar(x)` will be stored directly to those properties. If a user uses Spark 2 to read such a table it will fail to parse the schema. FYI, https://github.com/apache/spark/blob/branch-2.4/sql/catalyst/src/main/scala/org/apache/spark/sql/types/DataType.scala#L136 A table can be a newly created one by Spark 3.1 and later or an existing one modified by Spark 3.1 and on. ### Why are the changes needed? backward compatibility ### Does this PR introduce _any_ user-facing change? That's not necessarily user-facing as a bugfix and only related to internal table properties. ### How was this patch tested? manully Closes #34736 from yaooqinn/PR_TOOL_PICK_PR_34697_BRANCH-3.1. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 30 November 2021, 04:26:43 UTC |
| 61074aa | Jiaan Geng | 25 November 2021, 07:28:14 UTC | [SPARK-37389][SQL][3.1] Check unclosed bracketed comments ### What changes were proposed in this pull request? This PR used to backport https://github.com/apache/spark/pull/34668 to branch 3.1 ### Why are the changes needed? The execute plan is not expected, if we don't check unclosed bracketed comments. ### Does this PR introduce _any_ user-facing change? 'Yes'. The behavior of bracketed comments will more correctly. ### How was this patch tested? New tests. Closes #34696 from beliefer/SPARK-37389-backport-3.1. Authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 25 November 2021, 07:28:14 UTC |
| 4c0d22d | Tom van Bussel | 22 November 2021, 08:18:30 UTC | [SPARK-37388][SQL] Fix NPE in WidthBucket in WholeStageCodegenExec This PR fixes a `NullPointerException` in `WholeStageCodegenExec` caused by the expression `WidthBucket`. The cause of this NPE is that `WidthBucket` calls `WidthBucket.computeBucketNumber`, which can return `null`, but the generated code cannot deal with `null`s. This fixes a `NullPointerException` in Spark SQL. No Added tests to `MathExpressionsSuite`. This suite already had tests for `WidthBucket` with interval inputs, but lacked tests with double inputs. I checked that the tests failed without the fix, and succeed with the fix. Closes #34670 from tomvanbussel/SPARK-37388. Authored-by: Tom van Bussel <tom.vanbussel@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 77f397464823a547c27d98ed306703cb9c73cec3) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 22 November 2021, 08:21:39 UTC |
| a1851cb | yangjie01 | 22 November 2021, 01:11:40 UTC | [SPARK-37209][YARN][TESTS] Fix `YarnShuffleIntegrationSuite` releated UTs when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars` ### What changes were proposed in this pull request? `YarnShuffleIntegrationSuite`, `YarnShuffleAuthSuite` and `YarnShuffleAlternateNameConfigSuite` will failed when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars`, the fail reason is `java.lang.NoClassDefFoundError: breeze/linalg/Matrix`. The above UTS can succeed when using `hadoop-2.7` profile without `assembly/target/scala-%s/jars` because `KryoSerializer.loadableSparkClasses` can workaroud when `Utils.isTesting` is true, but `Utils.isTesting` is false when using `hadoop-3.2` profile. After investigated, I found that when `hadoop-2.7` profile is used, `SPARK_TESTING` will be propagated to AM and Executor, but when `hadoop-3.2` profile is used, `SPARK_TESTING` will not be propagated to AM and Executor. In order to ensure the consistent behavior of using `hadoop-2.7` and ``hadoop-3.2``, this pr change to manually propagate `SPARK_TESTING` environment variable if it exists to ensure `Utils.isTesting` is true in above test scenario. ### Why are the changes needed? Ensure `YarnShuffleIntegrationSuite` releated UTs can succeed when using `hadoop-3.2` profile without `assembly/target/scala-%s/jars` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass the Jenkins or GitHub Action - Manual test `YarnShuffleIntegrationSuite`. `YarnShuffleAuthSuite` and `YarnShuffleAlternateNameConfigSuite` can be verified in the same way. Please ensure that the `assembly/target/scala-%s/jars` directory does not exist before executing the test command, we can clean up the whole project by executing follow command or clone a new local code repo. 1. run with `hadoop-3.2` profile ``` mvn clean install -Phadoop-3.2 -Pyarn -Dtest=none -DwildcardSuites=org.apache.spark.deploy.yarn.YarnShuffleIntegrationSuite ``` **Before** ``` YarnShuffleIntegrationSuite: - external shuffle service *** FAILED *** FAILED did not equal FINISHED (stdout/stderr was not captured) (BaseYarnClusterSuite.scala:227) Run completed in 48 seconds, 137 milliseconds. Total number of tests run: 1 Suites: completed 2, aborted 0 Tests: succeeded 0, failed 1, canceled 0, ignored 0, pending 0 *** 1 TEST FAILED *** ``` Error stack as follows: ``` 21/11/20 23:00:09.682 main ERROR Client: Application diagnostics message: User class threw exception: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 6) (localhost executor 1): java.lang.NoClassDefFoundError: breeze/linalg/Matrix at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:348) at org.apache.spark.util.Utils$.classForName(Utils.scala:216) at org.apache.spark.serializer.KryoSerializer$.$anonfun$loadableSparkClasses$1(KryoSerializer.scala:537) at scala.collection.immutable.List.flatMap(List.scala:366) at org.apache.spark.serializer.KryoSerializer$.loadableSparkClasses$lzycompute(KryoSerializer.scala:535) at org.apache.spark.serializer.KryoSerializer$.org$apache$spark$serializer$KryoSerializer$$loadableSparkClasses(KryoSerializer.scala:502) at org.apache.spark.serializer.KryoSerializer.newKryo(KryoSerializer.scala:226) at org.apache.spark.serializer.KryoSerializer$$anon$1.create(KryoSerializer.scala:102) at com.esotericsoftware.kryo.pool.KryoPoolQueueImpl.borrow(KryoPoolQueueImpl.java:48) at org.apache.spark.serializer.KryoSerializer$PoolWrapper.borrow(KryoSerializer.scala:109) at org.apache.spark.serializer.KryoSerializerInstance.borrowKryo(KryoSerializer.scala:346) at org.apache.spark.serializer.KryoSerializationStream.<init>(KryoSerializer.scala:266) at org.apache.spark.serializer.KryoSerializerInstance.serializeStream(KryoSerializer.scala:432) at org.apache.spark.shuffle.ShufflePartitionPairsWriter.open(ShufflePartitionPairsWriter.scala:76) at org.apache.spark.shuffle.ShufflePartitionPairsWriter.write(ShufflePartitionPairsWriter.scala:59) at org.apache.spark.util.collection.WritablePartitionedIterator.writeNext(WritablePartitionedPairCollection.scala:83) at org.apache.spark.util.collection.ExternalSorter.$anonfun$writePartitionedMapOutput$1(ExternalSorter.scala:772) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1468) at org.apache.spark.util.collection.ExternalSorter.writePartitionedMapOutput(ExternalSorter.scala:775) at org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:70) at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52) at org.apache.spark.scheduler.Task.run(Task.scala:136) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:507) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1468) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:510) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.lang.ClassNotFoundException: breeze.linalg.Matrix at java.net.URLClassLoader.findClass(URLClassLoader.java:382) at java.lang.ClassLoader.loadClass(ClassLoader.java:419) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352) at java.lang.ClassLoader.loadClass(ClassLoader.java:352) ... 32 more ``` **After** ``` YarnShuffleIntegrationSuite: - external shuffle service Run completed in 35 seconds, 188 milliseconds. Total number of tests run: 1 Suites: completed 2, aborted 0 Tests: succeeded 1, failed 0, canceled 0, ignored 0, pending 0 All tests passed. ``` 2. run with `hadoop-2.7` profile ``` mvn clean install -Phadoop-2.7 -Pyarn -Dtest=none -DwildcardSuites=org.apache.spark.deploy.yarn.YarnShuffleIntegrationSuite ``` **Before** ``` YarnShuffleIntegrationSuite: - external shuffle service Run completed in 30 seconds, 828 milliseconds. Total number of tests run: 1 Suites: completed 2, aborted 0 Tests: succeeded 1, failed 0, canceled 0, ignored 0, pending 0 All tests passed. ``` **After** ``` YarnShuffleIntegrationSuite: - external shuffle service Run completed in 30 seconds, 967 milliseconds. Total number of tests run: 1 Suites: completed 2, aborted 0 Tests: succeeded 1, failed 0, canceled 0, ignored 0, pending 0 All tests passed. ``` Closes #34620 from LuciferYang/SPARK-37209. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit a7b3fc7cef4c5df0254b945fe9f6815b072b31dd) Signed-off-by: Sean Owen <srowen@gmail.com> | 22 November 2021, 01:12:13 UTC |
| d96e5de | zero323 | 20 November 2021, 10:45:27 UTC | [SPARK-37390][PYTHON][DOCS] Add default value to getattr(app, add_javascript) ### What changes were proposed in this pull request? This PR adds `default` (`None`) value to `getattr(app, add_javascript)`. ### Why are the changes needed? Current logic fails on `getattr(app, "add_javascript")` when executed with Sphinx 4.x. The problem can be illustrated with a simple snippet. ```python >>> class Sphinx: ... def add_js_file(self, filename: str, priority: int = 500, **kwargs: Any) -> None: ... ... >>> app = Sphinx() >>> getattr(app, "add_js_file", getattr(app, "add_javascript")) Traceback (most recent call last): File "<ipython-input-11-442ab6dfc933>", line 1, in <module> getattr(app, "add_js_file", getattr(app, "add_javascript")) AttributeError: 'Sphinx' object has no attribute 'add_javascript' ``` After this PR is merged we'll fallback to `getattr(app, "add_js_file")`: ```python >>> getattr(app, "add_js_file", getattr(app, "add_javascript", None)) <bound method Sphinx.add_js_file of <__main__.Sphinx object at 0x7f444456abe0>> ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manual docs build. Closes #34669 from zero323/SPARK-37390. Authored-by: zero323 <mszymkiewicz@gmail.com> Signed-off-by: zero323 <mszymkiewicz@gmail.com> (cherry picked from commit b9e9167f589db372f0416425cdf35b48a6216b50) Signed-off-by: zero323 <mszymkiewicz@gmail.com> | 20 November 2021, 10:46:08 UTC |
| 04af08e | zero323 | 19 November 2021, 00:47:17 UTC | [MINOR][R][DOCS] Fix minor issues in SparkR docs examples ### What changes were proposed in this pull request? This PR fixes two minor problems in SpakR `examples` - Replace misplaced standard comment (`#`) with roxygen comment (`#'`) in `sparkR.session` `examples` - Add missing comma in `write.stream` examples. ### Why are the changes needed? - `sparkR.session` examples are not fully rendered. - `write.stream` example is not syntactically valid. ### Does this PR introduce _any_ user-facing change? Docs only. ### How was this patch tested? Manual inspection of build docs. Closes #34654 from zero323/sparkr-docs-fixes. Authored-by: zero323 <mszymkiewicz@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 207dd4ce72a5566c554f224edb046106cf97b952) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 19 November 2021, 00:47:53 UTC |
| 380441a | Angerszhuuuu | 16 November 2021, 23:56:21 UTC | [SPARK-37346][DOC] Add migration guide link for structured streaming ### What changes were proposed in this pull request? Add migration guide link for structured streaming ### Why are the changes needed? Add migration guide link for structured streaming ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Not need Closes #34618 from AngersZhuuuu/SPARK-37346. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 1b84a6b3cc6ace4f8cf3b2ca700991ae43bcf4bd) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 16 November 2021, 23:56:54 UTC |
| 608c19c | Dongjoon Hyun | 14 November 2021, 23:48:49 UTC | [SPARK-37323][INFRA][3.1] Pin `docutils` to 0.17.x ### What changes were proposed in this pull request? This PR aims to ping `docutils` to `0.17.x` to recover branch-3.1 GitHub Action linter job. ### Why are the changes needed? `docutils` 0.18 is released October 26 and causes Python linter failure in branch-3.1. - https://pypi.org/project/docutils/#history - https://github.com/apache/spark/commits/branch-3.1 ``` Exception occurred: File "/__t/Python/3.6.15/x64/lib/python3.6/site-packages/docutils/writers/html5_polyglot/__init__.py", line 445, in section_title_tags if (ids and self.settings.section_self_link AttributeError: 'Values' object has no attribute 'section_self_link' The full traceback has been saved in /tmp/sphinx-err-y2ttd83t.log, if you want to report the issue to the developers. Please also report this if it was a user error, so that a better error message can be provided next time. A bug report can be filed in the tracker at <https://github.com/sphinx-doc/sphinx/issues>. Thanks! make: *** [Makefile:20: html] Error 2 Error: Process completed with exit code 2. ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass the linter job on this PR. Closes #34591 from dongjoon-hyun/SPARK-37323. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 14 November 2021, 23:48:49 UTC |
| 3d1427f | William Hyun | 14 November 2021, 20:32:36 UTC | [SPARK-37322][TESTS] `run_scala_tests` should respect test module order ### What changes were proposed in this pull request? This PR aims to make `run_scala_tests` respect test module order ### Why are the changes needed? Currently the execution order is random. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Manually through the following and check if the catalyst module runs first. ``` $ SKIP_MIMA=1 SKIP_UNIDOC=1 ./dev/run-tests --parallelism 1 --modules "catalyst,hive-thriftserver" ``` Closes #34590 from williamhyun/order. Authored-by: William Hyun <william@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit c2221a8e3d95ce22d76208c705179c5954318567) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 14 November 2021, 20:32:54 UTC |
| 97a8b10 | Kousuke Saruta | 14 November 2021, 16:45:20 UTC | [SPARK-37320][K8S][TESTS] Delete py_container_checks.zip after the test in DepsTestsSuite finishes ### What changes were proposed in this pull request? This PR fixes an issue that `py_container_checks.zip` still remains in `resource-managers/kubernetes/integration-tests/tests/` even after the test `Launcher python client dependencies using a zip file` in `DepsTestsSuite` finishes. ### Why are the changes needed? To keep the repository clean. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Confirmed that the zip file will be removed after the test finishes with the following command using MiniKube. ``` PVC_TESTS_HOST_PATH=/path PVC_TESTS_VM_PATH=/path build/mvn -Dspark.kubernetes.test.namespace=default -Pkubernetes -Pkubernetes-integration-tests -pl resource-managers/kubernetes/integration-tests integration-test ``` Closes #34588 from sarutak/remove-zip-k8s. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit d8cee85e0264fe879f9d1eeec7541a8e94ff83f6) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 14 November 2021, 16:45:39 UTC |
| e397c77 | zero323 | 13 November 2021, 14:53:24 UTC | [SPARK-37288][PYTHON][3.2] Backport since annotation update ### What changes were proposed in this pull request? This PR changes since annotation to support `float` arguments: ```python def since(version: Union[str, float]) -> Callable[[T], T]: ... ``` ### Why are the changes needed? `since` is used with both `str` and `float` both in Spark and related libraries and this change has been already done for Spark >= 3.3 (SPARK-36906), Note that this technically fixes a bug in the downstream projects that run mypy checks against `pyspark.since`. When they use it, for example, with `pyspark.since(3.2)`, mypy checks fails; however, this case is legitimate. After this change, the mypy check can pass in thier CIs. ### Does this PR introduce _any_ user-facing change? ```python since(3.2) def f(): ... ``` is going to type check if downstream projects run mypy to validate the types. Otherwise, it does not affect anything invasive or user-facing behavior change. ### How was this patch tested? Existing tests and manual testing. Closes #34555 from zero323/SPARK-37288. Authored-by: zero323 <mszymkiewicz@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit bdde69363f75f4f37370e38cddb47cd3631168b0) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 13 November 2021, 14:53:42 UTC |
| 599e258 | Dongjoon Hyun | 09 November 2021, 11:03:34 UTC | [SPARK-37253][PYTHON] `try_simplify_traceback` should not fail when `tb_frame.f_lineno` is None ### What changes were proposed in this pull request? This PR aims to handle the corner case when `tb_frame.f_lineno` is `None` in `try_simplify_traceback` which was added by https://github.com/apache/spark/pull/30309 at Apache Spark 3.1.0. ### Why are the changes needed? This will handle the following corner case. ```python Traceback (most recent call last): File "/Users/dongjoon/APACHE/spark-merge/python/lib/pyspark.zip/pyspark/worker.py", line 630, in main tb = try_simplify_traceback(sys.exc_info()[-1]) File "/Users/dongjoon/APACHE/spark-merge/python/lib/pyspark.zip/pyspark/util.py", line 217, in try_simplify_traceback new_tb = types.TracebackType( TypeError: 'NoneType' object cannot be interpreted as an integer ``` Python GitHub Repo also has the test case for this corner case. - https://github.com/python/cpython/blob/main/Lib/test/test_exceptions.py#L2373 ```python None if frame.f_lineno is None else ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? N/A Closes #34530 from dongjoon-hyun/SPARK-37253. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 8ae88d01b46d581367d0047b50fcfb65078ab972) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 09 November 2021, 11:03:56 UTC |
| faba1fe | Dongjoon Hyun | 09 November 2021, 02:37:03 UTC | [SPARK-37252][PYTHON][TESTS] Ignore `test_memory_limit` on non-Linux environment ### What changes were proposed in this pull request? This PR aims to ignore `test_memory_limit` on non-Linux environment. ### Why are the changes needed? Like the documentation https://github.com/apache/spark/pull/23664, it fails on non-Linux environment like the following MacOS example. **BEFORE** ``` $ build/sbt -Phadoop-cloud -Phadoop-3.2 test:package $ python/run-tests --modules pyspark-core ... ====================================================================== FAIL: test_memory_limit (pyspark.tests.test_worker.WorkerMemoryTest) ---------------------------------------------------------------------- Traceback (most recent call last): File "/Users/dongjoon/APACHE/spark-merge/python/pyspark/tests/test_worker.py", line 212, in test_memory_limit self.assertEqual(soft_limit, 2 * 1024 * 1024 * 1024) AssertionError: 9223372036854775807 != 2147483648 ---------------------------------------------------------------------- ``` **AFTER** ``` ... Tests passed in 104 seconds Skipped tests in pyspark.tests.test_serializers with /Users/dongjoon/.pyenv/versions/3.8.12/bin/python3: test_serialize (pyspark.tests.test_serializers.SciPyTests) ... skipped 'SciPy not installed' Skipped tests in pyspark.tests.test_worker with /Users/dongjoon/.pyenv/versions/3.8.12/bin/python3: test_memory_limit (pyspark.tests.test_worker.WorkerMemoryTest) ... skipped "Memory limit feature in Python worker is dependent on Python's 'resource' module on Linux; however, not found or not on Linux." ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Manual. Closes #34527 from dongjoon-hyun/SPARK-37252. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 2c7f20151e99c212443a1f8762350d0a96a26440) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 09 November 2021, 02:38:33 UTC |
| 84937e1 | Angerszhuuuu | 08 November 2021, 20:08:32 UTC | [SPARK-37196][SQL] HiveDecimal enforcePrecisionScale failed return null For case ``` withTempDir { dir => withSQLConf(HiveUtils.CONVERT_METASTORE_PARQUET.key -> "false") { withTable("test_precision") { val df = sql("SELECT 'dummy' AS name, 1000000000000000000010.7000000000000010 AS value") df.write.mode("Overwrite").parquet(dir.getAbsolutePath) sql( s""" |CREATE EXTERNAL TABLE test_precision(name STRING, value DECIMAL(18,6)) |STORED AS PARQUET LOCATION '${dir.getAbsolutePath}' |""".stripMargin) checkAnswer(sql("SELECT * FROM test_precision"), Row("dummy", null)) } } } ``` We write a data with schema It's caused by you create a df with ``` root |-- name: string (nullable = false) |-- value: decimal(38,16) (nullable = false) ``` but create table schema ``` root |-- name: string (nullable = false) |-- value: decimal(18,6) (nullable = false) ``` This will cause enforcePrecisionScale return `null` ``` public HiveDecimal getPrimitiveJavaObject(Object o) { return o == null ? null : this.enforcePrecisionScale(((HiveDecimalWritable)o).getHiveDecimal()); } ``` Then throw NPE when call `toCatalystDecimal ` We should judge if the return value is `null` to avoid throw NPE Fix bug No Added UT Closes #34519 from AngersZhuuuu/SPARK-37196. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit a4f8ffbbfb0158a03ff52f1ed0dde75241c3a90e) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 08 November 2021, 20:15:37 UTC |
| acc4293 | Jiaan Geng | 05 November 2021, 08:13:11 UTC | [SPARK-37203][SQL] Fix NotSerializableException when observe with TypedImperativeAggregate Currently, ``` val namedObservation = Observation("named") val df = spark.range(100) val observed_df = df.observe( namedObservation, percentile_approx($"id", lit(0.5), lit(100)).as("percentile_approx_val")) observed_df.collect() namedObservation.get ``` throws exception as follows: ``` 15:16:27.994 ERROR org.apache.spark.util.Utils: Exception encountered java.io.NotSerializableException: org.apache.spark.sql.catalyst.expressions.aggregate.ApproximatePercentile$PercentileDigest at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1184) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1548) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1509) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1432) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178) at java.io.ObjectOutputStream.writeArray(ObjectOutputStream.java:1378) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1174) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1548) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1509) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1432) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1548) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1509) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1432) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178) at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:348) at org.apache.spark.scheduler.DirectTaskResult.$anonfun$writeExternal$2(TaskResult.scala:55) at org.apache.spark.scheduler.DirectTaskResult.$anonfun$writeExternal$2$adapted(TaskResult.scala:55) at scala.collection.Iterator.foreach(Iterator.scala:943) at scala.collection.Iterator.foreach$(Iterator.scala:943) at scala.collection.AbstractIterator.foreach(Iterator.scala:1431) at scala.collection.IterableLike.foreach(IterableLike.scala:74) at scala.collection.IterableLike.foreach$(IterableLike.scala:73) at scala.collection.AbstractIterable.foreach(Iterable.scala:56) at org.apache.spark.scheduler.DirectTaskResult.$anonfun$writeExternal$1(TaskResult.scala:55) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at org.apache.spark.util.Utils$.tryOrIOException(Utils.scala:1434) at org.apache.spark.scheduler.DirectTaskResult.writeExternal(TaskResult.scala:51) at java.io.ObjectOutputStream.writeExternalData(ObjectOutputStream.java:1459) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1430) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178) at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:348) at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44) at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:616) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) ``` This PR will fix the issue. After the change, `assert(namedObservation.get === Map("percentile_approx_val" -> 49))` `java.io.NotSerializableException` will not happen. Fix `NotSerializableException` when observe with `TypedImperativeAggregate`. No. This PR change the implement of `AggregatingAccumulator` who uses serialize and deserialize of `TypedImperativeAggregate` now. New tests. Closes #34474 from beliefer/SPARK-37203. Authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 3f3201a7882b817a8a3ecbfeb369dde01e7689d8) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 05 November 2021, 08:29:21 UTC |
| e9bead7 | mans2singh | 02 November 2021, 02:01:57 UTC | [MINOR][DOCS] Corrected spacing in structured streaming programming ### What changes were proposed in this pull request? There is no space between `with` and `<code>` as shown below: `... configured with<code>spark.sql.streaming.fileSource.cleaner.numThreads</code> ...` ### Why are the changes needed? Added space ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Only documentation was changed and no code was change. Closes #34458 from mans2singh/structured_streaming_programming_guide_space. Authored-by: mans2singh <mans2singh@yahoo.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 675071a38e47dc2c55cf4f71de7ad0bebc1b4f2b) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 02 November 2021, 02:02:40 UTC |
| 5db119f | ulysses-you | 26 October 2021, 07:53:38 UTC | [SPARK-37098][SQL][3.1] Alter table properties should invalidate cache This PR backport https://github.com/apache/spark/pull/34365 to branch-3.1 ### What changes were proposed in this pull request? Invalidate the table cache after alter table properties (set and unset). ### Why are the changes needed? The table properties can change the behavior of wriing. e.g. the parquet table with `parquet.compression`. If you execute the following SQL, we will get the file with snappy compression rather than zstd. ``` CREATE TABLE t (c int) STORED AS PARQUET; // cache table metadata SELECT * FROM t; ALTER TABLE t SET TBLPROPERTIES('parquet.compression'='zstd'); INSERT INTO TABLE t values(1); ``` So we should invalidate the table cache after alter table properties. ### Does this PR introduce _any_ user-facing change? yes, bug fix ### How was this patch tested? Add test Closes #34390 from ulysses-you/SOARK-37098-3.1. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 26 October 2021, 07:53:38 UTC |
| 05aea97 | Kent Yao | 26 October 2021, 03:10:10 UTC | Revert "[SPARK-37098][SQL] Alter table properties should invalidate cache" This reverts commit 286a37663213ef3abfbf9effb8cd5723ec6382ff. | 26 October 2021, 03:10:10 UTC |
| 286a376 | ulysses-you | 25 October 2021, 08:02:38 UTC | [SPARK-37098][SQL] Alter table properties should invalidate cache ### What changes were proposed in this pull request? Invalidate the table cache after alter table properties (set and unset). ### Why are the changes needed? The table properties can change the behavior of wriing. e.g. the parquet table with `parquet.compression`. If you execute the following SQL, we will get the file with snappy compression rather than zstd. ``` CREATE TABLE t (c int) STORED AS PARQUET; // cache table metadata SELECT * FROM t; ALTER TABLE t SET TBLPROPERTIES('parquet.compression'='zstd'); INSERT INTO TABLE t values(1); ``` So we should invalidate the table cache after alter table properties. ### Does this PR introduce _any_ user-facing change? yes, bug fix ### How was this patch tested? Add test Closes #34365 from ulysses-you/SPARK-37098. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Kent Yao <yao@apache.org> (cherry picked from commit 02d3b3b452892779b3f0df7018a9574fde02afee) Signed-off-by: Kent Yao <yao@apache.org> | 25 October 2021, 08:03:24 UTC |
| c23698f | Takuya UESHIN | 21 October 2021, 01:25:42 UTC | [SPARK-37079][PYTHON][SQL] Fix DataFrameWriterV2.partitionedBy to send the arguments to JVM properly ### What changes were proposed in this pull request? Fix `DataFrameWriterV2.partitionedBy` to send the arguments to JVM properly. ### Why are the changes needed? In PySpark, `DataFrameWriterV2.partitionedBy` doesn't send the arguments to JVM properly. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manually checked whether the arguments are sent to JVM or not. Closes #34347 from ueshin/issues/SPARK-37079/partitionBy. Authored-by: Takuya UESHIN <ueshin@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 33deeb35f1c994328b577970d4577e6d9288bfc2) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 21 October 2021, 01:26:08 UTC |
| 74fe4fa | Weiwei Yang | 20 October 2021, 05:42:06 UTC | [SPARK-37049][K8S] executorIdleTimeout should check `creationTimestamp` instead of `startTime` SPARK-33099 added the support to respect `spark.dynamicAllocation.executorIdleTimeout` in `ExecutorPodsAllocator`. However, when it checks if a pending executor pod is timed out, it checks against the pod's [startTime](https://github.com/kubernetes/api/blob/2a5dae08c42b1e8fdc1379432d8898efece65363/core/v1/types.go#L3664-L3667), see code [here](https://github.com/apache/spark/blob/c2ba498ff678ddda034cedf45cc17fbeefe922fd/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocator.scala#L459). A pending pod `startTime` is empty, and this causes the function `isExecutorIdleTimedOut()` always return true for pending pods. This can be reproduced locally, run the following job ``` ${SPARK_HOME}/bin/spark-submit --master k8s://http://localhost:8001 --deploy-mode cluster --name spark-group-example \ --master k8s://http://localhost:8001 --deploy-mode cluster \ --class org.apache.spark.examples.GroupByTest \ --conf spark.executor.instances=1 \ --conf spark.kubernetes.namespace=spark-test \ --conf spark.kubernetes.executor.request.cores=1 \ --conf spark.dynamicAllocation.enabled=true \ --conf spark.shuffle.service.enabled=true \ --conf spark.dynamicAllocation.shuffleTracking.enabled=true \ --conf spark.shuffle.service.enabled=false \ --conf spark.kubernetes.container.image=local/spark:3.3.0 \ --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \ local:///opt/spark/examples/jars/spark-examples_2.12-3.3.0-SNAPSHOT.jar \ 1000 1000 100 1000 ``` the local cluster doesn't have enough resources to run more than 4 executors, the rest of the executor pods will be pending. The job will have task backlogs and triggers to request more executors from K8s: ``` 21/10/19 22:51:45 INFO ExecutorPodsAllocator: Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 1 running: 0. 21/10/19 22:51:51 INFO ExecutorPodsAllocator: Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 2 running: 1. 21/10/19 22:51:52 INFO ExecutorPodsAllocator: Going to request 2 executors from Kubernetes for ResourceProfile Id: 0, target: 4 running: 2. 21/10/19 22:51:53 INFO ExecutorPodsAllocator: Going to request 4 executors from Kubernetes for ResourceProfile Id: 0, target: 8 running: 4. ... 21/10/19 22:52:14 INFO ExecutorPodsAllocator: Deleting 39 excess pod requests (23,59,32,41,50,68,35,44,17,8,53,62,26,71,11,56,29,38,47,20,65,5,14,46,64,73,55,49,40,67,58,13,22,31,7,16,52,70,43). 21/10/19 22:52:18 INFO ExecutorPodsAllocator: Deleting 28 excess pod requests (25,34,61,37,10,19,28,60,69,63,45,54,72,36,18,9,27,21,57,12,48,30,39,66,15,42,24,33). ``` At `22:51:45`, it starts to request executors; and at `22:52:14` it starts to delete excess executor pods. This is 29s but spark.dynamicAllocation.executorIdleTimeout is set to 60s. The config was not honored. ### What changes were proposed in this pull request? Change the check from using pod's `startTime` to `creationTimestamp`. [creationTimestamp](https://github.com/kubernetes/apimachinery/blob/e6c90c4366be1504309a6aafe0d816856450f36a/pkg/apis/meta/v1/types.go#L193-L201) is the timestamp when a pod gets created on K8s: ``` // CreationTimestamp is a timestamp representing the server time when this object was // created. It is not guaranteed to be set in happens-before order across separate operations. // Clients may not set this value. It is represented in RFC3339 form and is in UTC. ``` [startTime](https://github.com/kubernetes/api/blob/2a5dae08c42b1e8fdc1379432d8898efece65363/core/v1/types.go#L3664-L3667) is the timestamp when pod gets started: ``` // RFC 3339 date and time at which the object was acknowledged by the Kubelet. // This is before the Kubelet pulled the container image(s) for the pod. // +optional ``` a pending pod's startTime is empty. Here is a example of a pending pod: ``` NAMESPACE NAME READY STATUS RESTARTS AGE default pending-pod-example 0/1 Pending 0 2s kubectl get pod pending-pod-example -o yaml | grep creationTimestamp ---> creationTimestamp: "2021-10-19T16:17:52Z" // pending pod has no startTime kubectl get pod pending-pod-example -o yaml | grep startTime ---> // empty // running pod has startTime set to the timestamp when the pod gets started kubectl get pod coredns-558bd4d5db-6qrtx -n kube-system -o yaml | grep startTime f:startTime: {} ---> startTime: "2021-08-04T23:44:44Z" ``` ### Why are the changes needed? This fixed the issue that `spark.dynamicAllocation.executorIdleTimeout` currently is not honored by pending executor pods. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? The PR includes the UT changes, that has the testing coverage for this issue. Closes #34319 from yangwwei/SPARK-37049. Authored-by: Weiwei Yang <wyang@cloudera.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 041cd5d7d15ec4184ae51a8a10a26bef05bd261f) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 20 October 2021, 05:47:21 UTC |
| c43f355 | Josh Rosen | 14 October 2021, 21:34:24 UTC | [SPARK-23626][CORE] Eagerly compute RDD.partitions on entire DAG when submitting job to DAGScheduler ### What changes were proposed in this pull request? This PR fixes a longstanding issue where the `DAGScheduler'`s single-threaded event processing loop could become blocked by slow `RDD.getPartitions()` calls, preventing other events (like task completions and concurrent job submissions) from being processed in a timely manner. With this patch's change, Spark will now call `.partitions` on every RDD in the DAG before submitting a job to the scheduler, ensuring that the expensive `getPartitions()` calls occur outside of the scheduler event loop. #### Background The `RDD.partitions` method lazily computes an RDD's partitions by calling `RDD.getPartitions()`. The `getPartitions()` method is invoked only once per RDD and its result is cached in the `RDD.partitions_` private field. Sometimes the `getPartitions()` call can be expensive: for example, `HadoopRDD.getPartitions()` performs file listing operations. The `.partitions` method is invoked at many different places in Spark's code, including many existing call sites that are outside of the scheduler event loop. As a result, it's _often_ the case that an RDD's partitions will have been computed before the RDD is submitted to the DAGScheduler. For example, [`submitJob` calls `rdd.partitions.length`](https://github.com/apache/spark/blob/3ba57f5edc5594ee676249cd309b8f0d8248462e/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala#L837), so the DAG root's partitions will be computed outside of the scheduler event loop. However, there's still some cases where `partitions` gets evaluated for the first time inside of the `DAGScheduler` internals. For example, [`ShuffledRDD.getPartitions`](https://github.com/apache/spark/blob/3ba57f5edc5594ee676249cd309b8f0d8248462e/core/src/main/scala/org/apache/spark/rdd/ShuffledRDD.scala#L92-L94) doesn't call `.partitions` on the RDD being shuffled, so a plan with a ShuffledRDD at the root won't necessarily result in `.partitions` having been called on all RDDs prior to scheduler job submission. #### Correctness: proving that we make no excess `.partitions` calls This PR adds code to traverse the DAG prior to job submission and call `.partitions` on every RDD encountered. I'd like to argue that this results in no _excess_ `.partitions` calls: in every case where the new code calls `.partitions` there is existing code which would have called `.partitions` at some point during a successful job execution: - Assume that this is the first time we are computing every RDD in the DAG. - Every RDD appears in some stage. - [`submitStage` will call `submitMissingTasks`](https://github.com/databricks/runtime/blob/1e83dfe4f685bad7f260621e77282b1b4cf9bca4/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala#L1438) on every stage root RDD. - [`submitStage` calls `getPreferredLocsInternal`](https://github.com/databricks/runtime/blob/1e83dfe4f685bad7f260621e77282b1b4cf9bca4/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala#L1687-L1696) on every stage root RDD. - [`getPreferredLocsInternal`](https://github.com/databricks/runtime/blob/1e83dfe4f685bad7f260621e77282b1b4cf9bca4/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala#L2995-L3043) visits the RDD and all of its parents RDDs that are computed in the same stage (via narrow dependencies) and calls `.partitions` on each RDD visited. - Therefore `.partitions` is invoked on every RDD in the DAG by the time the job has successfully completed. - Therefore this patch's change does not introduce any new calls to `.partitions` which would not have otherwise occurred (assuming the job succeeded). #### Ordering of `.partitions` calls I don't think the order in which `.partitions` calls occur matters for correctness: the DAGScheduler happens to invoke `.partitions` in a particular order today (defined by the DAG traversal order in internal scheduler methods), but there's many lots of out-of-order `.partition` calls occurring elsewhere in the codebase. #### Handling of exceptions in `.partitions` I've chosen **not** to add special error-handling for the new `.partitions` calls: if exceptions occur then they'll bubble up, unwrapped, to the user code submitting the Spark job. It's sometimes important to preserve exception wrapping behavior, but I don't think that concern is warranted in this particular case: whether `getPartitions` occurred inside or outside of the scheduler (impacting whether exceptions manifest in wrapped or unwrapped form, and impacting whether failed jobs appear in the Spark UI) was not crisply defined (and in some rare cases could even be [influenced by Spark settings in non-obvious ways](https://github.com/apache/spark/blob/10d5303174bf4a47508f6227bbdb1eaf4c92fcdb/core/src/main/scala/org/apache/spark/Partitioner.scala#L75-L79)), so I think it's both unlikely that users were relying on the old behavior and very difficult to preserve it. #### Should this have a configuration flag? Per discussion from a previous PR trying to solve this problem (https://github.com/apache/spark/pull/24438#pullrequestreview-232692586), I've decided to skip adding a configuration flag for this. ### Why are the changes needed? This fixes a longstanding scheduler performance problem which has been reported by multiple users. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? I added a regression test in `BasicSchedulerIntegrationSuite` to cover the regular job submission codepath (`DAGScheduler.submitJob`)This test uses CountDownLatches to simulate the submission of a job containing an RDD with a slow `getPartitions()` call and checks that a concurrently-submitted job is not blocked. I have **not** added separate integration tests for the `runApproximateJob` and `submitMapStage` codepaths (both of which also received the same fix). Closes #34265 from JoshRosen/SPARK-23626. Authored-by: Josh Rosen <joshrosen@databricks.com> Signed-off-by: Josh Rosen <joshrosen@databricks.com> (cherry picked from commit c4e975e175c01f67ece7ae492a79554ad1b44106) Signed-off-by: Josh Rosen <joshrosen@databricks.com> | 14 October 2021, 21:35:46 UTC |
| fe2f646 | ulysses-you | 13 October 2021, 16:36:16 UTC | [SPARK-36993][SQL] Fix json_tuple throw NPE if fields exist no foldable null value ### What changes were proposed in this pull request? Wrap `expr.eval(input)` with Option in `json_tuple`. ### Why are the changes needed? If json_tuple exists no foldable null field, Spark would throw NPE during eval field.toString. e.g. the query will fail with: ```SQL SELECT json_tuple('{"a":"1"}', if(c1 < 1, null, 'a')) FROM ( SELECT rand() AS c1 ); ``` ``` Caused by: java.lang.NullPointerException at org.apache.spark.sql.catalyst.expressions.JsonTuple.$anonfun$parseRow$2(jsonExpressions.scala:435) at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:286) at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62) at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49) at scala.collection.TraversableLike.map(TraversableLike.scala:286) at scala.collection.TraversableLike.map$(TraversableLike.scala:279) at scala.collection.AbstractTraversable.map(Traversable.scala:108) at org.apache.spark.sql.catalyst.expressions.JsonTuple.parseRow(jsonExpressions.scala:435) at org.apache.spark.sql.catalyst.expressions.JsonTuple.$anonfun$eval$6(jsonExpressions.scala:413) ``` ### Does this PR introduce _any_ user-facing change? yes, bug fix. ### How was this patch tested? add test in `json-functions.sql`. Closes #34268 from ulysses-you/SPARK-36993. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> (cherry picked from commit 7aedce44b73d9b0c56863f970257abf52ce551ce) Signed-off-by: Max Gekk <max.gekk@gmail.com> | 13 October 2021, 16:36:47 UTC |
| 758b370 | daugraph | 08 October 2021, 12:11:26 UTC | [SPARK-36717][CORE] Incorrect order of variable initialization may lead incorrect behavior ### What changes were proposed in this pull request? Incorrect order of variable initialization may lead to incorrect behavior, related code: TorrentBroadcast.scala , TorrentBroadCast will get wrong checksumEnabled value after initialization, this may not be what we need, we can move L94 front of setConf(SparkEnv.get.conf) to avoid this. Supplement: Snippet 1 ```scala class Broadcast { def setConf(): Unit = { checksumEnabled = true } setConf() var checksumEnabled = false } println(new Broadcast().checksumEnabled) ``` output: ```scala false ``` Snippet 2 ```scala class Broadcast { var checksumEnabled = false def setConf(): Unit = { checksumEnabled = true } setConf() } println(new Broadcast().checksumEnabled) ``` output: ```scala true ``` ### Why are the changes needed? we can move L94 front of setConf(SparkEnv.get.conf) to avoid this. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? No Closes #33957 from daugraph/branch0. Authored-by: daugraph <daugraph@qq.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 65f6a7c1ecdcf7d6df798e30c9fc03a5dbe0b047) Signed-off-by: Sean Owen <srowen@gmail.com> | 08 October 2021, 12:11:49 UTC |
| 33b30aa | Kousuke Saruta | 07 October 2021, 06:56:52 UTC | [SPARK-36874][SPARK-34634][SQL][3.1] ResolveReference.dedupRight should copy dataset_id tag to avoid ambiguous self join ### What changes were proposed in this pull request? This PR backports the change of SPARK-36874 (#34172) mainly, and SPARK-34634 (#31752) partially to care about the ambiguous self join for `ScriptTransformation`. This PR fixes an issue that ambiguous self join can't be detected if the left and right DataFrame are swapped. This is an example. ``` val df1 = Seq((1, 2, "A1"),(2, 1, "A2")).toDF("key1", "key2", "value") val df2 = df1.filter($"value" === "A2") df1.join(df2, df1("key1") === df2("key2")) // Ambiguous self join is detected and AnalysisException is thrown. df2.join(df1, df1("key1") === df2("key2)) // Ambiguous self join is not detected. ``` The root cause seems that an inner function `collectConflictPlans` in `ResolveReference.dedupRight.` doesn't copy the `dataset_id` tag when it copies a `LogicalPlan`. ### Why are the changes needed? Bug fix. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? New tests. Closes #34205 from sarutak/backport-SPARK-36874. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 07 October 2021, 06:56:52 UTC |
| 90d1932 | tianhanhu | 06 October 2021, 10:06:09 UTC | [SPARK-36919][SQL] Make BadRecordException fields transient ### What changes were proposed in this pull request? Migrating a Spark application from 2.4.x to 3.1.x and finding a difference in the exception chaining behavior. In a case of parsing a malformed CSV, where the root cause exception should be Caused by: java.lang.RuntimeException: Malformed CSV record, only the top level exception is kept, and all lower level exceptions and root cause are lost. Thus, when we call ExceptionUtils.getRootCause on the exception, we still get itself. The reason for the difference is that RuntimeException is wrapped in BadRecordException, which has unserializable fields. When we try to serialize the exception from tasks and deserialize from scheduler, the exception is lost. This PR makes unserializable fields of BadRecordException transient, so the rest of the exception could be serialized and deserialized properly. ### Why are the changes needed? Make BadRecordException serializable ### Does this PR introduce _any_ user-facing change? User could get root cause of BadRecordException ### How was this patch tested? Unit testing Closes #34167 from tianhanhu/master. Authored-by: tianhanhu <adrianhu96@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit aed977c4682b6f378a26050ffab51b9b2075cae4) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 06 October 2021, 10:06:35 UTC |
| e1fc62d | Angerszhuuuu | 24 September 2021, 08:19:36 UTC | [SPARK-36792][SQL] InSet should handle NaN ### What changes were proposed in this pull request? InSet should handle NaN ``` InSet(Literal(Double.NaN), Set(Double.NaN, 1d)) should return true, but return false. ``` ### Why are the changes needed? InSet should handle NaN ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added UT Closes #34033 from AngersZhuuuu/SPARK-36792. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 64f4bf47af2412811ff2843cd363ce883a604ce7) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 24 September 2021, 08:20:05 UTC |
| 1b54580 | Hyukjin Kwon | 24 September 2021, 03:50:07 UTC | Revert "[SPARK-35672][CORE][YARN][3.1] Pass user classpath entries to executors using config instead of command line" This reverts commit b4916d4a410820ba00125c00b55ca724b27cc853. | 24 September 2021, 03:50:07 UTC |
| 8e36217 | yi.wu | 23 September 2021, 08:29:54 UTC | [SPARK-36782][CORE][FOLLOW-UP] Only handle shuffle block in separate thread pool ### What changes were proposed in this pull request? This's a follow-up of https://github.com/apache/spark/pull/34043. This PR proposes to only handle shuffle blocks in the separate thread pool and leave other blocks the same behavior as it is. ### Why are the changes needed? To avoid any potential overhead. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass existing tests. Closes #34076 from Ngone51/spark-36782-follow-up. Authored-by: yi.wu <yi.wu@databricks.com> Signed-off-by: Gengliang Wang <gengliang@apache.org> (cherry picked from commit 9d8ac7c8e90c1c2a6060e8f1e8f2f21e19622567) Signed-off-by: Gengliang Wang <gengliang@apache.org> | 23 September 2021, 08:51:47 UTC |
| 1b48a48 | Fabian A.J. Thiele | 23 September 2021, 04:56:49 UTC | [SPARK-36782][CORE] Avoid blocking dispatcher-BlockManagerMaster during UpdateBlockInfo ### What changes were proposed in this pull request? Delegate potentially blocking call to `mapOutputTracker.updateMapOutput` from within `UpdateBlockInfo` from `dispatcher-BlockManagerMaster` to the threadpool to avoid blocking the endpoint. This code path is only accessed for `ShuffleIndexBlockId`, other blocks are still executed on the `dispatcher-BlockManagerMaster` itself. Change `updateBlockInfo` to return `Future[Boolean]` instead of `Boolean`. Response will be sent to RPC caller upon successful completion of the future. Introduce a unit test that forces `MapOutputTracker` to make a broadcast as part of `MapOutputTracker.serializeOutputStatuses` when running decommission tests. ### Why are the changes needed? [SPARK-36782](https://issues.apache.org/jira/browse/SPARK-36782) describes a deadlock occurring if the `dispatcher-BlockManagerMaster` is allowed to block while waiting for write access to data structures. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test as introduced in this PR. --- Ping eejbyfeldt for notice. Closes #34043 from f-thiele/SPARK-36782. Lead-authored-by: Fabian A.J. Thiele <fabian.thiele@posteo.de> Co-authored-by: Emil Ejbyfeldt <eejbyfeldt@liveintent.com> Co-authored-by: Fabian A.J. Thiele <fthiele@liveintent.com> Signed-off-by: Gengliang Wang <gengliang@apache.org> | 23 September 2021, 08:43:39 UTC |
| b5cb3b6 | Hyukjin Kwon | 23 September 2021, 06:00:15 UTC | [MINOR][SQL][DOCS] Correct the 'options' description on UnresolvedRelation ### What changes were proposed in this pull request? This PR fixes the 'options' description on `UnresolvedRelation`. This comment was added in https://github.com/apache/spark/pull/29535 but not valid anymore because V1 also uses this `options` (and merge the options with the table properties) per https://github.com/apache/spark/pull/29712. This PR can go through from `master` to `branch-3.1`. ### Why are the changes needed? To make `UnresolvedRelation.options`'s description clearer. ### Does this PR introduce _any_ user-facing change? No, dev-only. ### How was this patch tested? Scala linter by `dev/linter-scala`. Closes #34075 from HyukjinKwon/minor-comment-unresolved-releation. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Huaxin Gao <huaxin_gao@apple.com> (cherry picked from commit 0076eba8d066936c32790ebc4058c52e2d21a207) Signed-off-by: Huaxin Gao <huaxin_gao@apple.com> | 23 September 2021, 06:01:06 UTC |
| 504d518 | jiaoqb | 23 September 2021, 03:47:38 UTC | [SPARK-36791][DOCS] Fix spelling mistakes in running-on-yarn.md file where JHS_POST should be JHS_HOST ### What changes were proposed in this pull request? The PR fixes SPARK-36791 by replacing JHS_POST with JHS_HOST ### Why are the changes needed? There are spelling mistakes in running-on-yarn.md file where JHS_POST should be JHS_HOST ### Does this PR introduce any user-facing change? No ### How was this patch tested? Not needed for docs Closes #34031 from jiaoqingbo/jiaoqingbo. Authored-by: jiaoqb <jiaoqb@asiainfo.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 8a1a91bd71218ef0eee9c4eac175134b62ba362a) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 23 September 2021, 03:48:28 UTC |