https://github.com/apache/spark
- HEAD
- refs/heads/branch-0.5
- refs/heads/branch-0.6
- refs/heads/branch-0.7
- refs/heads/branch-0.8
- refs/heads/branch-0.9
- refs/heads/branch-1.0
- refs/heads/branch-1.0-jdbc
- refs/heads/branch-1.1
- refs/heads/branch-1.2
- refs/heads/branch-1.3
- refs/heads/branch-1.4
- refs/heads/branch-1.5
- refs/heads/branch-1.6
- refs/heads/branch-2.0
- refs/heads/branch-2.1
- refs/heads/branch-2.2
- refs/heads/branch-2.3
- refs/heads/branch-2.4
- refs/heads/branch-3.0
- refs/heads/branch-3.1
- refs/heads/branch-3.2
- refs/heads/branch-3.3
- refs/heads/branch-3.4
- refs/heads/branch-3.5
- refs/heads/master
- refs/remotes/origin/branch-0.8
- refs/remotes/origin/td-rdd-save
- refs/tags/0.3-scala-2.8
- refs/tags/0.3-scala-2.9
- refs/tags/2.0.0-preview
- refs/tags/alpha-0.1
- refs/tags/alpha-0.2
- refs/tags/v0.5.0
- refs/tags/v0.5.1
- refs/tags/v0.5.2
- refs/tags/v0.6.0
- refs/tags/v0.6.0-yarn
- refs/tags/v0.6.1
- refs/tags/v0.6.2
- refs/tags/v0.7.0
- refs/tags/v0.7.0-bizo-1
- refs/tags/v0.7.1
- refs/tags/v0.7.2
- refs/tags/v0.9.1
- refs/tags/v0.9.2
- refs/tags/v1.0.0
- refs/tags/v1.0.1
- refs/tags/v1.0.2
- refs/tags/v1.1.0
- refs/tags/v1.1.1
- refs/tags/v1.2.0
- refs/tags/v1.2.1
- refs/tags/v1.2.2
- refs/tags/v1.3.0
- refs/tags/v1.3.1
- refs/tags/v1.4.0
- refs/tags/v1.4.1
- refs/tags/v1.5.0-rc1
- refs/tags/v1.5.0-rc2
- refs/tags/v1.5.0-rc3
- refs/tags/v1.5.1
- refs/tags/v1.6.0
- refs/tags/v1.6.1
- refs/tags/v1.6.2
- refs/tags/v1.6.3
- refs/tags/v2.0.0
- refs/tags/v2.0.1
- refs/tags/v2.0.2
- refs/tags/v2.1.0
- refs/tags/v2.1.1
- refs/tags/v2.1.2
- refs/tags/v2.1.2-rc1
- refs/tags/v2.1.2-rc2
- refs/tags/v2.1.2-rc3
- refs/tags/v2.1.2-rc4
- refs/tags/v2.1.3
- refs/tags/v2.1.3-rc1
- refs/tags/v2.1.3-rc2
- refs/tags/v2.2.0
- refs/tags/v2.2.1
- refs/tags/v2.2.1-rc1
- refs/tags/v2.2.1-rc2
- refs/tags/v2.2.2
- refs/tags/v2.2.2-rc1
- refs/tags/v2.2.2-rc2
- refs/tags/v2.2.3
- refs/tags/v2.2.3-rc1
- refs/tags/v2.3.0
- refs/tags/v2.3.0-rc1
- refs/tags/v2.3.0-rc2
- refs/tags/v2.3.0-rc3
- refs/tags/v2.3.0-rc4
- refs/tags/v2.3.1
- refs/tags/v2.3.1-rc1
- refs/tags/v2.3.1-rc2
- refs/tags/v2.3.1-rc3
- refs/tags/v2.3.1-rc4
- refs/tags/v2.3.2
- refs/tags/v2.3.2-rc1
- refs/tags/v2.3.2-rc2
- refs/tags/v2.3.2-rc3
- refs/tags/v2.3.2-rc4
- refs/tags/v2.3.2-rc5
- refs/tags/v2.3.2-rc6
- refs/tags/v2.3.3
- refs/tags/v2.3.3-rc1
- refs/tags/v2.3.3-rc2
- refs/tags/v2.3.4
- refs/tags/v2.3.4-rc1
- refs/tags/v2.4.0
- refs/tags/v2.4.0-rc1
- refs/tags/v2.4.0-rc2
- refs/tags/v2.4.0-rc3
- refs/tags/v2.4.0-rc4
- refs/tags/v2.4.0-rc5
- refs/tags/v2.4.1
- refs/tags/v2.4.1-rc1
- refs/tags/v2.4.1-rc2
- refs/tags/v2.4.1-rc3
- refs/tags/v2.4.1-rc4
- refs/tags/v2.4.1-rc5
- refs/tags/v2.4.1-rc6
- refs/tags/v2.4.1-rc7
- refs/tags/v2.4.1-rc8
- refs/tags/v2.4.1-rc9
- refs/tags/v2.4.2
- refs/tags/v2.4.2-rc1
- refs/tags/v2.4.3
- refs/tags/v2.4.3-rc1
- refs/tags/v2.4.4
- refs/tags/v2.4.4-rc1
- refs/tags/v2.4.4-rc2
- refs/tags/v2.4.4-rc3
- refs/tags/v2.4.5
- refs/tags/v2.4.5-rc1
- refs/tags/v2.4.5-rc2
- refs/tags/v2.4.6
- refs/tags/v2.4.6-rc1
- refs/tags/v2.4.6-rc2
- refs/tags/v2.4.6-rc3
- refs/tags/v2.4.6-rc4
- refs/tags/v2.4.6-rc5
- refs/tags/v2.4.6-rc6
- refs/tags/v2.4.6-rc7
- refs/tags/v2.4.6-rc8
- refs/tags/v2.4.7
- refs/tags/v2.4.7-rc1
- refs/tags/v2.4.7-rc2
- refs/tags/v2.4.7-rc3
- refs/tags/v2.4.8
- refs/tags/v2.4.8-rc1
- refs/tags/v2.4.8-rc2
- refs/tags/v2.4.8-rc3
- refs/tags/v2.4.8-rc4
- refs/tags/v3.0.0
- refs/tags/v3.0.0-preview2
- refs/tags/v3.0.0-preview2-rc1
- refs/tags/v3.0.0-preview2-rc2
- refs/tags/v3.0.0-rc1
- refs/tags/v3.0.0-rc2
- refs/tags/v3.0.0-rc3
- refs/tags/v3.0.1
- refs/tags/v3.0.1-rc1
- refs/tags/v3.0.1-rc2
- refs/tags/v3.0.1-rc3
- refs/tags/v3.0.2
- refs/tags/v3.0.2-rc1
- refs/tags/v3.0.3
- refs/tags/v3.0.3-rc1
- refs/tags/v3.1.0-rc1
- refs/tags/v3.1.1
- refs/tags/v3.1.1-rc1
- refs/tags/v3.1.1-rc2
- refs/tags/v3.1.1-rc3
- refs/tags/v3.1.2
- refs/tags/v3.1.2-rc1
- refs/tags/v3.1.3
- refs/tags/v3.1.3-rc1
- refs/tags/v3.1.3-rc2
- refs/tags/v3.1.3-rc3
- refs/tags/v3.1.3-rc4
- refs/tags/v3.2.0
- refs/tags/v3.2.0-rc1
- refs/tags/v3.2.0-rc2
- refs/tags/v3.2.0-rc3
- refs/tags/v3.2.0-rc4
- refs/tags/v3.2.0-rc5
- refs/tags/v3.2.0-rc6
- refs/tags/v3.2.0-rc7
- refs/tags/v3.2.1
- refs/tags/v3.2.1-rc1
- refs/tags/v3.2.1-rc2
- refs/tags/v3.2.2
- refs/tags/v3.2.2-rc1
- refs/tags/v3.2.3
- refs/tags/v3.2.3-rc1
- refs/tags/v3.2.4
- refs/tags/v3.2.4-rc1
- refs/tags/v3.3.0
- refs/tags/v3.3.0-rc1
- refs/tags/v3.3.0-rc2
- refs/tags/v3.3.0-rc3
- refs/tags/v3.3.0-rc4
- refs/tags/v3.3.0-rc5
- refs/tags/v3.3.0-rc6
- refs/tags/v3.3.1
- refs/tags/v3.3.1-rc1
- refs/tags/v3.3.1-rc2
- refs/tags/v3.3.1-rc3
- refs/tags/v3.3.1-rc4
- refs/tags/v3.3.2
- refs/tags/v3.3.2-rc1
- refs/tags/v3.3.3
- refs/tags/v3.3.3-rc1
- refs/tags/v3.3.4
- refs/tags/v3.3.4-rc1
- refs/tags/v3.4.0
- refs/tags/v3.4.0-rc1
- refs/tags/v3.4.0-rc2
- refs/tags/v3.4.0-rc3
- refs/tags/v3.4.0-rc4
- refs/tags/v3.4.0-rc5
- refs/tags/v3.4.0-rc6
- refs/tags/v3.4.0-rc7
- refs/tags/v3.4.1
- refs/tags/v3.4.1-rc1
- refs/tags/v3.4.2
- refs/tags/v3.4.2-rc1
- refs/tags/v3.4.3
- refs/tags/v3.4.3-rc1
- refs/tags/v3.4.3-rc2
- refs/tags/v3.5.0
- refs/tags/v3.5.0-rc1
- refs/tags/v3.5.0-rc2
- refs/tags/v3.5.0-rc3
- refs/tags/v3.5.0-rc4
- refs/tags/v3.5.0-rc5
- refs/tags/v3.5.1
- refs/tags/v3.5.1-rc1
- refs/tags/v3.5.1-rc2
- refs/tags/v3.5.2
- refs/tags/v3.5.2-rc1
- refs/tags/v3.5.2-rc2
- refs/tags/v3.5.2-rc3
- refs/tags/v3.5.2-rc4
- refs/tags/v3.5.2-rc5
- refs/tags/v4.0.0-preview1
- refs/tags/v4.0.0-preview1-rc1
- refs/tags/v4.0.0-preview1-rc2
- refs/tags/v4.0.0-preview1-rc3
Take a new snapshot of a software origin
If the archived software origin currently browsed is not synchronized with its upstream version (for instance when new commits have been issued), you can explicitly request Software Heritage to take a new snapshot of it.
Use the form below to proceed. Once a request has been submitted and accepted, it will be processed as soon as possible. You can then check its processing state by visiting this dedicated page.
Processing "take a new snapshot" request ...
Permalinks
To reference or cite the objects present in the Software Heritage archive, permalinks based on SoftWare Hash IDentifiers (SWHIDs) must be used.
Select below a type of object currently browsed in order to display its associated SWHID and permalink.
| Revision | Author | Date | Message | Commit Date |
|---|---|---|---|---|
| 13f2465 | Dongjoon Hyun | 19 August 2019, 07:11:32 UTC | Preparing Spark release v2.4.4-rc1 | 19 August 2019, 07:11:32 UTC |
| 73032a0 | Dongjoon Hyun | 18 August 2019, 14:35:06 UTC | Revert "[SPARK-25474][SQL][2.4] Support `spark.sql.statistics.fallBackToHdfs` in data source tables" This reverts commit 5f4feeb0ae236cc2b4cff80889bf23c8e017d9d4. | 18 August 2019, 14:35:06 UTC |
| b98a372 | Kousuke Saruta | 18 August 2019, 14:11:18 UTC | [SPARK-28647][WEBUI][2.4] Recover additional metric feature This PR is for backporting SPARK-28647(#25374) to branch-2.4. The original PR removed `additional-metrics.js` but branch-2.4 still uses it so I don't remove it and related things for branch-2.4. ### What changes were proposed in this pull request? Added checkboxes to enable users to select which optional metrics (`On Heap Memory`, `Off Heap Memory` and `Select All` in this case) to be shown in `ExecuorPage`. ### Why are the changes needed? By SPARK-17019, `On Heap Memory` and `Off Heap Memory` are introduced as optional metrics. But they are not displayed because they are made `display: none` in css and there are no way to appear them. ### Does this PR introduce any user-facing change? The previous `ExecutorPage` doesn't show optional metrics. This change adds checkboxes to `ExecutorPage` for optional metrics. We can choose which metrics should be shown by checking corresponding checkboxes. 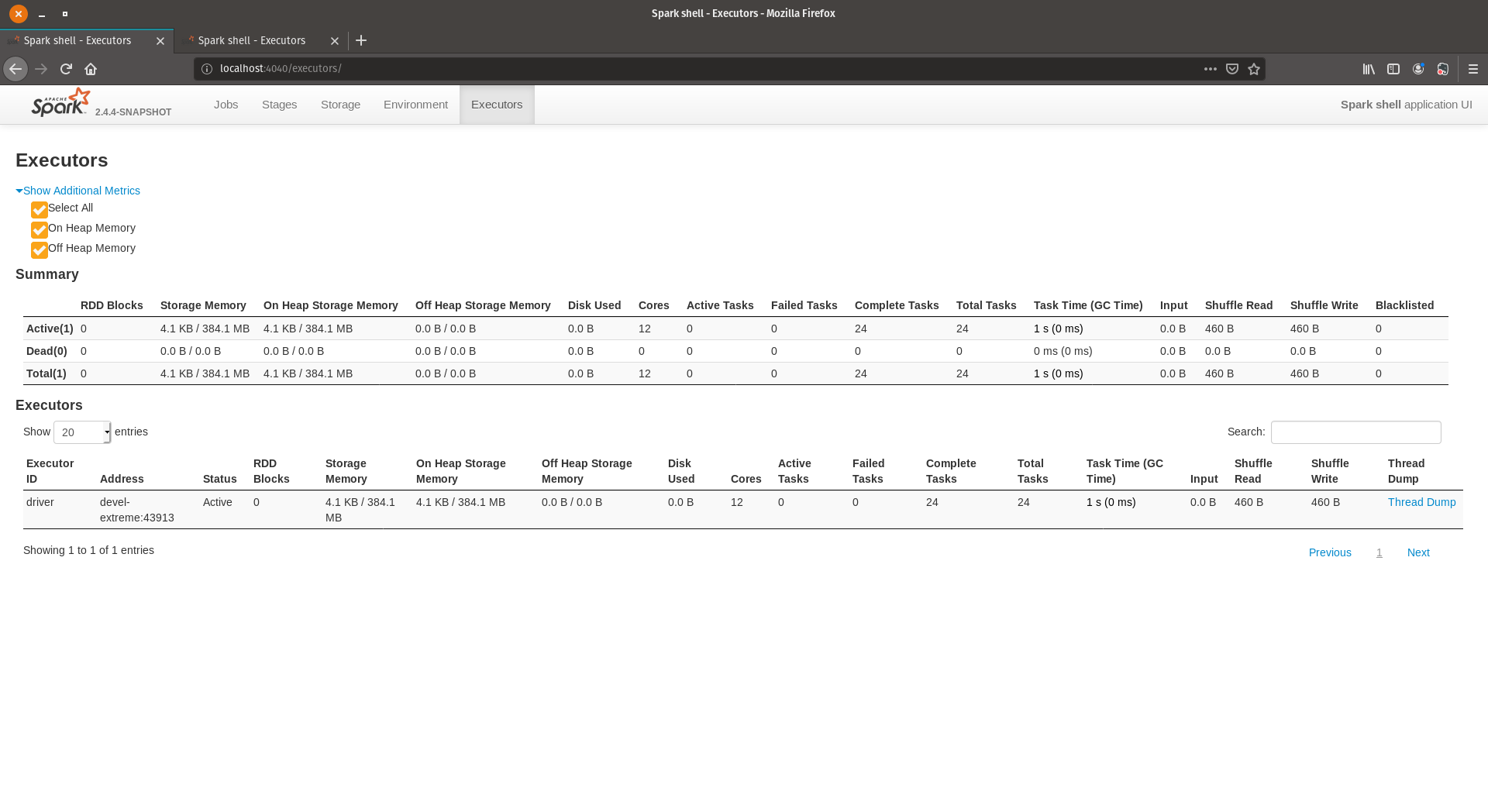 ### How was this patch tested? Manual test. Closes #25484 from sarutak/backport-SPARK-28647-branch-2.4. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 18 August 2019, 14:11:18 UTC |
| 0246f48 | Dongjoon Hyun | 17 August 2019, 18:11:36 UTC | [SPARK-28766][R][DOC] Fix CRAN incoming feasibility warning on invalid URL ### What changes were proposed in this pull request? This updates an URL in R doc to fix `Had CRAN check errors; see logs`. ### Why are the changes needed? Currently, this invalid link causes a warning during CRAN incoming feasibility. We had better fix this before submitting `3.0.0/2.4.4/2.3.4`. **BEFORE** ``` * checking CRAN incoming feasibility ... NOTE Maintainer: ‘Shivaram Venkataraman <shivaramcs.berkeley.edu>’ Found the following (possibly) invalid URLs: URL: https://wiki.apache.org/hadoop/HCFS (moved to https://cwiki.apache.org/confluence/display/hadoop/HCFS) From: man/spark.addFile.Rd Status: 404 Message: Not Found ``` **AFTER** ``` * checking CRAN incoming feasibility ... Note_to_CRAN_maintainers Maintainer: ‘Shivaram Venkataraman <shivaramcs.berkeley.edu>’ ``` ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Check the warning message during R testing. ``` $ R/install-dev.sh $ R/run-tests.sh ``` Closes #25483 from dongjoon-hyun/SPARK-28766. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 5756a47a9fafca2d0b31de2b2374429f73b6e5e2) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 17 August 2019, 18:11:51 UTC |
| 97471bd | Dongjoon Hyun | 15 August 2019, 18:22:57 UTC | [MINOR][DOC] Use `Java 8` instead of `Java 8+` as a running environment After Apache Spark 3.0.0 supports JDK11 officially, people will try JDK11 on old Spark releases (especially 2.4.4/2.3.4) in the same way because our document says `Java 8+`. We had better avoid that misleading situation. This PR aims to remove `+` from `Java 8+` in the documentation (master/2.4/2.3). Especially, 2.4.4 release and 2.3.4 release (cc kiszk ) On master branch, we will add JDK11 after [SPARK-24417.](https://issues.apache.org/jira/browse/SPARK-24417) This is a documentation only change. <img width="923" alt="java8" src="https://user-images.githubusercontent.com/9700541/63116589-e1504800-bf4e-11e9-8904-b160ec7a42c0.png"> Closes #25466 from dongjoon-hyun/SPARK-DOC-JDK8. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 123eb58d61ad7c7ebe540f1634088696a3cc85bc) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 15 August 2019, 18:24:02 UTC |
| 5a06584 | HyukjinKwon | 15 August 2019, 04:36:20 UTC | [SPARK-27234][SS][PYTHON][BRANCH-2.4] Use InheritableThreadLocal for current epoch in EpochTracker (to support Python UDFs) ## What changes were proposed in this pull request? This PR proposes to use `InheritableThreadLocal` instead of `ThreadLocal` for current epoch in `EpochTracker`. Python UDF needs threads to write out to and read it from Python processes and when there are new threads, previously set epoch is lost. After this PR, Python UDFs can be used at Structured Streaming with the continuous mode. ## How was this patch tested? Manually tested: ```python from pyspark.sql.functions import col, udf fooUDF = udf(lambda p: "foo") spark \ .readStream \ .format("rate") \ .load()\ .withColumn("foo", fooUDF(col("value")))\ .writeStream\ .format("console")\ .trigger(continuous="1 second").start() ``` Note that test was not ported because: 1. `IntegratedUDFTestUtils` only exists in master. 2. Missing SS testing utils in PySpark code base. 3. Writing new test for branch-2.4 specifically might bring even more overhead due to mismatch against master. Closes #25457 from HyukjinKwon/SPARK-27234-backport. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 15 August 2019, 04:36:20 UTC |
| dfcebca | Fokko Driesprong | 13 August 2019, 23:03:23 UTC | [SPARK-28713][BUILD][2.4] Bump checkstyle from 8.2 to 8.23 ## What changes were proposed in this pull request? Backport to `branch-2.4` of https://github.com/apache/spark/pull/25432 Fixes a vulnerability from the GitHub Security Advisory Database: _Moderate severity vulnerability that affects com.puppycrawl.tools:checkstyle_ Checkstyle prior to 8.18 loads external DTDs by default, which can potentially lead to denial of service attacks or the leaking of confidential information. https://github.com/checkstyle/checkstyle/issues/6474 Affected versions: < 8.18 ## How was this patch tested? Ran checkstyle locally. Closes #25437 from Fokko/branch-2.4. Authored-by: Fokko Driesprong <fokko@apache.org> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 13 August 2019, 23:03:23 UTC |
| c37abba | Gengliang Wang | 12 August 2019, 18:47:29 UTC | [SPARK-28638][WEBUI] Task summary should only contain successful tasks' metrics ## What changes were proposed in this pull request? Currently, on requesting summary metrics, cached data are returned if the current number of "SUCCESS" tasks is the same as the value in cached data. However, the number of "SUCCESS" tasks is wrong when there are running tasks. In `AppStatusStore`, the KVStore is `ElementTrackingStore`, instead of `InMemoryStore`. The value count is always the number of "SUCCESS" tasks + "RUNNING" tasks. Thus, even when the running tasks are finished, the out-of-update cached data is returned. This PR is to fix the code in getting the number of "SUCCESS" tasks. ## How was this patch tested? Test manually, run ``` sc.parallelize(1 to 160, 40).map(i => Thread.sleep(i*100)).collect() ``` and keep refreshing the stage page , we can see the task summary metrics is wrong. ### Before fix:  ### After fix:  Closes #25369 from gengliangwang/fixStagePage. Authored-by: Gengliang Wang <gengliang.wang@databricks.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> (cherry picked from commit 48d04f74ca895497b9d8bab18c7708f76f55c520) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> | 12 August 2019, 18:48:00 UTC |
| a2bbbf8 | Rob Vesse | 07 August 2019, 23:55:11 UTC | [SPARK-28649][INFRA] Add Python .eggs to .gitignore ## What changes were proposed in this pull request? If you build Spark distributions you potentially end up with a `python/.eggs` directory in your working copy which is not currently ignored by Spark's `.gitignore` file. Since these are transient build artifacts there is no reason to ever commit these to Git so this should be placed in the `.gitignore` list ## How was this patch tested? Verified the offending artifacts were no longer reported as untracked content by Git Closes #25380 from rvesse/patch-1. Authored-by: Rob Vesse <rvesse@dotnetrdf.org> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 6ea4a737eaf6de41deb3ca9595c84a19b1b35554) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 07 August 2019, 23:55:29 UTC |
| 04d9f8f | Dongjoon Hyun | 04 August 2019, 16:42:47 UTC | [SPARK-28609][DOC] Fix broken styles/links and make up-to-date This PR aims to fix the broken styles/links and make the doc up-to-date for Apache Spark 2.4.4 and 3.0.0 release. - `building-spark.md`  - `configuration.md`  - `sql-pyspark-pandas-with-arrow.md`  - `streaming-programming-guide.md`  - `structured-streaming-programming-guide.md` (1/2)  - `structured-streaming-programming-guide.md` (2/2)  - `submitting-applications.md`  Manual. Build the doc. ``` SKIP_API=1 jekyll build ``` Closes #25345 from dongjoon-hyun/SPARK-28609. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 4856c0e33abd1666f606d57102c198adf5cb5fc2) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 04 August 2019, 16:45:04 UTC |
| 6c61321 | WeichenXu | 03 August 2019, 01:31:15 UTC | [SPARK-28582][PYTHON] Fix flaky test DaemonTests.do_termination_test which fail on Python 3.7 This PR picks up https://github.com/apache/spark/pull/25315 back after removing `Popen.wait` usage which exists in Python 3 only. I saw the last test results wrongly and thought it was passed. Fix flaky test DaemonTests.do_termination_test which fail on Python 3.7. I add a sleep after the test connection to daemon. Run test ``` python/run-tests --python-executables=python3.7 --testname "pyspark.tests.test_daemon DaemonTests" ``` **Before** Fail on test "test_termination_sigterm". And we can see daemon process do not exit. **After** Test passed Closes #25343 from HyukjinKwon/SPARK-28582. Authored-by: WeichenXu <weichen.xu@databricks.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit b3394db1930b3c9f55438cb27bb2c584bf041f8e) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 03 August 2019, 01:33:13 UTC |
| be52903 | Dongjoon Hyun | 02 August 2019, 23:41:00 UTC | [SPARK-28606][INFRA] Update CRAN key to recover docker image generation CRAN repo changed the key and it causes our release script failure. This is a release blocker for Apache Spark 2.4.4 and 3.0.0. - https://cran.r-project.org/bin/linux/ubuntu/README.html ``` Err:1 https://cloud.r-project.org/bin/linux/ubuntu bionic-cran35/ InRelease The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 51716619E084DAB9 ... W: GPG error: https://cloud.r-project.org/bin/linux/ubuntu bionic-cran35/ InRelease: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 51716619E084DAB9 E: The repository 'https://cloud.r-project.org/bin/linux/ubuntu bionic-cran35/ InRelease' is not signed. ``` Note that they are reusing `cran35` for R 3.6 although they changed the key. ``` Even though R has moved to version 3.6, for compatibility the sources.list entry still uses the cran3.5 designation. ``` This PR aims to recover the docker image generation first. We will verify the R doc generation in a separate JIRA and PR. Manual. After `docker-build.log`, it should continue to the next stage, `Building v3.0.0-rc1`. ``` $ dev/create-release/do-release-docker.sh -d /tmp/spark-3.0.0 -n -s docs ... Log file: docker-build.log Building v3.0.0-rc1; output will be at /tmp/spark-3.0.0/output ``` Closes #25339 from dongjoon-hyun/SPARK-28606. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: DB Tsai <d_tsai@apple.com> (cherry picked from commit 0c6874fb37f97c36a5265455066de9e516845df2) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 03 August 2019, 00:04:15 UTC |
| fe0f53a | Dongjoon Hyun | 02 August 2019, 17:08:29 UTC | Revert "[SPARK-28582][PYSPARK] Fix flaky test DaemonTests.do_termination_test which fail on Python 3.7" This reverts commit 20e46ef6e3e49e754062717c2cb249c6eb99e86a. | 02 August 2019, 17:08:29 UTC |
| dad1cd6 | Jungtaek Lim (HeartSaVioR) | 02 August 2019, 16:12:54 UTC | [MINOR][DOC][SS] Correct description of minPartitions in Kafka option ## What changes were proposed in this pull request? `minPartitions` has been used as a hint and relevant method (KafkaOffsetRangeCalculator.getRanges) doesn't guarantee the behavior that partitions will be equal or more than given value. https://github.com/apache/spark/blob/d67b98ea016e9b714bef68feaac108edd08159c9/external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaOffsetRangeCalculator.scala#L32-L46 This patch makes clear the configuration is a hint, and actual partitions could be less or more. ## How was this patch tested? Just a documentation change. Closes #25332 from HeartSaVioR/MINOR-correct-kafka-structured-streaming-doc-minpartition. Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 7ffc00ccc37fc94a45b7241bb3c6a17736b55ba3) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 02 August 2019, 16:13:08 UTC |
| 20e46ef | WeichenXu | 02 August 2019, 13:07:06 UTC | [SPARK-28582][PYSPARK] Fix flaky test DaemonTests.do_termination_test which fail on Python 3.7 Fix flaky test DaemonTests.do_termination_test which fail on Python 3.7. I add a sleep after the test connection to daemon. Run test ``` python/run-tests --python-executables=python3.7 --testname "pyspark.tests.test_daemon DaemonTests" ``` **Before** Fail on test "test_termination_sigterm". And we can see daemon process do not exit. **After** Test passed Closes #25315 from WeichenXu123/fix_py37_daemon. Authored-by: WeichenXu <weichen.xu@databricks.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit fbeee0c5bcea32346b2279c5b67044f12e5faf7d) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 02 August 2019, 13:13:27 UTC |
| a065a50 | HyukjinKwon | 02 August 2019, 13:12:04 UTC | Revert "[SPARK-28582][PYSPARK] Fix flaky test DaemonTests.do_termination_test which fail on Python 3.7" This reverts commit dc09a02c142d3787e728c8b25eb8417649d98e9f. | 02 August 2019, 13:12:04 UTC |
| dc09a02 | WeichenXu | 02 August 2019, 13:07:06 UTC | [SPARK-28582][PYSPARK] Fix flaky test DaemonTests.do_termination_test which fail on Python 3.7 Fix flaky test DaemonTests.do_termination_test which fail on Python 3.7. I add a sleep after the test connection to daemon. Run test ``` python/run-tests --python-executables=python3.7 --testname "pyspark.tests.test_daemon DaemonTests" ``` **Before** Fail on test "test_termination_sigterm". And we can see daemon process do not exit. **After** Test passed Closes #25315 from WeichenXu123/fix_py37_daemon. Authored-by: WeichenXu <weichen.xu@databricks.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit fbeee0c5bcea32346b2279c5b67044f12e5faf7d) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 02 August 2019, 13:10:56 UTC |
| 9c8c8ba | HyukjinKwon | 01 August 2019, 09:27:22 UTC | [SPARK-28153][PYTHON][BRANCH-2.4] Use AtomicReference at InputFileBlockHolder (to support input_file_name with Python UDF) ## What changes were proposed in this pull request? This PR backports https://github.com/apache/spark/pull/24958 to branch-2.4. This PR proposes to use `AtomicReference` so that parent and child threads can access to the same file block holder. Python UDF expressions are turned to a plan and then it launches a separate thread to consume the input iterator. In the separate child thread, the iterator sets `InputFileBlockHolder.set` before the parent does which the parent thread is unable to read later. 1. In this separate child thread, if it happens to call `InputFileBlockHolder.set` first without initialization of the parent's thread local (which is done when the `ThreadLocal.get()` is first called), the child thread seems calling its own `initialValue` to initialize. 2. After that, the parent calls its own `initialValue` to initializes at the first call of `ThreadLocal.get()`. 3. Both now have two different references. Updating at child isn't reflected to parent. This PR fixes it via initializing parent's thread local with `AtomicReference` for file status so that they can be used in each task, and children thread's update is reflected. I also tried to explain this a bit more at https://github.com/apache/spark/pull/24958#discussion_r297203041. ## How was this patch tested? Manually tested and unittest was added. Closes #25321 from HyukjinKwon/backport-SPARK-28153. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 01 August 2019, 09:27:22 UTC |
| 93f5fb8 | Marcelo Vanzin | 01 August 2019, 00:44:20 UTC | [SPARK-24352][CORE][TESTS] De-flake StandaloneDynamicAllocationSuite blacklist test The issue is that the test tried to stop an existing scheduler and replace it with a new one set up for the test. That can cause issues because both were sharing the same RpcEnv underneath, and unregistering RpcEndpoints is actually asynchronous (see comment in Dispatcher.unregisterRpcEndpoint). So that could lead to races where the new scheduler tried to register before the old one was fully unregistered. The updated test avoids the issue by using a separate RpcEnv / scheduler instance altogether, and also avoids a misleading NPE in the test logs. Closes #25318 from vanzin/SPARK-24352. Authored-by: Marcelo Vanzin <vanzin@cloudera.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit b3ffd8be14779cbb824d14b409f0a6eab93444ba) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 01 August 2019, 00:45:32 UTC |
| 6a361d4 | sychen | 31 July 2019, 20:24:36 UTC | [SPARK-28564][CORE] Access history application defaults to the last attempt id ## What changes were proposed in this pull request? When we set ```spark.history.ui.maxApplications``` to a small value, we can't get some apps from the page search. If the url is spliced (http://localhost:18080/history/local-xxx), it can be accessed if the app has no attempt. But in the case of multiple attempted apps, such a url cannot be accessed, and the page displays Not Found. ## How was this patch tested? Add UT Closes #25301 from cxzl25/hs_app_last_attempt_id. Authored-by: sychen <sychen@ctrip.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> (cherry picked from commit 70ef9064a8aa605b09e639d5a40528b063af25b7) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> | 31 July 2019, 20:24:52 UTC |
| 992b1bb | gengjiaan | 31 July 2019, 03:17:44 UTC | [MINOR][CORE][DOCS] Fix inconsistent description of showConsoleProgress ## What changes were proposed in this pull request? The latest docs http://spark.apache.org/docs/latest/configuration.html contains some description as below: spark.ui.showConsoleProgress | true | Show the progress bar in the console. The progress bar shows the progress of stages that run for longer than 500ms. If multiple stages run at the same time, multiple progress bars will be displayed on the same line. -- | -- | -- But the class `org.apache.spark.internal.config.UI` define the config `spark.ui.showConsoleProgress` as below: ``` val UI_SHOW_CONSOLE_PROGRESS = ConfigBuilder("spark.ui.showConsoleProgress") .doc("When true, show the progress bar in the console.") .booleanConf .createWithDefault(false) ``` So I think there are exists some little mistake and lead to confuse reader. ## How was this patch tested? No need UT. Closes #25297 from beliefer/inconsistent-desc-showConsoleProgress. Authored-by: gengjiaan <gengjiaan@360.cn> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit dba4375359a2dfed1f009edc3b1bcf6b3253fe02) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 31 July 2019, 03:18:07 UTC |
| 9d9c5a5 | Ajith | 30 July 2019, 22:43:44 UTC | [SPARK-26152][CORE][2.4] Synchronize Worker Cleanup with Worker Shutdown ## What changes were proposed in this pull request? The race between org.apache.spark.deploy.DeployMessages.WorkDirCleanup event and org.apache.spark.deploy.worker.Worker#onStop. Here its possible that while the WorkDirCleanup event is being processed, org.apache.spark.deploy.worker.Worker#cleanupThreadExecutor was shutdown. hence any submission after ThreadPoolExecutor will result in java.util.concurrent.RejectedExecutionException ## How was this patch tested? Manually Closes #25302 from dbtsai/branch-2.4-fix. Authored-by: Ajith <ajith2489@gmail.com> Signed-off-by: DB Tsai <d_tsai@apple.com> | 30 July 2019, 22:43:44 UTC |
| 5f4feeb | shahid | 29 July 2019, 16:20:09 UTC | [SPARK-25474][SQL][2.4] Support `spark.sql.statistics.fallBackToHdfs` in data source tables ## What changes were proposed in this pull request? Backport the commit https://github.com/apache/spark/commit/485ae6d1818e8756a86da38d6aefc8f1dbde49c2 into SPARK-2.4 branch. ## How was this patch tested? Added tests. Closes #25284 from shahidki31/branch-2.4. Authored-by: shahid <shahidki31@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 29 July 2019, 16:20:09 UTC |
| 8934560 | Dongjoon Hyun | 28 July 2019, 01:55:36 UTC | [SPARK-28545][SQL] Add the hash map size to the directional log of ObjectAggregationIterator ## What changes were proposed in this pull request? `ObjectAggregationIterator` shows a directional info message to increase `spark.sql.objectHashAggregate.sortBased.fallbackThreshold` when the size of the in-memory hash map grows too large and it falls back to sort-based aggregation. However, we don't know how much we need to increase. This PR adds the size of the current in-memory hash map size to the log message. **BEFORE** ``` 15:21:41.669 Executor task launch worker for task 0 INFO ObjectAggregationIterator: Aggregation hash map reaches threshold capacity (2 entries), ... ``` **AFTER** ``` 15:20:05.742 Executor task launch worker for task 0 INFO ObjectAggregationIterator: Aggregation hash map size 2 reaches threshold capacity (2 entries), ... ``` ## How was this patch tested? Manual. For example, run `ObjectHashAggregateSuite.scala`'s `typed_count fallback to sort-based aggregation` and search the above message in `target/unit-tests.log`. Closes #25276 from dongjoon-hyun/SPARK-28545. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit d943ee0a881540aa356cdce533b693baaf7c644f) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 28 July 2019, 01:55:50 UTC |
| 2e0763b | Marcelo Vanzin | 27 July 2019, 18:06:35 UTC | [SPARK-28535][CORE][TEST] Slow down tasks to de-flake JobCancellationSuite This test tries to detect correct behavior in racy code, where the event thread is racing with the executor thread that's trying to kill the running task. If the event that signals the stage end arrives first, any delay in the delivery of the message to kill the task causes the code to rapidly process elements, and may cause the test to assert. Adding a 10ms delay in LocalSchedulerBackend before the task kill makes the test run through ~1000 elements. A longer delay can easily cause the 10000 elements to be processed. Instead, by adding a small delay (10ms) in the test code that processes elements, there's a much lower probability that the kill event will not arrive before the end; that leaves a window of 100s for the event to be delivered to the executor. And because each element only sleeps for 10ms, the test is not really slowed down at all. Closes #25270 from vanzin/SPARK-28535. Authored-by: Marcelo Vanzin <vanzin@cloudera.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 7f84104b3981dc69238730e0bed7c8c5bd113d76) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 27 July 2019, 18:06:52 UTC |
| afb7492 | Shixiong Zhu | 26 July 2019, 07:10:56 UTC | [SPARK-28489][SS] Fix a bug that KafkaOffsetRangeCalculator.getRanges may drop offsets ## What changes were proposed in this pull request? `KafkaOffsetRangeCalculator.getRanges` may drop offsets due to round off errors. The test added in this PR is one example. This PR rewrites the logic in `KafkaOffsetRangeCalculator.getRanges` to ensure it never drops offsets. ## How was this patch tested? The regression test. Closes #25237 from zsxwing/fix-range. Authored-by: Shixiong Zhu <zsxwing@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit b9c2521de2bb6281356be55685df94f2d51bcc02) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 26 July 2019, 07:11:13 UTC |
| 2c2b102 | Dongjoon Hyun | 26 July 2019, 00:25:13 UTC | [MINOR][SQL] Fix log messages of DataWritingSparkTask ## What changes were proposed in this pull request? This PR fixes the log messages like `attempt 0stage 9.0` by adding a comma followed by space. These are all instances in `DataWritingSparkTask` which was introduced at https://github.com/apache/spark/commit/6d16b9885d6ad01e1cc56d5241b7ebad99487a0c. This should be fixed in `branch-2.4`, too. ``` 19/07/25 18:35:01 INFO DataWritingSparkTask: Commit authorized for partition 65 (task 153, attempt 0stage 9.0) 19/07/25 18:35:01 INFO DataWritingSparkTask: Committed partition 65 (task 153, attempt 0stage 9.0) ``` ## How was this patch tested? This only changes log messages. Pass the Jenkins with the existing tests. Closes #25257 from dongjoon-hyun/DataWritingSparkTask. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit cefce21acc64ab88d1286fa5486be489bc707a89) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 26 July 2019, 00:25:37 UTC |
| a285c0d | zhengruifeng | 24 July 2019, 01:20:22 UTC | [SPARK-28421][ML] SparseVector.apply performance optimization ## What changes were proposed in this pull request? optimize the `SparseVector.apply` by avoiding internal conversion Since the speed up is significant (2.5X ~ 5X), and this method is widely used in ml, I suggest back porting. | size| nnz | apply(old) | apply2(new impl) | apply3(new impl with extra range check)| |------|----------|------------|----------|----------| |10000000|100|75294|12208|18682| |10000000|10000|75616|23132|32932| |10000000|1000000|92949|42529|48821| ## How was this patch tested? existing tests using following code to test performance (here the new impl is named `apply2`, and another impl with extra range check is named `apply3`): ``` import scala.util.Random import org.apache.spark.ml.linalg._ val size = 10000000 for (nnz <- Seq(100, 10000, 1000000)) { val rng = new Random(123) val indices = Array.fill(nnz + nnz)(rng.nextInt.abs % size).distinct.take(nnz).sorted val values = Array.fill(nnz)(rng.nextDouble) val vec = Vectors.sparse(size, indices, values).toSparse val tic1 = System.currentTimeMillis; (0 until 100).foreach{ round => var i = 0; var sum = 0.0; while(i < size) {sum+=vec(i); i+=1} }; val toc1 = System.currentTimeMillis; val tic2 = System.currentTimeMillis; (0 until 100).foreach{ round => var i = 0; var sum = 0.0; while(i < size) {sum+=vec.apply2(i); i+=1} }; val toc2 = System.currentTimeMillis; val tic3 = System.currentTimeMillis; (0 until 100).foreach{ round => var i = 0; var sum = 0.0; while(i < size) {sum+=vec.apply3(i); i+=1} }; val toc3 = System.currentTimeMillis; println((size, nnz, toc1 - tic1, toc2 - tic2, toc3 - tic3)) } ``` Closes #25178 from zhengruifeng/sparse_vec_apply. Authored-by: zhengruifeng <ruifengz@foxmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> | 25 July 2019, 12:57:02 UTC |
| 59137e2 | Luca Canali | 25 July 2019, 08:51:51 UTC | [SPARK-26995][K8S][2.4] Make ld-linux-x86-64.so.2 visible to snappy native library under /lib in docker image with Alpine Linux ## What changes were proposed in this pull request? This is a back port of #23898. Running Spark in Docker image with Alpine Linux 3.9.0 throws errors when using snappy. The issue can be reproduced for example as follows: `Seq(1,2).toDF("id").write.format("parquet").save("DELETEME1")` The key part of the error stack is as follows `SparkException: Task failed while writing rows. .... Caused by: java.lang.UnsatisfiedLinkError: /tmp/snappy-1.1.7-2b4872f1-7c41-4b84-bda1-dbcb8dd0ce4c-libsnappyjava.so: Error loading shared library ld-linux-x86-64.so.2: Noded by /tmp/snappy-1.1.7-2b4872f1-7c41-4b84-bda1-dbcb8dd0ce4c-libsnappyjava.so)` The source of the error appears to be that libsnappyjava.so needs ld-linux-x86-64.so.2 and looks for it in /lib, while in Alpine Linux 3.9.0 with libc6-compat version 1.1.20-r3 ld-linux-x86-64.so.2 is located in /lib64. Note: this issue is not present with Alpine Linux 3.8 and libc6-compat version 1.1.19-r10 A possible workaround proposed with this PR is to modify the Dockerfile by adding a symbolic link between /lib and /lib64 so that linux-x86-64.so.2 can be found in /lib. This is probably not the cleanest solution, but I have observed that this is what happened/happens already when using Alpine Linux 3.8.1 (a version of Alpine Linux which was not affected by the issue reported here). ## How was this patch tested? Manually tested by running a simple workload with spark-shell, using docker on a client machine and using Spark on a Kubernetes cluster. The test workload is: `Seq(1,2).toDF("id").write.format("parquet").save("DELETEME1")` Added a test to the KubernetesSuite / BasicTestsSuite Closes #25255 from dongjoon-hyun/SPARK-26995. Authored-by: Luca Canali <luca.canali@cern.ch> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 25 July 2019, 08:51:51 UTC |
| 771db3b | Bruce Robbins | 25 July 2019, 08:36:26 UTC | [SPARK-28156][SQL][BACKPORT-2.4] Self-join should not miss cached view Back-port of #24960 to branch-2.4. The issue is when self-join a cached view, only one side of join uses cached relation. The cause is in `ResolveReferences` we do deduplicate for a view to have new output attributes. Then in `AliasViewChild`, the rule adds extra project under a view. So it breaks cache matching. The fix is when dedup, we only dedup a view which has output different to its child plan. Otherwise, we dedup on the view's child plan. ```scala val df = Seq.tabulate(5) { x => (x, x + 1, x + 2, x + 3) }.toDF("a", "b", "c", "d") df.write.mode("overwrite").format("orc").saveAsTable("table1") sql("drop view if exists table1_vw") sql("create view table1_vw as select * from table1") val cachedView = sql("select a, b, c, d from table1_vw") cachedView.createOrReplaceTempView("cachedview") cachedView.persist() val queryDf = sql( s"""select leftside.a, leftside.b |from cachedview leftside |join cachedview rightside |on leftside.a = rightside.a """.stripMargin) ``` Query plan before this PR: ```scala == Physical Plan == *(2) Project [a#12664, b#12665] +- *(2) BroadcastHashJoin [a#12664], [a#12660], Inner, BuildRight :- *(2) Filter isnotnull(a#12664) : +- *(2) InMemoryTableScan [a#12664, b#12665], [isnotnull(a#12664)] : +- InMemoryRelation [a#12664, b#12665, c#12666, d#12667], StorageLevel(disk, memory, deserialized, 1 replicas) : +- *(1) FileScan orc default.table1[a#12660,b#12661,c#12662,d#12663] Batched: true, DataFilters: [], Format: ORC, Location: InMemoryF ileIndex[file:/Users/viirya/repos/spark-1/sql/core/spark-warehouse/org.apache.spark.sql...., PartitionFilters: [], PushedFilters: [], ReadSchema: struc t<a:int,b:int,c:int,d:int> +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint))) +- *(1) Project [a#12660] +- *(1) Filter isnotnull(a#12660) +- *(1) FileScan orc default.table1[a#12660] Batched: true, DataFilters: [isnotnull(a#12660)], Format: ORC, Location: InMemoryFileIndex[fil e:/Users/viirya/repos/spark-1/sql/core/spark-warehouse/org.apache.spark.sql...., PartitionFilters: [], PushedFilters: [IsNotNull(a)], ReadSchema: struc t<a:int> ``` Query plan after this PR: ```scala == Physical Plan == *(2) Project [a#12664, b#12665] +- *(2) BroadcastHashJoin [a#12664], [a#12692], Inner, BuildRight :- *(2) Filter isnotnull(a#12664) : +- *(2) InMemoryTableScan [a#12664, b#12665], [isnotnull(a#12664)] : +- InMemoryRelation [a#12664, b#12665, c#12666, d#12667], StorageLevel(disk, memory, deserialized, 1 replicas) : +- *(1) FileScan orc default.table1[a#12660,b#12661,c#12662,d#12663] Batched: true, DataFilters: [], Format: ORC, Location: InMemoryFileIndex[file:/Users/viirya/repos/spark-1/sql/core/spark-warehouse/org.apache.spark.sql...., PartitionFilters: [], PushedFilters: [], ReadSchema: struct<a:int,b:int,c:int,d:int> +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint))) +- *(1) Filter isnotnull(a#12692) +- *(1) InMemoryTableScan [a#12692], [isnotnull(a#12692)] +- InMemoryRelation [a#12692, b#12693, c#12694, d#12695], StorageLevel(disk, memory, deserialized, 1 replicas) +- *(1) FileScan orc default.table1[a#12660,b#12661,c#12662,d#12663] Batched: true, DataFilters: [], Format: ORC, Location: InMemoryFileIndex[file:/Users/viirya/repos/spark-1/sql/core/spark-warehouse/org.apache.spark.sql...., PartitionFilters: [], PushedFilters: [], ReadSchema: struct<a:int,b:int,c:int,d:int> ``` Added test. Closes #25068 from bersprockets/selfjoin_24. Lead-authored-by: Bruce Robbins <bersprockets@gmail.com> Co-authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 25 July 2019, 08:36:26 UTC |
| 98ba2f6 | shivsood | 25 July 2019, 02:35:13 UTC | [SPARK-28152][SQL][2.4] Mapped ShortType to SMALLINT and FloatType to REAL for MsSqlServerDialect ## What changes were proposed in this pull request? This is a backport of SPARK-28152 to Spark 2.4. SPARK-28152 PR aims to correct mappings in `MsSqlServerDialect`. `ShortType` is mapped to `SMALLINT` and `FloatType` is mapped to `REAL` per [JBDC mapping]( https://docs.microsoft.com/en-us/sql/connect/jdbc/using-basic-data-types?view=sql-server-2017) respectively. ShortType and FloatTypes are not correctly mapped to right JDBC types when using JDBC connector. This results in tables and spark data frame being created with unintended types. The issue was observed when validating against SQLServer. Refer [JBDC mapping]( https://docs.microsoft.com/en-us/sql/connect/jdbc/using-basic-data-types?view=sql-server-2017 ) for guidance on mappings between SQLServer, JDBC and Java. Note that java "Short" type should be mapped to JDBC "SMALLINT" and java Float should be mapped to JDBC "REAL". Some example issue that can happen because of wrong mappings - Write from df with column type results in a SQL table of with column type as INTEGER as opposed to SMALLINT.Thus a larger table that expected. - Read results in a dataframe with type INTEGER as opposed to ShortType - ShortType has a problem in both the the write and read path - FloatTypes only have an issue with read path. In the write path Spark data type 'FloatType' is correctly mapped to JDBC equivalent data type 'Real'. But in the read path when JDBC data types need to be converted to Catalyst data types ( getCatalystType) 'Real' gets incorrectly gets mapped to 'DoubleType' rather than 'FloatType'. Refer #28151 which contained this fix as one part of a larger PR. Following PR #28151 discussion it was decided to file seperate PRs for each of the fixes. ## How was this patch tested? UnitTest added in JDBCSuite.scala and these were tested. Integration test updated and passed in MsSqlServerDialect.scala E2E test done with SQLServer Closes #25248 from shivsood/PR_28152_2.4. Authored-by: shivsood <shivsood@microsoft.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 25 July 2019, 02:35:13 UTC |
| 366519d | Dongjoon Hyun | 24 July 2019, 21:20:25 UTC | [SPARK-28496][INFRA] Use branch name instead of tag during dry-run ## What changes were proposed in this pull request? There are two cases when we use `dry run`. First, when the tag already exists, we can ask `confirmation` on the existing tag name. ``` $ dev/create-release/do-release-docker.sh -d /tmp/spark-2.4.4 -n -s docs Output directory already exists. Overwrite and continue? [y/n] y Branch [branch-2.4]: Current branch version is 2.4.4-SNAPSHOT. Release [2.4.4]: 2.4.3 RC # [1]: v2.4.3-rc1 already exists. Continue anyway [y/n]? y This is a dry run. Please confirm the ref that will be built for testing. Ref [v2.4.3-rc1]: ``` Second, when the tag doesn't exist, we had better ask `confirmation` on the branch name. If we do not change the default value, it will fail eventually. ``` $ dev/create-release/do-release-docker.sh -d /tmp/spark-2.4.4 -n -s docs Branch [branch-2.4]: Current branch version is 2.4.4-SNAPSHOT. Release [2.4.4]: RC # [1]: This is a dry run. Please confirm the ref that will be built for testing. Ref [v2.4.4-rc1]: ``` This PR improves the second case by providing the branch name instead. This helps the release testing before tagging. ## How was this patch tested? Manually do the following and check the default value of `Ref` field. ``` $ dev/create-release/do-release-docker.sh -d /tmp/spark-2.4.4 -n -s docs Branch [branch-2.4]: Current branch version is 2.4.4-SNAPSHOT. Release [2.4.4]: RC # [1]: This is a dry run. Please confirm the ref that will be built for testing. Ref [branch-2.4]: ... ``` Closes #25240 from dongjoon-hyun/SPARK-28496. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> (cherry picked from commit cfca26e97384246f21ecb9d70eb0f7792607fc47) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 24 July 2019, 22:07:58 UTC |
| 73bb605 | Zhu, Lipeng | 19 March 2019, 15:43:23 UTC | [SPARK-27168][SQL][TEST] Add docker integration test for MsSql server ## What changes were proposed in this pull request? This PR aims to add a JDBC integration test for MsSql server. ## How was this patch tested? ``` ./build/mvn clean install -DskipTests ./build/mvn test -Pdocker-integration-tests -pl :spark-docker-integration-tests_2.12 \ -Dtest=none -DwildcardSuites=org.apache.spark.sql.jdbc.MsSqlServerIntegrationSuite ``` Closes #24099 from lipzhu/SPARK-27168. Lead-authored-by: Zhu, Lipeng <lipzhu@ebay.com> Co-authored-by: Dongjoon Hyun <dhyun@apple.com> Co-authored-by: Lipeng Zhu <lipzhu@icloud.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 24 July 2019, 02:13:53 UTC |
| 4336d1c | Zhu, Lipeng | 16 March 2019, 01:21:59 UTC | [SPARK-27159][SQL] update mssql server dialect to support binary type ## What changes were proposed in this pull request? Change the binary type mapping from default blob to varbinary(max) for mssql server. https://docs.microsoft.com/en-us/sql/t-sql/data-types/binary-and-varbinary-transact-sql?view=sql-server-2017  ## How was this patch tested? Unit test. Closes #24091 from lipzhu/SPARK-27159. Authored-by: Zhu, Lipeng <lipzhu@ebay.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> | 24 July 2019, 02:08:01 UTC |
| c01c294 | Dongjoon Hyun | 22 July 2019, 17:45:18 UTC | [SPARK-28468][INFRA][2.4] Upgrade pip to fix `sphinx` install error ## What changes were proposed in this pull request? Spark 2.4.x should be a LTS version and we should use the release script in `branch-2.4` to avoid the previous mistakes. Currently, `do-release-docker.sh` fails at `sphinx` installation to `Python 2.7` at `branch-2.4` only. This PR aims to upgrade `pip` to handle this. ``` $ dev/create-release/do-release-docker.sh -d /tmp/spark-2.4.4 -n ... = Building spark-rm image with tag latest... Command: docker build -t spark-rm:latest --build-arg UID=501 /Users/dhyun/APACHE/spark-2.4/dev/create-release/spark-rm Log file: docker-build.log // Terminated. ``` ``` $ tail /tmp/spark-2.4.4/docker-build.log Collecting sphinx Downloading https://files.pythonhosted.org/packages/89/1e/64c77163706556b647f99d67b42fced9d39ae6b1b86673965a2cd28037b5/Sphinx-2.1.2.tar.gz (6.3MB) Complete output from command python setup.py egg_info: ERROR: Sphinx requires at least Python 3.5 to run. ---------------------------------------- Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-2tylGA/sphinx/ You are using pip version 8.1.1, however version 19.1.1 is available. You should consider upgrading via the 'pip install --upgrade pip' command. ``` The following is the short reproducible step. ``` $ docker build -t spark-rm-test2 --build-arg UID=501 dev/create-release/spark-rm ``` ## How was this patch tested? Manual. ``` $ docker build -t spark-rm-test2 --build-arg UID=501 dev/create-release/spark-rm ``` Closes #25226 from dongjoon-hyun/SPARK-28468. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 22 July 2019, 17:45:18 UTC |
| b26e82f | pengbo | 22 July 2019, 05:12:49 UTC | [SPARK-27416][SQL][BRANCH-2.4] UnsafeMapData & UnsafeArrayData Kryo serialization … This is a Spark 2.4.x backport of #24357 by pengbo. Original description follows below: --- ## What changes were proposed in this pull request? Finish the rest work of https://github.com/apache/spark/pull/24317, https://github.com/apache/spark/pull/9030 a. Implement Kryo serialization for UnsafeArrayData b. fix UnsafeMapData Java/Kryo Serialization issue when two machines have different Oops size c. Move the duplicate code "getBytes()" to Utils. ## How was this patch tested? According Units has been added & tested Closes #25223 from JoshRosen/SPARK-27416-2.4. Authored-by: pengbo <bo.peng1019@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 22 July 2019, 05:12:49 UTC |
| a7e2de8 | Arun Pandian | 21 July 2019, 20:07:22 UTC | [SPARK-28464][DOC][SS] Document Kafka source minPartitions option Adding doc for the kafka source minPartitions option to "Structured Streaming + Kafka Integration Guide" The text is based on the content in https://docs.databricks.com/spark/latest/structured-streaming/kafka.html#configuration Closes #25219 from arunpandianp/SPARK-28464. Authored-by: Arun Pandian <apandian@groupon.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit a0a58cf2effc4f4fb17ef3b1ca3def2d4022c970) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 21 July 2019, 20:23:49 UTC |
| 5b8b9fb | Josh Rosen | 18 July 2019, 20:15:39 UTC | [SPARK-28430][UI] Fix stage table rendering when some tasks' metrics are missing ## What changes were proposed in this pull request? The Spark UI's stages table misrenders the input/output metrics columns when some tasks are missing input metrics. See the screenshot below for an example of the problem:  This is because those columns' are defined as ```scala {if (hasInput(stage)) { metricInfo(task) { m => ... <td>....</td> } } ``` where `metricInfo` renders the node returned by the closure in case metrics are defined or returns `Nil` in case metrics are not defined. If metrics are undefined then we'll fail to render the empty `<td></td>` tag, causing columns to become misaligned as shown in the screenshot. To fix this, this patch changes this to ```scala {if (hasInput(stage)) { <td>{ metricInfo(task) { m => ... Unparsed(...) } }</td> } ``` which is an idiom that's already in use for the shuffle read / write columns. ## How was this patch tested? It isn't. I'm arguing for correctness because the modifications are consistent with rendering methods that work correctly for other columns. Closes #25183 from JoshRosen/joshrosen/fix-task-table-with-partial-io-metrics. Authored-by: Josh Rosen <rosenville@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 3776fbdfdeac07d191f231b29cf906cabdc6de3f) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 18 July 2019, 20:15:54 UTC |
| 76251c3 | HyukjinKwon | 17 July 2019, 09:44:11 UTC | [SPARK-28418][PYTHON][SQL] Wait for event process in 'test_query_execution_listener_on_collect' It fixes a flaky test: ``` ERROR [0.164s]: test_query_execution_listener_on_collect (pyspark.sql.tests.test_dataframe.QueryExecutionListenerTests) ---------------------------------------------------------------------- Traceback (most recent call last): File "/home/jenkins/python/pyspark/sql/tests/test_dataframe.py", line 758, in test_query_execution_listener_on_collect "The callback from the query execution listener should be called after 'collect'") AssertionError: The callback from the query execution listener should be called after 'collect' ``` Seems it can be failed because the event was somehow delayed but checked first. Manually. Closes #25177 from HyukjinKwon/SPARK-28418. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 66179fa8426324e11819e04af4cf3eabf9f2627f) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 17 July 2019, 09:47:16 UTC |
| 198f2f3 | herman | 17 July 2019, 01:01:15 UTC | [SPARK-27485][BRANCH-2.4] EnsureRequirements.reorder should handle duplicate expressions gracefully Backport of 421d9d56efd447d31787e77316ce0eafb5fe45a5 ## What changes were proposed in this pull request? When reordering joins EnsureRequirements only checks if all the join keys are present in the partitioning expression seq. This is problematic when the joins keys and and partitioning expressions both contain duplicates but not the same number of duplicates for each expression, e.g. `Seq(a, a, b)` vs `Seq(a, b, b)`. This fails with an index lookup failure in the `reorder` function. This PR fixes this removing the equality checking logic from the `reorderJoinKeys` function, and by doing the multiset equality in the `reorder` function while building the reordered key sequences. ## How was this patch tested? Added a unit test to the `PlannerSuite` and added an integration test to `JoinSuite` Closes #25174 from hvanhovell/SPARK-27485-2.4. Authored-by: herman <herman@databricks.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 17 July 2019, 01:01:15 UTC |
| 63898cb | gatorsmile | 16 July 2019, 13:57:14 UTC | Revert "[SPARK-27485] EnsureRequirements.reorder should handle duplicate expressions gracefully" This reverts commit 72f547d4a960ba0ba9cace53a0a5553eca1b4dd6. | 16 July 2019, 13:57:14 UTC |
| 3f5a114 | Jungtaek Lim (HeartSaVioR) | 16 July 2019, 13:27:53 UTC | [SPARK-28247][SS][BRANCH-2.4] Fix flaky test "query without test harness" on ContinuousSuite ## What changes were proposed in this pull request? This patch fixes the flaky test "query without test harness" on ContinuousSuite, via adding some more gaps on waiting query to commit the epoch which writes output rows. The observation of this issue is below (injected some debug logs to get them): ``` reader creation time 1562225320210 epoch 1 launched 1562225320593 (+380ms from reader creation time) epoch 13 launched 1562225321702 (+1.5s from reader creation time) partition reader creation time 1562225321715 (+1.5s from reader creation time) next read time for first next call 1562225321210 (+1s from reader creation time) first next called in partition reader 1562225321746 (immediately after creation of partition reader) wait finished in next called in partition reader 1562225321746 (no wait) second next called in partition reader 1562225321747 (immediately after first next()) epoch 0 commit started 1562225321861 writing rows (0, 1) (belong to epoch 13) 1562225321866 (+100ms after first next()) wait start in waitForRateSourceTriggers(2) 1562225322059 next read time for second next call 1562225322210 (+1s from previous "next read time") wait finished in next called in partition reader 1562225322211 (+450ms wait) writing rows (2, 3) (belong to epoch 13) 1562225322211 (immediately after next()) epoch 14 launched 1562225322246 desired wait time in waitForRateSourceTriggers(2) 1562225322510 (+2.3s from reader creation time) epoch 12 committed 1562225323034 ``` These rows were written within desired wait time, but the epoch 13 couldn't be committed within it. Interestingly, epoch 12 was lucky to be committed within a gap between finished waiting in waitForRateSourceTriggers and query.stop() - but even suppose the rows were written in epoch 12, it would be just in luck and epoch should be committed within desired wait time. This patch modifies Rate continuous stream to track the highest committed value, so that test can wait until desired value is reported to the stream as committed. This patch also modifies Rate continuous stream to track the timestamp at stream gets the first committed offset, and let `waitForRateSourceTriggers` use the timestamp. This also relies on waiting for specific period, but safer approach compared to current based on the observation above. Based on the change, this patch saves couple of seconds in test time. ## How was this patch tested? 3 sequential test runs succeeded locally. Closes #25154 from HeartSaVioR/SPARK-28247-branch-2.4. Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> | 16 July 2019, 13:27:53 UTC |
| 72f547d | herman | 16 July 2019, 09:09:52 UTC | [SPARK-27485] EnsureRequirements.reorder should handle duplicate expressions gracefully ## What changes were proposed in this pull request? When reordering joins EnsureRequirements only checks if all the join keys are present in the partitioning expression seq. This is problematic when the joins keys and and partitioning expressions both contain duplicates but not the same number of duplicates for each expression, e.g. `Seq(a, a, b)` vs `Seq(a, b, b)`. This fails with an index lookup failure in the `reorder` function. This PR fixes this removing the equality checking logic from the `reorderJoinKeys` function, and by doing the multiset equality in the `reorder` function while building the reordered key sequences. ## How was this patch tested? Added a unit test to the `PlannerSuite` and added an integration test to `JoinSuite` Closes #25167 from hvanhovell/SPARK-27485. Authored-by: herman <herman@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 16 July 2019, 12:33:38 UTC |
| c9c9eac | Gabor Somogyi | 15 July 2019, 18:01:03 UTC | [SPARK-28404][SS] Fix negative timeout value in RateStreamContinuousPartitionReader ## What changes were proposed in this pull request? `System.currentTimeMillis` read two times in a loop in `RateStreamContinuousPartitionReader`. If the test machine is slow enough and it spends quite some time between the `while` condition check and the `Thread.sleep` then the timeout value is negative and throws `IllegalArgumentException`. In this PR I've fixed this issue. ## How was this patch tested? Existing unit tests. Closes #25162 from gaborgsomogyi/SPARK-28404. Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 8f7ccc5e9c8be723947947c4130a48781bf6e355) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 15 July 2019, 18:01:16 UTC |
| 35d5886 | Liang-Chi Hsieh | 14 July 2019, 06:26:00 UTC | [SPARK-28378][PYTHON] Remove usage of cgi.escape ## What changes were proposed in this pull request? `cgi.escape` is deprecated [1], and removed at 3.8 [2]. We better to replace it. [1] https://docs.python.org/3/library/cgi.html#cgi.escape. [2] https://docs.python.org/3.8/whatsnew/3.8.html#api-and-feature-removals ## How was this patch tested? Existing tests. Closes #25142 from viirya/remove-cgi-escape. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 14 July 2019, 06:28:18 UTC |
| 98aebf4 | Marcelo Vanzin | 13 July 2019, 18:38:54 UTC | [SPARK-28371][SQL] Make Parquet "StartsWith" filter null-safe Parquet may call the filter with a null value to check whether nulls are accepted. While it seems Spark avoids that path in Parquet with 1.10, in 1.11 that causes Spark unit tests to fail. Tested with Parquet 1.11 (and new unit test). Closes #25140 from vanzin/SPARK-28371. Authored-by: Marcelo Vanzin <vanzin@cloudera.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 7f9da2b7f8a2331ce403cd7afecfd874f8049c04) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 13 July 2019, 18:39:25 UTC |
| 1a6a67f | gatorsmile | 12 July 2019, 23:06:44 UTC | [SPARK-28361][SQL][TEST] Test equality of generated code with id in class name A code gen test in WholeStageCodeGenSuite was flaky because it used the codegen metrics class to test if the generated code for equivalent plans was identical under a particular flag. This patch switches the test to compare the generated code directly. N/A Closes #25131 from gatorsmile/WholeStageCodegenSuite. Authored-by: gatorsmile <gatorsmile@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 60b89cf8097ff583a29a6a19f1db4afa780f3109) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 12 July 2019, 23:22:02 UTC |
| 094a20c | Dongjoon Hyun | 12 July 2019, 09:40:07 UTC | [SPARK-28357][CORE][TEST] Fix Flaky Test - FileAppenderSuite.rollingfile appender - size-based rolling compressed ## What changes were proposed in this pull request? `SizeBasedRollingPolicy.shouldRollover` returns false when the size is equal to `rolloverSizeBytes`. ```scala /** Should rollover if the next set of bytes is going to exceed the size limit */ def shouldRollover(bytesToBeWritten: Long): Boolean = { logDebug(s"$bytesToBeWritten + $bytesWrittenSinceRollover > $rolloverSizeBytes") bytesToBeWritten + bytesWrittenSinceRollover > rolloverSizeBytes } ``` - https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/107553/testReport/org.apache.spark.util/FileAppenderSuite/rolling_file_appender___size_based_rolling__compressed_/ ``` org.scalatest.exceptions.TestFailedException: 1000 was not less than 1000 ``` ## How was this patch tested? Pass the Jenkins with the updated test. Closes #25125 from dongjoon-hyun/SPARK-28357. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 1c29212394adcbde2de4f4dfdc43a1cf32671ae1) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 12 July 2019, 09:40:25 UTC |
| 17974e2 | Maxim Gekk | 11 July 2019, 01:12:03 UTC | [SPARK-28015][SQL] Check stringToDate() consumes entire input for the yyyy and yyyy-[m]m formats Fix `stringToDate()` for the formats `yyyy` and `yyyy-[m]m` that assumes there are no additional chars after the last components `yyyy` and `[m]m`. In the PR, I propose to check that entire input was consumed for the formats. After the fix, the input `1999 08 01` will be invalid because it matches to the pattern `yyyy` but the strings contains additional chars ` 08 01`. Since Spark 1.6.3 ~ 2.4.3, the behavior is the same. ``` spark-sql> SELECT CAST('1999 08 01' AS DATE); 1999-01-01 ``` This PR makes it return NULL like Hive. ``` spark-sql> SELECT CAST('1999 08 01' AS DATE); NULL ``` Added new checks to `DateTimeUtilsSuite` for the `1999 08 01` and `1999 08` inputs. Closes #25097 from MaxGekk/spark-28015-invalid-date-format. Authored-by: Maxim Gekk <maxim.gekk@databricks.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 11 July 2019, 02:50:29 UTC |
| 1abac14 | Gabor Somogyi | 10 July 2019, 16:35:39 UTC | [SPARK-28335][DSTREAMS][TEST] DirectKafkaStreamSuite wait for Kafka async commit `DirectKafkaStreamSuite.offset recovery from kafka` commits offsets to Kafka with `Consumer.commitAsync` API (and then reads it back). Since this API is asynchronous it may send notifications late(or not at all). The actual test makes the assumption if the data sent and collected then the offset must be committed as well. This is not true. In this PR I've made the following modifications: * Wait for async offset commit before context stopped * Added commit succeed log to see whether it arrived at all * Using `ConcurrentHashMap` for committed offsets because 2 threads are using the variable (`JobGenerator` and `ScalaTest...`) Existing unit test in a loop + jenkins runs. Closes #25100 from gaborgsomogyi/SPARK-28335. Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 579edf472822802285b5cd7d07f63503015eff5a) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 10 July 2019, 16:36:55 UTC |
| 55f92a3 | wuyi | 09 July 2019, 06:49:31 UTC | [SPARK-28302][CORE] Make sure to generate unique output file for SparkLauncher on Windows ## What changes were proposed in this pull request? When using SparkLauncher to submit applications **concurrently** with multiple threads under **Windows**, some apps would show that "The process cannot access the file because it is being used by another process" and remains in LOST state at the end. The issue can be reproduced by this [demo](https://issues.apache.org/jira/secure/attachment/12973920/Main.scala). After digging into the code, I find that, Windows cmd `%RANDOM%` would return the same number if we call it instantly(e.g. < 500ms) after last call. As a result, SparkLauncher would get same output file(spark-class-launcher-output-%RANDOM%.txt) for apps. Then, the following app would hit the issue when it tries to write the same file which has already been opened for writing by another app. We should make sure to generate unique output file for SparkLauncher on Windows to avoid this issue. ## How was this patch tested? Tested manually on Windows. Closes #25076 from Ngone51/SPARK-28302. Authored-by: wuyi <ngone_5451@163.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 925f620570a022ff8229bfde076e7dde6bf242df) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 09 July 2019, 06:50:38 UTC |
| 072e0eb | Dongjoon Hyun | 09 July 2019, 02:40:41 UTC | [SPARK-28308][CORE] CalendarInterval sub-second part should be padded before parsing The sub-second part of the interval should be padded before parsing. Currently, Spark gives a correct value only when there is 9 digits below `.`. ``` spark-sql> select interval '0 0:0:0.123456789' day to second; interval 123 milliseconds 456 microseconds spark-sql> select interval '0 0:0:0.12345678' day to second; interval 12 milliseconds 345 microseconds spark-sql> select interval '0 0:0:0.1234' day to second; interval 1 microseconds ``` Pass the Jenkins with the fixed test cases. Closes #25079 from dongjoon-hyun/SPARK-28308. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit a5ff9221fc23cc758db228493d451f542591eff7) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 09 July 2019, 02:42:47 UTC |
| 19487cb | Gabor Somogyi | 08 July 2019, 18:10:03 UTC | [SPARK-28261][CORE] Fix client reuse test There is the following code in [TransportClientFactory#createClient](https://github.com/apache/spark/blob/master/common/network-common/src/main/java/org/apache/spark/network/client/TransportClientFactory.java#L150) ``` int clientIndex = rand.nextInt(numConnectionsPerPeer); TransportClient cachedClient = clientPool.clients[clientIndex]; ``` which choose a client from its pool randomly. If we are unlucky we might not get the max number of connections out, but less than that. To prove that I've tried out the following test: ```java Test public void testRandom() { Random rand = new Random(); Set<Integer> clients = Collections.synchronizedSet(new HashSet<>()); long iterCounter = 0; while (true) { iterCounter++; int maxConnections = 4; clients.clear(); for (int i = 0; i < maxConnections * 10; i++) { int clientIndex = rand.nextInt(maxConnections); clients.add(clientIndex); } if (clients.size() != maxConnections) { System.err.println("Unexpected clients size (iterCounter=" + iterCounter + "): " + clients.size() + ", maxConnections: " + maxConnections); } if (iterCounter % 100000 == 0) { System.out.println("IterCounter: " + iterCounter); } } } ``` Result: ``` Unexpected clients size (iterCounter=22388): 3, maxConnections: 4 Unexpected clients size (iterCounter=36244): 3, maxConnections: 4 Unexpected clients size (iterCounter=85798): 3, maxConnections: 4 IterCounter: 100000 Unexpected clients size (iterCounter=97108): 3, maxConnections: 4 Unexpected clients size (iterCounter=119121): 3, maxConnections: 4 Unexpected clients size (iterCounter=129948): 3, maxConnections: 4 Unexpected clients size (iterCounter=173736): 3, maxConnections: 4 Unexpected clients size (iterCounter=178138): 3, maxConnections: 4 Unexpected clients size (iterCounter=195108): 3, maxConnections: 4 IterCounter: 200000 Unexpected clients size (iterCounter=209006): 3, maxConnections: 4 Unexpected clients size (iterCounter=217105): 3, maxConnections: 4 Unexpected clients size (iterCounter=222456): 3, maxConnections: 4 Unexpected clients size (iterCounter=226899): 3, maxConnections: 4 Unexpected clients size (iterCounter=229101): 3, maxConnections: 4 Unexpected clients size (iterCounter=253549): 3, maxConnections: 4 Unexpected clients size (iterCounter=277550): 3, maxConnections: 4 Unexpected clients size (iterCounter=289637): 3, maxConnections: 4 ... ``` In this PR I've adapted the test code not to have this flakyness. Additional (not committed test) + existing unit tests in a loop. Closes #25075 from gaborgsomogyi/SPARK-28261. Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit e11a55827e7475aab77e8a4ea0baed7c14059908) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 08 July 2019, 18:11:37 UTC |
| ec6d0c9 | Gabor Somogyi | 03 July 2019, 16:34:31 UTC | [MINOR] Add requestHeaderSize debug log ## What changes were proposed in this pull request? `requestHeaderSize` is added in https://github.com/apache/spark/pull/23090 and applies to Spark + History server UI as well. Without debug log it's hard to find out on which side what configuration is used. In this PR I've added a log message which prints out the value. ## How was this patch tested? Manually checked log files. Closes #25045 from gaborgsomogyi/SPARK-26118. Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 0b6c2c259c1ed109a824b678c9ccbd9fd767d2fe) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 03 July 2019, 16:34:45 UTC |
| d57b392 | Marco Gaido | 01 July 2019, 02:40:12 UTC | [SPARK-28170][ML][PYTHON] Uniform Vectors and Matrix documentation ## What changes were proposed in this pull request? The documentation in `linalg.py` is not consistent. This PR uniforms the documentation. ## How was this patch tested? NA Closes #25011 from mgaido91/SPARK-28170. Authored-by: Marco Gaido <marcogaido91@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 048224ce9a3bdb304ba24852ecc66c7f14c25c11) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 01 July 2019, 02:40:35 UTC |
| 9f9bf13 | LantaoJin | 30 June 2019, 20:14:41 UTC | [SPARK-28160][CORE] Fix a bug that callback function may hang when unchecked exception missed This is very like #23590 . `ByteBuffer.allocate` may throw `OutOfMemoryError` when the response is large but no enough memory is available. However, when this happens, `TransportClient.sendRpcSync` will just hang forever if the timeout set to unlimited. This PR catches `Throwable` and uses the error to complete `SettableFuture`. I tested in my IDE by setting the value of size to -1 to verify the result. Without this patch, it won't be finished until timeout (May hang forever if timeout set to MAX_INT), or the expected `IllegalArgumentException` will be caught. ```java Override public void onSuccess(ByteBuffer response) { try { int size = response.remaining(); ByteBuffer copy = ByteBuffer.allocate(size); // set size to -1 in runtime when debug copy.put(response); // flip "copy" to make it readable copy.flip(); result.set(copy); } catch (Throwable t) { result.setException(t); } } ``` Closes #24964 from LantaoJin/SPARK-28160. Lead-authored-by: LantaoJin <jinlantao@gmail.com> Co-authored-by: lajin <lajin@ebay.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> (cherry picked from commit 0e421000e0ea2c090b6fab0201a6046afceec132) Signed-off-by: Sean Owen <sean.owen@databricks.com> | 30 June 2019, 20:18:11 UTC |
| b477194 | Dongjoon Hyun | 27 June 2019, 16:57:44 UTC | [SPARK-28157][CORE][2.4] Make SHS clear KVStore `LogInfo`s for the blacklisted entries ## What changes were proposed in this pull request? At Spark 2.4.0/2.3.2/2.2.3, [SPARK-24948](https://issues.apache.org/jira/browse/SPARK-24948) delegated access permission checks to the file system, and maintains a blacklist for all event log files failed once at reading. The blacklisted log files are released back after `CLEAN_INTERVAL_S` seconds. However, the released files whose sizes don't changes are ignored forever due to `info.fileSize < entry.getLen()` condition (previously [here](https://github.com/apache/spark/commit/3c96937c7b1d7a010b630f4b98fd22dafc37808b#diff-a7befb99e7bd7e3ab5c46c2568aa5b3eR454) and now at [shouldReloadLog](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L571)) which returns `false` always when the size is the same with the existing value in `KVStore`. This is recovered only via SHS restart. This PR aims to remove the existing entry from `KVStore` when it goes to the blacklist. ## How was this patch tested? Pass the Jenkins with the updated test case. Closes #24975 from dongjoon-hyun/SPARK-28157-2.4. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: DB Tsai <d_tsai@apple.com> | 27 June 2019, 16:57:44 UTC |
| eb66d3b | shivusondur | 26 June 2019, 17:42:33 UTC | [SPARK-28164] Fix usage description of `start-slave.sh` ## What changes were proposed in this pull request? updated the usage message in sbin/start-slave.sh. <masterURL> argument moved to first ## How was this patch tested? tested locally with Starting master starting slave with (./start-slave.sh spark://<IP>:<PORT> -c 1 and opening spark shell with ./spark-shell --master spark://<IP>:<PORT> Closes #24974 from shivusondur/jira28164. Authored-by: shivusondur <shivusondur@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> (cherry picked from commit bd232b98b470a609472a4ea8df912f8fad06ba06) Signed-off-by: Sean Owen <sean.owen@databricks.com> | 26 June 2019, 17:43:02 UTC |
| 680c1b6 | Parth Chandra | 26 June 2019, 07:48:27 UTC | [SPARK-27100][SQL][2.4] Use `Array` instead of `Seq` in `FilePartition` to prevent StackOverflowError … prevent `StackOverflowError ` ShuffleMapTask's partition field is a FilePartition and FilePartition's 'files' field is a Stream$cons which is essentially a linked list. It is therefore serialized recursively. If the number of files in each partition is, say, 10000 files, recursing into a linked list of length 10000 overflows the stack The problem is only in Bucketed partitions. The corresponding implementation for non Bucketed partitions uses a StreamBuffer. The proposed change applies the same for Bucketed partitions. Existing unit tests. Added new unit test. The unit test fails without the patch. Manual testing on dataset used to reproduce the problem. Closes #24957 from parthchandra/branch-2.4. Authored-by: Parth Chandra <parthc@apple.com> Signed-off-by: DB Tsai <d_tsai@apple.com> | 26 June 2019, 07:48:27 UTC |
| eb97f95 | zhengruifeng | 25 June 2019, 11:50:34 UTC | [SPARK-28154][ML][FOLLOWUP] GMM fix double caching if the input dataset is alreadly cached, then we do not need to cache the internal rdd (like kmeans) existing test Closes #24919 from zhengruifeng/gmm_fix_double_caching. Authored-by: zhengruifeng <ruifengz@foxmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> (cherry picked from commit c83b3ddb56d4a32158676b042a7eae861689e141) Signed-off-by: Sean Owen <sean.owen@databricks.com> | 25 June 2019, 12:01:16 UTC |
| e5cc11d | Yuming Wang | 24 June 2019, 16:04:34 UTC | Revert "[SPARK-28093][SPARK-28109][SQL][2.4] Fix TRIM/LTRIM/RTRIM function parameter order issue" ## What changes were proposed in this pull request? This reverts commit 4990be9. The parameter orders might be different in different vendors. We can change it in 3.x to make it more consistent with the other vendors. However, it could break the existing customers' workloads if they already use `trim`. ## How was this patch tested? N/A Closes #24943 from wangyum/SPARK-28093-REVERT-2.4. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 24 June 2019, 16:04:34 UTC |
| d1a3e4d | zhengruifeng | 24 June 2019, 14:34:01 UTC | [SPARK-27018][CORE] Fix incorrect removal of checkpointed file in PeriodicCheckpointer ## What changes were proposed in this pull request? remove the oldest checkpointed file only if next checkpoint exists. I think this patch needs back-porting. ## How was this patch tested? existing test local check in spark-shell with following suite: ``` import org.apache.spark.ml.linalg.Vectors import org.apache.spark.ml.classification.GBTClassifier case class Row(features: org.apache.spark.ml.linalg.Vector, label: Int) sc.setCheckpointDir("/checkpoints") val trainingData = sc.parallelize(1 to 2426874, 256).map(x => Row(Vectors.dense(x, x + 1, x * 2 % 10), if (x % 5 == 0) 1 else 0)).toDF val classifier = new GBTClassifier() .setLabelCol("label") .setFeaturesCol("features") .setProbabilityCol("probability") .setMaxIter(100) .setMaxDepth(10) .setCheckpointInterval(2) classifier.fit(trainingData) ``` Closes #24870 from zhengruifeng/ck_update. Authored-by: zhengruifeng <ruifengz@foxmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> (cherry picked from commit 6064368415636e8668d8db835a218872f6846d98) Signed-off-by: Sean Owen <sean.owen@databricks.com> | 24 June 2019, 14:34:33 UTC |
| a71e90a | Juliusz Sompolski | 21 June 2019, 14:56:49 UTC | [SPARK-26038][BRANCH-2.4] Decimal toScalaBigInt/toJavaBigInteger for decimals not fitting in long This is a Spark 2.4.x backport of #23022. Original description follows below: ## What changes were proposed in this pull request? Fix Decimal `toScalaBigInt` and `toJavaBigInteger` used to only work for decimals not fitting long. ## How was this patch tested? Added test to DecimalSuite. Closes #24928 from JoshRosen/joshrosen/SPARK-26038-backport. Authored-by: Juliusz Sompolski <julek@databricks.com> Signed-off-by: Josh Rosen <rosenville@gmail.com> | 21 June 2019, 14:56:49 UTC |
| 4990be9 | Yuming Wang | 20 June 2019, 19:49:05 UTC | [SPARK-28093][SPARK-28109][SQL][2.4] Fix TRIM/LTRIM/RTRIM function parameter order issue ## What changes were proposed in this pull request? This pr backport #24902 and #24911 to branch-2.4. ## How was this patch tested? unit tests Closes #24907 from wangyum/SPARK-28093-branch-2.4. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 20 June 2019, 19:49:05 UTC |
| f9105c0 | tools4origins | 20 June 2019, 15:10:19 UTC | [MINOR][DOC] Fix python variance() documentation ## What changes were proposed in this pull request? The Python documentation incorrectly says that `variance()` acts as `var_pop` whereas it acts like `var_samp` here: https://spark.apache.org/docs/latest/api/python/pyspark.sql.html#pyspark.sql.functions.variance It was not the case in Spark 1.6 doc but it is in Spark 2.0 doc: https://spark.apache.org/docs/1.6.0/api/java/org/apache/spark/sql/functions.html https://spark.apache.org/docs/2.0.0/api/java/org/apache/spark/sql/functions.html The Scala documentation is correct: https://spark.apache.org/docs/latest/api/java/org/apache/spark/sql/functions.html#variance-org.apache.spark.sql.Column- The alias is set on this line: https://github.com/apache/spark/blob/v2.4.3/sql/core/src/main/scala/org/apache/spark/sql/functions.scala#L786 ## How was this patch tested? Using variance() in pyspark 2.4.3 returns: ``` >>> spark.createDataFrame([(1, ), (2, ), (3, )], "a: int").select(variance("a")).show() +-----------+ |var_samp(a)| +-----------+ | 1.0| +-----------+ ``` Closes #24895 from tools4origins/patch-1. Authored-by: tools4origins <tools4origins@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 25c5d5788311ba74f4aac2f97054b4e9ef7e295c) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 20 June 2019, 15:11:50 UTC |
| ba7f61e | mwlon | 20 June 2019, 02:03:35 UTC | [SPARK-26555][SQL][BRANCH-2.4] make ScalaReflection subtype checking thread safe This is a Spark 2.4.x backport of #24085. Original description follows below: ## What changes were proposed in this pull request? Make ScalaReflection subtype checking thread safe by adding a lock. There is a thread safety bug in the <:< operator in all versions of scala (https://github.com/scala/bug/issues/10766). ## How was this patch tested? Existing tests and a new one for the new subtype checking function. Closes #24913 from JoshRosen/joshrosen/SPARK-26555-branch-2.4-backport. Authored-by: mwlon <mloncaric@hmc.edu> Signed-off-by: Josh Rosen <rosenville@gmail.com> | 20 June 2019, 02:03:35 UTC |
| e4f5d84 | Sean Owen | 19 June 2019, 01:27:43 UTC | [SPARK-28081][ML] Handle large vocab counts in word2vec ## What changes were proposed in this pull request? The word2vec logic fails if a corpora has a word with count > 1e9. We should be able to handle very large counts generally better here by using longs to count. This takes over https://github.com/apache/spark/pull/24814 ## How was this patch tested? Existing tests. Closes #24893 from srowen/SPARK-28081. Authored-by: Sean Owen <sean.owen@databricks.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> (cherry picked from commit e96dd82f12f2b6d93860e23f4f98a86c3faf57c5) Signed-off-by: Sean Owen <sean.owen@databricks.com> | 19 June 2019, 01:28:22 UTC |
| f4efcbf | Liang-Chi Hsieh | 18 June 2019, 04:48:32 UTC | [SPARK-28058][DOC] Add a note to doc of mode of CSV for column pruning ## What changes were proposed in this pull request? When using `DROPMALFORMED` mode, corrupted records aren't dropped if malformed columns aren't read. This behavior is due to CSV parser column pruning. Current doc of `DROPMALFORMED` doesn't mention the effect of column pruning. Users will be confused by the fact that `DROPMALFORMED` mode doesn't work as expected. Column pruning also affects other modes. This is a doc improvement to add a note to doc of `mode` to explain it. ## How was this patch tested? N/A. This is just doc change. Closes #24894 from viirya/SPARK-28058. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit b7bdc3111ec2778d7d54d09ba339d893250aa65d) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 18 June 2019, 04:48:51 UTC |
| 9ddb6b5 | Mellacheruvu Sandeep | 17 June 2019, 05:54:08 UTC | [SPARK-24898][DOC] Adding spark.checkpoint.compress to the docs ## What changes were proposed in this pull request? Adding spark.checkpoint.compress configuration parameter to the documentation  ## How was this patch tested? Checked locally for jeykyll html docs. Also validated the html for any issues. Closes #24883 from sandeepvja/SPARK-24898. Authored-by: Mellacheruvu Sandeep <mellacheruvu.sandeep@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit b7b445255370e29d6b420b02389b022a1c65942e) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 17 June 2019, 05:54:21 UTC |
| f94410e | Sean Owen | 14 June 2019, 17:44:43 UTC | [SPARK-21882][CORE] OutputMetrics doesn't count written bytes correctly in the saveAsHadoopDataset function ## What changes were proposed in this pull request? (Continuation of https://github.com/apache/spark/pull/19118 ; see for details) ## How was this patch tested? Existing tests. Closes #24863 from srowen/SPARK-21882.2. Authored-by: Sean Owen <sean.owen@databricks.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> (cherry picked from commit b508eab9858b94f14b29e023812448e3d0c97712) Signed-off-by: Sean Owen <sean.owen@databricks.com> | 14 June 2019, 17:45:16 UTC |
| 29a39e8 | Liang-Chi Hsieh | 13 June 2019, 02:04:41 UTC | [SPARK-28031][PYSPARK][TEST] Improve doctest on over function of Column ## What changes were proposed in this pull request? Just found the doctest on `over` function of `Column` is commented out. The window spec is also not for the window function used there. We should either remove the doctest, or improve it. Because other functions of `Column` have doctest generally, so this PR tries to improve it. ## How was this patch tested? Added doctest. Closes #24854 from viirya/column-test-minor. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit ddf4a5031287c0c26ea462dd89ea99d769473213) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 13 June 2019, 02:04:59 UTC |
| c961e7c | sandeep katta | 11 June 2019, 14:14:24 UTC | [SPARK-27917][SQL][BACKPORT-2.4] canonical form of CaseWhen object is incorrect ## What changes were proposed in this pull request? For caseWhen Object canonicalized is not handled for e.g let's consider below CaseWhen Object val attrRef = AttributeReference("ACCESS_CHECK", StringType)() val caseWhenObj1 = CaseWhen(Seq((attrRef, Literal("A")))) caseWhenObj1.canonicalized **ouput** is as below CASE WHEN ACCESS_CHECK#0 THEN A END (**Before Fix)** **After Fix** : CASE WHEN none#0 THEN A END So when there will be aliasref like below statements, semantic equals will fail. Sematic equals returns true if the canonicalized form of both the expressions are same. val attrRef = AttributeReference("ACCESS_CHECK", StringType)() val aliasAttrRef = attrRef.withName("access_check") val caseWhenObj1 = CaseWhen(Seq((attrRef, Literal("A")))) val caseWhenObj2 = CaseWhen(Seq((aliasAttrRef, Literal("A")))) **assert(caseWhenObj2.semanticEquals(caseWhenObj1.semanticEquals) fails** **caseWhenObj1.canonicalized** Before Fix:CASE WHEN ACCESS_CHECK#0 THEN A END After Fix: CASE WHEN none#0 THEN A END **caseWhenObj2.canonicalized** Before Fix:CASE WHEN access_check#0 THEN A END After Fix: CASE WHEN none#0 THEN A END ## How was this patch tested? Added UT Closes #24836 from sandeep-katta/spark2.4. Authored-by: sandeep katta <sandeep.katta2007@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 11 June 2019, 14:14:24 UTC |
| 89ca658 | Yuexin Zhang | 07 June 2019, 13:02:02 UTC | [SPARK-27973][MINOR] [EXAMPLES]correct DirectKafkaWordCount usage text with groupId ## What changes were proposed in this pull request? Usage: DirectKafkaWordCount <brokers> <topics> -- <brokers> is a list of one or more Kafka brokers <groupId> is a consumer group name to consume from topics <topics> is a list of one or more kafka topics to consume from ## How was this patch tested? N/A. Please review https://spark.apache.org/contributing.html before opening a pull request. Closes #24819 from cnZach/minor_DirectKafkaWordCount_UsageWithGroupId. Authored-by: Yuexin Zhang <zach.yx.zhang@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> | 08 June 2019, 20:34:44 UTC |
| ad23006 | Liang-Chi Hsieh | 08 June 2019, 07:10:37 UTC | [SPARK-27798][SQL][BRANCH-2.4] from_avro shouldn't produces same value when converted to local relation ## What changes were proposed in this pull request? When using `from_avro` to deserialize avro data to catalyst StructType format, if `ConvertToLocalRelation` is applied at the time, `from_avro` produces only the last value (overriding previous values). The cause is `AvroDeserializer` reuses output row for StructType. Normally, it should be fine in Spark SQL. But `ConvertToLocalRelation` just uses `InterpretedProjection` to project local rows. `InterpretedProjection` creates new row for each output thro, it includes the same nested row object from `AvroDeserializer`. By the end, converted local relation has only last value. This is to backport the fix to branch 2.4 and uses `InterpretedMutableProjection` in `ConvertToLocalRelation` and call `copy()` on output rows. ## How was this patch tested? Added test. Closes #24822 from viirya/SPARK-27798-2.4. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 08 June 2019, 07:10:37 UTC |
| 1a86eb3 | Jordan Sanders | 05 June 2019, 21:57:36 UTC | [MINOR][SQL] Skip warning if JOB_SUMMARY_LEVEL is set to NONE ## What changes were proposed in this pull request? I believe the log message: `Committer $committerClass is not a ParquetOutputCommitter and cannot create job summaries. Set Parquet option ${ParquetOutputFormat.JOB_SUMMARY_LEVEL} to NONE.` is at odds with the `if` statement that logs the warning. Despite the instructions in the warning, users still encounter the warning if `JOB_SUMMARY_LEVEL` is already set to `NONE`. This pull request introduces a change to skip logging the warning if `JOB_SUMMARY_LEVEL` is set to `NONE`. ## How was this patch tested? I built to make sure everything still compiled and I ran the existing test suite. I didn't feel it was worth the overhead to add a test to make sure a log message does not get logged, but if reviewers feel differently, I can add one. Closes #24808 from jmsanders/master. Authored-by: Jordan Sanders <jmsanders@users.noreply.github.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 05 June 2019, 21:58:19 UTC |
| 9d307dd | Jules Damji | 04 June 2019, 23:17:53 UTC | [MINOR][DOC] Avro data source documentation change This is a minor documentation change whereby the https://spark.apache.org/docs/latest/sql-data-sources-avro.html mentions "The date type and naming of record fields should match the input Avro data or Catalyst data," The term Catalyst data is confusing. It should instead say, Spark's internal data type such as String Type or IntegerType. (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) There are no code changes; only doc changes. Please review https://spark.apache.org/contributing.html before opening a pull request. Closes #24787 from dmatrix/br-orc-ds.doc.changes. Authored-by: Jules Damji <dmatrix@comcast.net> Signed-off-by: gatorsmile <gatorsmile@gmail.com> (cherry picked from commit b71abd654de2886ff2b44cada81ea909a0712f7c) Signed-off-by: gatorsmile <gatorsmile@gmail.com> | 04 June 2019, 23:19:39 UTC |
| 880cb7b | Liang-Chi Hsieh | 04 June 2019, 07:27:44 UTC | [SPARK-27873][SQL][BRANCH-2.4] columnNameOfCorruptRecord should not be checked with column names in CSV header when disabling enforceSchema ## What changes were proposed in this pull request? If we want to keep corrupt record when reading CSV, we provide a new column into the schema, that is `columnNameOfCorruptRecord`. But this new column isn't actually a column in CSV header. So if `enforceSchema` is disabled, `CSVHeaderChecker` throws a exception complaining that number of column in CSV header isn't equal to that in the schema. This backports the fix into branch-2.4. ## How was this patch tested? Added test. Closes #24771 from viirya/SPARK-27873-2.4. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 04 June 2019, 07:27:44 UTC |
| 6715135 | HyukjinKwon | 03 June 2019, 14:58:35 UTC | [MINOR][BRANCH-2.4] Avoid hardcoded py4j-0.10.7-src.zip in Scala ## What changes were proposed in this pull request? This PR targets to deduplicate hardcoded `py4j-0.10.7-src.zip` in order to make py4j upgrade easier. ## How was this patch tested? N/A Closes #24772 from HyukjinKwon/backport-minor-py4j. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 03 June 2019, 14:58:35 UTC |
| 6baed83 | Ajith | 02 June 2019, 17:54:21 UTC | [SPARK-27907][SQL] HiveUDAF should return NULL in case of 0 rows ## What changes were proposed in this pull request? When query returns zero rows, the HiveUDAFFunction throws NPE ## CASE 1: create table abc(a int) select histogram_numeric(a,2) from abc // NPE ``` Job aborted due to stage failure: Task 0 in stage 1.0 failed 1 times, most recent failure: Lost task 0.0 in stage 1.0 (TID 0, localhost, executor driver): java.lang.NullPointerException at org.apache.spark.sql.hive.HiveUDAFFunction.eval(hiveUDFs.scala:471) at org.apache.spark.sql.hive.HiveUDAFFunction.eval(hiveUDFs.scala:315) at org.apache.spark.sql.catalyst.expressions.aggregate.TypedImperativeAggregate.eval(interfaces.scala:543) at org.apache.spark.sql.execution.aggregate.AggregationIterator.$anonfun$generateResultProjection$5(AggregationIterator.scala:231) at org.apache.spark.sql.execution.aggregate.ObjectAggregationIterator.outputForEmptyGroupingKeyWithoutInput(ObjectAggregationIterator.scala:97) at org.apache.spark.sql.execution.aggregate.ObjectHashAggregateExec.$anonfun$doExecute$2(ObjectHashAggregateExec.scala:132) at org.apache.spark.sql.execution.aggregate.ObjectHashAggregateExec.$anonfun$doExecute$2$adapted(ObjectHashAggregateExec.scala:107) at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsWithIndexInternal$2(RDD.scala:839) at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsWithIndexInternal$2$adapted(RDD.scala:839) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:327) at org.apache.spark.rdd.RDD.iterator(RDD.scala:291) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:327) at org.apache.spark.rdd.RDD.iterator(RDD.scala:291) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:327) at org.apache.spark.rdd.RDD.iterator(RDD.scala:291) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90) at org.apache.spark.scheduler.Task.run(Task.scala:122) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:425) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1350) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:428) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) ``` ## CASE 2: create table abc(a int) insert into abc values (1) select histogram_numeric(a,2) from abc where a=3 // NPE ``` Job aborted due to stage failure: Task 0 in stage 4.0 failed 1 times, most recent failure: Lost task 0.0 in stage 4.0 (TID 5, localhost, executor driver): java.lang.NullPointerException at org.apache.spark.sql.hive.HiveUDAFFunction.serialize(hiveUDFs.scala:477) at org.apache.spark.sql.hive.HiveUDAFFunction.serialize(hiveUDFs.scala:315) at org.apache.spark.sql.catalyst.expressions.aggregate.TypedImperativeAggregate.serializeAggregateBufferInPlace(interfaces.scala:570) at org.apache.spark.sql.execution.aggregate.AggregationIterator.$anonfun$generateResultProjection$6(AggregationIterator.scala:254) at org.apache.spark.sql.execution.aggregate.ObjectAggregationIterator.outputForEmptyGroupingKeyWithoutInput(ObjectAggregationIterator.scala:97) at org.apache.spark.sql.execution.aggregate.ObjectHashAggregateExec.$anonfun$doExecute$2(ObjectHashAggregateExec.scala:132) at org.apache.spark.sql.execution.aggregate.ObjectHashAggregateExec.$anonfun$doExecute$2$adapted(ObjectHashAggregateExec.scala:107) at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsWithIndexInternal$2(RDD.scala:839) at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsWithIndexInternal$2$adapted(RDD.scala:839) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:327) at org.apache.spark.rdd.RDD.iterator(RDD.scala:291) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:327) at org.apache.spark.rdd.RDD.iterator(RDD.scala:291) at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:94) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52) at org.apache.spark.scheduler.Task.run(Task.scala:122) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:425) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1350) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:428) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) ``` Hence add a check not avoid NPE ## How was this patch tested? Added new UT case Closes #24762 from ajithme/hiveudaf. Authored-by: Ajith <ajith2489@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 3806887afb36266aee8749ac95ea0e9016fbf6ff) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 02 June 2019, 17:54:42 UTC |
| ee46b0f | Dongjoon Hyun | 01 June 2019, 05:37:52 UTC | Revert "[SPARK-27896][ML] Fix definition of clustering silhouette coefficient for 1-element clusters" This reverts commit 16f2ceb0cb8407023e7bd14575221b0a718e50de. | 01 June 2019, 05:37:52 UTC |
| 16f2ceb | Sean Owen | 31 May 2019, 23:27:20 UTC | [SPARK-27896][ML] Fix definition of clustering silhouette coefficient for 1-element clusters ## What changes were proposed in this pull request? Single-point clusters should have silhouette score of 0, according to the original paper and scikit implementation. ## How was this patch tested? Existing test suite + new test case. Closes #24756 from srowen/SPARK-27896. Authored-by: Sean Owen <sean.owen@databricks.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit aec0869fb2ae1ace93056ee1f9ea50b1bdbae9ad) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 31 May 2019, 23:27:35 UTC |
| f41ba2a | Sean Owen | 31 May 2019, 22:50:13 UTC | [SPARK-27794][R][DOCS][BACKPORT] Use https URL for CRAN repo ## What changes were proposed in this pull request? Use https URL for CRAN repo (and for a Scala download in a Dockerfile) Backport of https://github.com/apache/spark/pull/24664 ## How was this patch tested? Existing tests Closes #24758 from srowen/SPARK-27794.2. Authored-by: Sean Owen <sean.owen@databricks.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 31 May 2019, 22:50:13 UTC |
| 2adf548 | mwlon | 31 May 2019, 15:09:47 UTC | [SPARK-26192][MESOS][2.4] Retrieve enableFetcherCache option from submission for driver URIs ## What changes were proposed in this pull request? Retrieve enableFetcherCache option from submission conf rather than dispatcher conf. This resolves some confusing behavior where Spark drivers currently get this conf from the dispatcher, whereas Spark executors get this conf from the submission. After this change, the conf will only need to be specified once. ## How was this patch tested? With (updated) existing tests. Closes #24750 from mwlon/SPARK-26192-min-2.4. Authored-by: mwlon <mloncaric@hmc.edu> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 31 May 2019, 15:09:47 UTC |
| 84bd808 | Marcelo Vanzin | 29 May 2019, 21:56:36 UTC | [SPARK-27868][CORE] Better default value and documentation for socket server backlog. First, there is currently no public documentation for this setting. So it's hard to even know that it could be a problem if your application starts failing with weird shuffle errors. Second, the javadoc attached to the code was incorrect; the default value just uses the default value from the JRE, which is 50, instead of having an unbounded queue as the comment implies. So use a default that is a "rounded" version of the JRE default, and provide documentation explaining that this value may need to be adjusted. Also added a log message that was very helpful in debugging an issue caused by this problem. Closes #24732 from vanzin/SPARK-27868. Authored-by: Marcelo Vanzin <vanzin@cloudera.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 09ed64d795d3199a94e175273fff6fcea6b52131) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 29 May 2019, 21:57:58 UTC |
| b876c14 | Aaruna | 29 May 2019, 17:30:16 UTC | [SPARK-27869][CORE] Redact sensitive information in System Properties from UI Currently system properties are not redacted. This PR fixes that, so that any credentials passed as System properties are redacted as well. Manual test. Run the following and see the UI. ``` bin/spark-shell --conf 'spark.driver.extraJavaOptions=-DMYSECRET=app' ``` Closes #24733 from aaruna/27869. Authored-by: Aaruna <aaruna.godthi@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit bfa7f112e3258926befe9eaa9a489d3e0c4e2a0a) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 29 May 2019, 17:32:55 UTC |
| 456ecb5 | Yuming Wang | 29 May 2019, 17:03:23 UTC | [SPARK-27863][SQL][BACKPORT-2.4] Metadata files and temporary files should not be counted as data files ## What changes were proposed in this pull request? This PR backport https://github.com/apache/spark/pull/24725 to branch-2.4. ## How was this patch tested? unit tests Closes #24737 from wangyum/SPARK-27863-branch-2.4. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 29 May 2019, 17:03:23 UTC |
| a4bbe02 | MJ Tang | 28 May 2019, 14:29:46 UTC | [SPARK-27657][ML] Fix the log format of ml.util.Instrumentation.logFai… …lure ## What changes were proposed in this pull request? The failure log format is fixed according to the jdk implementation. ## How was this patch tested? Manual tests have been done. The new failure log format would be like: java.lang.RuntimeException: Failed to finish the task at com.xxx.Test.test(Test.java:106) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.testng.internal.MethodInvocationHelper.invokeMethod(MethodInvocationHelper.java:124) at org.testng.internal.Invoker.invokeMethod(Invoker.java:571) at org.testng.internal.Invoker.invokeTestMethod(Invoker.java:707) at org.testng.internal.Invoker.invokeTestMethods(Invoker.java:979) at org.testng.internal.TestMethodWorker.invokeTestMethods(TestMethodWorker.java:125) at org.testng.internal.TestMethodWorker.run(TestMethodWorker.java:109) at org.testng.TestRunner.privateRun(TestRunner.java:648) at org.testng.TestRunner.run(TestRunner.java:505) at org.testng.SuiteRunner.runTest(SuiteRunner.java:455) at org.testng.SuiteRunner.runSequentially(SuiteRunner.java:450) at org.testng.SuiteRunner.privateRun(SuiteRunner.java:415) at org.testng.SuiteRunner.run(SuiteRunner.java:364) at org.testng.SuiteRunnerWorker.runSuite(SuiteRunnerWorker.java:52) at org.testng.SuiteRunnerWorker.run(SuiteRunnerWorker.java:84) at org.testng.TestNG.runSuitesSequentially(TestNG.java:1187) at org.testng.TestNG.runSuitesLocally(TestNG.java:1116) at org.testng.TestNG.runSuites(TestNG.java:1028) at org.testng.TestNG.run(TestNG.java:996) at org.testng.IDEARemoteTestNG.run(IDEARemoteTestNG.java:72) at org.testng.RemoteTestNGStarter.main(RemoteTestNGStarter.java:123) Caused by: java.io.FileNotFoundException: File is not found at com.xxx.Test.test(Test.java:105) ... 24 more Closes #24684 from breakdawn/master. Authored-by: MJ Tang <mingjtang@ebay.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> (cherry picked from commit 1824cbfa39c92d999e24173f2337f518aa5e3e9b) Signed-off-by: Sean Owen <sean.owen@databricks.com> | 28 May 2019, 14:30:23 UTC |
| 0d9be28 | Gabbi Merz | 28 May 2019, 03:09:23 UTC | [SPARK-27858][SQL] Fix for avro deserialization on union types with multiple non-null types ## What changes were proposed in this pull request? This PR aims to fix an issue on a union avro type with more than one non-null value (for instance `["string", "null", "int"]`) whose the deserialization to a DataFrame would throw a `java.lang.ArrayIndexOutOfBoundsException`. The issue was that the `fieldWriter` relied on the index from the avro schema before nulls were filtered out. ## How was this patch tested? A test for the case of multiple non-null values was added and the tests were run using sbt by running `testOnly org.apache.spark.sql.avro.AvroSuite` Closes #24722 from gcmerz/master. Authored-by: Gabbi Merz <gmerz@palantir.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 29e154b2f12058c59eaa411989ead833119f165f) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 28 May 2019, 03:09:37 UTC |
| 7223c0e | Yuming Wang | 26 May 2019, 15:35:58 UTC | [SPARK-27441][SQL][TEST] Add read/write tests to Hive serde tables ## What changes were proposed in this pull request? The versions between Hive, Parquet and ORC after the built-in Hive upgraded to 2.3.5 for Hadoop 3.2: - built-in Hive is 1.2.1.spark2: | ORC | Parquet -- | -- | -- Spark datasource table | 1.5.5 | 1.10.1 Spark hive table | Hive built-in | 1.6.0 Apache Hive 1.2.1 | Hive built-in | 1.6.0 - built-in Hive is 2.3.5: | ORC | Parquet -- | -- | -- Spark datasource table | 1.5.5 | 1.10.1 Spark hive table | 1.5.5 | [1.10.1](https://github.com/apache/spark/pull/24346) Apache Hive 2.3.5 | 1.3.4 | 1.8.1 We should add a test for Hive Serde table. This pr adds tests to test read/write of all supported data types using Parquet and ORC. ## How was this patch tested? unit tests Closes #24345 from wangyum/SPARK-27441. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 193304b51bee164c1d355b75be039f762118bdba) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 26 May 2019, 15:36:12 UTC |
| a287110 | Jose Torres | 26 May 2019, 00:25:08 UTC | [SPARK-27711][CORE] Unset InputFileBlockHolder at the end of tasks ## What changes were proposed in this pull request? Unset InputFileBlockHolder at the end of tasks to stop the file name from leaking over to other tasks in the same thread. This happens in particular in Pyspark because of its complex threading model. Backport to 2.4. ## How was this patch tested? new pyspark test Closes #24690 from jose-torres/fix24. Authored-by: Jose Torres <torres.joseph.f+github@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 26 May 2019, 00:25:08 UTC |
| 80fe1ed | Gabor Somogyi | 24 May 2019, 15:03:59 UTC | [MINOR][DOC] ForeachBatch doc fix. ## What changes were proposed in this pull request? ForeachBatch doc is wrongly formatted. This PR formats it. ## How was this patch tested? ``` cd docs SKIP_API=1 jekyll build ``` Manual webpage check. Closes #24698 from gaborgsomogyi/foreachbatchdoc. Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 24 May 2019, 15:05:42 UTC |
| fb60066 | HyukjinKwon | 23 May 2019, 20:39:13 UTC | Revert "Revert "[SPARK-27539][SQL] Fix inaccurate aggregate outputRows estimation with column containing null values"" This reverts commit e0e8a6de1345e6e716bb8c6e35a98e981feb3bab. | 23 May 2019, 20:39:13 UTC |
| ec6a08b | HyukjinKwon | 23 May 2019, 20:39:06 UTC | Revert "Revert "[SPARK-27351][SQL] Wrong outputRows estimation after AggregateEstimation wit…"" This reverts commit e69ad46c72ed26c8293da95dc19b6f31445c0df5. | 23 May 2019, 20:39:06 UTC |
| d6ab7e6 | Sean Owen | 23 May 2019, 20:21:21 UTC | [SPARK-26045][BUILD] Leave avro, avro-ipc dependendencies as compile scope even for hadoop-provided usages ## What changes were proposed in this pull request? Leave avro, avro-ipc dependendencies as compile scope even for hadoop-provided usages, to ensure 1.8 is used. Hadoop 2.7 has Avro 1.7, and Spark won't generally work with that. Reports from the field are that this works, to include avro 1.8 with the Spark distro on Hadoop 2.7. ## How was this patch tested? Existing tests Closes #24680 from srowen/SPARK-26045. Authored-by: Sean Owen <sean.owen@databricks.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 32f310b585fd79980a841d0b507f188123ff8121) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 23 May 2019, 20:21:39 UTC |
| e69ad46 | HyukjinKwon | 23 May 2019, 18:19:48 UTC | Revert "[SPARK-27351][SQL] Wrong outputRows estimation after AggregateEstimation wit…" This reverts commit 40668c53ed799881db1f316ceaf2f978b294d8ed. | 23 May 2019, 18:19:48 UTC |
| e0e8a6d | HyukjinKwon | 23 May 2019, 18:19:40 UTC | Revert "[SPARK-27539][SQL] Fix inaccurate aggregate outputRows estimation with column containing null values" This reverts commit 42cb4a2ccdb5ca6216677dc4285c3e74cfb7e707. | 23 May 2019, 18:19:40 UTC |
| fa7c319 | Dongjoon Hyun | 22 May 2019, 10:11:29 UTC | [SPARK-27800][SQL][HOTFIX][FOLLOWUP] Fix wrong answer on BitwiseXor test cases This PR is a follow up of https://github.com/apache/spark/pull/24669 to fix the wrong answers used in test cases. Closes #24674 from dongjoon-hyun/SPARK-27800. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit a24cdc00bfa4eb011022aedec22a345a0e0e981d) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 22 May 2019, 10:12:24 UTC |
| 4d687a5 | Liu Xiao | 22 May 2019, 04:52:19 UTC | [SPARK-27800][SQL][DOC] Fix wrong answer of example for BitwiseXor ## What changes were proposed in this pull request? Fix example for bitwise xor function. 3 ^ 5 should be 6 rather than 2. - See https://spark.apache.org/docs/latest/api/sql/index.html#_14 ## How was this patch tested? manual tests Closes #24669 from alex-lx/master. Authored-by: Liu Xiao <hhdxlx@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit bf617996aa95dd51be15da64ba9254f98697560c) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 22 May 2019, 04:52:34 UTC |
| 1e2b60f | David Navas | 21 May 2019, 17:21:46 UTC | [SPARK-27726][CORE] Fix performance of ElementTrackingStore deletes when using InMemoryStore under high loads The details of the PR are explored in-depth in the sub-tasks of the umbrella jira SPARK-27726. Briefly: 1. Stop issuing asynchronous requests to cleanup elements in the tracking store when a request is already pending 2. Fix a couple of thread-safety issues (mutable state and mis-ordered updates) 3. Move Summary deletion outside of Stage deletion loop like Tasks already are 4. Reimplement multi-delete in a removeAllKeys call which allows InMemoryStore to implement it in a performant manner. 5. Some generic typing and exception handling cleanup We see about five orders of magnitude improvement in the deletion code, which for us is the difference between a server that needs restarting daily, and one that is stable over weeks. Unit tests for the fire-once asynchronous code and the removeAll calls in both LevelDB and InMemoryStore are supplied. It was noted that the testing code for the LevelDB and InMemoryStore is highly repetitive, and should probably be merged, but we did not attempt that in this PR. A version of this code was run in our production 2.3.3 and we were able to sustain higher throughput without going into GC overload (which was happening on a daily basis some weeks ago). A version of this code was also put under a purpose-built Performance Suite of tests to verify performance under both types of Store implementations for both before and after code streams and for both total and partial delete cases (this code is not included in this PR). Closes #24616 from davidnavas/PentaBugFix. Authored-by: David Navas <davidn@clearstorydata.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> (cherry picked from commit 9e73be38a53214780512d0cafedfae9d472cdd05) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> | 21 May 2019, 18:08:07 UTC |
| 694ebb4 | Prashant Sharma | 21 May 2019, 09:23:38 UTC | [MINOR][DOCS] Fix Spark hive example. ## What changes were proposed in this pull request? Documentation has an error, https://spark.apache.org/docs/latest/sql-data-sources-hive-tables.html#hive-tables. The example: ```scala scala> val dataDir = "/tmp/parquet_data" dataDir: String = /tmp/parquet_data scala> spark.range(10).write.parquet(dataDir) scala> sql(s"CREATE EXTERNAL TABLE hive_ints(key int) STORED AS PARQUET LOCATION '$dataDir'") res6: org.apache.spark.sql.DataFrame = [] scala> sql("SELECT * FROM hive_ints").show() +----+ | key| +----+ |null| |null| |null| |null| |null| |null| |null| |null| |null| |null| +----+ ``` Range does not emit `key`, but `id` instead. Closes #24657 from ScrapCodes/fix_hive_example. Lead-authored-by: Prashant Sharma <prashant@apache.org> Co-authored-by: Prashant Sharma <prashsh1@in.ibm.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 5f4b50513cd34cd3dcf7f72972bfcd1f51031723) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 21 May 2019, 09:24:05 UTC |