https://github.com/apache/spark
- HEAD
- refs/heads/branch-0.5
- refs/heads/branch-0.6
- refs/heads/branch-0.7
- refs/heads/branch-0.8
- refs/heads/branch-0.9
- refs/heads/branch-1.0
- refs/heads/branch-1.0-jdbc
- refs/heads/branch-1.1
- refs/heads/branch-1.2
- refs/heads/branch-1.3
- refs/heads/branch-1.4
- refs/heads/branch-1.5
- refs/heads/branch-1.6
- refs/heads/branch-2.0
- refs/heads/branch-2.1
- refs/heads/branch-2.2
- refs/heads/branch-2.3
- refs/heads/branch-2.4
- refs/heads/branch-3.0
- refs/heads/branch-3.1
- refs/heads/branch-3.2
- refs/heads/branch-3.3
- refs/heads/branch-3.4
- refs/heads/branch-3.5
- refs/heads/master
- refs/remotes/origin/branch-0.8
- refs/remotes/origin/td-rdd-save
- refs/tags/0.3-scala-2.8
- refs/tags/0.3-scala-2.9
- refs/tags/2.0.0-preview
- refs/tags/alpha-0.1
- refs/tags/alpha-0.2
- refs/tags/v0.5.0
- refs/tags/v0.5.1
- refs/tags/v0.5.2
- refs/tags/v0.6.0
- refs/tags/v0.6.0-yarn
- refs/tags/v0.6.1
- refs/tags/v0.6.2
- refs/tags/v0.7.0
- refs/tags/v0.7.0-bizo-1
- refs/tags/v0.7.1
- refs/tags/v0.7.2
- refs/tags/v0.9.1
- refs/tags/v0.9.2
- refs/tags/v1.0.0
- refs/tags/v1.0.1
- refs/tags/v1.0.2
- refs/tags/v1.1.0
- refs/tags/v1.1.1
- refs/tags/v1.2.0
- refs/tags/v1.2.1
- refs/tags/v1.2.2
- refs/tags/v1.3.0
- refs/tags/v1.3.1
- refs/tags/v1.4.0
- refs/tags/v1.4.1
- refs/tags/v1.5.0-rc1
- refs/tags/v1.5.0-rc2
- refs/tags/v1.5.0-rc3
- refs/tags/v1.5.1
- refs/tags/v1.6.0
- refs/tags/v1.6.1
- refs/tags/v1.6.2
- refs/tags/v1.6.3
- refs/tags/v2.0.0
- refs/tags/v2.0.1
- refs/tags/v2.0.2
- refs/tags/v2.1.0
- refs/tags/v2.1.1
- refs/tags/v2.1.2
- refs/tags/v2.1.2-rc1
- refs/tags/v2.1.2-rc2
- refs/tags/v2.1.2-rc3
- refs/tags/v2.1.2-rc4
- refs/tags/v2.1.3
- refs/tags/v2.1.3-rc1
- refs/tags/v2.1.3-rc2
- refs/tags/v2.2.0
- refs/tags/v2.2.1
- refs/tags/v2.2.1-rc1
- refs/tags/v2.2.1-rc2
- refs/tags/v2.2.2
- refs/tags/v2.2.2-rc1
- refs/tags/v2.2.2-rc2
- refs/tags/v2.2.3
- refs/tags/v2.2.3-rc1
- refs/tags/v2.3.0
- refs/tags/v2.3.0-rc1
- refs/tags/v2.3.0-rc2
- refs/tags/v2.3.0-rc3
- refs/tags/v2.3.0-rc4
- refs/tags/v2.3.1
- refs/tags/v2.3.1-rc1
- refs/tags/v2.3.1-rc2
- refs/tags/v2.3.1-rc3
- refs/tags/v2.3.1-rc4
- refs/tags/v2.3.2
- refs/tags/v2.3.2-rc1
- refs/tags/v2.3.2-rc2
- refs/tags/v2.3.2-rc3
- refs/tags/v2.3.2-rc4
- refs/tags/v2.3.2-rc5
- refs/tags/v2.3.2-rc6
- refs/tags/v2.3.3
- refs/tags/v2.3.3-rc1
- refs/tags/v2.3.3-rc2
- refs/tags/v2.3.4
- refs/tags/v2.3.4-rc1
- refs/tags/v2.4.0
- refs/tags/v2.4.0-rc1
- refs/tags/v2.4.0-rc2
- refs/tags/v2.4.0-rc3
- refs/tags/v2.4.0-rc4
- refs/tags/v2.4.0-rc5
- refs/tags/v2.4.1
- refs/tags/v2.4.1-rc1
- refs/tags/v2.4.1-rc2
- refs/tags/v2.4.1-rc3
- refs/tags/v2.4.1-rc4
- refs/tags/v2.4.1-rc5
- refs/tags/v2.4.1-rc6
- refs/tags/v2.4.1-rc7
- refs/tags/v2.4.1-rc8
- refs/tags/v2.4.1-rc9
- refs/tags/v2.4.2
- refs/tags/v2.4.2-rc1
- refs/tags/v2.4.3
- refs/tags/v2.4.3-rc1
- refs/tags/v2.4.4
- refs/tags/v2.4.4-rc1
- refs/tags/v2.4.4-rc2
- refs/tags/v2.4.4-rc3
- refs/tags/v2.4.5
- refs/tags/v2.4.5-rc1
- refs/tags/v2.4.5-rc2
- refs/tags/v2.4.6
- refs/tags/v2.4.6-rc1
- refs/tags/v2.4.6-rc2
- refs/tags/v2.4.6-rc3
- refs/tags/v2.4.6-rc4
- refs/tags/v2.4.6-rc5
- refs/tags/v2.4.6-rc6
- refs/tags/v2.4.6-rc7
- refs/tags/v2.4.6-rc8
- refs/tags/v2.4.7
- refs/tags/v2.4.7-rc1
- refs/tags/v2.4.7-rc2
- refs/tags/v2.4.7-rc3
- refs/tags/v2.4.8
- refs/tags/v2.4.8-rc1
- refs/tags/v2.4.8-rc2
- refs/tags/v2.4.8-rc3
- refs/tags/v2.4.8-rc4
- refs/tags/v3.0.0
- refs/tags/v3.0.0-preview2
- refs/tags/v3.0.0-preview2-rc1
- refs/tags/v3.0.0-preview2-rc2
- refs/tags/v3.0.0-rc1
- refs/tags/v3.0.0-rc2
- refs/tags/v3.0.0-rc3
- refs/tags/v3.0.1
- refs/tags/v3.0.1-rc1
- refs/tags/v3.0.1-rc2
- refs/tags/v3.0.1-rc3
- refs/tags/v3.0.2
- refs/tags/v3.0.2-rc1
- refs/tags/v3.0.3
- refs/tags/v3.0.3-rc1
- refs/tags/v3.1.0-rc1
- refs/tags/v3.1.1
- refs/tags/v3.1.1-rc1
- refs/tags/v3.1.1-rc2
- refs/tags/v3.1.1-rc3
- refs/tags/v3.1.2
- refs/tags/v3.1.2-rc1
- refs/tags/v3.1.3
- refs/tags/v3.1.3-rc1
- refs/tags/v3.1.3-rc2
- refs/tags/v3.1.3-rc3
- refs/tags/v3.1.3-rc4
- refs/tags/v3.2.0
- refs/tags/v3.2.0-rc1
- refs/tags/v3.2.0-rc2
- refs/tags/v3.2.0-rc3
- refs/tags/v3.2.0-rc4
- refs/tags/v3.2.0-rc5
- refs/tags/v3.2.0-rc6
- refs/tags/v3.2.0-rc7
- refs/tags/v3.2.1
- refs/tags/v3.2.1-rc1
- refs/tags/v3.2.1-rc2
- refs/tags/v3.2.2
- refs/tags/v3.2.2-rc1
- refs/tags/v3.2.3
- refs/tags/v3.2.3-rc1
- refs/tags/v3.2.4
- refs/tags/v3.2.4-rc1
- refs/tags/v3.3.0
- refs/tags/v3.3.0-rc1
- refs/tags/v3.3.0-rc2
- refs/tags/v3.3.0-rc3
- refs/tags/v3.3.0-rc4
- refs/tags/v3.3.0-rc5
- refs/tags/v3.3.0-rc6
- refs/tags/v3.3.1
- refs/tags/v3.3.1-rc1
- refs/tags/v3.3.1-rc2
- refs/tags/v3.3.1-rc3
- refs/tags/v3.3.1-rc4
- refs/tags/v3.3.2
- refs/tags/v3.3.2-rc1
- refs/tags/v3.3.3
- refs/tags/v3.3.3-rc1
- refs/tags/v3.3.4
- refs/tags/v3.3.4-rc1
- refs/tags/v3.4.0
- refs/tags/v3.4.0-rc1
- refs/tags/v3.4.0-rc2
- refs/tags/v3.4.0-rc3
- refs/tags/v3.4.0-rc4
- refs/tags/v3.4.0-rc5
- refs/tags/v3.4.0-rc6
- refs/tags/v3.4.0-rc7
- refs/tags/v3.4.1
- refs/tags/v3.4.1-rc1
- refs/tags/v3.4.2
- refs/tags/v3.4.2-rc1
- refs/tags/v3.5.0
- refs/tags/v3.5.0-rc1
- refs/tags/v3.5.0-rc2
- refs/tags/v3.5.0-rc3
- refs/tags/v3.5.0-rc4
- refs/tags/v3.5.0-rc5
- refs/tags/v3.5.1
- refs/tags/v3.5.1-rc1
- refs/tags/v3.5.1-rc2
Take a new snapshot of a software origin
If the archived software origin currently browsed is not synchronized with its upstream version (for instance when new commits have been issued), you can explicitly request Software Heritage to take a new snapshot of it.
Use the form below to proceed. Once a request has been submitted and accepted, it will be processed as soon as possible. You can then check its processing state by visiting this dedicated page.
Processing "take a new snapshot" request ...
Permalinks
To reference or cite the objects present in the Software Heritage archive, permalinks based on SoftWare Hash IDentifiers (SWHIDs) must be used.
Select below a type of object currently browsed in order to display its associated SWHID and permalink.
| Revision | Author | Date | Message | Commit Date |
|---|---|---|---|---|
| 4a418a4 | Hyukjin Kwon | 19 September 2023, 05:51:27 UTC | [SPARK-45210][DOCS][3.4] Switch languages consistently across docs for all code snippets (Spark 3.4 and below) ### What changes were proposed in this pull request? This PR proposes to recover the availity of switching languages consistently across docs for all code snippets in Spark 3.4 and below by using the proper class selector in the JQuery. Previously the selector was a string `.nav-link tab_python` which did not comply multiple class selection: https://www.w3.org/TR/CSS21/selector.html#class-html. I assume it worked as a legacy behaviour somewhere. Now it uses the standard way `.nav-link.tab_python`. Note that https://github.com/apache/spark/pull/42657 works because there's only single class assigned (after we refactored the site at https://github.com/apache/spark/pull/40269) ### Why are the changes needed? This is a regression in our documentation site. ### Does this PR introduce _any_ user-facing change? Yes, once you click the language tab, it will apply to the examples in the whole page. ### How was this patch tested? Manually tested after building the site.  ### Was this patch authored or co-authored using generative AI tooling? No. Closes #42989 from HyukjinKwon/SPARK-45210. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 796d8785c61e09d1098350657fd44707763687db) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 19 September 2023, 05:52:29 UTC |
| 61e0348 | Josh Rosen | 16 December 2022, 10:16:25 UTC | [SPARK-41541][SQL] Fix call to wrong child method in SQLShuffleWriteMetricsReporter.decRecordsWritten() ### What changes were proposed in this pull request? This PR fixes a bug in `SQLShuffleWriteMetricsReporter.decRecordsWritten()`: this method is supposed to call the delegate `metricsReporter`'s `decRecordsWritten` method but due to a typo it calls the `decBytesWritten` method instead. ### Why are the changes needed? One of the situations where `decRecordsWritten(v)` is called while reverting shuffle writes from failed/canceled tasks. Due to the mixup in these calls, the _recordsWritten_ metric ends up being _v_ records too high (since it wasn't decremented) and the _bytesWritten_ metric ends up _v_ records too low, causing some failed tasks' write metrics to look like > {"Shuffle Bytes Written":-2109,"Shuffle Write Time":2923270,"Shuffle Records Written":2109} instead of > {"Shuffle Bytes Written":0,"Shuffle Write Time":2923270,"Shuffle Records Written":0} ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests / manual code review only. The existing SQLMetricsSuite contains end-to-end tests which exercise this class but they don't exercise the decrement path because they don't exercise the shuffle write failure paths. In theory I could add new unit tests but I don't think the ROI is worth it given that this class is intended to be a simple wrapper and it ~never changes (this PR is the first change to the file in 5 years). Closes #39086 from JoshRosen/SPARK-41541. Authored-by: Josh Rosen <joshrosen@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit ed27121607cf526e69420a1faff01383759c9134) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 16 December 2022, 10:17:06 UTC |
| 7c3887c | Peter Toth | 22 October 2022, 01:39:32 UTC | [SPARK-40874][PYTHON] Fix broadcasts in Python UDFs when encryption enabled This PR fixes a bug in broadcast handling `PythonRunner` when encryption is enabed. Due to this bug the following pyspark script: ``` bin/pyspark --conf spark.io.encryption.enabled=true ... bar = {"a": "aa", "b": "bb"} foo = spark.sparkContext.broadcast(bar) spark.udf.register("MYUDF", lambda x: foo.value[x] if x else "") spark.sql("SELECT MYUDF('a') AS a, MYUDF('b') AS b").collect() ``` fails with: ``` 22/10/21 17:14:32 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)/ 1] org.apache.spark.api.python.PythonException: Traceback (most recent call last): File "/Users/petertoth/git/apache/spark/python/lib/pyspark.zip/pyspark/worker.py", line 811, in main func, profiler, deserializer, serializer = read_command(pickleSer, infile) File "/Users/petertoth/git/apache/spark/python/lib/pyspark.zip/pyspark/worker.py", line 87, in read_command command = serializer._read_with_length(file) File "/Users/petertoth/git/apache/spark/python/lib/pyspark.zip/pyspark/serializers.py", line 173, in _read_with_length return self.loads(obj) File "/Users/petertoth/git/apache/spark/python/lib/pyspark.zip/pyspark/serializers.py", line 471, in loads return cloudpickle.loads(obj, encoding=encoding) EOFError: Ran out of input ``` The reason for this failure is that we have multiple Python UDF referencing the same broadcast and in the current code: https://github.com/apache/spark/blob/748fa2792e488a6b923b32e2898d9bb6e16fb4ca/core/src/main/scala/org/apache/spark/api/python/PythonRunner.scala#L385-L420 the number of broadcasts (`cnt`) is correct (1) but the broadcast id is serialized 2 times from JVM to Python ruining the next item that Python expects from JVM side. Please note that the example above works in Spark 3.3 without this fix. That is because https://github.com/apache/spark/pull/36121 in Spark 3.4 modified `ExpressionSet` and so `udfs` in `ExtractPythonUDFs`: https://github.com/apache/spark/blob/748fa2792e488a6b923b32e2898d9bb6e16fb4ca/sql/core/src/main/scala/org/apache/spark/sql/execution/python/ExtractPythonUDFs.scala#L239-L242 changed from `Stream` to `Vector`. When `broadcastVars` (and so `idsAndFiles`) is a `Stream` the example accidentaly works as the broadcast id is written to `dataOut` once (`oldBids.add(id)` in `idsAndFiles.foreach` is called before the 2nd item is calculated in `broadcastVars.flatMap`). But that doesn't mean that https://github.com/apache/spark/pull/36121 introduced the regression as `EncryptedPythonBroadcastServer` shouldn't serve the broadcast data 2 times (which `EncryptedPythonBroadcastServer` does now, but it is not noticed) as it could fail other cases when there are more than 1 broadcast used in UDFs). To fix a bug. No. Added new UT. Closes #38334 from peter-toth/SPARK-40874-fix-broadcasts-in-python-udf. Authored-by: Peter Toth <peter.toth@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 8a96f69bb536729eaa59fae55160f8a6747efbe3) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 24 October 2022, 01:29:51 UTC |
| bc9e434 | Hyukjin Kwon | 16 September 2022, 01:08:59 UTC | [SPARK-40461][INFRA] Set upperbound for pyzmq 24.0.0 for Python linter This PR sets the upperbound for `pyzmq` as `<24.0.0` in our CI Python linter job. The new release seems having a problem (https://github.com/zeromq/pyzmq/commit/2d3327d2e50c2510d45db2fc51488578a737b79b). To fix the linter build failure. See https://github.com/apache/spark/actions/runs/3063515551/jobs/4947782771 ``` /tmp/timer_created_0ftep6.c: In function ‘main’: /tmp/timer_created_0ftep6.c:2:5: warning: implicit declaration of function ‘timer_create’ [-Wimplicit-function-declaration] 2 | timer_create(); | ^~~~~~~~~~~~ x86_64-linux-gnu-gcc -pthread tmp/timer_created_0ftep6.o -L/usr/lib/x86_64-linux-gnu -o a.out /usr/bin/ld: tmp/timer_created_0ftep6.o: in function `main': /tmp/timer_created_0ftep6.c:2: undefined reference to `timer_create' collect2: error: ld returned 1 exit status no timer_create, linking librt ************************************************ building 'zmq.libzmq' extension creating build/temp.linux-x86_64-cpython-39/buildutils creating build/temp.linux-x86_64-cpython-39/bundled creating build/temp.linux-x86_64-cpython-39/bundled/zeromq creating build/temp.linux-x86_64-cpython-39/bundled/zeromq/src x86_64-linux-gnu-g++ -pthread -std=c++11 -pthread -Wno-unused-result -Wsign-compare -DNDEBUG -g -fwrapv -O2 -Wall -g -fstack-protector-strong -Wformat -Werror=format-security -g -fwrapv -O2 -fPIC -DZMQ_HAVE_CURVE=1 -DZMQ_USE_TWEETNACL=1 -DZMQ_USE_EPOLL=1 -DZMQ_IOTHREADS_USE_EPOLL=1 -DZMQ_POLL_BASED_ON_POLL=1 -Ibundled/zeromq/include -Ibundled -I/usr/include/python3.9 -c buildutils/initlibzmq.cpp -o build/temp.linux-x86_64-cpython-39/buildutils/initlibzmq.o buildutils/initlibzmq.cpp:10:10: fatal error: Python.h: No such file or directory 10 | #include "Python.h" | ^~~~~~~~~~ compilation terminated. error: command '/usr/bin/x86_64-linux-gnu-g++' failed with exit code 1 [end of output] note: This error originates from a subprocess, and is likely not a problem with pip. ERROR: Failed building wheel for pyzmq ERROR: Could not build wheels for pyzmq, which is required to install pyproject.toml-based projects ``` No, test-only. CI in this PRs should validate it. Closes #37904 from HyukjinKwon/fix-linter. Lead-authored-by: Hyukjin Kwon <gurwls223@apache.org> Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 254bd80278843b3bc13584ca2f04391a770a78c7) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 16 September 2022, 01:14:05 UTC |
| 63025e9 | Carmen Kwan | 06 September 2022, 13:11:24 UTC | [SPARK-40315][SQL] Add hashCode() for Literal of ArrayBasedMapData ### What changes were proposed in this pull request? There is no explicit `hashCode()` function override for `ArrayBasedMapData`. As a result, there is a non-deterministic error where the `hashCode()` computed for `Literal`s of `ArrayBasedMapData` can be different for two equal objects (`Literal`s of `ArrayBasedMapData` with equal keys and values). In this PR, we add a `hashCode` function so that it works exactly as we expect. ### Why are the changes needed? This is a bug fix for a non-deterministic error. It is also more consistent with the rest of Spark if we implement the `hashCode` method instead of relying on defaults. We can't add the `hashCode` directly to `ArrayBasedMapData` because of SPARK-9415. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? A simple unit test was added. Closes #37807 from c27kwan/SPARK-40315-lit. Authored-by: Carmen Kwan <carmen.kwan@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit e85a4ffbdfa063c8da91b23dfbde77e2f9ed62e9) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 06 September 2022, 13:15:27 UTC |
| 6b021fe | Bruce Robbins | 29 August 2022, 01:45:21 UTC | [SPARK-39184][SQL][3.1] Handle undersized result array in date and timestamp sequences Backport of #37513 and its follow-up #37542. ### What changes were proposed in this pull request? Add code to defensively check if the pre-allocated result array is big enough to handle the next element in a date or timestamp sequence. ### Why are the changes needed? `InternalSequenceBase.getSequenceLength` is a fast method for estimating the size of the result array. It uses an estimated step size in micros which is not always entirely accurate for the date/time/time-zone combination. As a result, `getSequenceLength` occasionally overestimates the size of the result array and also occasionally underestimates the size of the result array. `getSequenceLength` sometimes overestimates the size of the result array when the step size is in months (because `InternalSequenceBase` assumes 28 days per month). This case is handled: `InternalSequenceBase` will slice the array, if needed. `getSequenceLength` sometimes underestimates the size of the result array when the sequence crosses a DST "spring forward" without a corresponding "fall backward". This case is not handled (thus, this PR). For example: ``` select sequence( timestamp'2022-03-13 00:00:00', timestamp'2022-03-14 00:00:00', interval 1 day) as x; ``` In the America/Los_Angeles time zone, this results in the following error: ``` java.lang.ArrayIndexOutOfBoundsException: 1 at scala.runtime.ScalaRunTime$.array_update(ScalaRunTime.scala:77) ``` This happens because `InternalSequenceBase` calculates an estimated step size of 24 hours. If you add 24 hours to 2022-03-13 00:00:00 in the America/Los_Angeles time zone, you get 2022-03-14 01:00:00 (because 2022-03-13 has only 23 hours due to "spring forward"). Since 2022-03-14 01:00:00 is later than the specified stop value, `getSequenceLength` assumes the stop value is not included in the result. Therefore, `getSequenceLength` estimates an array size of 1. However, when actually creating the sequence, `InternalSequenceBase` does not use a step of 24 hours, but of 1 day. When you add 1 day to 2022-03-13 00:00:00, you get 2022-03-14 00:00:00. Now the stop value *is* included, and we overrun the end of the result array. The new unit test includes examples of problematic date sequences. This PR adds code to to handle the underestimation case: it checks if we're about to overrun the array, and if so, gets a new array that's larger by 1. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? New unit test. Closes #37699 from bersprockets/date_sequence_array_size_issue_31. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 29 August 2022, 01:45:21 UTC |
| ca8cdb2 | Ruifeng Zheng | 27 August 2022, 10:39:17 UTC | [SPARK-40241][DOCS] Correct the link of GenericUDTF ### What changes were proposed in this pull request? Correct the link ### Why are the changes needed? existing link was wrong ### Does this PR introduce _any_ user-facing change? yes, a link was updated ### How was this patch tested? Manually check Closes #37685 from zhengruifeng/doc_fix_udtf. Authored-by: Ruifeng Zheng <ruifengz@apache.org> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit 8ffcecb68fafd0466e839281588aab50cd046b49) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 27 August 2022, 10:41:33 UTC |
| 65936ef | Robert (Bobby) Evans | 22 August 2022, 08:33:37 UTC | [SPARK-40089][SQL] Fix sorting for some Decimal types ### What changes were proposed in this pull request? This fixes https://issues.apache.org/jira/browse/SPARK-40089 where the prefix can overflow in some cases and the code assumes that the overflow is always on the negative side, not the positive side. ### Why are the changes needed? This adds a check when the overflow does happen to know what is the proper prefix to return. ### Does this PR introduce _any_ user-facing change? No, unless you consider getting the sort order correct a user facing change. ### How was this patch tested? I tested manually with the file in the JIRA and I added a small unit test. Closes #37540 from revans2/fix_dec_sort. Authored-by: Robert (Bobby) Evans <bobby@apache.org> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 8dfd3dfc115d6e249f00a9a434b866d28e2eae45) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 22 August 2022, 08:35:57 UTC |
| a1a2534 | Weichen Xu | 19 August 2022, 04:26:34 UTC | [SPARK-35542][ML] Fix: Bucketizer created for multiple columns with parameters splitsArray, inputCols and outputCols can not be loaded after saving it Signed-off-by: Weichen Xu <weichen.xudatabricks.com> ### What changes were proposed in this pull request? Fix: Bucketizer created for multiple columns with parameters splitsArray, inputCols and outputCols can not be loaded after saving it ### Why are the changes needed? Bugfix. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test Closes #37568 from WeichenXu123/SPARK-35542. Authored-by: Weichen Xu <weichen.xu@databricks.com> Signed-off-by: Weichen Xu <weichen.xu@databricks.com> (cherry picked from commit 876ce6a5df118095de51c3c4789d6db6da95eb23) Signed-off-by: Weichen Xu <weichen.xu@databricks.com> | 19 August 2022, 04:28:04 UTC |
| a6f5293 | Bruce Robbins | 18 August 2022, 20:04:14 UTC | [SPARK-37544][SQL][3.1] Correct date arithmetic in sequences Backport of #36546 ### What changes were proposed in this pull request? Change `TemporalSequenceImpl` to pass a time-zone aware value to `DateTimeUtils#timestampAddInterval`, rather than a time-zone agnostic value, when performing `Date` arithmetic. ### Why are the changes needed? The following query gets the wrong answer if run in the America/Los_Angeles time zone: ``` spark-sql> select sequence(date '2021-01-01', date '2022-01-01', interval '3' month) x; [2021-01-01,2021-03-31,2021-06-30,2021-09-30,2022-01-01] Time taken: 0.664 seconds, Fetched 1 row(s) spark-sql> ``` The answer should be ``` [2021-01-01,2021-04-01,2021-07-01,2021-10-01,2022-01-01] ``` `TemporalSequenceImpl` converts the date to micros by multiplying days by micros per day. This converts the date into a time-zone agnostic timestamp. However, `TemporalSequenceImpl` uses `DateTimeUtils#timestampAddInterval` to perform the arithmetic, and that function assumes a _time-zone aware_ timestamp. This PR converts the date to a time-zone aware value before calling `DateTimeUtils#timestampAddInterval`. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? New unit test. Closes #37559 from bersprockets/date_sequence_issue_31. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 18 August 2022, 20:04:14 UTC |
| 07cc6a8 | Hyukjin Kwon | 18 August 2022, 03:23:02 UTC | [SPARK-40121][PYTHON][SQL] Initialize projection used for Python UDF This PR proposes to initialize the projection so non-deterministic expressions can be evaluated with Python UDFs. To make the Python UDF working with non-deterministic expressions. Yes. ```python from pyspark.sql.functions import udf, rand spark.range(10).select(udf(lambda x: x, "double")(rand())).show() ``` **Before** ``` java.lang.NullPointerException at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificMutableProjection.apply(Unknown Source) at org.apache.spark.sql.execution.python.EvalPythonExec.$anonfun$doExecute$10(EvalPythonExec.scala:126) at scala.collection.Iterator$$anon$10.next(Iterator.scala:461) at scala.collection.Iterator$$anon$10.next(Iterator.scala:461) at scala.collection.Iterator$GroupedIterator.takeDestructively(Iterator.scala:1161) at scala.collection.Iterator$GroupedIterator.go(Iterator.scala:1176) at scala.collection.Iterator$GroupedIterator.fill(Iterator.scala:1213) ``` **After** ``` +----------------------------------+ |<lambda>rand(-2507211707257730645)| +----------------------------------+ | 0.7691724424045242| | 0.09602244075319044| | 0.3006471278112862| | 0.4182649571961977| | 0.29349096650900974| | 0.7987097908937618| | 0.5324802583101007| | 0.72460930912789| | 0.1367749768412846| | 0.17277322931919348| +----------------------------------+ ``` Manually tested, and unittest was added. Closes #37552 from HyukjinKwon/SPARK-40121. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 336c9bc535895530cc3983b24e7507229fa9570d) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 18 August 2022, 03:25:26 UTC |
| 1bb9e33 | Wenli Looi | 17 August 2022, 06:28:55 UTC | [SPARK-40117][PYTHON][SQL] Convert condition to java in DataFrameWriterV2.overwrite ### What changes were proposed in this pull request? Fix DataFrameWriterV2.overwrite() fails to convert the condition parameter to java. This prevents the function from being called. It is caused by the following commit that deleted the `_to_java_column` call instead of fixing it: https://github.com/apache/spark/commit/a1e459ed9f6777fb8d5a2d09fda666402f9230b9 ### Why are the changes needed? DataFrameWriterV2.overwrite() cannot be called. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Manually checked whether the arguments are sent to JVM or not. Closes #37547 from looi/fix-overwrite. Authored-by: Wenli Looi <wlooi@ucalgary.ca> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 46379863ab0dd2ee8fcf1e31e76476ff18397f60) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 17 August 2022, 06:29:59 UTC |
| de68152 | Peter Toth | 15 August 2022, 13:45:01 UTC | [SPARK-39887][SQL][3.1] RemoveRedundantAliases should keep aliases that make the output of projection nodes unique ### What changes were proposed in this pull request? Keep the output attributes of a `Union` node's first child in the `RemoveRedundantAliases` rule to avoid correctness issues. ### Why are the changes needed? To fix the result of the following query: ``` SELECT a, b AS a FROM ( SELECT a, a AS b FROM (SELECT a FROM VALUES (1) AS t(a)) UNION ALL SELECT a, b FROM (SELECT a, b FROM VALUES (1, 2) AS t(a, b)) ) ``` Before this PR the query returns the incorrect result: ``` +---+---+ | a| a| +---+---+ | 1| 1| | 2| 2| +---+---+ ``` After this PR it returns the expected result: ``` +---+---+ | a| a| +---+---+ | 1| 1| | 1| 2| +---+---+ ``` ### Does this PR introduce _any_ user-facing change? Yes, fixes a correctness issue. ### How was this patch tested? Added new UTs. Closes #37496 from peter-toth/SPARK-39887-keep-attributes-of-unions-first-child-3.1. Authored-by: Peter Toth <ptoth@cloudera.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 15 August 2022, 13:45:01 UTC |
| f2453e8 | Weichen Xu | 15 August 2022, 10:03:08 UTC | [SPARK-40079] Add Imputer inputCols validation for empty input case Signed-off-by: Weichen Xu <weichen.xudatabricks.com> ### What changes were proposed in this pull request? Add Imputer inputCols validation for empty input case ### Why are the changes needed? If Imputer inputCols is empty, the `fit` works fine but when saving model, error will be raised: > AnalysisException: Datasource does not support writing empty or nested empty schemas. Please make sure the data schema has at least one or more column(s). ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Unit test. Closes #37518 from WeichenXu123/imputer-param-validation. Authored-by: Weichen Xu <weichen.xu@databricks.com> Signed-off-by: Weichen Xu <weichen.xu@databricks.com> (cherry picked from commit 87094f89655b7df09cdecb47c653461ae855b0ac) Signed-off-by: Weichen Xu <weichen.xu@databricks.com> | 15 August 2022, 10:08:51 UTC |
| 6242776 | Hyukjin Kwon | 11 August 2022, 06:01:05 UTC | [SPARK-40043][PYTHON][SS][DOCS] Document DataStreamWriter.toTable and DataStreamReader.table ### What changes were proposed in this pull request? This PR is a followup of https://github.com/apache/spark/pull/30835 that adds `DataStreamWriter.toTable` and `DataStreamReader.table` into PySpark documentation. ### Why are the changes needed? To document both features. ### Does this PR introduce _any_ user-facing change? Yes, both API will be shown in PySpark reference documentation. ### How was this patch tested? Manually built the documentation and checked. Closes #37477 from HyukjinKwon/SPARK-40043. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 447003324d2cf9f2bfa799ef3a1e744a5bc9277d) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 11 August 2022, 06:01:52 UTC |
| e246300 | yangjie01 | 10 August 2022, 00:59:35 UTC | [SPARK-40022][YARN][TESTS] Ignore pyspark suites in `YarnClusterSuite` when python3 is unavailable ### What changes were proposed in this pull request? This pr adds `assume(isPythonAvailable)` to `testPySpark` method in `YarnClusterSuite` to make `YarnClusterSuite` test succeeded in an environment without Python 3 configured. ### Why are the changes needed? `YarnClusterSuite` should not `ABORTED` when `python3` is not configured. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? - Pass GitHub Actions - Manual test Run ``` mvn clean test -pl resource-managers/yarn -am -Pyarn -DwildcardSuites=org.apache.spark.deploy.yarn.YarnClusterSuite -Dtest=none ``` in an environment without Python 3 configured: **Before** ``` YarnClusterSuite: org.apache.spark.deploy.yarn.YarnClusterSuite *** ABORTED *** java.lang.RuntimeException: Unable to load a Suite class that was discovered in the runpath: org.apache.spark.deploy.yarn.YarnClusterSuite at org.scalatest.tools.DiscoverySuite$.getSuiteInstance(DiscoverySuite.scala:81) at org.scalatest.tools.DiscoverySuite.$anonfun$nestedSuites$1(DiscoverySuite.scala:38) at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:286) at scala.collection.Iterator.foreach(Iterator.scala:943) at scala.collection.Iterator.foreach$(Iterator.scala:943) at scala.collection.AbstractIterator.foreach(Iterator.scala:1431) at scala.collection.IterableLike.foreach(IterableLike.scala:74) at scala.collection.IterableLike.foreach$(IterableLike.scala:73) at scala.collection.AbstractIterable.foreach(Iterable.scala:56) at scala.collection.TraversableLike.map(TraversableLike.scala:286) ... Run completed in 833 milliseconds. Total number of tests run: 0 Suites: completed 1, aborted 1 Tests: succeeded 0, failed 0, canceled 0, ignored 0, pending 0 *** 1 SUITE ABORTED *** ``` **After** ``` YarnClusterSuite: - run Spark in yarn-client mode - run Spark in yarn-cluster mode - run Spark in yarn-client mode with unmanaged am - run Spark in yarn-client mode with different configurations, ensuring redaction - run Spark in yarn-cluster mode with different configurations, ensuring redaction - yarn-cluster should respect conf overrides in SparkHadoopUtil (SPARK-16414, SPARK-23630) - SPARK-35672: run Spark in yarn-client mode with additional jar using URI scheme 'local' - SPARK-35672: run Spark in yarn-cluster mode with additional jar using URI scheme 'local' - SPARK-35672: run Spark in yarn-client mode with additional jar using URI scheme 'local' and gateway-replacement path - SPARK-35672: run Spark in yarn-cluster mode with additional jar using URI scheme 'local' and gateway-replacement path - SPARK-35672: run Spark in yarn-cluster mode with additional jar using URI scheme 'local' and gateway-replacement path containing an environment variable - SPARK-35672: run Spark in yarn-client mode with additional jar using URI scheme 'file' - SPARK-35672: run Spark in yarn-cluster mode with additional jar using URI scheme 'file' - run Spark in yarn-cluster mode unsuccessfully - run Spark in yarn-cluster mode failure after sc initialized - run Python application in yarn-client mode !!! CANCELED !!! YarnClusterSuite.this.isPythonAvailable was false (YarnClusterSuite.scala:376) - run Python application in yarn-cluster mode !!! CANCELED !!! YarnClusterSuite.this.isPythonAvailable was false (YarnClusterSuite.scala:376) - run Python application in yarn-cluster mode using spark.yarn.appMasterEnv to override local envvar !!! CANCELED !!! YarnClusterSuite.this.isPythonAvailable was false (YarnClusterSuite.scala:376) - user class path first in client mode - user class path first in cluster mode - monitor app using launcher library - running Spark in yarn-cluster mode displays driver log links - timeout to get SparkContext in cluster mode triggers failure - executor env overwrite AM env in client mode - executor env overwrite AM env in cluster mode - SPARK-34472: ivySettings file with no scheme or file:// scheme should be localized on driver in cluster mode - SPARK-34472: ivySettings file with no scheme or file:// scheme should retain user provided path in client mode - SPARK-34472: ivySettings file with non-file:// schemes should throw an error Run completed in 7 minutes, 2 seconds. Total number of tests run: 25 Suites: completed 2, aborted 0 Tests: succeeded 25, failed 0, canceled 3, ignored 0, pending 0 All tests passed. ``` Closes #37454 from LuciferYang/yarnclustersuite. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 8e472443081342a0e0dc37aa154e30a0a6df39b7) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 10 August 2022, 01:00:49 UTC |
| a25394a | ulysses-you | 05 August 2022, 10:26:57 UTC | [SPARK-39867][SQL][3.1] Global limit should not inherit OrderPreservingUnaryNode backport branch-3.1 for https://github.com/apache/spark/pull/37284 ### What changes were proposed in this pull request? Make GlobalLimit inherit UnaryNode rather than OrderPreservingUnaryNode ### Why are the changes needed? Global limit can not promise the output ordering is same with child, it actually depend on the certain physical plan. For all physical plan with gobal limits: - CollectLimitExec: it does not promise output ordering - GlobalLimitExec: it required all tuples so it can assume the child is shuffle or child is single partition. Then it can use output ordering of child - TakeOrderedAndProjectExec: it do sort inside it's implementation This bug get worse since we pull out v1 write require ordering. ### Does this PR introduce _any_ user-facing change? yes, bug fix ### How was this patch tested? fix test and add test Closes #37398 from ulysses-you/SPARK-39867-3.1. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 05 August 2022, 10:26:57 UTC |
| 08c650d | Hyukjin Kwon | 04 August 2022, 01:51:11 UTC | [SPARK-39972][PYTHON][SQL][TESTS] Revert the test case of SPARK-39962 in branch-3.2 and branch-3.1 ### What changes were proposed in this pull request? This PR reverts the test in https://github.com/apache/spark/pull/37390 in branch-3.2 and branch-3.1 because testing util does not exist in branch-3.2 and branch-3.1. ### Why are the changes needed? See https://github.com/apache/spark/pull/37390#issuecomment-1204658808 ### Does this PR introduce _any_ user-facing change? No, test-only. ### How was this patch tested? Logically clean revert. Closes #37401 from HyukjinKwon/SPARK-39972. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit bc9a5d7689b9ac7dbfbdfc4e61741a1ceaa0b9ac) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 04 August 2022, 01:51:27 UTC |
| 9605dde | ulysses-you | 03 August 2022, 17:03:45 UTC | [SPARK-39952][SQL] SaveIntoDataSourceCommand should recache result relation ### What changes were proposed in this pull request? recacheByPlan the result relation inside `SaveIntoDataSourceCommand` ### Why are the changes needed? The behavior of `SaveIntoDataSourceCommand` is similar with `InsertIntoDataSourceCommand` which supports append or overwirte data. In order to keep data consistent, we should always do recacheByPlan the relation on post hoc. ### Does this PR introduce _any_ user-facing change? yes, bug fix ### How was this patch tested? add test Closes #37380 from ulysses-you/refresh. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 5fe0b245f7891a05bc4e1e641fd0aa9130118ea4) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 03 August 2022, 17:05:45 UTC |
| a5f14f4 | zzzzming95 | 03 August 2022, 12:22:55 UTC | [SPARK-39900][SQL] Address partial or negated condition in binary format's predicate pushdown ### What changes were proposed in this pull request? fix `BinaryFileFormat` filter push down bug. Before modification, when Filter tree is: ```` -Not - - IsNotNull ```` Since `IsNotNull` cannot be matched, `IsNotNull` will return a result that is always true (that is, `case _ => (_ => true)`), that is, no filter pushdown is performed. But because there is still a `Not`, after negation, it will return a result that is always False, that is, no result can be returned. ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? test suit in `BinaryFileFormatSuite` ``` testCreateFilterFunction( Seq(Not(IsNull(LENGTH))), Seq((t1, true), (t2, true), (t3, true))) ``` Closes #37350 from zzzzming95/SPARK-39900. Lead-authored-by: zzzzming95 <505306252@qq.com> Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit a0dc7d9117b66426aaa2257c8d448a2f96882ecd) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 03 August 2022, 12:23:32 UTC |
| 7e0a5ef | Hyukjin Kwon | 03 August 2022, 07:11:20 UTC | [SPARK-39962][PYTHON][SQL] Apply projection when group attributes are empty This PR proposes to apply the projection to respect the reordered columns in its child when group attributes are empty. To respect the column order in the child. Yes, it fixes a bug as below: ```python import pandas as pd from pyspark.sql import functions as f f.pandas_udf("double") def AVG(x: pd.Series) -> float: return x.mean() abc = spark.createDataFrame([(1.0, 5.0, 17.0)], schema=["a", "b", "c"]) abc.agg(AVG("a"), AVG("c")).show() abc.select("c", "a").agg(AVG("a"), AVG("c")).show() ``` **Before** ``` +------+------+ |AVG(a)|AVG(c)| +------+------+ | 17.0| 1.0| +------+------+ ``` **After** ``` +------+------+ |AVG(a)|AVG(c)| +------+------+ | 1.0| 17.0| +------+------+ ``` Manually tested, and added an unittest. Closes #37390 from HyukjinKwon/SPARK-39962. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 5335c784ae76c9cc0aaa7a4b57b3cd6b3891ad9a) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 03 August 2022, 07:13:08 UTC |
| 586ccce | ulysses-you | 03 August 2022, 03:14:18 UTC | [SPARK-39835][SQL][3.1] Fix EliminateSorts remove global sort below the local sort backport https://github.com/apache/spark/pull/37250 into branch-3.1 ### What changes were proposed in this pull request? Correct the `EliminateSorts` follows: - If the upper sort is global then we can remove the global or local sort recursively. - If the upper sort is local then we can only remove the local sort recursively. ### Why are the changes needed? If a global sort below locol sort, we should not remove the global sort becuase the output partitioning can be affected. This issue is going to worse since we pull out the V1 Write sort to logcial side. ### Does this PR introduce _any_ user-facing change? yes, bug fix ### How was this patch tested? add test Closes #37276 from ulysses-you/SPARK-39835-3.1. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 03 August 2022, 03:14:18 UTC |
| ed842ba | ulysses-you | 02 August 2022, 09:05:48 UTC | [SPARK-39932][SQL] WindowExec should clear the final partition buffer ### What changes were proposed in this pull request? Explicitly clear final partition buffer if can not find next in `WindowExec`. The same fix in `WindowInPandasExec` ### Why are the changes needed? We do a repartition after a window, then we need do a local sort after window due to RoundRobinPartitioning shuffle. The error stack: ```java ExternalAppendOnlyUnsafeRowArray INFO - Reached spill threshold of 4096 rows, switching to org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter org.apache.spark.memory.SparkOutOfMemoryError: Unable to acquire 65536 bytes of memory, got 0 at org.apache.spark.memory.MemoryConsumer.throwOom(MemoryConsumer.java:157) at org.apache.spark.memory.MemoryConsumer.allocateArray(MemoryConsumer.java:97) at org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter.growPointerArrayIfNecessary(UnsafeExternalSorter.java:352) at org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter.allocateMemoryForRecordIfNecessary(UnsafeExternalSorter.java:435) at org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter.insertRecord(UnsafeExternalSorter.java:455) at org.apache.spark.sql.execution.UnsafeExternalRowSorter.insertRow(UnsafeExternalRowSorter.java:138) at org.apache.spark.sql.execution.UnsafeExternalRowSorter.sort(UnsafeExternalRowSorter.java:226) at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec$.$anonfun$prepareShuffleDependency$10(ShuffleExchangeExec.scala:355) ``` `WindowExec` only clear buffer in `fetchNextPartition` so the final partition buffer miss to clear. It is not a big problem since we have task completion listener. ```scala taskContext.addTaskCompletionListener(context -> { cleanupResources(); }); ``` This bug only affects if the window is not the last operator for this task and the follow operator like sort. ### Does this PR introduce _any_ user-facing change? yes, bug fix ### How was this patch tested? N/A Closes #37358 from ulysses-you/window. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 1fac870126c289a7ec75f45b6b61c93b9a4965d4) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 02 August 2022, 09:06:38 UTC |
| 3768ee1 | yangjie01 | 27 July 2022, 00:26:47 UTC | [SPARK-39879][SQL][TESTS] Reduce local-cluster maximum memory size in `BroadcastJoinSuite*` and `HiveSparkSubmitSuite` ### What changes were proposed in this pull request? This pr change `local-cluster[2, 1, 1024]` in `BroadcastJoinSuite*` and `HiveSparkSubmitSuite` to `local-cluster[2, 1, 512]` to reduce test maximum memory usage. ### Why are the changes needed? Reduce the maximum memory usage of test cases. ### Does this PR introduce _any_ user-facing change? No, test-only. ### How was this patch tested? Should monitor CI Closes #37298 from LuciferYang/reduce-local-cluster-memory. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 01d41e7de418d0a40db7b16ddd0d8546f0794d17) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 27 July 2022, 00:27:24 UTC |
| 736c7ca | Hyukjin Kwon | 25 July 2022, 06:56:19 UTC | Revert "[SPARK-39856][SQL][TESTS] Increase the number of partitions in TPC-DS build to avoid out-of-memory" This reverts commit 22102931a9044f688ad5ff03c241d5deee17dfe1. | 25 July 2022, 06:56:19 UTC |
| 2210293 | Hyukjin Kwon | 25 July 2022, 03:44:54 UTC | [SPARK-39856][SQL][TESTS] Increase the number of partitions in TPC-DS build to avoid out-of-memory This PR proposes to avoid out-of-memory in TPC-DS build at GitHub Actions CI by: - Increasing the number of partitions being used in shuffle. - Truncating precisions after 10th in floats. The number of partitions was previously set to 1 because of different results in precisions that generally we can just ignore. - Sort the results regardless of join type since Apache Spark does not guarantee the order of results One of the reasons for the large memory usage seems to be single partition that's being used in the shuffle. No, test-only. GitHub Actions in this CI will test it out. Closes #37270 from HyukjinKwon/deflake-tpcds. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 7358253755762f9bfe6cedc1a50ec14616cfeace) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 25 July 2022, 03:49:48 UTC |
| aba37d6 | Ruifeng Zheng | 22 July 2022, 03:11:57 UTC | [SPARK-39831][BUILD] Fix R dependencies installation failure ### What changes were proposed in this pull request? move `libfontconfig1-dev libharfbuzz-dev libfribidi-dev libfreetype6-dev libpng-dev libtiff5-dev libjpeg-dev` from Install dependencies for documentation generation to Install R linter dependencies and SparkR Update after https://github.com/apache/spark/pull/37243: **add `apt update` before installation.** ### Why are the changes needed? to make CI happy Install R linter dependencies and SparkR started to fail after devtools_2.4.4 was released. ``` --------------------------- [ANTICONF] -------------------------------- Configuration failed to find the fontconfig freetype2 library. Try installing: * deb: libfontconfig1-dev (Debian, Ubuntu, etc) * rpm: fontconfig-devel (Fedora, EPEL) * csw: fontconfig_dev (Solaris) * brew: freetype (OSX) it seems that libfontconfig1-dev is needed now. ``` also refer to https://github.com/r-lib/systemfonts/issues/35#issuecomment-633560151 ### Does this PR introduce any user-facing change? No ### How was this patch tested? CI passed Closes #37247 from Yikun/patch-25. Lead-authored-by: Ruifeng Zheng <ruifengz@apache.org> Co-authored-by: Yikun Jiang <yikunkero@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit ffa82c219029a7f6f3caf613dd1d0ab56d0c599e) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 22 July 2022, 03:12:35 UTC |
| 248f34e | Hyukjin Kwon | 22 July 2022, 00:06:09 UTC | Revert "[SPARK-39831][BUILD] Fix R dependencies installation failure" This reverts commit b5cc9eda12465f4f3c7a8a193033d1764002ab10. | 22 July 2022, 00:06:09 UTC |
| b5cc9ed | Ruifeng Zheng | 21 July 2022, 13:29:18 UTC | [SPARK-39831][BUILD] Fix R dependencies installation failure ### What changes were proposed in this pull request? move `libfontconfig1-dev libharfbuzz-dev libfribidi-dev libfreetype6-dev libpng-dev libtiff5-dev libjpeg-dev` from `Install dependencies for documentation generation` to `Install R linter dependencies and SparkR` ### Why are the changes needed? to make CI happy `Install R linter dependencies and SparkR` started to fail after `devtools_2.4.4` was released. ``` --------------------------- [ANTICONF] -------------------------------- Configuration failed to find the fontconfig freetype2 library. Try installing: * deb: libfontconfig1-dev (Debian, Ubuntu, etc) * rpm: fontconfig-devel (Fedora, EPEL) * csw: fontconfig_dev (Solaris) * brew: freetype (OSX) ``` it seems that `libfontconfig1-dev` is needed now. also refer to https://github.com/r-lib/systemfonts/issues/35#issuecomment-633560151 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? existing tests Closes #37243 from zhengruifeng/ci_add_dep. Authored-by: Ruifeng Zheng <ruifengz@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 67efa318ec8cababdb5683ac262a8ebc3b3beefb) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 21 July 2022, 13:29:54 UTC |
| 36fc73e | tianlzhang | 14 July 2022, 04:49:57 UTC | [SPARK-39672][SQL][3.1] Fix removing project before filter with correlated subquery ### What changes were proposed in this pull request? Add more checks to`removeProjectBeforeFilter` in `ColumnPruning` and only remove the project if 1. the filter condition contains correlated subquery 2. same attribute exists in both output of child of Project and subquery ### Why are the changes needed? This is a legitimate self-join query and should not throw exception when de-duplicating attributes in subquery and outer values. ```sql select * from ( select v1.a, v1.b, v2.c from v1 inner join v2 on v1.a=v2.a) t3 where not exists ( select 1 from v2 where t3.a=v2.a and t3.b=v2.b and t3.c=v2.c ) ``` Here's what happens with the current code. The above query is analyzed into following `LogicalPlan` before `ColumnPruning`. ``` Project [a#250, b#251, c#268] +- Filter NOT exists#272 [(a#250 = a#266) && (b#251 = b#267) && (c#268 = c#268#277)] : +- Project [1 AS 1#273, _1#259 AS a#266, _2#260 AS b#267, _3#261 AS c#268#277] : +- LocalRelation [_1#259, _2#260, _3#261] +- Project [a#250, b#251, c#268] +- Join Inner, (a#250 = a#266) :- Project [a#250, b#251] : +- Project [_1#243 AS a#250, _2#244 AS b#251] : +- LocalRelation [_1#243, _2#244, _3#245] +- Project [a#266, c#268] +- Project [_1#259 AS a#266, _3#261 AS c#268] +- LocalRelation [_1#259, _2#260, _3#261] ``` Then in `ColumnPruning`, the Project before Filter (between Filter and Join) is removed. This changes the `outputSet` of the child of Filter among which the same attribute also exists in the subquery. Later, when `RewritePredicateSubquery` de-duplicates conflicting attributes, it would complain `Found conflicting attributes a#266 in the condition joining outer plan`. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Add UT. Closes #37074 from manuzhang/spark-39672. Lead-authored-by: tianlzhang <tianlzhang@ebay.com> Co-authored-by: Manu Zhang <OwenZhang1990@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 14 July 2022, 04:49:57 UTC |
| 07f5926 | Max Gekk | 05 July 2022, 15:20:53 UTC | [SPARK-39677][SQL][DOCS][3.1] Fix args formatting of the regexp and like functions ### What changes were proposed in this pull request? In the PR, I propose to fix args formatting of some regexp functions by adding explicit new lines. That fixes the following items in arg lists. Before: <img width="745" alt="Screenshot 2022-07-05 at 09 48 28" src="https://user-images.githubusercontent.com/1580697/177274234-04209d43-a542-4c71-b5ca-6f3239208015.png"> After: <img width="704" alt="Screenshot 2022-07-05 at 11 06 13" src="https://user-images.githubusercontent.com/1580697/177280718-cb05184c-8559-4461-b94d-dfaaafda7dd2.png"> ### Why are the changes needed? To improve readability of Spark SQL docs. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? By building docs and checking manually: ``` $ SKIP_SCALADOC=1 SKIP_PYTHONDOC=1 SKIP_RDOC=1 bundle exec jekyll build ``` Authored-by: Max Gekk <max.gekkgmail.com> Signed-off-by: Max Gekk <max.gekkgmail.com> (cherry picked from commit 4e42f8b12e8dc57a15998f22d508a19cf3c856aa) Signed-off-by: Max Gekk <max.gekkgmail.com> Closes #37094 from MaxGekk/fix-regexp-docs-3.1. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 05 July 2022, 15:20:53 UTC |
| cc8ab36 | ulysses-you | 05 July 2022, 02:54:18 UTC | [SPARK-39656][SQL][3.1] Fix wrong namespace in DescribeNamespaceExec backport https://github.com/apache/spark/pull/37049 for branch-3.1 ### What changes were proposed in this pull request? DescribeNamespaceExec change ns.last to ns.quoted ### Why are the changes needed? DescribeNamespaceExec should show the whole namespace rather than last ### Does this PR introduce _any_ user-facing change? yes, a small bug fix ### How was this patch tested? fix test Closes #37073 from ulysses-you/desc-namespace-3.1. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 05 July 2022, 02:54:18 UTC |
| b324b61 | Dongjoon Hyun | 27 June 2022, 19:52:11 UTC | [SPARK-39621][PYTHON][TESTS] Make `run-tests.py` robust by avoiding `rmtree` on MacOS This PR aims to make `run-tests.py` robust by avoiding `rmtree` on MacOS. There exists a race condition in Python and it causes flakiness in MacOS - https://bugs.python.org/issue29699 - https://github.com/python/cpython/issues/73885 No. After passing CIs, this should be tested on MacOS. Closes #37010 from dongjoon-hyun/SPARK-39621. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 432945db743965f1beb59e3a001605335ca2df83) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 27 June 2022, 19:54:45 UTC |
| 205766e | Bruce Robbins | 21 June 2022, 23:31:56 UTC | [SPARK-39496][SQL][3.1] Handle null struct in Inline.eval ### What changes were proposed in this pull request? Backport of #36903 Change `Inline.eval` to return a row of null values rather than a null row in the case of a null input struct. ### Why are the changes needed? Consider the following query: ``` set spark.sql.codegen.wholeStage=false; select inline(array(named_struct('a', 1, 'b', 2), null)); ``` This query fails with a `NullPointerException`: ``` 22/06/16 15:10:06 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0) java.lang.NullPointerException at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificUnsafeProjection.apply(Unknown Source) at org.apache.spark.sql.execution.GenerateExec.$anonfun$doExecute$11(GenerateExec.scala:122) ``` (In Spark 3.1.x, you don't need to set `spark.sql.codegen.wholeStage` to false to reproduce the error, since Spark 3.1.x has no codegen path for `Inline`). This query fails regardless of the setting of `spark.sql.codegen.wholeStage`: ``` val dfWide = (Seq((1)) .toDF("col0") .selectExpr(Seq.tabulate(99)(x => s"$x as col${x + 1}"): _*)) val df = (dfWide .selectExpr("*", "array(named_struct('a', 1, 'b', 2), null) as struct_array")) df.selectExpr("*", "inline(struct_array)").collect ``` It fails with ``` 22/06/16 15:18:55 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)/ 1] java.lang.NullPointerException at org.apache.spark.sql.catalyst.expressions.JoinedRow.isNullAt(JoinedRow.scala:80) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificUnsafeProjection.writeFields_0_8$(Unknown Source) ``` When `Inline.eval` returns a null row in the collection, GenerateExec gets a NullPointerException either when joining the null row with required child output, or projecting the null row. This PR avoids producing the null row and produces a row of null values instead: ``` spark-sql> set spark.sql.codegen.wholeStage=false; spark.sql.codegen.wholeStage false Time taken: 3.095 seconds, Fetched 1 row(s) spark-sql> select inline(array(named_struct('a', 1, 'b', 2), null)); 1 2 NULL NULL Time taken: 1.214 seconds, Fetched 2 row(s) spark-sql> ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? New unit test. Closes #36949 from bersprockets/inline_eval_null_struct_issue_31. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 21 June 2022, 23:31:56 UTC |
| 14bc8ec | Sean Owen | 17 June 2022, 16:36:49 UTC | [SPARK-39505][UI] Escape log content rendered in UI ### What changes were proposed in this pull request? Escape log content rendered to the UI. ### Why are the changes needed? Log content may contain reserved characters or other code in the log and be misinterpreted in the UI as HTML. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests Closes #36902 from srowen/LogViewEscape. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 17 June 2022, 18:32:40 UTC |
| b432226 | wangguangxin.cn | 16 June 2022, 01:27:24 UTC | [SPARK-39476][SQL] Disable Unwrap cast optimize when casting from Long to Float/ Double or from Integer to Float Cast from Integer to Float or from Long to Double/Float may loss precision if the length of Integer/Long beyonds the **significant digits** of a Double(which is 15 or 16 digits) or Float(which is 7 or 8 digits). For example, ```select *, cast(a as int) from (select cast(33554435 as foat) a )``` gives `33554436` instead of `33554435`. When it comes the optimization rule `UnwrapCastInBinaryComparison`, it may result in incorrect (confused) result . We can reproduce it with following script. ``` spark.range(10).map(i => 64707595868612313L).createOrReplaceTempView("tbl") val df = sql("select * from tbl where cast(value as double) = cast('64707595868612313' as double)") df.explain(true) df.show() ``` With we disable this optimization rule , it returns 10 records. But if we enable this optimization rule, it returns empty, since the sql is optimized to ``` select * from tbl where value = 64707595868612312L ``` Fix the behavior that may confuse users (or maybe a bug?) No Add a new UT Closes #36873 from WangGuangxin/SPARK-24994-followup. Authored-by: wangguangxin.cn <wangguangxin.cn@bytedance.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 9612db3fc9c38204b2bf9f724dedb9ec5f636556) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 16 June 2022, 01:35:27 UTC |
| 3e9bb03 | Ole Sasse | 12 June 2022, 09:15:05 UTC | [SPARK-39259][SQL][3.1] Evaluate timestamps consistently in subqueries ### What changes were proposed in this pull request? Apply the optimizer rule ComputeCurrentTime consistently across subqueries. This is a backport of https://github.com/apache/spark/pull/36654 with adjustements: * The rule does not use pruning * The transformWithSubqueries function was also backported ### Why are the changes needed? At the moment timestamp functions like now() can return different values within a query if subqueries are involved ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? A new unit test was added Closes #36818 from olaky/SPARK-39259-spark_3_1. Authored-by: Ole Sasse <ole.sasse@databricks.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 12 June 2022, 09:15:05 UTC |
| 512d337 | Amin Borjian | 08 June 2022, 20:30:44 UTC | [SPARK-39393][SQL] Parquet data source only supports push-down predicate filters for non-repeated primitive types ### What changes were proposed in this pull request? In Spark version 3.1.0 and newer, Spark creates extra filter predicate conditions for repeated parquet columns. These fields do not have the ability to have a filter predicate, according to the [PARQUET-34](https://issues.apache.org/jira/browse/PARQUET-34) issue in the parquet library. This PR solves this problem until the appropriate functionality is provided by the parquet. Before this PR: Assume follow Protocol buffer schema: ``` message Model { string name = 1; repeated string keywords = 2; } ``` Suppose a parquet file is created from a set of records in the above format with the help of the parquet-protobuf library. Using Spark version 3.1.0 or newer, we get following exception when run the following query using spark-shell: ``` val data = spark.read.parquet("/path/to/parquet") data.registerTempTable("models") spark.sql("select * from models where array_contains(keywords, 'X')").show(false) ``` ``` Caused by: java.lang.IllegalArgumentException: FilterPredicates do not currently support repeated columns. Column keywords is repeated. at org.apache.parquet.filter2.predicate.SchemaCompatibilityValidator.validateColumn(SchemaCompatibilityValidator.java:176) at org.apache.parquet.filter2.predicate.SchemaCompatibilityValidator.validateColumnFilterPredicate(SchemaCompatibilityValidator.java:149) at org.apache.parquet.filter2.predicate.SchemaCompatibilityValidator.visit(SchemaCompatibilityValidator.java:89) at org.apache.parquet.filter2.predicate.SchemaCompatibilityValidator.visit(SchemaCompatibilityValidator.java:56) at org.apache.parquet.filter2.predicate.Operators$NotEq.accept(Operators.java:192) at org.apache.parquet.filter2.predicate.SchemaCompatibilityValidator.validate(SchemaCompatibilityValidator.java:61) at org.apache.parquet.filter2.compat.RowGroupFilter.visit(RowGroupFilter.java:95) at org.apache.parquet.filter2.compat.RowGroupFilter.visit(RowGroupFilter.java:45) at org.apache.parquet.filter2.compat.FilterCompat$FilterPredicateCompat.accept(FilterCompat.java:149) at org.apache.parquet.filter2.compat.RowGroupFilter.filterRowGroups(RowGroupFilter.java:72) at org.apache.parquet.hadoop.ParquetFileReader.filterRowGroups(ParquetFileReader.java:870) at org.apache.parquet.hadoop.ParquetFileReader.<init>(ParquetFileReader.java:789) at org.apache.parquet.hadoop.ParquetFileReader.open(ParquetFileReader.java:657) at org.apache.parquet.hadoop.ParquetRecordReader.initializeInternalReader(ParquetRecordReader.java:162) at org.apache.parquet.hadoop.ParquetRecordReader.initialize(ParquetRecordReader.java:140) at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat.$anonfun$buildReaderWithPartitionValues$2(ParquetFileFormat.scala:373) at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.org$apache$spark$sql$execution$datasources$FileScanRDD$$anon$$readCurrentFile(FileScanRDD.scala:127) ... ``` The cause of the problem is due to a change in the data filtering conditions: ``` spark.sql("select * from log where array_contains(keywords, 'X')").explain(true); // Spark 3.0.2 and older == Physical Plan == ... +- FileScan parquet [link#0,keywords#1] DataFilters: [array_contains(keywords#1, Google)] PushedFilters: [] ... // Spark 3.1.0 and newer == Physical Plan == ... +- FileScan parquet [link#0,keywords#1] DataFilters: [isnotnull(keywords#1), array_contains(keywords#1, Google)] PushedFilters: [IsNotNull(keywords)] ... ``` Pushing filters down for repeated columns of parquet is not necessary because it is not supported by parquet library for now. So we can exclude them from pushed predicate filters and solve issue. ### Why are the changes needed? Predicate filters that are pushed down to parquet should not be created on repeated-type fields. ### Does this PR introduce any user-facing change? No, It's only fixed a bug and before this, due to the limitations of the parquet library, no more work was possible. ### How was this patch tested? Add an extra test to ensure problem solved. Closes #36781 from Borjianamin98/master. Authored-by: Amin Borjian <borjianamin98@outlook.com> Signed-off-by: huaxingao <huaxin_gao@apple.com> (cherry picked from commit ac2881a8c3cfb196722a5680a62ebd6bb9fba728) Signed-off-by: huaxingao <huaxin_gao@apple.com> | 08 June 2022, 20:31:59 UTC |
| 0908337 | sandeepvinayak | 31 May 2022, 22:28:07 UTC | [SPARK-39283][CORE] Fix deadlock between TaskMemoryManager and UnsafeExternalSorter.SpillableIterator ### What changes were proposed in this pull request? This PR fixes a deadlock between TaskMemoryManager and UnsafeExternalSorter.SpillableIterator. ### Why are the changes needed? We are facing the deadlock issue b/w TaskMemoryManager and UnsafeExternalSorter.SpillableIterator during the join. It turns out that in UnsafeExternalSorter.SpillableIterator#spill() function, it tries to get lock on UnsafeExternalSorter`SpillableIterator` and UnsafeExternalSorter and call `freePage` to free all allocated pages except the last one which takes the lock on TaskMemoryManager. At the same time, there can be another `MemoryConsumer` using `UnsafeExternalSorter` as part of sorting can try to allocatePage needs to get lock on `TaskMemoryManager` which can cause spill to happen which requires lock on `UnsafeExternalSorter` again causing deadlock. There is a similar fix here as well: https://issues.apache.org/jira/browse/SPARK-27338 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing unit tests. Closes #36680 from sandeepvinayak/SPARK-39283. Authored-by: sandeepvinayak <sandeep.pal@outlook.com> Signed-off-by: Josh Rosen <joshrosen@databricks.com> (cherry picked from commit 8d0c035f102b005c2e85f03253f1c0c24f0a539f) Signed-off-by: Josh Rosen <joshrosen@databricks.com> | 31 May 2022, 22:33:27 UTC |
| 68d6950 | Takuya UESHIN | 26 May 2022, 01:36:03 UTC | [SPARK-39293][SQL] Fix the accumulator of ArrayAggregate to handle complex types properly Fix the accumulator of `ArrayAggregate` to handle complex types properly. The accumulator of `ArrayAggregate` should copy the intermediate result if string, struct, array, or map. If the intermediate data of `ArrayAggregate` holds reusable data, the result will be duplicated. ```scala import org.apache.spark.sql.functions._ val reverse = udf((s: String) => s.reverse) val df = Seq(Array("abc", "def")).toDF("array") val testArray = df.withColumn( "agg", aggregate( col("array"), array().cast("array<string>"), (acc, s) => concat(acc, array(reverse(s))))) aggArray.show(truncate=false) ``` should be: ``` +----------+----------+ |array |agg | +----------+----------+ |[abc, def]|[cba, fed]| +----------+----------+ ``` but: ``` +----------+----------+ |array |agg | +----------+----------+ |[abc, def]|[fed, fed]| +----------+----------+ ``` Yes, this fixes the correctness issue. Added a test. Closes #36674 from ueshin/issues/SPARK-39293/array_aggregate. Authored-by: Takuya UESHIN <ueshin@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit d6a11cb4b411c8136eb241aac167bc96990f5421) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 92e82fdf8e2faec5add61e2448f11272dfb19c6e) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 26 May 2022, 01:38:55 UTC |
| 3cc5d4a | Ivan Sadikov | 25 May 2022, 02:39:54 UTC | [SPARK-39252][PYSPARK][TESTS] Remove flaky test_df_is_empty This PR removes flaky `test_df_is_empty` as reported in https://issues.apache.org/jira/browse/SPARK-39252. I will open a follow-up PR to reintroduce the test and fix the flakiness (or see if it was a regression). No. Existing unit tests. Closes #36656 from sadikovi/SPARK-39252. Authored-by: Ivan Sadikov <ivan.sadikov@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 9823bb385cd6dca7c4fb5a6315721420ad42f80a) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 25 May 2022, 07:33:13 UTC |
| 661cc52 | Hyukjin Kwon | 25 May 2022, 07:32:41 UTC | Revert "[SPARK-39252][PYSPARK][TESTS] Remove flaky test_df_is_empty" This reverts commit ad42284f3f1aa3d3d691b95ea76ea8eae535abe2. | 25 May 2022, 07:32:41 UTC |
| ad42284 | Ivan Sadikov | 25 May 2022, 02:39:54 UTC | [SPARK-39252][PYSPARK][TESTS] Remove flaky test_df_is_empty This PR removes flaky `test_df_is_empty` as reported in https://issues.apache.org/jira/browse/SPARK-39252. I will open a follow-up PR to reintroduce the test and fix the flakiness (or see if it was a regression). No. Existing unit tests. Closes #36656 from sadikovi/SPARK-39252. Authored-by: Ivan Sadikov <ivan.sadikov@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 9823bb385cd6dca7c4fb5a6315721420ad42f80a) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 25 May 2022, 07:30:42 UTC |
| a7d0edf | Hyukjin Kwon | 25 May 2022, 07:28:31 UTC | Revert "[SPARK-39252][PYSPARK][TESTS] Remove flaky test_df_is_empty" This reverts commit 3b2c1b916a29fef0463dc3a6d9df2e46a91cf446. | 25 May 2022, 07:28:31 UTC |
| 3b2c1b9 | Ivan Sadikov | 25 May 2022, 02:39:54 UTC | [SPARK-39252][PYSPARK][TESTS] Remove flaky test_df_is_empty This PR removes flaky `test_df_is_empty` as reported in https://issues.apache.org/jira/browse/SPARK-39252. I will open a follow-up PR to reintroduce the test and fix the flakiness (or see if it was a regression). No. Existing unit tests. Closes #36656 from sadikovi/SPARK-39252. Authored-by: Ivan Sadikov <ivan.sadikov@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 9823bb385cd6dca7c4fb5a6315721420ad42f80a) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 25 May 2022, 02:42:46 UTC |
| 3362ea0 | Jungtaek Lim | 19 May 2022, 02:50:05 UTC | [SPARK-39219][DOC] Promote Structured Streaming over DStream ### What changes were proposed in this pull request? This PR proposes to add NOTE section for DStream guide doc to promote Structured Streaming. Screenshot: <img width="992" alt="screenshot-spark-streaming-programming-guide-change" src="https://user-images.githubusercontent.com/1317309/168977732-4c32db9a-0fb1-4a82-a542-bf385e5f3683.png"> ### Why are the changes needed? We see efforts of community are more focused on Structured Streaming (based on Spark SQL) than Spark Streaming (DStream). We would like to encourage end users to use Structured Streaming than Spark Streaming whenever possible for their workloads. ### Does this PR introduce _any_ user-facing change? Yes, doc change. ### How was this patch tested? N/A Closes #36590 from HeartSaVioR/SPARK-39219. Authored-by: Jungtaek Lim <kabhwan.opensource@gmail.com> Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com> (cherry picked from commit 7d153392db2f61104da0af1cb175f4ee7c7fbc38) Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com> | 19 May 2022, 02:51:18 UTC |
| d557a56 | Lorenzo Martini | 10 May 2022, 00:44:19 UTC | [SPARK-39107][SQL] Account for empty string input in regex replace ### What changes were proposed in this pull request? When trying to perform a regex replace, account for the possibility of having empty strings as input. ### Why are the changes needed? https://github.com/apache/spark/pull/29891 was merged to address https://issues.apache.org/jira/browse/SPARK-30796 and introduced a bug that would not allow regex matching on empty strings, as it would account for position within substring but not consider the case where input string has length 0 (empty string) From https://issues.apache.org/jira/browse/SPARK-39107 there is a change in behavior between spark versions. 3.0.2 ``` scala> val df = spark.sql("SELECT '' AS col") df: org.apache.spark.sql.DataFrame = [col: string] scala> df.withColumn("replaced", regexp_replace(col("col"), "^$", "<empty>")).show +---+--------+ |col|replaced| +---+--------+ | | <empty>| +---+--------+ ``` 3.1.2 ``` scala> val df = spark.sql("SELECT '' AS col") df: org.apache.spark.sql.DataFrame = [col: string] scala> df.withColumn("replaced", regexp_replace(col("col"), "^$", "<empty>")).show +---+--------+ |col|replaced| +---+--------+ | | | +---+--------+ ``` The 3.0.2 outcome is the expected and correct one ### Does this PR introduce _any_ user-facing change? Yes compared to spark 3.2.1, as it brings back the correct behavior when trying to regex match empty strings, as shown in the example above. ### How was this patch tested? Added special casing test in `RegexpExpressionsSuite.RegexReplace` with empty string replacement. Closes #36457 from LorenzoMartini/lmartini/fix-empty-string-replace. Authored-by: Lorenzo Martini <lmartini@palantir.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 731aa2cdf8a78835621fbf3de2d3492b27711d1a) Signed-off-by: Sean Owen <srowen@gmail.com> | 10 May 2022, 00:45:25 UTC |
| 4d339c1 | Kazuyuki Tanimura | 06 April 2022, 00:49:44 UTC | [SPARK-38786][SQL][TEST] Bug in StatisticsSuite 'change stats after add/drop partition command' ### What changes were proposed in this pull request? https://github.com/apache/spark/blob/cbffc12f90e45d33e651e38cf886d7ab4bcf96da/sql/hive/src/test/scala/org/apache/spark/sql/hive/StatisticsSuite.scala#L979 It should be `partDir2` instead of `partDir1`. Looks like it is a copy paste bug. ### Why are the changes needed? Due to this test bug, the drop command was dropping a wrong (`partDir1`) underlying file in the test. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added extra underlying file location check. Closes #36075 from kazuyukitanimura/SPARK-38786. Authored-by: Kazuyuki Tanimura <ktanimura@apple.com> Signed-off-by: Chao Sun <sunchao@apple.com> (cherry picked from commit a6b04f007c07fe00637aa8be33a56f247a494110) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit a52a245d11c20b0360d463c973388f3ee05768ac) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 04161ac55750dac055a4b7b018ac989ff1acc439) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 09 May 2022, 00:44:49 UTC |
| 19576c4 | Vitalii Li | 06 May 2022, 09:01:51 UTC | [SPARK-39060][SQL][3.1] Typo in error messages of decimal overflow ### What changes were proposed in this pull request? This PR removes extra curly bracket from debug string for Decimal type in SQL. This is a backport from master branch. Commit: https://github.com/apache/spark/commit/165ce4eb7d6d75201beb1bff879efa99fde24f94 ### Why are the changes needed? Typo in error messages of decimal overflow. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? By running tests: ``` $ build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite -- -z decimalArithmeticOperations.sql" ``` Closes #36459 from vli-databricks/SPARK-39060-3.1. Authored-by: Vitalii Li <vitalii.li@databricks.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 06 May 2022, 09:01:51 UTC |
| 8f6a3a5 | Ivan Sadikov | 02 May 2022, 23:30:05 UTC | [SPARK-39084][PYSPARK] Fix df.rdd.isEmpty() by using TaskContext to stop iterator on task completion This PR fixes the issue described in https://issues.apache.org/jira/browse/SPARK-39084 where calling `df.rdd.isEmpty()` on a particular dataset could result in a JVM crash and/or executor failure. The issue was due to Python iterator not being synchronised with Java iterator so when the task is complete, the Python iterator continues to process data. We have introduced ContextAwareIterator as part of https://issues.apache.org/jira/browse/SPARK-33277 but we did not fix all of the places where this should be used. Fixes the JVM crash when checking isEmpty() on a dataset. No. I added a test case that reproduces the issue 100%. I confirmed that the test fails without the fix and passes with the fix. Closes #36425 from sadikovi/fix-pyspark-iter-2. Authored-by: Ivan Sadikov <ivan.sadikov@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 9305cc744d27daa6a746d3eb30e7639c63329072) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 02 May 2022, 23:35:18 UTC |
| be52490 | Hyukjin Kwon | 02 May 2022, 23:34:39 UTC | Revert "[SPARK-39084][PYSPARK] Fix df.rdd.isEmpty() by using TaskContext to stop iterator on task completion" This reverts commit 660a9f845f954b4bf2c3a7d51988b33ae94e3207. | 02 May 2022, 23:34:39 UTC |
| 660a9f8 | Ivan Sadikov | 02 May 2022, 23:30:05 UTC | [SPARK-39084][PYSPARK] Fix df.rdd.isEmpty() by using TaskContext to stop iterator on task completion This PR fixes the issue described in https://issues.apache.org/jira/browse/SPARK-39084 where calling `df.rdd.isEmpty()` on a particular dataset could result in a JVM crash and/or executor failure. The issue was due to Python iterator not being synchronised with Java iterator so when the task is complete, the Python iterator continues to process data. We have introduced ContextAwareIterator as part of https://issues.apache.org/jira/browse/SPARK-33277 but we did not fix all of the places where this should be used. Fixes the JVM crash when checking isEmpty() on a dataset. No. I added a test case that reproduces the issue 100%. I confirmed that the test fails without the fix and passes with the fix. Closes #36425 from sadikovi/fix-pyspark-iter-2. Authored-by: Ivan Sadikov <ivan.sadikov@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 9305cc744d27daa6a746d3eb30e7639c63329072) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 02 May 2022, 23:32:40 UTC |
| 2a996f1 | allisonwang-db | 28 April 2022, 19:11:17 UTC | [SPARK-38918][SQL][3.1] Nested column pruning should filter out attributes that do not belong to the current relation ### What changes were proposed in this pull request? Backport https://github.com/apache/spark/pull/36216 to branch-3.1. ### Why are the changes needed? To fix a bug in `SchemaPruning`. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test Closes #36387 from allisonwang-db/spark-38918-branch-3.1. Authored-by: allisonwang-db <allison.wang@databricks.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 28 April 2022, 19:11:17 UTC |
| 30be8d0 | vadim | 27 April 2022, 07:56:18 UTC | [SPARK-39032][PYTHON][DOCS] Examples' tag for pyspark.sql.functions.when() ### What changes were proposed in this pull request? Fix missing keyword for `pyspark.sql.functions.when()` documentation. ### Why are the changes needed? [Documentation](https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.sql.functions.when.html) is not formatted correctly ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? All tests passed. Closes #36369 from vadim/SPARK-39032. Authored-by: vadim <86705+vadim@users.noreply.github.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 5b53bdfa83061c160652e07b999f996fc8bd2ece) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 27 April 2022, 07:57:01 UTC |
| 7217c51 | Bruce Robbins | 27 April 2022, 07:38:22 UTC | [SPARK-38868][SQL][3.2] Don't propagate exceptions from filter predicate when optimizing outer joins Backport of #36230 ### What changes were proposed in this pull request? Change `EliminateOuterJoin#canFilterOutNull` to return `false` when a `where` condition throws an exception. ### Why are the changes needed? Consider this query: ``` select * from (select id, id as b from range(0, 10)) l left outer join (select id, id + 1 as c from range(0, 10)) r on l.id = r.id where assert_true(c > 0) is null; ``` The query should succeed, but instead fails with ``` java.lang.RuntimeException: '(c#1L > cast(0 as bigint))' is not true! ``` This happens even though there is no row where `c > 0` is false. The `EliminateOuterJoin` rule checks if it can convert the outer join to a inner join based on the expression in the where clause, which in this case is ``` assert_true(c > 0) is null ``` `EliminateOuterJoin#canFilterOutNull` evaluates that expression with `c` set to `null` to see if the result is `null` or `false`. That rule doesn't expect the result to be a `RuntimeException`, but in this case it always is. That is, the assertion is failing during optimization, not at run time. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? New unit test. Closes #36341 from bersprockets/outer_join_eval_assert_issue_32. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 3690c8ceb9e5c2f642b9f9e1af526f76d2e2a71a) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 27 April 2022, 07:39:47 UTC |
| ee1d0c8 | Hyukjin Kwon | 22 April 2022, 10:01:05 UTC | [SPARK-38992][CORE] Avoid using bash -c in ShellBasedGroupsMappingProvider ### What changes were proposed in this pull request? This PR proposes to avoid using `bash -c` in `ShellBasedGroupsMappingProvider`. This could allow users a command injection. ### Why are the changes needed? For a security purpose. ### Does this PR introduce _any_ user-facing change? Virtually no. ### How was this patch tested? Manually tested. Closes #36315 from HyukjinKwon/SPARK-38992. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit c83618e4e5fc092829a1f2a726f12fb832e802cc) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 22 April 2022, 10:02:08 UTC |
| d3fd4d4 | Bruce Robbins | 22 April 2022, 03:30:34 UTC | [SPARK-38990][SQL] Avoid `NullPointerException` when evaluating date_trunc/trunc format as a bound reference ### What changes were proposed in this pull request? Change `TruncInstant.evalHelper` to pass the input row to `format.eval` when `format` is a not a literal (and therefore might be a bound reference). ### Why are the changes needed? This query fails with a `java.lang.NullPointerException`: ``` select date_trunc(col1, col2) from values ('week', timestamp'2012-01-01') as data(col1, col2); ``` This only happens if the data comes from an inline table. When the source is an inline table, `ConvertToLocalRelation` attempts to evaluate the function against the data in interpreted mode. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Update to unit tests. Closes #36312 from bersprockets/date_trunc_issue. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 2e4f4abf553cedec1fa8611b9494a01d24e6238a) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 22 April 2022, 03:31:24 UTC |
| 7bf89c3 | Sean Owen | 22 April 2022, 02:26:26 UTC | [MINOR][DOCS] Also remove Google Analytics from Spark release docs, per ASF policy ### What changes were proposed in this pull request? Remove Google Analytics from Spark release docs. See also https://github.com/apache/spark-website/pull/384 ### Why are the changes needed? New ASF privacy policy requirement ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? N/A Closes #36310 from srowen/PrivacyPolicy. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 7a58670e2e68ee4950cf62c2be236e00eb8fc44b) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 22 April 2022, 02:26:54 UTC |
| 3c73106 | sychen | 21 April 2022, 02:34:39 UTC | [SPARK-38936][SQL] Script transform feed thread should have name ### What changes were proposed in this pull request? re-add thread name(`Thread-ScriptTransformation-Feed`). ### Why are the changes needed? Lost feed thread name after [SPARK-32105](https://issues.apache.org/jira/browse/SPARK-32105) refactoring. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? exist UT Closes #36245 from cxzl25/SPARK-38936. Authored-by: sychen <sychen@ctrip.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 4dc12eb54544a12ff7ddf078ca8bcec9471212c3) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 21 April 2022, 02:35:13 UTC |
| fefd54d | Kent Yao | 20 April 2022, 06:38:26 UTC | [SPARK-38922][CORE] TaskLocation.apply throw NullPointerException ### What changes were proposed in this pull request? TaskLocation.apply w/o NULL check may throw NPE and fail job scheduling ``` Caused by: java.lang.NullPointerException at scala.collection.immutable.StringLike$class.stripPrefix(StringLike.scala:155) at scala.collection.immutable.StringOps.stripPrefix(StringOps.scala:29) at org.apache.spark.scheduler.TaskLocation$.apply(TaskLocation.scala:71) at org.apache.spark.scheduler.DAGScheduler$$anonfun$org$apache$spark$scheduler$DAGScheduler$$getPreferredLocsInternal ``` For instance, `org.apache.spark.rdd.HadoopRDD#convertSplitLocationInfo` might generate unexpected `Some(null)` elements where should be replace by `Option.apply` ### Why are the changes needed? fix NPE ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? new tests Closes #36222 from yaooqinn/SPARK-38922. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Kent Yao <yao@apache.org> (cherry picked from commit 33e07f3cd926105c6d28986eb6218f237505549e) Signed-off-by: Kent Yao <yao@apache.org> | 20 April 2022, 06:39:37 UTC |
| c7733d3 | fhygh | 18 April 2022, 15:11:32 UTC | [SPARK-37643][SQL] when charVarcharAsString is true, for char datatype predicate query should skip rpadding rule after add ApplyCharTypePadding rule, when predicate query column data type is char, if column value length is less then defined, will be right-padding, then query will get incorrect result fix query incorrect issue when predicate column data type is char, so in this case when charVarcharAsString is true, we should skip the rpadding rule. before this fix, if we query with char data type for predicate, then we should be careful to set charVarcharAsString to true. add new UT. Closes #36187 from fhygh/charpredicatequery. Authored-by: fhygh <283452027@qq.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit c1ea8b446d00dd0123a0fad93a3e143933419a76) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 18 April 2022, 15:19:33 UTC |
| 95fb780 | Sean Owen | 17 April 2022, 23:54:45 UTC | [SPARK-38816][ML][DOCS] Fix comment about choice of initial factors in ALS ### What changes were proposed in this pull request? Change a comment in ALS code to match impl. The comment refers to taking the absolute value of a Normal(0,1) value, but it doesn't. ### Why are the changes needed? The docs and impl are inconsistent. The current behavior actually seems fine, desirable, so, change the comments. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests Closes #36228 from srowen/SPARK-38816. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit b2b350b1566b8b45c6dba2f79ccbc2dc4e95816d) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 17 April 2022, 23:55:29 UTC |
| 21c7abc | fhygh | 15 April 2022, 11:42:18 UTC | [SPARK-38892][SQL][TESTS] Fix a test case schema assertion of ParquetPartitionDiscoverySuite ### What changes were proposed in this pull request? in ParquetPartitionDiscoverySuite, thare are some assert have no parctical significance. `assert(input.schema.sameType(input.schema))` ### Why are the changes needed? fix this to assert the actual result. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? updated testsuites Closes #36189 from fhygh/assertutfix. Authored-by: fhygh <283452027@qq.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 4835946de2ef71b176da5106e9b6c2706e182722) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 15 April 2022, 11:43:07 UTC |
| 2684762 | Hyukjin Kwon | 07 April 2022, 00:44:36 UTC | Revert "[MINOR][SQL][SS][DOCS] Add varargs to Dataset.observe(String, ..) with a documentation fix" This reverts commit dea607fc6040fc9f252632b6c73d5948ada02a98. | 07 April 2022, 00:44:36 UTC |
| dea607f | Hyukjin Kwon | 06 April 2022, 08:26:17 UTC | [MINOR][SQL][SS][DOCS] Add varargs to Dataset.observe(String, ..) with a documentation fix ### What changes were proposed in this pull request? This PR proposes two minor changes: - Fixes the example at `Dataset.observe(String, ...)` - Adds `varargs` to be consistent with another overloaded version: `Dataset.observe(Observation, ..)` ### Why are the changes needed? To provide a correct example, support Java APIs properly with `varargs` and API consistency. ### Does this PR introduce _any_ user-facing change? Yes, the example is fixed in the documentation. Additionally Java users should be able to use `Dataset.observe(String, ..)` per `varargs`. ### How was this patch tested? Manually tested. CI should verify the changes too. Closes #36084 from HyukjinKwon/minor-docs. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit fb3f380b3834ca24947a82cb8d87efeae6487664) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 06 April 2022, 08:26:56 UTC |
| 1a7b3a4 | Kent Yao | 03 April 2022, 17:30:38 UTC | [SPARK-38446][CORE] Fix deadlock between ExecutorClassLoader and FileDownloadCallback caused by Log4j ### What changes were proposed in this pull request? While `log4j.ignoreTCL/log4j2.ignoreTCL` is false, which is the default, it uses the context ClassLoader for the current Thread, see `org.apache.logging.log4j.util.LoaderUtil.loadClass`. While ExecutorClassLoader try to loadClass through remotely though the FileDownload, if error occurs, we will long on debug level, and `log4j...LoaderUtil` will be blocked by ExecutorClassLoader acquired classloading lock. Fortunately, it only happens when ThresholdFilter's level is `debug`. or we can set `log4j.ignoreTCL/log4j2.ignoreTCL` to true, but I don't know what else it will cause. So in this PR, I simply remove the debug log which cause this deadlock ### Why are the changes needed? fix deadlock ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? https://github.com/apache/incubator-kyuubi/pull/2046#discussion_r821414439, with a ut in kyuubi project, resolved(https://github.com/apache/incubator-kyuubi/actions/runs/1950222737) ### Additional Resources [ut.jstack.txt](https://github.com/apache/spark/files/8206457/ut.jstack.txt) Closes #35765 from yaooqinn/SPARK-38446. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit aef674564ff12e78bd2f30846e3dcb69988249ae) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 03 April 2022, 17:31:10 UTC |
| f677272 | Dereck Li | 01 April 2022, 14:54:11 UTC | [SPARK-38754][SQL][TEST][3.1] Using EquivalentExpressions getEquivalentExprs function instead of getExprState at SubexpressionEliminationSuite ### What changes were proposed in this pull request? This pr use EquivalentExpressions getEquivalentExprs function instead of getExprState at SubexpressionEliminationSuite, and remove cpus paramter. ### Why are the changes needed? Fixes build error ### Does this PR introduce _any_ user-facing change? NO ### How was this patch tested? CI Tests Closes #36033 from monkeyboy123/SPARK-38754. Authored-by: Dereck Li <monkeyboy.ljh@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 01 April 2022, 14:54:11 UTC |
| e12c9e7 | Dereck Li | 31 March 2022, 13:33:08 UTC | [SPARK-38333][SQL] PlanExpression expression should skip addExprTree function in Executor It is master branch pr [SPARK-38333](https://github.com/apache/spark/pull/35662) Bug fix, it is potential issue. No UT Closes #36012 from monkeyboy123/spark-38333. Authored-by: Dereck Li <monkeyboy.ljh@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit a40acd4392a8611062763ce6ec7bc853d401c646) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 31 March 2022, 13:37:22 UTC |
| 4b3f8d4 | Dongjoon Hyun | 30 March 2022, 15:26:41 UTC | [SPARK-38652][K8S] `uploadFileUri` should preserve file scheme ### What changes were proposed in this pull request? This PR replaces `new Path(fileUri.getPath)` with `new Path(fileUri)`. By using `Path` class constructor with URI parameter, we can preserve file scheme. ### Why are the changes needed? If we use, `Path` class constructor with `String` parameter, it loses file scheme information. Although the original code works so far, it fails at Apache Hadoop 3.3.2 and breaks dependency upload feature which is covered by K8s Minikube integration tests. ```scala test("uploadFileUri") { val fileUri = org.apache.spark.util.Utils.resolveURI("/tmp/1.txt") assert(new Path(fileUri).toString == "file:/private/tmp/1.txt") assert(new Path(fileUri.getPath).toString == "/private/tmp/1.txt") } ``` ### Does this PR introduce _any_ user-facing change? No, this will prevent a regression at Apache Spark 3.3.0 instead. ### How was this patch tested? Pass the CIs. In addition, this PR and #36009 will recover K8s IT `DepsTestsSuite`. Closes #36010 from dongjoon-hyun/SPARK-38652. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit cab8aa1c4fe66c4cb1b69112094a203a04758f76) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 30 March 2022, 15:27:20 UTC |
| b3e3110 | Bruce Robbins | 27 March 2022, 00:31:49 UTC | [SPARK-38528][SQL][3.2] Eagerly iterate over aggregate sequence when building project list in `ExtractGenerator` Backport of #35837. When building the project list from an aggregate sequence in `ExtractGenerator`, convert the aggregate sequence to an `IndexedSeq` before performing the flatMap operation. This query fails with a `NullPointerException`: ``` val df = Seq(1, 2, 3).toDF("v") df.select(Stream(explode(array(min($"v"), max($"v"))), sum($"v")): _*).collect ``` If you change `Stream` to `Seq`, then it succeeds. `ExtractGenerator` uses a flatMap operation over `aggList` for two purposes: - To produce a new aggregate list - to update `projectExprs` (which is initialized as an array of nulls). When `aggList` is a `Stream`, the flatMap operation evaluates lazily, so all entries in `projectExprs` after the first will still be null when the rule completes. Changing `aggList` to an `IndexedSeq` forces the flatMap to evaluate eagerly. No New unit test Closes #35851 from bersprockets/generator_aggregate_issue_32. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 7842621ff50001e1cde8e2e6a2fc48c2cdcaf3d4) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 27 March 2022, 00:32:55 UTC |
| 789ec13 | mcdull-zhang | 26 March 2022, 04:48:08 UTC | [SPARK-38570][SQL][3.1] Incorrect DynamicPartitionPruning caused by Literal This is a backport of #35878 to branch 3.1. The return value of Literal.references is an empty AttributeSet, so Literal is mistaken for a partition column. For example, the sql in the test case will generate such a physical plan when the adaptive is closed: ```tex *(4) Project [store_id#5281, date_id#5283, state_province#5292] +- *(4) BroadcastHashJoin [store_id#5281], [store_id#5291], Inner, BuildRight, false :- Union : :- *(1) Project [4 AS store_id#5281, date_id#5283] : : +- *(1) Filter ((isnotnull(date_id#5283) AND (date_id#5283 >= 1300)) AND dynamicpruningexpression(4 IN dynamicpruning#5300)) : : : +- ReusedSubquery SubqueryBroadcast dynamicpruning#5300, 0, [store_id#5291], [id=#336] : : +- *(1) ColumnarToRow : : +- FileScan parquet default.fact_sk[date_id#5283,store_id#5286] Batched: true, DataFilters: [isnotnull(date_id#5283), (date_id#5283 >= 1300)], Format: Parquet, Location: CatalogFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache.s..., PartitionFilters: [dynamicpruningexpression(4 IN dynamicpruning#5300)], PushedFilters: [IsNotNull(date_id), GreaterThanOrEqual(date_id,1300)], ReadSchema: struct<date_id:int> : : +- SubqueryBroadcast dynamicpruning#5300, 0, [store_id#5291], [id=#336] : : +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)),false), [id=#335] : : +- *(1) Project [store_id#5291, state_province#5292] : : +- *(1) Filter (((isnotnull(country#5293) AND (country#5293 = US)) AND ((store_id#5291 <=> 4) OR (store_id#5291 <=> 5))) AND isnotnull(store_id#5291)) : : +- *(1) ColumnarToRow : : +- FileScan parquet default.dim_store[store_id#5291,state_province#5292,country#5293] Batched: true, DataFilters: [isnotnull(country#5293), (country#5293 = US), ((store_id#5291 <=> 4) OR (store_id#5291 <=> 5)), ..., Format: Parquet, Location: InMemoryFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache...., PartitionFilters: [], PushedFilters: [IsNotNull(country), EqualTo(country,US), Or(EqualNullSafe(store_id,4),EqualNullSafe(store_id,5))..., ReadSchema: struct<store_id:int,state_province:string,country:string> : +- *(2) Project [5 AS store_id#5282, date_id#5287] : +- *(2) Filter ((isnotnull(date_id#5287) AND (date_id#5287 <= 1000)) AND dynamicpruningexpression(5 IN dynamicpruning#5300)) : : +- ReusedSubquery SubqueryBroadcast dynamicpruning#5300, 0, [store_id#5291], [id=#336] : +- *(2) ColumnarToRow : +- FileScan parquet default.fact_stats[date_id#5287,store_id#5290] Batched: true, DataFilters: [isnotnull(date_id#5287), (date_id#5287 <= 1000)], Format: Parquet, Location: CatalogFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache.s..., PartitionFilters: [dynamicpruningexpression(5 IN dynamicpruning#5300)], PushedFilters: [IsNotNull(date_id), LessThanOrEqual(date_id,1000)], ReadSchema: struct<date_id:int> : +- ReusedSubquery SubqueryBroadcast dynamicpruning#5300, 0, [store_id#5291], [id=#336] +- ReusedExchange [store_id#5291, state_province#5292], BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)),false), [id=#335] ``` after this pr: ```tex *(4) Project [store_id#5281, date_id#5283, state_province#5292] +- *(4) BroadcastHashJoin [store_id#5281], [store_id#5291], Inner, BuildRight, false :- Union : :- *(1) Project [4 AS store_id#5281, date_id#5283] : : +- *(1) Filter (isnotnull(date_id#5283) AND (date_id#5283 >= 1300)) : : +- *(1) ColumnarToRow : : +- FileScan parquet default.fact_sk[date_id#5283,store_id#5286] Batched: true, DataFilters: [isnotnull(date_id#5283), (date_id#5283 >= 1300)], Format: Parquet, Location: CatalogFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache.s..., PartitionFilters: [], PushedFilters: [IsNotNull(date_id), GreaterThanOrEqual(date_id,1300)], ReadSchema: struct<date_id:int> : +- *(2) Project [5 AS store_id#5282, date_id#5287] : +- *(2) Filter (isnotnull(date_id#5287) AND (date_id#5287 <= 1000)) : +- *(2) ColumnarToRow : +- FileScan parquet default.fact_stats[date_id#5287,store_id#5290] Batched: true, DataFilters: [isnotnull(date_id#5287), (date_id#5287 <= 1000)], Format: Parquet, Location: CatalogFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache.s..., PartitionFilters: [], PushedFilters: [IsNotNull(date_id), LessThanOrEqual(date_id,1000)], ReadSchema: struct<date_id:int> +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)),false), [id=#326] +- *(3) Project [store_id#5291, state_province#5292] +- *(3) Filter (((isnotnull(country#5293) AND (country#5293 = US)) AND ((store_id#5291 <=> 4) OR (store_id#5291 <=> 5))) AND isnotnull(store_id#5291)) +- *(3) ColumnarToRow +- FileScan parquet default.dim_store[store_id#5291,state_province#5292,country#5293] Batched: true, DataFilters: [isnotnull(country#5293), (country#5293 = US), ((store_id#5291 <=> 4) OR (store_id#5291 <=> 5)), ..., Format: Parquet, Location: InMemoryFileIndex(1 paths)[file:/Users/dongdongzhang/code/study/spark/spark-warehouse/org.apache...., PartitionFilters: [], PushedFilters: [IsNotNull(country), EqualTo(country,US), Or(EqualNullSafe(store_id,4),EqualNullSafe(store_id,5))..., ReadSchema: struct<store_id:int,state_province:string,country:string> ``` Execution performance improvement No Added unit test Closes #35967 from mcdull-zhang/spark_38570_3.2. Authored-by: mcdull-zhang <work4dong@163.com> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit 8621914e2052eeab25e6ac4e7d5f48b5570c71f7) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 26 March 2022, 05:27:25 UTC |
| b0b226e | Hyukjin Kwon | 24 March 2022, 03:12:38 UTC | [SPARK-38631][CORE] Uses Java-based implementation for un-tarring at Utils.unpack ### What changes were proposed in this pull request? This PR proposes to use `FileUtil.unTarUsingJava` that is a Java implementation for un-tar `.tar` files. `unTarUsingJava` is not public but it exists in all Hadoop versions from 2.1+, see HADOOP-9264. The security issue reproduction requires a non-Windows platform, and a non-gzipped TAR archive file name (contents don't matter). ### Why are the changes needed? There is a risk for arbitrary shell command injection via `Utils.unpack` when the filename is controlled by a malicious user. This is due to an issue in Hadoop's `unTar`, that is not properly escaping the filename before passing to a shell command:https://github.com/apache/hadoop/blob/trunk/hadoop-common-project/hadoop-common/src/main/java/org/apache/hadoop/fs/FileUtil.java#L904 ### Does this PR introduce _any_ user-facing change? Yes, it prevents a security issue that, previously, allowed users to execute arbitrary shall command. ### How was this patch tested? Manually tested in local, and existing test cases should cover. Closes #35946 from HyukjinKwon/SPARK-38631. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 057c051285ec32c665fb458d0670c1c16ba536b2) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 24 March 2022, 03:13:11 UTC |
| 43c6b91 | Kent Yao | 23 March 2022, 09:25:47 UTC | resolve conflicts | 23 March 2022, 09:31:06 UTC |
| 25ac5fc | huangmaoyang2 | 23 March 2022, 06:06:58 UTC | [SPARK-38629][SQL][DOCS] Two links beneath Spark SQL Guide/Data Sources do not work properly SPARK-38629 Two links beneath Spark SQL Guide/Data Sources do not work properly ### What changes were proposed in this pull request? Two typos have been corrected in sql-data-sources.md under Spark's docs directory. ### Why are the changes needed? Two links under latest documentation [Spark SQL Guide/Data Sources](https://spark.apache.org/docs/latest/sql-data-sources.html) do not work properly, when click 'Ignore Corrupt File' or 'Ignore Missing Files', it does redirect me to the right page, but does not scroll to the right section. This issue actually has been there since v3.0.0. ### Does this PR introduce _any_ user-facing change? Yes ### How was this patch tested? I've built the documentation locally and tested my change. Closes #35944 from morvenhuang/SPARK-38629. Authored-by: huangmaoyang2 <huangmaoyang1@jd.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit ac9ae98011424a030a6ef264caf077b8873e251d) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 23 March 2022, 06:07:34 UTC |
| 674feec | Yimin | 22 March 2022, 10:24:12 UTC | [SPARK-38579][SQL][WEBUI] Requesting Restful API can cause NullPointerException ### What changes were proposed in this pull request? Added null check for `exec.metricValues`. ### Why are the changes needed? When requesting Restful API {baseURL}/api/v1/applications/$appId/sql/$executionId which is introduced by this PR https://github.com/apache/spark/pull/28208, it can cause NullPointerException. The root cause is, when calling method doUpdate() of `LiveExecutionData`, `metricsValues` can be null. Then, when statement `printableMetrics(graph.allNodes, exec.metricValues)` is executed, it will throw NullPointerException. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Tested manually. Closes #35884 from yym1995/fix-npe. Lead-authored-by: Yimin <yimin.y@outlook.com> Co-authored-by: Yimin Yang <26797163+yym1995@users.noreply.github.com> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit 99992a4e050a00564049be6938f5734876c17518) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 22 March 2022, 10:25:33 UTC |
| 7a607b7 | Dongjoon Hyun | 13 March 2022, 03:33:23 UTC | [SPARK-38538][K8S][TESTS] Fix driver environment verification in BasicDriverFeatureStepSuite ### What changes were proposed in this pull request? This PR aims to fix the driver environment verification logic in `BasicDriverFeatureStepSuite`. ### Why are the changes needed? When SPARK-25876 added a test logic at Apache Spark 3.0.0, it used `envs(v) === v` instead of `envs(k) === v`. https://github.com/apache/spark/blob/c032928515e74367137c668ce692d8fd53696485/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/deploy/k8s/features/BasicDriverFeatureStepSuite.scala#L94-L96 This bug was hidden because the test key-value pairs have identical set. If we have different strings for keys and values, the test case fails. https://github.com/apache/spark/blob/c032928515e74367137c668ce692d8fd53696485/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/deploy/k8s/features/BasicDriverFeatureStepSuite.scala#L42-L44 ### Does this PR introduce _any_ user-facing change? To have a correct test coverage. ### How was this patch tested? Pass the CIs. Closes #35828 from dongjoon-hyun/SPARK-38538. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit 6becf4e93e68e36fbcdc82768de497d86072abeb) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 13 March 2022, 03:34:22 UTC |
| 968dd47 | Jungtaek Lim | 09 March 2022, 02:03:57 UTC | [SPARK-38412][SS] Fix the swapped sequence of from and to in StateSchemaCompatibilityChecker ### What changes were proposed in this pull request? This PR fixes the StateSchemaCompatibilityChecker which mistakenly swapped `from` (should be provided schema) and `to` (should be existing schema). ### Why are the changes needed? The bug mistakenly allows the case where it should not be allowed, and disallows the case where it should be allowed. That allows nullable column to be stored into non-nullable column, which should be prohibited. This is less likely making runtime problem since state schema is conceptual one and row can be stored even not respecting the state schema. The opposite case is worse, that disallows non-nullable column to be stored into nullable column, which should be allowed. Spark fails the query for this case. ### Does this PR introduce _any_ user-facing change? Yes, after the fix, storing non-nullable column into nullable column for state will be allowed, which should have been allowed. ### How was this patch tested? Modified UTs. Closes #35731 from HeartSaVioR/SPARK-38412. Authored-by: Jungtaek Lim <kabhwan.opensource@gmail.com> Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com> (cherry picked from commit 43c7824bba40ebfb64dcd50d8d0e84b5a4d3c8c7) Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com> | 09 March 2022, 02:22:22 UTC |
| 0496173 | Karen Feng | 09 March 2022, 01:34:01 UTC | [SPARK-37865][SQL] Fix union deduplication correctness bug Fixes a correctness bug in `Union` in the case that there are duplicate output columns. Previously, duplicate columns on one side of the union would result in a duplicate column being output on the other side of the union. To do so, we go through the union’s child’s output and find the duplicates. For each duplicate set, there is a first duplicate: this one is left alone. All following duplicates are aliased and given a tag; this tag is used to remove ambiguity during resolution. As the first duplicate is left alone, the user can still select it, avoiding a breaking change. As the later duplicates are given new expression IDs, this fixes the correctness bug. Output of union with duplicate columns in the children was incorrect Example query: ``` SELECT a, a FROM VALUES (1, 1), (1, 2) AS t1(a, b) UNION ALL SELECT c, d FROM VALUES (2, 2), (2, 3) AS t2(c, d) ``` Result before: ``` a | a _ | _ 1 | 1 1 | 1 2 | 2 2 | 2 ``` Result after: ``` a | a _ | _ 1 | 1 1 | 1 2 | 2 2 | 3 ``` Unit tests Closes #35760 from karenfeng/spark-37865. Authored-by: Karen Feng <karen.feng@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 59ce0a706cb52a54244a747d0a070b61f5cddd1c) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 09 March 2022, 01:36:41 UTC |
| 0277139 | Rob Reeves | 08 March 2022, 18:20:43 UTC | [SPARK-38309][CORE] Fix SHS `shuffleTotalReads` and `shuffleTotalBlocks` percentile metrics ### What changes were proposed in this pull request? #### Background In PR #26508 (SPARK-26260) the SHS stage metric percentiles were updated to only include successful tasks when using disk storage. It did this by making the values for each metric negative when the task is not in a successful state. This approach was chosen to avoid breaking changes to disk storage. See [this comment](https://github.com/apache/spark/pull/26508#issuecomment-554540314) for context. To get the percentiles, it reads the metric values, starting at 0, in ascending order. This filters out all tasks that are not successful because the values are less than 0. To get the percentile values it scales the percentiles to the list index of successful tasks. For example if there are 200 tasks and you want percentiles [0, 25, 50, 75, 100] the lookup indexes in the task collection are [0, 50, 100, 150, 199]. #### Issue For metrics 1) shuffle total reads and 2) shuffle total blocks, PR #26508 incorrectly makes the metric indices positive. This means tasks that are not successful are included in the percentile calculations. The percentile lookup index calculation is still based on the number of successful task so the wrong task metric is returned for a given percentile. This was not caught because the unit test only verified values for one metric, `executorRunTime`. #### Fix The index values for `SHUFFLE_TOTAL_READS` and `SHUFFLE_TOTAL_BLOCKS` should not convert back to positive metric values for tasks that are not successful. I believe this was done because the metrics values are summed from two other metrics. Using the raw values still creates the desired outcome. `negative + negative = negative` and `positive + positive = positive`. There is no case where one metric will be negative and one will be positive. I also verified that these two metrics are only used in the percentile calculations where only successful tasks are used. ### Why are the changes needed? This change is required so that the SHS stage percentile metrics for shuffle read bytes and shuffle total blocks are correct. ### Does this PR introduce _any_ user-facing change? Yes. The user will see the correct percentile values for the stage summary shuffle read bytes. ### How was this patch tested? I updated the unit test to verify the percentile values for every task metric. I also modified the unit test to have unique values for every metric. Previously the test had the same metrics for every field. This would not catch bugs like the wrong field being read by accident. I manually validated the fix in the UI. **BEFORE**  **AFTER**  I manually validated the fix in the task summary API (`/api/v1/applications/application_123/1/stages/14/0/taskSummary\?quantiles\=0,0.25,0.5,0.75,1.0`). See `shuffleReadMetrics.readBytes` and `shuffleReadMetrics.totalBlocksFetched`. Before: ```json { "quantiles":[ 0.0, 0.25, 0.5, 0.75, 1.0 ], "shuffleReadMetrics":{ "readBytes":[ -2.0, -2.0, -2.0, -2.0, 5.63718681E8 ], "totalBlocksFetched":[ -2.0, -2.0, -2.0, -2.0, 2.0 ], ... }, ... } ``` After: ```json { "quantiles":[ 0.0, 0.25, 0.5, 0.75, 1.0 ], "shuffleReadMetrics":{ "readBytes":[ 5.62865286E8, 5.63779421E8, 5.63941681E8, 5.64327925E8, 5.7674183E8 ], "totalBlocksFetched":[ 2.0, 2.0, 2.0, 2.0, 2.0 ], ... } ... } ``` Closes #35637 from robreeves/SPARK-38309. Authored-by: Rob Reeves <roreeves@linkedin.com> Signed-off-by: Mridul Muralidharan <mridul<at>gmail.com> (cherry picked from commit 0ad76777e76f60d1aea0eed0a2a7bff20c7567d3) Signed-off-by: Mridul Muralidharan <mridulatgmail.com> | 08 March 2022, 18:24:12 UTC |
| 8d70d5d | Cheng Pan | 06 March 2022, 23:41:20 UTC | [SPARK-38411][CORE] Use `UTF-8` when `doMergeApplicationListingInternal` reads event logs ### What changes were proposed in this pull request? Use UTF-8 instead of system default encoding to read event log ### Why are the changes needed? After SPARK-29160, we should always use UTF-8 to read event log, otherwise, if Spark History Server run with different default charset than "UTF-8", will encounter such error. ``` 2022-03-04 12:16:00,143 [3752440] - INFO [log-replay-executor-19:Logging57] - Parsing hdfs://hz-cluster11/spark2-history/application_1640597251469_2453817_1.lz4 for listing data... 2022-03-04 12:16:00,145 [3752442] - ERROR [log-replay-executor-18:Logging94] - Exception while merging application listings java.nio.charset.MalformedInputException: Input length = 1 at java.nio.charset.CoderResult.throwException(CoderResult.java:281) at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:339) at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:178) at java.io.InputStreamReader.read(InputStreamReader.java:184) at java.io.BufferedReader.fill(BufferedReader.java:161) at java.io.BufferedReader.readLine(BufferedReader.java:324) at java.io.BufferedReader.readLine(BufferedReader.java:389) at scala.io.BufferedSource$BufferedLineIterator.hasNext(BufferedSource.scala:74) at scala.collection.Iterator$$anon$20.hasNext(Iterator.scala:884) at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:511) at org.apache.spark.scheduler.ReplayListenerBus.replay(ReplayListenerBus.scala:82) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$doMergeApplicationListing$4(FsHistoryProvider.scala:819) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$doMergeApplicationListing$4$adapted(FsHistoryProvider.scala:801) at org.apache.spark.util.Utils$.tryWithResource(Utils.scala:2626) at org.apache.spark.deploy.history.FsHistoryProvider.doMergeApplicationListing(FsHistoryProvider.scala:801) at org.apache.spark.deploy.history.FsHistoryProvider.mergeApplicationListing(FsHistoryProvider.scala:715) at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$checkForLogs$15(FsHistoryProvider.scala:581) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) ``` ### Does this PR introduce _any_ user-facing change? Yes, bug fix. ### How was this patch tested? Verification steps in ubuntu:20.04 1. build `spark-3.3.0-SNAPSHOT-bin-master.tgz` on commit `34618a7ef6` using `dev/make-distribution.sh --tgz --name master` 2. build `spark-3.3.0-SNAPSHOT-bin-SPARK-38411.tgz` on commit `2a8f56038b` using `dev/make-distribution.sh --tgz --name SPARK-38411` 3. switch to UTF-8 using `export LC_ALL=C.UTF-8 && bash` 4. generate event log contains no-ASCII chars. ``` bin/spark-submit \ --master local[*] \ --class org.apache.spark.examples.SparkPi \ --conf spark.eventLog.enabled=true \ --conf spark.user.key='计算圆周率' \ examples/jars/spark-examples_2.12-3.3.0-SNAPSHOT.jar ``` 5. switch to POSIX using `export LC_ALL=POSIX && bash` 6. run `spark-3.3.0-SNAPSHOT-bin-master/sbin/start-history-server.sh` and watch logs <details> ``` Spark Command: /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java -cp /spark-3.3.0-SNAPSHOT-bin-master/conf/:/spark-3.3.0-SNAPSHOT-bin-master/jars/* -Xmx1g org.apache.spark.deploy.history.HistoryServer ======================================== Using Spark's default log4j profile: org/apache/spark/log4j2-defaults.properties 22/03/06 13:37:19 INFO HistoryServer: Started daemon with process name: 48729c3ffc10aa9 22/03/06 13:37:19 INFO SignalUtils: Registering signal handler for TERM 22/03/06 13:37:19 INFO SignalUtils: Registering signal handler for HUP 22/03/06 13:37:19 INFO SignalUtils: Registering signal handler for INT 22/03/06 13:37:21 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 22/03/06 13:37:21 INFO SecurityManager: Changing view acls to: root 22/03/06 13:37:21 INFO SecurityManager: Changing modify acls to: root 22/03/06 13:37:21 INFO SecurityManager: Changing view acls groups to: 22/03/06 13:37:21 INFO SecurityManager: Changing modify acls groups to: 22/03/06 13:37:21 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set() 22/03/06 13:37:21 INFO FsHistoryProvider: History server ui acls disabled; users with admin permissions: ; groups with admin permissions: 22/03/06 13:37:22 INFO Utils: Successfully started service 'HistoryServerUI' on port 18080. 22/03/06 13:37:23 INFO HistoryServer: Bound HistoryServer to 0.0.0.0, and started at http://29c3ffc10aa9:18080 22/03/06 13:37:23 INFO FsHistoryProvider: Parsing file:/tmp/spark-events/local-1646573251839 for listing data... 22/03/06 13:37:25 ERROR FsHistoryProvider: Exception while merging application listings java.nio.charset.MalformedInputException: Input length = 1 at java.nio.charset.CoderResult.throwException(CoderResult.java:281) ~[?:1.8.0_312] at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:339) ~[?:1.8.0_312] at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:178) ~[?:1.8.0_312] at java.io.InputStreamReader.read(InputStreamReader.java:184) ~[?:1.8.0_312] at java.io.BufferedReader.fill(BufferedReader.java:161) ~[?:1.8.0_312] at java.io.BufferedReader.readLine(BufferedReader.java:324) ~[?:1.8.0_312] at java.io.BufferedReader.readLine(BufferedReader.java:389) ~[?:1.8.0_312] at scala.io.BufferedSource$BufferedLineIterator.hasNext(BufferedSource.scala:74) ~[scala-library-2.12.15.jar:?] at scala.collection.Iterator$$anon$20.hasNext(Iterator.scala:886) ~[scala-library-2.12.15.jar:?] at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:513) ~[scala-library-2.12.15.jar:?] at org.apache.spark.scheduler.ReplayListenerBus.replay(ReplayListenerBus.scala:82) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$doMergeApplicationListingInternal$4(FsHistoryProvider.scala:830) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$doMergeApplicationListingInternal$4$adapted(FsHistoryProvider.scala:812) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.util.Utils$.tryWithResource(Utils.scala:2738) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.doMergeApplicationListingInternal(FsHistoryProvider.scala:812) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.doMergeApplicationListing(FsHistoryProvider.scala:758) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.mergeApplicationListing(FsHistoryProvider.scala:718) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at org.apache.spark.deploy.history.FsHistoryProvider.$anonfun$checkForLogs$15(FsHistoryProvider.scala:584) ~[spark-core_2.12-3.3.0-SNAPSHOT.jar:3.3.0-SNAPSHOT] at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) [?:1.8.0_312] at java.util.concurrent.FutureTask.run(FutureTask.java:266) [?:1.8.0_312] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_312] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_312] at java.lang.Thread.run(Thread.java:748) [?:1.8.0_312] ``` </details> 7. run `spark-3.3.0-SNAPSHOT-bin-master/sbin/stop-history-server.sh` 8. run `spark-3.3.0-SNAPSHOT-bin-SPARK-38411/sbin/stop-history-server.sh` and watch logs <details> ``` Spark Command: /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java -cp /spark-3.3.0-SNAPSHOT-bin-SPARK-38411/conf/:/spark-3.3.0-SNAPSHOT-bin-SPARK-38411/jars/* -Xmx1g org.apache.spark.deploy.history.HistoryServer ======================================== Using Spark's default log4j profile: org/apache/spark/log4j2-defaults.properties 22/03/06 13:30:54 INFO HistoryServer: Started daemon with process name: 34729c3ffc10aa9 22/03/06 13:30:54 INFO SignalUtils: Registering signal handler for TERM 22/03/06 13:30:54 INFO SignalUtils: Registering signal handler for HUP 22/03/06 13:30:54 INFO SignalUtils: Registering signal handler for INT 22/03/06 13:30:55 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 22/03/06 13:30:56 INFO SecurityManager: Changing view acls to: root 22/03/06 13:30:56 INFO SecurityManager: Changing modify acls to: root 22/03/06 13:30:56 INFO SecurityManager: Changing view acls groups to: 22/03/06 13:30:56 INFO SecurityManager: Changing modify acls groups to: 22/03/06 13:30:56 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set() 22/03/06 13:30:56 INFO FsHistoryProvider: History server ui acls disabled; users with admin permissions: ; groups with admin permissions: 22/03/06 13:30:57 INFO Utils: Successfully started service 'HistoryServerUI' on port 18080. 22/03/06 13:30:57 INFO HistoryServer: Bound HistoryServer to 0.0.0.0, and started at http://29c3ffc10aa9:18080 22/03/06 13:30:57 INFO FsHistoryProvider: Parsing file:/tmp/spark-events/local-1646573251839 for listing data... 22/03/06 13:30:59 INFO FsHistoryProvider: Finished parsing file:/tmp/spark-events/local-1646573251839 ``` </details> Closes #35730 from pan3793/SPARK-38411. Authored-by: Cheng Pan <chengpan@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 135841f257fbb008aef211a5e38222940849cb26) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 06 March 2022, 23:41:47 UTC |
| 8889bf0 | attilapiros | 03 March 2022, 18:37:54 UTC | [SPARK-33206][CORE][3.1] Fix shuffle index cache weight calculation for small index files ### What changes were proposed in this pull request? Increasing the shuffle index weight with a constant number to avoid underestimating retained memory size caused by the bookkeeping objects: the `java.io.File` (depending on the path ~ 960 bytes) object and the `ShuffleIndexInformation` object (~180 bytes). ### Why are the changes needed? Underestimating cache entry size easily can cause OOM in the Yarn NodeManager. In the following analyses of a prod issue (HPROF file) we can see the leak suspect Guava's `LocalCache$Segment` objects: <img width="943" alt="Screenshot 2022-02-17 at 18 55 40" src="https://user-images.githubusercontent.com/2017933/154541995-44014212-2046-41d6-ba7f-99369ca7d739.png"> Going further we can see a `ShuffleIndexInformation` for a small index file (16 bytes) but the retained heap memory is 1192 bytes: <img width="1351" alt="image" src="https://user-images.githubusercontent.com/2017933/154645212-e0318d0f-cefa-4ae3-8a3b-97d2b506757d.png"> Finally we can see this is very common within this heap dump (using MAT's Object Query Language): <img width="1418" alt="image" src="https://user-images.githubusercontent.com/2017933/154547678-44c8af34-1765-4e14-b71a-dc03d1a304aa.png"> I have even exported the data to a CSV and done some calculations with `awk`: ``` $ tail -n+2 export.csv | awk -F, 'BEGIN { numUnderEstimated=0; } { sumOldSize += $1; corrected=$1 + 1176; sumCorrectedSize += corrected; sumRetainedMem += $2; if (corrected < $2) numUnderEstimated+=1; } END { print "sum old size: " sumOldSize / 1024 / 1024 " MB, sum corrected size: " sumCorrectedSize / 1024 / 1024 " MB, sum retained memory:" sumRetainedMem / 1024 / 1024 " MB, num under estimated: " numUnderEstimated }' ``` It gives the followings: ``` sum old size: 76.8785 MB, sum corrected size: 1066.93 MB, sum retained memory:1064.47 MB, num under estimated: 0 ``` So using the old calculation we were at 7.6.8 MB way under the default cache limit (100 MB). Using the correction (applying 1176 as increment to the size) we are at 1066.93 MB (~1GB) which is close to the real retained sum heap: 1064.47 MB (~1GB) and there is no entry which was underestimated. But we can go further and get rid of `java.io.File` completely and store the `ShuffleIndexInformation` for the file path. This way not only the cache size estimate is improved but the its size is decreased as well. Here the path size is not counted into the cache size as that string is interned. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? With the calculations above. Closes #35720 from attilapiros/SPARK-33206-3.1. Authored-by: attilapiros <piros.attila.zsolt@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 03 March 2022, 18:37:54 UTC |
| 6ec3045 | Yuming Wang | 02 March 2022, 19:57:38 UTC | [MINOR][SQL][DOCS] Add more examples to sql-ref-syntax-ddl-create-table-datasource ### What changes were proposed in this pull request? Add more examples to sql-ref-syntax-ddl-create-table-datasource: 1. Create partitioned and bucketed table through CTAS. 2. Create bucketed table through CTAS and CTE ### Why are the changes needed? Improve doc. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manual test. Closes #35712 from wangyum/sql-ref-syntax-ddl-create-table-datasource. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: huaxingao <huaxin_gao@apple.com> (cherry picked from commit 829d7fb045e47f1ddd43f2645949ea8257ca330d) Signed-off-by: huaxingao <huaxin_gao@apple.com> | 02 March 2022, 19:58:30 UTC |
| 357d3b2 | Ruifeng Zheng | 02 March 2022, 19:51:06 UTC | [SPARK-36553][ML] KMeans avoid compute auxiliary statistics for large K ### What changes were proposed in this pull request? SPARK-31007 introduce an auxiliary statistics to speed up computation in KMeasn. However, it needs a array of size `k * (k + 1) / 2`, which may cause overflow or OOM when k is too large. So we should skip this optimization in this case. ### Why are the changes needed? avoid overflow or OOM when k is too large (like 50,000) ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? existing testsuites Closes #35457 from zhengruifeng/kmean_k_limit. Authored-by: Ruifeng Zheng <ruifengz@foxmail.com> Signed-off-by: huaxingao <huaxin_gao@apple.com> (cherry picked from commit ad5427ebe644fc01a9b4c19a48f902f584245edf) Signed-off-by: huaxingao <huaxin_gao@apple.com> | 02 March 2022, 19:52:19 UTC |
| 3b1bdeb | Dongjoon Hyun | 02 March 2022, 06:27:18 UTC | Revert "[SPARK-37090][BUILD][3.1] Upgrade libthrift to 0.16.0 to avoid security vulnerabilities" This reverts commit d7b0567d40e040d3c49089d88f635d66c06adbe0. | 02 March 2022, 06:27:18 UTC |
| 1e1f6b2 | allisonwang-db | 01 March 2022, 07:13:50 UTC | [SPARK-38180][SQL][3.1] Allow safe up-cast expressions in correlated equality predicates Backport https://github.com/apache/spark/pull/35486 to branch-3.1. ### What changes were proposed in this pull request? This PR relaxes the constraint added in [SPARK-35080](https://issues.apache.org/jira/browse/SPARK-35080) by allowing safe up-cast expressions in correlated equality predicates. ### Why are the changes needed? Cast expressions are often added by the compiler during query analysis. Correlated equality predicates can be less restrictive to support this common pattern if a cast expression guarantees one-to-one mapping between the child expression and the output datatype (safe up-cast). ### Does this PR introduce _any_ user-facing change? Yes. Safe up-cast expressions are allowed in correlated equality predicates: ```sql SELECT (SELECT SUM(b) FROM VALUES (1, 1), (1, 2) t(a, b) WHERE CAST(a AS STRING) = x) FROM VALUES ('1'), ('2') t(x) ``` Before this change, this query will throw AnalysisException "Correlated column is not allowed in predicate...", and after this change, this query can run successfully. ### How was this patch tested? Unit tests. Closes #35689 from allisonwang-db/spark-38180-3.1. Authored-by: allisonwang-db <allison.wang@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 01 March 2022, 07:13:50 UTC |
| d7b0567 | Yuming Wang | 26 February 2022, 15:26:11 UTC | [SPARK-37090][BUILD][3.1] Upgrade libthrift to 0.16.0 to avoid security vulnerabilities This is a backport of https://github.com/apache/spark/pull/34362 to branch 3.1. ### What changes were proposed in this pull request? This PR ported HIVE-21498, HIVE-25098 and upgraded libthrift to 0.16.0. The CHANGES list for libthrift 0.16.0 is available at: https://github.com/apache/thrift/blob/v0.16.0/CHANGES.md ### Why are the changes needed? To address [CVE-2020-13949](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-13949). ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing test. Closes #35647 from wangyum/SPARK-37090-branch-3.1. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Sean Owen <srowen@gmail.com> | 26 February 2022, 15:26:11 UTC |
| b98dc38 | Alfonso | 25 February 2022, 14:38:51 UTC | [MINOR][DOCS] Fix missing field in query ### What changes were proposed in this pull request? This PR fixes sql query in doc, let the query confrom to the query result in the following ### Why are the changes needed? Just a fix to doc ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? use project test Closes #35624 from redsnow1992/patch-1. Authored-by: Alfonso <alfonso_men@yahoo.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit daa5f9df4a1c8b3cf5db7142e54b765272c1f24c) Signed-off-by: Sean Owen <srowen@gmail.com> | 25 February 2022, 14:39:09 UTC |
| 82765a8 | Sean Owen | 25 February 2022, 14:34:04 UTC | [SPARK-38305][CORE] Explicitly check if source exists in unpack() before calling FileUtil methods ### What changes were proposed in this pull request? Explicitly check existence of source file in Utils.unpack before calling Hadoop FileUtil methods ### Why are the changes needed? A discussion from the Hadoop community raised a potential issue in calling these methods when a file doesn't exist. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests Closes #35632 from srowen/SPARK-38305. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 64e1f28f1626247cc1361dcb395288227454ca8f) Signed-off-by: Sean Owen <srowen@gmail.com> | 25 February 2022, 14:34:31 UTC |
| 35953cd | Bo Zhang | 24 February 2022, 07:07:38 UTC | [SPARK-38236][SQL][3.2][3.1] Check if table location is absolute by "new Path(locationUri).isAbsolute" in create/alter table ### What changes were proposed in this pull request? After https://github.com/apache/spark/pull/28527, we change to create table under the database location when the table location is relative. However the criteria to determine if a table location is relative/absolute is `URI.isAbsolute`, which basically checks if the table location URI has a scheme defined. So table URIs like `/table/path` are treated as relative and the scheme and authority of the database location URI are used to create the table. For example, when the database location URI is `s3a://bucket/db`, the table will be created at `s3a://bucket/table/path`, while it should be created under the file system defined in `SessionCatalog.hadoopConf` instead. This change fixes that by treating table location as absolute when the first letter of its path is slash. This also applies to alter table. ### Why are the changes needed? This is to fix the behavior described above. ### Does this PR introduce _any_ user-facing change? Yes. When users try to create/alter a table with a location that starts with a slash but without a scheme defined, the table will be created under/altered to the file system defined in `SessionCatalog.hadoopConf`, instead of the one defined in the database location URI. ### How was this patch tested? Updated unit tests. Closes #35591 from bozhang2820/spark-31709-3.2. Authored-by: Bo Zhang <bo.zhang@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 915f0cc5a594da567b9e83fba05a3eb7897c739c) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 24 February 2022, 07:08:08 UTC |
| 687494a | Ruifeng Zheng | 24 February 2022, 02:49:52 UTC | [SPARK-38286][SQL] Union's maxRows and maxRowsPerPartition may overflow check Union's maxRows and maxRowsPerPartition Union's maxRows and maxRowsPerPartition may overflow: case 1: ``` scala> val df1 = spark.range(0, Long.MaxValue, 1, 1) df1: org.apache.spark.sql.Dataset[Long] = [id: bigint] scala> val df2 = spark.range(0, 100, 1, 10) df2: org.apache.spark.sql.Dataset[Long] = [id: bigint] scala> val union = df1.union(df2) union: org.apache.spark.sql.Dataset[Long] = [id: bigint] scala> union.queryExecution.logical.maxRowsPerPartition res19: Option[Long] = Some(-9223372036854775799) scala> union.queryExecution.logical.maxRows res20: Option[Long] = Some(-9223372036854775709) ``` case 2: ``` scala> val n = 2000000 n: Int = 2000000 scala> val df1 = spark.range(0, n, 1, 1).selectExpr("id % 5 as key1", "id as value1") df1: org.apache.spark.sql.DataFrame = [key1: bigint, value1: bigint] scala> val df2 = spark.range(0, n, 1, 2).selectExpr("id % 3 as key2", "id as value2") df2: org.apache.spark.sql.DataFrame = [key2: bigint, value2: bigint] scala> val df3 = spark.range(0, n, 1, 3).selectExpr("id % 4 as key3", "id as value3") df3: org.apache.spark.sql.DataFrame = [key3: bigint, value3: bigint] scala> val joined = df1.join(df2, col("key1") === col("key2")).join(df3, col("key1") === col("key3")) joined: org.apache.spark.sql.DataFrame = [key1: bigint, value1: bigint ... 4 more fields] scala> val unioned = joined.select(col("key1"), col("value3")).union(joined.select(col("key1"), col("value2"))) unioned: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [key1: bigint, value3: bigint] scala> unioned.queryExecution.optimizedPlan.maxRows res32: Option[Long] = Some(-2446744073709551616) scala> unioned.queryExecution.optimizedPlan.maxRows res33: Option[Long] = Some(-2446744073709551616) ``` No added testsuite Closes #35609 from zhengruifeng/union_maxRows_validate. Authored-by: Ruifeng Zheng <ruifengz@foxmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 683bc46ff9a791ab6b9cd3cb95be6bbc368121e0) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 24 February 2022, 02:52:48 UTC |
| 337bc56 | itholic | 22 February 2022, 07:41:16 UTC | [SPARK-38279][TESTS][3.2] Pin MarkupSafe to 2.0.1 fix linter failure This PR proposes to pin the Python package `markupsafe` to 2.0.1 to fix the CI failure as below. ``` ImportError: cannot import name 'soft_unicode' from 'markupsafe' (/home/runner/work/_temp/setup-sam-43osIE/.venv/lib/python3.10/site-packages/markupsafe/__init__.py) ``` Since `markupsafe==2.1.0` has removed `soft_unicode`, `from markupsafe import soft_unicode` no longer working properly. See https://github.com/aws/aws-sam-cli/issues/3661 for more detail. To fix the CI failure on branch-3.2 No. The existing tests are should be passed Closes #35602 from itholic/SPARK-38279. Authored-by: itholic <haejoon.lee@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 79099cf7baf6e094884b5f77e82a4915272f15c5) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 22 February 2022, 07:47:40 UTC |
| adc9c82 | Franck Thang | 22 February 2022, 05:49:32 UTC | [SPARK-37290][SQL] - Exponential planning time in case of non-deterministic function ### What changes were proposed in this pull request? When using non-deterministic function, the method getAllValidConstraints can throw an OOM ``` protected def getAllValidConstraints(projectList: Seq[NamedExpression]): ExpressionSet = { var allConstraints = child.constraints projectList.foreach { case a Alias(l: Literal, _) => allConstraints += EqualNullSafe(a.toAttribute, l) case a Alias(e, _) => // For every alias in `projectList`, replace the reference in constraints by its attribute. allConstraints ++= allConstraints.map(_ transform { case expr: Expression if expr.semanticEquals(e) => a.toAttribute }) allConstraints += EqualNullSafe(e, a.toAttribute) case _ => // Don't change. } allConstraints } ``` In particular, this line `allConstraints ++= allConstraints.map(...)` can generate an exponential number of expressions This is because non deterministic functions are considered unique in a ExpressionSet Therefore, the number of non-deterministic expressions double every time we go through this line We can filter and keep only deterministic expression because 1 - the `semanticEquals` automatically discard non deterministic expressions 2 - this method is only used in one code path, and we keep only determinic expressions ``` lazy val constraints: ExpressionSet = { if (conf.constraintPropagationEnabled) { validConstraints .union(inferAdditionalConstraints(validConstraints)) .union(constructIsNotNullConstraints(validConstraints, output)) .filter { c => c.references.nonEmpty && c.references.subsetOf(outputSet) && c.deterministic } } else { ExpressionSet() } } ``` ### Why are the changes needed? It can lead to an exponential number of expressions and / or OOM ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Local test Closes #35233 from Stelyus/SPARK-37290. Authored-by: Franck Thang <stelyus@outlook.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 881f562f7b6a2bed76b01f956bc02c4b87ad6b80) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 22 February 2022, 05:52:12 UTC |
| ac69643 | Itay Bittan | 20 February 2022, 02:51:53 UTC | [MINOR][DOCS] fix default value of history server ### What changes were proposed in this pull request? Alignment between the documentation and the code. ### Why are the changes needed? The [actual default value ](https://github.com/apache/spark/blame/master/core/src/main/scala/org/apache/spark/internal/config/History.scala#L198) for `spark.history.custom.executor.log.url.applyIncompleteApplication` is `true` and not `false` as stated in the documentation. ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? Closes #35577 from itayB/doc. Authored-by: Itay Bittan <itay.bittan@gmail.com> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit ae67adde4d2dc0a75e03710fc3e66ea253feeda3) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 20 February 2022, 02:53:11 UTC |
| 5dd54f9 | Karthik Subramanian | 18 February 2022, 03:52:11 UTC | [MINOR][DOC] Fix documentation for structured streaming - addListener ### What changes were proposed in this pull request? This PR fixes the incorrect documentation in Structured Streaming Guide where it says `sparkSession.streams.attachListener()` instead of `sparkSession.streams.addListener()` which is the correct usage as mentioned in the code snippet below in the same doc. 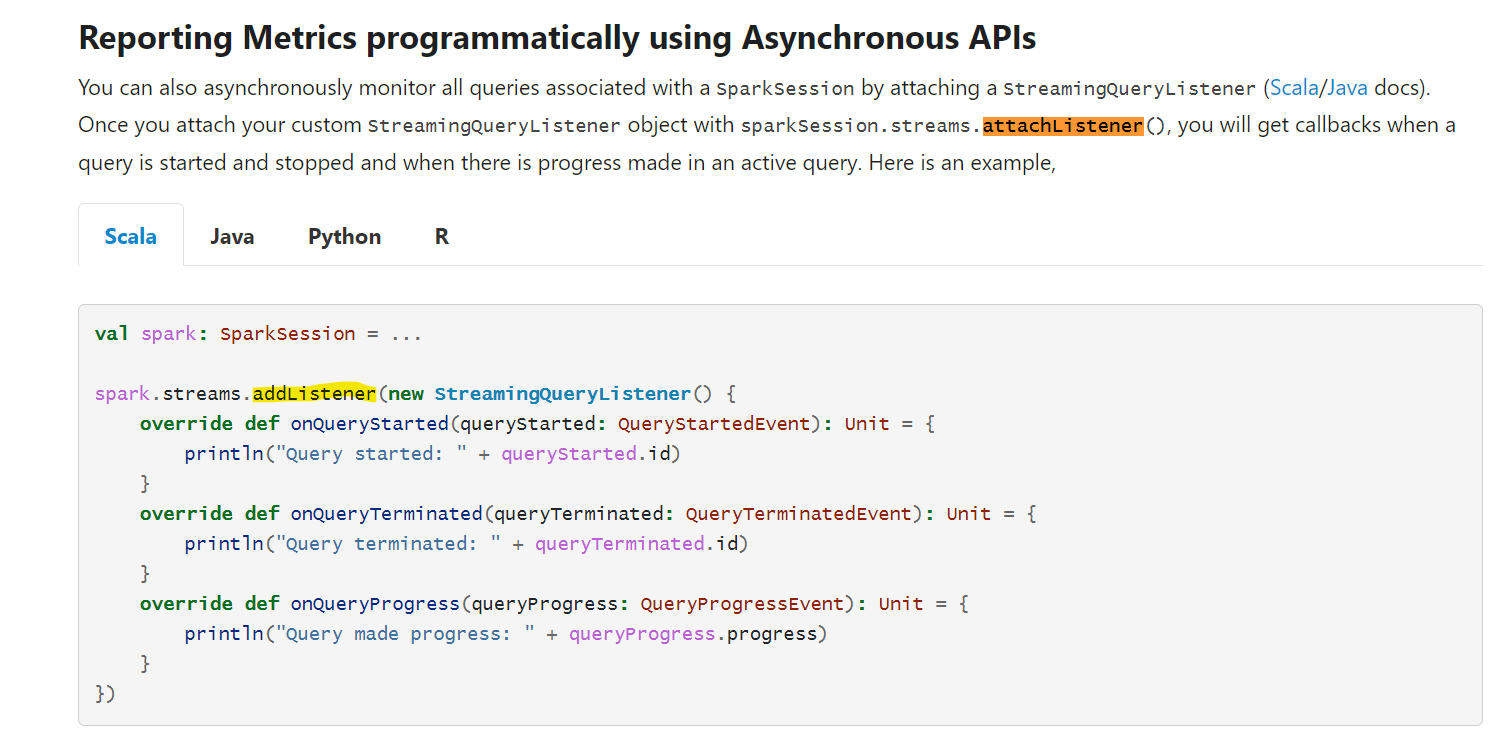 ### Why are the changes needed? The documentation was erroneous, and needs to be fixed to avoid confusion by readers ### Does this PR introduce _any_ user-facing change? Yes, since it's a doc fix. This fix needs to be applied to previous versions retro-actively as well. ### How was this patch tested? Not necessary Closes #35562 from yeskarthik/fix-structured-streaming-docs-1. Authored-by: Karthik Subramanian <karsubr@microsoft.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 837248a0c42d55ad48240647d503ad544e64f016) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 18 February 2022, 03:53:18 UTC |
| d1ca91c | tianlzhang | 15 February 2022, 03:52:37 UTC | [SPARK-38211][SQL][DOCS] Add SQL migration guide on restoring loose upcast from string to other types ### What changes were proposed in this pull request? Add doc on restoring loose upcast from string to other types (behavior before 2.4.1) to SQL migration guide. ### Why are the changes needed? After [SPARK-24586](https://issues.apache.org/jira/browse/SPARK-24586), loose upcasting from string to other types are not allowed by default. User can still set `spark.sql.legacy.looseUpcast=true` to restore old behavior but it's not documented. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Only doc change. Closes #35519 from manuzhang/spark-38211. Authored-by: tianlzhang <tianlzhang@ebay.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 78514e3149bc43b2485e4be0ab982601a842600b) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 15 February 2022, 03:53:04 UTC |
| 4098d26 | Angerszhuuuu | 10 February 2022, 13:55:58 UTC | [SPARK-35531][SQL][3.1] Directly pass hive Table to HiveClient when call getPartitions to avoid unnecessary convert from HiveTable -> CatalogTable -> HiveTable ### What changes were proposed in this pull request? In current `HiveexternalCatalog.listpartitions`, it use ``` final def getPartitions( db: String, table: String, partialSpec: Option[TablePartitionSpec]): Seq[CatalogTablePartition] = { getPartitions(getTable(db, table), partialSpec) } ``` It call `geTables` to get a raw HiveTable then convert it to a CatalogTable, in `getPartitions` it re-convert it to a HiveTable. This cause a conflicts since in HiveTable we store schema as lowercase but for bucket cols and sort cols it didn't convert it to lowercase. In this pr, we directly pass raw HiveTable to HiveClient's request to avoid unnecessary convert and potential conflicts, also respect case sensitivity. ### Why are the changes needed? When user create a hive bucket table with upper case schema, the table schema will be stored as lower cases while bucket column info will stay the same with user input. if we try to insert into this table, an HiveException reports bucket column is not in table schema. here is a simple repro ``` spark.sql(""" CREATE TABLE TEST1( V1 BIGINT, S1 INT) PARTITIONED BY (PK BIGINT) CLUSTERED BY (V1) SORTED BY (S1) INTO 200 BUCKETS STORED AS PARQUET """).show spark.sql("INSERT INTO TEST1 SELECT * FROM VALUES(1,1,1)").show ``` Error message: ``` scala> spark.sql("INSERT INTO TEST1 SELECT * FROM VALUES(1,1,1)").show org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: Bucket columns V1 is not part of the table columns ([FieldSchema(name:v1, type:bigint, comment:null), FieldSchema(name:s1, type:int, comment:null)] at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:112) at org.apache.spark.sql.hive.HiveExternalCatalog.listPartitions(HiveExternalCatalog.scala:1242) at org.apache.spark.sql.catalyst.catalog.ExternalCatalogWithListener.listPartitions(ExternalCatalogWithListener.scala:254) at org.apache.spark.sql.catalyst.catalog.SessionCatalog.listPartitions(SessionCatalog.scala:1166) at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.run(InsertIntoHadoopFsRelationCommand.scala:103) at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:108) at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:106) at org.apache.spark.sql.execution.command.DataWritingCommandExec.executeCollect(commands.scala:120) at org.apache.spark.sql.Dataset.$anonfun$logicalPlan$1(Dataset.scala:228) at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3687) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:103) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64) at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3685) at org.apache.spark.sql.Dataset.<init>(Dataset.scala:228) at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:99) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772) at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:96) at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:615) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772) at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:610) ... 47 elided Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: Bucket columns V1 is not part of the table columns ([FieldSchema(name:v1, type:bigint, comment:null), FieldSchema(name:s1, type:int, comment:null)] at org.apache.hadoop.hive.ql.metadata.Table.setBucketCols(Table.java:552) at org.apache.spark.sql.hive.client.HiveClientImpl$.toHiveTable(HiveClientImpl.scala:1082) at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$getPartitions$1(HiveClientImpl.scala:732) at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$withHiveState$1(HiveClientImpl.scala:291) at org.apache.spark.sql.hive.client.HiveClientImpl.liftedTree1$1(HiveClientImpl.scala:224) at org.apache.spark.sql.hive.client.HiveClientImpl.retryLocked(HiveClientImpl.scala:223) at org.apache.spark.sql.hive.client.HiveClientImpl.withHiveState(HiveClientImpl.scala:273) at org.apache.spark.sql.hive.client.HiveClientImpl.getPartitions(HiveClientImpl.scala:731) at org.apache.spark.sql.hive.client.HiveClient.getPartitions(HiveClient.scala:222) at org.apache.spark.sql.hive.client.HiveClient.getPartitions$(HiveClient.scala:218) at org.apache.spark.sql.hive.client.HiveClientImpl.getPartitions(HiveClientImpl.scala:91) at org.apache.spark.sql.hive.HiveExternalCatalog.$anonfun$listPartitions$1(HiveExternalCatalog.scala:1245) at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:102) ... 69 more ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? UT Closes #35475 from AngersZhuuuu/SPARK-35531-3.1. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 10 February 2022, 13:55:58 UTC |
| 851ebad | Dongjoon Hyun | 09 February 2022, 21:20:46 UTC | [SPARK-38151][SQL][TESTS] Handle `Pacific/Kanton` in DateTimeUtilsSuite ### What changes were proposed in this pull request? This PR aims to fix the flaky UT failures due to https://bugs.openjdk.java.net/browse/JDK-8274407 (`Update Timezone Data to 2021c`) and its backport commits that renamed 'Pacific/Enderbury' to 'Pacific/Kanton' in the latest Java `17.0.2`, `11.0.14`, and `8u311`. ``` Rename Pacific/Enderbury to Pacific/Kanton. ``` ### Why are the changes needed? The flaky failures were observed twice in `GitHub Action` environment like the following. **MASTER** - https://github.com/dongjoon-hyun/spark/runs/5119322349?check_suite_focus=true ``` [info] - daysToMicros and microsToDays *** FAILED *** (620 milliseconds) [info] 9131 did not equal 9130 Round trip of 9130 did not work in tz Pacific/Kanton (DateTimeUtilsSuite.scala:783) ``` **BRANCH-3.2** - https://github.com/apache/spark/runs/5122380604?check_suite_focus=true ``` [info] - daysToMicros and microsToDays *** FAILED *** (643 milliseconds) [info] 9131 did not equal 9130 Round trip of 9130 did not work in tz Pacific/Kanton (DateTimeUtilsSuite.scala:771) ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass the CIs Closes #35468 from dongjoon-hyun/SPARK-38151. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 4dde01fc5b0ed44fd6c5ad8da093650931e4dcd4) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 09 February 2022, 21:21:05 UTC |
| 47de971 | kuwii | 09 February 2022, 17:53:11 UTC | [SPARK-38056][WEB UI][3.1] Fix issue of Structured streaming not working in history server when using LevelDB ### What changes were proposed in this pull request? Change type of `org.apache.spark.sql.streaming.ui.StreamingQueryData.runId` from `UUID` to `String`. ### Why are the changes needed? In [SPARK-31953](https://github.com/apache/spark/commit/4f9667035886a67e6c9a4e8fad2efa390e87ca68), structured streaming support is added in history server. However this does not work when history server is using LevelDB instead of in-memory KV store. - Level DB does not support `UUID` as key. - If `spark.history.store.path` is set in history server to use Level DB, when writing info to the store during replaying events, error will occur. - `StreamingQueryStatusListener` will throw exceptions when writing info, saying `java.lang.IllegalArgumentException: Type java.util.UUID not allowed as key.`. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Added tests in `StreamingQueryStatusListenerSuite` to test whether `StreamingQueryData` can be successfully written to in-memory store and LevelDB. Closes #35463 from kuwii/hs-streaming-fix-3.1. Authored-by: kuwii <kuwii.someone@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 09 February 2022, 17:53:11 UTC |
| e120a53 | khalidmammadov | 09 February 2022, 08:54:31 UTC | [SPARK-38120][SQL] Fix HiveExternalCatalog.listPartitions when partition column name is upper case and dot in partition value ### What changes were proposed in this pull request? HiveExternalCatalog.listPartitions method call is failing when a partition column name is upper case and partition value contains dot. It's related to this change https://github.com/apache/spark/commit/f18b905f6cace7686ef169fda7de474079d0af23 The test case in that PR does not produce the issue as partition column name is lower case. This change will lowercase the partition column name during comparison to produce expected result, it's is inline with the actual spec transformation i.e. making it lower case for Hive and using the same function Below how to reproduce the issue: ``` Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 1.8.0_312) Type in expressions to have them evaluated. Type :help for more information. scala> import org.apache.spark.sql.catalyst.TableIdentifier import org.apache.spark.sql.catalyst.TableIdentifier scala> spark.sql("CREATE TABLE customer(id INT, name STRING) PARTITIONED BY (partCol1 STRING, partCol2 STRING)") 22/02/06 21:10:45 WARN ResolveSessionCatalog: A Hive serde table will be created as there is no table provider specified. You can set spark.sql.legacy.createHiveTableByDefault to false so that native data source table will be created instead. res0: org.apache.spark.sql.DataFrame = [] scala> spark.sql("INSERT INTO customer PARTITION (partCol1 = 'CA', partCol2 = 'i.j') VALUES (100, 'John')") res1: org.apache.spark.sql.DataFrame = [] scala> spark.sessionState.catalog.listPartitions(TableIdentifier("customer"), Some(Map("partCol2" -> "i.j"))).foreach(println) java.util.NoSuchElementException: key not found: partcol2 at scala.collection.immutable.Map$Map2.apply(Map.scala:227) at org.apache.spark.sql.catalyst.catalog.ExternalCatalogUtils$.$anonfun$isPartialPartitionSpec$1(ExternalCatalogUtils.scala:205) at org.apache.spark.sql.catalyst.catalog.ExternalCatalogUtils$.$anonfun$isPartialPartitionSpec$1$adapted(ExternalCatalogUtils.scala:202) at scala.collection.immutable.Map$Map1.forall(Map.scala:196) at org.apache.spark.sql.catalyst.catalog.ExternalCatalogUtils$.isPartialPartitionSpec(ExternalCatalogUtils.scala:202) at org.apache.spark.sql.hive.HiveExternalCatalog.$anonfun$listPartitions$6(HiveExternalCatalog.scala:1312) at org.apache.spark.sql.hive.HiveExternalCatalog.$anonfun$listPartitions$6$adapted(HiveExternalCatalog.scala:1312) at scala.collection.TraversableLike.$anonfun$filterImpl$1(TraversableLike.scala:304) at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62) at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49) at scala.collection.TraversableLike.filterImpl(TraversableLike.scala:303) at scala.collection.TraversableLike.filterImpl$(TraversableLike.scala:297) at scala.collection.AbstractTraversable.filterImpl(Traversable.scala:108) at scala.collection.TraversableLike.filter(TraversableLike.scala:395) at scala.collection.TraversableLike.filter$(TraversableLike.scala:395) at scala.collection.AbstractTraversable.filter(Traversable.scala:108) at org.apache.spark.sql.hive.HiveExternalCatalog.$anonfun$listPartitions$1(HiveExternalCatalog.scala:1312) at org.apache.spark.sql.hive.HiveExternalCatalog.withClientWrappingException(HiveExternalCatalog.scala:114) at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:103) at org.apache.spark.sql.hive.HiveExternalCatalog.listPartitions(HiveExternalCatalog.scala:1296) at org.apache.spark.sql.catalyst.catalog.ExternalCatalogWithListener.listPartitions(ExternalCatalogWithListener.scala:254) at org.apache.spark.sql.catalyst.catalog.SessionCatalog.listPartitions(SessionCatalog.scala:1251) ... 47 elided *******AFTER FIX********* scala> import org.apache.spark.sql.catalyst.TableIdentifier import org.apache.spark.sql.catalyst.TableIdentifier scala> spark.sql("CREATE TABLE customer(id INT, name STRING) PARTITIONED BY (partCol1 STRING, partCol2 STRING)") 22/02/06 22:08:11 WARN ResolveSessionCatalog: A Hive serde table will be created as there is no table provider specified. You can set spark.sql.legacy.createHiveTableByDefault to false so that native data source table will be created instead. res1: org.apache.spark.sql.DataFrame = [] scala> spark.sql("INSERT INTO customer PARTITION (partCol1 = 'CA', partCol2 = 'i.j') VALUES (100, 'John')") res2: org.apache.spark.sql.DataFrame = [] scala> spark.sessionState.catalog.listPartitions(TableIdentifier("customer"), Some(Map("partCol2" -> "i.j"))).foreach(println) CatalogPartition( Partition Values: [partCol1=CA, partCol2=i.j] Location: file:/home/khalid/dev/oss/test/spark-warehouse/customer/partcol1=CA/partcol2=i.j Serde Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe InputFormat: org.apache.hadoop.mapred.TextInputFormat OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat Storage Properties: [serialization.format=1] Partition Parameters: {rawDataSize=0, numFiles=1, transient_lastDdlTime=1644185314, totalSize=9, COLUMN_STATS_ACCURATE={"BASIC_STATS":"true"}, numRows=0} Created Time: Sun Feb 06 22:08:34 GMT 2022 Last Access: UNKNOWN Partition Statistics: 9 bytes) ``` ### Why are the changes needed? It fixes the bug ### Does this PR introduce _any_ user-facing change? Yes ### How was this patch tested? `build/sbt -v -d "test:testOnly *CatalogSuite"` Closes #35409 from khalidmammadov/fix_list_partitions_bug2. Authored-by: khalidmammadov <xmamedov@hotmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 2ba8a4e263933e7500cbc7c38badb6cb059803c9) Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 4b1ff1180c740294d834e829451f8e4fc78668d6) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 09 February 2022, 17:30:18 UTC |
| 66e73c4 | Shardul Mahadik | 09 February 2022, 03:20:24 UTC | [SPARK-38030][SQL][3.1] Canonicalization should not remove nullability of AttributeReference dataType This is a backport of https://github.com/apache/spark/pull/35332 to branch 3.1 ### What changes were proposed in this pull request? Canonicalization of AttributeReference should not remove nullability information of its dataType. ### Why are the changes needed? SPARK-38030 lists an issue where canonicalization of cast resulted in an unresolved expression, thus causing query failure. The issue was that the child AttributeReference's dataType was converted to nullable during canonicalization and hence the Cast's `checkInputDataTypes` fails. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added unit test to ensure that canonicalization preserves nullability of AttributeReference and does not result in an unresolved cast. Also added a test to ensure that the issue observed in SPARK-38030 (interaction of this bug with AQE) is fixed. This test/repro only works on 3.1 because the code which triggers access on an unresolved object is [lazy](https://github.com/apache/spark/blob/7e5c3b216431b6a5e9a0786bf7cded694228cdee/sql/core/src/main/scala/org/apache/spark/sql/execution/exchange/ShuffleExchangeExec.scala#L132) in 3.2+ and hence does not trigger the issue in 3.2+. Closes #35444 from shardulm94/SPARK-38030-3.1. Authored-by: Shardul Mahadik <smahadik@linkedin.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 09 February 2022, 03:20:24 UTC |