https://github.com/apache/spark
- HEAD
- refs/heads/branch-0.5
- refs/heads/branch-0.6
- refs/heads/branch-0.7
- refs/heads/branch-0.8
- refs/heads/branch-0.9
- refs/heads/branch-1.0
- refs/heads/branch-1.0-jdbc
- refs/heads/branch-1.1
- refs/heads/branch-1.2
- refs/heads/branch-1.3
- refs/heads/branch-1.4
- refs/heads/branch-1.5
- refs/heads/branch-1.6
- refs/heads/branch-2.0
- refs/heads/branch-2.1
- refs/heads/branch-2.2
- refs/heads/branch-2.3
- refs/heads/branch-2.4
- refs/heads/branch-3.0
- refs/heads/branch-3.1
- refs/heads/branch-3.2
- refs/heads/branch-3.3
- refs/heads/branch-3.4
- refs/heads/branch-3.5
- refs/heads/master
- refs/remotes/origin/branch-0.8
- refs/remotes/origin/td-rdd-save
- refs/tags/0.3-scala-2.8
- refs/tags/0.3-scala-2.9
- refs/tags/2.0.0-preview
- refs/tags/alpha-0.1
- refs/tags/alpha-0.2
- refs/tags/v0.5.0
- refs/tags/v0.5.1
- refs/tags/v0.5.2
- refs/tags/v0.6.0
- refs/tags/v0.6.0-yarn
- refs/tags/v0.6.1
- refs/tags/v0.6.2
- refs/tags/v0.7.0
- refs/tags/v0.7.0-bizo-1
- refs/tags/v0.7.1
- refs/tags/v0.7.2
- refs/tags/v0.9.1
- refs/tags/v0.9.2
- refs/tags/v1.0.0
- refs/tags/v1.0.1
- refs/tags/v1.0.2
- refs/tags/v1.1.0
- refs/tags/v1.1.1
- refs/tags/v1.2.0
- refs/tags/v1.2.1
- refs/tags/v1.2.2
- refs/tags/v1.3.0
- refs/tags/v1.3.1
- refs/tags/v1.4.0
- refs/tags/v1.4.1
- refs/tags/v1.5.0-rc1
- refs/tags/v1.5.0-rc2
- refs/tags/v1.5.0-rc3
- refs/tags/v1.5.1
- refs/tags/v1.6.0
- refs/tags/v1.6.1
- refs/tags/v1.6.2
- refs/tags/v1.6.3
- refs/tags/v2.0.0
- refs/tags/v2.0.1
- refs/tags/v2.0.2
- refs/tags/v2.1.0
- refs/tags/v2.1.1
- refs/tags/v2.1.2
- refs/tags/v2.1.2-rc1
- refs/tags/v2.1.2-rc2
- refs/tags/v2.1.2-rc3
- refs/tags/v2.1.2-rc4
- refs/tags/v2.1.3
- refs/tags/v2.1.3-rc1
- refs/tags/v2.1.3-rc2
- refs/tags/v2.2.0
- refs/tags/v2.2.1
- refs/tags/v2.2.1-rc1
- refs/tags/v2.2.1-rc2
- refs/tags/v2.2.2
- refs/tags/v2.2.2-rc1
- refs/tags/v2.2.2-rc2
- refs/tags/v2.2.3
- refs/tags/v2.2.3-rc1
- refs/tags/v2.3.0
- refs/tags/v2.3.0-rc1
- refs/tags/v2.3.0-rc2
- refs/tags/v2.3.0-rc3
- refs/tags/v2.3.0-rc4
- refs/tags/v2.3.1
- refs/tags/v2.3.1-rc1
- refs/tags/v2.3.1-rc2
- refs/tags/v2.3.1-rc3
- refs/tags/v2.3.1-rc4
- refs/tags/v2.3.2
- refs/tags/v2.3.2-rc1
- refs/tags/v2.3.2-rc2
- refs/tags/v2.3.2-rc3
- refs/tags/v2.3.2-rc4
- refs/tags/v2.3.2-rc5
- refs/tags/v2.3.2-rc6
- refs/tags/v2.3.3
- refs/tags/v2.3.3-rc1
- refs/tags/v2.3.3-rc2
- refs/tags/v2.3.4
- refs/tags/v2.3.4-rc1
- refs/tags/v2.4.0
- refs/tags/v2.4.0-rc1
- refs/tags/v2.4.0-rc2
- refs/tags/v2.4.0-rc3
- refs/tags/v2.4.0-rc4
- refs/tags/v2.4.0-rc5
- refs/tags/v2.4.1
- refs/tags/v2.4.1-rc1
- refs/tags/v2.4.1-rc2
- refs/tags/v2.4.1-rc3
- refs/tags/v2.4.1-rc4
- refs/tags/v2.4.1-rc5
- refs/tags/v2.4.1-rc6
- refs/tags/v2.4.1-rc7
- refs/tags/v2.4.1-rc8
- refs/tags/v2.4.1-rc9
- refs/tags/v2.4.2
- refs/tags/v2.4.2-rc1
- refs/tags/v2.4.3
- refs/tags/v2.4.3-rc1
- refs/tags/v2.4.4
- refs/tags/v2.4.4-rc1
- refs/tags/v2.4.4-rc2
- refs/tags/v2.4.4-rc3
- refs/tags/v2.4.5
- refs/tags/v2.4.5-rc1
- refs/tags/v2.4.5-rc2
- refs/tags/v2.4.6
- refs/tags/v2.4.6-rc1
- refs/tags/v2.4.6-rc2
- refs/tags/v2.4.6-rc3
- refs/tags/v2.4.6-rc4
- refs/tags/v2.4.6-rc5
- refs/tags/v2.4.6-rc6
- refs/tags/v2.4.6-rc7
- refs/tags/v2.4.6-rc8
- refs/tags/v2.4.7
- refs/tags/v2.4.7-rc1
- refs/tags/v2.4.7-rc2
- refs/tags/v2.4.7-rc3
- refs/tags/v2.4.8
- refs/tags/v2.4.8-rc1
- refs/tags/v2.4.8-rc2
- refs/tags/v2.4.8-rc3
- refs/tags/v2.4.8-rc4
- refs/tags/v3.0.0
- refs/tags/v3.0.0-preview2
- refs/tags/v3.0.0-preview2-rc1
- refs/tags/v3.0.0-preview2-rc2
- refs/tags/v3.0.0-rc1
- refs/tags/v3.0.0-rc2
- refs/tags/v3.0.0-rc3
- refs/tags/v3.0.1
- refs/tags/v3.0.1-rc1
- refs/tags/v3.0.1-rc2
- refs/tags/v3.0.1-rc3
- refs/tags/v3.0.2
- refs/tags/v3.0.2-rc1
- refs/tags/v3.0.3
- refs/tags/v3.0.3-rc1
- refs/tags/v3.1.0-rc1
- refs/tags/v3.1.1
- refs/tags/v3.1.1-rc1
- refs/tags/v3.1.1-rc2
- refs/tags/v3.1.1-rc3
- refs/tags/v3.1.2
- refs/tags/v3.1.2-rc1
- refs/tags/v3.1.3
- refs/tags/v3.1.3-rc1
- refs/tags/v3.1.3-rc2
- refs/tags/v3.1.3-rc3
- refs/tags/v3.1.3-rc4
- refs/tags/v3.2.0
- refs/tags/v3.2.0-rc1
- refs/tags/v3.2.0-rc2
- refs/tags/v3.2.0-rc3
- refs/tags/v3.2.0-rc4
- refs/tags/v3.2.0-rc5
- refs/tags/v3.2.0-rc6
- refs/tags/v3.2.0-rc7
- refs/tags/v3.2.1
- refs/tags/v3.2.1-rc1
- refs/tags/v3.2.1-rc2
- refs/tags/v3.2.2
- refs/tags/v3.2.2-rc1
- refs/tags/v3.2.3
- refs/tags/v3.2.3-rc1
- refs/tags/v3.2.4
- refs/tags/v3.2.4-rc1
- refs/tags/v3.3.0
- refs/tags/v3.3.0-rc1
- refs/tags/v3.3.0-rc2
- refs/tags/v3.3.0-rc3
- refs/tags/v3.3.0-rc4
- refs/tags/v3.3.0-rc5
- refs/tags/v3.3.0-rc6
- refs/tags/v3.3.1
- refs/tags/v3.3.1-rc1
- refs/tags/v3.3.1-rc2
- refs/tags/v3.3.1-rc3
- refs/tags/v3.3.1-rc4
- refs/tags/v3.3.2
- refs/tags/v3.3.2-rc1
- refs/tags/v3.3.3
- refs/tags/v3.3.3-rc1
- refs/tags/v3.3.4
- refs/tags/v3.3.4-rc1
- refs/tags/v3.4.0
- refs/tags/v3.4.0-rc1
- refs/tags/v3.4.0-rc2
- refs/tags/v3.4.0-rc3
- refs/tags/v3.4.0-rc4
- refs/tags/v3.4.0-rc5
- refs/tags/v3.4.0-rc6
- refs/tags/v3.4.0-rc7
- refs/tags/v3.4.1
- refs/tags/v3.4.1-rc1
- refs/tags/v3.4.2
- refs/tags/v3.4.2-rc1
- refs/tags/v3.5.0
- refs/tags/v3.5.0-rc1
- refs/tags/v3.5.0-rc2
- refs/tags/v3.5.0-rc3
- refs/tags/v3.5.0-rc4
- refs/tags/v3.5.0-rc5
- refs/tags/v3.5.1
- refs/tags/v3.5.1-rc1
- refs/tags/v3.5.1-rc2
Take a new snapshot of a software origin
If the archived software origin currently browsed is not synchronized with its upstream version (for instance when new commits have been issued), you can explicitly request Software Heritage to take a new snapshot of it.
Use the form below to proceed. Once a request has been submitted and accepted, it will be processed as soon as possible. You can then check its processing state by visiting this dedicated page.
Processing "take a new snapshot" request ...
Permalinks
To reference or cite the objects present in the Software Heritage archive, permalinks based on SoftWare Hash IDentifiers (SWHIDs) must be used.
Select below a type of object currently browsed in order to display its associated SWHID and permalink.
| Revision | Author | Date | Message | Commit Date |
|---|---|---|---|---|
| 489ecb0 | Sameer Agarwal | 22 January 2018, 18:49:08 UTC | Preparing Spark release v2.3.0-rc2 | 22 January 2018, 18:49:08 UTC |
| 4e75b0c | Sandor Murakozi | 22 January 2018, 18:36:28 UTC | [SPARK-23121][CORE] Fix for ui becoming unaccessible for long running streaming apps ## What changes were proposed in this pull request? The allJobs and the job pages attempt to use stage attempt and DAG visualization from the store, but for long running jobs they are not guaranteed to be retained, leading to exceptions when these pages are rendered. To fix it `store.lastStageAttempt(stageId)` and `store.operationGraphForJob(jobId)` are wrapped in `store.asOption` and default values are used if the info is missing. ## How was this patch tested? Manual testing of the UI, also using the test command reported in SPARK-23121: ./bin/spark-submit --class org.apache.spark.examples.streaming.HdfsWordCount ./examples/jars/spark-examples_2.11-2.4.0-SNAPSHOT.jar /spark Closes #20287 Author: Sandor Murakozi <smurakozi@gmail.com> Closes #20330 from smurakozi/SPARK-23121. (cherry picked from commit 446948af1d8dbc080a26a6eec6f743d338f1d12b) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> | 22 January 2018, 18:36:39 UTC |
| d963ba0 | Wenchen Fan | 22 January 2018, 12:56:38 UTC | [SPARK-23090][SQL] polish ColumnVector ## What changes were proposed in this pull request? Several improvements: * provide a default implementation for the batch get methods * rename `getChildColumn` to `getChild`, which is more concise * remove `getStruct(int, int)`, it's only used to simplify the codegen, which is an internal thing, we should not add a public API for this purpose. ## How was this patch tested? existing tests Author: Wenchen Fan <wenchen@databricks.com> Closes #20277 from cloud-fan/column-vector. (cherry picked from commit 5d680cae486c77cdb12dbe9e043710e49e8d51e4) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 22 January 2018, 12:56:57 UTC |
| 1069fad | gatorsmile | 22 January 2018, 12:32:59 UTC | [MINOR][SQL][TEST] Test case cleanups for recent PRs ## What changes were proposed in this pull request? Revert the unneeded test case changes we made in SPARK-23000 Also fixes the test suites that do not call `super.afterAll()` in the local `afterAll`. The `afterAll()` of `TestHiveSingleton` actually reset the environments. ## How was this patch tested? N/A Author: gatorsmile <gatorsmile@gmail.com> Closes #20341 from gatorsmile/testRelated. (cherry picked from commit 896e45af5fea264683b1d7d20a1711f33908a06f) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 22 January 2018, 12:33:07 UTC |
| d933fce | gatorsmile | 22 January 2018, 12:31:24 UTC | [SPARK-23170][SQL] Dump the statistics of effective runs of analyzer and optimizer rules ## What changes were proposed in this pull request? Dump the statistics of effective runs of analyzer and optimizer rules. ## How was this patch tested? Do a manual run of TPCDSQuerySuite ``` === Metrics of Analyzer/Optimizer Rules === Total number of runs: 175899 Total time: 25.486559948 seconds Rule Effective Time / Total Time Effective Runs / Total Runs org.apache.spark.sql.catalyst.optimizer.ColumnPruning 1603280450 / 2868461549 761 / 1877 org.apache.spark.sql.catalyst.analysis.Analyzer$CTESubstitution 2045860009 / 2056602674 37 / 788 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveAggregateFunctions 440719059 / 1693110949 38 / 1982 org.apache.spark.sql.catalyst.optimizer.Optimizer$OptimizeSubqueries 1429834919 / 1446016225 39 / 285 org.apache.spark.sql.catalyst.optimizer.PruneFilters 33273083 / 1389586938 3 / 1592 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveReferences 821183615 / 1266668754 616 / 1982 org.apache.spark.sql.catalyst.optimizer.ReorderJoin 775837028 / 866238225 132 / 1592 org.apache.spark.sql.catalyst.analysis.DecimalPrecision 550683593 / 748854507 211 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveSubquery 513075345 / 634370596 49 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$FixNullability 33475731 / 606406532 12 / 742 org.apache.spark.sql.catalyst.analysis.TypeCoercion$ImplicitTypeCasts 193144298 / 545403925 86 / 1982 org.apache.spark.sql.catalyst.optimizer.BooleanSimplification 18651497 / 495725004 7 / 1592 org.apache.spark.sql.catalyst.optimizer.PushPredicateThroughJoin 369257217 / 489934378 709 / 1592 org.apache.spark.sql.catalyst.optimizer.RemoveRedundantAliases 3707000 / 468291609 9 / 1592 org.apache.spark.sql.catalyst.optimizer.InferFiltersFromConstraints 410155900 / 435254175 192 / 285 org.apache.spark.sql.execution.datasources.FindDataSourceTable 348885539 / 371855866 233 / 1982 org.apache.spark.sql.catalyst.optimizer.NullPropagation 11307645 / 307531225 26 / 1592 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveFunctions 120324545 / 304948785 294 / 1982 org.apache.spark.sql.catalyst.analysis.TypeCoercion$FunctionArgumentConversion 92323199 / 286695007 38 / 1982 org.apache.spark.sql.catalyst.optimizer.PushDownPredicate 230084193 / 265845972 785 / 1592 org.apache.spark.sql.catalyst.analysis.TypeCoercion$PromoteStrings 45938401 / 265144009 40 / 1982 org.apache.spark.sql.catalyst.analysis.TypeCoercion$InConversion 14888776 / 261499450 1 / 1982 org.apache.spark.sql.catalyst.analysis.TypeCoercion$CaseWhenCoercion 113796384 / 244913861 29 / 1982 org.apache.spark.sql.catalyst.optimizer.ConstantFolding 65008069 / 236548480 126 / 1592 org.apache.spark.sql.catalyst.analysis.Analyzer$ExtractGenerator 0 / 226338929 0 / 1982 org.apache.spark.sql.catalyst.analysis.ResolveTimeZone 98134906 / 221323770 417 / 1982 org.apache.spark.sql.catalyst.optimizer.ReorderAssociativeOperator 0 / 208421703 0 / 1592 org.apache.spark.sql.catalyst.optimizer.OptimizeIn 8762534 / 199351958 16 / 1592 org.apache.spark.sql.catalyst.analysis.TypeCoercion$DateTimeOperations 11980016 / 190779046 27 / 1982 org.apache.spark.sql.catalyst.optimizer.SimplifyBinaryComparison 0 / 188887385 0 / 1592 org.apache.spark.sql.catalyst.optimizer.SimplifyConditionals 0 / 186812106 0 / 1592 org.apache.spark.sql.catalyst.optimizer.SimplifyCaseConversionExpressions 0 / 183885230 0 / 1592 org.apache.spark.sql.catalyst.optimizer.SimplifyCasts 17128295 / 182901910 69 / 1592 org.apache.spark.sql.catalyst.analysis.TypeCoercion$Division 14579110 / 180309340 8 / 1982 org.apache.spark.sql.catalyst.analysis.TypeCoercion$BooleanEquality 0 / 176740516 0 / 1982 org.apache.spark.sql.catalyst.analysis.TypeCoercion$IfCoercion 0 / 170781986 0 / 1982 org.apache.spark.sql.catalyst.optimizer.LikeSimplification 771605 / 164136736 1 / 1592 org.apache.spark.sql.catalyst.optimizer.RemoveDispensableExpressions 0 / 155958962 0 / 1592 org.apache.spark.sql.catalyst.analysis.ResolveCreateNamedStruct 0 / 151222943 0 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveWindowOrder 7534632 / 146596355 14 / 1982 org.apache.spark.sql.catalyst.analysis.TypeCoercion$EltCoercion 0 / 144488654 0 / 1982 org.apache.spark.sql.catalyst.analysis.TypeCoercion$ConcatCoercion 0 / 142403338 0 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveWindowFrame 12067635 / 141500665 21 / 1982 org.apache.spark.sql.catalyst.analysis.TimeWindowing 0 / 140431958 0 / 1982 org.apache.spark.sql.catalyst.analysis.TypeCoercion$WindowFrameCoercion 0 / 125471960 0 / 1982 org.apache.spark.sql.catalyst.optimizer.EliminateOuterJoin 14226972 / 124922019 11 / 1592 org.apache.spark.sql.catalyst.analysis.TypeCoercion$StackCoercion 0 / 123613887 0 / 1982 org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery 8491071 / 121179056 7 / 1592 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveGroupingAnalytics 55526073 / 120290529 11 / 1982 org.apache.spark.sql.catalyst.optimizer.ConstantPropagation 0 / 113886790 0 / 1592 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveDeserializer 52383759 / 107160222 148 / 1982 org.apache.spark.sql.catalyst.analysis.CleanupAliases 52543524 / 102091518 344 / 1086 org.apache.spark.sql.catalyst.optimizer.RemoveRedundantProject 40682895 / 94403652 342 / 1877 org.apache.spark.sql.catalyst.analysis.Analyzer$ExtractWindowExpressions 38473816 / 89740578 23 / 1982 org.apache.spark.sql.catalyst.optimizer.CollapseProject 46806090 / 83315506 281 / 1877 org.apache.spark.sql.catalyst.optimizer.FoldablePropagation 0 / 78750087 0 / 1592 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveAliases 13742765 / 77227258 47 / 1982 org.apache.spark.sql.catalyst.optimizer.CombineFilters 53386729 / 76960344 448 / 1592 org.apache.spark.sql.execution.datasources.DataSourceAnalysis 68034341 / 75724186 24 / 742 org.apache.spark.sql.catalyst.analysis.Analyzer$LookupFunctions 0 / 71151084 0 / 750 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveMissingReferences 12139848 / 67599140 8 / 1982 org.apache.spark.sql.catalyst.optimizer.PullupCorrelatedPredicates 45017938 / 65968777 23 / 285 org.apache.spark.sql.execution.datasources.v2.PushDownOperatorsToDataSource 0 / 60937767 0 / 285 org.apache.spark.sql.catalyst.optimizer.CollapseRepartition 0 / 59897237 0 / 1592 org.apache.spark.sql.catalyst.optimizer.PushProjectionThroughUnion 8547262 / 53941370 10 / 1592 org.apache.spark.sql.catalyst.analysis.Analyzer$HandleNullInputsForUDF 0 / 52735976 0 / 742 org.apache.spark.sql.catalyst.analysis.TypeCoercion$WidenSetOperationTypes 9797713 / 52401665 9 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$PullOutNondeterministic 0 / 51741500 0 / 742 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations 28614911 / 51061186 233 / 1990 org.apache.spark.sql.execution.datasources.PruneFileSourcePartitions 0 / 50621510 0 / 285 org.apache.spark.sql.catalyst.optimizer.CombineUnions 2777800 / 50262112 17 / 1877 org.apache.spark.sql.catalyst.analysis.Analyzer$GlobalAggregates 1640641 / 49633909 46 / 1982 org.apache.spark.sql.catalyst.optimizer.DecimalAggregates 20198374 / 48488419 100 / 385 org.apache.spark.sql.catalyst.optimizer.LimitPushDown 0 / 45052523 0 / 1592 org.apache.spark.sql.catalyst.optimizer.CombineLimits 0 / 44719443 0 / 1592 org.apache.spark.sql.catalyst.optimizer.EliminateSorts 0 / 44216930 0 / 1592 org.apache.spark.sql.catalyst.optimizer.RewritePredicateSubquery 36235699 / 44165786 148 / 285 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveNewInstance 0 / 42750307 0 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveUpCast 0 / 41811748 0 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveOrdinalInOrderByAndGroupBy 3819476 / 41776562 4 / 1982 org.apache.spark.sql.catalyst.optimizer.ComputeCurrentTime 0 / 40527808 0 / 285 org.apache.spark.sql.catalyst.optimizer.CollapseWindow 0 / 36832538 0 / 1592 org.apache.spark.sql.catalyst.optimizer.EliminateSerialization 0 / 36120667 0 / 1592 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveAggAliasInGroupBy 0 / 32435826 0 / 1982 org.apache.spark.sql.execution.datasources.PreprocessTableCreation 0 / 32145218 0 / 742 org.apache.spark.sql.execution.datasources.ResolveSQLOnFile 0 / 30295614 0 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolvePivot 0 / 30111655 0 / 1982 org.apache.spark.sql.catalyst.expressions.codegen.package$ExpressionCanonicalizer$CleanExpressions 59930 / 28038201 26 / 8280 org.apache.spark.sql.catalyst.analysis.ResolveInlineTables 0 / 27808108 0 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveSubqueryColumnAliases 0 / 27066690 0 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveGenerate 0 / 26660210 0 / 1982 org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveNaturalAndUsingJoin 0 / 25255184 0 / 1982 org.apache.spark.sql.catalyst.analysis.ResolveTableValuedFunctions 0 / 24663088 0 / 1990 org.apache.spark.sql.catalyst.analysis.SubstituteUnresolvedOrdinals 9709079 / 24450670 4 / 788 org.apache.spark.sql.catalyst.analysis.ResolveHints$ResolveBroadcastHints 0 / 23776535 0 / 750 org.apache.spark.sql.catalyst.optimizer.ReplaceExpressions 0 / 22697895 0 / 285 org.apache.spark.sql.catalyst.optimizer.CheckCartesianProducts 0 / 22523798 0 / 285 org.apache.spark.sql.catalyst.optimizer.ReplaceDistinctWithAggregate 988593 / 21535410 15 / 300 org.apache.spark.sql.catalyst.optimizer.EliminateMapObjects 0 / 20269996 0 / 285 org.apache.spark.sql.catalyst.optimizer.RewriteDistinctAggregates 0 / 19388592 0 / 285 org.apache.spark.sql.catalyst.analysis.EliminateSubqueryAliases 17675532 / 18971185 215 / 285 org.apache.spark.sql.catalyst.optimizer.GetCurrentDatabase 0 / 18271152 0 / 285 org.apache.spark.sql.catalyst.optimizer.PropagateEmptyRelation 2077097 / 17190855 3 / 288 org.apache.spark.sql.catalyst.analysis.EliminateBarriers 0 / 16736359 0 / 1086 org.apache.spark.sql.execution.OptimizeMetadataOnlyQuery 0 / 16669341 0 / 285 org.apache.spark.sql.catalyst.analysis.UpdateOuterReferences 0 / 14470235 0 / 742 org.apache.spark.sql.catalyst.optimizer.ReplaceExceptWithAntiJoin 6715625 / 12190561 1 / 300 org.apache.spark.sql.catalyst.optimizer.ReplaceIntersectWithSemiJoin 3451793 / 11431432 7 / 300 org.apache.spark.sql.execution.python.ExtractPythonUDFFromAggregate 0 / 10810568 0 / 285 org.apache.spark.sql.catalyst.optimizer.RemoveRepetitionFromGroupExpressions 344198 / 10475276 1 / 286 org.apache.spark.sql.catalyst.analysis.Analyzer$WindowsSubstitution 0 / 10386630 0 / 788 org.apache.spark.sql.catalyst.analysis.EliminateUnions 0 / 10096526 0 / 788 org.apache.spark.sql.catalyst.analysis.AliasViewChild 0 / 9991706 0 / 742 org.apache.spark.sql.catalyst.optimizer.ConvertToLocalRelation 0 / 9649334 0 / 288 org.apache.spark.sql.catalyst.analysis.ResolveHints$RemoveAllHints 0 / 8739109 0 / 750 org.apache.spark.sql.execution.datasources.PreprocessTableInsertion 0 / 8420889 0 / 742 org.apache.spark.sql.catalyst.analysis.EliminateView 0 / 8319134 0 / 285 org.apache.spark.sql.catalyst.optimizer.RemoveLiteralFromGroupExpressions 0 / 7392627 0 / 286 org.apache.spark.sql.catalyst.optimizer.ReplaceExceptWithFilter 0 / 7170516 0 / 300 org.apache.spark.sql.catalyst.optimizer.SimplifyCreateArrayOps 0 / 7109643 0 / 1592 org.apache.spark.sql.catalyst.optimizer.SimplifyCreateStructOps 0 / 6837590 0 / 1592 org.apache.spark.sql.catalyst.optimizer.SimplifyCreateMapOps 0 / 6617848 0 / 1592 org.apache.spark.sql.catalyst.optimizer.CombineConcats 0 / 5768406 0 / 1592 org.apache.spark.sql.catalyst.optimizer.ReplaceDeduplicateWithAggregate 0 / 5349831 0 / 285 org.apache.spark.sql.catalyst.optimizer.CombineTypedFilters 0 / 5186642 0 / 285 org.apache.spark.sql.catalyst.optimizer.EliminateDistinct 0 / 2427686 0 / 285 org.apache.spark.sql.catalyst.optimizer.CostBasedJoinReorder 0 / 2420436 0 / 285 ``` Author: gatorsmile <gatorsmile@gmail.com> Closes #20342 from gatorsmile/reportExecution. (cherry picked from commit 78801881c405de47f7e53eea3e0420dd69593dbd) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 22 January 2018, 12:31:42 UTC |
| 743b917 | gatorsmile | 22 January 2018, 12:27:59 UTC | [SPARK-23122][PYSPARK][FOLLOW-UP] Update the docs for UDF Registration ## What changes were proposed in this pull request? This PR is to update the docs for UDF registration ## How was this patch tested? N/A Author: gatorsmile <gatorsmile@gmail.com> Closes #20348 from gatorsmile/testUpdateDoc. (cherry picked from commit 73281161fc7fddd645c712986ec376ac2b1bd213) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 22 January 2018, 12:28:08 UTC |
| cf078a2 | Arseniy Tashoyan | 22 January 2018, 12:17:05 UTC | [MINOR][DOC] Fix the path to the examples jar ## What changes were proposed in this pull request? The example jar file is now in ./examples/jars directory of Spark distribution. Author: Arseniy Tashoyan <tashoyan@users.noreply.github.com> Closes #20349 from tashoyan/patch-1. (cherry picked from commit 60175e959f275d2961798fbc5a9150dac9de51ff) Signed-off-by: jerryshao <sshao@hortonworks.com> | 22 January 2018, 12:20:45 UTC |
| 57c320a | Marcelo Vanzin | 22 January 2018, 06:49:12 UTC | [SPARK-23020][CORE] Fix races in launcher code, test. The race in the code is because the handle might update its state to the wrong state if the connection handling thread is still processing incoming data; so the handle needs to wait for the connection to finish up before checking the final state. The race in the test is because when waiting for a handle to reach a final state, the waitFor() method needs to wait until all handle state is updated (which also includes waiting for the connection thread above to finish). Otherwise, waitFor() may return too early, which would cause a bunch of different races (like the listener not being yet notified of the state change, or being in the middle of being notified, or the handle not being properly disposed and causing postChecks() to assert). On top of that I found, by code inspection, a couple of potential races that could make a handle end up in the wrong state when being killed. The original version of this fix introduced the flipped version of the first race described above; the connection closing might override the handle state before the handle might have a chance to do cleanup. The fix there is to only dispose of the handle from the connection when there is an error, and let the handle dispose itself in the normal case. The fix also caused a bug in YarnClusterSuite to be surfaced; the code was checking for a file in the classpath that was not expected to be there in client mode. Because of the above issues, the error was not propagating correctly and the (buggy) test was incorrectly passing. Tested by running the existing unit tests a lot (and not seeing the errors I was seeing before). Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20297 from vanzin/SPARK-23020. (cherry picked from commit ec228976156619ed8df21a85bceb5fd3bdeb5855) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 22 January 2018, 06:49:32 UTC |
| 36af73b | Dongjoon Hyun | 22 January 2018, 06:18:57 UTC | [MINOR][SQL] Fix wrong comments on org.apache.spark.sql.parquet.row.attributes ## What changes were proposed in this pull request? This PR fixes the wrong comment on `org.apache.spark.sql.parquet.row.attributes` which is useful for UDTs like Vector/Matrix. Please see [SPARK-22320](https://issues.apache.org/jira/browse/SPARK-22320) for the usage. Originally, [SPARK-19411](https://github.com/apache/spark/commit/bf493686eb17006727b3ec81849b22f3df68fdef#diff-ee26d4c4be21e92e92a02e9f16dbc285L314) left this behind during removing optional column metadatas. In the same PR, the same comment was removed at line 310-311. ## How was this patch tested? N/A (This is about comments). Author: Dongjoon Hyun <dongjoon@apache.org> Closes #20346 from dongjoon-hyun/minor_comment_parquet. (cherry picked from commit 8142a3b883a5fe6fc620a2c5b25b6bde4fda32e5) Signed-off-by: hyukjinkwon <gurwls223@gmail.com> | 22 January 2018, 06:19:15 UTC |
| 5781fa7 | Russell Spitzer | 22 January 2018, 04:27:51 UTC | [SPARK-22976][CORE] Cluster mode driver dir removed while running ## What changes were proposed in this pull request? The clean up logic on the worker perviously determined the liveness of a particular applicaiton based on whether or not it had running executors. This would fail in the case that a directory was made for a driver running in cluster mode if that driver had no running executors on the same machine. To preserve driver directories we consider both executors and running drivers when checking directory liveness. ## How was this patch tested? Manually started up two node cluster with a single core on each node. Turned on worker directory cleanup and set the interval to 1 second and liveness to one second. Without the patch the driver directory is removed immediately after the app is launched. With the patch it is not ### Without Patch ``` INFO 2018-01-05 23:48:24,693 Logging.scala:54 - Asked to launch driver driver-20180105234824-0000 INFO 2018-01-05 23:48:25,293 Logging.scala:54 - Changing view acls to: cassandra INFO 2018-01-05 23:48:25,293 Logging.scala:54 - Changing modify acls to: cassandra INFO 2018-01-05 23:48:25,294 Logging.scala:54 - Changing view acls groups to: INFO 2018-01-05 23:48:25,294 Logging.scala:54 - Changing modify acls groups to: INFO 2018-01-05 23:48:25,294 Logging.scala:54 - SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(cassandra); groups with view permissions: Set(); users with modify permissions: Set(cassandra); groups with modify permissions: Set() INFO 2018-01-05 23:48:25,330 Logging.scala:54 - Copying user jar file:/home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180105234824-0000/writeRead-0.1.jar INFO 2018-01-05 23:48:25,332 Logging.scala:54 - Copying /home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180105234824-0000/writeRead-0.1.jar INFO 2018-01-05 23:48:25,361 Logging.scala:54 - Launch Command: "/usr/lib/jvm/jdk1.8.0_40//bin/java" .... **** INFO 2018-01-05 23:48:56,577 Logging.scala:54 - Removing directory: /var/lib/spark/worker/driver-20180105234824-0000 ### << Cleaned up **** -- One minute passes while app runs (app has 1 minute sleep built in) -- WARN 2018-01-05 23:49:58,080 ShuffleSecretManager.java:73 - Attempted to unregister application app-20180105234831-0000 when it is not registered INFO 2018-01-05 23:49:58,081 ExternalShuffleBlockResolver.java:163 - Application app-20180105234831-0000 removed, cleanupLocalDirs = false INFO 2018-01-05 23:49:58,081 ExternalShuffleBlockResolver.java:163 - Application app-20180105234831-0000 removed, cleanupLocalDirs = false INFO 2018-01-05 23:49:58,082 ExternalShuffleBlockResolver.java:163 - Application app-20180105234831-0000 removed, cleanupLocalDirs = true INFO 2018-01-05 23:50:00,999 Logging.scala:54 - Driver driver-20180105234824-0000 exited successfully ``` With Patch ``` INFO 2018-01-08 23:19:54,603 Logging.scala:54 - Asked to launch driver driver-20180108231954-0002 INFO 2018-01-08 23:19:54,975 Logging.scala:54 - Changing view acls to: automaton INFO 2018-01-08 23:19:54,976 Logging.scala:54 - Changing modify acls to: automaton INFO 2018-01-08 23:19:54,976 Logging.scala:54 - Changing view acls groups to: INFO 2018-01-08 23:19:54,976 Logging.scala:54 - Changing modify acls groups to: INFO 2018-01-08 23:19:54,976 Logging.scala:54 - SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(automaton); groups with view permissions: Set(); users with modify permissions: Set(automaton); groups with modify permissions: Set() INFO 2018-01-08 23:19:55,029 Logging.scala:54 - Copying user jar file:/home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180108231954-0002/writeRead-0.1.jar INFO 2018-01-08 23:19:55,031 Logging.scala:54 - Copying /home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180108231954-0002/writeRead-0.1.jar INFO 2018-01-08 23:19:55,038 Logging.scala:54 - Launch Command: ...... INFO 2018-01-08 23:21:28,674 ShuffleSecretManager.java:69 - Unregistered shuffle secret for application app-20180108232000-0000 INFO 2018-01-08 23:21:28,675 ExternalShuffleBlockResolver.java:163 - Application app-20180108232000-0000 removed, cleanupLocalDirs = false INFO 2018-01-08 23:21:28,675 ExternalShuffleBlockResolver.java:163 - Application app-20180108232000-0000 removed, cleanupLocalDirs = false INFO 2018-01-08 23:21:28,681 ExternalShuffleBlockResolver.java:163 - Application app-20180108232000-0000 removed, cleanupLocalDirs = true INFO 2018-01-08 23:21:31,703 Logging.scala:54 - Driver driver-20180108231954-0002 exited successfully ***** INFO 2018-01-08 23:21:32,346 Logging.scala:54 - Removing directory: /var/lib/spark/worker/driver-20180108231954-0002 ### < Happening AFTER the Run completes rather than during it ***** ``` Author: Russell Spitzer <Russell.Spitzer@gmail.com> Closes #20298 from RussellSpitzer/SPARK-22976-master. (cherry picked from commit 11daeb833222b1cd349fb1410307d64ab33981db) Signed-off-by: jerryshao <sshao@hortonworks.com> | 22 January 2018, 04:28:11 UTC |
| 7520491 | Felix Cheung | 21 January 2018, 19:23:51 UTC | [SPARK-21293][SS][SPARKR] Add doc example for streaming join, dedup ## What changes were proposed in this pull request? streaming programming guide changes ## How was this patch tested? manually Author: Felix Cheung <felixcheung_m@hotmail.com> Closes #20340 from felixcheung/rstreamdoc. (cherry picked from commit 2239d7a410e906ccd40aa8e84d637e9d06cd7b8a) Signed-off-by: Felix Cheung <felixcheung@apache.org> | 21 January 2018, 19:24:05 UTC |
| e0ef30f | Marco Gaido | 21 January 2018, 06:39:49 UTC | [SPARK-23087][SQL] CheckCartesianProduct too restrictive when condition is false/null ## What changes were proposed in this pull request? CheckCartesianProduct raises an AnalysisException also when the join condition is always false/null. In this case, we shouldn't raise it, since the result will not be a cartesian product. ## How was this patch tested? added UT Author: Marco Gaido <marcogaido91@gmail.com> Closes #20333 from mgaido91/SPARK-23087. (cherry picked from commit 121dc96f088a7b157d5b2cffb626b0e22d1fc052) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 21 January 2018, 06:39:58 UTC |
| b9c1367 | fjh100456 | 20 January 2018, 22:49:49 UTC | [SPARK-21786][SQL] The 'spark.sql.parquet.compression.codec' and 'spark.sql.orc.compression.codec' configuration doesn't take effect on hive table writing [SPARK-21786][SQL] The 'spark.sql.parquet.compression.codec' and 'spark.sql.orc.compression.codec' configuration doesn't take effect on hive table writing What changes were proposed in this pull request? Pass ‘spark.sql.parquet.compression.codec’ value to ‘parquet.compression’. Pass ‘spark.sql.orc.compression.codec’ value to ‘orc.compress’. How was this patch tested? Add test. Note: This is the same issue mentioned in #19218 . That branch was deleted mistakenly, so make a new pr instead. gatorsmile maropu dongjoon-hyun discipleforteen Author: fjh100456 <fu.jinhua6@zte.com.cn> Author: Takeshi Yamamuro <yamamuro@apache.org> Author: Wenchen Fan <wenchen@databricks.com> Author: gatorsmile <gatorsmile@gmail.com> Author: Yinan Li <liyinan926@gmail.com> Author: Marcelo Vanzin <vanzin@cloudera.com> Author: Juliusz Sompolski <julek@databricks.com> Author: Felix Cheung <felixcheung_m@hotmail.com> Author: jerryshao <sshao@hortonworks.com> Author: Li Jin <ice.xelloss@gmail.com> Author: Gera Shegalov <gera@apache.org> Author: chetkhatri <ckhatrimanjal@gmail.com> Author: Joseph K. Bradley <joseph@databricks.com> Author: Bago Amirbekian <bago@databricks.com> Author: Xianjin YE <advancedxy@gmail.com> Author: Bruce Robbins <bersprockets@gmail.com> Author: zuotingbing <zuo.tingbing9@zte.com.cn> Author: Kent Yao <yaooqinn@hotmail.com> Author: hyukjinkwon <gurwls223@gmail.com> Author: Adrian Ionescu <adrian@databricks.com> Closes #20087 from fjh100456/HiveTableWriting. (cherry picked from commit 00d169156d4b1c91d2bcfd788b254b03c509dc41) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 20 January 2018, 22:50:04 UTC |
| e11d5ea | Shashwat Anand | 20 January 2018, 22:34:37 UTC | [SPARK-23165][DOC] Spelling mistake fix in quick-start doc. ## What changes were proposed in this pull request? Fix spelling in quick-start doc. ## How was this patch tested? Doc only. Author: Shashwat Anand <me@shashwat.me> Closes #20336 from ashashwat/SPARK-23165. (cherry picked from commit 84a076e0e9a38a26edf7b702c24fdbbcf1e697b9) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 20 January 2018, 22:35:53 UTC |
| 0cde521 | Sean Owen | 20 January 2018, 06:46:34 UTC | [SPARK-23091][ML] Incorrect unit test for approxQuantile ## What changes were proposed in this pull request? Narrow bound on approx quantile test to epsilon from 2*epsilon to match paper ## How was this patch tested? Existing tests. Author: Sean Owen <sowen@cloudera.com> Closes #20324 from srowen/SPARK-23091. (cherry picked from commit 396cdfbea45232bacbc03bfaf8be4ea85d47d3fd) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 20 January 2018, 06:46:47 UTC |
| c647f91 | Kent Yao | 19 January 2018, 23:49:29 UTC | [SPARK-21771][SQL] remove useless hive client in SparkSQLEnv ## What changes were proposed in this pull request? Once a meta hive client is created, it generates its SessionState which creates a lot of session related directories, some deleteOnExit, some does not. if a hive client is useless we may not create it at the very start. ## How was this patch tested? N/A cc hvanhovell cloud-fan Author: Kent Yao <11215016@zju.edu.cn> Closes #18983 from yaooqinn/patch-1. (cherry picked from commit 793841c6b8b98b918dcf241e29f60ef125914db9) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 19 January 2018, 23:49:37 UTC |
| f9ad00a | Marcelo Vanzin | 19 January 2018, 21:14:24 UTC | [SPARK-23135][UI] Fix rendering of accumulators in the stage page. This follows the behavior of 2.2: only named accumulators with a value are rendered. Screenshot:  Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20299 from vanzin/SPARK-23135. (cherry picked from commit f6da41b0150725fe96ccb2ee3b48840b207f47eb) Signed-off-by: Sameer Agarwal <sameerag@apache.org> | 19 January 2018, 21:14:38 UTC |
| d0cb198 | Marcelo Vanzin | 19 January 2018, 19:32:20 UTC | [SPARK-23103][CORE] Ensure correct sort order for negative values in LevelDB. The code was sorting "0" as "less than" negative values, which is a little wrong. Fix is simple, most of the changes are the added test and related cleanup. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20284 from vanzin/SPARK-23103. (cherry picked from commit aa3a1276f9e23ffbb093d00743e63cd4369f9f57) Signed-off-by: Imran Rashid <irashid@cloudera.com> | 19 January 2018, 19:32:38 UTC |
| 4b79514 | Marcelo Vanzin | 19 January 2018, 19:26:37 UTC | [SPARK-20664][CORE] Delete stale application data from SHS. Detect the deletion of event log files from storage, and remove data about the related application attempt in the SHS. Also contains code to fix SPARK-21571 based on code by ericvandenbergfb. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20138 from vanzin/SPARK-20664. (cherry picked from commit fed2139f053fac4a9a6952ff0ab1cc2a5f657bd0) Signed-off-by: Imran Rashid <irashid@cloudera.com> | 19 January 2018, 19:27:02 UTC |
| ffe4591 | foxish | 19 January 2018, 18:23:13 UTC | [SPARK-23104][K8S][DOCS] Changes to Kubernetes scheduler documentation ## What changes were proposed in this pull request? Docs changes: - Adding a warning that the backend is experimental. - Removing a defunct internal-only option from documentation - Clarifying that node selectors can be used right away, and other minor cosmetic changes ## How was this patch tested? Docs only change Author: foxish <ramanathana@google.com> Closes #20314 from foxish/ambiguous-docs. (cherry picked from commit 73d3b230f3816a854a181c0912d87b180e347271) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> | 19 January 2018, 18:23:26 UTC |
| 55efeff | Wenchen Fan | 19 January 2018, 16:58:21 UTC | [SPARK-23149][SQL] polish ColumnarBatch ## What changes were proposed in this pull request? Several cleanups in `ColumnarBatch` * remove `schema`. The `ColumnVector`s inside `ColumnarBatch` already have the data type information, we don't need this `schema`. * remove `capacity`. `ColumnarBatch` is just a wrapper of `ColumnVector`s, not builders, it doesn't need a capacity property. * remove `DEFAULT_BATCH_SIZE`. As a wrapper, `ColumnarBatch` can't decide the batch size, it should be decided by the reader, e.g. parquet reader, orc reader, cached table reader. The default batch size should also be defined by the reader. ## How was this patch tested? existing tests. Author: Wenchen Fan <wenchen@databricks.com> Closes #20316 from cloud-fan/columnar-batch. (cherry picked from commit d8aaa771e249b3f54b57ce24763e53fd65a0dbf7) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 19 January 2018, 16:58:29 UTC |
| 8d6845c | gatorsmile | 19 January 2018, 14:47:18 UTC | [SPARK-23000][TEST] Keep Derby DB Location Unchanged After Session Cloning ## What changes were proposed in this pull request? After session cloning in `TestHive`, the conf of the singleton SparkContext for derby DB location is changed to a new directory. The new directory is created in `HiveUtils.newTemporaryConfiguration(useInMemoryDerby = false)`. This PR is to keep the conf value of `ConfVars.METASTORECONNECTURLKEY.varname` unchanged during the session clone. ## How was this patch tested? The issue can be reproduced by the command: > build/sbt -Phive "hive/test-only org.apache.spark.sql.hive.HiveSessionStateSuite org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite" Also added a test case. Author: gatorsmile <gatorsmile@gmail.com> Closes #20328 from gatorsmile/fixTestFailure. (cherry picked from commit 6c39654efcb2aa8cb4d082ab7277a6fa38fb48e4) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 19 January 2018, 14:47:36 UTC |
| b7a8199 | Marco Gaido | 19 January 2018, 11:46:48 UTC | [SPARK-23089][STS] Recreate session log directory if it doesn't exist ## What changes were proposed in this pull request? When creating a session directory, Thrift should create the parent directory (i.e. /tmp/base_session_log_dir) if it is not present. It is common that many tools delete empty directories, so the directory may be deleted. This can cause the session log to be disabled. This was fixed in HIVE-12262: this PR brings it in Spark too. ## How was this patch tested? manual tests Author: Marco Gaido <marcogaido91@gmail.com> Closes #20281 from mgaido91/SPARK-23089. (cherry picked from commit e41400c3c8aace9eb72e6134173f222627fb0faf) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 19 January 2018, 11:47:15 UTC |
| ef7989d | Liang-Chi Hsieh | 19 January 2018, 10:48:42 UTC | [SPARK-23048][ML] Add OneHotEncoderEstimator document and examples ## What changes were proposed in this pull request? We have `OneHotEncoderEstimator` now and `OneHotEncoder` will be deprecated since 2.3.0. We should add `OneHotEncoderEstimator` into mllib document. We also need to provide corresponding examples for `OneHotEncoderEstimator` which are used in the document too. ## How was this patch tested? Existing tests. Author: Liang-Chi Hsieh <viirya@gmail.com> Closes #20257 from viirya/SPARK-23048. (cherry picked from commit b74366481cc87490adf4e69d26389ec737548c15) Signed-off-by: Nick Pentreath <nickp@za.ibm.com> | 19 January 2018, 10:48:55 UTC |
| e582231 | Nick Pentreath | 19 January 2018, 10:43:23 UTC | [SPARK-23127][DOC] Update FeatureHasher guide for categoricalCols parameter Update user guide entry for `FeatureHasher` to match the Scala / Python doc, to describe the `categoricalCols` parameter. ## How was this patch tested? Doc only Author: Nick Pentreath <nickp@za.ibm.com> Closes #20293 from MLnick/SPARK-23127-catCol-userguide. (cherry picked from commit 60203fca6a605ad158184e1e0ce5187e144a3ea7) Signed-off-by: Nick Pentreath <nickp@za.ibm.com> | 19 January 2018, 10:43:35 UTC |
| 54c1fae | Sameer Agarwal | 19 January 2018, 09:38:08 UTC | [BUILD][MINOR] Fix java style check issues ## What changes were proposed in this pull request? This patch fixes a few recently introduced java style check errors in master and release branch. As an aside, given that [java linting currently fails](https://github.com/apache/spark/pull/10763 ) on machines with a clean maven cache, it'd be great to find another workaround to [re-enable the java style checks](https://github.com/apache/spark/blob/3a07eff5af601511e97a05e6fea0e3d48f74c4f0/dev/run-tests.py#L577) as part of Spark PRB. /cc zsxwing JoshRosen srowen for any suggestions ## How was this patch tested? Manual Check Author: Sameer Agarwal <sameerag@apache.org> Closes #20323 from sameeragarwal/java. (cherry picked from commit 9c4b99861cda3f9ec44ca8c1adc81a293508190c) Signed-off-by: Sameer Agarwal <sameerag@apache.org> | 19 January 2018, 09:38:20 UTC |
| 541dbc0 | Takuya UESHIN | 19 January 2018, 03:37:08 UTC | [SPARK-23054][SQL][PYSPARK][FOLLOWUP] Use sqlType casting when casting PythonUserDefinedType to String. ## What changes were proposed in this pull request? This is a follow-up of #20246. If a UDT in Python doesn't have its corresponding Scala UDT, cast to string will be the raw string of the internal value, e.g. `"org.apache.spark.sql.catalyst.expressions.UnsafeArrayDataxxxxxxxx"` if the internal type is `ArrayType`. This pr fixes it by using its `sqlType` casting. ## How was this patch tested? Added a test and existing tests. Author: Takuya UESHIN <ueshin@databricks.com> Closes #20306 from ueshin/issues/SPARK-23054/fup1. (cherry picked from commit 568055da93049c207bb830f244ff9b60c638837c) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 19 January 2018, 03:38:37 UTC |
| 225b1af | brandonJY | 19 January 2018, 00:57:49 UTC | [DOCS] change to dataset for java code in structured-streaming-kafka-integration document ## What changes were proposed in this pull request? In latest structured-streaming-kafka-integration document, Java code example for Kafka integration is using `DataFrame<Row>`, shouldn't it be changed to `DataSet<Row>`? ## How was this patch tested? manual test has been performed to test the updated example Java code in Spark 2.2.1 with Kafka 1.0 Author: brandonJY <brandonJY@users.noreply.github.com> Closes #20312 from brandonJY/patch-2. (cherry picked from commit 6121e91b7f5c9513d68674e4d5edbc3a4a5fd5fd) Signed-off-by: Sean Owen <sowen@cloudera.com> | 19 January 2018, 00:57:56 UTC |
| acf3b70 | Tathagata Das | 19 January 2018, 00:29:45 UTC | [SPARK-23142][SS][DOCS] Added docs for continuous processing ## What changes were proposed in this pull request? Added documentation for continuous processing. Modified two locations. - Modified the overview to have a mention of Continuous Processing. - Added a new section on Continuous Processing at the end.   ## How was this patch tested? N/A Author: Tathagata Das <tathagata.das1565@gmail.com> Closes #20308 from tdas/SPARK-23142. (cherry picked from commit 4cd2ecc0c7222fef1337e04f1948333296c3be86) Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com> | 19 January 2018, 00:29:56 UTC |
| 7057e31 | Yinan Li | 18 January 2018, 22:44:22 UTC | [SPARK-22962][K8S] Fail fast if submission client local files are used ## What changes were proposed in this pull request? In the Kubernetes mode, fails fast in the submission process if any submission client local dependencies are used as the use case is not supported yet. ## How was this patch tested? Unit tests, integration tests, and manual tests. vanzin foxish Author: Yinan Li <liyinan926@gmail.com> Closes #20320 from liyinan926/master. (cherry picked from commit 5d7c4ba4d73a72f26d591108db3c20b4a6c84f3f) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> | 18 January 2018, 22:44:33 UTC |
| a295034 | Burak Yavuz | 18 January 2018, 22:36:06 UTC | [SPARK-23094] Fix invalid character handling in JsonDataSource ## What changes were proposed in this pull request? There were two related fixes regarding `from_json`, `get_json_object` and `json_tuple` ([Fix #1](https://github.com/apache/spark/commit/c8803c06854683c8761fdb3c0e4c55d5a9e22a95), [Fix #2](https://github.com/apache/spark/commit/86174ea89b39a300caaba6baffac70f3dc702788)), but they weren't comprehensive it seems. I wanted to extend those fixes to all the parsers, and add tests for each case. ## How was this patch tested? Regression tests Author: Burak Yavuz <brkyvz@gmail.com> Closes #20302 from brkyvz/json-invfix. (cherry picked from commit e01919e834d301e13adc8919932796ebae900576) Signed-off-by: hyukjinkwon <gurwls223@gmail.com> | 18 January 2018, 22:36:21 UTC |
| b8c6d93 | Andrew Korzhuev | 18 January 2018, 22:00:12 UTC | [SPARK-23133][K8S] Fix passing java options to Executor Pass through spark java options to the executor in context of docker image. Closes #20296 andrusha: Deployed two version of containers to local k8s, checked that java options were present in the updated image on the running executor. Manual test Author: Andrew Korzhuev <korzhuev@andrusha.me> Closes #20322 from foxish/patch-1. (cherry picked from commit f568e9cf76f657d094f1d036ab5a95f2531f5761) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> | 18 January 2018, 22:01:19 UTC |
| 1f88fcd | Tathagata Das | 18 January 2018, 20:33:39 UTC | [SPARK-23144][SS] Added console sink for continuous processing ## What changes were proposed in this pull request? Refactored ConsoleWriter into ConsoleMicrobatchWriter and ConsoleContinuousWriter. ## How was this patch tested? new unit test Author: Tathagata Das <tathagata.das1565@gmail.com> Closes #20311 from tdas/SPARK-23144. (cherry picked from commit bf34d665b9c865e00fac7001500bf6d521c2dff9) Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com> | 18 January 2018, 20:33:54 UTC |
| e6e8bbe | Tathagata Das | 18 January 2018, 20:25:52 UTC | [SPARK-23143][SS][PYTHON] Added python API for setting continuous trigger ## What changes were proposed in this pull request? Self-explanatory. ## How was this patch tested? New python tests. Author: Tathagata Das <tathagata.das1565@gmail.com> Closes #20309 from tdas/SPARK-23143. (cherry picked from commit 2d41f040a34d6483919fd5d491cf90eee5429290) Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com> | 18 January 2018, 20:26:07 UTC |
| bfdbdd3 | Fernando Pereira | 18 January 2018, 19:02:03 UTC | [SPARK-23029][DOCS] Specifying default units of configuration entries ## What changes were proposed in this pull request? This PR completes the docs, specifying the default units assumed in configuration entries of type size. This is crucial since unit-less values are accepted and the user might assume the base unit is bytes, which in most cases it is not, leading to hard-to-debug problems. ## How was this patch tested? This patch updates only documentation only. Author: Fernando Pereira <fernando.pereira@epfl.ch> Closes #20269 from ferdonline/docs_units. (cherry picked from commit 9678941f54ebc5db935ed8d694e502086e2a31c0) Signed-off-by: Sean Owen <sowen@cloudera.com> | 18 January 2018, 19:02:10 UTC |
| bd0a162 | jerryshao | 18 January 2018, 18:19:36 UTC | [SPARK-23147][UI] Fix task page table IndexOutOfBound Exception ## What changes were proposed in this pull request? Stage's task page table will throw an exception when there's no complete tasks. Furthermore, because the `dataSize` doesn't take running tasks into account, so sometimes UI cannot show the running tasks. Besides table will only be displayed when first task is finished according to the default sortColumn("index"). 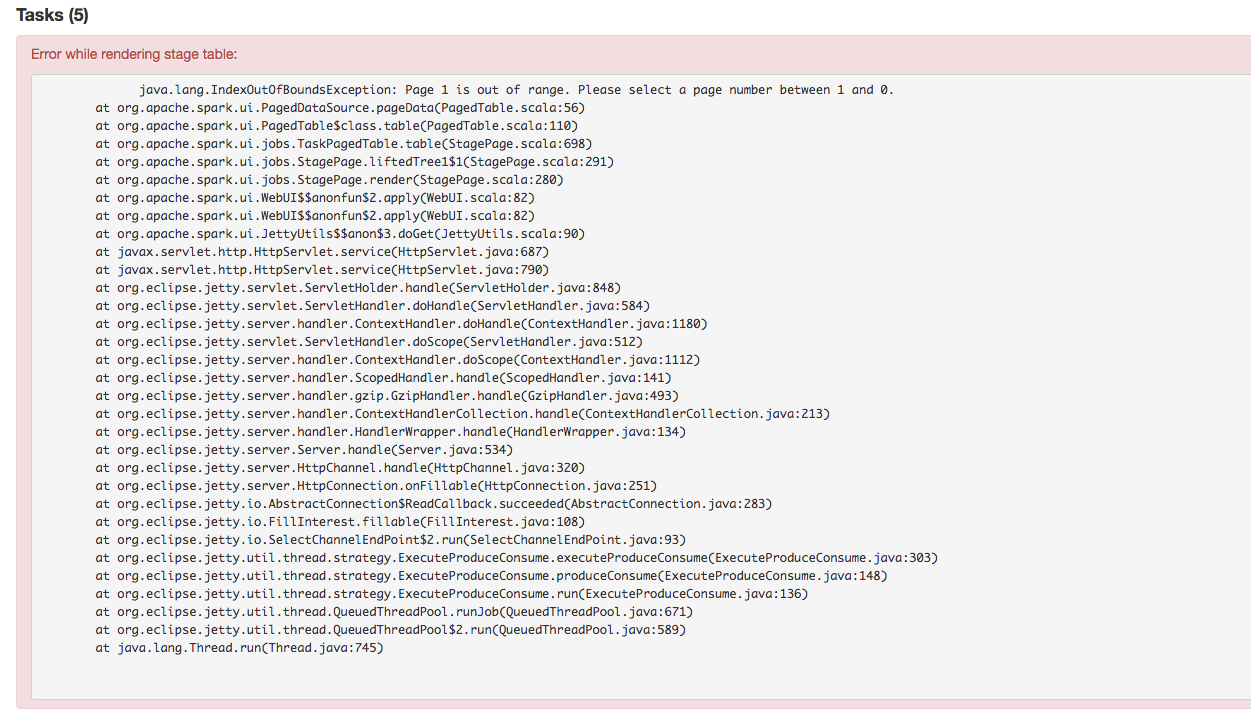 To reproduce this issue, user could try `sc.parallelize(1 to 20, 20).map { i => Thread.sleep(10000); i }.collect()` or `sc.parallelize(1 to 20, 20).map { i => Thread.sleep((20 - i) * 1000); i }.collect` to reproduce the above issue. Here propose a solution to fix it. Not sure if it is a right fix, please help to review. ## How was this patch tested? Manual test. Author: jerryshao <sshao@hortonworks.com> Closes #20315 from jerryshao/SPARK-23147. (cherry picked from commit cf7ee1767ddadce08dce050fc3b40c77cdd187da) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> | 18 January 2018, 18:19:48 UTC |
| e0421c6 | Takuya UESHIN | 18 January 2018, 13:33:04 UTC | [SPARK-23141][SQL][PYSPARK] Support data type string as a returnType for registerJavaFunction. ## What changes were proposed in this pull request? Currently `UDFRegistration.registerJavaFunction` doesn't support data type string as a `returnType` whereas `UDFRegistration.register`, `udf`, or `pandas_udf` does. We can support it for `UDFRegistration.registerJavaFunction` as well. ## How was this patch tested? Added a doctest and existing tests. Author: Takuya UESHIN <ueshin@databricks.com> Closes #20307 from ueshin/issues/SPARK-23141. (cherry picked from commit 5063b7481173ad72bd0dc941b5cf3c9b26a591e4) Signed-off-by: hyukjinkwon <gurwls223@gmail.com> | 18 January 2018, 13:33:25 UTC |
| 8a98274 | Marco Gaido | 18 January 2018, 13:24:39 UTC | [SPARK-22036][SQL] Decimal multiplication with high precision/scale often returns NULL ## What changes were proposed in this pull request? When there is an operation between Decimals and the result is a number which is not representable exactly with the result's precision and scale, Spark is returning `NULL`. This was done to reflect Hive's behavior, but it is against SQL ANSI 2011, which states that "If the result cannot be represented exactly in the result type, then whether it is rounded or truncated is implementation-defined". Moreover, Hive now changed its behavior in order to respect the standard, thanks to HIVE-15331. Therefore, the PR propose to: - update the rules to determine the result precision and scale according to the new Hive's ones introduces in HIVE-15331; - round the result of the operations, when it is not representable exactly with the result's precision and scale, instead of returning `NULL` - introduce a new config `spark.sql.decimalOperations.allowPrecisionLoss` which default to `true` (ie. the new behavior) in order to allow users to switch back to the previous one. Hive behavior reflects SQLServer's one. The only difference is that the precision and scale are adjusted for all the arithmetic operations in Hive, while SQL Server is said to do so only for multiplications and divisions in the documentation. This PR follows Hive's behavior. A more detailed explanation is available here: https://mail-archives.apache.org/mod_mbox/spark-dev/201712.mbox/%3CCAEorWNAJ4TxJR9NBcgSFMD_VxTg8qVxusjP%2BAJP-x%2BJV9zH-yA%40mail.gmail.com%3E. ## How was this patch tested? modified and added UTs. Comparisons with results of Hive and SQLServer. Author: Marco Gaido <marcogaido91@gmail.com> Closes #20023 from mgaido91/SPARK-22036. (cherry picked from commit e28eb431146bcdcaf02a6f6c406ca30920592a6a) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 18 January 2018, 13:25:16 UTC |
| f801ac4 | jerryshao | 18 January 2018, 11:18:55 UTC | [SPARK-23140][SQL] Add DataSourceV2Strategy to Hive Session state's planner ## What changes were proposed in this pull request? `DataSourceV2Strategy` is missing in `HiveSessionStateBuilder`'s planner, which will throw exception as described in [SPARK-23140](https://issues.apache.org/jira/browse/SPARK-23140). ## How was this patch tested? Manual test. Author: jerryshao <sshao@hortonworks.com> Closes #20305 from jerryshao/SPARK-23140. (cherry picked from commit 7a2248341396840628eef398aa512cac3e3bd55f) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 18 January 2018, 11:20:16 UTC |
| 2a87c3a | Jose Torres | 18 January 2018, 06:36:29 UTC | [SPARK-23052][SS] Migrate ConsoleSink to data source V2 api. ## What changes were proposed in this pull request? Migrate ConsoleSink to data source V2 api. Note that this includes a missing piece in DataStreamWriter required to specify a data source V2 writer. Note also that I've removed the "Rerun batch" part of the sink, because as far as I can tell this would never have actually happened. A MicroBatchExecution object will only commit each batch once for its lifetime, and a new MicroBatchExecution object would have a new ConsoleSink object which doesn't know it's retrying a batch. So I think this represents an anti-feature rather than a weakness in the V2 API. ## How was this patch tested? new unit test Author: Jose Torres <jose@databricks.com> Closes #20243 from jose-torres/console-sink. (cherry picked from commit 1c76a91e5fae11dcb66c453889e587b48039fdc9) Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com> | 18 January 2018, 06:36:41 UTC |
| 3a80cc5 | hyukjinkwon | 18 January 2018, 05:51:05 UTC | [SPARK-23122][PYTHON][SQL] Deprecate register* for UDFs in SQLContext and Catalog in PySpark ## What changes were proposed in this pull request? This PR proposes to deprecate `register*` for UDFs in `SQLContext` and `Catalog` in Spark 2.3.0. These are inconsistent with Scala / Java APIs and also these basically do the same things with `spark.udf.register*`. Also, this PR moves the logcis from `[sqlContext|spark.catalog].register*` to `spark.udf.register*` and reuse the docstring. This PR also handles minor doc corrections. It also includes https://github.com/apache/spark/pull/20158 ## How was this patch tested? Manually tested, manually checked the API documentation and tests added to check if deprecated APIs call the aliases correctly. Author: hyukjinkwon <gurwls223@gmail.com> Closes #20288 from HyukjinKwon/deprecate-udf. (cherry picked from commit 39d244d921d8d2d3ed741e8e8f1175515a74bdbd) Signed-off-by: Takuya UESHIN <ueshin@databricks.com> | 18 January 2018, 05:51:19 UTC |
| f2688ef | Xiayun Sun | 18 January 2018, 00:42:38 UTC | [SPARK-21996][SQL] read files with space in name for streaming ## What changes were proposed in this pull request? Structured streaming is now able to read files with space in file name (previously it would skip the file and output a warning) ## How was this patch tested? Added new unit test. Author: Xiayun Sun <xiayunsun@gmail.com> Closes #19247 from xysun/SPARK-21996. (cherry picked from commit 02194702068291b3af77486d01029fb848c36d7b) Signed-off-by: Shixiong Zhu <zsxwing@gmail.com> | 18 January 2018, 00:42:45 UTC |
| 050c1e2 | Tathagata Das | 18 January 2018, 00:41:43 UTC | [SPARK-23064][DOCS][SS] Added documentation for stream-stream joins ## What changes were proposed in this pull request? Added documentation for stream-stream joins     ## How was this patch tested? N/a Author: Tathagata Das <tathagata.das1565@gmail.com> Closes #20255 from tdas/join-docs. (cherry picked from commit 1002bd6b23ff78a010ca259ea76988ef4c478c6e) Signed-off-by: Shixiong Zhu <zsxwing@gmail.com> | 18 January 2018, 00:41:49 UTC |
| 9783aea | Tathagata Das | 18 January 2018, 00:40:02 UTC | [SPARK-23119][SS] Minor fixes to V2 streaming APIs ## What changes were proposed in this pull request? - Added `InterfaceStability.Evolving` annotations - Improved docs. ## How was this patch tested? Existing tests. Author: Tathagata Das <tathagata.das1565@gmail.com> Closes #20286 from tdas/SPARK-23119. (cherry picked from commit bac0d661af6092dd26638223156827aceb901229) Signed-off-by: Shixiong Zhu <zsxwing@gmail.com> | 18 January 2018, 00:40:11 UTC |
| b84c2a3 | hyukjinkwon | 17 January 2018, 22:30:54 UTC | [SPARK-23132][PYTHON][ML] Run doctests in ml.image when testing ## What changes were proposed in this pull request? This PR proposes to actually run the doctests in `ml/image.py`. ## How was this patch tested? doctests in `python/pyspark/ml/image.py`. Author: hyukjinkwon <gurwls223@gmail.com> Closes #20294 from HyukjinKwon/trigger-image. (cherry picked from commit 45ad97df87c89cb94ce9564e5773897b6d9326f5) Signed-off-by: hyukjinkwon <gurwls223@gmail.com> | 17 January 2018, 22:31:10 UTC |
| 6e509fd | Li Jin | 17 January 2018, 22:26:43 UTC | [SPARK-23047][PYTHON][SQL] Change MapVector to NullableMapVector in ArrowColumnVector ## What changes were proposed in this pull request? This PR changes usage of `MapVector` in Spark codebase to use `NullableMapVector`. `MapVector` is an internal Arrow class that is not supposed to be used directly. We should use `NullableMapVector` instead. ## How was this patch tested? Existing test. Author: Li Jin <ice.xelloss@gmail.com> Closes #20239 from icexelloss/arrow-map-vector. (cherry picked from commit 4e6f8fb150ae09c7d1de6beecb2b98e5afa5da19) Signed-off-by: hyukjinkwon <gurwls223@gmail.com> | 17 January 2018, 22:26:57 UTC |
| 79ccd0c | Jose Torres | 17 January 2018, 21:58:44 UTC | [SPARK-23093][SS] Don't change run id when reconfiguring a continuous processing query. ## What changes were proposed in this pull request? Keep the run ID static, using a different ID for the epoch coordinator to avoid cross-execution message contamination. ## How was this patch tested? new and existing unit tests Author: Jose Torres <jose@databricks.com> Closes #20282 from jose-torres/fix-runid. (cherry picked from commit e946c63dd56d121cf898084ed7e9b5b0868b226e) Signed-off-by: Shixiong Zhu <zsxwing@gmail.com> | 17 January 2018, 21:58:53 UTC |
| dbd2a55 | Jose Torres | 17 January 2018, 21:52:51 UTC | [SPARK-23033][SS] Don't use task level retry for continuous processing ## What changes were proposed in this pull request? Continuous processing tasks will fail on any attempt number greater than 0. ContinuousExecution will catch these failures and restart globally from the last recorded checkpoints. ## How was this patch tested? unit test Author: Jose Torres <jose@databricks.com> Closes #20225 from jose-torres/no-retry. (cherry picked from commit 86a845031824a5334db6a5299c6f5dcc982bc5b8) Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com> | 17 January 2018, 21:53:02 UTC |
| 1a6dfaf | Sameer Agarwal | 17 January 2018, 17:27:49 UTC | [SPARK-23020] Ignore Flaky Test: SparkLauncherSuite.testInProcessLauncher ## What changes were proposed in this pull request? Temporarily ignoring flaky test `SparkLauncherSuite.testInProcessLauncher` to de-flake the builds. This should be re-enabled when SPARK-23020 is merged. ## How was this patch tested? N/A (Test Only Change) Author: Sameer Agarwal <sameerag@apache.org> Closes #20291 from sameeragarwal/disable-test-2. (cherry picked from commit c132538a164cd8b55dbd7e8ffdc0c0782a0b588c) Signed-off-by: Sameer Agarwal <sameerag@apache.org> | 17 January 2018, 17:28:02 UTC |
| aae73a2 | Wang Gengliang | 17 January 2018, 16:05:26 UTC | [SPARK-23079][SQL] Fix query constraints propagation with aliases ## What changes were proposed in this pull request? Previously, PR #19201 fix the problem of non-converging constraints. After that PR #19149 improve the loop and constraints is inferred only once. So the problem of non-converging constraints is gone. However, the case below will fail. ``` spark.range(5).write.saveAsTable("t") val t = spark.read.table("t") val left = t.withColumn("xid", $"id" + lit(1)).as("x") val right = t.withColumnRenamed("id", "xid").as("y") val df = left.join(right, "xid").filter("id = 3").toDF() checkAnswer(df, Row(4, 3)) ``` Because `aliasMap` replace all the aliased child. See the test case in PR for details. This PR is to fix this bug by removing useless code for preventing non-converging constraints. It can be also fixed with #20270, but this is much simpler and clean up the code. ## How was this patch tested? Unit test Author: Wang Gengliang <ltnwgl@gmail.com> Closes #20278 from gengliangwang/FixConstraintSimple. (cherry picked from commit 8598a982b4147abe5f1aae005fea0fd5ae395ac4) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 17 January 2018, 16:05:52 UTC |
| cbb6bda | Dongjoon Hyun | 17 January 2018, 13:53:36 UTC | [SPARK-21783][SQL] Turn on ORC filter push-down by default ## What changes were proposed in this pull request? ORC filter push-down is disabled by default from the beginning, [SPARK-2883](https://github.com/apache/spark/commit/aa31e431fc09f0477f1c2351c6275769a31aca90#diff-41ef65b9ef5b518f77e2a03559893f4dR149 ). Now, Apache Spark starts to depend on Apache ORC 1.4.1. For Apache Spark 2.3, this PR turns on ORC filter push-down by default like Parquet ([SPARK-9207](https://issues.apache.org/jira/browse/SPARK-21783)) as a part of [SPARK-20901](https://issues.apache.org/jira/browse/SPARK-20901), "Feature parity for ORC with Parquet". ## How was this patch tested? Pass the existing tests. Author: Dongjoon Hyun <dongjoon@apache.org> Closes #20265 from dongjoon-hyun/SPARK-21783. (cherry picked from commit 0f8a28617a0742d5a99debfbae91222c2e3b5cec) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 17 January 2018, 13:54:19 UTC |
| bfbc2d4 | Henry Robinson | 17 January 2018, 08:01:41 UTC | [SPARK-23062][SQL] Improve EXCEPT documentation ## What changes were proposed in this pull request? Make the default behavior of EXCEPT (i.e. EXCEPT DISTINCT) more explicit in the documentation, and call out the change in behavior from 1.x. Author: Henry Robinson <henry@cloudera.com> Closes #20254 from henryr/spark-23062. (cherry picked from commit 1f3d933e0bd2b1e934a233ed699ad39295376e71) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 17 January 2018, 08:02:04 UTC |
| 8ef323c | Dongjoon Hyun | 17 January 2018, 06:32:18 UTC | [SPARK-23072][SQL][TEST] Add a Unicode schema test for file-based data sources ## What changes were proposed in this pull request? After [SPARK-20682](https://github.com/apache/spark/pull/19651), Apache Spark 2.3 is able to read ORC files with Unicode schema. Previously, it raises `org.apache.spark.sql.catalyst.parser.ParseException`. This PR adds a Unicode schema test for CSV/JSON/ORC/Parquet file-based data sources. Note that TEXT data source only has [a single column with a fixed name 'value'](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/text/TextFileFormat.scala#L71). ## How was this patch tested? Pass the newly added test case. Author: Dongjoon Hyun <dongjoon@apache.org> Closes #20266 from dongjoon-hyun/SPARK-23072. (cherry picked from commit a0aedb0ded4183cc33b27e369df1cbf862779e26) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 17 January 2018, 06:33:28 UTC |
| 00c744e | Jose Torres | 17 January 2018, 06:27:28 UTC | Fix merge between 07ae39d0ec and 1667057851 ## What changes were proposed in this pull request? The first commit added a new test, and the second refactored the class the test was in. The automatic merge put the test in the wrong place. ## How was this patch tested? - Author: Jose Torres <jose@databricks.com> Closes #20289 from jose-torres/fix. (cherry picked from commit a963980a6d2b4bef2c546aa33acf0aa501d2507b) Signed-off-by: Shixiong Zhu <zsxwing@gmail.com> | 17 January 2018, 06:27:35 UTC |
| b9339ee | Sameer Agarwal | 17 January 2018, 06:17:37 UTC | Revert "[SPARK-23020][CORE] Fix races in launcher code, test." This reverts commit 20c69816a63071b82b1035d4b48798c358206421. | 17 January 2018, 06:17:37 UTC |
| 0a441d2 | Jose Torres | 17 January 2018, 02:11:27 UTC | [SPARK-22908][SS] Roll forward continuous processing Kafka support with fix to continuous Kafka data reader ## What changes were proposed in this pull request? The Kafka reader is now interruptible and can close itself. ## How was this patch tested? I locally ran one of the ContinuousKafkaSourceSuite tests in a tight loop. Before the fix, my machine ran out of open file descriptors a few iterations in; now it works fine. Author: Jose Torres <jose@databricks.com> Closes #20253 from jose-torres/fix-data-reader. (cherry picked from commit 16670578519a7b787b0c63888b7d2873af12d5b9) Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com> | 17 January 2018, 02:14:03 UTC |
| 08252bb | Gabor Somogyi | 17 January 2018, 02:03:25 UTC | [SPARK-22361][SQL][TEST] Add unit test for Window Frames ## What changes were proposed in this pull request? There are already quite a few integration tests using window frames, but the unit tests coverage is not ideal. In this PR the already existing tests are reorganized, extended and where gaps found additional cases added. ## How was this patch tested? Automated: Pass the Jenkins. Author: Gabor Somogyi <gabor.g.somogyi@gmail.com> Closes #20019 from gaborgsomogyi/SPARK-22361. (cherry picked from commit a9b845ebb5b51eb619cfa7d73b6153024a6a420d) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 17 January 2018, 02:04:07 UTC |
| 41d1a32 | Dilip Biswal | 17 January 2018, 01:57:30 UTC | [SPARK-23095][SQL] Decorrelation of scalar subquery fails with java.util.NoSuchElementException ## What changes were proposed in this pull request? The following SQL involving scalar correlated query returns a map exception. ``` SQL SELECT t1a FROM t1 WHERE t1a = (SELECT count(*) FROM t2 WHERE t2c = t1c HAVING count(*) >= 1) ``` ``` SQL key not found: ExprId(278,786682bb-41f9-4bd5-a397-928272cc8e4e) java.util.NoSuchElementException: key not found: ExprId(278,786682bb-41f9-4bd5-a397-928272cc8e4e) at scala.collection.MapLike$class.default(MapLike.scala:228) at scala.collection.AbstractMap.default(Map.scala:59) at scala.collection.MapLike$class.apply(MapLike.scala:141) at scala.collection.AbstractMap.apply(Map.scala:59) at org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery$.org$apache$spark$sql$catalyst$optimizer$RewriteCorrelatedScalarSubquery$$evalSubqueryOnZeroTups(subquery.scala:378) at org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery$$anonfun$org$apache$spark$sql$catalyst$optimizer$RewriteCorrelatedScalarSubquery$$constructLeftJoins$1.apply(subquery.scala:430) at org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery$$anonfun$org$apache$spark$sql$catalyst$optimizer$RewriteCorrelatedScalarSubquery$$constructLeftJoins$1.apply(subquery.scala:426) ``` In this case, after evaluating the HAVING clause "count(*) > 1" statically against the binding of aggregtation result on empty input, we determine that this query will not have a the count bug. We should simply return the evalSubqueryOnZeroTups with empty value. (Please fill in changes proposed in this fix) ## How was this patch tested? A new test was added in the Subquery bucket. Author: Dilip Biswal <dbiswal@us.ibm.com> Closes #20283 from dilipbiswal/scalar-count-defect. (cherry picked from commit 0c2ba427bc7323729e6ffb34f1f06a97f0bf0c1d) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 17 January 2018, 01:57:44 UTC |
| 833a584 | Bago Amirbekian | 16 January 2018, 20:56:57 UTC | [SPARK-23045][ML][SPARKR] Update RFormula to use OneHotEncoderEstimator. ## What changes were proposed in this pull request? RFormula should use VectorSizeHint & OneHotEncoderEstimator in its pipeline to avoid using the deprecated OneHotEncoder & to ensure the model produced can be used in streaming. ## How was this patch tested? Unit tests. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Bago Amirbekian <bago@databricks.com> Closes #20229 from MrBago/rFormula. (cherry picked from commit 4371466b3f06ca171b10568e776c9446f7bae6dd) Signed-off-by: Joseph K. Bradley <joseph@databricks.com> | 16 January 2018, 20:57:07 UTC |
| 863ffdc | Wenchen Fan | 16 January 2018, 14:41:30 UTC | [SPARK-22392][SQL] data source v2 columnar batch reader ## What changes were proposed in this pull request? a new Data Source V2 interface to allow the data source to return `ColumnarBatch` during the scan. ## How was this patch tested? new tests Author: Wenchen Fan <wenchen@databricks.com> Closes #20153 from cloud-fan/columnar-reader. (cherry picked from commit 75db14864d2bd9b8e13154226e94d466e3a7e0a0) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 16 January 2018, 14:42:33 UTC |
| 5c06ee2 | gatorsmile | 16 January 2018, 11:20:33 UTC | [SPARK-22978][PYSPARK] Register Vectorized UDFs for SQL Statement ## What changes were proposed in this pull request? Register Vectorized UDFs for SQL Statement. For example, ```Python >>> from pyspark.sql.functions import pandas_udf, PandasUDFType >>> pandas_udf("integer", PandasUDFType.SCALAR) ... def add_one(x): ... return x + 1 ... >>> _ = spark.udf.register("add_one", add_one) >>> spark.sql("SELECT add_one(id) FROM range(3)").collect() [Row(add_one(id)=1), Row(add_one(id)=2), Row(add_one(id)=3)] ``` ## How was this patch tested? Added test cases Author: gatorsmile <gatorsmile@gmail.com> Closes #20171 from gatorsmile/supportVectorizedUDF. (cherry picked from commit b85eb946ac298e711dad25db0d04eee41d7fd236) Signed-off-by: hyukjinkwon <gurwls223@gmail.com> | 16 January 2018, 11:21:36 UTC |
| 20c6981 | Marcelo Vanzin | 16 January 2018, 06:40:44 UTC | [SPARK-23020][CORE] Fix races in launcher code, test. The race in the code is because the handle might update its state to the wrong state if the connection handling thread is still processing incoming data; so the handle needs to wait for the connection to finish up before checking the final state. The race in the test is because when waiting for a handle to reach a final state, the waitFor() method needs to wait until all handle state is updated (which also includes waiting for the connection thread above to finish). Otherwise, waitFor() may return too early, which would cause a bunch of different races (like the listener not being yet notified of the state change, or being in the middle of being notified, or the handle not being properly disposed and causing postChecks() to assert). On top of that I found, by code inspection, a couple of potential races that could make a handle end up in the wrong state when being killed. Tested by running the existing unit tests a lot (and not seeing the errors I was seeing before). Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20223 from vanzin/SPARK-23020. (cherry picked from commit 66217dac4f8952a9923625908ad3dcb030763c81) Signed-off-by: Sameer Agarwal <sameerag@apache.org> | 16 January 2018, 06:41:26 UTC |
| e58c4a9 | Yuanjian Li | 16 January 2018, 06:01:14 UTC | [SPARK-22956][SS] Bug fix for 2 streams union failover scenario ## What changes were proposed in this pull request? This problem reported by yanlin-Lynn ivoson and LiangchangZ. Thanks! When we union 2 streams from kafka or other sources, while one of them have no continues data coming and in the same time task restart, this will cause an `IllegalStateException`. This mainly cause because the code in [MicroBatchExecution](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala#L190) , while one stream has no continues data, its comittedOffset same with availableOffset during `populateStartOffsets`, and `currentPartitionOffsets` not properly handled in KafkaSource. Also, maybe we should also consider this scenario in other Source. ## How was this patch tested? Add a UT in KafkaSourceSuite.scala Author: Yuanjian Li <xyliyuanjian@gmail.com> Closes #20150 from xuanyuanking/SPARK-22956. (cherry picked from commit 07ae39d0ec1f03b1c73259373a8bb599694c7860) Signed-off-by: Shixiong Zhu <zsxwing@gmail.com> | 16 January 2018, 06:01:23 UTC |
| e2ffb97 | Sameer Agarwal | 16 January 2018, 03:20:18 UTC | [SPARK-23000] Use fully qualified table names in HiveMetastoreCatalogSuite ## What changes were proposed in this pull request? In another attempt to fix DataSourceWithHiveMetastoreCatalogSuite, this patch uses qualified table names (`default.t`) in the individual tests. ## How was this patch tested? N/A (Test Only Change) Author: Sameer Agarwal <sameerag@apache.org> Closes #20273 from sameeragarwal/flaky-test. (cherry picked from commit c7572b79da0a29e502890d7618eaf805a1c9f474) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 16 January 2018, 03:20:35 UTC |
| bb8e5ad | Marco Gaido | 16 January 2018, 02:47:42 UTC | [SPARK-23080][SQL] Improve error message for built-in functions ## What changes were proposed in this pull request? When a user puts the wrong number of parameters in a function, an AnalysisException is thrown. If the function is a UDF, he user is told how many parameters the function expected and how many he/she put. If the function, instead, is a built-in one, no information about the number of parameters expected and the actual one is provided. This can help in some cases, to debug the errors (eg. bad quotes escaping may lead to a different number of parameters than expected, etc. etc.) The PR adds the information about the number of parameters passed and the expected one, analogously to what happens for UDF. ## How was this patch tested? modified existing UT + manual test Author: Marco Gaido <marcogaido91@gmail.com> Closes #20271 from mgaido91/SPARK-23080. (cherry picked from commit 8ab2d7ea99b2cff8b54b2cb3a1dbf7580845986a) Signed-off-by: hyukjinkwon <gurwls223@gmail.com> | 16 January 2018, 02:47:58 UTC |
| 706a308 | xubo245 | 15 January 2018, 15:13:15 UTC | [SPARK-23035][SQL] Fix improper information of TempTableAlreadyExistsException ## What changes were proposed in this pull request? Problem: it throw TempTableAlreadyExistsException and output "Temporary table '$table' already exists" when we create temp view by using org.apache.spark.sql.catalyst.catalog.GlobalTempViewManager#create, it's improper. So fix improper information about TempTableAlreadyExistsException when create temp view: change "Temporary table" to "Temporary view" ## How was this patch tested? test("rename temporary view - destination table already exists, with: CREATE TEMPORARY view") test("rename temporary view - destination table with database name,with:CREATE TEMPORARY view") Author: xubo245 <601450868@qq.com> Closes #20227 from xubo245/fixDeprecated. (cherry picked from commit 6c81fe227a6233f5d9665d2efadf8a1cf09f700d) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 15 January 2018, 15:13:38 UTC |
| c6a3b92 | gatorsmile | 15 January 2018, 14:32:38 UTC | [SPARK-23070] Bump previousSparkVersion in MimaBuild.scala to be 2.2.0 ## What changes were proposed in this pull request? Bump previousSparkVersion in MimaBuild.scala to be 2.2.0 and add the missing exclusions to `v23excludes` in `MimaExcludes`. No item can be un-excluded in `v23excludes`. ## How was this patch tested? The existing tests. Author: gatorsmile <gatorsmile@gmail.com> Closes #20264 from gatorsmile/bump22. (cherry picked from commit bd08a9e7af4137bddca638e627ad2ae531bce20f) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 15 January 2018, 14:33:01 UTC |
| 3491ca4 | Yuming Wang | 15 January 2018, 13:49:34 UTC | [SPARK-19550][BUILD][FOLLOW-UP] Remove MaxPermSize for sql module ## What changes were proposed in this pull request? Remove `MaxPermSize` for `sql` module ## How was this patch tested? Manually tested. Author: Yuming Wang <yumwang@ebay.com> Closes #20268 from wangyum/SPARK-19550-MaxPermSize. (cherry picked from commit a38c887ac093d7cf343d807515147d87ca931ce7) Signed-off-by: Sean Owen <sowen@cloudera.com> | 15 January 2018, 13:49:43 UTC |
| 188999a | Takeshi Yamamuro | 15 January 2018, 08:26:52 UTC | [SPARK-23023][SQL] Cast field data to strings in showString ## What changes were proposed in this pull request? The current `Datset.showString` prints rows thru `RowEncoder` deserializers like; ``` scala> Seq(Seq(Seq(1, 2), Seq(3), Seq(4, 5, 6))).toDF("a").show(false) +------------------------------------------------------------+ |a | +------------------------------------------------------------+ |[WrappedArray(1, 2), WrappedArray(3), WrappedArray(4, 5, 6)]| +------------------------------------------------------------+ ``` This result is incorrect because the correct one is; ``` scala> Seq(Seq(Seq(1, 2), Seq(3), Seq(4, 5, 6))).toDF("a").show(false) +------------------------+ |a | +------------------------+ |[[1, 2], [3], [4, 5, 6]]| +------------------------+ ``` So, this pr fixed code in `showString` to cast field data to strings before printing. ## How was this patch tested? Added tests in `DataFrameSuite`. Author: Takeshi Yamamuro <yamamuro@apache.org> Closes #20214 from maropu/SPARK-23023. (cherry picked from commit b59808385cfe24ce768e5b3098b9034e64b99a5a) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 15 January 2018, 08:28:20 UTC |
| 81b9899 | Dongjoon Hyun | 15 January 2018, 04:06:56 UTC | [SPARK-23049][SQL] `spark.sql.files.ignoreCorruptFiles` should work for ORC files ## What changes were proposed in this pull request? When `spark.sql.files.ignoreCorruptFiles=true`, we should ignore corrupted ORC files. ## How was this patch tested? Pass the Jenkins with a newly added test case. Author: Dongjoon Hyun <dongjoon@apache.org> Closes #20240 from dongjoon-hyun/SPARK-23049. (cherry picked from commit 9a96bfc8bf021cb4b6c62fac6ce1bcf87affcd43) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 15 January 2018, 04:08:15 UTC |
| 30574fd | Takeshi Yamamuro | 15 January 2018, 02:55:21 UTC | [SPARK-23054][SQL] Fix incorrect results of casting UserDefinedType to String ## What changes were proposed in this pull request? This pr fixed the issue when casting `UserDefinedType`s into strings; ``` >>> from pyspark.ml.classification import MultilayerPerceptronClassifier >>> from pyspark.ml.linalg import Vectors >>> df = spark.createDataFrame([(0.0, Vectors.dense([0.0, 0.0])), (1.0, Vectors.dense([0.0, 1.0]))], ["label", "features"]) >>> df.selectExpr("CAST(features AS STRING)").show(truncate = False) +-------------------------------------------+ |features | +-------------------------------------------+ |[6,1,0,0,2800000020,2,0,0,0] | |[6,1,0,0,2800000020,2,0,0,3ff0000000000000]| +-------------------------------------------+ ``` The root cause is that `Cast` handles input data as `UserDefinedType.sqlType`(this is underlying storage type), so we should pass data into `UserDefinedType.deserialize` then `toString`. This pr modified the result into; ``` +---------+ |features | +---------+ |[0.0,0.0]| |[0.0,1.0]| +---------+ ``` ## How was this patch tested? Added tests in `UserDefinedTypeSuite `. Author: Takeshi Yamamuro <yamamuro@apache.org> Closes #20246 from maropu/SPARK-23054. (cherry picked from commit b98ffa4d6dabaf787177d3f14b200fc4b118c7ce) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 15 January 2018, 02:55:50 UTC |
| 2879236 | guoxiaolong | 14 January 2018, 18:02:49 UTC | [SPARK-22999][SQL] show databases like command' can remove the like keyword ## What changes were proposed in this pull request? SHOW DATABASES (LIKE pattern = STRING)? Can be like the back increase? When using this command, LIKE keyword can be removed. You can refer to the SHOW TABLES command, SHOW TABLES 'test *' and SHOW TABELS like 'test *' can be used. Similarly SHOW DATABASES 'test *' and SHOW DATABASES like 'test *' can be used. ## How was this patch tested? unit tests manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. Author: guoxiaolong <guo.xiaolong1@zte.com.cn> Closes #20194 from guoxiaolongzte/SPARK-22999. (cherry picked from commit 42a1a15d739890bdfbb367ef94198b19e98ffcb7) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 14 January 2018, 18:03:16 UTC |
| 9051e1a | Sandor Murakozi | 14 January 2018, 14:32:35 UTC | [SPARK-23051][CORE] Fix for broken job description in Spark UI ## What changes were proposed in this pull request? In 2.2, Spark UI displayed the stage description if the job description was not set. This functionality was broken, the GUI has shown no description in this case. In addition, the code uses jobName and jobDescription instead of stageName and stageDescription when JobTableRowData is created. In this PR the logic producing values for the job rows was modified to find the latest stage attempt for the job and use that as a fallback if job description was missing. StageName and stageDescription are also set using values from stage and jobName/description is used only as a fallback. ## How was this patch tested? Manual testing of the UI, using the code in the bug report. Author: Sandor Murakozi <smurakozi@gmail.com> Closes #20251 from smurakozi/SPARK-23051. (cherry picked from commit 60eeecd7760aee6ce2fd207c83ae40054eadaf83) Signed-off-by: Sean Owen <sowen@cloudera.com> | 14 January 2018, 14:32:43 UTC |
| 5fbbd94 | Takeshi Yamamuro | 14 January 2018, 14:26:21 UTC | [SPARK-23021][SQL] AnalysisBarrier should override innerChildren to print correct explain output ## What changes were proposed in this pull request? `AnalysisBarrier` in the current master cuts off explain results for parsed logical plans; ``` scala> Seq((1, 1)).toDF("a", "b").groupBy("a").count().sample(0.1).explain(true) == Parsed Logical Plan == Sample 0.0, 0.1, false, -7661439431999668039 +- AnalysisBarrier Aggregate [a#5], [a#5, count(1) AS count#14L] ``` To fix this, `AnalysisBarrier` needs to override `innerChildren` and this pr changed the output to; ``` == Parsed Logical Plan == Sample 0.0, 0.1, false, -5086223488015741426 +- AnalysisBarrier +- Aggregate [a#5], [a#5, count(1) AS count#14L] +- Project [_1#2 AS a#5, _2#3 AS b#6] +- LocalRelation [_1#2, _2#3] ``` ## How was this patch tested? Added tests in `DataFrameSuite`. Author: Takeshi Yamamuro <yamamuro@apache.org> Closes #20247 from maropu/SPARK-23021-2. (cherry picked from commit 990f05c80347c6eec2ee06823cff587c9ea90b49) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 14 January 2018, 14:27:26 UTC |
| 0d425c3 | Felix Cheung | 14 January 2018, 10:43:10 UTC | [SPARK-23069][DOCS][SPARKR] fix R doc for describe missing text ## What changes were proposed in this pull request? fix doc truncated ## How was this patch tested? manually Author: Felix Cheung <felixcheung_m@hotmail.com> Closes #20263 from felixcheung/r23docfix. (cherry picked from commit 66738d29c59871b29d26fc3756772b95ef536248) Signed-off-by: hyukjinkwon <gurwls223@gmail.com> | 14 January 2018, 10:43:23 UTC |
| a335a49 | Dongjoon Hyun | 14 January 2018, 07:26:12 UTC | [SPARK-23038][TEST] Update docker/spark-test (JDK/OS) ## What changes were proposed in this pull request? This PR aims to update the followings in `docker/spark-test`. - JDK7 -> JDK8 Spark 2.2+ supports JDK8 only. - Ubuntu 12.04.5 LTS(precise) -> Ubuntu 16.04.3 LTS(xeniel) The end of life of `precise` was April 28, 2017. ## How was this patch tested? Manual. * Master ``` $ cd external/docker $ ./build $ export SPARK_HOME=... $ docker run -v $SPARK_HOME:/opt/spark spark-test-master CONTAINER_IP=172.17.0.3 ... 18/01/11 06:50:25 INFO MasterWebUI: Bound MasterWebUI to 172.17.0.3, and started at http://172.17.0.3:8080 18/01/11 06:50:25 INFO Utils: Successfully started service on port 6066. 18/01/11 06:50:25 INFO StandaloneRestServer: Started REST server for submitting applications on port 6066 18/01/11 06:50:25 INFO Master: I have been elected leader! New state: ALIVE ``` * Slave ``` $ docker run -v $SPARK_HOME:/opt/spark spark-test-worker spark://172.17.0.3:7077 CONTAINER_IP=172.17.0.4 ... 18/01/11 06:51:54 INFO Worker: Successfully registered with master spark://172.17.0.3:7077 ``` After slave starts, master will show ``` 18/01/11 06:51:54 INFO Master: Registering worker 172.17.0.4:8888 with 4 cores, 1024.0 MB RAM ``` Author: Dongjoon Hyun <dongjoon@apache.org> Closes #20230 from dongjoon-hyun/SPARK-23038. (cherry picked from commit 7a3d0aad2b89aef54f7dd580397302e9ff984d9d) Signed-off-by: Felix Cheung <felixcheung@apache.org> | 14 January 2018, 07:30:04 UTC |
| 1f4a08b | foxish | 14 January 2018, 05:34:28 UTC | [SPARK-23063][K8S] K8s changes for publishing scripts (and a couple of other misses) ## What changes were proposed in this pull request? Including the `-Pkubernetes` flag in a few places it was missed. ## How was this patch tested? checkstyle, mima through manual tests. Author: foxish <ramanathana@google.com> Closes #20256 from foxish/SPARK-23063. (cherry picked from commit c3548d11c3c57e8f2c6ebd9d2d6a3924ddcd3cba) Signed-off-by: Felix Cheung <felixcheung@apache.org> | 14 January 2018, 05:34:43 UTC |
| bcd87ae | Takeshi Yamamuro | 13 January 2018, 21:39:38 UTC | [SPARK-21213][SQL][FOLLOWUP] Use compatible types for comparisons in compareAndGetNewStats ## What changes were proposed in this pull request? This pr fixed code to compare values in `compareAndGetNewStats`. The test below fails in the current master; ``` val oldStats2 = CatalogStatistics(sizeInBytes = BigInt(Long.MaxValue) * 2) val newStats5 = CommandUtils.compareAndGetNewStats( Some(oldStats2), newTotalSize = BigInt(Long.MaxValue) * 2, None) assert(newStats5.isEmpty) ``` ## How was this patch tested? Added some tests in `CommandUtilsSuite`. Author: Takeshi Yamamuro <yamamuro@apache.org> Closes #20245 from maropu/SPARK-21213-FOLLOWUP. (cherry picked from commit 0066d6f6fa604817468471832968d4339f71c5cb) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 13 January 2018, 21:40:30 UTC |
| 0fc5533 | CodingCat | 13 January 2018, 18:36:32 UTC | [SPARK-22790][SQL] add a configurable factor to describe HadoopFsRelation's size ## What changes were proposed in this pull request? as per discussion in https://github.com/apache/spark/pull/19864#discussion_r156847927 the current HadoopFsRelation is purely based on the underlying file size which is not accurate and makes the execution vulnerable to errors like OOM Users can enable CBO with the functionalities in https://github.com/apache/spark/pull/19864 to avoid this issue This JIRA proposes to add a configurable factor to sizeInBytes method in HadoopFsRelation class so that users can mitigate this problem without CBO ## How was this patch tested? Existing tests Author: CodingCat <zhunansjtu@gmail.com> Author: Nan Zhu <nanzhu@uber.com> Closes #20072 from CodingCat/SPARK-22790. (cherry picked from commit ba891ec993c616dc4249fc786c56ea82ed04a827) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 13 January 2018, 18:36:52 UTC |
| 8d32ed5 | xubo245 | 13 January 2018, 18:28:57 UTC | [SPARK-23036][SQL][TEST] Add withGlobalTempView for testing ## What changes were proposed in this pull request? Add withGlobalTempView when create global temp view, like withTempView and withView. And correct some improper usage. Please see jira. There are other similar place like that. I will fix it if community need. Please confirm it. ## How was this patch tested? no new test. Author: xubo245 <601450868@qq.com> Closes #20228 from xubo245/DropTempView. (cherry picked from commit bd4a21b4820c4ebaf750131574a6b2eeea36907e) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 13 January 2018, 18:29:36 UTC |
| 801ffd7 | Yuming Wang | 13 January 2018, 16:01:44 UTC | [SPARK-22870][CORE] Dynamic allocation should allow 0 idle time ## What changes were proposed in this pull request? This pr to make `0` as a valid value for `spark.dynamicAllocation.executorIdleTimeout`. For details, see the jira description: https://issues.apache.org/jira/browse/SPARK-22870. ## How was this patch tested? N/A Author: Yuming Wang <yumwang@ebay.com> Author: Yuming Wang <wgyumg@gmail.com> Closes #20080 from wangyum/SPARK-22870. (cherry picked from commit fc6fe8a1d0f161c4788f3db94de49a8669ba3bcc) Signed-off-by: Sean Owen <sowen@cloudera.com> | 13 January 2018, 16:01:53 UTC |
| ca27d9c | hyukjinkwon | 13 January 2018, 07:13:44 UTC | [SPARK-22980][PYTHON][SQL] Clarify the length of each series is of each batch within scalar Pandas UDF ## What changes were proposed in this pull request? This PR proposes to add a note that saying the length of a scalar Pandas UDF's `Series` is not of the whole input column but of the batch. We are fine for a group map UDF because the usage is different from our typical UDF but scalar UDFs might cause confusion with the normal UDF. For example, please consider this example: ```python from pyspark.sql.functions import pandas_udf, col, lit df = spark.range(1) f = pandas_udf(lambda x, y: len(x) + y, LongType()) df.select(f(lit('text'), col('id'))).show() ``` ``` +------------------+ |<lambda>(text, id)| +------------------+ | 1| +------------------+ ``` ```python from pyspark.sql.functions import udf, col, lit df = spark.range(1) f = udf(lambda x, y: len(x) + y, "long") df.select(f(lit('text'), col('id'))).show() ``` ``` +------------------+ |<lambda>(text, id)| +------------------+ | 4| +------------------+ ``` ## How was this patch tested? Manually built the doc and checked the output. Author: hyukjinkwon <gurwls223@gmail.com> Closes #20237 from HyukjinKwon/SPARK-22980. (cherry picked from commit cd9f49a2aed3799964976ead06080a0f7044a0c3) Signed-off-by: hyukjinkwon <gurwls223@gmail.com> | 13 January 2018, 07:13:57 UTC |
| 60bcb46 | Sameer Agarwal | 12 January 2018, 23:07:14 UTC | Revert "[SPARK-22908] Add kafka source and sink for continuous processing." This reverts commit f891ee3249e04576dd579cbab6f8f1632550e6bd. | 12 January 2018, 23:07:14 UTC |
| 02176f4 | Marco Gaido | 12 January 2018, 19:25:37 UTC | [SPARK-22975][SS] MetricsReporter should not throw exception when there was no progress reported ## What changes were proposed in this pull request? `MetricsReporter ` assumes that there has been some progress for the query, ie. `lastProgress` is not null. If this is not true, as it might happen in particular conditions, a `NullPointerException` can be thrown. The PR checks whether there is a `lastProgress` and if this is not true, it returns a default value for the metrics. ## How was this patch tested? added UT Author: Marco Gaido <marcogaido91@gmail.com> Closes #20189 from mgaido91/SPARK-22975. (cherry picked from commit 54277398afbde92a38ba2802f4a7a3e5910533de) Signed-off-by: Shixiong Zhu <zsxwing@gmail.com> | 12 January 2018, 19:25:45 UTC |
| db27a93 | Dongjoon Hyun | 12 January 2018, 18:18:42 UTC | [MINOR][BUILD] Fix Java linter errors ## What changes were proposed in this pull request? This PR cleans up the java-lint errors (for v2.3.0-rc1 tag). Hopefully, this will be the final one. ``` $ dev/lint-java Using `mvn` from path: /usr/local/bin/mvn Checkstyle checks failed at following occurrences: [ERROR] src/main/java/org/apache/spark/unsafe/memory/HeapMemoryAllocator.java:[85] (sizes) LineLength: Line is longer than 100 characters (found 101). [ERROR] src/main/java/org/apache/spark/launcher/InProcessAppHandle.java:[20,8] (imports) UnusedImports: Unused import - java.io.IOException. [ERROR] src/main/java/org/apache/spark/sql/execution/datasources/orc/OrcColumnVector.java:[41,9] (modifier) ModifierOrder: 'private' modifier out of order with the JLS suggestions. [ERROR] src/test/java/test/org/apache/spark/sql/JavaDataFrameSuite.java:[464] (sizes) LineLength: Line is longer than 100 characters (found 102). ``` ## How was this patch tested? Manual. ``` $ dev/lint-java Using `mvn` from path: /usr/local/bin/mvn Checkstyle checks passed. ``` Author: Dongjoon Hyun <dongjoon@apache.org> Closes #20242 from dongjoon-hyun/fix_lint_java_2.3_rc1. (cherry picked from commit 7bd14cfd40500a0b6462cda647bdbb686a430328) Signed-off-by: Sameer Agarwal <sameerag@apache.org> | 12 January 2018, 18:18:59 UTC |
| 6152da3 | Marco Gaido | 12 January 2018, 10:04:44 UTC | [SPARK-23025][SQL] Support Null type in scala reflection ## What changes were proposed in this pull request? Add support for `Null` type in the `schemaFor` method for Scala reflection. ## How was this patch tested? Added UT Author: Marco Gaido <marcogaido91@gmail.com> Closes #20219 from mgaido91/SPARK-23025. (cherry picked from commit 505086806997b4331d4a8c2fc5e08345d869a23c) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 12 January 2018, 10:05:12 UTC |
| d512d87 | WeichenXu | 12 January 2018, 09:27:02 UTC | [SPARK-23008][ML][FOLLOW-UP] mark OneHotEncoder python API deprecated ## What changes were proposed in this pull request? mark OneHotEncoder python API deprecated ## How was this patch tested? N/A Author: WeichenXu <weichen.xu@databricks.com> Closes #20241 from WeichenXu123/mark_ohe_deprecated. (cherry picked from commit a7d98d53ceaf69cabaecc6c9113f17438c4e61f6) Signed-off-by: Nick Pentreath <nickp@za.ibm.com> | 12 January 2018, 09:27:59 UTC |
| 3ae3e1b | ho3rexqj | 12 January 2018, 07:27:00 UTC | [SPARK-22986][CORE] Use a cache to avoid instantiating multiple instances of broadcast variable values When resources happen to be constrained on an executor the first time a broadcast variable is instantiated it is persisted to disk by the BlockManager. Consequently, every subsequent call to TorrentBroadcast::readBroadcastBlock from other instances of that broadcast variable spawns another instance of the underlying value. That is, broadcast variables are spawned once per executor **unless** memory is constrained, in which case every instance of a broadcast variable is provided with a unique copy of the underlying value. This patch fixes the above by explicitly caching the underlying values using weak references in a ReferenceMap. Author: ho3rexqj <ho3rexqj@gmail.com> Closes #20183 from ho3rexqj/fix/cache-broadcast-values. (cherry picked from commit cbe7c6fbf9dc2fc422b93b3644c40d449a869eea) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 12 January 2018, 07:27:31 UTC |
| 55695c7 | WeichenXu | 12 January 2018, 00:20:30 UTC | [SPARK-23008][ML] OnehotEncoderEstimator python API ## What changes were proposed in this pull request? OnehotEncoderEstimator python API. ## How was this patch tested? doctest Author: WeichenXu <weichen.xu@databricks.com> Closes #20209 from WeichenXu123/ohe_py. (cherry picked from commit b5042d75c2faa5f15bc1e160d75f06dfdd6eea37) Signed-off-by: Joseph K. Bradley <joseph@databricks.com> | 12 January 2018, 00:20:41 UTC |
| 6bb2296 | Sameer Agarwal | 11 January 2018, 23:23:17 UTC | Preparing development version 2.3.1-SNAPSHOT | 11 January 2018, 23:23:17 UTC |
| 964cc2e | Sameer Agarwal | 11 January 2018, 23:23:10 UTC | Preparing Spark release v2.3.0-rc1 | 11 January 2018, 23:23:10 UTC |
| 2ec3026 | Bago Amirbekian | 11 January 2018, 21:57:15 UTC | [SPARK-23046][ML][SPARKR] Have RFormula include VectorSizeHint in pipeline ## What changes were proposed in this pull request? Including VectorSizeHint in RFormula piplelines will allow them to be applied to streaming dataframes. ## How was this patch tested? Unit tests. Author: Bago Amirbekian <bago@databricks.com> Closes #20238 from MrBago/rFormulaVectorSize. (cherry picked from commit 186bf8fb2e9ff8a80f3f6bcb5f2a0327fa79a1c9) Signed-off-by: Joseph K. Bradley <joseph@databricks.com> | 11 January 2018, 21:57:27 UTC |
| f891ee3 | Jose Torres | 11 January 2018, 18:52:12 UTC | [SPARK-22908] Add kafka source and sink for continuous processing. ## What changes were proposed in this pull request? Add kafka source and sink for continuous processing. This involves two small changes to the execution engine: * Bring data reader close() into the normal data reader thread to avoid thread safety issues. * Fix up the semantics of the RECONFIGURING StreamExecution state. State updates are now atomic, and we don't have to deal with swallowing an exception. ## How was this patch tested? new unit tests Author: Jose Torres <jose@databricks.com> Closes #20096 from jose-torres/continuous-kafka. (cherry picked from commit 6f7aaed805070d29dcba32e04ca7a1f581fa54b9) Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com> | 11 January 2018, 18:52:26 UTC |
| b94debd | Marcelo Vanzin | 11 January 2018, 18:37:35 UTC | [SPARK-22994][K8S] Use a single image for all Spark containers. This change allows a user to submit a Spark application on kubernetes having to provide a single image, instead of one image for each type of container. The image's entry point now takes an extra argument that identifies the process that is being started. The configuration still allows the user to provide different images for each container type if they so desire. On top of that, the entry point was simplified a bit to share more code; mainly, the same env variable is used to propagate the user-defined classpath to the different containers. Aside from being modified to match the new behavior, the 'build-push-docker-images.sh' script was renamed to 'docker-image-tool.sh' to more closely match its purpose; the old name was a little awkward and now also not entirely correct, since there is a single image. It was also moved to 'bin' since it's not necessarily an admin tool. Docs have been updated to match the new behavior. Tested locally with minikube. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20192 from vanzin/SPARK-22994. (cherry picked from commit 0b2eefb674151a0af64806728b38d9410da552ec) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> | 11 January 2018, 18:37:55 UTC |
| f624850 | gatorsmile | 11 January 2018, 13:33:42 UTC | [SPARK-19732][FOLLOW-UP] Document behavior changes made in na.fill and fillna ## What changes were proposed in this pull request? https://github.com/apache/spark/pull/18164 introduces the behavior changes. We need to document it. ## How was this patch tested? N/A Author: gatorsmile <gatorsmile@gmail.com> Closes #20234 from gatorsmile/docBehaviorChange. (cherry picked from commit b46e58b74c82dac37b7b92284ea3714919c5a886) Signed-off-by: hyukjinkwon <gurwls223@gmail.com> | 11 January 2018, 13:33:57 UTC |
| 9ca0f6e | gatorsmile | 11 January 2018, 13:32:36 UTC | [SPARK-23000][TEST-HADOOP2.6] Fix Flaky test suite DataSourceWithHiveMetastoreCatalogSuite ## What changes were proposed in this pull request? The Spark 2.3 branch still failed due to the flaky test suite `DataSourceWithHiveMetastoreCatalogSuite `. https://amplab.cs.berkeley.edu/jenkins/job/spark-branch-2.3-test-sbt-hadoop-2.6/ Although https://github.com/apache/spark/pull/20207 is unable to reproduce it in Spark 2.3, it sounds like the current DB of Spark's Catalog is changed based on the following stacktrace. Thus, we just need to reset it. ``` [info] DataSourceWithHiveMetastoreCatalogSuite: 02:40:39.486 ERROR org.apache.hadoop.hive.ql.parse.CalcitePlanner: org.apache.hadoop.hive.ql.parse.SemanticException: Line 1:14 Table not found 't' at org.apache.hadoop.hive.ql.parse.SemanticAnalyzer.getMetaData(SemanticAnalyzer.java:1594) at org.apache.hadoop.hive.ql.parse.SemanticAnalyzer.getMetaData(SemanticAnalyzer.java:1545) at org.apache.hadoop.hive.ql.parse.SemanticAnalyzer.genResolvedParseTree(SemanticAnalyzer.java:10077) at org.apache.hadoop.hive.ql.parse.SemanticAnalyzer.analyzeInternal(SemanticAnalyzer.java:10128) at org.apache.hadoop.hive.ql.parse.CalcitePlanner.analyzeInternal(CalcitePlanner.java:209) at org.apache.hadoop.hive.ql.parse.BaseSemanticAnalyzer.analyze(BaseSemanticAnalyzer.java:227) at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:424) at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:308) at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:1122) at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1170) at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1059) at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1049) at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$runHive$1.apply(HiveClientImpl.scala:694) at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$runHive$1.apply(HiveClientImpl.scala:683) at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$withHiveState$1.apply(HiveClientImpl.scala:272) at org.apache.spark.sql.hive.client.HiveClientImpl.liftedTree1$1(HiveClientImpl.scala:210) at org.apache.spark.sql.hive.client.HiveClientImpl.retryLocked(HiveClientImpl.scala:209) at org.apache.spark.sql.hive.client.HiveClientImpl.withHiveState(HiveClientImpl.scala:255) at org.apache.spark.sql.hive.client.HiveClientImpl.runHive(HiveClientImpl.scala:683) at org.apache.spark.sql.hive.client.HiveClientImpl.runSqlHive(HiveClientImpl.scala:673) at org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite$$anonfun$9$$anonfun$apply$1$$anonfun$apply$mcV$sp$3.apply$mcV$sp(HiveMetastoreCatalogSuite.scala:185) at org.apache.spark.sql.test.SQLTestUtilsBase$class.withTable(SQLTestUtils.scala:273) at org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite.withTable(HiveMetastoreCatalogSuite.scala:139) at org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite$$anonfun$9$$anonfun$apply$1.apply$mcV$sp(HiveMetastoreCatalogSuite.scala:163) at org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite$$anonfun$9$$anonfun$apply$1.apply(HiveMetastoreCatalogSuite.scala:163) at org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite$$anonfun$9$$anonfun$apply$1.apply(HiveMetastoreCatalogSuite.scala:163) at org.scalatest.OutcomeOf$class.outcomeOf(OutcomeOf.scala:85) at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104) at org.scalatest.Transformer.apply(Transformer.scala:22) at org.scalatest.Transformer.apply(Transformer.scala:20) at org.scalatest.FunSuiteLike$$anon$1.apply(FunSuiteLike.scala:186) at org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:68) at org.scalatest.FunSuiteLike$class.invokeWithFixture$1(FunSuiteLike.scala:183) at org.scalatest.FunSuiteLike$$anonfun$runTest$1.apply(FunSuiteLike.scala:196) at org.scalatest.FunSuiteLike$$anonfun$runTest$1.apply(FunSuiteLike.scala:196) at org.scalatest.SuperEngine.runTestImpl(Engine.scala:289) at org.scalatest.FunSuiteLike$class.runTest(FunSuiteLike.scala:196) at org.scalatest.FunSuite.runTest(FunSuite.scala:1560) at org.scalatest.FunSuiteLike$$anonfun$runTests$1.apply(FunSuiteLike.scala:229) at org.scalatest.FunSuiteLike$$anonfun$runTests$1.apply(FunSuiteLike.scala:229) at org.scalatest.SuperEngine$$anonfun$traverseSubNodes$1$1.apply(Engine.scala:396) at org.scalatest.SuperEngine$$anonfun$traverseSubNodes$1$1.apply(Engine.scala:384) at scala.collection.immutable.List.foreach(List.scala:381) at org.scalatest.SuperEngine.traverseSubNodes$1(Engine.scala:384) at org.scalatest.SuperEngine.org$scalatest$SuperEngine$$runTestsInBranch(Engine.scala:379) at org.scalatest.SuperEngine.runTestsImpl(Engine.scala:461) at org.scalatest.FunSuiteLike$class.runTests(FunSuiteLike.scala:229) at org.scalatest.FunSuite.runTests(FunSuite.scala:1560) at org.scalatest.Suite$class.run(Suite.scala:1147) at org.scalatest.FunSuite.org$scalatest$FunSuiteLike$$super$run(FunSuite.scala:1560) at org.scalatest.FunSuiteLike$$anonfun$run$1.apply(FunSuiteLike.scala:233) at org.scalatest.FunSuiteLike$$anonfun$run$1.apply(FunSuiteLike.scala:233) at org.scalatest.SuperEngine.runImpl(Engine.scala:521) at org.scalatest.FunSuiteLike$class.run(FunSuiteLike.scala:233) at org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterAll$$super$run(SparkFunSuite.scala:31) at org.scalatest.BeforeAndAfterAll$class.liftedTree1$1(BeforeAndAfterAll.scala:213) at org.scalatest.BeforeAndAfterAll$class.run(BeforeAndAfterAll.scala:210) at org.apache.spark.SparkFunSuite.run(SparkFunSuite.scala:31) at org.scalatest.tools.Framework.org$scalatest$tools$Framework$$runSuite(Framework.scala:314) at org.scalatest.tools.Framework$ScalaTestTask.execute(Framework.scala:480) at sbt.ForkMain$Run$2.call(ForkMain.java:296) at sbt.ForkMain$Run$2.call(ForkMain.java:286) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) ``` ## How was this patch tested? N/A Author: gatorsmile <gatorsmile@gmail.com> Closes #20218 from gatorsmile/testFixAgain. (cherry picked from commit 76892bcf2c08efd7e9c5b16d377e623d82fe695e) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 11 January 2018, 13:33:09 UTC |
| 7995989 | wuyi5 | 11 January 2018, 13:17:15 UTC | [SPARK-22967][TESTS] Fix VersionSuite's unit tests by change Windows path into URI path ## What changes were proposed in this pull request? Two unit test will fail due to Windows format path: 1.test(s"$version: read avro file containing decimal") ``` org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:java.lang.IllegalArgumentException: Can not create a Path from an empty string); ``` 2.test(s"$version: SPARK-17920: Insert into/overwrite avro table") ``` Unable to infer the schema. The schema specification is required to create the table `default`.`tab2`.; org.apache.spark.sql.AnalysisException: Unable to infer the schema. The schema specification is required to create the table `default`.`tab2`.; ``` This pr fix these two unit test by change Windows path into URI path. ## How was this patch tested? Existed. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: wuyi5 <ngone_5451@163.com> Closes #20199 from Ngone51/SPARK-22967. (cherry picked from commit 0552c36e02434c60dad82024334d291f6008b822) Signed-off-by: hyukjinkwon <gurwls223@gmail.com> | 11 January 2018, 13:17:28 UTC |
| b781301 | Marcelo Vanzin | 11 January 2018, 11:41:48 UTC | [SPARK-20657][CORE] Speed up rendering of the stages page. There are two main changes to speed up rendering of the tasks list when rendering the stage page. The first one makes the code only load the tasks being shown in the current page of the tasks table, and information related to only those tasks. One side-effect of this change is that the graph that shows task-related events now only shows events for the tasks in the current page, instead of the previously hardcoded limit of "events for the first 1000 tasks". That ends up helping with readability, though. To make sorting efficient when using a disk store, the task wrapper was extended to include many new indices, one for each of the sortable columns in the UI, and metrics for which quantiles are calculated. The second changes the way metric quantiles are calculated for stages. Instead of using the "Distribution" class to process data for all task metrics, which requires scanning all tasks of a stage, the code now uses the KVStore "skip()" functionality to only read tasks that contain interesting information for the quantiles that are desired. This is still not cheap; because there are many metrics that the UI and API track, the code needs to scan the index for each metric to gather the information. Savings come mainly from skipping deserialization when using the disk store, but the in-memory code also seems to be faster than before (most probably because of other changes in this patch). To make subsequent calls faster, some quantiles are cached in the status store. This makes UIs much faster after the first time a stage has been loaded. With the above changes, a lot of code in the UI layer could be simplified. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20013 from vanzin/SPARK-20657. (cherry picked from commit 1c70da3bfbb4016e394de2c73eb0db7cdd9a6968) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 11 January 2018, 11:42:19 UTC |
| d9a973d | gatorsmile | 11 January 2018, 10:17:34 UTC | [SPARK-23001][SQL] Fix NullPointerException when DESC a database with NULL description ## What changes were proposed in this pull request? When users' DB description is NULL, users might hit `NullPointerException`. This PR is to fix the issue. ## How was this patch tested? Added test cases Author: gatorsmile <gatorsmile@gmail.com> Closes #20215 from gatorsmile/SPARK-23001. (cherry picked from commit 87c98de8b23f0e978958fc83677fdc4c339b7e6a) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 11 January 2018, 10:17:56 UTC |
| 317b0aa | Mingjie Tang | 11 January 2018, 03:51:03 UTC | [SPARK-22587] Spark job fails if fs.defaultFS and application jar are different url ## What changes were proposed in this pull request? Two filesystems comparing does not consider the authority of URI. This is specific for WASB file storage system, where userInfo is honored to differentiate filesystems. For example: wasbs://user1xyz.net, wasbs://user2xyz.net would consider as two filesystem. Therefore, we have to add the authority to compare two filesystem, and two filesystem with different authority can not be the same FS. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Mingjie Tang <mtang@hortonworks.com> Closes #19885 from merlintang/EAR-7377. (cherry picked from commit a6647ffbf7a312a3e119a9beef90880cc915aa60) Signed-off-by: jerryshao <sshao@hortonworks.com> | 11 January 2018, 03:51:34 UTC |