https://github.com/apache/spark
- HEAD
- refs/heads/branch-0.5
- refs/heads/branch-0.6
- refs/heads/branch-0.7
- refs/heads/branch-0.8
- refs/heads/branch-0.9
- refs/heads/branch-1.0
- refs/heads/branch-1.0-jdbc
- refs/heads/branch-1.1
- refs/heads/branch-1.2
- refs/heads/branch-1.3
- refs/heads/branch-1.4
- refs/heads/branch-1.5
- refs/heads/branch-1.6
- refs/heads/branch-2.0
- refs/heads/branch-2.1
- refs/heads/branch-2.2
- refs/heads/branch-2.3
- refs/heads/branch-2.4
- refs/heads/branch-3.0
- refs/heads/branch-3.1
- refs/heads/branch-3.2
- refs/heads/branch-3.3
- refs/heads/branch-3.4
- refs/heads/branch-3.5
- refs/heads/master
- refs/remotes/origin/branch-0.8
- refs/remotes/origin/td-rdd-save
- refs/tags/0.3-scala-2.8
- refs/tags/0.3-scala-2.9
- refs/tags/2.0.0-preview
- refs/tags/alpha-0.1
- refs/tags/alpha-0.2
- refs/tags/v0.5.0
- refs/tags/v0.5.1
- refs/tags/v0.5.2
- refs/tags/v0.6.0
- refs/tags/v0.6.0-yarn
- refs/tags/v0.6.1
- refs/tags/v0.6.2
- refs/tags/v0.7.0
- refs/tags/v0.7.0-bizo-1
- refs/tags/v0.7.1
- refs/tags/v0.7.2
- refs/tags/v0.9.1
- refs/tags/v0.9.2
- refs/tags/v1.0.0
- refs/tags/v1.0.1
- refs/tags/v1.0.2
- refs/tags/v1.1.0
- refs/tags/v1.1.1
- refs/tags/v1.2.0
- refs/tags/v1.2.1
- refs/tags/v1.2.2
- refs/tags/v1.3.0
- refs/tags/v1.3.1
- refs/tags/v1.4.0
- refs/tags/v1.4.1
- refs/tags/v1.5.0-rc1
- refs/tags/v1.5.0-rc2
- refs/tags/v1.5.0-rc3
- refs/tags/v1.5.1
- refs/tags/v1.6.0
- refs/tags/v1.6.1
- refs/tags/v1.6.2
- refs/tags/v1.6.3
- refs/tags/v2.0.0
- refs/tags/v2.0.1
- refs/tags/v2.0.2
- refs/tags/v2.1.0
- refs/tags/v2.1.1
- refs/tags/v2.1.2
- refs/tags/v2.1.2-rc1
- refs/tags/v2.1.2-rc2
- refs/tags/v2.1.2-rc3
- refs/tags/v2.1.2-rc4
- refs/tags/v2.1.3
- refs/tags/v2.1.3-rc1
- refs/tags/v2.1.3-rc2
- refs/tags/v2.2.0
- refs/tags/v2.2.1
- refs/tags/v2.2.1-rc1
- refs/tags/v2.2.1-rc2
- refs/tags/v2.2.2
- refs/tags/v2.2.2-rc1
- refs/tags/v2.2.2-rc2
- refs/tags/v2.2.3
- refs/tags/v2.2.3-rc1
- refs/tags/v2.3.0
- refs/tags/v2.3.0-rc1
- refs/tags/v2.3.0-rc2
- refs/tags/v2.3.0-rc3
- refs/tags/v2.3.0-rc4
- refs/tags/v2.3.1
- refs/tags/v2.3.1-rc1
- refs/tags/v2.3.1-rc2
- refs/tags/v2.3.1-rc3
- refs/tags/v2.3.1-rc4
- refs/tags/v2.3.2
- refs/tags/v2.3.2-rc1
- refs/tags/v2.3.2-rc2
- refs/tags/v2.3.2-rc3
- refs/tags/v2.3.2-rc4
- refs/tags/v2.3.2-rc5
- refs/tags/v2.3.2-rc6
- refs/tags/v2.3.3
- refs/tags/v2.3.3-rc1
- refs/tags/v2.3.3-rc2
- refs/tags/v2.3.4
- refs/tags/v2.3.4-rc1
- refs/tags/v2.4.0
- refs/tags/v2.4.0-rc1
- refs/tags/v2.4.0-rc2
- refs/tags/v2.4.0-rc3
- refs/tags/v2.4.0-rc4
- refs/tags/v2.4.0-rc5
- refs/tags/v2.4.1
- refs/tags/v2.4.1-rc1
- refs/tags/v2.4.1-rc2
- refs/tags/v2.4.1-rc3
- refs/tags/v2.4.1-rc4
- refs/tags/v2.4.1-rc5
- refs/tags/v2.4.1-rc6
- refs/tags/v2.4.1-rc7
- refs/tags/v2.4.1-rc8
- refs/tags/v2.4.1-rc9
- refs/tags/v2.4.2
- refs/tags/v2.4.2-rc1
- refs/tags/v2.4.3
- refs/tags/v2.4.3-rc1
- refs/tags/v2.4.4
- refs/tags/v2.4.4-rc1
- refs/tags/v2.4.4-rc2
- refs/tags/v2.4.4-rc3
- refs/tags/v2.4.5
- refs/tags/v2.4.5-rc1
- refs/tags/v2.4.5-rc2
- refs/tags/v2.4.6
- refs/tags/v2.4.6-rc1
- refs/tags/v2.4.6-rc2
- refs/tags/v2.4.6-rc3
- refs/tags/v2.4.6-rc4
- refs/tags/v2.4.6-rc5
- refs/tags/v2.4.6-rc6
- refs/tags/v2.4.6-rc7
- refs/tags/v2.4.6-rc8
- refs/tags/v2.4.7
- refs/tags/v2.4.7-rc1
- refs/tags/v2.4.7-rc2
- refs/tags/v2.4.7-rc3
- refs/tags/v2.4.8
- refs/tags/v2.4.8-rc1
- refs/tags/v2.4.8-rc2
- refs/tags/v2.4.8-rc3
- refs/tags/v2.4.8-rc4
- refs/tags/v3.0.0
- refs/tags/v3.0.0-preview2
- refs/tags/v3.0.0-preview2-rc1
- refs/tags/v3.0.0-preview2-rc2
- refs/tags/v3.0.0-rc1
- refs/tags/v3.0.0-rc2
- refs/tags/v3.0.0-rc3
- refs/tags/v3.0.1
- refs/tags/v3.0.1-rc1
- refs/tags/v3.0.1-rc2
- refs/tags/v3.0.1-rc3
- refs/tags/v3.0.2
- refs/tags/v3.0.2-rc1
- refs/tags/v3.0.3
- refs/tags/v3.0.3-rc1
- refs/tags/v3.1.0-rc1
- refs/tags/v3.1.1
- refs/tags/v3.1.1-rc1
- refs/tags/v3.1.1-rc2
- refs/tags/v3.1.1-rc3
- refs/tags/v3.1.2
- refs/tags/v3.1.2-rc1
- refs/tags/v3.1.3
- refs/tags/v3.1.3-rc1
- refs/tags/v3.1.3-rc2
- refs/tags/v3.1.3-rc3
- refs/tags/v3.1.3-rc4
- refs/tags/v3.2.0
- refs/tags/v3.2.0-rc1
- refs/tags/v3.2.0-rc2
- refs/tags/v3.2.0-rc3
- refs/tags/v3.2.0-rc4
- refs/tags/v3.2.0-rc5
- refs/tags/v3.2.0-rc6
- refs/tags/v3.2.0-rc7
- refs/tags/v3.2.1
- refs/tags/v3.2.1-rc1
- refs/tags/v3.2.1-rc2
- refs/tags/v3.2.2
- refs/tags/v3.2.2-rc1
- refs/tags/v3.2.3
- refs/tags/v3.2.3-rc1
- refs/tags/v3.2.4
- refs/tags/v3.2.4-rc1
- refs/tags/v3.3.0
- refs/tags/v3.3.0-rc1
- refs/tags/v3.3.0-rc2
- refs/tags/v3.3.0-rc3
- refs/tags/v3.3.0-rc4
- refs/tags/v3.3.0-rc5
- refs/tags/v3.3.0-rc6
- refs/tags/v3.3.1
- refs/tags/v3.3.1-rc1
- refs/tags/v3.3.1-rc2
- refs/tags/v3.3.1-rc3
- refs/tags/v3.3.1-rc4
- refs/tags/v3.3.2
- refs/tags/v3.3.2-rc1
- refs/tags/v3.3.3
- refs/tags/v3.3.3-rc1
- refs/tags/v3.3.4
- refs/tags/v3.3.4-rc1
- refs/tags/v3.4.0
- refs/tags/v3.4.0-rc1
- refs/tags/v3.4.0-rc2
- refs/tags/v3.4.0-rc3
- refs/tags/v3.4.0-rc4
- refs/tags/v3.4.0-rc5
- refs/tags/v3.4.0-rc6
- refs/tags/v3.4.0-rc7
- refs/tags/v3.4.1
- refs/tags/v3.4.1-rc1
- refs/tags/v3.4.2
- refs/tags/v3.4.2-rc1
- refs/tags/v3.4.3
- refs/tags/v3.4.3-rc1
- refs/tags/v3.4.3-rc2
- refs/tags/v3.5.0
- refs/tags/v3.5.0-rc1
- refs/tags/v3.5.0-rc2
- refs/tags/v3.5.0-rc3
- refs/tags/v3.5.0-rc4
- refs/tags/v3.5.0-rc5
- refs/tags/v3.5.1
- refs/tags/v3.5.1-rc1
- refs/tags/v3.5.1-rc2
- refs/tags/v4.0.0-preview1
- refs/tags/v4.0.0-preview1-rc1
- refs/tags/v4.0.0-preview1-rc2
- refs/tags/v4.0.0-preview1-rc3
Take a new snapshot of a software origin
If the archived software origin currently browsed is not synchronized with its upstream version (for instance when new commits have been issued), you can explicitly request Software Heritage to take a new snapshot of it.
Use the form below to proceed. Once a request has been submitted and accepted, it will be processed as soon as possible. You can then check its processing state by visiting this dedicated page.
Processing "take a new snapshot" request ...
Permalinks
To reference or cite the objects present in the Software Heritage archive, permalinks based on SoftWare Hash IDentifiers (SWHIDs) must be used.
Select below a type of object currently browsed in order to display its associated SWHID and permalink.
| Revision | Author | Date | Message | Commit Date |
|---|---|---|---|---|
| e428fe9 | Hyukjin Kwon | 19 September 2023, 05:51:27 UTC | [SPARK-45210][DOCS][3.4] Switch languages consistently across docs for all code snippets (Spark 3.4 and below) ### What changes were proposed in this pull request? This PR proposes to recover the availity of switching languages consistently across docs for all code snippets in Spark 3.4 and below by using the proper class selector in the JQuery. Previously the selector was a string `.nav-link tab_python` which did not comply multiple class selection: https://www.w3.org/TR/CSS21/selector.html#class-html. I assume it worked as a legacy behaviour somewhere. Now it uses the standard way `.nav-link.tab_python`. Note that https://github.com/apache/spark/pull/42657 works because there's only single class assigned (after we refactored the site at https://github.com/apache/spark/pull/40269) ### Why are the changes needed? This is a regression in our documentation site. ### Does this PR introduce _any_ user-facing change? Yes, once you click the language tab, it will apply to the examples in the whole page. ### How was this patch tested? Manually tested after building the site.  ### Was this patch authored or co-authored using generative AI tooling? No. Closes #42989 from HyukjinKwon/SPARK-45210. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 796d8785c61e09d1098350657fd44707763687db) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 19 September 2023, 05:52:08 UTC |
| f67e168 | 余良 | 09 August 2023, 05:46:57 UTC | [SPARK-44581][YARN] Fix the bug that ShutdownHookManager gets wrong UGI from SecurityManager of ApplicationMaster ### What changes were proposed in this pull request? I make the SecurityManager instance a lazy value ### Why are the changes needed? fix the bug in issue [SPARK-44581](https://issues.apache.org/jira/browse/SPARK-44581) **Bug:** In spark3.2 it throws the org.apache.hadoop.security.AccessControlException, but in spark2.4 this hook does not throw exception. I rebuild the hadoop-client-api.jar, and add some debug log before the hadoop shutdown hook is created, and rebuild the spark-yarn.jar to add some debug log when creating the spark shutdown hook manager, here is the screenshot of the log:  We can see from the screenshot, the ShutdownHookManager is initialized before the ApplicationManager create a new ugi. **Reason** The main cause is that ShutdownHook thread is created before we create the ugi in ApplicationMaster. When we set the config key "hadoop.security.credential.provider.path", the ApplicationMaster will try to get a filesystem when generating SSLOptions, and when initialize the filesystem during which it will generate a new thread whose ugi is inherited from the current process (yarn). After this, it will generate a new ugi (SPARK_USER) in ApplicationMaster and execute the doAs() function. Here is the chain of the call: ApplicationMaster.(ApplicationMaster.scala:83) -> org.apache.spark.SecurityManager.(SecurityManager.scala:98) -> org.apache.spark.SSLOptions$.parse(SSLOptions.scala:188) -> org.apache.hadoop.conf.Configuration.getPassword(Configuration.java:2353) -> org.apache.hadoop.conf.Configuration.getPasswordFromCredentialProviders(Configuration.java:2434) -> org.apache.hadoop.security.alias.CredentialProviderFactory.getProviders(CredentialProviderFactory.java:82) ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? I didn't add new UnitTest for this, but I rebuild the package, and runs a program in my cluster, and turns out that the user when I delete the staging file turns to be the same with the SPARK_USER. Closes #42405 from liangyu-1/SPARK-44581. Authored-by: 余良 <yul165@chinaunicom.cn> Signed-off-by: Kent Yao <yao@apache.org> (cherry picked from commit e584ed4ad96a0f0573455511d7be0e9b2afbeb96) Signed-off-by: Kent Yao <yao@apache.org> | 09 August 2023, 05:48:30 UTC |
| 37c2745 | Cheng Pan | 06 May 2023, 14:37:44 UTC | [SPARK-43395][BUILD] Exclude macOS tar extended metadata in make-distribution.sh ### What changes were proposed in this pull request? Add args `--no-mac-metadata --no-xattrs --no-fflags` to `tar` on macOS in `dev/make-distribution.sh` to exclude macOS-specific extended metadata. ### Why are the changes needed? The binary tarball created on macOS includes extended macOS-specific metadata and xattrs, which causes warnings when unarchiving it on Linux. Step to reproduce 1. create tarball on macOS (13.3.1) ``` ➜ apache-spark git:(master) tar --version bsdtar 3.5.3 - libarchive 3.5.3 zlib/1.2.11 liblzma/5.0.5 bz2lib/1.0.8 ``` ``` ➜ apache-spark git:(master) dev/make-distribution.sh --tgz ``` 2. unarchive the binary tarball on Linux (CentOS-7) ``` ➜ ~ tar --version tar (GNU tar) 1.26 Copyright (C) 2011 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>. This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Written by John Gilmore and Jay Fenlason. ``` ``` ➜ ~ tar -xzf spark-3.5.0-SNAPSHOT-bin-3.3.5.tgz tar: Ignoring unknown extended header keyword `SCHILY.fflags' tar: Ignoring unknown extended header keyword `LIBARCHIVE.xattr.com.apple.FinderInfo' ``` ### Does this PR introduce _any_ user-facing change? No, dev only. ### How was this patch tested? Create binary tarball on macOS then unarchive on Linux, warnings disappear after this change. Closes #41074 from pan3793/SPARK-43395. Authored-by: Cheng Pan <chengpan@apache.org> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 2d0240df3c474902e263f67b93fb497ca13da00f) Signed-off-by: Sean Owen <srowen@gmail.com> | 06 May 2023, 14:38:32 UTC |
| d68d46c | Dongjoon Hyun | 09 April 2023, 20:22:29 UTC | Preparing development version 3.2.5-SNAPSHOT | 09 April 2023, 20:22:29 UTC |
| 0ae10ac | Dongjoon Hyun | 09 April 2023, 20:22:25 UTC | Preparing Spark release v3.2.4-rc1 | 09 April 2023, 20:22:25 UTC |
| d9ee508 | Dongjoon Hyun | 07 April 2023, 19:54:05 UTC | [SPARK-43069][BUILD] Use `sbt-eclipse` instead of `sbteclipse-plugin` ### What changes were proposed in this pull request? This PR aims to use `sbt-eclipse` instead of `sbteclipse-plugin`. ### Why are the changes needed? Thanks to SPARK-34959, Apache Spark 3.2+ uses SBT 1.5.0 and we can use `set-eclipse` instead of old `sbteclipse-plugin`. - https://github.com/sbt/sbt-eclipse/releases/tag/6.0.0 ### Does this PR introduce _any_ user-facing change? No, this is a dev-only plugin. ### How was this patch tested? Pass the CIs and manual tests. ``` $ build/sbt eclipse Using /Users/dongjoon/.jenv/versions/1.8 as default JAVA_HOME. Note, this will be overridden by -java-home if it is set. Using SPARK_LOCAL_IP=localhost Attempting to fetch sbt Launching sbt from build/sbt-launch-1.8.2.jar [info] welcome to sbt 1.8.2 (AppleJDK-8.0.302.8.1 Java 1.8.0_302) [info] loading settings for project spark-merge-build from plugins.sbt ... [info] loading project definition from /Users/dongjoon/APACHE/spark-merge/project [info] Updating https://repo1.maven.org/maven2/com/github/sbt/sbt-eclipse_2.12_1.0/6.0.0/sbt-eclipse-6.0.0.pom 100.0% [##########] 2.5 KiB (4.5 KiB / s) ... ``` Closes #40708 from dongjoon-hyun/SPARK-43069. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 9cba5529d1fc3faf6b743a632df751d84ec86a07) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 07 April 2023, 19:54:42 UTC |
| 7773740 | thyecust | 03 April 2023, 13:24:17 UTC | [SPARK-43005][PYSPARK] Fix typo in pyspark/pandas/config.py By comparing compute.isin_limit and plotting.max_rows, `v is v` is likely to be a typo. ### What changes were proposed in this pull request? fix `v is v >= 0` with `v >= 0`. ### Why are the changes needed? By comparing compute.isin_limit and plotting.max_rows, `v is v` is likely to be a typo. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? By GitHub Actions. Closes #40620 from thyecust/patch-2. Authored-by: thyecust <thy@mail.ecust.edu.cn> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 5ac2b0fc024ae499119dfd5ab2ee4d038418c5fd) Signed-off-by: Sean Owen <srowen@gmail.com> | 03 April 2023, 13:24:55 UTC |
| 568fbcf | thyecust | 03 April 2023, 03:36:04 UTC | [SPARK-43004][CORE] Fix typo in ResourceRequest.equals() vendor == vendor is always true, this is likely to be a typo. ### What changes were proposed in this pull request? fix `vendor == vendor` with `that.vendor == vendor`, and `discoveryScript == discoveryScript` with `that.discoveryScript == discoveryScript` ### Why are the changes needed? vendor == vendor is always true, this is likely to be a typo. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? By GitHub Actions. Closes #40622 from thyecust/patch-4. Authored-by: thyecust <thy@mail.ecust.edu.cn> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 52c000ece27c9ef34969a7fb252714588f395926) Signed-off-by: Sean Owen <srowen@gmail.com> | 03 April 2023, 03:36:35 UTC |
| 8488a25 | Xingbo Jiang | 30 March 2023, 22:48:04 UTC | [SPARK-42967][CORE][3.2][3.3][3.4] Fix SparkListenerTaskStart.stageAttemptId when a task is started after the stage is cancelled ### What changes were proposed in this pull request? The PR fixes a bug that SparkListenerTaskStart can have `stageAttemptId = -1` when a task is launched after the stage is cancelled. Actually, we should use the information within `Task` to update the `stageAttemptId` field. ### Why are the changes needed? -1 is not a legal stageAttemptId value, thus it can lead to unexpected problem if a subscriber try to parse the stage information from the SparkListenerTaskStart event. ### Does this PR introduce _any_ user-facing change? No, it's a bugfix. ### How was this patch tested? Manually verified. Closes #40592 from jiangxb1987/SPARK-42967. Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com> Signed-off-by: Gengliang Wang <gengliang@apache.org> (cherry picked from commit 1a6b1770c85f37982b15d261abf9cc6e4be740f4) Signed-off-by: Gengliang Wang <gengliang@apache.org> | 30 March 2023, 22:48:50 UTC |
| 59f0e08 | Cheng Pan | 27 March 2023, 22:31:16 UTC | [SPARK-42906][K8S] Replace a starting digit with `x` in resource name prefix ### What changes were proposed in this pull request? Change the generated resource name prefix to meet K8s requirements > DNS-1035 label must consist of lower case alphanumeric characters or '-', start with an alphabetic character, and end with an alphanumeric character (e.g. 'my-name', or 'abc-123', regex used for validation is '[a-z]([-a-z0-9]*[a-z0-9])?') ### Why are the changes needed? In current implementation, the following app name causes error ``` bin/spark-submit \ --master k8s://https://*.*.*.*:6443 \ --deploy-mode cluster \ --name 你好_187609 \ ... ``` ``` Exception in thread "main" io.fabric8.kubernetes.client.KubernetesClientException: Failure executing: POST at: https://*.*.*.*:6443/api/v1/namespaces/spark/services. Message: Service "187609-f19020870d12c349-driver-svc" is invalid: metadata.name: Invalid value: "187609-f19020870d12c349-driver-svc": a DNS-1035 label must consist of lower case alphanumeric characters or '-', start with an alphabetic character, and end with an alphanumeric character (e.g. 'my-name', or 'abc-123', regex used for validation is '[a-z]([-a-z0-9]*[a-z0-9])?'). ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? New UT. Closes #40533 from pan3793/SPARK-42906. Authored-by: Cheng Pan <chengpan@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 0b9a3017005ccab025b93d7b545412b226d4e63c) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 27 March 2023, 22:31:56 UTC |
| e178b49 | yangjie01 | 27 March 2023, 16:42:40 UTC | [SPARK-42934][BUILD] Add `spark.hadoop.hadoop.security.key.provider.path` to `scalatest-maven-plugin` ### What changes were proposed in this pull request? When testing `OrcEncryptionSuite` using maven, all test suites are always skipped. So this pr add `spark.hadoop.hadoop.security.key.provider.path` to `systemProperties` of `scalatest-maven-plugin` to make `OrcEncryptionSuite` can test by maven. ### Why are the changes needed? Make `OrcEncryptionSuite` can test by maven. ### Does this PR introduce _any_ user-facing change? No, just for maven test ### How was this patch tested? - Pass GitHub Actions - Manual testing: run ``` build/mvn clean install -pl sql/core -DskipTests -am build/mvn test -pl sql/core -Dtest=none -DwildcardSuites=org.apache.spark.sql.execution.datasources.orc.OrcEncryptionSuite ``` **Before** ``` Discovery starting. Discovery completed in 3 seconds, 218 milliseconds. Run starting. Expected test count is: 4 OrcEncryptionSuite: 21:57:58.344 WARN org.apache.hadoop.util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable - Write and read an encrypted file !!! CANCELED !!! [] was empty org.apache.orc.impl.NullKeyProvider5af5d76f doesn't has the test keys. ORC shim is created with old Hadoop libraries (OrcEncryptionSuite.scala:37) - Write and read an encrypted table !!! CANCELED !!! [] was empty org.apache.orc.impl.NullKeyProvider5ad6cc21 doesn't has the test keys. ORC shim is created with old Hadoop libraries (OrcEncryptionSuite.scala:65) - SPARK-35325: Write and read encrypted nested columns !!! CANCELED !!! [] was empty org.apache.orc.impl.NullKeyProvider691124ee doesn't has the test keys. ORC shim is created with old Hadoop libraries (OrcEncryptionSuite.scala:116) - SPARK-35992: Write and read fully-encrypted columns with default masking !!! CANCELED !!! [] was empty org.apache.orc.impl.NullKeyProvider5403799b doesn't has the test keys. ORC shim is created with old Hadoop libraries (OrcEncryptionSuite.scala:166) 21:58:00.035 WARN org.apache.spark.sql.execution.datasources.orc.OrcEncryptionSuite: ===== POSSIBLE THREAD LEAK IN SUITE o.a.s.sql.execution.datasources.orc.OrcEncryptionSuite, threads: rpc-boss-3-1 (daemon=true), shuffle-boss-6-1 (daemon=true) ===== Run completed in 5 seconds, 41 milliseconds. Total number of tests run: 0 Suites: completed 2, aborted 0 Tests: succeeded 0, failed 0, canceled 4, ignored 0, pending 0 No tests were executed. ``` **After** ``` Discovery starting. Discovery completed in 3 seconds, 185 milliseconds. Run starting. Expected test count is: 4 OrcEncryptionSuite: 21:58:46.540 WARN org.apache.hadoop.util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable - Write and read an encrypted file - Write and read an encrypted table - SPARK-35325: Write and read encrypted nested columns - SPARK-35992: Write and read fully-encrypted columns with default masking 21:58:51.933 WARN org.apache.spark.sql.execution.datasources.orc.OrcEncryptionSuite: ===== POSSIBLE THREAD LEAK IN SUITE o.a.s.sql.execution.datasources.orc.OrcEncryptionSuite, threads: rpc-boss-3-1 (daemon=true), shuffle-boss-6-1 (daemon=true) ===== Run completed in 8 seconds, 708 milliseconds. Total number of tests run: 4 Suites: completed 2, aborted 0 Tests: succeeded 4, failed 0, canceled 0, ignored 0, pending 0 All tests passed. ``` Closes #40566 from LuciferYang/SPARK-42934-2. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit a3d9e0ae0f95a55766078da5d0bf0f74f3c3cfc3) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 27 March 2023, 16:43:10 UTC |
| 51e5aa6 | Dongjoon Hyun | 15 March 2023, 07:39:25 UTC | [SPARK-42799][BUILD] Update SBT build `xercesImpl` version to match with `pom.xml` This PR aims to update `XercesImpl` version to `2.12.2` from `2.12.0` in order to match with the version of `pom.xml`. https://github.com/apache/spark/blob/149e020a5ca88b2db9c56a9d48e0c1c896b57069/pom.xml#L1429-L1433 When we updated this version via SPARK-39183, we missed to update `SparkBuild.scala`. - https://github.com/apache/spark/pull/36544 No, this is a dev-only change because the release artifact' dependency is managed by Maven. Pass the CIs. Closes #40431 from dongjoon-hyun/SPARK-42799. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 049aa380b8b1361c2898bc499e64613d329c6f72) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 15 March 2023, 07:42:04 UTC |
| 2cf8f02 | zwangsheng | 14 March 2023, 15:49:13 UTC | [SPARK-42785][K8S][CORE] When spark submit without `--deploy-mode`, avoid facing NPE in Kubernetes Case ### What changes were proposed in this pull request? After https://github.com/apache/spark/pull/37880 when user spark submit without `--deploy-mode XXX` or `–conf spark.submit.deployMode=XXXX`, may face NPE with this code. ### Why are the changes needed? https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala#164 ```scala args.deployMode.equals("client") && ``` Of course, submit without `deployMode` is not allowed and will throw an exception and terminate the application, but we should leave it to the later logic to give the appropriate hint instead of giving a NPE. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? 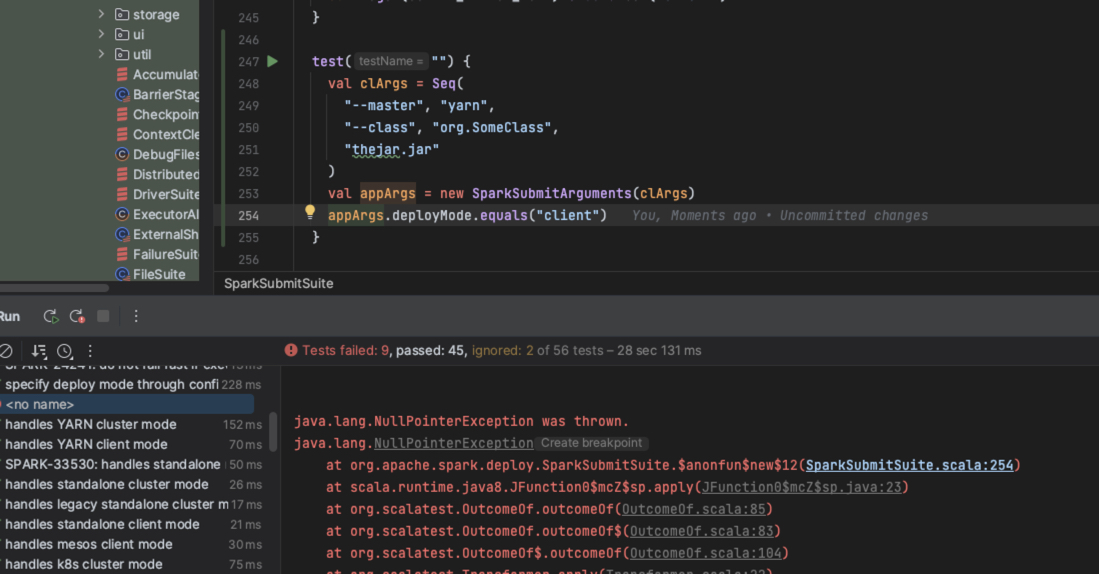 Closes #40414 from zwangsheng/SPARK-42785. Authored-by: zwangsheng <2213335496@qq.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 767253bb6219f775a8a21f1cdd0eb8c25fa0b9de) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 14 March 2023, 15:49:49 UTC |
| 5e14e0a | Ruifeng Zheng | 11 March 2023, 14:45:54 UTC | [SPARK-42747][ML] Fix incorrect internal status of LoR and AFT ### What changes were proposed in this pull request? Add a hook `onParamChange` in `Params.{set, setDefault, clear}`, so that subclass can update the internal status within it. ### Why are the changes needed? In 3.1, we added internal auxiliary variables in LoR and AFT to optimize prediction/transformation. In LoR, when users call `model.{setThreshold, setThresholds}`, the internal status will be correctly updated. But users still can call `model.set(model.threshold, value)`, then the status will not be updated. And when users call `model.clear(model.threshold)`, the status should be updated with default threshold value 0.5. for example: ``` import org.apache.spark.ml.linalg._ import org.apache.spark.ml.classification._ val df = Seq((1.0, 1.0, Vectors.dense(0.0, 5.0)), (0.0, 2.0, Vectors.dense(1.0, 2.0)), (1.0, 3.0, Vectors.dense(2.0, 1.0)), (0.0, 4.0, Vectors.dense(3.0, 3.0))).toDF("label", "weight", "features") val lor = new LogisticRegression().setWeightCol("weight") val model = lor.fit(df) val vec = Vectors.dense(0.0, 5.0) val p0 = model.predict(vec) // return 0.0 model.setThreshold(0.05) // change status val p1 = model.set(model.threshold, 0.5).predict(vec) // return 1.0; but should be 0.0 val p2 = model.clear(model.threshold).predict(vec) // return 1.0; but should be 0.0 ``` what makes it even worse it that `pyspark.ml` always set params via `model.set(model.threshold, value)`, so the internal status is easily out of sync, see the example in [SPARK-42747](https://issues.apache.org/jira/browse/SPARK-42747) ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? added ut Closes #40367 from zhengruifeng/ml_param_hook. Authored-by: Ruifeng Zheng <ruifengz@apache.org> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 5a702f22f49ca6a1b6220ac645e3fce70ec5189d) Signed-off-by: Sean Owen <srowen@gmail.com> | 11 March 2023, 14:46:24 UTC |
| 794d143 | Kent Yao | 09 March 2023, 05:33:43 UTC | [SPARK-42697][WEBUI] Fix /api/v1/applications to return total uptime instead of 0 for the duration field ### What changes were proposed in this pull request? Fix /api/v1/applications to return total uptime instead of 0 for duration ### Why are the changes needed? Fix REST API OneApplicationResource ### Does this PR introduce _any_ user-facing change? yes, /api/v1/applications will return the total uptime instead of 0 for the duration ### How was this patch tested? locally build and run ```json [ { "id" : "local-1678183638394", "name" : "SparkSQL::10.221.102.180", "attempts" : [ { "startTime" : "2023-03-07T10:07:17.754GMT", "endTime" : "1969-12-31T23:59:59.999GMT", "lastUpdated" : "2023-03-07T10:07:17.754GMT", "duration" : 20317, "sparkUser" : "kentyao", "completed" : false, "appSparkVersion" : "3.5.0-SNAPSHOT", "startTimeEpoch" : 1678183637754, "endTimeEpoch" : -1, "lastUpdatedEpoch" : 1678183637754 } ] } ] ``` Closes #40313 from yaooqinn/SPARK-42697. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Kent Yao <yao@apache.org> (cherry picked from commit d3d8fdc2882f5c084897ca9b2af9a063358f3a21) Signed-off-by: Kent Yao <yao@apache.org> | 09 March 2023, 05:34:51 UTC |
| 362ef94 | Shrikant Prasad | 08 March 2023, 03:33:39 UTC | [SPARK-39399][CORE][K8S] Fix proxy-user authentication for Spark on k8s in cluster deploy mode ### What changes were proposed in this pull request? The PR fixes the authentication failure of the proxy user on driver side while accessing kerberized hdfs through spark on k8s job. It follows the similar approach as it was done for Mesos: https://github.com/mesosphere/spark/pull/26 ### Why are the changes needed? When we try to access the kerberized HDFS through a proxy user in Spark Job running in cluster deploy mode with Kubernetes resource manager, we encounter AccessControlException. This is because authentication in driver is done using tokens of the proxy user and since proxy user doesn't have any delegation tokens on driver, auth fails. Further details: https://issues.apache.org/jira/browse/SPARK-25355?focusedCommentId=17532063&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-17532063 https://issues.apache.org/jira/browse/SPARK-25355?focusedCommentId=17532135&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-17532135 ### Does this PR introduce _any_ user-facing change? Yes, user will now be able to use proxy-user to access kerberized hdfs with Spark on K8s. ### How was this patch tested? The patch was tested by: 1. Running job which accesses kerberized hdfs with proxy user in cluster mode and client mode with kubernetes resource manager. 2. Running job which accesses kerberized hdfs without proxy user in cluster mode and client mode with kubernetes resource manager. 3. Build and run test github action : https://github.com/shrprasa/spark/actions/runs/3051203625 Closes #37880 from shrprasa/proxy_user_fix. Authored-by: Shrikant Prasad <shrprasa@visa.com> Signed-off-by: Kent Yao <yao@apache.org> (cherry picked from commit b3b3557ccbe53e34e0d0dbe3d21f49a230ee621b) Signed-off-by: Kent Yao <yao@apache.org> | 08 March 2023, 03:35:16 UTC |
| 954faa4 | Yikf | 06 March 2023, 22:08:08 UTC | [SPARK-42478][SQL][3.2] Make a serializable jobTrackerId instead of a non-serializable JobID in FileWriterFactory This is a backport of https://github.com/apache/spark/pull/40064 for branch-3.2 ### What changes were proposed in this pull request? Make a serializable jobTrackerId instead of a non-serializable JobID in FileWriterFactory ### Why are the changes needed? [SPARK-41448](https://issues.apache.org/jira/browse/SPARK-41448) make consistent MR job IDs in FileBatchWriter and FileFormatWriter, but it breaks a serializable issue, JobId is non-serializable. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? GA Closes #40289 from Yikf/backport-SPARK-42478-3.2. Authored-by: Yikf <yikaifei@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 06 March 2023, 22:08:08 UTC |
| 5a382f1 | yangjie01 | 06 March 2023, 19:05:42 UTC | [SPARK-42673][BUILD] Make `build/mvn` build Spark only with the verified maven version ### What changes were proposed in this pull request? `build/mvn` tends to use the new maven version to build Spark now, and GA starts to use 3.9.0 as the default maven version. But there may be some uncertain factors when building Spark with unverified version. For example, `java-11-17` GA build task build with maven 3.9.0 has many error logs in master like follow: ``` Error: [ERROR] An error occurred attempting to read POM org.codehaus.plexus.util.xml.pull.XmlPullParserException: UTF-8 BOM plus xml decl of ISO-8859-1 is incompatible (position: START_DOCUMENT seen <?xml version="1.0" encoding="ISO-8859-1"... 1:42) at org.codehaus.plexus.util.xml.pull.MXParser.parseXmlDeclWithVersion (MXParser.java:3423) at org.codehaus.plexus.util.xml.pull.MXParser.parseXmlDecl (MXParser.java:3345) at org.codehaus.plexus.util.xml.pull.MXParser.parsePI (MXParser.java:3197) at org.codehaus.plexus.util.xml.pull.MXParser.parseProlog (MXParser.java:1828) at org.codehaus.plexus.util.xml.pull.MXParser.nextImpl (MXParser.java:1757) at org.codehaus.plexus.util.xml.pull.MXParser.next (MXParser.java:1375) at org.apache.maven.model.io.xpp3.MavenXpp3Reader.read (MavenXpp3Reader.java:3940) at org.apache.maven.model.io.xpp3.MavenXpp3Reader.read (MavenXpp3Reader.java:612) at org.apache.maven.model.io.xpp3.MavenXpp3Reader.read (MavenXpp3Reader.java:627) at org.cyclonedx.maven.BaseCycloneDxMojo.readPom (BaseCycloneDxMojo.java:759) at org.cyclonedx.maven.BaseCycloneDxMojo.readPom (BaseCycloneDxMojo.java:746) at org.cyclonedx.maven.BaseCycloneDxMojo.retrieveParentProject (BaseCycloneDxMojo.java:694) at org.cyclonedx.maven.BaseCycloneDxMojo.getClosestMetadata (BaseCycloneDxMojo.java:524) at org.cyclonedx.maven.BaseCycloneDxMojo.convert (BaseCycloneDxMojo.java:481) at org.cyclonedx.maven.CycloneDxMojo.execute (CycloneDxMojo.java:70) at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo (DefaultBuildPluginManager.java:126) at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute2 (MojoExecutor.java:342) at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute (MojoExecutor.java:330) at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:213) at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:175) at org.apache.maven.lifecycle.internal.MojoExecutor.access$000 (MojoExecutor.java:76) at org.apache.maven.lifecycle.internal.MojoExecutor$1.run (MojoExecutor.java:163) at org.apache.maven.plugin.DefaultMojosExecutionStrategy.execute (DefaultMojosExecutionStrategy.java:39) at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:160) at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:105) at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:73) at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:53) at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:118) at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:260) at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:172) at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:100) at org.apache.maven.cli.MavenCli.execute (MavenCli.java:821) at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:270) at org.apache.maven.cli.MavenCli.main (MavenCli.java:192) at jdk.internal.reflect.NativeMethodAccessorImpl.invoke0 (Native Method) at jdk.internal.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:77) at jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke (Method.java:568) at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:282) at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:225) at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:406) at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:347) ``` So this pr change the version check condition of `build/mvn` to make it build Spark only with the verified maven version. ### Why are the changes needed? Make `build/mvn` build Spark only with the verified maven version ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - `java-11-17` GA build task pass and no error message as above - Manual test: 1. Make the system use maven 3.9.0( > 3.8.7 ) by default: run `mvn -version` ``` Apache Maven 3.9.0 (9b58d2bad23a66be161c4664ef21ce219c2c8584) Maven home: /Users/${userName}/Tools/maven Java version: 1.8.0_362, vendor: Azul Systems, Inc., runtime: /Users/${userName}/Tools/zulu8/zulu-8.jdk/Contents/Home/jre Default locale: zh_CN, platform encoding: UTF-8 OS name: "mac os x", version: "13.2.1", arch: "aarch64", family: "mac" ``` and run `build/mvn -version` ``` Using `mvn` from path: /${basedir}/spark/build/apache-maven-3.8.7/bin/mvn Using SPARK_LOCAL_IP=localhost Apache Maven 3.8.7 (b89d5959fcde851dcb1c8946a785a163f14e1e29) Maven home: /${basedir}/spark/build/apache-maven-3.8.7 Java version: 1.8.0_362, vendor: Azul Systems, Inc., runtime: /Users/${userName}/Tools/zulu8/zulu-8.jdk/Contents/Home/jre Default locale: zh_CN, platform encoding: UTF-8 OS name: "mac os x", version: "13.2.1", arch: "aarch64", family: "mac" ``` We can see Spark use 3.8.7 in build directory when the system default maven > 3.8.7 2. Make the system use maven 3.8.7 by default: run `mvn -version` ``` mvn -version Apache Maven 3.8.7 (b89d5959fcde851dcb1c8946a785a163f14e1e29) Maven home: /Users/${userName}/Tools/maven Java version: 1.8.0_362, vendor: Azul Systems, Inc., runtime: /Users/${userName}/Tools/zulu8/zulu-8.jdk/Contents/Home/jre Default locale: zh_CN, platform encoding: UTF-8 OS name: "mac os x", version: "13.2.1", arch: "aarch64", family: "mac" ``` and run `build/mvn -version` ``` Using `mvn` from path: /Users/${userName}/Tools/maven/bin/mvn Using SPARK_LOCAL_IP=localhost Apache Maven 3.8.7 (b89d5959fcde851dcb1c8946a785a163f14e1e29) Maven home: /Users/${userName}/Tools/maven Java version: 1.8.0_362, vendor: Azul Systems, Inc., runtime: /Users/${userName}/Tools/zulu8/zulu-8.jdk/Contents/Home/jre Default locale: zh_CN, platform encoding: UTF-8 OS name: "mac os x", version: "13.2.1", arch: "aarch64", family: "mac" ``` We can see Spark use system default maven 3.8.7 when the system default maven is 3.8.7. 3. Make the system use maven 3.8.6( < 3.8.7 ) by default: run `mvn -version` ``` mvn -version Apache Maven 3.8.6 (84538c9988a25aec085021c365c560670ad80f63) Maven home: /Users/${userName}/Tools/maven Java version: 1.8.0_362, vendor: Azul Systems, Inc., runtime: /Users/${userName}/Tools/zulu8/zulu-8.jdk/Contents/Home/jre Default locale: zh_CN, platform encoding: UTF-8 OS name: "mac os x", version: "13.2.1", arch: "aarch64", family: "mac" ``` and run `build/mvn -version` ``` Using `mvn` from path: /Users/${userName}/Tools/maven/bin/mvn Using SPARK_LOCAL_IP=localhost Apache Maven 3.8.7 (b89d5959fcde851dcb1c8946a785a163f14e1e29) Maven home: /Users/${userName}/Tools/maven Java version: 1.8.0_362, vendor: Azul Systems, Inc., runtime: /Users/${userName}/Tools/zulu8/zulu-8.jdk/Contents/Home/jre Default locale: zh_CN, platform encoding: UTF-8 OS name: "mac os x", version: "13.2.1", arch: "aarch64", family: "mac" ``` We can see Spark use 3.8.7 in build directory when the system default maven < 3.8.7. Closes #40283 from LuciferYang/ban-maven-3.9.x. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit f70b8cf1a00002b6c6b96ec4e6ad4d6c2f0ab392) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 06 March 2023, 19:06:20 UTC |
| 789d891 | Dongjoon Hyun | 02 March 2023, 09:03:32 UTC | [SPARK-42649][CORE] Remove the standard Apache License header from the top of third-party source files This PR aims to remove the standard Apache License header from the top of third-party source files. According to LICENSE file, I found two files. - https://github.com/apache/spark/blob/master/LICENSE This was requested via `devspark` mailing list. - https://lists.apache.org/thread/wfy9sykncw2znhzlvyd18bkyjr7l9x43 Here is the ASF legal policy. - https://www.apache.org/legal/src-headers.html#3party > Do not add the standard Apache License header to the top of third-party source files. No. This is a source code distribution. Manual review. Closes #40249 from dongjoon-hyun/SPARK-42649. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 2c9f67ca5d1bb5de0fe4418ebcf95f2d1a8e3371) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 02 March 2023, 09:05:15 UTC |
| 76b79f8 | John Zhuge | 28 February 2023, 02:19:23 UTC | [SPARK-42596][CORE][YARN] OMP_NUM_THREADS not set to number of executor cores by default ### What changes were proposed in this pull request? The PR fixes a mistake in SPARK-41188 that removed the PythonRunner code setting OMP_NUM_THREADS to number of executor cores by default. That author and reviewers thought it's a duplicate. ### Why are the changes needed? SPARK-41188 stopped setting OMP_NUM_THREADS to number of executor cores by default when running Python UDF on YARN. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Manual testing Closes #40199 from jzhuge/SPARK-42596. Authored-by: John Zhuge <jzhuge@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 43b15b31d26bbf1e539728e6c64aab4eda7ade62) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 28 February 2023, 02:20:02 UTC |
| 358ee49 | Kent Yao | 21 February 2023, 12:07:52 UTC | [MINOR][TESTS] Avoid NPE in an anonym SparkListener in DataFrameReaderWriterSuite ### What changes were proposed in this pull request? Avoid the following NPE in an anonym SparkListener in DataFrameReaderWriterSuite, as job desc may be absent ``` java.lang.NullPointerException at java.util.concurrent.ConcurrentLinkedQueue.checkNotNull(ConcurrentLinkedQueue.java:920) at java.util.concurrent.ConcurrentLinkedQueue.offer(ConcurrentLinkedQueue.java:327) at java.util.concurrent.ConcurrentLinkedQueue.add(ConcurrentLinkedQueue.java:297) at org.apache.spark.sql.test.DataFrameReaderWriterSuite$$anon$2.onJobStart(DataFrameReaderWriterSuite.scala:1151) at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:37) at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28) at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:117) at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:101) at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105) at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105) at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62) at org.apache.spark.scheduler.AsyncEventQueue.org$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100) at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96) at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1462) at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96) ``` ### Why are the changes needed? Test Improvement ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? existing tests Closes #40102 from yaooqinn/test-minor. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 088ebdeea67dd509048a7559f1c92a3636e18ce6) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 21 February 2023, 12:08:59 UTC |
| 0b84da9 | Cheng Pan | 20 February 2023, 17:40:44 UTC | [SPARK-41952][SQL] Fix Parquet zstd off-heap memory leak as a workaround for PARQUET-2160 ### What changes were proposed in this pull request? SPARK-41952 was raised for a while, but unfortunately, the Parquet community does not publish the patched version yet, as a workaround, we can fix the issue on the Spark side first. We encountered this memory issue when migrating data from parquet/snappy to parquet/zstd, Spark executors always occupy unreasonable off-heap memory and have a high risk of being killed by NM. See more discussions at https://github.com/apache/parquet-mr/pull/982 and https://github.com/apache/iceberg/pull/5681 ### Why are the changes needed? The issue is fixed in the parquet community [PARQUET-2160](https://issues.apache.org/jira/browse/PARQUET-2160), but the patched version is not available yet. ### Does this PR introduce _any_ user-facing change? Yes, it's bug fix. ### How was this patch tested? The existing UT should cover the correctness check, I also verified this patch by scanning a large parquet/zstd table. ``` spark-shell --executor-cores 4 --executor-memory 6g --conf spark.executor.memoryOverhead=2g ``` ``` spark.sql("select sum(hash(*)) from parquet_zstd_table ").show(false) ``` - before this patch All executors get killed by NM quickly. ``` ERROR YarnScheduler: Lost executor 1 on hadoop-xxxx.****.org: Container killed by YARN for exceeding physical memory limits. 8.2 GB of 8 GB physical memory used. Consider boosting spark.executor.memoryOverhead. ``` <img width="1872" alt="image" src="https://user-images.githubusercontent.com/26535726/220031678-e9060244-5586-4f0c-8fe7-55bb4e20a580.png"> - after this patch Query runs well, no executor gets killed. <img width="1881" alt="image" src="https://user-images.githubusercontent.com/26535726/220031917-4fe38c07-b38f-49c6-a982-2091a6c2a8ed.png"> Closes #40091 from pan3793/SPARK-41952. Authored-by: Cheng Pan <chengpan@apache.org> Signed-off-by: Chao Sun <sunchao@apple.com> | 20 February 2023, 17:42:30 UTC |
| 9c16785 | Dongjoon Hyun | 16 February 2023, 05:52:17 UTC | [SPARK-42462][K8S] Prevent `docker-image-tool.sh` from publishing OCI manifests ### What changes were proposed in this pull request? This is found during Apache Spark 3.3.2 docker image publishing. It's not an Apache Spark but important for `docker-image-tool.sh` to provide backward compatibility during cross-building. This PR targets for all **future releases**, Apache Spark 3.4.0/3.3.3/3.2.4. ### Why are the changes needed? Docker `buildx` v0.10.0 publishes OCI Manifests by default which is not supported by `docker manifest` command like the following. https://github.com/docker/buildx/issues/1509 ``` $ docker manifest inspect apache/spark:v3.3.2 no such manifest: docker.io/apache/spark:v3.3.2 ``` Note that the published images are working on both AMD64/ARM64 machines, but `docker manifest` cannot be used. For example, we cannot create `latest` tag. ### Does this PR introduce _any_ user-facing change? This will fix the regression of Docker `buildx`. ### How was this patch tested? Manually builds the multi-arch image and check `manifest`. ``` $ docker manifest inspect apache/spark:v3.3.2 { "schemaVersion": 2, "mediaType": "application/vnd.docker.distribution.manifest.list.v2+json", "manifests": [ { "mediaType": "application/vnd.docker.distribution.manifest.v2+json", "size": 3444, "digest": "sha256:30ae5023fc384ae3b68d2fb83adde44b1ece05f926cfceecac44204cdc9e79cb", "platform": { "architecture": "amd64", "os": "linux" } }, { "mediaType": "application/vnd.docker.distribution.manifest.v2+json", "size": 3444, "digest": "sha256:aac13b5b5a681aefa91036d2acae91d30a743c2e78087c6df79af4de46a16e1b", "platform": { "architecture": "arm64", "os": "linux" } } ] } ``` Closes #40051 from dongjoon-hyun/SPARK-42462. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 2ac70ae5381333aa899d82f6cd4c3bbae524e1c2) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 16 February 2023, 05:52:54 UTC |
| 07b7199 | Liang-Chi Hsieh | 10 February 2023, 02:17:27 UTC | [MINOR][SS] Fix setTimeoutTimestamp doc ### What changes were proposed in this pull request? This patch updates the API doc of `setTimeoutTimestamp` of `GroupState`. ### Why are the changes needed? Update incorrect API doc. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Doc change only. Closes #39958 from viirya/fix_group_state. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> (cherry picked from commit a180e67d3859a4e145beaf671c1221fb4d6cbda7) Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 10 February 2023, 02:18:08 UTC |
| eecd939 | awdavidson | 09 February 2023, 00:02:12 UTC | [SPARK-40819][SQL][FOLLOWUP] Update SqlConf version for nanosAsLong configuration As requested by HyukjinKwon in https://github.com/apache/spark/pull/38312 NB: This change needs to be backported ### What changes were proposed in this pull request? Update version set for "spark.sql.legacy.parquet.nanosAsLong" configuration in SqlConf. This update is required because the previous PR set version to `3.2.3` which has already been released. Updating to version `3.2.4` will correctly reflect when this configuration element was added ### Why are the changes needed? Correctness and to complete SPARK-40819 ### Does this PR introduce _any_ user-facing change? No, this is merely so this configuration element has the correct version ### How was this patch tested? N/A Closes #39943 from awdavidson/SPARK-40819_sql-conf. Authored-by: awdavidson <54780428+awdavidson@users.noreply.github.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 409c661542c4b966876f0af4119803de25670649) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 09 February 2023, 00:02:54 UTC |
| 117ec15 | Dongjoon Hyun | 08 February 2023, 21:33:13 UTC | Revert "[SPARK-41962][MINOR][SQL] Update the order of imports in class SpecificParquetRecordReaderBase" This reverts commit c8b47ec2d0a066f539a98488502fce99efe006f0. | 08 February 2023, 21:33:13 UTC |
| f82176c | alfreddavidson | 08 February 2023, 02:07:59 UTC | [SPARK-40819][SQL][3.2] Timestamp nanos behaviour regression As per HyukjinKwon request on https://github.com/apache/spark/pull/38312 to backport fix into 3.2 ### What changes were proposed in this pull request? Handle `TimeUnit.NANOS` for parquet `Timestamps` addressing a regression in behaviour since 3.2 ### Why are the changes needed? Since version 3.2 reading parquet files that contain attributes with type `TIMESTAMP(NANOS,true)` is not possible as ParquetSchemaConverter returns ``` Caused by: org.apache.spark.sql.AnalysisException: Illegal Parquet type: INT64 (TIMESTAMP(NANOS,true)) ``` https://issues.apache.org/jira/browse/SPARK-34661 introduced a change matching on the `LogicalTypeAnnotation` which only covers Timestamp cases for `TimeUnit.MILLIS` and `TimeUnit.MICROS` meaning `TimeUnit.NANOS` would return `illegalType()` Prior to 3.2 the matching used the `originalType` which for `TIMESTAMP(NANOS,true)` return `null` and therefore resulted to a `LongType`, the change proposed is too consider `TimeUnit.NANOS` and return `LongType` making behaviour the same as before. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added unit test covering this scenario. Internally deployed to read parquet files that contain `TIMESTAMP(NANOS,true)` Closes #39905 from awdavidson/ts-nanos-fix-3.2. Authored-by: alfreddavidson <alfie.davidson9@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 08 February 2023, 02:07:59 UTC |
| c8b47ec | wayneguow | 07 February 2023, 07:11:09 UTC | [SPARK-41962][MINOR][SQL] Update the order of imports in class SpecificParquetRecordReaderBase ### What changes were proposed in this pull request? Update the order of imports in class SpecificParquetRecordReaderBase. ### Why are the changes needed? Follow the code style. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Passed GA. Closes #39906 from wayneguow/import. Authored-by: wayneguow <guow93@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit d6134f78d3d448a990af53beb8850ff91b71aef6) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 07 February 2023, 07:11:45 UTC |
| d304a65 | oleksii.diagiliev | 03 February 2023, 16:49:42 UTC | [SPARK-41554] fix changing of Decimal scale when scale decreased by m… …ore than 18 This is a backport PR for https://github.com/apache/spark/pull/39099 Closes #39381 from fe2s/branch-3.2-fix-decimal-scaling. Authored-by: oleksii.diagiliev <oleksii.diagiliev@workday.com> Signed-off-by: Sean Owen <srowen@gmail.com> | 03 February 2023, 16:49:42 UTC |
| 8f22e31 | Deepyaman Datta | 03 February 2023, 06:50:32 UTC | [MINOR][DOCS][PYTHON][PS] Fix the `.groupby()` method docstring ### What changes were proposed in this pull request? Update the docstring for the `.groupby()` method. ### Why are the changes needed? The `.groupby()` method accept a list of columns (or a single column), and a column is defined by a `Series` or name (`Label`). It's a bit confusing to say "using a Series of columns", because `Series` (capitalized) is a specific object that isn't actually used/reasonable to use here. ### Does this PR introduce _any_ user-facing change? Yes (documentation) ### How was this patch tested? N/A Closes #38625 from deepyaman/patch-3. Authored-by: Deepyaman Datta <deepyaman.datta@utexas.edu> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 71154dc1b35c7227ef9033fe5abc2a8b3f2d0990) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 03 February 2023, 06:51:29 UTC |
| e973496 | Wenchen Fan | 01 February 2023, 09:36:14 UTC | [SPARK-42259][SQL] ResolveGroupingAnalytics should take care of Python UDAF This is a long-standing correctness issue with Python UDAF and grouping analytics. The rule `ResolveGroupingAnalytics` should take care of Python UDAF when matching aggregate expressions. bug fix Yes, the query result was wrong before existing tests Closes #39824 from cloud-fan/python. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 1219c8492376e038894111cd5d922229260482e7) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 01 February 2023, 09:41:44 UTC |
| ab5109e | Dongjoon Hyun | 27 January 2023, 00:39:17 UTC | [SPARK-42201][BUILD] `build/sbt` should allow `SBT_OPTS` to override JVM memory setting ### What changes were proposed in this pull request? This PR aims to fix a bug which `build/sbt` doesn't allow JVM memory setting via `SBT_OPTS`. ### Why are the changes needed? `SBT_OPTS` is supposed to be used in this way in the community. https://github.com/apache/spark/blob/e30bb538e480940b1963eb14c3267662912d8584/appveyor.yml#L54 However, `SBT_OPTS` memory setting like the following is ignored because ` -Xms4096m -Xmx4096m -XX:ReservedCodeCacheSize=512m` is injected by default after `SBT_OPTS`. We should switch the order. ``` $ SBT_OPTS="-Xmx6g" build/sbt package ``` https://github.com/apache/spark/blob/e30bb538e480940b1963eb14c3267662912d8584/build/sbt-launch-lib.bash#L124 ### Does this PR introduce _any_ user-facing change? No. This is a dev-only change. ### How was this patch tested? Manually run the following. ``` $ SBT_OPTS="-Xmx6g" build/sbt package ``` While running the above command, check the JVM options. ``` $ ps aux | grep java dongjoon 36683 434.3 3.1 418465456 1031888 s001 R+ 1:11PM 0:19.86 /Users/dongjoon/.jenv/versions/temurin17/bin/java -Xms4096m -Xmx4096m -XX:ReservedCodeCacheSize=512m -Xmx6g -jar build/sbt-launch-1.8.2.jar package ``` Closes #39758 from dongjoon-hyun/SPARK-42201. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 66ec1eb630a4682f5ad2ed2ee989ffcce9031608) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 27 January 2023, 00:39:46 UTC |
| 1800bff | Steve Vaughan Jr | 26 January 2023, 02:23:00 UTC | [SPARK-42188][BUILD][3.2] Force SBT protobuf version to match Maven ### What changes were proposed in this pull request? Update `SparkBuild.scala` to force SBT use of `protobuf-java` to match the Maven version. The Maven dependencyManagement section forces `protobuf-java` to use `2.5.0`, but SBT is using `3.14.0`. ### Why are the changes needed? Define `protoVersion` in `SparkBuild.scala` and use it in `DependencyOverrides` to force the SBT version of `protobuf-java` to match the setting defined in the Maven top-level `pom.xml`. Add comments to both `pom.xml` and `SparkBuild.scala` to ensure that the values are kept in sync. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Before the update, SBT reported using `3.14.0`: ``` % build/sbt dependencyTree | grep proto | sed 's/^.*-com/com/' | sort | uniq -c 8 com.google.protobuf:protobuf-java:2.5.0 (evicted by: 3.14.0) 70 com.google.protobuf:protobuf-java:3.14.0 ``` After the patch is applied, SBT reports using `2.5.0`: ``` % build/sbt dependencyTree | grep proto | sed 's/^.*-com/com/' | sort | uniq -c 70 com.google.protobuf:protobuf-java:2.5.0 ``` Closes #39745 from snmvaughan/feature/SPARK-42188. Authored-by: Steve Vaughan Jr <s_vaughan@apple.com> Signed-off-by: huaxingao <huaxin_gao@apple.com> | 26 January 2023, 02:23:00 UTC |
| 2a37f22 | Enrico Minack | 26 January 2023, 01:43:24 UTC | [SPARK-42168][3.2][SQL][PYTHON] Fix required child distribution of FlatMapCoGroupsInPandas (as in CoGroup) ### What changes were proposed in this pull request? Make `FlatMapCoGroupsInPandas` (used by PySpark) report its required child distribution as `HashClusteredDistribution`, rather than `ClusteredDistribution`. That is the same distribution as reported by `CoGroup` (used by Scala). ### Why are the changes needed? This allows the `EnsureRequirements` rule to correctly recognizes that `FlatMapCoGroupsInPandas` requiring `HashClusteredDistribution(id, day)` is not compatible with `HashPartitioning(day, id)`, while `ClusteredDistribution(id, day)` is compatible with `HashPartitioning(day, id)`. The following example returns an incorrect result in Spark 3.0, 3.1, and 3.2. ```Scala import org.apache.spark.sql.expressions.Window import org.apache.spark.sql.functions.{col, lit, sum} val ids = 1000 val days = 1000 val parts = 10 val id_df = spark.range(ids) val day_df = spark.range(days).withColumnRenamed("id", "day") val id_day_df = id_df.join(day_df) // these redundant aliases are needed to workaround bug SPARK-42132 val left_df = id_day_df.select($"id".as("id"), $"day".as("day"), lit("left").as("side")).repartition(parts).cache() val right_df = id_day_df.select($"id".as("id"), $"day".as("day"), lit("right").as("side")).repartition(parts).cache() //.withColumnRenamed("id", "id2") // note the column order is different to the groupBy("id", "day") column order below val window = Window.partitionBy("day", "id") case class Key(id: BigInt, day: BigInt) case class Value(id: BigInt, day: BigInt, side: String) case class Sum(id: BigInt, day: BigInt, side: String, day_sum: BigInt) val left_grouped_df = left_df.groupBy("id", "day").as[Key, Value] val right_grouped_df = right_df.withColumn("day_sum", sum(col("day")).over(window)).groupBy("id", "day").as[Key, Sum] val df = left_grouped_df.cogroup(right_grouped_df)((key: Key, left: Iterator[Value], right: Iterator[Sum]) => left) df.explain() df.show(5) ``` Output was ``` == Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- FlatMapCoGroupsInPandas [id#8L, day#9L], [id#29L, day#30L], cogroup(id#8L, day#9L, side#10, id#29L, day#30L, side#31, day_sum#54L), [id#64L, day#65L, lefts#66, rights#67] :- Sort [id#8L ASC NULLS FIRST, day#9L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#8L, day#9L, 200), ENSURE_REQUIREMENTS, [plan_id=117] : +- ... +- Sort [id#29L ASC NULLS FIRST, day#30L ASC NULLS FIRST], false, 0 +- Project [id#29L, day#30L, id#29L, day#30L, side#31, day_sum#54L] +- Window [sum(day#30L) windowspecdefinition(day#30L, id#29L, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS day_sum#54L], [day#30L, id#29L] +- Sort [day#30L ASC NULLS FIRST, id#29L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(day#30L, id#29L, 200), ENSURE_REQUIREMENTS, [plan_id=112] +- ... +---+---+-----+------+ | id|day|lefts|rights| +---+---+-----+------+ | 0| 3| 0| 1| | 0| 4| 0| 1| | 0| 13| 1| 0| | 0| 27| 0| 1| | 0| 31| 0| 1| +---+---+-----+------+ only showing top 5 rows ``` Output now is ``` == Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- FlatMapCoGroupsInPandas [id#8L, day#9L], [id#29L, day#30L], cogroup(id#8L, day#9L, side#10, id#29L, day#30L, side#31, day_sum#54L), [id#64L, day#65L, lefts#66, rights#67] :- Sort [id#8L ASC NULLS FIRST, day#9L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#8L, day#9L, 200), ENSURE_REQUIREMENTS, [plan_id=117] : +- ... +- Sort [id#29L ASC NULLS FIRST, day#30L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#29L, day#30L, 200), ENSURE_REQUIREMENTS, [plan_id=118] +- Project [id#29L, day#30L, id#29L, day#30L, side#31, day_sum#54L] +- Window [sum(day#30L) windowspecdefinition(day#30L, id#29L, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS day_sum#54L], [day#30L, id#29L] +- Sort [day#30L ASC NULLS FIRST, id#29L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(day#30L, id#29L, 200), ENSURE_REQUIREMENTS, [plan_id=112] +- ... +---+---+-----+------+ | id|day|lefts|rights| +---+---+-----+------+ | 0| 13| 1| 1| | 0| 63| 1| 1| | 0| 89| 1| 1| | 0| 95| 1| 1| | 0| 96| 1| 1| +---+---+-----+------+ only showing top 5 rows ``` Spark 3.3 [reworked](https://github.com/apache/spark/pull/32875/files#diff-e938569a4ca4eba8f7e10fe473d4f9c306ea253df151405bcaba880a601f075fR75-R76) `HashClusteredDistribution`, and is not sensitive to using `ClusteredDistribution`: #32875 ### Does this PR introduce _any_ user-facing change? This fixes correctness. ### How was this patch tested? A unit test in `EnsureRequirementsSuite`. Closes #39717 from EnricoMi/branch-3.2-cogroup-window-bug. Authored-by: Enrico Minack <github@enrico.minack.dev> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 26 January 2023, 01:43:24 UTC |
| fed407a | Ted Yu | 24 January 2023, 18:15:22 UTC | [SPARK-42090][3.2] Introduce sasl retry count in RetryingBlockTransferor ### What changes were proposed in this pull request? This PR introduces sasl retry count in RetryingBlockTransferor. ### Why are the changes needed? Previously a boolean variable, saslTimeoutSeen, was used. However, the boolean variable wouldn't cover the following scenario: 1. SaslTimeoutException 2. IOException 3. SaslTimeoutException 4. IOException Even though IOException at #2 is retried (resulting in increment of retryCount), the retryCount would be cleared at step #4. Since the intention of saslTimeoutSeen is to undo the increment due to retrying SaslTimeoutException, we should keep a counter for SaslTimeoutException retries and subtract the value of this counter from retryCount. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? New test is added, courtesy of Mridul. Closes #39611 from tedyu/sasl-cnt. Authored-by: Ted Yu <yuzhihonggmail.com> Signed-off-by: Mridul Muralidharan <mridul<at>gmail.com> Closes #39710 from akpatnam25/SPARK-42090-backport-3.2. Authored-by: Ted Yu <yuzhihong@gmail.com> Signed-off-by: Mridul Muralidharan <mridul<at>gmail.com> | 24 January 2023, 18:15:22 UTC |
| dcd5d75 | Dongjoon Hyun | 24 January 2023, 08:06:25 UTC | [MINOR][K8S][DOCS] Add all resource managers in `Scheduling Within an Application` section ### What changes were proposed in this pull request? `Job Scheduling` document doesn't mention `K8s resource manager` so far because `Scheduling Across Applications` section only mentions all resource managers except K8s. This PR aims to add all supported resource managers in `Scheduling Within an Application section` section. ### Why are the changes needed? K8s also supports `FAIR` schedule within an application. ### Does this PR introduce _any_ user-facing change? No. This is a doc-only update. ### How was this patch tested? N/A Closes #39704 from dongjoon-hyun/minor_job_scheduling. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 45dbc44410f9bf74c7fb4431aad458db32960461) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 24 January 2023, 08:06:43 UTC |
| 35023e8 | Dongjoon Hyun | 24 January 2023, 07:47:26 UTC | [SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should provide FAIR scheduler ### What changes were proposed in this pull request? Like our documentation, `spark.sheduler.mode=FAIR` should provide a `FAIR Scheduling Within an Application`. https://spark.apache.org/docs/latest/job-scheduling.html#scheduling-within-an-application  This bug is hidden in our CI because we have `fairscheduler.xml` always as one of test resources. - https://github.com/apache/spark/blob/master/core/src/test/resources/fairscheduler.xml ### Why are the changes needed? Currently, when `spark.scheduler.mode=FAIR` is given without scheduler allocation file, Spark creates `Fair Scheduler Pools` with `FIFO` scheduler which is wrong. We need to switch the mode to `FAIR` from `FIFO`. **BEFORE** ``` $ bin/spark-shell -c spark.scheduler.mode=FAIR Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 23/01/22 14:47:37 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 23/01/22 14:47:38 WARN FairSchedulableBuilder: Fair Scheduler configuration file not found so jobs will be scheduled in FIFO order. To use fair scheduling, configure pools in fairscheduler.xml or set spark.scheduler.allocation.file to a file that contains the configuration. Spark context Web UI available at http://localhost:4040 ```  **AFTER** ``` $ bin/spark-shell -c spark.scheduler.mode=FAIR Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 23/01/22 14:48:18 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://localhost:4040 ``` 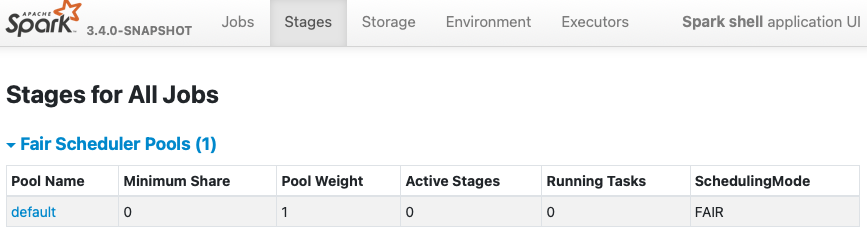 ### Does this PR introduce _any_ user-facing change? Yes, but this is a bug fix to match with Apache Spark official documentation. ### How was this patch tested? Pass the CIs. Closes #39703 from dongjoon-hyun/SPARK-42157. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 4d51bfa725c26996641f566e42ae392195d639c5) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 24 January 2023, 07:48:37 UTC |
| 1a26c7b | Aravind Patnam | 21 January 2023, 03:39:01 UTC | [SPARK-41415][3.2] SASL Request Retries Add the ability to retry SASL requests. Will add it as a metric too soon to track SASL retries. We are seeing increased SASL timeouts internally, and this issue would mitigate the issue. We already have this feature enabled for our 2.3 jobs, and we have seen failures significantly decrease. No Added unit tests, and tested on cluster to ensure the retries are being triggered correctly. Closes #38959 from akpatnam25/SPARK-41415. Authored-by: Aravind Patnam <apatnamlinkedin.com> Signed-off-by: Mridul Muralidharan <mridul<at>gmail.com> Closes #39645 from akpatnam25/SPARK-41415-backport-3.2. Authored-by: Aravind Patnam <apatnam@linkedin.com> Signed-off-by: Mridul Muralidharan <mridul<at>gmail.com> | 21 January 2023, 03:39:01 UTC |
| 68fb5c4 | Anton Ippolitov | 20 January 2023, 22:43:42 UTC | [SPARK-40817][K8S][3.2] `spark.files` should preserve remote files ### What changes were proposed in this pull request? Backport https://github.com/apache/spark/pull/38376 to `branch-3.2` You can find a detailed description of the issue and an example reproduction on the Jira card: https://issues.apache.org/jira/browse/SPARK-40817 The idea for this fix is to update the logic which uploads user-specified files (via `spark.jars`, `spark.files`, etc) to `spark.kubernetes.file.upload.path`. After uploading local files, it used to overwrite the initial list of URIs passed by the user and it would thus erase all remote URIs which were specified there. Small example of this behaviour: 1. User set the value of `spark.jars` to `s3a://some-bucket/my-application.jar,/tmp/some-local-jar.jar` when running `spark-submit` in cluster mode 2. `BasicDriverFeatureStep.getAdditionalPodSystemProperties()` gets called at one point while running `spark-submit` 3. This function would set `spark.jars` to a new value of `${SPARK_KUBERNETES_UPLOAD_PATH}/spark-upload-${RANDOM_STRING}/some-local-jar.jar`. Note that `s3a://some-bucket/my-application.jar` has been discarded. With the logic proposed in this PR, the new value of `spark.jars` would be `s3a://some-bucket/my-application.jar,${SPARK_KUBERNETES_UPLOAD_PATH}/spark-upload-${RANDOM_STRING}/some-local-jar.jar`, so in other words we are making sure that remote URIs are no longer discarded. ### Why are the changes needed? We encountered this issue in production when trying to launch Spark on Kubernetes jobs in cluster mode with a fix of local and remote dependencies. ### Does this PR introduce _any_ user-facing change? Yes, see description of the new behaviour above. ### How was this patch tested? - Added a unit test for the new behaviour - Added an integration test for the new behaviour - Tried this patch in our Kubernetes environment with `SparkPi`: ``` spark-submit \ --master k8s://https://$KUBERNETES_API_SERVER_URL:443 \ --deploy-mode cluster \ --name=spark-submit-test \ --class org.apache.spark.examples.SparkPi \ --conf spark.jars=/opt/my-local-jar.jar,s3a://$BUCKET_NAME/my-remote-jar.jar \ --conf spark.kubernetes.file.upload.path=s3a://$BUCKET_NAME/my-upload-path/ \ [...] /opt/spark/examples/jars/spark-examples_2.12-3.1.3.jar ``` Before applying the patch, `s3a://$BUCKET_NAME/my-remote-jar.jar` was discarded from the final value of `spark.jars`. After applying the patch and launching the job again, I confirmed that `s3a://$BUCKET_NAME/my-remote-jar.jar` was no longer discarded by looking at the Spark config for the running job. Closes #39670 from antonipp/spark-40817-branch-3.2. Authored-by: Anton Ippolitov <anton.ippolitov@datadoghq.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 20 January 2023, 22:43:42 UTC |
| 60de4a5 | Dongjoon Hyun | 15 January 2023, 09:09:54 UTC | [SPARK-42071][CORE] Register `scala.math.Ordering$Reverse` to KyroSerializer This PR aims to register `scala.math.Ordering$Reverse` to KyroSerializer. Scala 2.12.12 added a new class 'Reverse' via https://github.com/scala/scala/pull/8965. This affects Apache Spark 3.2.0+. No. Pass the CIs with newly added test case. Closes #39578 from dongjoon-hyun/SPARK-42071. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit e3c0fbeadfe5242fa6265cb0646d72d3b5f6ef35) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 15 January 2023, 09:10:47 UTC |
| 4e8907a | Stefaan Lippens | 12 January 2023, 09:24:30 UTC | [SPARK-41989][PYTHON] Avoid breaking logging config from pyspark.pandas See https://issues.apache.org/jira/browse/SPARK-41989 for in depth explanation Short summary: `pyspark/pandas/__init__.py` uses, at import time, `logging.warning()` which might silently call `logging.basicConfig()`. So by importing `pyspark.pandas` (directly or indirectly) a user might unknowingly break their own logging setup (e.g. when based on `logging.basicConfig()` or related). `logging.getLogger(...).warning()` does not trigger this behavior. User-defined logging setups will be more predictable. Manual testing so far. I'm not sure it's worthwhile to cover this with a unit test Closes #39516 from soxofaan/SPARK-41989-pyspark-pandas-logging-setup. Authored-by: Stefaan Lippens <stefaan.lippens@vito.be> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 04836babb7a1a2aafa7c65393c53c42937ef75a4) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 12 January 2023, 09:25:47 UTC |
| 1421811 | huaxingao | 10 January 2023, 20:59:32 UTC | [SPARK-38173][SQL][3.2] Quoted column cannot be recognized correctly when quotedRegexColumnNames is true ### What changes were proposed in this pull request? backporting https://github.com/apache/spark/pull/35476 to 3.2 ### Why are the changes needed? bug fixing in 3.2 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? new UT Closes #39473 from huaxingao/3.2. Authored-by: huaxingao <huaxin_gao@apple.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 10 January 2023, 20:59:32 UTC |
| 7eca60d | Enrico Minack | 06 January 2023, 03:32:45 UTC | [SPARK-41162][SQL][3.3] Fix anti- and semi-join for self-join with aggregations ### What changes were proposed in this pull request? Backport #39131 to branch-3.3. Rule `PushDownLeftSemiAntiJoin` should not push an anti-join below an `Aggregate` when the join condition references an attribute that exists in its right plan and its left plan's child. This usually happens when the anti-join / semi-join is a self-join while `DeduplicateRelations` cannot deduplicate those attributes (in this example due to the projection of `value` to `id`). This behaviour already exists for `Project` and `Union`, but `Aggregate` lacks this safety guard. ### Why are the changes needed? Without this change, the optimizer creates an incorrect plan. This example fails with `distinct()` (an aggregation), and succeeds without `distinct()`, but both queries are identical: ```scala val ids = Seq(1, 2, 3).toDF("id").distinct() val result = ids.withColumn("id", $"id" + 1).join(ids, Seq("id"), "left_anti").collect() assert(result.length == 1) ``` With `distinct()`, rule `PushDownLeftSemiAntiJoin` creates a join condition `(value#907 + 1) = value#907`, which can never be true. This effectively removes the anti-join. **Before this PR:** The anti-join is fully removed from the plan. ``` == Physical Plan == AdaptiveSparkPlan (16) +- == Final Plan == LocalTableScan (1) (16) AdaptiveSparkPlan Output [1]: [id#900] Arguments: isFinalPlan=true ``` This is caused by `PushDownLeftSemiAntiJoin` adding join condition `(value#907 + 1) = value#907`, which is wrong as because `id#910` in `(id#910 + 1) AS id#912` exists in the right child of the join as well as in the left grandchild: ``` === Applying Rule org.apache.spark.sql.catalyst.optimizer.PushDownLeftSemiAntiJoin === !Join LeftAnti, (id#912 = id#910) Aggregate [id#910], [(id#910 + 1) AS id#912] !:- Aggregate [id#910], [(id#910 + 1) AS id#912] +- Project [value#907 AS id#910] !: +- Project [value#907 AS id#910] +- Join LeftAnti, ((value#907 + 1) = value#907) !: +- LocalRelation [value#907] :- LocalRelation [value#907] !+- Aggregate [id#910], [id#910] +- Aggregate [id#910], [id#910] ! +- Project [value#914 AS id#910] +- Project [value#914 AS id#910] ! +- LocalRelation [value#914] +- LocalRelation [value#914] ``` The right child of the join and in the left grandchild would become the children of the pushed-down join, which creates an invalid join condition. **After this PR:** Join condition `(id#910 + 1) AS id#912` is understood to become ambiguous as both sides of the prospect join contain `id#910`. Hence, the join is not pushed down. The rule is then not applied any more. The final plan contains the anti-join: ``` == Physical Plan == AdaptiveSparkPlan (24) +- == Final Plan == * BroadcastHashJoin LeftSemi BuildRight (14) :- * HashAggregate (7) : +- AQEShuffleRead (6) : +- ShuffleQueryStage (5), Statistics(sizeInBytes=48.0 B, rowCount=3) : +- Exchange (4) : +- * HashAggregate (3) : +- * Project (2) : +- * LocalTableScan (1) +- BroadcastQueryStage (13), Statistics(sizeInBytes=1024.0 KiB, rowCount=3) +- BroadcastExchange (12) +- * HashAggregate (11) +- AQEShuffleRead (10) +- ShuffleQueryStage (9), Statistics(sizeInBytes=48.0 B, rowCount=3) +- ReusedExchange (8) (8) ReusedExchange [Reuses operator id: 4] Output [1]: [id#898] (24) AdaptiveSparkPlan Output [1]: [id#900] Arguments: isFinalPlan=true ``` ### Does this PR introduce _any_ user-facing change? It fixes correctness. ### How was this patch tested? Unit tests in `DataFrameJoinSuite` and `LeftSemiAntiJoinPushDownSuite`. Closes #39409 from EnricoMi/branch-antijoin-selfjoin-fix-3.3. Authored-by: Enrico Minack <github@enrico.minack.dev> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit b97f79da04acc9bde1cb4def7dc33c22cfc11372) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 06 January 2023, 03:33:11 UTC |
| 0f5e231 | Dongjoon Hyun | 25 June 2022, 11:37:53 UTC | [SPARK-39596][INFRA][FOLLOWUP] Install `mvtnorm` and `statmod` at linter job Closes #36988 from dongjoon-hyun/SPARK-39596-2. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 4c79cc7d5f0d818e479565f5d623e168d777ba0a) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 04 January 2023, 06:03:09 UTC |
| 706cecd | Dongjoon Hyun | 25 June 2022, 07:31:54 UTC | [SPARK-39596][INFRA] Install `ggplot2` for GitHub Action linter job ### What changes were proposed in this pull request? This PR aims to fix GitHub Action linter job by installing `ggplot2`. ### Why are the changes needed? It starts to fail like the following. - https://github.com/apache/spark/runs/7047294196?check_suite_focus=true ``` x Failed to parse Rd in histogram.Rd ℹ there is no package called ‘ggplot2’ ``` ### Does this PR introduce _any_ user-facing change? No. This is a dev-only change. ### How was this patch tested? Pass the GitHub Action linter job. Closes #36987 from dongjoon-hyun/SPARK-39596. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit bf59f6e4bd7f34f8a36bfef1e93e0ddccddf9e43) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 04 January 2023, 06:02:29 UTC |
| b8978fe | khalidmammadov | 21 February 2022, 02:04:48 UTC | [SPARK-38261][INFRA] Add missing R packages from base image Current GitHub workflow job **Linters, licenses, dependencies and documentation generation** is missing R packages to complete Documentation and API build. **Build and test** - is not failing as these packages are installed on the base image. We need to keep them in-sync IMO with the base image for easy switch back to ubuntu runner when ready. Reference: [**The base image**](https://hub.docker.com/layers/dongjoon/apache-spark-github-action-image/20220207/images/sha256-af09d172ff8e2cbd71df9a1bc5384a47578c4a4cc293786c539333cafaf4a7ce?context=explore) Adding missing packages to the workflow file To make them inline with the base image config and make the job task **complete** for standalone execution (i.e. without this image) No GitHub builds and in the local Docker containers Closes #35583 from khalidmammadov/sync_doc_build_with_base. Authored-by: khalidmammadov <xmamedov@hotmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 898542746b2c56b2571562ed8e9818bcb565aff2) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 04 January 2023, 06:01:08 UTC |
| 576ca6e | Dongjoon Hyun | 04 January 2023, 05:03:20 UTC | Revert "[SPARK-36939][PYTHON][DOCS] Add orphan migration page into list in PySpark documentation" This reverts commit 0565d95a86e738d24e9c05a4c5c3c3815944b4be. | 04 January 2023, 05:03:20 UTC |
| 09f65c1 | Dongjoon Hyun | 29 September 2021, 18:39:01 UTC | [SPARK-36883][INFRA] Upgrade R version to 4.1.1 in CI images ### What changes were proposed in this pull request? This PR aims to upgrade GitHub Action CI image to recover CRAN installation failure. ### Why are the changes needed? Sometimes, GitHub Action linter job failed - https://github.com/apache/spark/runs/3739748809 New image have R 4.1.1 and will recover the failure. ``` $ docker run -it --rm dongjoon/apache-spark-github-action-image:20210928 R --version R version 4.1.1 (2021-08-10) -- "Kick Things" Copyright (C) 2021 The R Foundation for Statistical Computing Platform: x86_64-pc-linux-gnu (64-bit) R is free software and comes with ABSOLUTELY NO WARRANTY. You are welcome to redistribute it under the terms of the GNU General Public License versions 2 or 3. For more information about these matters see https://www.gnu.org/licenses/. ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass `GitHub Action`. Closes #34138 from dongjoon-hyun/SPARK-36883. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit aa9064ad96ff7cefaa4381e912608b0b0d39a09c) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 04 January 2023, 03:07:11 UTC |
| 736964e | Bjørn Jørgensen | 04 January 2023, 01:23:53 UTC | [SPARK-41030][BUILD][3.2] Upgrade `Apache Ivy` to 2.5.1 ### What changes were proposed in this pull request? Upgrade `Apache Ivy` from 2.5.0 to 2.5.1 [Release notes](https://ant.apache.org/ivy/history/2.5.1/release-notes.html) ### Why are the changes needed? [CVE-2022-37865](https://nvd.nist.gov/vuln/detail/CVE-2022-37865) This is a [9.1 CRITICAL](https://nvd.nist.gov/vuln-metrics/cvss/v3-calculator?name=CVE-2022-37865&vector=AV:N/AC:L/PR:N/UI:N/S:U/C:N/I:H/A:H&version=3.1&source=NIST) and [CVE-2022-37866](https://nvd.nist.gov/vuln/detail/CVE-2022-37866) ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass GA Closes #39371 from bjornjorgensen/ivy.version_2.5.1. Lead-authored-by: Bjørn Jørgensen <bjornjorgensen@gmail.com> Co-authored-by: Bjørn <bjornjorgensen@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 04 January 2023, 01:23:53 UTC |
| 63722c3 | Dongjoon Hyun | 04 January 2023, 01:22:24 UTC | [SPARK-41865][INFRA][3.2] Use pycodestyle to 2.7.0 to fix pycodestyle errors ### What changes were proposed in this pull request? `branch-3.2` has been broken for a while with false-positive failures. - https://github.com/apache/spark/actions/runs/3833643461/jobs/6525303096 ``` pycodestyle checks failed: ./python/pyspark/broadcast.py:102:23: E275 missing whitespace after keyword ./python/pyspark/sql/tests/test_context.py:166:19: E275 missing whitespace after keyword ./python/pyspark/sql/tests/test_pandas_udf_grouped_agg.py:512:15: E275 missing whitespace after keyword ./python/pyspark/sql/pandas/conversion.py:174:20: E275 missing whitespace after keyword ./python/pyspark/sql/readwriter.py:662:60: E275 missing whitespace after keyword ./python/pyspark/sql/readwriter.py:694:60: E275 missing whitespace after keyword ./python/pyspark/ml/tests/test_tuning.py:203:23: E275 missing whitespace after keyword ./python/pyspark/worker.py:583:27: E275 missing whitespace after keyword Error: Process completed with exit code 1. ``` ### Why are the changes needed? To fix `pycodestyle`. Apache Spark expects `2.7.0` like the following. https://github.com/apache/spark/blob/ad2d42709abfc8f8ad27f836c811a4b75ef32ee9/dev/lint-python#L25 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass `pycodestyle`.  Closes #39374 from dongjoon-hyun/SPARK-41865. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 04 January 2023, 01:22:24 UTC |
| ad2d427 | Dongjoon Hyun | 03 January 2023, 23:01:43 UTC | [SPARK-41863][INFRA][PYTHON][TESTS] Skip `flake8` tests if the command is not available ### What changes were proposed in this pull request? This PR aims to skip `flake8` tests if the command is not available. ### Why are the changes needed? Linters are optional modules and we can be skip in some systems like `mypy`. ``` $ dev/lint-python starting python compilation test... python compilation succeeded. The Python library providing 'black' module was not found. Skipping black checks for now. The flake8 command was not found. Skipping for now. The mypy command was not found. Skipping for now. all lint-python tests passed! ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manual tests. Closes #39372 from dongjoon-hyun/SPARK-41863. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 1a5ef40a4d59b377b028b55ea3805caf5d55f28f) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 03 January 2023, 23:02:15 UTC |
| a64f600 | Jungtaek Lim | 28 December 2022, 11:51:09 UTC | [SPARK-41732][SQL][SS][3.3] Apply tree-pattern based pruning for the rule SessionWindowing This PR ports back #39245 to branch-3.3. This PR proposes to apply tree-pattern based pruning for the rule SessionWindowing, to minimize the evaluation of rule with SessionWindow node. The rule SessionWindowing is unnecessarily evaluated multiple times without proper pruning. No. Existing tests. Closes #39253 from HeartSaVioR/SPARK-41732-3.3. Authored-by: Jungtaek Lim <kabhwan.opensource@gmail.com> Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com> (cherry picked from commit 02a7fda304b39779bff7fe88f146ae106bd61f1a) Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com> | 28 December 2022, 12:02:25 UTC |
| 5fef831 | Gengliang Wang | 22 December 2022, 05:57:04 UTC | [SPARK-41668][SQL][3.2] DECODE function returns wrong results when passed NULL ### What changes were proposed in this pull request? The DECODE function was implemented for Oracle compatibility. It works similar to CASE expression, but it is supposed to have one major difference: NULL == NULL https://docs.oracle.com/database/121/SQLRF/functions057.htm#SQLRF00631 The Spark implementation does not observe this, however: ``` > select decode(null, 6, 'Spark', NULL, 'SQL', 4, 'rocks'); NULL ``` The result is supposed to be 'SQL'. This PR is to fix the issue. ### Why are the changes needed? Bug fix and Oracle compatibility. ### Does this PR introduce _any_ user-facing change? Yes, DECODE function will return matched value when passed null, instead of always returning null. ### How was this patch tested? New UT. Closes #39166 from gengliangwang/fixDecode3.2. Authored-by: Gengliang Wang <gengliang@apache.org> Signed-off-by: Gengliang Wang <gengliang@apache.org> | 22 December 2022, 05:57:04 UTC |
| b5c4bb7 | Bruce Robbins | 20 December 2022, 00:29:18 UTC | [SPARK-41535][SQL] Set null correctly for calendar interval fields in `InterpretedUnsafeProjection` and `InterpretedMutableProjection` In `InterpretedUnsafeProjection`, use `UnsafeWriter.write`, rather than `UnsafeWriter.setNullAt`, to set null for interval fields. Also, in `InterpretedMutableProjection`, use `InternalRow.setInterval`, rather than `InternalRow.setNullAt`, to set null for interval fields. This returns the wrong answer: ``` set spark.sql.codegen.wholeStage=false; set spark.sql.codegen.factoryMode=NO_CODEGEN; select first(col1), last(col2) from values (make_interval(0, 0, 0, 7, 0, 0, 0), make_interval(17, 0, 0, 2, 0, 0, 0)) as data(col1, col2); +---------------+---------------+ |first(col1) |last(col2) | +---------------+---------------+ |16 years 2 days|16 years 2 days| +---------------+---------------+ ``` In the above case, `TungstenAggregationIterator` uses `InterpretedUnsafeProjection` to create the aggregation buffer and to initialize all the fields to null. `InterpretedUnsafeProjection` incorrectly calls `UnsafeRowWriter#setNullAt`, rather than `unsafeRowWriter#write`, for the two calendar interval fields. As a result, the writer never allocates memory from the variable length region for the two intervals, and the pointers in the fixed region get left as zero. Later, when `InterpretedMutableProjection` attempts to update the first field, `UnsafeRow#setInterval` picks up the zero pointer and stores interval data on top of the null-tracking bit set. The call to UnsafeRow#setInterval for the second field also stomps the null-tracking bit set. Later updates to the null-tracking bit set (e.g., calls to `setNotNullAt`) further corrupt the interval data, turning `interval 7 years 2 days` into `interval 16 years 2 days`. Even after one fixes the above bug in `InterpretedUnsafeProjection` so that the buffer is created correctly, `InterpretedMutableProjection` has a similar bug to SPARK-41395, except this time for calendar interval data: ``` set spark.sql.codegen.wholeStage=false; set spark.sql.codegen.factoryMode=NO_CODEGEN; select first(col1), last(col2), max(col3) from values (null, null, 1), (make_interval(0, 0, 0, 7, 0, 0, 0), make_interval(17, 0, 0, 2, 0, 0, 0), 3) as data(col1, col2, col3); +---------------+---------------+---------+ |first(col1) |last(col2) |max(col3)| +---------------+---------------+---------+ |16 years 2 days|16 years 2 days|3 | +---------------+---------------+---------+ ``` These two bugs could get exercised during codegen fallback. No. New unit tests. Closes #39117 from bersprockets/unsafe_interval_issue. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 7f153842041d66e9cf0465262f4458cfffda4f43) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 20 December 2022, 00:31:15 UTC |
| d054101 | Josh Rosen | 16 December 2022, 10:16:25 UTC | [SPARK-41541][SQL] Fix call to wrong child method in SQLShuffleWriteMetricsReporter.decRecordsWritten() ### What changes were proposed in this pull request? This PR fixes a bug in `SQLShuffleWriteMetricsReporter.decRecordsWritten()`: this method is supposed to call the delegate `metricsReporter`'s `decRecordsWritten` method but due to a typo it calls the `decBytesWritten` method instead. ### Why are the changes needed? One of the situations where `decRecordsWritten(v)` is called while reverting shuffle writes from failed/canceled tasks. Due to the mixup in these calls, the _recordsWritten_ metric ends up being _v_ records too high (since it wasn't decremented) and the _bytesWritten_ metric ends up _v_ records too low, causing some failed tasks' write metrics to look like > {"Shuffle Bytes Written":-2109,"Shuffle Write Time":2923270,"Shuffle Records Written":2109} instead of > {"Shuffle Bytes Written":0,"Shuffle Write Time":2923270,"Shuffle Records Written":0} ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests / manual code review only. The existing SQLMetricsSuite contains end-to-end tests which exercise this class but they don't exercise the decrement path because they don't exercise the shuffle write failure paths. In theory I could add new unit tests but I don't think the ROI is worth it given that this class is intended to be a simple wrapper and it ~never changes (this PR is the first change to the file in 5 years). Closes #39086 from JoshRosen/SPARK-41541. Authored-by: Josh Rosen <joshrosen@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit ed27121607cf526e69420a1faff01383759c9134) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 16 December 2022, 10:16:51 UTC |
| 54a1c0f | yangjie01 | 15 December 2022, 08:39:44 UTC | [SPARK-41522][BUILD] Pin `versions-maven-plugin` to 2.13.0 to recover `test-dependencies.sh` ### What changes were proposed in this pull request? This pr aims to pin `versions-maven-plugin` to 2.13.0 to recover `test-dependencies.sh` and make GA pass , this pr should revert after we know how to use version 2.14.0. ### Why are the changes needed? `dev/test-dependencies.sh` always use latest `versions-maven-plugin` version, and `versions-maven-plugin` 2.14.0 has not set the version of the sub-module. Run: ``` build/mvn -q versions:set -DnewVersion=spark-928034 -DgenerateBackupPoms=false ``` **2.14.0** ``` + git status On branch test-ci Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: assembly/pom.xml modified: core/pom.xml modified: examples/pom.xml modified: graphx/pom.xml modified: hadoop-cloud/pom.xml modified: launcher/pom.xml modified: mllib-local/pom.xml modified: mllib/pom.xml modified: pom.xml modified: repl/pom.xml modified: streaming/pom.xml modified: tools/pom.xml ``` **2.13.0** ``` + git status On branch test-ci Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: assembly/pom.xml modified: common/kvstore/pom.xml modified: common/network-common/pom.xml modified: common/network-shuffle/pom.xml modified: common/network-yarn/pom.xml modified: common/sketch/pom.xml modified: common/tags/pom.xml modified: common/unsafe/pom.xml modified: connector/avro/pom.xml modified: connector/connect/common/pom.xml modified: connector/connect/server/pom.xml modified: connector/docker-integration-tests/pom.xml modified: connector/kafka-0-10-assembly/pom.xml modified: connector/kafka-0-10-sql/pom.xml modified: connector/kafka-0-10-token-provider/pom.xml modified: connector/kafka-0-10/pom.xml modified: connector/kinesis-asl-assembly/pom.xml modified: connector/kinesis-asl/pom.xml modified: connector/protobuf/pom.xml modified: connector/spark-ganglia-lgpl/pom.xml modified: core/pom.xml modified: dev/test-dependencies.sh modified: examples/pom.xml modified: graphx/pom.xml modified: hadoop-cloud/pom.xml modified: launcher/pom.xml modified: mllib-local/pom.xml modified: mllib/pom.xml modified: pom.xml modified: repl/pom.xml modified: resource-managers/kubernetes/core/pom.xml modified: resource-managers/kubernetes/integration-tests/pom.xml modified: resource-managers/mesos/pom.xml modified: resource-managers/yarn/pom.xml modified: sql/catalyst/pom.xml modified: sql/core/pom.xml modified: sql/hive-thriftserver/pom.xml modified: sql/hive/pom.xml modified: streaming/pom.xml modified: tools/pom.xml ``` Therefore, the following compilation error will occur when using 2.14.0. ``` 2022-12-15T02:37:35.5536924Z [ERROR] [ERROR] Some problems were encountered while processing the POMs: 2022-12-15T02:37:35.5538469Z [FATAL] Non-resolvable parent POM for org.apache.spark:spark-sketch_2.12:3.4.0-SNAPSHOT: Could not find artifact org.apache.spark:spark-parent_2.12:pom:3.4.0-SNAPSHOT and 'parent.relativePath' points at wrong local POM line 22, column 11 ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GitHub Actions Closes #39067 from LuciferYang/test-ci. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit bfe1af9a720ed235937a0fdf665376ffff7cce54) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 15 December 2022, 08:40:36 UTC |
| c6bd820 | Hyukjin Kwon | 13 December 2022, 14:34:09 UTC | [SPARK-41360][CORE][BUILD][FOLLOW-UP] Exclude BlockManagerMessages.RegisterBlockManager in MiMa This PR is a followup of https://github.com/apache/spark/pull/38876 that excludes BlockManagerMessages.RegisterBlockManager in MiMa compatibility check. It fails in MiMa check presumably with Scala 2.13 in other branches. Should be safer to exclude them all in the affected branches. No, dev-only. Filters copied from error messages. Will monitor the build in other branches. Closes #39052 from HyukjinKwon/SPARK-41360-followup. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit a2ceff29f9d1c0133fa0c8274fa84c43106e90f0) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 13 December 2022, 14:38:43 UTC |
| 63a7b0b | Yi Wu | 12 December 2022, 19:29:37 UTC | [SPARK-41360][CORE] Avoid BlockManager re-registration if the executor has been lost ### What changes were proposed in this pull request? This PR majorly proposes to reject the block manager re-registration if the executor has been already considered lost/dead from the scheduler backend. Along with the major proposal, this PR also includes a few other changes: * Only post `SparkListenerBlockManagerAdded` event when the registration succeeds * Return an "invalid" executor id when the re-registration fails * Do not report all blocks when the re-registration fails ### Why are the changes needed? BlockManager re-registration from lost executor (terminated/terminating executor or orphan executor) has led to some known issues, e.g., false-active executor shows up in UP (SPARK-35011), [block fetching to the dead executor](https://github.com/apache/spark/pull/32114#issuecomment-899979045). And since there's no re-registration from the lost executor itself, it's meaningless to have BlockManager re-registration when the executor is already lost. Regarding the corner case where the re-registration event comes earlier before the lost executor is actually removed from the scheduler backend, I think it is not possible. Because re-registration will only be required when the BlockManager doesn't see the block manager in `blockManagerInfo`. And the block manager will only be removed from `blockManagerInfo` whether when the executor is already know lost or removed by the driver proactively. So the executor should always be removed from the scheduler backend first before the re-registration event comes. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test Closes #38876 from Ngone51/fix-blockmanager-reregister. Authored-by: Yi Wu <yi.wu@databricks.com> Signed-off-by: Mridul Muralidharan <mridul<at>gmail.com> (cherry picked from commit c3f46d5c6d69a9b21473dae6d86dee53833dfd52) Signed-off-by: Mridul Muralidharan <mridulatgmail.com> | 12 December 2022, 19:30:30 UTC |
| 18d1412 | Hui An | 12 December 2022, 10:17:49 UTC | [SPARK-41448] Make consistent MR job IDs in FileBatchWriter and FileFormatWriter ### What changes were proposed in this pull request? Make consistent MR job IDs in FileBatchWriter and FileFormatWriter ### Why are the changes needed? [SPARK-26873](https://issues.apache.org/jira/browse/SPARK-26873) fix the consistent issue for FileFormatWriter, but [SPARK-33402](https://issues.apache.org/jira/browse/SPARK-33402) break this requirement by introducing a random long, we need to address this to expects identical task IDs across attempts for correctness. Also FileBatchWriter doesn't follow this requirement, need to fix it as well. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? Closes #38980 from boneanxs/SPARK-41448. Authored-by: Hui An <hui.an@shopee.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 7801666f3b5ea3bfa0f95571c1d68147ce5240ec) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 12 December 2022, 10:20:44 UTC |
| 3beab1f | Cheng Pan | 09 December 2022, 18:17:36 UTC | [SPARK-41376][CORE][3.2] Correct the Netty preferDirectBufs check logic on executor start ### What changes were proposed in this pull request? Backport #38901 to branch-3.2. Fix the condition for judging Netty prefer direct memory on executor start, the logic should match `org.apache.spark.network.client.TransportClientFactory`. ### Why are the changes needed? The check logical was added in SPARK-27991, the original intention is to avoid potential Netty OOM issue when Netty uses direct memory to consume shuffle data, but the condition is not sufficient, this PR updates the logic to match `org.apache.spark.network.client.TransportClientFactory` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manual testing. Closes #38982 from pan3793/SPARK-41376-3.2. Authored-by: Cheng Pan <chengpan@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 09 December 2022, 18:17:36 UTC |
| 43402fd | Yikun Jiang | 09 December 2022, 14:15:48 UTC | [SPARK-40270][PS][FOLLOWUP][3.2] Skip test_style when pandas <1.3.0 ### What changes were proposed in this pull request? According to https://pandas.pydata.org/docs/reference/api/pandas.io.formats.style.Styler.to_latex.html: `pandas.io.formats.style.Styler.to_latex` introduced since 1.3.0, so before panda 1.3.0, should skip the check ``` ERROR [0.180s]: test_style (pyspark.pandas.tests.test_dataframe.DataFrameTest) ---------------------------------------------------------------------- Traceback (most recent call last): File "/__w/spark/spark/python/pyspark/pandas/tests/test_dataframe.py", line 5795, in test_style check_style() File "/__w/spark/spark/python/pyspark/pandas/tests/test_dataframe.py", line 5793, in check_style self.assert_eq(pdf_style.to_latex(), psdf_style.to_latex()) AttributeError: 'Styler' object has no attribute 'to_latex' ``` Related: https://github.com/apache/spark/commit/58375a86e6ff49c5bcee49939fbd98eb848ae59f ### Why are the changes needed? This test break the 3.2 branch pyspark test (with python 3.6 + pandas 1.1.x), so I think better add the `skipIf` it. See also https://github.com/apache/spark/pull/38982#issuecomment-1343923114 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? CI passed Closes #39008 from Yikun/branch-3.2-style-check. Authored-by: Yikun Jiang <yikunkero@gmail.com> Signed-off-by: Yikun Jiang <yikunkero@gmail.com> | 09 December 2022, 14:15:48 UTC |
| 556a3ca | Bruce Robbins | 09 December 2022, 12:44:45 UTC | [SPARK-41395][SQL] `InterpretedMutableProjection` should use `setDecimal` to set null values for decimals in an unsafe row Change `InterpretedMutableProjection` to use `setDecimal` rather than `setNullAt` to set null values for decimals in unsafe rows. The following returns the wrong answer: ``` set spark.sql.codegen.wholeStage=false; set spark.sql.codegen.factoryMode=NO_CODEGEN; select max(col1), max(col2) from values (cast(null as decimal(27,2)), cast(null as decimal(27,2))), (cast(77.77 as decimal(27,2)), cast(245.00 as decimal(27,2))) as data(col1, col2); +---------+---------+ |max(col1)|max(col2)| +---------+---------+ |null |239.88 | +---------+---------+ ``` This is because `InterpretedMutableProjection` inappropriately uses `InternalRow#setNullAt` on unsafe rows to set null for decimal types with precision > `Decimal.MAX_LONG_DIGITS`. When `setNullAt` is used, the pointer to the decimal's storage area in the variable length region gets zeroed out. Later, when `InterpretedMutableProjection` calls `setDecimal` on that field, `UnsafeRow#setDecimal` picks up the zero pointer and stores decimal data on top of the null-tracking bit set. Later updates to the null-tracking bit set (e.g., calls to `setNotNullAt`) further corrupt the decimal data (turning 245.00 into 239.88, for example). The stomping of the null-tracking bit set also can make non-null fields appear null (turning 77.77 into null, for example). This bug can manifest for end-users after codegen fallback (say, if an expression's generated code fails to compile). [Codegen for mutable projection](https://github.com/apache/spark/blob/89b2ee27d258dec8fe265fa862846e800a374d8e/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/codegen/CodeGenerator.scala#L1729) uses `mutableRow.setDecimal` for null decimal values regardless of precision or the type for `mutableRow`, so this PR does the same. No. New unit tests. Closes #38923 from bersprockets/unsafe_decimal_issue. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit fec210b36be22f187b51b67970960692f75ac31f) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 09 December 2022, 12:46:45 UTC |
| aac8d0a | Dongjoon Hyun | 05 December 2022, 09:09:50 UTC | [SPARK-41388][K8S] `getReusablePVCs` should ignore recently created PVCs in the previous batch This PR aims to prevent `getReusablePVCs` from choosing recently created PVCs in the very previous batch by excluding newly created PVCs whose creation time is within `spark.kubernetes.allocation.batch.delay`. In case of slow K8s control plane situation where `spark.kubernetes.allocation.batch.delay` is too short relatively or `spark.kubernetes.executor.enablePollingWithResourceVersion=true` is used, `onNewSnapshots` may not return the full list of executor pods created by the previous batch. This sometimes makes Spark driver think the PVCs in the previous batch are reusable for the next batch. No. Pass the CIs with the newly created test case. Closes #38912 from dongjoon-hyun/SPARK-41388. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit e234cd8276a603ab8a191dd078b11c605b22a50c) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 651f5da7d58554ebd4b15c5b0204acf2d08ca439) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 05 December 2022, 09:21:44 UTC |
| 44b6db8 | Lingyun Yuan | 30 November 2022, 19:47:15 UTC | [SPARK-41327][CORE] Fix `SparkStatusTracker.getExecutorInfos` by switch On/OffHeapStorageMemory info ### What changes were proposed in this pull request? This PR aims to fix `SparkStatusTracker.getExecutorInfos` to return a correct `on/offHeapStorageMemory`. ### Why are the changes needed? `SparkExecutorInfoImpl` used the following parameter order. https://github.com/apache/spark/blob/54c57fa86906f933e089a33ef25ae0c053769cc8/core/src/main/scala/org/apache/spark/StatusAPIImpl.scala#L42-L45 SPARK-20659 introduced a bug with wrong parameter order at Apache Spark 2.4.0. - https://github.com/apache/spark/pull/20546/files#diff-7daca909d33ff8e9b4938e2b4a4aaa1558fbdf4604273b9e38cce32c55e1508cR118-R121 ### Does this PR introduce _any_ user-facing change? Yes. ### How was this patch tested? Manually review. Closes #38843 from ylybest/master. Lead-authored-by: Lingyun Yuan <ylybest@gmail.com> Co-authored-by: ylybest <119458293+ylybest@users.noreply.github.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 388824c448804161b076507f0f39ef0596e0a0bf) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 30 November 2022, 19:48:11 UTC |
| b95a771 | sychen | 30 November 2022, 03:52:43 UTC | [SPARK-40987][CORE] `BlockManager#removeBlockInternal` should ensure the lock is unlocked gracefully ### What changes were proposed in this pull request? `BlockManager#removeBlockInternal` should ensure the lock is unlocked gracefully. `removeBlockInternal` tries to call `removeBlock` in the finally block. ### Why are the changes needed? When the driver submits a job, `DAGScheduler` calls `sc.broadcast(taskBinaryBytes)`. `TorrentBroadcast#writeBlocks` may fail due to disk problems during `blockManager#putBytes`. `BlockManager#doPut` calls `BlockManager#removeBlockInternal` to clean up the block. `BlockManager#removeBlockInternal` calls `DiskStore#remove` to clean up blocks on disk. `DiskStore#remove` will try to create the directory because the directory does not exist, and an exception will be thrown at this time. `BlockInfoManager#blockInfoWrappers` block info and lock not removed. The catch block in `TorrentBroadcast#writeBlocks` will call `blockManager.removeBroadcast` to clean up the broadcast. Because the block lock in `BlockInfoManager#blockInfoWrappers` is not released, the `dag-scheduler-event-loop` thread of `DAGScheduler` will wait forever. ``` 22/11/01 18:27:48 WARN BlockManager: Putting block broadcast_0_piece0 failed due to exception java.io.IOException: XXXXX. 22/11/01 18:27:48 ERROR TorrentBroadcast: Store broadcast broadcast_0 fail, remove all pieces of the broadcast ``` ``` "dag-scheduler-event-loop" #54 daemon prio=5 os_prio=31 tid=0x00007fc98e3fa800 nid=0x7203 waiting on condition [0x0000700008c1e000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000007add3d8c8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039) at org.apache.spark.storage.BlockInfoManager.$anonfun$acquireLock$1(BlockInfoManager.scala:221) at org.apache.spark.storage.BlockInfoManager.$anonfun$acquireLock$1$adapted(BlockInfoManager.scala:214) at org.apache.spark.storage.BlockInfoManager$$Lambda$3038/1307533457.apply(Unknown Source) at org.apache.spark.storage.BlockInfoWrapper.withLock(BlockInfoManager.scala:105) at org.apache.spark.storage.BlockInfoManager.acquireLock(BlockInfoManager.scala:214) at org.apache.spark.storage.BlockInfoManager.lockForWriting(BlockInfoManager.scala:293) at org.apache.spark.storage.BlockManager.removeBlock(BlockManager.scala:1979) at org.apache.spark.storage.BlockManager.$anonfun$removeBroadcast$3(BlockManager.scala:1970) at org.apache.spark.storage.BlockManager.$anonfun$removeBroadcast$3$adapted(BlockManager.scala:1970) at org.apache.spark.storage.BlockManager$$Lambda$3092/1241801156.apply(Unknown Source) at scala.collection.Iterator.foreach(Iterator.scala:943) at scala.collection.Iterator.foreach$(Iterator.scala:943) at scala.collection.AbstractIterator.foreach(Iterator.scala:1431) at org.apache.spark.storage.BlockManager.removeBroadcast(BlockManager.scala:1970) at org.apache.spark.broadcast.TorrentBroadcast.writeBlocks(TorrentBroadcast.scala:179) at org.apache.spark.broadcast.TorrentBroadcast.<init>(TorrentBroadcast.scala:99) at org.apache.spark.broadcast.TorrentBroadcastFactory.newBroadcast(TorrentBroadcastFactory.scala:38) at org.apache.spark.broadcast.BroadcastManager.newBroadcast(BroadcastManager.scala:78) at org.apache.spark.SparkContext.broadcastInternal(SparkContext.scala:1538) at org.apache.spark.SparkContext.broadcast(SparkContext.scala:1520) at org.apache.spark.scheduler.DAGScheduler.submitMissingTasks(DAGScheduler.scala:1539) at org.apache.spark.scheduler.DAGScheduler.submitStage(DAGScheduler.scala:1355) at org.apache.spark.scheduler.DAGScheduler.handleJobSubmitted(DAGScheduler.scala:1297) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2929) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2921) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2910) at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49) ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Throw an exception before `Files.createDirectory` to simulate disk problems. DiskBlockManager#getFile ```java if (filename.contains("piece")) { throw new java.io.IOException("disk issue") } Files.createDirectory(path) ``` ``` ./bin/spark-shell ``` ```scala spark.sql("select 1").collect() ``` ``` 22/11/24 19:29:58 WARN BlockManager: Putting block broadcast_0_piece0 failed due to exception java.io.IOException: disk issue. 22/11/24 19:29:58 ERROR TorrentBroadcast: Store broadcast broadcast_0 fail, remove all pieces of the broadcast org.apache.spark.SparkException: Job aborted due to stage failure: Task serialization failed: java.io.IOException: disk issue java.io.IOException: disk issue at org.apache.spark.storage.DiskBlockManager.getFile(DiskBlockManager.scala:109) at org.apache.spark.storage.DiskBlockManager.containsBlock(DiskBlockManager.scala:160) at org.apache.spark.storage.DiskStore.contains(DiskStore.scala:153) at org.apache.spark.storage.BlockManager.org$apache$spark$storage$BlockManager$$getCurrentBlockStatus(BlockManager.scala:879) at org.apache.spark.storage.BlockManager.removeBlockInternal(BlockManager.scala:1998) at org.apache.spark.storage.BlockManager.org$apache$spark$storage$BlockManager$$doPut(BlockManager.scala:1484) at org.apache.spark.storage.BlockManager$BlockStoreUpdater.save(BlockManager.scala:378) at org.apache.spark.storage.BlockManager.putBytes(BlockManager.scala:1419) at org.apache.spark.broadcast.TorrentBroadcast.$anonfun$writeBlocks$1(TorrentBroadcast.scala:170) at org.apache.spark.broadcast.TorrentBroadcast.$anonfun$writeBlocks$1$adapted(TorrentBroadcast.scala:164) at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36) at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33) at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:198) at org.apache.spark.broadcast.TorrentBroadcast.writeBlocks(TorrentBroadcast.scala:164) at org.apache.spark.broadcast.TorrentBroadcast.<init>(TorrentBroadcast.scala:99) at org.apache.spark.broadcast.TorrentBroadcastFactory.newBroadcast(TorrentBroadcastFactory.scala:38) at org.apache.spark.broadcast.BroadcastManager.newBroadcast(BroadcastManager.scala:78) at org.apache.spark.SparkContext.broadcastInternal(SparkContext.scala:1538) at org.apache.spark.SparkContext.broadcast(SparkContext.scala:1520) at org.apache.spark.scheduler.DAGScheduler.submitMissingTasks(DAGScheduler.scala:1539) at org.apache.spark.scheduler.DAGScheduler.submitStage(DAGScheduler.scala:1355) at org.apache.spark.scheduler.DAGScheduler.handleJobSubmitted(DAGScheduler.scala:1297) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2929) ``` Closes #38467 from cxzl25/SPARK-40987. Authored-by: sychen <sychen@ctrip.com> Signed-off-by: Mridul <mridul<at>gmail.com> (cherry picked from commit bbab0afb9a6919694cda5b9d490203af93a23460) Signed-off-by: Mridul <mridulatgmail.com> | 30 November 2022, 03:54:28 UTC |
| 1945045 | John Caveman | 28 November 2022, 14:25:00 UTC | [SPARK-41254][YARN] bugfix wrong usage when check YarnAllocator.rpIdToYarnResource key existence ### What changes were proposed in this pull request? bugfix, a misuse of ConcurrentHashMap.contains causing map YarnAllocator.rpIdToYarnResource always updated ### Why are the changes needed? It causing duplicated log during yarn resource allocation and unnecessary object creation and gc ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests Closes #38790 from CavemanIV/SPARK-41254. Authored-by: John Caveman <selnteer@gmail.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit bccfe5bca600b3091ea93b4c5d6437af8381973f) Signed-off-by: Sean Owen <srowen@gmail.com> | 28 November 2022, 14:25:21 UTC |
| 3b9cca7 | Weichen Xu | 19 November 2022, 09:23:20 UTC | [SPARK-41188][CORE][ML] Set executorEnv OMP_NUM_THREADS to be spark.task.cpus by default for spark executor JVM processes Signed-off-by: Weichen Xu <weichen.xudatabricks.com> ### What changes were proposed in this pull request? Set executorEnv OMP_NUM_THREADS to be spark.task.cpus by default for spark executor JVM processes. ### Why are the changes needed? This is for limiting the thread number for OpenBLAS routine to the number of cores assigned to this executor because some spark ML algorithms calls OpenBlAS via netlib-java, e.g.: Spark ALS estimator training calls LAPACK API `dppsv` (internally it will call BLAS lib), if it calls OpenBLAS lib, by default OpenBLAS will try to use all CPU cores. But spark will launch multiple spark tasks on a spark worker, and each spark task might call `dppsv` API at the same time, and each call internally it will create multiple threads (threads number equals to CPU cores), this causes CPU oversubscription. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manually. Closes #38699 from WeichenXu123/SPARK-41188. Authored-by: Weichen Xu <weichen.xu@databricks.com> Signed-off-by: Weichen Xu <weichen.xu@databricks.com> (cherry picked from commit 82a41d8ca273e7a93333268324c6958f8bb14d9e) Signed-off-by: Weichen Xu <weichen.xu@databricks.com> | 19 November 2022, 09:24:53 UTC |
| b9a0261 | Chao Sun | 14 November 2022, 16:01:34 UTC | Preparing development version 3.2.4-SNAPSHOT | 14 November 2022, 16:01:34 UTC |
| b53c341 | Chao Sun | 14 November 2022, 16:01:29 UTC | Preparing Spark release v3.2.3-rc1 | 14 November 2022, 16:01:29 UTC |
| ddccb6f | Chao Sun | 14 November 2022, 06:27:12 UTC | [SPARK-41091][BUILD][3.2] Fix Docker release tool for branch-3.2 ### What changes were proposed in this pull request? This tries to fix `do-release-docker.sh` for branch-3.2. ### Why are the changes needed? Currently the following error will occur if running the script in `branch-3.2`: ``` #5 917.4 g++ -std=gnu++14 -shared -L/usr/lib/R/lib -Wl,-Bsymbolic-functions -Wl,-z,relro -o testthat.so init.o reassign.o test-catch.o test-example.o test-runner.o -L/usr/lib/R/lib -lR #5 917.5 installing to /usr/local/lib/R/site-library/00LOCK-testthat/00new/testthat/libs #5 917.5 ** R #5 917.5 ** inst #5 917.5 ** byte-compile and prepare package for lazy loading #5 924.4 ** help #5 924.6 *** installing help indices #5 924.7 *** copying figures #5 924.7 ** building package indices #5 924.9 ** installing vignettes #5 924.9 ** testing if installed package can be loaded from temporary location #5 925.1 ** checking absolute paths in shared objects and dynamic libraries #5 925.1 ** testing if installed package can be loaded from final location #5 925.5 ** testing if installed package keeps a record of temporary installation path #5 925.5 * DONE (testthat) #5 925.8 ERROR: dependency 'pkgdown' is not available for package 'devtools' #5 925.8 * removing '/usr/local/lib/R/site-library/devtools' #5 925.8 #5 925.8 The downloaded source packages are in #5 925.8 '/tmp/Rtmp3nJI60/downloaded_packages' #5 925.8 Warning messages: #5 925.8 1: In install.packages(c("curl", "xml2", "httr", "devtools", "testthat", : #5 925.8 installation of package 'textshaping' had non-zero exit status #5 925.8 2: In install.packages(c("curl", "xml2", "httr", "devtools", "testthat", : #5 925.8 installation of package 'ragg' had non-zero exit status #5 925.8 3: In install.packages(c("curl", "xml2", "httr", "devtools", "testthat", : #5 925.8 installation of package 'pkgdown' had non-zero exit status #5 925.8 4: In install.packages(c("curl", "xml2", "httr", "devtools", "testthat", : #5 925.8 installation of package 'devtools' had non-zero exit status #5 926.0 Error in loadNamespace(x) : there is no package called 'devtools' #5 926.0 Calls: loadNamespace -> withRestarts -> withOneRestart -> doWithOneRestart #5 926.0 Execution halted ``` The same error doesn't happen on master. I checked the diff between the two and it seems the following line: ``` $APT_INSTALL libfontconfig1-dev libharfbuzz-dev libfribidi-dev libfreetype6-dev libpng-dev libtiff5-dev libjpeg-dev && \ ``` introduced in https://github.com/apache/spark/pull/34728 made the difference. I verified that after adding the line, `do-release-docker.sh` (dry run mode) was able to finish successfully. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manually Closes #38643 from sunchao/fix-docker-release. Authored-by: Chao Sun <sunchao@apple.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 14 November 2022, 06:27:12 UTC |
| f0f83b5 | Enrico Minack | 09 November 2022, 07:59:54 UTC | [SPARK-40588] FileFormatWriter materializes AQE plan before accessing outputOrdering The `FileFormatWriter` materializes an `AdaptiveQueryPlan` before accessing the plan's `outputOrdering`. This is required for Spark 3.0 to 3.3. Spark 3.4 does not need this because `FileFormatWriter` gets the final plan. `FileFormatWriter` enforces an ordering if the written plan does not provide that ordering. An `AdaptiveQueryPlan` does not know its final ordering (Spark 3.0 to 3.3), in which case `FileFormatWriter` enforces the ordering (e.g. by column `"a"`) even if the plan provides a compatible ordering (e.g. by columns `"a", "b"`). In case of spilling, that order (e.g. by columns `"a", "b"`) gets broken (see SPARK-40588). This fixes SPARK-40588, which was introduced in 3.0. This restores behaviour from Spark 2.4. The final plan that is written to files cannot be extracted from `FileFormatWriter`. The bug explained in [SPARK-40588](https://issues.apache.org/jira/browse/SPARK-40588) can only be asserted on the result files when spilling occurs. This is very hard to control in an unit test scenario. Therefore, this was tested manually. The [example to reproduce this issue](https://issues.apache.org/jira/browse/SPARK-40588?focusedCommentId=17621032&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-17621032) given in SPARK-40588 now produces sorted files. The actual plan written into the files changed from ``` Sort [input[0, bigint, false] ASC NULLS FIRST], false, 0 +- AdaptiveSparkPlan isFinalPlan=false +- Sort [day#2L ASC NULLS FIRST, id#4L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(day#2L, 2), REPARTITION_BY_NUM, [id=#30] +- BroadcastNestedLoopJoin BuildLeft, Inner :- BroadcastExchange IdentityBroadcastMode, [id=#28] : +- Project [id#0L AS day#2L] : +- Range (0, 2, step=1, splits=2) +- Range (0, 10000000, step=1, splits=2) ``` where `FileFormatWriter` enforces order with `Sort [input[0, bigint, false] ASC NULLS FIRST], false, 0`, to ``` *(3) Sort [day#2L ASC NULLS FIRST, id#4L ASC NULLS FIRST], false, 0 +- AQEShuffleRead coalesced +- ShuffleQueryStage 1 +- Exchange hashpartitioning(day#2L, 200), REPARTITION_BY_COL, [id=#68] +- *(2) BroadcastNestedLoopJoin BuildLeft, Inner :- BroadcastQueryStage 0 : +- BroadcastExchange IdentityBroadcastMode, [id=#42] : +- *(1) Project [id#0L AS day#2L] : +- *(1) Range (0, 2, step=1, splits=2) +- *(2) Range (0, 1000000, step=1, splits=2) ``` where the sort given by the user is the outermost sort now. Closes #38358 from EnricoMi/branch-3.3-materialize-aqe-plan. Authored-by: Enrico Minack <github@enrico.minack.dev> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit f0cad7ad6c2618d2d0d8c8598bbd54c2ca366b6b) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 09 November 2022, 08:01:27 UTC |
| f4ebe8f | Bruce Robbins | 09 November 2022, 01:29:11 UTC | [SPARK-41035][SQL] Don't patch foldable children of aggregate functions in `RewriteDistinctAggregates` `RewriteDistinctAggregates` doesn't typically patch foldable children of the distinct aggregation functions except in one odd case (and seemingly by accident). This PR extends the policy of not patching foldables to that odd case. This query produces incorrect results: ``` select a, count(distinct 100) as cnt1, count(distinct b, 100) as cnt2 from values (1, 2), (4, 5) as data(a, b) group by a; +---+----+----+ |a |cnt1|cnt2| +---+----+----+ |1 |1 |0 | |4 |1 |0 | +---+----+----+ ``` The values for `cnt2` should be 1 and 1 (not 0 and 0). If you change the literal used in the first aggregate function, the second aggregate function now works correctly: ``` select a, count(distinct 101) as cnt1, count(distinct b, 100) as cnt2 from values (1, 2), (4, 5) as data(a, b) group by a; +---+----+----+ |a |cnt1|cnt2| +---+----+----+ |1 |1 |1 | |4 |1 |1 | +---+----+----+ ``` The bug is in the rule `RewriteDistinctAggregates`. When a distinct aggregation has only foldable children, `RewriteDistinctAggregates` uses the first child as the grouping key (_grouping key_ in this context means the function children of distinct aggregate functions: `RewriteDistinctAggregates` groups distinct aggregations by function children to determine the `Expand` projections it needs to create). Therefore, the first foldable child gets included in the `Expand` projection associated with the aggregation, with a corresponding output attribute that is also included in the map for patching aggregate functions in the final aggregation. The `Expand` projections for all other distinct aggregate groups will have `null` in the slot associated with that output attribute. If the same foldable expression is used in a distinct aggregation associated with a different group, `RewriteDistinctAggregates` will improperly patch the associated aggregate function to use the previous aggregation's output attribute. Since the output attribute is associated with a different group, the value of that slot in the `Expand` projection will always be `null`. In the example above, `count(distinct 100) as cnt1` is the aggregation with only foldable children, and `count(distinct b, 100) as cnt2` is the aggregation that gets inappropriately patched with the wrong group's output attribute. As a result `count(distinct b, 100) as cnt2` (from the first example above) essentially becomes `count(distinct b, null) as cnt2`, which is always zero. `RewriteDistinctAggregates` doesn't typically patch foldable children of the distinct aggregation functions in the final aggregation. It potentially patches foldable expressions only when there is a distinct aggregation with only foldable children, and even then it doesn't patch the aggregation that has only foldable children, but instead some other unlucky aggregate function that happened to use the same foldable expression. This PR skips patching any foldable expressions in the aggregate functions to avoid patching an aggregation with a different group's output attribute. No. New unit test. Closes #38565 from bersprockets/distinct_literal_issue. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 0add57a1c0290a158666027afb3e035728d2dcee) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 09 November 2022, 01:42:38 UTC |
| b834c3f | attilapiros | 05 November 2022, 12:29:02 UTC | [SPARK-32380][SQL] Fixing access of HBase table via Hive from Spark This is an update of https://github.com/apache/spark/pull/29178 which was closed because the root cause of the error was just vaguely defined there but here I will give an explanation why `HiveHBaseTableInputFormat` does not work well with the `NewHadoopRDD` (see in the next section). The PR modify `TableReader.scala` to create `OldHadoopRDD` when input format is 'org.apache.hadoop.hive.hbase.HiveHBaseTableInputFormat'. - environments (Cloudera distribution 7.1.7.SP1): hadoop 3.1.1 hive 3.1.300 spark 3.2.1 hbase 2.2.3 With the `NewHadoopRDD` the following exception is raised: ``` java.io.IOException: Cannot create a record reader because of a previous error. Please look at the previous logs lines from the task's full log for more details. at org.apache.hadoop.hbase.mapreduce.TableInputFormatBase.getSplits(TableInputFormatBase.java:253) at org.apache.spark.rdd.NewHadoopRDD.getPartitions(NewHadoopRDD.scala:131) at org.apache.spark.rdd.RDD.$anonfun$partitions$2(RDD.scala:300) at scala.Option.getOrElse(Option.scala:189) at org.apache.spark.rdd.RDD.partitions(RDD.scala:296) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.$anonfun$partitions$2(RDD.scala:300) at scala.Option.getOrElse(Option.scala:189) at org.apache.spark.rdd.RDD.partitions(RDD.scala:296) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.$anonfun$partitions$2(RDD.scala:300) at scala.Option.getOrElse(Option.scala:189) at org.apache.spark.rdd.RDD.partitions(RDD.scala:296) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.$anonfun$partitions$2(RDD.scala:300) at scala.Option.getOrElse(Option.scala:189) at org.apache.spark.rdd.RDD.partitions(RDD.scala:296) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.$anonfun$partitions$2(RDD.scala:300) at scala.Option.getOrElse(Option.scala:189) at org.apache.spark.rdd.RDD.partitions(RDD.scala:296) at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:446) at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:429) at org.apache.spark.sql.execution.CollectLimitExec.executeCollect(limit.scala:48) at org.apache.spark.sql.Dataset.collectFromPlan(Dataset.scala:3715) at org.apache.spark.sql.Dataset.$anonfun$head$1(Dataset.scala:2728) at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3706) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:103) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64) at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3704) at org.apache.spark.sql.Dataset.head(Dataset.scala:2728) at org.apache.spark.sql.Dataset.take(Dataset.scala:2935) at org.apache.spark.sql.Dataset.getRows(Dataset.scala:287) at org.apache.spark.sql.Dataset.showString(Dataset.scala:326) at org.apache.spark.sql.Dataset.show(Dataset.scala:806) at org.apache.spark.sql.Dataset.show(Dataset.scala:765) at org.apache.spark.sql.Dataset.show(Dataset.scala:774) ... 47 elided Caused by: java.lang.IllegalStateException: The input format instance has not been properly initialized. Ensure you call initializeTable either in your constructor or initialize method at org.apache.hadoop.hbase.mapreduce.TableInputFormatBase.getTable(TableInputFormatBase.java:557) at org.apache.hadoop.hbase.mapreduce.TableInputFormatBase.getSplits(TableInputFormatBase.java:248) ... 86 more ``` There are two interfaces: - the new `org.apache.hadoop.mapreduce.InputFormat`: providing a one arg method `getSplits(JobContext context)` (returning `List<InputSplit>`) - the old `org.apache.hadoop.mapred.InputFormat`: providing a two arg method `getSplits(JobConf job, int numSplits)` (returning `InputSplit[]`) And in Hive both are implemented by `HiveHBaseTableInputFormat` but only the old method leads to required initialisation and this why `NewHadoopRDD` fails here. Here all the link refers latest commits of the master branches for the mentioned components at the time of writing this description (to get the right line numbers in the future too as `master` itself is a moving target). Spark in `NewHadoopRDD` uses the new interface providing the one arg method: https://github.com/apache/spark/blob/5556cfc59aa97a3ad4ea0baacebe19859ec0bcb7/core/src/main/scala/org/apache/spark/rdd/NewHadoopRDD.scala#L136 Hive on the other hand binds the initialisation to the two args method coming from the old interface. See [Hive#getSplits](https://github.com/apache/hive/blob/fd029c5b246340058aee513980b8bf660aee0227/hbase-handler/src/java/org/apache/hadoop/hive/hbase/HiveHBaseTableInputFormat.java#L268): ``` Override public InputSplit[] getSplits(final JobConf jobConf, final int numSplits) throws IOException { ``` This calls `getSplitsInternal` which contains the [initialisation](https://github.com/apache/hive/blob/fd029c5b246340058aee513980b8bf660aee0227/hbase-handler/src/java/org/apache/hadoop/hive/hbase/HiveHBaseTableInputFormat.java#L299) too: ``` initializeTable(conn, tableName); ``` Interesting that Hive also uses the one arg method internally within the `getSplitsInternal` [here](https://github.com/apache/hive/blob/fd029c5b246340058aee513980b8bf660aee0227/hbase-handler/src/java/org/apache/hadoop/hive/hbase/HiveHBaseTableInputFormat.java#L356) but the initialisation done earlier. By calling the new interface method (what `NewHadoopRDD` does) the call goes straight to the HBase method: [org.apache.hadoop.hbase.mapreduce.TableInputFormatBase#getSplits](https://github.com/apache/hbase/blob/63cdd026f08cdde6ac0fde1342ffd050e8e02441/hbase-mapreduce/src/main/java/org/apache/hadoop/hbase/mapreduce/TableInputFormatBase.java#L230). Where there would be some `JobContext` based [initialisation](https://github.com/apache/hbase/blob/63cdd026f08cdde6ac0fde1342ffd050e8e02441/hbase-mapreduce/src/main/java/org/apache/hadoop/hbase/mapreduce/TableInputFormatBase.java#L234-L237) which by default is an [empty method](https://github.com/apache/hbase/blob/63cdd026f08cdde6ac0fde1342ffd050e8e02441/hbase-mapreduce/src/main/java/org/apache/hadoop/hbase/mapreduce/TableInputFormatBase.java#L628-L640): ```java /** * Handle subclass specific set up. Each of the entry points used by the MapReduce framework, * {link #createRecordReader(InputSplit, TaskAttemptContext)} and {link #getSplits(JobContext)}, * will call {link #initialize(JobContext)} as a convenient centralized location to handle * retrieving the necessary configuration information and calling * {link #initializeTable(Connection, TableName)}. Subclasses should implement their initialize * call such that it is safe to call multiple times. The current TableInputFormatBase * implementation relies on a non-null table reference to decide if an initialize call is needed, * but this behavior may change in the future. In particular, it is critical that initializeTable * not be called multiple times since this will leak Connection instances. */ protected void initialize(JobContext context) throws IOException { } ``` This is not overridden by Hive and hard to reason why we need that (its an internal Hive class) so it is easier to fix this in Spark. No. 1) create hbase table ``` hbase(main):001:0>create 'hbase_test1', 'cf1' hbase(main):001:0> put 'hbase_test', 'r1', 'cf1:c1', '123' ``` 2) create hive table related to hbase table hive> ``` CREATE EXTERNAL TABLE `hivetest.hbase_test`( `key` string COMMENT '', `value` string COMMENT '') ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe' STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ( 'hbase.columns.mapping'=':key,cf1:v1', 'serialization.format'='1') TBLPROPERTIES ( 'hbase.table.name'='hbase_test') ``` 3): spark-shell query hive table while data in HBase ``` scala> spark.sql("select * from hivetest.hbase_test").show() 22/11/05 01:14:16 WARN conf.HiveConf: HiveConf of name hive.masking.algo does not exist 22/11/05 01:14:16 WARN client.HiveClientImpl: Detected HiveConf hive.execution.engine is 'tez' and will be reset to 'mr' to disable useless hive logic Hive Session ID = f05b6866-86df-4d88-9eea-f1c45043bb5f +---+-----+ |key|value| +---+-----+ | r1| 123| +---+-----+ ``` Closes #38516 from attilapiros/SPARK-32380. Authored-by: attilapiros <piros.attila.zsolt@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 7009ef0510dae444c72e7513357e681b08379603) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 05 November 2022, 12:30:35 UTC |
| 5d62f47 | Bjørn Jørgensen | 03 November 2022, 22:05:37 UTC | [SPARK-40801][BUILD][3.2] Upgrade `Apache commons-text` to 1.10 ### What changes were proposed in this pull request? Upgrade Apache commons-text from 1.6 to 1.10.0 ### Why are the changes needed? [CVE-2022-42889](https://nvd.nist.gov/vuln/detail/CVE-2022-42889) this is a [9.8 CRITICAL](https://nvd.nist.gov/vuln-metrics/cvss/v3-calculator?name=CVE-2022-42889&vector=AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:H/A:H&version=3.1&source=NIST) ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass GA Closes #38352 from bjornjorgensen/patch-2. Lead-authored-by: Bjørn Jørgensen <bjornjorgensen@gmail.com> Co-authored-by: Bjørn <bjornjorgensen@gmail.com> Signed-off-by: Sean Owen <srowen@gmail.com> | 03 November 2022, 22:05:37 UTC |
| 1aef8b7 | Tobias Stadler | 03 November 2022, 17:34:04 UTC | [SPARK-40869][K8S] Resource name prefix should not start with a hyphen ### What changes were proposed in this pull request? Strip leading - from resource name prefix ### Why are the changes needed? leading - are not allowed for resource name prefix (especially spark.kubernetes.executor.podNamePrefix) ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test Closes #38331 from tobiasstadler/fix-SPARK-40869. Lead-authored-by: Tobias Stadler <ts.stadler@gmx.de> Co-authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 7f3b5987de1f79434a861408e6c8bf55c5598031) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 03 November 2022, 17:34:25 UTC |
| b9d22ac | yangjie01 | 01 November 2022, 23:10:36 UTC | [MINOR][BUILD] Correct the `files` contend in `checkstyle-suppressions.xml` ### What changes were proposed in this pull request? The pr aims to change the suppress files from `sql/core/src/main/java/org/apache/spark/sql/api.java/*` to `sql/core/src/main/java/org/apache/spark/sql/api/java/*`, the former seems to be a wrong code path. ### Why are the changes needed? Correct the `files` contend in `checkstyle-suppressions.xml` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GitHub Actions Closes #38469 from LuciferYang/fix-java-supperessions. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 5457193dc095bc6c97259e31fa3df44184822f65) Signed-off-by: Sean Owen <srowen@gmail.com> | 01 November 2022, 23:10:59 UTC |
| c12b4e2 | Cheng Pan | 01 November 2022, 12:32:37 UTC | [SPARK-40983][DOC] Remove Hadoop requirements for zstd mentioned in Parquet compression codec ### What changes were proposed in this pull request? Change the doc to remove Hadoop requirements for zstd mentioned in Parquet compression codec. ### Why are the changes needed? This requirement is removed after https://issues.apache.org/jira/browse/PARQUET-1866, and Spark uses Parquet 1.12.3 now. ### Does this PR introduce _any_ user-facing change? Yes, doc updated. ### How was this patch tested? <img width="1144" alt="image" src="https://user-images.githubusercontent.com/26535726/199180625-4e3a2ee1-3e4d-4d61-8842-f1d5b7b9321d.png"> Closes #38458 from pan3793/SPARK-40983. Authored-by: Cheng Pan <chengpan@apache.org> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit 9c1bb41ca34229c87b463b4941b4e9c829a0e396) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 01 November 2022, 12:33:19 UTC |
| 815f32f | Bruce Robbins | 31 October 2022, 01:45:17 UTC | [SPARK-40963][SQL] Set nullable correctly in project created by `ExtractGenerator` ### What changes were proposed in this pull request? When creating the project list for the new projection In `ExtractGenerator`, take into account whether the generator is outer when setting nullable on generator-related output attributes. ### Why are the changes needed? This PR fixes an issue that can produce either incorrect results or a `NullPointerException`. It's a bit of an obscure issue in that I am hard-pressed to reproduce without using a subquery that has a inline table. Example: ``` select c1, explode(c4) as c5 from ( select c1, array(c3) as c4 from ( select c1, explode_outer(c2) as c3 from values (1, array(1, 2)), (2, array(2, 3)), (3, null) as data(c1, c2) ) ); +---+---+ |c1 |c5 | +---+---+ |1 |1 | |1 |2 | |2 |2 | |2 |3 | |3 |0 | +---+---+ ``` In the last row, `c5` is 0, but should be `NULL`. Another example: ``` select c1, exists(c4, x -> x is null) as c5 from ( select c1, array(c3) as c4 from ( select c1, explode_outer(c2) as c3 from values (1, array(1, 2)), (2, array(2, 3)), (3, array()) as data(c1, c2) ) ); +---+-----+ |c1 |c5 | +---+-----+ |1 |false| |1 |false| |2 |false| |2 |false| |3 |false| +---+-----+ ``` In the last row, `false` should be `true`. In both cases, at the time `CreateArray(c3)` is instantiated, `c3`'s nullability is incorrect because the new projection created by `ExtractGenerator` uses `generatorOutput` from `explode_outer(c2)` as a projection list. `generatorOutput` doesn't take into account that `explode_outer(c2)` is an _outer_ explode, so the nullability setting is lost. `UpdateAttributeNullability` will eventually fix the nullable setting for attributes referring to `c3`, but it doesn't fix the `containsNull` setting for `c4` in `explode(c4)` (from the first example) or `exists(c4, x -> x is null)` (from the second example). This example fails with a `NullPointerException`: ``` select c1, inline_outer(c4) from ( select c1, array(c3) as c4 from ( select c1, explode_outer(c2) as c3 from values (1, array(named_struct('a', 1, 'b', 2))), (2, array(named_struct('a', 3, 'b', 4), named_struct('a', 5, 'b', 6))), (3, array()) as data(c1, c2) ) ); 22/10/30 17:34:42 ERROR Executor: Exception in task 1.0 in stage 8.0 (TID 14) java.lang.NullPointerException at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.generate_doConsume_1$(Unknown Source) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.generate_doConsume_0$(Unknown Source) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:760) at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:364) ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? New unit test. Closes #38440 from bersprockets/SPARK-40963. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 90d31541fb0313d762cc36067060e6445c04a9b6) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 31 October 2022, 01:45:41 UTC |
| 2df8bfb | Andy Grove | 26 October 2022, 20:34:33 UTC | [SPARK-38697][SQL][3.2] Extend SparkSessionExtensions to inject rules into AQE Optimizer ### What changes were proposed in this pull request? Backport SPARK-38697 to Spark 3.2.x ### Why are the changes needed? Allows users to inject logical plan optimizer rules into AQE ### Does this PR introduce _any_ user-facing change? Yes, new API method to inject logical plan optimizer rules into AQE ### How was this patch tested? Backport includes a unit test Closes #38401 from andygrove/backport-SPARK-38697-spark32. Authored-by: Andy Grove <andygrove73@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 26 October 2022, 20:34:33 UTC |
| e5744b9 | Mridul | 24 October 2022, 17:51:45 UTC | [SPARK-40902][MESOS][TESTS] Fix issue with mesos tests failing due to quick submission of drivers ### What changes were proposed in this pull request? ##### Quick submission of drivers in tests to mesos scheduler results in dropping drivers Queued drivers in `MesosClusterScheduler` are ordered based on `MesosDriverDescription` - and the ordering used checks for priority (if different), followed by comparison of submission time. For two driver submissions with same priority, if made in quick succession (such that submission time is same due to millisecond granularity of Date), this results in dropping the second `MesosDriverDescription` from `queuedDrivers` (since `driverOrdering` returns `0` when comparing the descriptions). This PR fixes the more immediate issue with tests. ### Why are the changes needed? Flakey tests, [see here](https://lists.apache.org/thread/jof098qxp0s6qqmt9qwv52f9665b1pjg) for an example. ### Does this PR introduce _any_ user-facing change? No. Fixing only tests for now - as mesos support is deprecated, not changing scheduler itself to address this. ### How was this patch tested? Fixes unit tests Closes #38378 from mridulm/fix_MesosClusterSchedulerSuite. Authored-by: Mridul <mridulatgmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 60b1056307b3ee9d880a936f3a97c5fb16a2b698) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 24 October 2022, 17:52:07 UTC |
| 8448038 | yangjie01 | 24 October 2022, 07:32:23 UTC | [SPARK-40851][INFRA ][SQL][TESTS][3.2] Make GA run successfully with the latest Java 8/11/17 ### What changes were proposed in this pull request? The main change of this pr as follows: - Replace `Antarctica/Vostok` to `Asia/Urumqi` in Spark code - Replace `Europe/Amsterdam` to `Europe/Brussels` in Spark code - Regenerate `gregorian-julian-rebase-micros.json` using generate 'gregorian-julian-rebase-micros.json' in `RebaseDateTimeSuite` with Java 8u352 - Regenerate `julian-gregorian-rebase-micros.json` using generate 'julian-gregorian-rebase-micros.json' in RebaseDateTimeSuite with Java 8u352 ### Why are the changes needed? Make GA run successfully with the latest Java 8/11/17: - Java 8u352 - Java 11.0.17 - Java 17.0.5 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass GitHub Actions - Manual test: the following commands can test pass with Java 8u345, 8u352, 11.0.16, 11.0.17, 17.0.4 and 17.0.5 - `build/sbt "catalyst/test"` - `build/sbt "sql/testOnly *SQLQueryTestSuite -- -t \"timestamp-ltz.sql\""` - `build/sbt "sql/testOnly *SQLQueryTestSuite -- -t \"timestamp-ntz.sql\""` Closes #38365 from LuciferYang/SPARK-40851-32. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 24 October 2022, 07:32:23 UTC |
| b6b4945 | Peter Toth | 22 October 2022, 01:39:32 UTC | [SPARK-40874][PYTHON] Fix broadcasts in Python UDFs when encryption enabled This PR fixes a bug in broadcast handling `PythonRunner` when encryption is enabed. Due to this bug the following pyspark script: ``` bin/pyspark --conf spark.io.encryption.enabled=true ... bar = {"a": "aa", "b": "bb"} foo = spark.sparkContext.broadcast(bar) spark.udf.register("MYUDF", lambda x: foo.value[x] if x else "") spark.sql("SELECT MYUDF('a') AS a, MYUDF('b') AS b").collect() ``` fails with: ``` 22/10/21 17:14:32 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)/ 1] org.apache.spark.api.python.PythonException: Traceback (most recent call last): File "/Users/petertoth/git/apache/spark/python/lib/pyspark.zip/pyspark/worker.py", line 811, in main func, profiler, deserializer, serializer = read_command(pickleSer, infile) File "/Users/petertoth/git/apache/spark/python/lib/pyspark.zip/pyspark/worker.py", line 87, in read_command command = serializer._read_with_length(file) File "/Users/petertoth/git/apache/spark/python/lib/pyspark.zip/pyspark/serializers.py", line 173, in _read_with_length return self.loads(obj) File "/Users/petertoth/git/apache/spark/python/lib/pyspark.zip/pyspark/serializers.py", line 471, in loads return cloudpickle.loads(obj, encoding=encoding) EOFError: Ran out of input ``` The reason for this failure is that we have multiple Python UDF referencing the same broadcast and in the current code: https://github.com/apache/spark/blob/748fa2792e488a6b923b32e2898d9bb6e16fb4ca/core/src/main/scala/org/apache/spark/api/python/PythonRunner.scala#L385-L420 the number of broadcasts (`cnt`) is correct (1) but the broadcast id is serialized 2 times from JVM to Python ruining the next item that Python expects from JVM side. Please note that the example above works in Spark 3.3 without this fix. That is because https://github.com/apache/spark/pull/36121 in Spark 3.4 modified `ExpressionSet` and so `udfs` in `ExtractPythonUDFs`: https://github.com/apache/spark/blob/748fa2792e488a6b923b32e2898d9bb6e16fb4ca/sql/core/src/main/scala/org/apache/spark/sql/execution/python/ExtractPythonUDFs.scala#L239-L242 changed from `Stream` to `Vector`. When `broadcastVars` (and so `idsAndFiles`) is a `Stream` the example accidentaly works as the broadcast id is written to `dataOut` once (`oldBids.add(id)` in `idsAndFiles.foreach` is called before the 2nd item is calculated in `broadcastVars.flatMap`). But that doesn't mean that https://github.com/apache/spark/pull/36121 introduced the regression as `EncryptedPythonBroadcastServer` shouldn't serve the broadcast data 2 times (which `EncryptedPythonBroadcastServer` does now, but it is not noticed) as it could fail other cases when there are more than 1 broadcast used in UDFs). To fix a bug. No. Added new UT. Closes #38334 from peter-toth/SPARK-40874-fix-broadcasts-in-python-udf. Authored-by: Peter Toth <peter.toth@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 8a96f69bb536729eaa59fae55160f8a6747efbe3) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 24 October 2022, 01:29:19 UTC |
| db2974b | zhangbutao | 18 October 2022, 21:54:39 UTC | [SPARK-40829][SQL] STORED AS serde in CREATE TABLE LIKE view does not work ### What changes were proposed in this pull request? After [SPARK-29839](https://issues.apache.org/jira/browse/SPARK-29839), we could create a table with specife based a existing view, but the serde of created is always parquet. However, if we use USING syntax ([SPARK-29421](https://issues.apache.org/jira/browse/SPARK-29421)) to create a table with specified serde based a view, we can get the correct serde. ### Why are the changes needed? We should add specified serde for the created table when using `create table like view stored as` syntax. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit Test Closes #38295 from zhangbutao/SPARK-40829. Authored-by: zhangbutao <zhangbutao@cmss.chinamobile.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 4ad29829bf53fff26172845312b334008bc4cb68) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 18 October 2022, 21:54:59 UTC |
| 3cc2ba9 | zhouyifan279 | 12 October 2022, 03:34:43 UTC | [SPARK-8731] Beeline doesn't work with -e option when started in background ### What changes were proposed in this pull request? Append jline option "-Djline.terminal=jline.UnsupportedTerminal" to enable the Beeline process to run in background. ### Why are the changes needed? Currently, if we execute spark Beeline in background, the Beeline process stops immediately. <img width="1350" alt="image" src="https://user-images.githubusercontent.com/88070094/194742935-8235b1ba-386e-4470-b182-873ef185e19f.png"> ### Does this PR introduce _any_ user-facing change? User will be able to execute Spark Beeline in background. ### How was this patch tested? 1. Start Spark ThriftServer 2. Execute command `./bin/beeline -u "jdbc:hive2://localhost:10000" -e "select 1;" &` 3. Verify Beeline process output in console: <img width="1407" alt="image" src="https://user-images.githubusercontent.com/88070094/194743153-ff3f1d19-ac23-443b-97a6-f024719008cd.png"> ### Note Beeline works fine on Windows when backgrounded:  Closes #38172 from zhouyifan279/SPARK-8731. Authored-by: zhouyifan279 <zhouyifan279@gmail.com> Signed-off-by: Kent Yao <yao@apache.org> (cherry picked from commit cb0d6ed46acee7271597764e018558b86aa8c29b) Signed-off-by: Kent Yao <yao@apache.org> | 12 October 2022, 03:35:36 UTC |
| ad2fb0e | Yuming Wang | 06 October 2022, 05:02:22 UTC | [SPARK-40660][SQL][3.3] Switch to XORShiftRandom to distribute elements ### What changes were proposed in this pull request? Cherry-picked from #38106 and reverted changes in RDD.scala: https://github.com/apache/spark/blob/d2952b671a3579759ad9ce326ed8389f5270fd9f/core/src/main/scala/org/apache/spark/rdd/RDD.scala#L507 ### Why are the changes needed? The number of output files has changed since SPARK-40407. [Some downstream projects](https://github.com/apache/iceberg/blob/c07f2aabc0a1d02f068ecf1514d2479c0fbdd3b0/spark/v3.3/spark-extensions/src/test/java/org/apache/iceberg/spark/extensions/TestRewriteDataFilesProcedure.java#L578-L579) use repartition to determine the number of output files in the test. ``` bin/spark-shell --master "local[2]" spark.range(10).repartition(10).write.mode("overwrite").parquet("/tmp/spark/repartition") ``` Before this PR and after SPARK-40407, the number of output files is 8. After this PR or before SPARK-40407, the number of output files is 10. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Unit test. Closes #38110 from wangyum/branch-3.3-SPARK-40660. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit 5fe895a65a4a9d65f81d43af473b5e3a855ed8c8) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 06 October 2022, 05:02:51 UTC |
| b43e38b | attilapiros | 04 October 2022, 21:41:47 UTC | [SPARK-40617][CORE][3.2] Fix race condition at the handling of ExecutorMetricsPoller's stageTCMP entries ### What changes were proposed in this pull request? Fix a race condition in ExecutorMetricsPoller between `getExecutorUpdates()` and `onTaskStart()` methods by avoiding removing entries when another stage is not started yet. ### Why are the changes needed? Spurious failures are reported because of the following assert: ``` 22/09/29 09:46:24 ERROR SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker for task 3063.0 in stage 1997.0 (TID 677249),5,main] java.lang.AssertionError: assertion failed: task count shouldn't below 0 at scala.Predef$.assert(Predef.scala:223) at org.apache.spark.executor.ExecutorMetricsPoller.decrementCount$1(ExecutorMetricsPoller.scala:130) at org.apache.spark.executor.ExecutorMetricsPoller.$anonfun$onTaskCompletion$3(ExecutorMetricsPoller.scala:135) at java.base/java.util.concurrent.ConcurrentHashMap.computeIfPresent(ConcurrentHashMap.java:1822) at org.apache.spark.executor.ExecutorMetricsPoller.onTaskCompletion(ExecutorMetricsPoller.scala:135) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:737) at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) at java.base/java.lang.Thread.run(Thread.java:829) 22/09/29 09:46:24 INFO MemoryStore: MemoryStore cleared 22/09/29 09:46:24 INFO BlockManager: BlockManager stopped 22/09/29 09:46:24 INFO ShutdownHookManager: Shutdown hook called 22/09/29 09:46:24 INFO ShutdownHookManager: Deleting directory /mnt/yarn/usercache/hadoop/appcache/application_1664443624160_0001/spark-93efc2d4-84de-494b-a3b7-2cb1c3a45426 ``` I have checked the code and the basic assumption to have at least as many `onTaskStart()` calls as `onTaskCompletion()` for the same `stageId` & `stageAttemptId` pair is correct. But there is race condition between `getExecutorUpdates()` and `onTaskStart()`. First of all we have two different threads: - task runner: to execute the task and informs `ExecutorMetricsPoller` about task starts and completion - heartbeater: which uses the `ExecutorMetricsPoller` to get the metrics To show the race condition assume a task just finished which was running on its own (no other tasks was running). So this will decrease the `count` from 1 to 0. On the task runner thread let say a new task starts. So the execution is in the `onTaskStart()` method let's assume the `countAndPeaks` is already computed and here the counter is 0 but the execution is still before incrementing the counter. So we are in between the following two lines: ```scala val countAndPeaks = stageTCMP.computeIfAbsent((stageId, stageAttemptId), _ => TCMP(new AtomicLong(0), new AtomicLongArray(ExecutorMetricType.numMetrics))) val stageCount = countAndPeaks.count.incrementAndGet() ``` Let's look at the other thread (heartbeater) where the `getExecutorUpdates()` is running and it is at the `removeIfInactive()` method: ```scala def removeIfInactive(k: StageKey, v: TCMP): TCMP = { if (v.count.get == 0) { logDebug(s"removing (${k._1}, ${k._2}) from stageTCMP") null } else { v } } ``` And here this entry is removed from `stageTCMP` as the count is 0. Let's go back to the task runner thread where we increase the counter to 1 but that value will be lost as we have no entry in the `stageTCMP` for this stage and attempt. So if a new task comes instead of 2 we will have 1 in the `stageTCMP` and when those two tasks finishes the second one will decrease the counter from 0 to -1. This is when the assert raised. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test. I managed to reproduce the issue with a temporary test: ```scala test("reproduce assert failure") { val testMemoryManager = new TestMemoryManager(new SparkConf()) val taskId = new AtomicLong(0) val runFlag = new AtomicBoolean(true) val poller = new ExecutorMetricsPoller(testMemoryManager, 1000, None) val callUpdates = new Thread("getExecutorOpdates") { override def run() { while (runFlag.get()) { poller.getExecutorUpdates.size } } } val taskStartRunner1 = new Thread("taskRunner1") { override def run() { while (runFlag.get) { var l = taskId.incrementAndGet() poller.onTaskStart(l, 0, 0) poller.onTaskCompletion(l, 0, 0) } } } val taskStartRunner2 = new Thread("taskRunner2") { override def run() { while (runFlag.get) { var l = taskId.incrementAndGet() poller.onTaskStart(l, 0, 0) poller.onTaskCompletion(l, 0, 0) } } } val taskStartRunner3 = new Thread("taskRunner3") { override def run() { while (runFlag.get) { var l = taskId.incrementAndGet() var m = taskId.incrementAndGet() poller.onTaskStart(l, 0, 0) poller.onTaskStart(m, 0, 0) poller.onTaskCompletion(l, 0, 0) poller.onTaskCompletion(m, 0, 0) } } } callUpdates.start() taskStartRunner1.start() taskStartRunner2.start() taskStartRunner3.start() Thread.sleep(1000 * 20) runFlag.set(false) callUpdates.join() taskStartRunner1.join() taskStartRunner2.join() taskStartRunner3.join() } ``` The assert which raised is: ``` Exception in thread "taskRunner3" java.lang.AssertionError: assertion failed: task count shouldn't below 0 at scala.Predef$.assert(Predef.scala:223) at org.apache.spark.executor.ExecutorMetricsPoller.decrementCount$1(ExecutorMetricsPoller.scala:130) at org.apache.spark.executor.ExecutorMetricsPoller.$anonfun$onTaskCompletion$3(ExecutorMetricsPoller.scala:135) at java.base/java.util.concurrent.ConcurrentHashMap.computeIfPresent(ConcurrentHashMap.java:1828) at org.apache.spark.executor.ExecutorMetricsPoller.onTaskCompletion(ExecutorMetricsPoller.scala:135) at org.apache.spark.executor.ExecutorMetricsPollerSuite$$anon$4.run(ExecutorMetricsPollerSuite.scala:64) ``` But when I switch off `removeIfInactive()` by using the following code: ```scala if (false && v.count.get == 0) { logDebug(s"removing (${k._1}, ${k._2}) from stageTCMP") null } else { v } ``` Then no assert is raised. Closes #38056 from attilapiros/SPARK-40617. Authored-by: attilapiros <piros.attila.zsoltgmail.com> Signed-off-by: attilapiros <piros.attila.zsoltgmail.com> (cherry picked from commit 564a51b64e71f7402c2674de073b3b18001df56f) Signed-off-by: attilapiros <piros.attila.zsoltgmail.com> (cherry picked from commit 90a27757ec17c2511049114a437f365326e51225) Closes #38083 from attilapiros/SPARK-40617-3.2. Authored-by: attilapiros <piros.attila.zsolt@gmail.com> Signed-off-by: attilapiros <piros.attila.zsolt@gmail.com> | 04 October 2022, 21:41:47 UTC |
| 4b1e06b | Warren Zhu | 04 October 2022, 20:38:17 UTC | [SPARK-40636][CORE] Fix wrong remained shuffles log in BlockManagerDecommissioner ### What changes were proposed in this pull request Fix wrong remained shuffles log in BlockManagerDecommissioner ### Why are the changes needed? BlockManagerDecommissioner should log correct remained shuffles. Current log used all shuffles num as remained. ``` 4 of 24 local shuffles are added. In total, 24 shuffles are remained. 2022-09-30 17:42:15.035 PDT 0 of 24 local shuffles are added. In total, 24 shuffles are remained. 2022-09-30 17:42:45.069 PDT 0 of 24 local shuffles are added. In total, 24 shuffles are remained. ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Manually tested Closes #38078 from warrenzhu25/deco-log. Authored-by: Warren Zhu <warren.zhu25@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit b39f2d6acf25726d99bf2c2fa84ba6a227d0d909) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 04 October 2022, 20:38:37 UTC |
| ac772e9 | attilapiros | 30 September 2022, 21:52:40 UTC | [SPARK-40612][CORE] Fixing the principal used for delegation token renewal on non-YARN resource managers ### What changes were proposed in this pull request? When the delegation token is fetched at the first time (see the `fetchDelegationTokens()` call at `HadoopFSDelegationTokenProvider#getTokenRenewalInterval()`) the principal is the current user but at the subsequent token renewals (see `obtainDelegationTokens()` where `getTokenRenewer()` is used to identify the principal) are using a MapReduce/Yarn specific principal even on resource managers different from YARN. This PR fixes `getTokenRenewer()` to use the current user instead of `org.apache.hadoop.mapred.Master.getMasterPrincipal(hadoopConf)` when the resource manager is not YARN. The condition `(master != null && master.contains("yarn"))` is the very same what we already have in `hadoopFSsToAccess()`. I would like to say thank you for squito who have done the investigation regarding of the problem which lead to this PR. ### Why are the changes needed? To avoid `org.apache.hadoop.security.AccessControlException: Permission denied.` for long running applications. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manually. Closes #38048 from attilapiros/SPARK-40612. Authored-by: attilapiros <piros.attila.zsolt@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 6484992535767ae8dc93df1c79efc66420728155) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 30 September 2022, 21:53:00 UTC |
| d046b98 | Yuming Wang | 27 September 2022, 22:32:37 UTC | [SPARK-40574][DOCS] Enhance DROP TABLE documentation ### What changes were proposed in this pull request? This PR adds `PURGE` in `DROP TABLE` documentation. Related documentation and code: 1. Hive `DROP TABLE` documentation: https://cwiki.apache.org/confluence/display/hive/languagemanual+ddl <img width="877" alt="image" src="https://user-images.githubusercontent.com/5399861/192425153-63ac5373-dd34-48b3-864c-324cf5ba5db9.png"> 2. Hive code: https://github.com/apache/hive/blob/rel/release-2.3.9/ql/src/java/org/apache/hadoop/hive/ql/metadata/Hive.java#L1185-L1209 3. Spark code: https://github.com/apache/spark/blob/v3.3.0/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala#L1317-L1327 ### Why are the changes needed? Enhance documentation. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? manual test. Closes #38011 from wangyum/SPARK-40574. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 11eefc81e5c1f3ec7db6df8ba068a7155f7abda3) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 27 September 2022, 22:32:56 UTC |
| b441d43 | Daniel Ranchal Parrado | 27 September 2022, 22:25:11 UTC | [SPARK-40583][DOCS] Fixing artifactId name in `cloud-integration.md` ### What changes were proposed in this pull request? I am changing the name of the artifactId that enables the integration with several cloud infrastructures. ### Why are the changes needed? The name of the package is wrong and it does not exist. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? It is not needed. Closes #38021 from danitico/fix/SPARK-40583. Authored-by: Daniel Ranchal Parrado <daniel.ranchal@vlex.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit dac58f82d1c10fb91f85fd9670f88d88dbe2feea) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 27 September 2022, 22:25:34 UTC |
| dc9041a | Dongjoon Hyun | 27 September 2022, 09:14:22 UTC | [SPARK-40562][SQL] Add `spark.sql.legacy.groupingIdWithAppendedUserGroupBy` This PR aims to add a new legacy configuration to keep `grouping__id` value like the released Apache Spark 3.2 and 3.3. Please note that this syntax is non-SQL standard and even Hive doesn't support it. ```SQL hive> SELECT version(); OK 3.1.3 r4df4d75bf1e16fe0af75aad0b4179c34c07fc975 Time taken: 0.111 seconds, Fetched: 1 row(s) hive> SELECT count(*), grouping__id from t GROUP BY a GROUPING SETS (b); FAILED: SemanticException 1:63 [Error 10213]: Grouping sets expression is not in GROUP BY key. Error encountered near token 'b' ``` SPARK-40218 fixed a bug caused by SPARK-34932 (at Apache Spark 3.2.0). As a side effect, `grouping__id` values are changed. - Apache Spark 3.2.0, 3.2.1, 3.2.2, 3.3.0. ```scala scala> sql("SELECT count(*), grouping__id from (VALUES (1,1,1),(2,2,2)) AS t(k1,k2,v) GROUP BY k1 GROUPING SETS (k2) ").show() +--------+------------+ |count(1)|grouping__id| +--------+------------+ | 1| 1| | 1| 1| +--------+------------+ ``` - After SPARK-40218, Apache Spark 3.4.0, 3.3.1, 3.2.3 ```scala scala> sql("SELECT count(*), grouping__id from (VALUES (1,1,1),(2,2,2)) AS t(k1,k2,v) GROUP BY k1 GROUPING SETS (k2) ").show() +--------+------------+ |count(1)|grouping__id| +--------+------------+ | 1| 2| | 1| 2| +--------+------------+ ``` - This PR (Apache Spark 3.4.0, 3.3.1, 3.2.3) ```scala scala> sql("SELECT count(*), grouping__id from (VALUES (1,1,1),(2,2,2)) AS t(k1,k2,v) GROUP BY k1 GROUPING SETS (k2) ").show() +--------+------------+ |count(1)|grouping__id| +--------+------------+ | 1| 2| | 1| 2| +--------+------------+ scala> sql("set spark.sql.legacy.groupingIdWithAppendedUserGroupBy=true") res1: org.apache.spark.sql.DataFrame = [key: string, value: string]scala> sql("SELECT count(*), grouping__id from (VALUES (1,1,1),(2,2,2)) AS t(k1,k2,v) GROUP BY k1 GROUPING SETS (k2) ").show() +--------+------------+ |count(1)|grouping__id| +--------+------------+ | 1| 1| | 1| 1| +--------+------------+ ``` No, this simply added back the previous behavior by the legacy configuration. Pass the CIs. Closes #38001 from dongjoon-hyun/SPARK-40562. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 5c0ebf3d97ae49b6e2bd2096c2d590abf4d725bd) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 27 September 2022, 09:16:44 UTC |
| f9a05dd | Frank Yin | 23 September 2022, 11:23:26 UTC | [SPARK-39200][CORE] Make Fallback Storage readFully on content Looks like from bug description, fallback storage doesn't readFully and then cause `org.apache.spark.shuffle.FetchFailedException: Decompression error: Corrupted block detected`. This is an attempt to fix this by read the underlying stream fully. Fix a bug documented in SPARK-39200 No Wrote a unit test Closes #37960 from ukby1234/SPARK-39200. Authored-by: Frank Yin <franky@ziprecruiter.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 07061f1a07a96f59ae42c9df6110eb784d2f3dab) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 23 September 2022, 11:27:16 UTC |
| 18e83f9 | Bobby Wang | 22 September 2022, 12:59:00 UTC | [SPARK-40407][SQL] Fix the potential data skew caused by df.repartition ### What changes were proposed in this pull request? ``` scala val df = spark.range(0, 100, 1, 50).repartition(4) val v = df.rdd.mapPartitions { iter => { Iterator.single(iter.length) }.collect() println(v.mkString(",")) ``` The above simple code outputs `50,0,0,50`, which means there is no data in partition 1 and partition 2. The RoundRobin seems to ensure to distribute the records evenly *in the same partition*, and not guarantee it between partitions. Below is the code to generate the key ``` scala case RoundRobinPartitioning(numPartitions) => // Distributes elements evenly across output partitions, starting from a random partition. var position = new Random(TaskContext.get().partitionId()).nextInt(numPartitions) (row: InternalRow) => { // The HashPartitioner will handle the `mod` by the number of partitions position += 1 position } ``` In this case, There are 50 partitions, each partition will only compute 2 elements. The issue for RoundRobin here is it always starts with position=2 to do the Roundrobin. See the output of Random ``` scala scala> (1 to 200).foreach(partitionId => print(new Random(partitionId).nextInt(4) + " ")) // the position is always 2. 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 ``` Similarly, the below Random code also outputs the same value, ``` scala (1 to 200).foreach(partitionId => print(new Random(partitionId).nextInt(2) + " ")) (1 to 200).foreach(partitionId => print(new Random(partitionId).nextInt(4) + " ")) (1 to 200).foreach(partitionId => print(new Random(partitionId).nextInt(8) + " ")) (1 to 200).foreach(partitionId => print(new Random(partitionId).nextInt(16) + " ")) (1 to 200).foreach(partitionId => print(new Random(partitionId).nextInt(32) + " ")) ``` Consider partition 0, the total elements are [0, 1], so when shuffle writes, for element 0, the key will be (position + 1) = 2 + 1 = 3%4=3, the element 1, the key will be (position + 1)=(3+1)=4%4 = 0 consider partition 1, the total elements are [2, 3], so when shuffle writes, for element 2, the key will be (position + 1) = 2 + 1 = 3%4=3, the element 3, the key will be (position + 1)=(3+1)=4%4 = 0 The calculation is also applied for other left partitions since the starting position is always 2 for this case. So, as you can see, each partition will write its elements to Partition [0, 3], which results in Partition [1, 2] without any data. This PR changes the starting position of RoundRobin. The default position calculated by `new Random(partitionId).nextInt(numPartitions)` may always be the same for different partitions, which means each partition will output the data into the same keys when shuffle writes, and some keys may not have any data in some special cases. ### Why are the changes needed? The PR can fix the data skew issue for the special cases. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Will add some tests and watch CI pass Closes #37855 from wbo4958/roundrobin-data-skew. Authored-by: Bobby Wang <wbo4958@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit f6c4e58b85d7486c70cd6d58aae208f037e657fa) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 22 September 2022, 13:00:11 UTC |
| 3ac1c3d | yangjie01 | 22 September 2022, 11:14:50 UTC | [SPARK-40490][YARN][TESTS][3.2] Ensure YarnShuffleIntegrationSuite tests registeredExecFile reload scenarios ### What changes were proposed in this pull request? After SPARK-17321, `YarnShuffleService` will persist data to local shuffle state db/reload data from local shuffle state db only when Yarn NodeManager start with `YarnConfiguration#NM_RECOVERY_ENABLED = true`. `YarnShuffleIntegrationSuite` not set `YarnConfiguration#NM_RECOVERY_ENABLED` and the default value of the configuration is false, so `YarnShuffleIntegrationSuite` will neither trigger data persistence to the db nor verify the reload of data. This pr aims to let `YarnShuffleIntegrationSuite` restart the verification of registeredExecFile reload scenarios, to achieve this goal, this pr make the following changes: 1. Add a new un-document configuration `spark.yarn.shuffle.testing` to `YarnShuffleService`, and Initialize `_recoveryPath` when `_recoveryPath == null && spark.yarn.shuffle.testing == true`. 2. Only set `spark.yarn.shuffle.testing = true` in `YarnShuffleIntegrationSuite`, and add assertions to check `registeredExecFile` is not null to ensure that registeredExecFile reload scenarios will be verified. ### Why are the changes needed? Fix registeredExecFile reload test scenarios. Why not test by configuring `YarnConfiguration#NM_RECOVERY_ENABLED` as true? This configuration has been tried **Hadoop 3.3.1** ``` build/mvn clean install -pl resource-managers/yarn -Pyarn -Dtest=none -DwildcardSuites=org.apache.spark.deploy.yarn.YarnShuffleIntegrationSuite -Phadoop-3 ``` ``` YarnShuffleIntegrationSuite: *** RUN ABORTED *** java.lang.NoClassDefFoundError: org/apache/hadoop/shaded/org/iq80/leveldb/DBException at org.apache.hadoop.yarn.server.nodemanager.NodeManager.initAndStartRecoveryStore(NodeManager.java:313) at org.apache.hadoop.yarn.server.nodemanager.NodeManager.serviceInit(NodeManager.java:370) at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164) at org.apache.hadoop.yarn.server.MiniYARNCluster$NodeManagerWrapper.serviceInit(MiniYARNCluster.java:597) at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164) at org.apache.hadoop.service.CompositeService.serviceInit(CompositeService.java:109) at org.apache.hadoop.yarn.server.MiniYARNCluster.serviceInit(MiniYARNCluster.java:327) at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164) at org.apache.spark.deploy.yarn.BaseYarnClusterSuite.beforeAll(BaseYarnClusterSuite.scala:105) at org.scalatest.BeforeAndAfterAll.liftedTree1$1(BeforeAndAfterAll.scala:212) ... Cause: java.lang.ClassNotFoundException: org.apache.hadoop.shaded.org.iq80.leveldb.DBException at java.net.URLClassLoader.findClass(URLClassLoader.java:387) at java.lang.ClassLoader.loadClass(ClassLoader.java:419) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352) at java.lang.ClassLoader.loadClass(ClassLoader.java:352) at org.apache.hadoop.yarn.server.nodemanager.NodeManager.initAndStartRecoveryStore(NodeManager.java:313) at org.apache.hadoop.yarn.server.nodemanager.NodeManager.serviceInit(NodeManager.java:370) at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164) at org.apache.hadoop.yarn.server.MiniYARNCluster$NodeManagerWrapper.serviceInit(MiniYARNCluster.java:597) at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164) at org.apache.hadoop.service.CompositeService.serviceInit(CompositeService.java:109) ``` **Hadoop 2.7.4** ``` build/mvn clean install -pl resource-managers/yarn -Pyarn -Dtest=none -DwildcardSuites=org.apache.spark.deploy.yarn.YarnShuffleIntegrationSuite -Phadoop-2 ``` ``` YarnShuffleIntegrationSuite: org.apache.spark.deploy.yarn.YarnShuffleIntegrationSuite *** ABORTED *** java.lang.IllegalArgumentException: Cannot support recovery with an ephemeral server port. Check the setting of yarn.nodemanager.address at org.apache.hadoop.yarn.server.nodemanager.containermanager.ContainerManagerImpl.serviceStart(ContainerManagerImpl.java:395) at org.apache.hadoop.service.AbstractService.start(AbstractService.java:193) at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:120) at org.apache.hadoop.yarn.server.nodemanager.NodeManager.serviceStart(NodeManager.java:272) at org.apache.hadoop.service.AbstractService.start(AbstractService.java:193) at org.apache.hadoop.yarn.server.MiniYARNCluster$NodeManagerWrapper.serviceStart(MiniYARNCluster.java:560) at org.apache.hadoop.service.AbstractService.start(AbstractService.java:193) at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:120) at org.apache.hadoop.yarn.server.MiniYARNCluster.serviceStart(MiniYARNCluster.java:278) at org.apache.hadoop.service.AbstractService.start(AbstractService.java:193) ... Run completed in 3 seconds, 992 milliseconds. Total number of tests run: 0 Suites: completed 1, aborted 1 Tests: succeeded 0, failed 0, canceled 0, ignored 0, pending 0 *** 1 SUITE ABORTED *** ``` From the above test, we need to use a fixed port to enable Yarn NodeManager recovery, but this is difficult to be guaranteed in UT, so this pr try a workaround way. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GitHub Actions Closes #37963 from LuciferYang/SPARK-40490-32. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 22 September 2022, 11:14:50 UTC |
| e90a57e | Chao Sun | 16 September 2022, 17:46:36 UTC | [SPARK-40169][SQL] Don't pushdown Parquet filters with no reference to data schema ### What changes were proposed in this pull request? Currently in Parquet V1 read path, Spark will pushdown data filters even if they have no reference in the Parquet read schema. This can cause correctness issues as described in [SPARK-39833](https://issues.apache.org/jira/browse/SPARK-39833). The root cause, it seems, is because in the V1 path, we first use `AttributeReference` equality to filter out data columns without partition columns, and then use `AttributeSet` equality to filter out filters with only references to data columns. There's inconsistency in the two steps, when case sensitive check is false. Take the following scenario as example: - data column: `[COL, a]` - partition column: `[col]` - filter: `col > 10` With `AttributeReference` equality, `COL` is not considered equal to `col` (because their names are different), and thus the filtered out data column set is still `[COL, a]`. However, when calculating filters with only reference to data columns, `COL` is **considered equal** to `col`. Consequently, the filter `col > 10`, when checking with `[COL, a]`, is considered to have reference to data columns, and thus will be pushed down to Parquet as data filter. On the Parquet side, since `col` doesn't exist in the file schema (it only has `COL`), when column index enabled, it will incorrectly return wrong number of rows. See [PARQUET-2170](https://issues.apache.org/jira/browse/PARQUET-2170) for more detail. In general, where data columns overlap with partition columns and case sensitivity is false, partition filters will not be filter out before we calculate filters with only reference to data columns, which is incorrect. ### Why are the changes needed? This fixes the correctness bug described in [SPARK-39833](https://issues.apache.org/jira/browse/SPARK-39833). ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? There are existing test cases for this issue from [SPARK-39833](https://issues.apache.org/jira/browse/SPARK-39833). This also modified them to test the scenarios when case sensitivity is on or off. Closes #37881 from sunchao/SPARK-40169. Authored-by: Chao Sun <sunchao@apple.com> Signed-off-by: Chao Sun <sunchao@apple.com> | 16 September 2022, 17:50:45 UTC |
| 1b84e44 | Ivan Sadikov | 16 September 2022, 13:05:03 UTC | [SPARK-40470][SQL] Handle GetArrayStructFields and GetMapValue in "arrays_zip" function ### What changes were proposed in this pull request? This is a follow-up for https://github.com/apache/spark/pull/37833. The PR fixes column names in `arrays_zip` function for the cases when `GetArrayStructFields` and `GetMapValue` expressions are used (see unit tests for more details). Before the patch, the column names would be indexes or an AnalysisException would be thrown in the case of `GetArrayStructFields` example. ### Why are the changes needed? Fixes an inconsistency issue in Spark 3.2 and onwards where the fields would be labeled as indexes instead of column names. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? I added unit tests that reproduce the issue and confirmed that the patch fixes them. Closes #37911 from sadikovi/SPARK-40470. Authored-by: Ivan Sadikov <ivan.sadikov@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 9b0f979141ba2c4124d96bc5da69ea5cac51df0d) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 16 September 2022, 13:05:27 UTC |
| 8068bd3 | Hyukjin Kwon | 16 September 2022, 01:08:59 UTC | [SPARK-40461][INFRA] Set upperbound for pyzmq 24.0.0 for Python linter This PR sets the upperbound for `pyzmq` as `<24.0.0` in our CI Python linter job. The new release seems having a problem (https://github.com/zeromq/pyzmq/commit/2d3327d2e50c2510d45db2fc51488578a737b79b). To fix the linter build failure. See https://github.com/apache/spark/actions/runs/3063515551/jobs/4947782771 ``` /tmp/timer_created_0ftep6.c: In function ‘main’: /tmp/timer_created_0ftep6.c:2:5: warning: implicit declaration of function ‘timer_create’ [-Wimplicit-function-declaration] 2 | timer_create(); | ^~~~~~~~~~~~ x86_64-linux-gnu-gcc -pthread tmp/timer_created_0ftep6.o -L/usr/lib/x86_64-linux-gnu -o a.out /usr/bin/ld: tmp/timer_created_0ftep6.o: in function `main': /tmp/timer_created_0ftep6.c:2: undefined reference to `timer_create' collect2: error: ld returned 1 exit status no timer_create, linking librt ************************************************ building 'zmq.libzmq' extension creating build/temp.linux-x86_64-cpython-39/buildutils creating build/temp.linux-x86_64-cpython-39/bundled creating build/temp.linux-x86_64-cpython-39/bundled/zeromq creating build/temp.linux-x86_64-cpython-39/bundled/zeromq/src x86_64-linux-gnu-g++ -pthread -std=c++11 -pthread -Wno-unused-result -Wsign-compare -DNDEBUG -g -fwrapv -O2 -Wall -g -fstack-protector-strong -Wformat -Werror=format-security -g -fwrapv -O2 -fPIC -DZMQ_HAVE_CURVE=1 -DZMQ_USE_TWEETNACL=1 -DZMQ_USE_EPOLL=1 -DZMQ_IOTHREADS_USE_EPOLL=1 -DZMQ_POLL_BASED_ON_POLL=1 -Ibundled/zeromq/include -Ibundled -I/usr/include/python3.9 -c buildutils/initlibzmq.cpp -o build/temp.linux-x86_64-cpython-39/buildutils/initlibzmq.o buildutils/initlibzmq.cpp:10:10: fatal error: Python.h: No such file or directory 10 | #include "Python.h" | ^~~~~~~~~~ compilation terminated. error: command '/usr/bin/x86_64-linux-gnu-g++' failed with exit code 1 [end of output] note: This error originates from a subprocess, and is likely not a problem with pip. ERROR: Failed building wheel for pyzmq ERROR: Could not build wheels for pyzmq, which is required to install pyproject.toml-based projects ``` No, test-only. CI in this PRs should validate it. Closes #37904 from HyukjinKwon/fix-linter. Lead-authored-by: Hyukjin Kwon <gurwls223@apache.org> Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 254bd80278843b3bc13584ca2f04391a770a78c7) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 16 September 2022, 01:13:14 UTC |
| a1b1ac7 | Dongjoon Hyun | 16 September 2022, 01:03:54 UTC | [SPARK-40459][K8S] `recoverDiskStore` should not stop by existing recomputed files ### What changes were proposed in this pull request? This PR aims to ignore `FileExistsException` during `recoverDiskStore` processing. ### Why are the changes needed? Although `recoverDiskStore` is already wrapped by `tryLogNonFatalError`, a single file recovery exception should not block the whole `recoverDiskStore` . https://github.com/apache/spark/blob/5938e84e72b81663ccacf0b36c2f8271455de292/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/shuffle/KubernetesLocalDiskShuffleExecutorComponents.scala#L45-L47 ``` org.apache.commons.io.FileExistsException: ... at org.apache.commons.io.FileUtils.requireAbsent(FileUtils.java:2587) at org.apache.commons.io.FileUtils.moveFile(FileUtils.java:2305) at org.apache.commons.io.FileUtils.moveFile(FileUtils.java:2283) at org.apache.spark.storage.DiskStore.moveFileToBlock(DiskStore.scala:150) at org.apache.spark.storage.BlockManager$TempFileBasedBlockStoreUpdater.saveToDiskStore(BlockManager.scala:487) at org.apache.spark.storage.BlockManager$BlockStoreUpdater.$anonfun$save$1(BlockManager.scala:407) at org.apache.spark.storage.BlockManager.org$apache$spark$storage$BlockManager$$doPut(BlockManager.scala:1445) at org.apache.spark.storage.BlockManager$BlockStoreUpdater.save(BlockManager.scala:380) at org.apache.spark.storage.BlockManager$TempFileBasedBlockStoreUpdater.save(BlockManager.scala:490) at org.apache.spark.shuffle.KubernetesLocalDiskShuffleExecutorComponents$.$anonfun$recoverDiskStore$14(KubernetesLocalDiskShuffleExecutorComponents.scala:95) at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36) at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33) at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:198) at org.apache.spark.shuffle.KubernetesLocalDiskShuffleExecutorComponents$.recoverDiskStore(KubernetesLocalDiskShuffleExecutorComponents.scala:91) ``` ### Does this PR introduce _any_ user-facing change? No, this will improve the recover rate. ### How was this patch tested? Pass the CIs. Closes #37903 from dongjoon-hyun/SPARK-40459. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit f24bb430122eaa311070cfdefbc82d34b0341701) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 16 September 2022, 01:04:28 UTC |
| ce55a8f | Kousuke Saruta | 15 September 2022, 00:27:20 UTC | [SPARK-38017][FOLLOWUP][3.2] Hide TimestampNTZ in the doc ### What changes were proposed in this pull request? This PR removes `TimestampNTZ` from the doc about `TimeWindow` and `SessionWIndow`. ### Why are the changes needed? As we discussed, it's better to hide `TimestampNTZ` from the doc. https://github.com/apache/spark/pull/35313#issuecomment-1185192162 ### Does this PR introduce _any_ user-facing change? The document will be changed, but there is no compatibility problem. ### How was this patch tested? Built the doc with `SKIP_RDOC=1 SKIP_SQLDOC=1 bundle exec jekyll build` at `doc` directory. Then, confirmed the generated HTML. Closes #37883 from sarutak/fix-window-doc-3.2. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 15 September 2022, 00:27:20 UTC |
| b39b721 | Ivan Sadikov | 12 September 2022, 04:33:36 UTC | [SPARK-40292][SQL] Fix column names in "arrays_zip" function when arrays are referenced from nested structs ### What changes were proposed in this pull request? This PR fixes an issue in `arrays_zip` function where a field index was used as a column name in the resulting schema which was a regression from Spark 3.1. With this change, the original behaviour is restored: a corresponding struct field name will be used instead of a field index. Example: ```sql with q as ( select named_struct( 'my_array', array(1, 2, 3), 'my_array2', array(4, 5, 6) ) as my_struct ) select arrays_zip(my_struct.my_array, my_struct.my_array2) from q ``` would return schema: ``` root |-- arrays_zip(my_struct.my_array, my_struct.my_array2): array (nullable = false) | |-- element: struct (containsNull = false) | | |-- 0: integer (nullable = true) | | |-- 1: integer (nullable = true) ``` which is somewhat inaccurate. PR adds handling of `GetStructField` expression to return the struct field names like this: ``` root |-- arrays_zip(my_struct.my_array, my_struct.my_array2): array (nullable = false) | |-- element: struct (containsNull = false) | | |-- my_array: integer (nullable = true) | | |-- my_array2: integer (nullable = true) ``` ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? Yes, `arrays_zip` function returns struct field names now as in Spark 3.1 instead of field indices. Some users might have worked around this issue so this patch would affect them by bringing back the original behaviour. ### How was this patch tested? Existing unit tests. I also added a test case that reproduces the problem. Closes #37833 from sadikovi/SPARK-40292. Authored-by: Ivan Sadikov <ivan.sadikov@databricks.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> (cherry picked from commit 443eea97578c41870c343cdb88cf69bfdf27033a) Signed-off-by: Max Gekk <max.gekk@gmail.com> | 12 September 2022, 04:34:11 UTC |