https://github.com/apache/spark
- HEAD
- refs/heads/branch-0.5
- refs/heads/branch-0.6
- refs/heads/branch-0.7
- refs/heads/branch-0.8
- refs/heads/branch-0.9
- refs/heads/branch-1.0
- refs/heads/branch-1.0-jdbc
- refs/heads/branch-1.1
- refs/heads/branch-1.2
- refs/heads/branch-1.3
- refs/heads/branch-1.4
- refs/heads/branch-1.5
- refs/heads/branch-1.6
- refs/heads/branch-2.0
- refs/heads/branch-2.1
- refs/heads/branch-2.2
- refs/heads/branch-2.3
- refs/heads/branch-2.4
- refs/heads/branch-3.0
- refs/heads/branch-3.1
- refs/heads/branch-3.2
- refs/heads/branch-3.3
- refs/heads/branch-3.4
- refs/heads/branch-3.5
- refs/heads/master
- refs/remotes/origin/branch-0.8
- refs/remotes/origin/td-rdd-save
- refs/tags/0.3-scala-2.8
- refs/tags/0.3-scala-2.9
- refs/tags/2.0.0-preview
- refs/tags/alpha-0.1
- refs/tags/alpha-0.2
- refs/tags/v0.5.0
- refs/tags/v0.5.1
- refs/tags/v0.5.2
- refs/tags/v0.6.0
- refs/tags/v0.6.0-yarn
- refs/tags/v0.6.1
- refs/tags/v0.6.2
- refs/tags/v0.7.0
- refs/tags/v0.7.0-bizo-1
- refs/tags/v0.7.1
- refs/tags/v0.7.2
- refs/tags/v0.9.1
- refs/tags/v0.9.2
- refs/tags/v1.0.0
- refs/tags/v1.0.1
- refs/tags/v1.0.2
- refs/tags/v1.1.0
- refs/tags/v1.1.1
- refs/tags/v1.2.0
- refs/tags/v1.2.1
- refs/tags/v1.2.2
- refs/tags/v1.3.0
- refs/tags/v1.3.1
- refs/tags/v1.4.0
- refs/tags/v1.4.1
- refs/tags/v1.5.0-rc1
- refs/tags/v1.5.0-rc2
- refs/tags/v1.5.0-rc3
- refs/tags/v1.5.1
- refs/tags/v1.6.0
- refs/tags/v1.6.1
- refs/tags/v1.6.2
- refs/tags/v1.6.3
- refs/tags/v2.0.0
- refs/tags/v2.0.1
- refs/tags/v2.0.2
- refs/tags/v2.1.0
- refs/tags/v2.1.1
- refs/tags/v2.1.2
- refs/tags/v2.1.2-rc1
- refs/tags/v2.1.2-rc2
- refs/tags/v2.1.2-rc3
- refs/tags/v2.1.2-rc4
- refs/tags/v2.1.3
- refs/tags/v2.1.3-rc1
- refs/tags/v2.1.3-rc2
- refs/tags/v2.2.0
- refs/tags/v2.2.1
- refs/tags/v2.2.1-rc1
- refs/tags/v2.2.1-rc2
- refs/tags/v2.2.2
- refs/tags/v2.2.2-rc1
- refs/tags/v2.2.2-rc2
- refs/tags/v2.2.3
- refs/tags/v2.2.3-rc1
- refs/tags/v2.3.0
- refs/tags/v2.3.0-rc1
- refs/tags/v2.3.0-rc2
- refs/tags/v2.3.0-rc3
- refs/tags/v2.3.0-rc4
- refs/tags/v2.3.1
- refs/tags/v2.3.1-rc1
- refs/tags/v2.3.1-rc2
- refs/tags/v2.3.1-rc3
- refs/tags/v2.3.1-rc4
- refs/tags/v2.3.2
- refs/tags/v2.3.2-rc1
- refs/tags/v2.3.2-rc2
- refs/tags/v2.3.2-rc3
- refs/tags/v2.3.2-rc4
- refs/tags/v2.3.2-rc5
- refs/tags/v2.3.2-rc6
- refs/tags/v2.3.3
- refs/tags/v2.3.3-rc1
- refs/tags/v2.3.3-rc2
- refs/tags/v2.3.4
- refs/tags/v2.3.4-rc1
- refs/tags/v2.4.0
- refs/tags/v2.4.0-rc1
- refs/tags/v2.4.0-rc2
- refs/tags/v2.4.0-rc3
- refs/tags/v2.4.0-rc4
- refs/tags/v2.4.0-rc5
- refs/tags/v2.4.1
- refs/tags/v2.4.1-rc1
- refs/tags/v2.4.1-rc2
- refs/tags/v2.4.1-rc3
- refs/tags/v2.4.1-rc4
- refs/tags/v2.4.1-rc5
- refs/tags/v2.4.1-rc6
- refs/tags/v2.4.1-rc7
- refs/tags/v2.4.1-rc8
- refs/tags/v2.4.1-rc9
- refs/tags/v2.4.2
- refs/tags/v2.4.2-rc1
- refs/tags/v2.4.3
- refs/tags/v2.4.3-rc1
- refs/tags/v2.4.4
- refs/tags/v2.4.4-rc1
- refs/tags/v2.4.4-rc2
- refs/tags/v2.4.4-rc3
- refs/tags/v2.4.5
- refs/tags/v2.4.5-rc1
- refs/tags/v2.4.5-rc2
- refs/tags/v2.4.6
- refs/tags/v2.4.6-rc1
- refs/tags/v2.4.6-rc2
- refs/tags/v2.4.6-rc3
- refs/tags/v2.4.6-rc4
- refs/tags/v2.4.6-rc5
- refs/tags/v2.4.6-rc6
- refs/tags/v2.4.6-rc7
- refs/tags/v2.4.6-rc8
- refs/tags/v2.4.7
- refs/tags/v2.4.7-rc1
- refs/tags/v2.4.7-rc2
- refs/tags/v2.4.7-rc3
- refs/tags/v2.4.8
- refs/tags/v2.4.8-rc1
- refs/tags/v2.4.8-rc2
- refs/tags/v2.4.8-rc3
- refs/tags/v2.4.8-rc4
- refs/tags/v3.0.0
- refs/tags/v3.0.0-preview2
- refs/tags/v3.0.0-preview2-rc1
- refs/tags/v3.0.0-preview2-rc2
- refs/tags/v3.0.0-rc1
- refs/tags/v3.0.0-rc2
- refs/tags/v3.0.0-rc3
- refs/tags/v3.0.1
- refs/tags/v3.0.1-rc1
- refs/tags/v3.0.1-rc2
- refs/tags/v3.0.1-rc3
- refs/tags/v3.0.2
- refs/tags/v3.0.2-rc1
- refs/tags/v3.0.3
- refs/tags/v3.0.3-rc1
- refs/tags/v3.1.0-rc1
- refs/tags/v3.1.1
- refs/tags/v3.1.1-rc1
- refs/tags/v3.1.1-rc2
- refs/tags/v3.1.1-rc3
- refs/tags/v3.1.2
- refs/tags/v3.1.2-rc1
- refs/tags/v3.1.3
- refs/tags/v3.1.3-rc1
- refs/tags/v3.1.3-rc2
- refs/tags/v3.1.3-rc3
- refs/tags/v3.1.3-rc4
- refs/tags/v3.2.0
- refs/tags/v3.2.0-rc1
- refs/tags/v3.2.0-rc2
- refs/tags/v3.2.0-rc3
- refs/tags/v3.2.0-rc4
- refs/tags/v3.2.0-rc5
- refs/tags/v3.2.0-rc6
- refs/tags/v3.2.0-rc7
- refs/tags/v3.2.1
- refs/tags/v3.2.1-rc1
- refs/tags/v3.2.1-rc2
- refs/tags/v3.2.2
- refs/tags/v3.2.2-rc1
- refs/tags/v3.2.3
- refs/tags/v3.2.3-rc1
- refs/tags/v3.2.4
- refs/tags/v3.2.4-rc1
- refs/tags/v3.3.0
- refs/tags/v3.3.0-rc1
- refs/tags/v3.3.0-rc2
- refs/tags/v3.3.0-rc3
- refs/tags/v3.3.0-rc4
- refs/tags/v3.3.0-rc5
- refs/tags/v3.3.0-rc6
- refs/tags/v3.3.1
- refs/tags/v3.3.1-rc1
- refs/tags/v3.3.1-rc2
- refs/tags/v3.3.1-rc3
- refs/tags/v3.3.1-rc4
- refs/tags/v3.3.2
- refs/tags/v3.3.2-rc1
- refs/tags/v3.3.3
- refs/tags/v3.3.3-rc1
- refs/tags/v3.3.4
- refs/tags/v3.3.4-rc1
- refs/tags/v3.4.0
- refs/tags/v3.4.0-rc1
- refs/tags/v3.4.0-rc2
- refs/tags/v3.4.0-rc3
- refs/tags/v3.4.0-rc4
- refs/tags/v3.4.0-rc5
- refs/tags/v3.4.0-rc6
- refs/tags/v3.4.0-rc7
- refs/tags/v3.4.1
- refs/tags/v3.4.1-rc1
- refs/tags/v3.4.2
- refs/tags/v3.4.2-rc1
- refs/tags/v3.4.3
- refs/tags/v3.4.3-rc1
- refs/tags/v3.4.3-rc2
- refs/tags/v3.5.0
- refs/tags/v3.5.0-rc1
- refs/tags/v3.5.0-rc2
- refs/tags/v3.5.0-rc3
- refs/tags/v3.5.0-rc4
- refs/tags/v3.5.0-rc5
- refs/tags/v3.5.1
- refs/tags/v3.5.1-rc1
- refs/tags/v3.5.1-rc2
- refs/tags/v4.0.0-preview1
- refs/tags/v4.0.0-preview1-rc1
- refs/tags/v4.0.0-preview1-rc2
- refs/tags/v4.0.0-preview1-rc3
Take a new snapshot of a software origin
If the archived software origin currently browsed is not synchronized with its upstream version (for instance when new commits have been issued), you can explicitly request Software Heritage to take a new snapshot of it.
Use the form below to proceed. Once a request has been submitted and accepted, it will be processed as soon as possible. You can then check its processing state by visiting this dedicated page.
Processing "take a new snapshot" request ...
Permalinks
To reference or cite the objects present in the Software Heritage archive, permalinks based on SoftWare Hash IDentifiers (SWHIDs) must be used.
Select below a type of object currently browsed in order to display its associated SWHID and permalink.
| Revision | Author | Date | Message | Commit Date |
|---|---|---|---|---|
| 65ac1e7 | Wu Yi | 15 June 2021, 04:04:50 UTC | Preparing Spark release v3.0.3-rc1 | 15 June 2021, 04:04:50 UTC |
| 673654b | Kun Wan | 13 June 2021, 21:01:00 UTC | [SPARK-35714][CORE] Bug fix for deadlock during the executor shutdown ### What changes were proposed in this pull request? Bug fix for deadlock during the executor shutdown ### Why are the changes needed? When a executor received a TERM signal, it (the second TERM signal) will lock java.lang.Shutdown class and then call Shutdown.exit() method to exit the JVM. Shutdown will call SparkShutdownHook to shutdown the executor. During the executor shutdown phase, RemoteProcessDisconnected event will be send to the RPC inbox, and then WorkerWatcher will try to call System.exit(-1) again. Because java.lang.Shutdown has already locked, a deadlock has occurred. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Test case "task reaper kills JVM if killed tasks keep running for too long" in JobCancellationSuite Closes #32868 from wankunde/SPARK-35714. Authored-by: Kun Wan <wankun@apache.org> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 69aa7ad11f68e96e045b5eb915e21708e018421a) Signed-off-by: Sean Owen <srowen@gmail.com> | 13 June 2021, 21:01:25 UTC |
| 3902af8 | Liang-Chi Hsieh | 12 June 2021, 16:51:47 UTC | [SPARK-35689][SS][3.0] Add log warn when keyWithIndexToValue returns null value ### What changes were proposed in this pull request? This patch adds log warn when `keyWithIndexToValue` returns null value in `SymmetricHashJoinStateManager`. This is the backport of #32828 to branch-3.0. ### Why are the changes needed? Once we get null from state store in SymmetricHashJoinStateManager, it is better to add meaningful logging for the case. It is better for debugging. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests. Closes #32890 from viirya/fix-ss-joinstatemanager-followup-3.0. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 12 June 2021, 16:51:47 UTC |
| 6597c3b | shahid | 12 June 2021, 06:38:41 UTC | [SPARK-35746][UI] Fix taskid in the stage page task event timeline ### What changes were proposed in this pull request? Task id is given incorrect in the timeline plot in Stage Page ### Why are the changes needed? Map event timeline plots to correct task **Before:**  **After**  ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Manually tested Closes #32888 from shahidki31/shahid/fixtaskid. Authored-by: shahid <shahidki31@gmail.com> Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com> (cherry picked from commit 450b415028c3b00f3a002126cd11318d3932e28f) Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com> | 12 June 2021, 06:40:52 UTC |
| 763e512 | Tanel Kiis | 11 June 2021, 13:03:08 UTC | [SPARK-35695][SQL] Collect observed metrics from cached and adaptive execution sub-trees ### What changes were proposed in this pull request? Collect observed metrics from cached and adaptive execution sub-trees. ### Why are the changes needed? Currently persisting/caching will hide all observed metrics in that sub-tree from reaching the `QueryExecutionListeners`. Adaptive query execution can also hide the metrics from reaching `QueryExecutionListeners`. ### Does this PR introduce _any_ user-facing change? Bugfix ### How was this patch tested? New UTs Closes #32862 from tanelk/SPARK-35695_collect_metrics_persist. Lead-authored-by: Tanel Kiis <tanel.kiis@gmail.com> Co-authored-by: tanel.kiis@gmail.com <tanel.kiis@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 692dc66c4a3660665c1f156df6eeb9ce6f86195e) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 11 June 2021, 13:03:44 UTC |
| 4fed690 | Kousuke Saruta | 10 June 2021, 17:20:35 UTC | [SPARK-35296][SQL] Allow Dataset.observe to work even if CollectMetricsExec in a task handles multiple partitions ### What changes were proposed in this pull request? This PR fixes an issue that `Dataset.observe` doesn't work if `CollectMetricsExec` in a task handles multiple partitions. If `coalesce` follows `observe` and the number of partitions shrinks after `coalesce`, `CollectMetricsExec` can handle multiple partitions in a task. ### Why are the changes needed? The current implementation of `CollectMetricsExec` doesn't consider the case it can handle multiple partitions. Because new `updater` is created for each partition even though those partitions belong to the same task, `collector.setState(updater)` raise an assertion error. This is a simple reproducible example. ``` $ bin/spark-shell --master "local[1]" scala> spark.range(1, 4, 1, 3).observe("my_event", count($"id").as("count_val")).coalesce(2).collect ``` ``` java.lang.AssertionError: assertion failed at scala.Predef$.assert(Predef.scala:208) at org.apache.spark.sql.execution.AggregatingAccumulator.setState(AggregatingAccumulator.scala:204) at org.apache.spark.sql.execution.CollectMetricsExec.$anonfun$doExecute$2(CollectMetricsExec.scala:72) at org.apache.spark.sql.execution.CollectMetricsExec.$anonfun$doExecute$2$adapted(CollectMetricsExec.scala:71) at org.apache.spark.TaskContext$$anon$1.onTaskCompletion(TaskContext.scala:125) at org.apache.spark.TaskContextImpl.$anonfun$markTaskCompleted$1(TaskContextImpl.scala:124) at org.apache.spark.TaskContextImpl.$anonfun$markTaskCompleted$1$adapted(TaskContextImpl.scala:124) at org.apache.spark.TaskContextImpl.$anonfun$invokeListeners$1(TaskContextImpl.scala:137) at org.apache.spark.TaskContextImpl.$anonfun$invokeListeners$1$adapted(TaskContextImpl.scala:135) ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? New test. Closes #32786 from sarutak/fix-collectmetricsexec. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 44b695fbb06b0d89783b4838941c68543c5a5c8b) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 10 June 2021, 17:21:19 UTC |
| f3ba9d9 | Emil Ejbyfeldt | 10 June 2021, 16:37:27 UTC | [SPARK-35653][SQL] Fix CatalystToExternalMap interpreted path fails for Map with case classes as keys or values ### What changes were proposed in this pull request? Use the key/value LambdaFunction to convert the elements instead of using CatalystTypeConverters.createToScalaConverter. This is how it is done in MapObjects and that correctly handles Arrays with case classes. ### Why are the changes needed? Before these changes the added test cases would fail with the following: ``` [info] - encode/decode for map with case class as value: Map(1 -> IntAndString(1,a)) (interpreted path) *** FAILED *** (64 milliseconds) [info] Encoded/Decoded data does not match input data [info] [info] in: Map(1 -> IntAndString(1,a)) [info] out: Map(1 -> [1,a]) [info] types: scala.collection.immutable.Map$Map1 [info] [info] Encoded Data: [org.apache.spark.sql.catalyst.expressions.UnsafeMapData5ecf5d9e] [info] Schema: value#823 [info] root [info] -- value: map (nullable = true) [info] |-- key: integer [info] |-- value: struct (valueContainsNull = true) [info] | |-- i: integer (nullable = false) [info] | |-- s: string (nullable = true) [info] [info] [info] fromRow Expressions: [info] catalysttoexternalmap(lambdavariable(CatalystToExternalMap_key, IntegerType, false, 178), lambdavariable(CatalystToExternalMap_key, IntegerType, false, 178), lambdavariable(CatalystToExternalMap_value, StructField(i,IntegerType,false), StructField(s,StringType,true), true, 179), if (isnull(lambdavariable(CatalystToExternalMap_value, StructField(i,IntegerType,false), StructField(s,StringType,true), true, 179))) null else newInstance(class org.apache.spark.sql.catalyst.encoders.IntAndString), input[0, map<int,struct<i:int,s:string>>, true], interface scala.collection.immutable.Map [info] :- lambdavariable(CatalystToExternalMap_key, IntegerType, false, 178) [info] :- lambdavariable(CatalystToExternalMap_key, IntegerType, false, 178) [info] :- lambdavariable(CatalystToExternalMap_value, StructField(i,IntegerType,false), StructField(s,StringType,true), true, 179) [info] :- if (isnull(lambdavariable(CatalystToExternalMap_value, StructField(i,IntegerType,false), StructField(s,StringType,true), true, 179))) null else newInstance(class org.apache.spark.sql.catalyst.encoders.IntAndString) [info] : :- isnull(lambdavariable(CatalystToExternalMap_value, StructField(i,IntegerType,false), StructField(s,StringType,true), true, 179)) [info] : : +- lambdavariable(CatalystToExternalMap_value, StructField(i,IntegerType,false), StructField(s,StringType,true), true, 179) [info] : :- null [info] : +- newInstance(class org.apache.spark.sql.catalyst.encoders.IntAndString) [info] : :- assertnotnull(lambdavariable(CatalystToExternalMap_value, StructField(i,IntegerType,false), StructField(s,StringType,true), true, 179).i) [info] : : +- lambdavariable(CatalystToExternalMap_value, StructField(i,IntegerType,false), StructField(s,StringType,true), true, 179).i [info] : : +- lambdavariable(CatalystToExternalMap_value, StructField(i,IntegerType,false), StructField(s,StringType,true), true, 179) [info] : +- lambdavariable(CatalystToExternalMap_value, StructField(i,IntegerType,false), StructField(s,StringType,true), true, 179).s.toString [info] : +- lambdavariable(CatalystToExternalMap_value, StructField(i,IntegerType,false), StructField(s,StringType,true), true, 179).s [info] : +- lambdavariable(CatalystToExternalMap_value, StructField(i,IntegerType,false), StructField(s,StringType,true), true, 179) [info] +- input[0, map<int,struct<i:int,s:string>>, true] (ExpressionEncoderSuite.scala:627) ``` So using a map with cases classes for keys or values and using the interpreted path would incorrect deserialize data from the catalyst representation. ### Does this PR introduce _any_ user-facing change? Yes, it fixes the bug. ### How was this patch tested? Existing and new unit tests in the ExpressionEncoderSuite Closes #32783 from eejbyfeldt/fix-interpreted-path-for-map-with-case-classes. Authored-by: Emil Ejbyfeldt <eejbyfeldt@liveintent.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> (cherry picked from commit e2e3fe77823387f6d4164eede05bf077b4235c87) Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 10 June 2021, 16:37:58 UTC |
| c8d0bd0 | Fu Chen | 10 June 2021, 07:32:10 UTC | [SPARK-35673][SQL] Fix user-defined hint and unrecognized hint in subquery Use `UnresolvedHint.resolved = child.resolved` instead `UnresolvedHint.resolved = false`, then the plan contains `UnresolvedHint` child can be optimized by rule in batch `Resolution`. For instance, before this pr, the following plan can't be optimized by `ResolveReferences`. ``` !'Project [*] +- SubqueryAlias __auto_generated_subquery_name +- UnresolvedHint use_hash +- Project [42 AS 42#10] +- OneRowRelation ``` fix hint in subquery bug No. New test. Closes #32841 from cfmcgrady/SPARK-35673. Authored-by: Fu Chen <cfmcgrady@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 5280f02747eed9849e4a64562d38aee11e21616f) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 10 June 2021, 07:48:07 UTC |
| fe18354 | dgd-contributor | 10 June 2021, 05:08:51 UTC | [SPARK-35679][SQL] instantToMicros overflow With Long.minValue cast to an instant, secs will be floored in function microsToInstant and cause overflow when multiply with Micros_per_second ``` def microsToInstant(micros: Long): Instant = { val secs = Math.floorDiv(micros, MICROS_PER_SECOND) // Unfolded Math.floorMod(us, MICROS_PER_SECOND) to reuse the result of // the above calculation of `secs` via `floorDiv`. val mos = micros - secs * MICROS_PER_SECOND <- it will overflow here Instant.ofEpochSecond(secs, mos * NANOS_PER_MICROS) } ``` But the overflow is acceptable because it won't produce any change to the result However, when convert the instant back to micro value, it will raise Overflow Error ``` def instantToMicros(instant: Instant): Long = { val us = Math.multiplyExact(instant.getEpochSecond, MICROS_PER_SECOND) <- It overflow here val result = Math.addExact(us, NANOSECONDS.toMicros(instant.getNano)) result } ``` Code to reproduce this error ``` instantToMicros(microToInstant(Long.MinValue)) ``` No Test added Closes #32839 from dgd-contributor/SPARK-35679_instantToMicro. Authored-by: dgd-contributor <dgd_contributor@viettel.com.vn> Signed-off-by: Max Gekk <max.gekk@gmail.com> (cherry picked from commit aa3de4077302fe7e0b23b01a338c7feab0e5974e) Signed-off-by: Max Gekk <max.gekk@gmail.com> | 10 June 2021, 05:24:14 UTC |
| 29ee5cd | ulysses-you | 09 June 2021, 06:57:56 UTC | [SPARK-35687][SQL][TEST] PythonUDFSuite move assume into its methods ### What changes were proposed in this pull request? Move `assume` into methods at `PythonUDFSuite`. ### Why are the changes needed? When we run Spark test with such command: `./build/mvn -Phadoop-2.7 -Phive -Phive-thriftserver -Pyarn -Pkubernetes clean test` get this exception: ``` PythonUDFSuite: org.apache.spark.sql.execution.python.PythonUDFSuite *** ABORTED *** java.lang.RuntimeException: Unable to load a Suite class that was discovered in the runpath: org.apache.spark.sql.execution.python.PythonUDFSuite at org.scalatest.tools.DiscoverySuite$.getSuiteInstance(DiscoverySuite.scala:81) at org.scalatest.tools.DiscoverySuite.$anonfun$nestedSuites$1(DiscoverySuite.scala:38) at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238) at scala.collection.Iterator.foreach(Iterator.scala:941) at scala.collection.Iterator.foreach$(Iterator.scala:941) at scala.collection.AbstractIterator.foreach(Iterator.scala:1429) at scala.collection.IterableLike.foreach(IterableLike.scala:74) at scala.collection.IterableLike.foreach$(IterableLike.scala:73) at scala.collection.AbstractIterable.foreach(Iterable.scala:56) at scala.collection.TraversableLike.map(TraversableLike.scala:238) ``` The test env has no PYSpark module so it failed. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? manual Closes #32833 from ulysses-you/SPARK-35687. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 825b62086254ee5edeaf16fccf632674711b1bd8) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 09 June 2021, 06:58:25 UTC |
| b5e6afb | Liang-Chi Hsieh | 08 June 2021, 22:20:30 UTC | [SPARK-35659][SS][3.0] Avoid write null to StateStore ### What changes were proposed in this pull request? This patch removes the usage of putting null into StateStore. This is backport of #32796 to branch-3.0. ### Why are the changes needed? According to `get` method doc in `StateStore` API, it returns non-null row if the key exists. So basically we should avoid write null to `StateStore`. You cannot distinguish if the returned null row is because the key doesn't exist, or the value is actually null. And due to the defined behavior of `get`, it is quite easy to cause NPE error if the caller doesn't expect to get a null if the caller believes the key exists. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added test. Closes #32823 from viirya/fix-ss-joinstatemanager-3.0. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 08 June 2021, 22:20:30 UTC |
| 7749bc5 | attilapiros | 02 June 2021, 16:34:28 UTC | [SPARK-35610][CORE] Fix the memory leak introduced by the Executor's stop shutdown hook ### What changes were proposed in this pull request? Fixing the memory leak by deregistering the shutdown hook when the executor is stopped. This way the Garbage Collector can release the executor object early. Which is a huge win for our tests as user's classloader could be also released which keeps references to objects which are created for the jars on the classpath. ### Why are the changes needed? I have identified this leak by running the Livy tests (I know it is close to the attic but this leak causes a constant OOM there) and it is in our Spark unit tests as well. This leak can be identified by checking the number of `LeakyEntry` in case of Scala 2.12.14 (and `ZipEntry` for Scala 2.12.10) instances which with its related data can take up a considerable amount of memory (as those are created from the jars which are on the classpath). I have my own tool for instrumenting JVM code [trace-agent](https://github.com/attilapiros/trace-agent) and with that I am able to call JVM diagnostic commands at specific methods. Let me show how it in action. It has a single text file embedded into the tool's jar called action.txt. In this case actions.txt content is: {noformat} $ unzip -q -c trace-agent-0.0.7.jar actions.txt diagnostic_command org.apache.spark.repl.ReplSuite runInterpreter cmd:gcClassHistogram,limit_output_lines:8,where:beforeAndAfter,with_gc:true diagnostic_command org.apache.spark.repl.ReplSuite afterAll cmd:gcClassHistogram,limit_output_lines:8,where:after,with_gc:true {noformat} Which creates a class histogram at the beginning and at the end of `org.apache.spark.repl.ReplSuite#runInterpreter()` (after triggering a GC which might not finish as GC is done in a separate thread..) and one histogram in the end of the `org.apache.spark.repl.ReplSuite#afterAll()` method. And the histograms are the followings on master branch: ``` $ ./build/sbt ";project repl;set Test/javaOptions += \"-javaagent:/Users/attilazsoltpiros/git/attilapiros/memoryLeak/trace-agent-0.0.7.jar\"; testOnly" |grep "ZipEntry\|LeakyEntry" 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 3: 394178 18920544 scala.reflect.io.FileZipArchive$LeakyEntry 3: 394178 18920544 scala.reflect.io.FileZipArchive$LeakyEntry 3: 591267 28380816 scala.reflect.io.FileZipArchive$LeakyEntry 3: 591267 28380816 scala.reflect.io.FileZipArchive$LeakyEntry 3: 788356 37841088 scala.reflect.io.FileZipArchive$LeakyEntry 3: 788356 37841088 scala.reflect.io.FileZipArchive$LeakyEntry 3: 985445 47301360 scala.reflect.io.FileZipArchive$LeakyEntry 3: 985445 47301360 scala.reflect.io.FileZipArchive$LeakyEntry 3: 1182534 56761632 scala.reflect.io.FileZipArchive$LeakyEntry 3: 1182534 56761632 scala.reflect.io.FileZipArchive$LeakyEntry 3: 1379623 66221904 scala.reflect.io.FileZipArchive$LeakyEntry 3: 1379623 66221904 scala.reflect.io.FileZipArchive$LeakyEntry 3: 1576712 75682176 scala.reflect.io.FileZipArchive$LeakyEntry ``` Where the header of the table is: ``` num #instances #bytes class name ``` So the `LeakyEntry` in the end is about 75MB (173MB in case of Scala 2.12.10 and before for another class called `ZipEntry`) but the first item (a char/byte arrays) and the second item (strings) in the histogram also relates to this leak: ``` $ ./build/sbt ";project repl;set Test/javaOptions += \"-javaagent:/Users/attilazsoltpiros/git/attilapiros/memoryLeak/trace-agent-0.0.7.jar\"; testOnly" |grep "1:\|2:\|3:" 1: 2701 3496112 [B 2: 21855 2607192 [C 3: 4885 537264 java.lang.Class 1: 480323 55970208 [C 2: 480499 11531976 java.lang.String 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 1: 481825 56148024 [C 2: 481998 11567952 java.lang.String 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 1: 487056 57550344 [C 2: 487179 11692296 java.lang.String 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 1: 487054 57551008 [C 2: 487176 11692224 java.lang.String 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 1: 927823 107139160 [C 2: 928072 22273728 java.lang.String 3: 394178 18920544 scala.reflect.io.FileZipArchive$LeakyEntry 1: 927793 107129328 [C 2: 928041 22272984 java.lang.String 3: 394178 18920544 scala.reflect.io.FileZipArchive$LeakyEntry 1: 1361851 155555608 [C 2: 1362261 32694264 java.lang.String 3: 591267 28380816 scala.reflect.io.FileZipArchive$LeakyEntry 1: 1361683 155493464 [C 2: 1362092 32690208 java.lang.String 3: 591267 28380816 scala.reflect.io.FileZipArchive$LeakyEntry 1: 1803074 205157728 [C 2: 1803268 43278432 java.lang.String 3: 788356 37841088 scala.reflect.io.FileZipArchive$LeakyEntry 1: 1802385 204938224 [C 2: 1802579 43261896 java.lang.String 3: 788356 37841088 scala.reflect.io.FileZipArchive$LeakyEntry 1: 2236631 253636592 [C 2: 2237029 53688696 java.lang.String 3: 985445 47301360 scala.reflect.io.FileZipArchive$LeakyEntry 1: 2236536 253603008 [C 2: 2236933 53686392 java.lang.String 3: 985445 47301360 scala.reflect.io.FileZipArchive$LeakyEntry 1: 2668892 301893920 [C 2: 2669510 64068240 java.lang.String 3: 1182534 56761632 scala.reflect.io.FileZipArchive$LeakyEntry 1: 2668759 301846376 [C 2: 2669376 64065024 java.lang.String 3: 1182534 56761632 scala.reflect.io.FileZipArchive$LeakyEntry 1: 3101238 350101048 [C 2: 3102073 74449752 java.lang.String 3: 1379623 66221904 scala.reflect.io.FileZipArchive$LeakyEntry 1: 3101240 350101104 [C 2: 3102075 74449800 java.lang.String 3: 1379623 66221904 scala.reflect.io.FileZipArchive$LeakyEntry 1: 3533785 398371760 [C 2: 3534835 84836040 java.lang.String 3: 1576712 75682176 scala.reflect.io.FileZipArchive$LeakyEntry 1: 3533759 398367088 [C 2: 3534807 84835368 java.lang.String 3: 1576712 75682176 scala.reflect.io.FileZipArchive$LeakyEntry 1: 3967049 446893400 [C 2: 3968314 95239536 java.lang.String 3: 1773801 85142448 scala.reflect.io.FileZipArchive$LeakyEntry [info] - SPARK-26633: ExecutorClassLoader.getResourceAsStream find REPL classes (8 seconds, 248 milliseconds) Setting default log level to "ERROR". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 1: 3966423 446709584 [C 2: 3967682 95224368 java.lang.String 3: 1773801 85142448 scala.reflect.io.FileZipArchive$LeakyEntry 1: 4399583 495097208 [C 2: 4401050 105625200 java.lang.String 3: 1970890 94602720 scala.reflect.io.FileZipArchive$LeakyEntry 1: 4399578 495070064 [C 2: 4401040 105624960 java.lang.String 3: 1970890 94602720 scala.reflect.io.FileZipArchive$LeakyEntry ``` The last three is about 700MB altogether. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? I used the trace-agent tool with the same settings for the modified code: ``` $ ./build/sbt ";project repl;set Test/javaOptions += \"-javaagent:/Users/attilazsoltpiros/git/attilapiros/memoryLeak/trace-agent-0.0.7.jar\"; testOnly" |grep "1:\|2:\|3:" 1: 2701 3496112 [B 2: 21855 2607192 [C 3: 4885 537264 java.lang.Class 1: 480323 55970208 [C 2: 480499 11531976 java.lang.String 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 1: 481825 56148024 [C 2: 481998 11567952 java.lang.String 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 1: 487056 57550344 [C 2: 487179 11692296 java.lang.String 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 1: 487054 57551008 [C 2: 487176 11692224 java.lang.String 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 1: 927823 107139160 [C 2: 928072 22273728 java.lang.String 3: 394178 18920544 scala.reflect.io.FileZipArchive$LeakyEntry 1: 927793 107129328 [C 2: 928041 22272984 java.lang.String 3: 394178 18920544 scala.reflect.io.FileZipArchive$LeakyEntry 1: 1361851 155555608 [C 2: 1362261 32694264 java.lang.String 3: 591267 28380816 scala.reflect.io.FileZipArchive$LeakyEntry 1: 1361683 155493464 [C 2: 1362092 32690208 java.lang.String 3: 591267 28380816 scala.reflect.io.FileZipArchive$LeakyEntry 1: 1803074 205157728 [C 2: 1803268 43278432 java.lang.String 3: 788356 37841088 scala.reflect.io.FileZipArchive$LeakyEntry 1: 1802385 204938224 [C 2: 1802579 43261896 java.lang.String 3: 788356 37841088 scala.reflect.io.FileZipArchive$LeakyEntry 1: 2236631 253636592 [C 2: 2237029 53688696 java.lang.String 3: 985445 47301360 scala.reflect.io.FileZipArchive$LeakyEntry 1: 2236536 253603008 [C 2: 2236933 53686392 java.lang.String 3: 985445 47301360 scala.reflect.io.FileZipArchive$LeakyEntry 1: 2668892 301893920 [C 2: 2669510 64068240 java.lang.String 3: 1182534 56761632 scala.reflect.io.FileZipArchive$LeakyEntry 1: 2668759 301846376 [C 2: 2669376 64065024 java.lang.String 3: 1182534 56761632 scala.reflect.io.FileZipArchive$LeakyEntry 1: 3101238 350101048 [C 2: 3102073 74449752 java.lang.String 3: 1379623 66221904 scala.reflect.io.FileZipArchive$LeakyEntry 1: 3101240 350101104 [C 2: 3102075 74449800 java.lang.String 3: 1379623 66221904 scala.reflect.io.FileZipArchive$LeakyEntry 1: 3533785 398371760 [C 2: 3534835 84836040 java.lang.String 3: 1576712 75682176 scala.reflect.io.FileZipArchive$LeakyEntry 1: 3533759 398367088 [C 2: 3534807 84835368 java.lang.String 3: 1576712 75682176 scala.reflect.io.FileZipArchive$LeakyEntry 1: 3967049 446893400 [C 2: 3968314 95239536 java.lang.String 3: 1773801 85142448 scala.reflect.io.FileZipArchive$LeakyEntry [info] - SPARK-26633: ExecutorClassLoader.getResourceAsStream find REPL classes (8 seconds, 248 milliseconds) Setting default log level to "ERROR". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 1: 3966423 446709584 [C 2: 3967682 95224368 java.lang.String 3: 1773801 85142448 scala.reflect.io.FileZipArchive$LeakyEntry 1: 4399583 495097208 [C 2: 4401050 105625200 java.lang.String 3: 1970890 94602720 scala.reflect.io.FileZipArchive$LeakyEntry 1: 4399578 495070064 [C 2: 4401040 105624960 java.lang.String 3: 1970890 94602720 scala.reflect.io.FileZipArchive$LeakyEntry [success] Total time: 174 s (02:54), completed Jun 2, 2021 2:00:43 PM ╭─attilazsoltpirosapiros-MBP16 ~/git/attilapiros/memoryLeak ‹SPARK-35610*› ╰─$ vim ╭─attilazsoltpirosapiros-MBP16 ~/git/attilapiros/memoryLeak ‹SPARK-35610*› ╰─$ ./build/sbt ";project repl;set Test/javaOptions += \"-javaagent:/Users/attilazsoltpiros/git/attilapiros/memoryLeak/trace-agent-0.0.7.jar\"; testOnly" |grep "1:\|2:\|3:" 1: 2685 3457368 [B 2: 21833 2606712 [C 3: 4885 537264 java.lang.Class 1: 480245 55978400 [C 2: 480421 11530104 java.lang.String 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 1: 480460 56005784 [C 2: 480633 11535192 java.lang.String 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 1: 486643 57537784 [C 2: 486766 11682384 java.lang.String 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 1: 486636 57538192 [C 2: 486758 11682192 java.lang.String 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 1: 501208 60411856 [C 2: 501180 12028320 java.lang.String 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 1: 501206 60412960 [C 2: 501177 12028248 java.lang.String 3: 197089 9460272 scala.reflect.io.FileZipArchive$LeakyEntry 1: 934925 108773320 [C 2: 935058 22441392 java.lang.String 3: 394178 18920544 scala.reflect.io.FileZipArchive$LeakyEntry 1: 934912 108769528 [C 2: 935044 22441056 java.lang.String 3: 394178 18920544 scala.reflect.io.FileZipArchive$LeakyEntry 1: 1370351 156901296 [C 2: 1370318 32887632 java.lang.String 3: 591267 28380816 scala.reflect.io.FileZipArchive$LeakyEntry 1: 1369660 156681680 [C 2: 1369627 32871048 java.lang.String 3: 591267 28380816 scala.reflect.io.FileZipArchive$LeakyEntry 1: 1803746 205383136 [C 2: 1803917 43294008 java.lang.String 3: 788356 37841088 scala.reflect.io.FileZipArchive$LeakyEntry 1: 1803658 205353096 [C 2: 1803828 43291872 java.lang.String 3: 788356 37841088 scala.reflect.io.FileZipArchive$LeakyEntry 1: 2235677 253608240 [C 2: 2236068 53665632 java.lang.String 3: 985445 47301360 scala.reflect.io.FileZipArchive$LeakyEntry 1: 2235539 253560088 [C 2: 2235929 53662296 java.lang.String 3: 985445 47301360 scala.reflect.io.FileZipArchive$LeakyEntry 1: 2667775 301799240 [C 2: 2668383 64041192 java.lang.String 3: 1182534 56761632 scala.reflect.io.FileZipArchive$LeakyEntry 1: 2667765 301798568 [C 2: 2668373 64040952 java.lang.String 3: 1182534 56761632 scala.reflect.io.FileZipArchive$LeakyEntry 1: 2666665 301491096 [C 2: 2667285 64014840 java.lang.String 3: 1182534 56761632 scala.reflect.io.FileZipArchive$LeakyEntry 1: 2666648 301490792 [C 2: 2667266 64014384 java.lang.String 3: 1182534 56761632 scala.reflect.io.FileZipArchive$LeakyEntry 1: 2668169 301833032 [C 2: 2668782 64050768 java.lang.String 3: 1182534 56761632 scala.reflect.io.FileZipArchive$LeakyEntry [info] - SPARK-26633: ExecutorClassLoader.getResourceAsStream find REPL classes (6 seconds, 396 milliseconds) Setting default log level to "ERROR". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 1: 2235495 253419952 [C 2: 2235887 53661288 java.lang.String 3: 985445 47301360 scala.reflect.io.FileZipArchive$LeakyEntry 1: 2668379 301800768 [C 2: 2668979 64055496 java.lang.String 3: 1182534 56761632 scala.reflect.io.FileZipArchive$LeakyEntry 1: 2236123 253522640 [C 2: 2236514 53676336 java.lang.String 3: 985445 47301360 scala.reflect.io.FileZipArchive$LeakyEntry ``` The sum of the last three numbers is about 354MB. Closes #32748 from attilapiros/SPARK-35610. Authored-by: attilapiros <piros.attila.zsolt@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 806edf8f4460b81e5b71ea00f83c14c4f8134bd4) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 02 June 2021, 16:34:57 UTC |
| 8f1c77d | Hyukjin Kwon | 01 June 2021, 01:35:52 UTC | [SPARK-35573][R][TESTS] Make SparkR tests pass with R 4.1+ This PR proposes to support R 4.1.0+ in SparkR. Currently the tests are being failed as below: ``` ══ Failed ══════════════════════════════════════════════════════════════════════ ── 1. Failure (test_sparkSQL_arrow.R:71:3): createDataFrame/collect Arrow optimi collect(createDataFrame(rdf)) not equal to `expected`. Component “g”: 'tzone' attributes are inconsistent ('UTC' and '') ── 2. Failure (test_sparkSQL_arrow.R:143:3): dapply() Arrow optimization - type collect(ret) not equal to `rdf`. Component “b”: 'tzone' attributes are inconsistent ('UTC' and '') ── 3. Failure (test_sparkSQL_arrow.R:229:3): gapply() Arrow optimization - type collect(ret) not equal to `rdf`. Component “b”: 'tzone' attributes are inconsistent ('UTC' and '') ── 4. Error (test_sparkSQL.R:1454:3): column functions ───────────────────────── Error: (converted from warning) cannot xtfrm data frames Backtrace: 1. base::sort(collect(distinct(select(df, input_file_name())))) test_sparkSQL.R:1454:2 2. base::sort.default(collect(distinct(select(df, input_file_name())))) 5. base::order(x, na.last = na.last, decreasing = decreasing) 6. base::lapply(z, function(x) if (is.object(x)) as.vector(xtfrm(x)) else x) 7. base:::FUN(X[[i]], ...) 10. base::xtfrm.data.frame(x) ── 5. Failure (test_utils.R:67:3): cleanClosure on R functions ───────────────── `actual` not equal to `g`. names for current but not for target Length mismatch: comparison on first 0 components ── 6. Failure (test_utils.R:80:3): cleanClosure on R functions ───────────────── `actual` not equal to `g`. names for current but not for target Length mismatch: comparison on first 0 components ``` It fixes three as below: - Avoid a sort on DataFrame which isn't legitimate: https://github.com/apache/spark/pull/32709#discussion_r642458108 - Treat the empty timezone and local timezone as equivalent in SparkR: https://github.com/apache/spark/pull/32709#discussion_r642464454 - Disable `check.environment` in the cleaned closure comparison (enabled by default from R 4.1+, https://cran.r-project.org/doc/manuals/r-release/NEWS.html), and keep the test as is https://github.com/apache/spark/pull/32709#discussion_r642510089 Higher R versions have bug fixes and improvements. More importantly R users tend to use highest R versions. Yes, SparkR will work together with R 4.1.0+ ```bash ./R/run-tests.sh ``` ``` sparkSQL_arrow: SparkSQL Arrow optimization: ................. ... sparkSQL: SparkSQL functions: ........................................................................................................................................................................................................ ........................................................................................................................................................................................................ ........................................................................................................................................................................................................ ........................................................................................................................................................................................................ ........................................................................................................................................................................................................ ........................................................................................................................................................................................................ ... utils: functions in utils.R: .............................................. ``` Closes #32709 from HyukjinKwon/SPARK-35573. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 1ba1b70cfe24f94b882ebc2dcc6f18d8638596a2) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 01 June 2021, 01:37:13 UTC |
| e33972e | Liang-Chi Hsieh | 31 May 2021, 07:45:56 UTC | [SPARK-35566][SS] Fix StateStoreRestoreExec output rows ### What changes were proposed in this pull request? This is a minor change to update how `StateStoreRestoreExec` computes its number of output rows. Previously we only count input rows, but the optionally restored rows are not counted in. ### Why are the changes needed? Currently the number of output rows of `StateStoreRestoreExec` only counts the each input row. But it actually outputs input rows + optional restored rows. We should provide correct number of output rows. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests. Closes #32703 from viirya/fix-outputrows. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 73ba4492b1deea953e4f22dbf36dfcacd81c0f8a) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 31 May 2021, 07:46:29 UTC |
| 246827f | Felix Cheung | 24 May 2021, 02:08:54 UTC | [SPARK-35495][R] Change SparkR maintainer for CRAN ### What changes were proposed in this pull request? As discussed, update SparkR maintainer for future release. ### Why are the changes needed? Shivaram will not be able to work with this in the future, so we would like to migrate off the maintainer contact email. shivaram Closes #32642 from felixcheung/sparkr-maintainer. Authored-by: Felix Cheung <felixcheung@users.noreply.github.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 1530876615a64b009fff261da1ba064d03778fca) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 24 May 2021, 02:09:34 UTC |
| 3298959 | Kent Yao | 23 May 2021, 15:07:57 UTC | [SPARK-35493][K8S] make `spark.blockManager.port` fallback for `spark.driver.blockManager.port` as same as other cluster managers ### What changes were proposed in this pull request? `spark.blockManager.port` does not work for k8s driver pods now, we should make it work as other cluster managers. ### Why are the changes needed? `spark.blockManager.port` should be able to work for spark driver pod ### Does this PR introduce _any_ user-facing change? yes, `spark.blockManager.port` will be respect iff it is present && `spark.driver.blockManager.port` is absent ### How was this patch tested? new tests Closes #32639 from yaooqinn/SPARK-35493. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 96b0548ab6d5fe36833812f7b6424c984f75c6dd) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 23 May 2021, 15:11:43 UTC |
| 4994c7b | Liang-Chi Hsieh | 23 May 2021, 02:13:33 UTC | [SPARK-35463][BUILD][FOLLOWUP] Redirect output for skipping checksum check ### What changes were proposed in this pull request? This patch is a followup of SPARK-35463. In SPARK-35463, we output a message to stdout and now we redirect it to stderr. ### Why are the changes needed? All `echo` statements in `build/mvn` should redirect to stderr if it is not followed by `exit`. It is because we use `build/mvn` to get stdout output by other scripts. If we don't redirect it, we can get invalid output, e.g. got "Skipping checksum because shasum is not installed." as `commons-cli` version. ### Does this PR introduce _any_ user-facing change? No. Dev only. ### How was this patch tested? Manually test on internal system. Closes #32637 from viirya/fix-build. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 594ffd2db224c89f5375645a7a249d4befca6163) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 23 May 2021, 02:14:00 UTC |
| ce63b9a | Kent Yao | 22 May 2021, 04:57:43 UTC | [SPARK-35482][K8S][3.0] Use `spark.blockManager.port` not the wrong `spark.blockmanager.port` in `BasicExecutorFeatureStep` backport #32621 to 3.0 ### What changes were proposed in this pull request? most spark conf keys are case sensitive, including `spark.blockManager.port`, we can not get the correct port number with `spark.blockmanager.port`. This PR changes the wrong key to `spark.blockManager.port` in `BasicExecutorFeatureStep`. This PR also ensures a fast fail when the port value is invalid for executor containers. When 0 is specified(it is valid as random port, but invalid as a k8s request), it should not be put in the `containerPort` field of executor pod desc. We do not expect executor pods to continuously fail to create because of invalid requests. ### Why are the changes needed? bugfix ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? new tests Closes #32624 from yaooqinn/backport. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 22 May 2021, 04:57:43 UTC |
| 90a30c4 | Dongjoon Hyun | 20 May 2021, 21:36:50 UTC | [SPARK-35463][BUILD] Skip checking checksum on a system without `shasum` ### What changes were proposed in this pull request? Not every build system has `shasum`. This PR aims to skip checksum checks on a system without `shasum`. ### Why are the changes needed? **PREPARE** ``` $ docker run -it --rm -v $PWD:/spark openjdk:11-slim /bin/bash roota0e001a6e50f:/# cd /spark/ roota0e001a6e50f:/spark# apt-get update roota0e001a6e50f:/spark# apt-get install curl roota0e001a6e50f:/spark# build/mvn clean ``` **BEFORE (Failure due to `command not found`)** ``` roota0e001a6e50f:/spark# build/mvn clean exec: curl --silent --show-error -L https://downloads.lightbend.com/scala/2.12.10/scala-2.12.10.tgz exec: curl --silent --show-error -L https://www.apache.org/dyn/closer.lua/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz?action=download exec: curl --silent --show-error -L https://archive.apache.org/dist/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz.sha512 Veryfing checksum from /spark/build/apache-maven-3.6.3-bin.tar.gz.sha512 build/mvn: line 81: shasum: command not found Bad checksum from https://archive.apache.org/dist/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz.sha512 ``` **AFTER** ``` roota0e001a6e50f:/spark# build/mvn clean exec: curl --silent --show-error -L https://downloads.lightbend.com/scala/2.12.10/scala-2.12.10.tgz Skipping checksum because shasum is not installed. exec: curl --silent --show-error -L https://www.apache.org/dyn/closer.lua/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz?action=download exec: curl --silent --show-error -L https://archive.apache.org/dist/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz.sha512 Skipping checksum because shasum is not installed. Using `mvn` from path: /spark/build/apache-maven-3.6.3/bin/mvn ``` ### Does this PR introduce _any_ user-facing change? Yes, this will recover the build. ### How was this patch tested? Manually with the above process. Closes #32613 from dongjoon-hyun/SPARK-35463. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 8e13b8c3d233b910a6bebbb89fb58fcc6b299e9f) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 20 May 2021, 21:37:22 UTC |
| 0800608 | Yikun Jiang | 20 May 2021, 20:59:13 UTC | [SPARK-35458][BUILD] Use ` > /dev/null` to replace `-q` in shasum ## What changes were proposed in this pull request? Use ` > /dev/null` to replace `-q` in shasum validation. ### Why are the changes needed? In PR https://github.com/apache/spark/pull/32505 , added the shasum check on maven. The `shasum -a 512 -q -c xxx.sha` is used to validate checksum, the `-q` args is for "don't print OK for each successfully verified file", but `-q` arg is introduce in shasum 6.x version. So we got the `Unknown option: q`. ``` ➜ ~ uname -a Darwin MacBook.local 19.6.0 Darwin Kernel Version 19.6.0: Mon Apr 12 20:57:45 PDT 2021; root:xnu-6153.141.28.1~1/RELEASE_X86_64 x86_64 ➜ ~ shasum -v 5.84 ➜ ~ shasum -q Unknown option: q Type shasum -h for help ``` it makes ARM CI failed: [1] https://amplab.cs.berkeley.edu/jenkins/job/spark-master-test-maven-arm/ ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? `shasum -a 512 -c wrong.sha > /dev/null` return code 1 without print `shasum -a 512 -c right.sha > /dev/null` return code 0 without print e2e test: ``` rm -f build/apache-maven-3.6.3-bin.tar.gz rm -r build/apache-maven-3.6.3-bin mvn -v ``` Closes #32604 from Yikun/patch-5. Authored-by: Yikun Jiang <yikunkero@gmail.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 38fbc0b4f77dbdd1ed9a69ca7ab170c7ccee04bc) Signed-off-by: Sean Owen <srowen@gmail.com> | 20 May 2021, 20:59:35 UTC |
| 89c4b27 | Yikun Jiang | 20 May 2021, 17:25:23 UTC | [SPARK-35373][BUILD][FOLLOWUP] Fix "binary operator expected" error on build/mvn ### What changes were proposed in this pull request? change $(command -v curl) to "$(command -v curl)" ### Why are the changes needed? We need change $(command -v curl) to "$(command -v curl)" to make sure it work when `curl` or `wget` is uninstall. othewise raised: `build/mvn: line 56: [: /root/spark/build/apache-maven-3.6.3-bin.tar.gz: binary operator expected` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? ``` apt remove curl rm -f build/apache-maven-3.6.3-bin.tar.gz rm -r build/apache-maven-3.6.3-bin mvn -v ``` Closes #32608 from Yikun/patch-6. Authored-by: Yikun Jiang <yikunkero@gmail.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 3c3533d845bd121a9e094ac6c17a0fb3684e269c) Signed-off-by: Sean Owen <srowen@gmail.com> | 20 May 2021, 17:25:42 UTC |
| d4b637e | Dongjoon Hyun | 19 May 2021, 16:51:58 UTC | [SPARK-35373][BUILD][FOLLOWUP][3.1] Update zinc installation ### What changes were proposed in this pull request? This PR is a follow-up of https://github.com/apache/spark/pull/32505 to fix `zinc` installation. ### Why are the changes needed? Currently, branch-3.1/3.0 is broken. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass the GitHub Action. Closes #32591 from dongjoon-hyun/SPARK-35373. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 50edf1246809ffe2b142cab4a9dc4e4e72df3fe7) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 19 May 2021, 16:52:18 UTC |
| 706f91e | Sean Owen | 13 May 2021, 14:06:57 UTC | [SPARK-35373][BUILD] Check Maven artifact checksum in build/mvn ### What changes were proposed in this pull request? `./build/mvn` now downloads the .sha512 checksum of Maven artifacts it downloads, and checks the checksum after download. ### Why are the changes needed? This ensures the integrity of the Maven artifact during a user's build, which may come from several non-ASF mirrors. ### Does this PR introduce _any_ user-facing change? Should not affect anything about Spark per se, just the build. ### How was this patch tested? Manual testing wherein I forced Maven/Scala download, verified checksums are downloaded and checked, and verified it fails on error with a corrupted checksum. Closes #32505 from srowen/SPARK-35373. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Sean Owen <srowen@gmail.com> | 19 May 2021, 14:05:34 UTC |
| 1606791 | Andy Grove | 19 May 2021, 12:45:26 UTC | [SPARK-35093][SQL] AQE now uses newQueryStage plan as key for looking up cached exchanges for re-use ### What changes were proposed in this pull request? AQE has an optimization where it attempts to reuse compatible exchanges but it does not take into account whether the exchanges are columnar or not, resulting in incorrect reuse under some circumstances. This PR simply changes the key used to lookup cached stages. It now uses the canonicalized form of the new query stage (potentially created by a plugin) rather than using the canonicalized form of the original exchange. ### Why are the changes needed? When using the [RAPIDS Accelerator for Apache Spark](https://github.com/NVIDIA/spark-rapids) we sometimes see a new query stage correctly create a row-based exchange and then Spark replaces it with a cached columnar exchange, which is not compatible, and this causes queries to fail. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? The patch has been tested with the query that highlighted this issue. I looked at writing unit tests for this but it would involve implementing a mock columnar exchange in the tests so would be quite a bit of work. If anyone has ideas on other ways to test this I am happy to hear them. Closes #32195 from andygrove/SPARK-35093. Authored-by: Andy Grove <andygrove73@gmail.com> Signed-off-by: Thomas Graves <tgraves@apache.org> (cherry picked from commit 52e3cf9ff50b4209e29cb06df09b1ef3a18bc83b) Signed-off-by: Thomas Graves <tgraves@apache.org> | 19 May 2021, 12:47:49 UTC |
| 0f78d8b | Yuzhou Sun | 19 May 2021, 07:46:27 UTC | [SPARK-35106][CORE][SQL] Avoid failing rename caused by destination directory not exist ### What changes were proposed in this pull request? 1. In HadoopMapReduceCommitProtocol, create parent directory before renaming custom partition path staging files 2. In InMemoryCatalog and HiveExternalCatalog, create new partition directory before renaming old partition path 3. Check return value of FileSystem#rename, if false, throw exception to avoid silent data loss cause by rename failure 4. Change DebugFilesystem#rename behavior to make it match HDFS's behavior (return false without rename when dst parent directory not exist) ### Why are the changes needed? Depends on FileSystem#rename implementation, when destination directory does not exist, file system may 1. return false without renaming file nor throwing exception (e.g. HDFS), or 2. create destination directory, rename files, and return true (e.g. LocalFileSystem) In the first case above, renames in HadoopMapReduceCommitProtocol for custom partition path will fail silently if the destination partition path does not exist. Failed renames can happen when 1. dynamicPartitionOverwrite == true, the custom partition path directories are deleted by the job before the rename; or 2. the custom partition path directories do not exist before the job; or 3. something else is wrong when file system handle `rename` The renames in MemoryCatalog and HiveExternalCatalog for partition renaming also have similar issue. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Modified DebugFilesystem#rename, and added new unit tests. Without the fix in src code, five InsertSuite tests and one AlterTableRenamePartitionSuite test failed: InsertSuite.SPARK-20236: dynamic partition overwrite with custom partition path (existing test with modified FS) ``` == Results == !== Correct Answer - 1 == == Spark Answer - 0 == struct<> struct<> ![2,1,1] ``` InsertSuite.SPARK-35106: insert overwrite with custom partition path ``` == Results == !== Correct Answer - 1 == == Spark Answer - 0 == struct<> struct<> ![2,1,1] ``` InsertSuite.SPARK-35106: dynamic partition overwrite with custom partition path ``` == Results == !== Correct Answer - 2 == == Spark Answer - 1 == !struct<> struct<i:int,part1:int,part2:int> [1,1,1] [1,1,1] ![1,1,2] ``` InsertSuite.SPARK-35106: Throw exception when rename custom partition paths returns false ``` Expected exception org.apache.spark.SparkException to be thrown, but no exception was thrown ``` InsertSuite.SPARK-35106: Throw exception when rename dynamic partition paths returns false ``` Expected exception org.apache.spark.SparkException to be thrown, but no exception was thrown ``` AlterTableRenamePartitionSuite.ALTER TABLE .. RENAME PARTITION V1: multi part partition (existing test with modified FS) ``` == Results == !== Correct Answer - 1 == == Spark Answer - 0 == struct<> struct<> ![3,123,3] ``` Closes #32530 from YuzhouSun/SPARK-35106. Authored-by: Yuzhou Sun <yuzhosun@amazon.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit a72d05c7e632fbb0d8a6082c3cacdf61f36518b4) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 19 May 2021, 07:47:11 UTC |
| 180fae8 | Kousuke Saruta | 18 May 2021, 16:39:02 UTC | [SPARK-35425][BUILD][3.0] Pin jinja2 in spark-rm/Dockerfile and add as a required dependency in the release README.md ### What changes were proposed in this pull request? This PR backports SPARK-35425 (#32573). The following two things are done in this PR. * Add note about Jinja2 as a required dependency for document build. * Add Jinja2 dependency for the document build to `spark-rm/Dockerfile` ### Why are the changes needed? SPARK-35375(#32509) confined the version of Jinja to <3.0.0. So it's good to note about it in `docs/README.md` and add the dependency to `spark-rm/Dockerfile`. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? I confimed that `make html` succeed under `python/docs` with dependencies installed by both of the following commands. ``` pip install sphinx==2.3.1 mkdocs==1.0.4 numpy==1.18.1 jinja2==2.11.3 pip install 'sphinx<3.5.0' mkdocs numpy 'jinja2<3.0.0' ``` Closes #32579 from sarutak/backport-SPARK-35425-branch-3.0. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 18 May 2021, 16:39:02 UTC |
| 8ebc1d3 | Takeshi Yamamuro | 17 May 2021, 00:26:04 UTC | [SPARK-35413][INFRA] Use the SHA of the latest commit when checking out databricks/tpcds-kit ### What changes were proposed in this pull request? This PR proposes to use the SHA of the latest commit ([2a5078a782192ddb6efbcead8de9973d6ab4f069](https://github.com/databricks/tpcds-kit/commit/2a5078a782192ddb6efbcead8de9973d6ab4f069)) when checking out `databricks/tpcds-kit`. This can prevent the test workflow from breaking accidentally if the repository changes drastically. ### Why are the changes needed? For better test workflow. ### Does this PR introduce _any_ user-facing change? No, dev-only. ### How was this patch tested? GA passed. Closes #32561 from maropu/UseRefInCheckout. Authored-by: Takeshi Yamamuro <yamamuro@apache.org> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org> (cherry picked from commit 2390b9dbcbc0b0377d694d2c3c2c0fa78179cbd6) Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org> | 17 May 2021, 00:27:02 UTC |
| d160cd2 | Oleksandr Shevchenko | 14 May 2021, 18:26:35 UTC | [SPARK-35405][DOC] Submitting Applications documentation has outdated information about K8s client mode support ### What changes were proposed in this pull request? [Submitting Applications doc](https://spark.apache.org/docs/latest/submitting-applications.html#master-urls) has outdated information about K8s client mode support. It still says "Client mode is currently unsupported and will be supported in future releases".  Whereas it's already supported and [Running Spark on Kubernetes doc](https://spark.apache.org/docs/latest/running-on-kubernetes.html#client-mode) says that it's supported started from 2.4.0 and has all needed information.  Changes:  JIRA: https://issues.apache.org/jira/browse/SPARK-35405 ### Why are the changes needed? Outdated information in the doc is misleading ### Does this PR introduce _any_ user-facing change? Documentation changes ### How was this patch tested? Documentation changes Closes #32551 from o-shevchenko/SPARK-35405. Authored-by: Oleksandr Shevchenko <oleksandr.shevchenko@datarobot.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit d2fbf0dce43cbc5bde99d572817011841d6a3d41) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 14 May 2021, 18:27:19 UTC |
| f8d0688 | Hyukjin Kwon | 13 May 2021, 17:35:56 UTC | [SPARK-35393][PYTHON][INFRA][TESTS] Recover pip packaging test in Github Actions Currently pip packaging test is being skipped: ``` ======================================================================== Running PySpark packaging tests ======================================================================== Constructing virtual env for testing Missing virtualenv & conda, skipping pip installability tests Cleaning up temporary directory - /tmp/tmp.iILYWISPXW ``` See https://github.com/apache/spark/runs/2568923639?check_suite_focus=true GitHub Actions's image has its default Conda installed at `/usr/share/miniconda` but seems like the image we're using for PySpark does not have it (which is legitimate). This PR proposes to install Conda to use in pip packaging tests in GitHub Actions. To recover the test coverage. No, dev-only. It was tested in my fork: https://github.com/HyukjinKwon/spark/runs/2575126882?check_suite_focus=true ``` ======================================================================== Running PySpark packaging tests ======================================================================== Constructing virtual env for testing Using conda virtual environments Testing pip installation with python 3.6 Using /tmp/tmp.qPjTenqfGn for virtualenv Collecting package metadata (current_repodata.json): ...working... done Solving environment: ...working... failed with repodata from current_repodata.json, will retry with next repodata source. Collecting package metadata (repodata.json): ...working... done Solving environment: ...working... done environment location: /tmp/tmp.qPjTenqfGn/3.6 added / updated specs: - numpy - pandas - pip - python=3.6 - setuptools ... Successfully ran pip sanity check ``` Closes #32537 from HyukjinKwon/SPARK-35393. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 7d371d27f2a974b682ffa16b71576e61e9338c34) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 14 May 2021, 01:49:44 UTC |
| ce8922d | Liang-Chi Hsieh | 10 May 2021, 07:29:05 UTC | [SPARK-35358][BUILD] Increase maximum Java heap used for release build to avoid OOM ### What changes were proposed in this pull request? This patch proposes to increase the maximum heap memory setting for release build. ### Why are the changes needed? When I was cutting RCs for 2.4.8, I frequently encountered OOM during building using mvn. It happens many times until I increased the heap memory setting. I am not sure if other release managers encounter the same issue. So I propose to increase the heap memory setting and see if it looks good for others. ### Does this PR introduce _any_ user-facing change? No, dev only. ### How was this patch tested? Manually used it during cutting RCs of 2.4.8. Closes #32487 from viirya/release-mvn-oom. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 20d32242a2574637d18771c2f7de5c9878f85bad) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 9623ccb60e292858f5d9ca614a9c31a98dbcdb22) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 10 May 2021, 07:30:12 UTC |
| 190c57b | Takeshi Yamamuro | 09 May 2021, 02:25:15 UTC | [SPARK-34795][SPARK-35192][SPARK-35293][SPARK-35327][SQL][TESTS][3.0] Adds a new job in GitHub Actions to check the output of TPC-DS queries ### What changes were proposed in this pull request? This PR proposes to add a new job in GitHub Actions to check the output of TPC-DS queries. NOTE: To generate TPC-DS table data in GA jobs, this PR includes generator code implemented in https://github.com/apache/spark/pull/32243 and https://github.com/apache/spark/pull/32460. This is the backport PR of https://github.com/apache/spark/pull/31886. ### Why are the changes needed? There are some cases where we noticed runtime-realted bugs after merging commits (e.g. .SPARK-33822). Therefore, I think it is worth adding a new job in GitHub Actions to check query output of TPC-DS (sf=1). ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? The new test added. Closes #32479 from maropu/TPCDSQueryTestSuite-Branch3.0. Authored-by: Takeshi Yamamuro <yamamuro@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 09 May 2021, 02:25:15 UTC |
| 2831c62 | Dongjoon Hyun | 08 May 2021, 20:02:08 UTC | Revert "[SPARK-35321][SQL][3.0] Don't register Hive permanent functions when creating Hive client" This reverts commit 5268a38878921d47d51cc04ab1863aed250bf06e. | 08 May 2021, 20:02:08 UTC |
| 5268a38 | Chao Sun | 08 May 2021, 00:41:10 UTC | [SPARK-35321][SQL][3.0] Don't register Hive permanent functions when creating Hive client This is a backport of #32446 for branch-3.0 ### What changes were proposed in this pull request? Instantiate a new Hive client through `Hive.getWithFastCheck(conf, false)` instead of `Hive.get(conf)`. ### Why are the changes needed? [HIVE-10319](https://issues.apache.org/jira/browse/HIVE-10319) introduced a new API `get_all_functions` which is only supported in Hive 1.3.0/2.0.0 and up. As result, when Spark 3.x talks to a HMS service of version 1.2 or lower, the following error will occur: ``` Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.thrift.TApplicationException: Invalid method name: 'get_all_functions' at org.apache.hadoop.hive.ql.metadata.Hive.getAllFunctions(Hive.java:3897) at org.apache.hadoop.hive.ql.metadata.Hive.reloadFunctions(Hive.java:248) at org.apache.hadoop.hive.ql.metadata.Hive.registerAllFunctionsOnce(Hive.java:231) ... 96 more Caused by: org.apache.thrift.TApplicationException: Invalid method name: 'get_all_functions' at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:79) at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.recv_get_all_functions(ThriftHiveMetastore.java:3845) at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.get_all_functions(ThriftHiveMetastore.java:3833) ``` The `get_all_functions` is called only when `doRegisterAllFns` is set to true: ```java private Hive(HiveConf c, boolean doRegisterAllFns) throws HiveException { conf = c; if (doRegisterAllFns) { registerAllFunctionsOnce(); } } ``` what this does is to register all Hive permanent functions defined in HMS in Hive's `FunctionRegistry` class, via iterating through results from `get_all_functions`. To Spark, this seems unnecessary as it loads Hive permanent (not built-in) UDF via directly calling the HMS API, i.e., `get_function`. The `FunctionRegistry` is only used in loading Hive's built-in function that is not supported by Spark. At this time, it only applies to `histogram_numeric`. ### Does this PR introduce _any_ user-facing change? Yes with this fix Spark now should be able to talk to HMS server with Hive 1.2.x and lower (with HIVE-24608 too) ### How was this patch tested? Manually started a HMS server of Hive version 1.2.2, with patched Hive 2.3.8 using HIVE-24608. Without the PR it failed with the above exception. With the PR the error disappeared and I can successfully perform common operations such as create table, create database, list tables, etc. Closes #32471 from sunchao/SPARK-35321-3.0. Authored-by: Chao Sun <sunchao@apache.org> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 08 May 2021, 00:41:10 UTC |
| b190e2b | Liang-Chi Hsieh | 07 May 2021, 16:07:57 UTC | [SPARK-35288][SQL] StaticInvoke should find the method without exact argument classes match ### What changes were proposed in this pull request? This patch proposes to make StaticInvoke able to find method with given method name even the parameter types do not exactly match to argument classes. ### Why are the changes needed? Unlike `Invoke`, `StaticInvoke` only tries to get the method with exact argument classes. If the calling method's parameter types are not exactly matched with the argument classes, `StaticInvoke` cannot find the method. `StaticInvoke` should be able to find the method under the cases too. ### Does this PR introduce _any_ user-facing change? Yes. `StaticInvoke` can find a method even the argument classes are not exactly matched. ### How was this patch tested? Unit test. Closes #32413 from viirya/static-invoke. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> (cherry picked from commit 33fbf5647b4a5587c78ac51339c0cbc9d70547a4) Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 07 May 2021, 16:09:01 UTC |
| 8ef4023 | dsolow | 05 May 2021, 03:46:13 UTC | [SPARK-34794][SQL] Fix lambda variable name issues in nested DataFrame functions ### What changes were proposed in this pull request? To fix lambda variable name issues in nested DataFrame functions, this PR modifies code to use a global counter for `LambdaVariables` names created by higher order functions. This is the rework of #31887. Closes #31887. ### Why are the changes needed? This moves away from the current hard-coded variable names which break on nested function calls. There is currently a bug where nested transforms in particular fail (the inner variable shadows the outer variable) For this query: ``` val df = Seq( (Seq(1,2,3), Seq("a", "b", "c")) ).toDF("numbers", "letters") df.select( f.flatten( f.transform( $"numbers", (number: Column) => { f.transform( $"letters", (letter: Column) => { f.struct( number.as("number"), letter.as("letter") ) } ) } ) ).as("zipped") ).show(10, false) ``` This is the current (incorrect) output: ``` +------------------------------------------------------------------------+ |zipped | +------------------------------------------------------------------------+ |[{a, a}, {b, b}, {c, c}, {a, a}, {b, b}, {c, c}, {a, a}, {b, b}, {c, c}]| +------------------------------------------------------------------------+ ``` And this is the correct output after fix: ``` +------------------------------------------------------------------------+ |zipped | +------------------------------------------------------------------------+ |[{1, a}, {1, b}, {1, c}, {2, a}, {2, b}, {2, c}, {3, a}, {3, b}, {3, c}]| +------------------------------------------------------------------------+ ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added the new test in `DataFrameFunctionsSuite`. Closes #32424 from maropu/pr31887. Lead-authored-by: dsolow <dsolow@sayari.com> Co-authored-by: Takeshi Yamamuro <yamamuro@apache.org> Co-authored-by: dmsolow <dsolow@sayarianalytics.com> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org> (cherry picked from commit f550e03b96638de93381734c4eada2ace02d9a4f) Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org> | 05 May 2021, 03:47:07 UTC |
| 07ec25f | Liang-Chi Hsieh | 01 May 2021, 17:20:46 UTC | [SPARK-35278][SQL] Invoke should find the method with correct number of parameters ### What changes were proposed in this pull request? This patch fixes `Invoke` expression when the target object has more than one method with the given method name. ### Why are the changes needed? `Invoke` will find out the method on the target object with given method name. If there are more than one method with the name, currently it is undeterministic which method will be used. We should add the condition of parameter number when finding the method. ### Does this PR introduce _any_ user-facing change? Yes, fixed a bug when using `Invoke` on a object where more than one method with the given method name. ### How was this patch tested? Unit test. Closes #32404 from viirya/verify-invoke-param-len. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> (cherry picked from commit 6ce1b161e96176777344beb610163636e7dfeb00) Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 01 May 2021, 17:21:20 UTC |
| c6659e6 | Angerszhuuuu | 28 April 2021, 10:15:29 UTC | [SPARK-35159][SQL][DOCS][3.0] Extract hive format doc ### What changes were proposed in this pull request? Extract common doc about hive format for `sql-ref-syntax-ddl-create-table-hiveformat.md` and `sql-ref-syntax-qry-select-transform.md` to refer.  ### Why are the changes needed? Improve doc ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Not need Closes #32378 from AngersZhuuuu/SPARK-35159-3.0. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org> | 28 April 2021, 10:15:29 UTC |
| a556bc8 | Angerszhuuuu | 28 April 2021, 07:54:44 UTC | [SPARK-33976][SQL][DOCS][3.0] Add a SQL doc page for a TRANSFORM clause ### What changes were proposed in this pull request? Add doc about `TRANSFORM` and related function.  ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Not need Closes #32375 from AngersZhuuuu/SPARK-33976-3.0. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org> | 28 April 2021, 07:54:44 UTC |
| 6e83789 | Wenchen Fan | 28 April 2021, 01:45:04 UTC | [SPARK-35244][SQL] Invoke should throw the original exception ### What changes were proposed in this pull request? This PR updates the interpreted code path of invoke expressions, to unwrap the `InvocationTargetException` ### Why are the changes needed? Make interpreted and codegen path consistent for invoke expressions. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? new UT Closes #32370 from cloud-fan/minor. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: hyukjinkwon <gurwls223@apache.org> | 28 April 2021, 06:00:51 UTC |
| 5ca67d6 | Bo Zhang | 27 April 2021, 01:59:30 UTC | [SPARK-35227][BUILD] Update the resolver for spark-packages in SparkSubmit This change is to use repos.spark-packages.org instead of Bintray as the repository service for spark-packages. The change is needed because Bintray will no longer be available from May 1st. This should be transparent for users who use SparkSubmit. Tested running spark-shell with --packages manually. Closes #32346 from bozhang2820/replace-bintray. Authored-by: Bo Zhang <bo.zhang@databricks.com> Signed-off-by: hyukjinkwon <gurwls223@apache.org> (cherry picked from commit f738fe07b6fc85c880b64a1cc2f6c7cc1cc1379b) Signed-off-by: hyukjinkwon <gurwls223@apache.org> | 27 April 2021, 02:01:47 UTC |
| ae57b2a | Shixiong Zhu | 26 April 2021, 23:07:09 UTC | [SPARK-28247][SS][TEST] Fix flaky test "query without test harness" on ContinuousSuite ### What changes were proposed in this pull request? This is another attempt to fix the flaky test "query without test harness" on ContinuousSuite. `query without test harness` is flaky because it starts a continuous query with two partitions but assumes they will run at the same speed. In this test, 0 and 2 will be written to partition 0, 1 and 3 will be written to partition 1. It assumes when we see 3, 2 should be written to the memory sink. But this is not guaranteed. We can add `if (currentValue == 2) Thread.sleep(5000)` at this line https://github.com/apache/spark/blob/b2a2b5d8206b7c09b180b8b6363f73c6c3fdb1d8/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/continuous/ContinuousRateStreamSource.scala#L135 to reproduce the failure: `Result set Set([0], [1], [3]) are not a superset of Set(0, 1, 2, 3)!` The fix is changing `waitForRateSourceCommittedValue` to wait until all partitions reach the desired values before stopping the query. ### Why are the changes needed? Fix a flaky test. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests. Manually verify the reproduction I mentioned above doesn't fail after this change. Closes #32316 from zsxwing/SPARK-28247-fix. Authored-by: Shixiong Zhu <zsxwing@gmail.com> Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com> (cherry picked from commit 0df3b501aeb2a88997e5a68a6a8f8e7f5196342c) Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com> | 26 April 2021, 23:08:29 UTC |
| 12c8193 | Chao Sun | 26 April 2021, 21:10:42 UTC | [SPARK-35233][3.0][BUILD] Switch from bintray to scala.jfrog.io for SBT download in branch 2.4 and 3.0 ### What changes were proposed in this pull request? Move SBT download URL from `https://dl.bintray.com/typesafe` to `https://scala.jfrog.io/artifactory`. ### Why are the changes needed? As [bintray is sunsetting](https://jfrog.com/blog/into-the-sunset-bintray-jcenter-gocenter-and-chartcenter/), we should migrate SBT download location away from it. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Tested manually and it is working, while previously it was failing because SBT 0.13.17 can't be found: ``` Attempting to fetch sbt Our attempt to download sbt locally to build/sbt-launch-0.13.17.jar failed. Please install sbt manually from http://www.scala-sbt.org/ ``` Closes #32353 from sunchao/SPARK-35233-3.0. Authored-by: Chao Sun <sunchao@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 26 April 2021, 21:10:42 UTC |
| d433457 | Max Gekk | 26 April 2021, 09:41:15 UTC | [SPARK-35224][SQL][TESTS][3.1][3.0] Fix buffer overflow in `MutableProjectionSuite` ### What changes were proposed in this pull request? In the test `"unsafe buffer with NO_CODEGEN"` of `MutableProjectionSuite`, fix unsafe buffer size calculation to be able to place all input fields without buffer overflow + meta-data. ### Why are the changes needed? To make the test suite `MutableProjectionSuite` more stable. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? By running the affected test suite: ``` $ build/sbt "test:testOnly *MutableProjectionSuite" ``` Authored-by: Max Gekk <max.gekkgmail.com> Signed-off-by: Max Gekk <max.gekkgmail.com> (cherry picked from commit d572a859891547f73b57ae8c9a3b800c48029678) Closes #32347 from MaxGekk/fix-buffer-overflow-MutableProjectionSuite-3.1. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> (cherry picked from commit c59db3d294cadb53d4a6729649e86b69058262af) Signed-off-by: Max Gekk <max.gekk@gmail.com> | 26 April 2021, 09:41:37 UTC |
| 4fa0e7f | Kent Yao | 25 April 2021, 12:27:12 UTC | [SPARK-35168][SQL] mapred.reduce.tasks should be shuffle.partitions not adaptive.coalescePartitions.initialPartitionNum ### What changes were proposed in this pull request? ```sql spark-sql> set spark.sql.adaptive.coalescePartitions.initialPartitionNum=1; spark.sql.adaptive.coalescePartitions.initialPartitionNum 1 Time taken: 2.18 seconds, Fetched 1 row(s) spark-sql> set mapred.reduce.tasks; 21/04/21 14:27:11 WARN SetCommand: Property mapred.reduce.tasks is deprecated, showing spark.sql.shuffle.partitions instead. spark.sql.shuffle.partitions 1 Time taken: 0.03 seconds, Fetched 1 row(s) spark-sql> set spark.sql.shuffle.partitions; spark.sql.shuffle.partitions 200 Time taken: 0.024 seconds, Fetched 1 row(s) spark-sql> set mapred.reduce.tasks=2; 21/04/21 14:31:52 WARN SetCommand: Property mapred.reduce.tasks is deprecated, automatically converted to spark.sql.shuffle.partitions instead. spark.sql.shuffle.partitions 2 Time taken: 0.017 seconds, Fetched 1 row(s) spark-sql> set mapred.reduce.tasks; 21/04/21 14:31:55 WARN SetCommand: Property mapred.reduce.tasks is deprecated, showing spark.sql.shuffle.partitions instead. spark.sql.shuffle.partitions 1 Time taken: 0.017 seconds, Fetched 1 row(s) spark-sql> ``` `mapred.reduce.tasks` is mapping to `spark.sql.shuffle.partitions` at write-side, but `spark.sql.adaptive.coalescePartitions.initialPartitionNum` might take precede of `spark.sql.shuffle.partitions` ### Why are the changes needed? roundtrip for `mapred.reduce.tasks` ### Does this PR introduce _any_ user-facing change? yes, `mapred.reduce.tasks` will always report `spark.sql.shuffle.partitions` whether `spark.sql.adaptive.coalescePartitions.initialPartitionNum` exists or not. ### How was this patch tested? a new test Closes #32265 from yaooqinn/SPARK-35168. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Kent Yao <yao@apache.org> (cherry picked from commit 5b1353f690bf416fdb3a34c94741425b95f97308) Signed-off-by: Kent Yao <yao@apache.org> | 25 April 2021, 12:28:05 UTC |
| ea678f3 | Kousuke Saruta | 24 April 2021, 22:10:54 UTC | [SPARK-35210][BUILD][3.0] Upgrade Jetty to 9.4.40 to fix ERR_CONNECTION_RESET issue ### What changes were proposed in this pull request? This PR backports SPARK-35210 (#32318). This PR proposes to upgrade Jetty to 9.4.40. ### Why are the changes needed? SPARK-34988 (#32091) upgraded Jetty to 9.4.39 for CVE-2021-28165. But after the upgrade, Jetty 9.4.40 was released to fix the ERR_CONNECTION_RESET issue (https://github.com/eclipse/jetty.project/issues/6152). This issue seems to affect Jetty 9.4.39 when POST method is used with SSL. For Spark, job submission using REST and ThriftServer with HTTPS protocol can be affected. ### Does this PR introduce _any_ user-facing change? No. No released version uses Jetty 9.3.39. ### How was this patch tested? CI. Closes #32323 from sarutak/backport-3.0-SPARK-35210. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 24 April 2021, 22:10:54 UTC |
| 4c79e10 | harupy | 24 April 2021, 21:36:44 UTC | [SPARK-35142][PYTHON][ML][3.0] Fix incorrect return type for `rawPredictionUDF` in `OneVsRestModel` ### What changes were proposed in this pull request? This PR backports https://github.com/apache/spark/pull/32245. Fixes incorrect return type for `rawPredictionUDF` in `OneVsRestModel`. ### Why are the changes needed? Bugfix ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test. Closes #32275 from harupy/backport-35142-3.0. Authored-by: harupy <17039389+harupy@users.noreply.github.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 24 April 2021, 21:36:44 UTC |
| 2abb948 | Yuming Wang | 24 April 2021, 12:14:09 UTC | [SPARK-34897][SQL][3.0] Support reconcile schemas based on index after nested column pruning This PR backports https://github.com/apache/spark/pull/31993 to branch-3.0. The origin PR description: ### What changes were proposed in this pull request? It will remove `StructField` when [pruning nested columns](https://github.com/apache/spark/blob/0f2c0b53e8fb18c86c67b5dd679c006db93f94a5/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/SchemaPruning.scala#L28-L42). For example: ```scala spark.sql( """ |CREATE TABLE t1 ( | _col0 INT, | _col1 STRING, | _col2 STRUCT<c1: STRING, c2: STRING, c3: STRING, c4: BIGINT>) |USING ORC |""".stripMargin) spark.sql("INSERT INTO t1 values(1, '2', struct('a', 'b', 'c', 10L))") spark.sql("SELECT _col0, _col2.c1 FROM t1").show ``` Before this pr. The returned schema is: ``` `_col0` INT,`_col2` STRUCT<`c1`: STRING> ``` add it will throw exception: ``` java.lang.AssertionError: assertion failed: The given data schema struct<_col0:int,_col2:struct<c1:string>> has less fields than the actual ORC physical schema, no idea which columns were dropped, fail to read. at scala.Predef$.assert(Predef.scala:223) at org.apache.spark.sql.execution.datasources.orc.OrcUtils$.requestedColumnIds(OrcUtils.scala:160) ``` After this pr. The returned schema is: ``` `_col0` INT,`_col1` STRING,`_col2` STRUCT<`c1`: STRING> ```. The finally schema is ``` `_col0` INT,`_col2` STRUCT<`c1`: STRING> ``` after the complete column pruning: https://github.com/apache/spark/blob/7a5647a93aaea9d1d78d9262e24fc8c010db04d0/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileSourceStrategy.scala#L208-L213 https://github.com/apache/spark/blob/e64eb75aede71a5403a4d4436e63b1fcfdeca14d/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/PushDownUtils.scala#L96-L97 ### Why are the changes needed? Fix bug. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Unit test. Closes #32310 from wangyum/SPARK-34897-3.0. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Yuming Wang <yumwang@ebay.com> | 24 April 2021, 12:14:09 UTC |
| 72db575 | kyoty | 22 April 2021, 12:00:04 UTC | [SPARK-35127][UI] When we switch between different stage-detail pages, the entry item in the newly-opened page may be blank ### What changes were proposed in this pull request? To make sure that pageSize shoud not be shared between different stage pages. The screenshots of the problem are placed in the attachment of [JIRA](https://issues.apache.org/jira/browse/SPARK-35127) ### Why are the changes needed? fix the bug. according to reference:`https://datatables.net/reference/option/lengthMenu` `-1` represents display all rows, but now we use `totalTasksToShow`, it will cause the select item show as empty when we swich between different stage-detail pages. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? manual test, it is a small io problem, and the modification does not affect the function, but just an adjustment of js configuration the gif below shows how the problem can be reproduced:   the gif below shows the result after modified:  Closes #32223 from kyoty/stages-task-empty-pagesize. Authored-by: kyoty <echohlne@gmail.com> Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com> (cherry picked from commit 7242d7f774b821cbcb564c8afeddecaf6664d159) Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com> | 22 April 2021, 12:00:59 UTC |
| 21e9e83 | sandeep.katta | 22 April 2021, 05:58:30 UTC | [SPARK-35096][SQL][3.0] SchemaPruning should adhere spark.sql.caseSensitive config ### What changes were proposed in this pull request? As a part of the SPARK-26837 pruning of nested fields from object serializers are supported. But it is missed to handle case insensitivity nature of spark In this PR I have resolved the column names to be pruned based on `spark.sql.caseSensitive ` config **Exception Before Fix** ``` Caused by: java.lang.ArrayIndexOutOfBoundsException: 0 at org.apache.spark.sql.types.StructType.apply(StructType.scala:414) at org.apache.spark.sql.catalyst.optimizer.ObjectSerializerPruning$$anonfun$apply$4.$anonfun$applyOrElse$3(objects.scala:216) at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238) at scala.collection.immutable.List.foreach(List.scala:392) at scala.collection.TraversableLike.map(TraversableLike.scala:238) at scala.collection.TraversableLike.map$(TraversableLike.scala:231) at scala.collection.immutable.List.map(List.scala:298) at org.apache.spark.sql.catalyst.optimizer.ObjectSerializerPruning$$anonfun$apply$4.applyOrElse(objects.scala:215) at org.apache.spark.sql.catalyst.optimizer.ObjectSerializerPruning$$anonfun$apply$4.applyOrElse(objects.scala:203) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDown$1(TreeNode.scala:309) at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:72) at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:309) at ``` ### Why are the changes needed? After Upgrade to Spark 3 `foreachBatch` API throws` java.lang.ArrayIndexOutOfBoundsException`. This issue will be fixed using this PR ### Does this PR introduce _any_ user-facing change? No, Infact fixes the regression ### How was this patch tested? Added tests and also tested verified manually Closes #32284 from sandeep-katta/SPARK-35096_backport. Authored-by: sandeep.katta <sandeep.katta2007@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 22 April 2021, 05:58:30 UTC |
| 7af1cb4 | Dongjoon Hyun | 22 April 2021, 03:11:28 UTC | Revert "[SPARK-35096][SQL] SchemaPruning should adhere spark.sql.caseSensitive config" This reverts commit aef17b740f48fe559520e1c958f7e22a4a00f698. | 22 April 2021, 03:11:28 UTC |
| b695ece | Dongjoon Hyun | 22 April 2021, 02:51:57 UTC | [SPARK-35178][BUILD][FOLLOWUP][3.1] Update Zinc argument ### What changes were proposed in this pull request? This is a follow-up to adjust zinc installation with the new parameter. ### Why are the changes needed? Currently, zinc is ignored. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manually. **BEFORE** ``` $ build/mvn clean exec: curl --silent --show-error -L https://downloads.lightbend.com/zinc/0.3.15 tar: Error opening archive: Unrecognized archive format exec: curl --silent --show-error -L https://downloads.lightbend.com/scala/2.12.10/scala-2.12.10.tgz exec: curl --silent --show-error -L https://www.apache.org/dyn/closer.lua/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz?action=download build/mvn: line 149: /Users/dongjoon/APACHE/spark-merge/build/zinc-0.3.15/bin/zinc: No such file or directory build/mvn: line 151: /Users/dongjoon/APACHE/spark-merge/build/zinc-0.3.15/bin/zinc: No such file or directory Using `mvn` from path: /Users/dongjoon/APACHE/spark-merge/build/apache-maven-3.6.3/bin/mvn [INFO] Scanning for projects... ``` **AFTER** ``` $ build/mvn clean exec: curl --silent --show-error -L https://downloads.lightbend.com/zinc/0.3.15/zinc-0.3.15.tgz exec: curl --silent --show-error -L https://downloads.lightbend.com/scala/2.12.10/scala-2.12.10.tgz exec: curl --silent --show-error -L https://www.apache.org/dyn/closer.lua/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz?action=download Using `mvn` from path: /Users/dongjoon/PRS/SPARK-PR-32282/build/apache-maven-3.6.3/bin/mvn [INFO] Scanning for projects... ``` Closes #32282 from dongjoon-hyun/SPARK-35178. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit b41624b439639206df9cbc0e95a6c61432fefd8e) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 22 April 2021, 02:52:13 UTC |
| 0ce7ecd | Sean Owen | 22 April 2021, 01:49:19 UTC | [SPARK-35178][BUILD] Use new Apache 'closer.lua' syntax to obtain Maven ### What changes were proposed in this pull request? Use new Apache 'closer.lua' syntax to obtain Maven ### Why are the changes needed? The current closer.lua redirector, which redirects to download Maven from a local mirror, has a new syntax. build/mvn does not work properly otherwise now. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manual testing. Closes #32277 from srowen/SPARK-35178. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 6860efe4688ea1057e7a2e57b086721e62198d44) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 22 April 2021, 01:49:47 UTC |
| aef17b7 | sandeep.katta | 21 April 2021, 07:16:17 UTC | [SPARK-35096][SQL] SchemaPruning should adhere spark.sql.caseSensitive config ### What changes were proposed in this pull request? As a part of the SPARK-26837 pruning of nested fields from object serializers are supported. But it is missed to handle case insensitivity nature of spark In this PR I have resolved the column names to be pruned based on `spark.sql.caseSensitive ` config **Exception Before Fix** ``` Caused by: java.lang.ArrayIndexOutOfBoundsException: 0 at org.apache.spark.sql.types.StructType.apply(StructType.scala:414) at org.apache.spark.sql.catalyst.optimizer.ObjectSerializerPruning$$anonfun$apply$4.$anonfun$applyOrElse$3(objects.scala:216) at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238) at scala.collection.immutable.List.foreach(List.scala:392) at scala.collection.TraversableLike.map(TraversableLike.scala:238) at scala.collection.TraversableLike.map$(TraversableLike.scala:231) at scala.collection.immutable.List.map(List.scala:298) at org.apache.spark.sql.catalyst.optimizer.ObjectSerializerPruning$$anonfun$apply$4.applyOrElse(objects.scala:215) at org.apache.spark.sql.catalyst.optimizer.ObjectSerializerPruning$$anonfun$apply$4.applyOrElse(objects.scala:203) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDown$1(TreeNode.scala:309) at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:72) at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:309) at ``` ### Why are the changes needed? After Upgrade to Spark 3 `foreachBatch` API throws` java.lang.ArrayIndexOutOfBoundsException`. This issue will be fixed using this PR ### Does this PR introduce _any_ user-facing change? No, Infact fixes the regression ### How was this patch tested? Added tests and also tested verified manually Closes #32194 from sandeep-katta/SPARK-35096. Authored-by: sandeep.katta <sandeep.katta2007@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 21 April 2021, 07:19:08 UTC |
| 5ac9605 | allisonwang-db | 20 April 2021, 03:11:40 UTC | [SPARK-35080][SQL] Only allow a subset of correlated equality predicates when a subquery is aggregated This PR updated the `foundNonEqualCorrelatedPred` logic for correlated subqueries in `CheckAnalysis` to only allow correlated equality predicates that guarantee one-to-one mapping between inner and outer attributes, instead of all equality predicates. To fix correctness bugs. Before this fix Spark can give wrong results for certain correlated subqueries that pass CheckAnalysis: Example 1: ```sql create or replace view t1(c) as values ('a'), ('b') create or replace view t2(c) as values ('ab'), ('abc'), ('bc') select c, (select count(*) from t2 where t1.c = substring(t2.c, 1, 1)) from t1 ``` Correct results: [(a, 2), (b, 1)] Spark results: ``` +---+-----------------+ |c |scalarsubquery(c)| +---+-----------------+ |a |1 | |a |1 | |b |1 | +---+-----------------+ ``` Example 2: ```sql create or replace view t1(a, b) as values (0, 6), (1, 5), (2, 4), (3, 3); create or replace view t2(c) as values (6); select c, (select count(*) from t1 where a + b = c) from t2; ``` Correct results: [(6, 4)] Spark results: ``` +---+-----------------+ |c |scalarsubquery(c)| +---+-----------------+ |6 |1 | |6 |1 | |6 |1 | |6 |1 | +---+-----------------+ ``` Yes. Users will not be able to run queries that contain unsupported correlated equality predicates. Added unit tests. Closes #32179 from allisonwang-db/spark-35080-subquery-bug. Lead-authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com> Co-authored-by: Wenchen Fan <cloud0fan@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit bad4b6f025de4946112a0897892a97d5ae6822cf) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 20 April 2021, 03:36:55 UTC |
| 8fd6d18 | HyukjinKwon | 19 April 2021, 10:52:06 UTC | [SPARK-35045][SQL][FOLLOW-UP] Add a configuration for CSV input buffer size ### What changes were proposed in this pull request? This PR makes the input buffer configurable (as an internal configuration). This is mainly to work around the regression in uniVocity/univocity-parsers#449. This is particularly useful for SQL workloads that requires to rewrite the `CREATE TABLE` with options. ### Why are the changes needed? To work around uniVocity/univocity-parsers#449. ### Does this PR introduce _any_ user-facing change? No, it's only internal option. ### How was this patch tested? Manually tested by modifying the unittest added in https://github.com/apache/spark/pull/31858 as below: ```diff diff --git a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala index fd25a79619d..705f38dbfbd 100644 --- a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala +++ b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala -2456,6 +2456,7 abstract class CSVSuite test("SPARK-34768: counting a long record with ignoreTrailingWhiteSpace set to true") { val bufSize = 128 val line = "X" * (bufSize - 1) + "| |" + spark.conf.set("spark.sql.csv.parser.inputBufferSize", 128) withTempPath { path => Seq(line).toDF.write.text(path.getAbsolutePath) assert(spark.read.format("csv") ``` Closes #32231 from HyukjinKwon/SPARK-35045-followup. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 70b606ffdd28f94fe64a12e7e0eadbf7b212bd83) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 19 April 2021, 10:52:28 UTC |
| 34d4da5 | HyukjinKwon | 14 April 2021, 09:13:48 UTC | [SPARK-35002][YARN][TESTS][FOLLOW-UP] Fix java.net.BindException in MiniYARNCluster This PR fixes two tests below: https://github.com/apache/spark/runs/2320161984 ``` [info] YarnShuffleIntegrationSuite: [info] org.apache.spark.deploy.yarn.YarnShuffleIntegrationSuite *** ABORTED *** (228 milliseconds) [info] org.apache.hadoop.yarn.exceptions.YarnRuntimeException: org.apache.hadoop.yarn.webapp.WebAppException: Error starting http server [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.startResourceManager(MiniYARNCluster.java:373) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.access$300(MiniYARNCluster.java:128) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster$ResourceManagerWrapper.serviceStart(MiniYARNCluster.java:503) [info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194) [info] at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:121) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.serviceStart(MiniYARNCluster.java:322) [info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194) [info] at org.apache.spark.deploy.yarn.BaseYarnClusterSuite.beforeAll(BaseYarnClusterSuite.scala:95) ... [info] Cause: java.net.BindException: Port in use: fv-az186-831:0 [info] at org.apache.hadoop.http.HttpServer2.constructBindException(HttpServer2.java:1231) [info] at org.apache.hadoop.http.HttpServer2.bindForSinglePort(HttpServer2.java:1253) [info] at org.apache.hadoop.http.HttpServer2.openListeners(HttpServer2.java:1316) [info] at org.apache.hadoop.http.HttpServer2.start(HttpServer2.java:1167) [info] at org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:449) [info] at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.startWepApp(ResourceManager.java:1247) [info] at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.serviceStart(ResourceManager.java:1356) [info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.startResourceManager(MiniYARNCluster.java:365) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.access$300(MiniYARNCluster.java:128) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster$ResourceManagerWrapper.serviceStart(MiniYARNCluster.java:503) [info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194) [info] at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:121) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.serviceStart(MiniYARNCluster.java:322) [info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194) [info] at org.apache.spark.deploy.yarn.BaseYarnClusterSuite.beforeAll(BaseYarnClusterSuite.scala:95) [info] at org.scalatest.BeforeAndAfterAll.liftedTree1$1(BeforeAndAfterAll.scala:212) [info] at org.scalatest.BeforeAndAfterAll.run(BeforeAndAfterAll.scala:210) [info] at org.scalatest.BeforeAndAfterAll.run$(BeforeAndAfterAll.scala:208) [info] at org.apache.spark.SparkFunSuite.run(SparkFunSuite.scala:61) ... ``` https://github.com/apache/spark/runs/2323342094 ``` [info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadSecret started [error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadSecret failed: java.lang.AssertionError: Connecting to /10.1.0.161:39895 timed out (120000 ms), took 120.081 sec [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadSecret(ExternalShuffleSecuritySuite.java:85) [error] ... [info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadAppId started [error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadAppId failed: java.lang.AssertionError: Connecting to /10.1.0.198:44633 timed out (120000 ms), took 120.08 sec [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadAppId(ExternalShuffleSecuritySuite.java:76) [error] ... [info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testValid started [error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testValid failed: java.io.IOException: Connecting to /10.1.0.119:43575 timed out (120000 ms), took 120.089 sec [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:285) [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:218) [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:230) [error] at org.apache.spark.network.shuffle.ExternalBlockStoreClient.registerWithShuffleServer(ExternalBlockStoreClient.java:211) [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.validate(ExternalShuffleSecuritySuite.java:108) [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testValid(ExternalShuffleSecuritySuite.java:68) [error] ... [info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testEncryption started [error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testEncryption failed: java.io.IOException: Connecting to /10.1.0.248:35271 timed out (120000 ms), took 120.014 sec [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:285) [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:218) [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:230) [error] at org.apache.spark.network.shuffle.ExternalBlockStoreClient.registerWithShuffleServer(ExternalBlockStoreClient.java:211) [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.validate(ExternalShuffleSecuritySuite.java:108) [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testEncryption(ExternalShu ``` For Yarn cluster suites, its difficult to fix. This PR makes it skipped if it fails to bind. For shuffle related suites, it uses local host To make the tests stable No, dev-only. Its tested in GitHub Actions: https://github.com/HyukjinKwon/spark/runs/2340210765 Closes #32126 from HyukjinKwon/SPARK-35002-followup. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit a153efa643dcb1d8e6c2242846b3db0b2be39ae7) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 16 April 2021, 00:00:53 UTC |
| 0033804 | HyukjinKwon | 15 April 2021, 23:58:45 UTC | Revert "[SPARK-35002][YARN][TESTS][FOLLOW-UP] Fix java.net.BindException in MiniYARNCluster" This reverts commit 7c1177c1d6e104106bdf5c4f26b866a579f0a2c2. | 15 April 2021, 23:58:45 UTC |
| e24115c | weixiuli | 14 April 2021, 16:44:48 UTC | [SPARK-34834][NETWORK] Fix a potential Netty memory leak in TransportResponseHandler ### What changes were proposed in this pull request? There is a potential Netty memory leak in TransportResponseHandler. ### Why are the changes needed? Fix a potential Netty memory leak in TransportResponseHandler. ### Does this PR introduce _any_ user-facing change? NO ### How was this patch tested? NO Closes #31942 from weixiuli/SPARK-34834. Authored-by: weixiuli <weixiuli@jd.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit bf9f3b884fcd6bd3428898581d4b5dca9bae6538) Signed-off-by: Sean Owen <srowen@gmail.com> | 14 April 2021, 16:45:14 UTC |
| fa872c4 | HyukjinKwon | 09 April 2021, 08:39:20 UTC | [SPARK-35002][INFRA][FOLLOW-UP] Use localhost instead of 127.0.0.1 at SPARK_LOCAL_IP in GA builds This PR replaces 127.0.0.1 to `localhost`. - https://github.com/apache/spark/pull/32096#discussion_r610349269 - https://github.com/apache/spark/pull/32096#issuecomment-816442481 No, dev-only. I didn't test it because it's CI specific issue. I will test it in Github Actions build in this PR. Closes #32102 from HyukjinKwon/SPARK-35002. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit a3d1e00317d82bc2296a6f339b9604b5d6bc6754) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 14 April 2021, 10:46:54 UTC |
| 2f22c1a | Yuming Wang | 09 April 2021, 06:03:51 UTC | [SPARK-35002][INFRA] Fix the java.net.BindException when testing with Github Action This PR tries to fix the `java.net.BindException` when testing with Github Action: ``` [info] org.apache.spark.sql.kafka010.producer.InternalKafkaProducerPoolSuite *** ABORTED *** (282 milliseconds) [info] java.net.BindException: Cannot assign requested address: Service 'sparkDriver' failed after 100 retries (on a random free port)! Consider explicitly setting the appropriate binding address for the service 'sparkDriver' (for example spark.driver.bindAddress for SparkDriver) to the correct binding address. [info] at sun.nio.ch.Net.bind0(Native Method) [info] at sun.nio.ch.Net.bind(Net.java:461) [info] at sun.nio.ch.Net.bind(Net.java:453) ``` https://github.com/apache/spark/pull/32090/checks?check_run_id=2295418529 Fix test framework. No. Test by Github Action. Closes #32096 from wangyum/SPARK_LOCAL_IP=localhost. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 9663c4061ae07634697345560c84359574a75692) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 14 April 2021, 10:44:34 UTC |
| 7c1177c | HyukjinKwon | 14 April 2021, 09:13:48 UTC | [SPARK-35002][YARN][TESTS][FOLLOW-UP] Fix java.net.BindException in MiniYARNCluster This PR fixes two tests below: https://github.com/apache/spark/runs/2320161984 ``` [info] YarnShuffleIntegrationSuite: [info] org.apache.spark.deploy.yarn.YarnShuffleIntegrationSuite *** ABORTED *** (228 milliseconds) [info] org.apache.hadoop.yarn.exceptions.YarnRuntimeException: org.apache.hadoop.yarn.webapp.WebAppException: Error starting http server [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.startResourceManager(MiniYARNCluster.java:373) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.access$300(MiniYARNCluster.java:128) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster$ResourceManagerWrapper.serviceStart(MiniYARNCluster.java:503) [info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194) [info] at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:121) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.serviceStart(MiniYARNCluster.java:322) [info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194) [info] at org.apache.spark.deploy.yarn.BaseYarnClusterSuite.beforeAll(BaseYarnClusterSuite.scala:95) ... [info] Cause: java.net.BindException: Port in use: fv-az186-831:0 [info] at org.apache.hadoop.http.HttpServer2.constructBindException(HttpServer2.java:1231) [info] at org.apache.hadoop.http.HttpServer2.bindForSinglePort(HttpServer2.java:1253) [info] at org.apache.hadoop.http.HttpServer2.openListeners(HttpServer2.java:1316) [info] at org.apache.hadoop.http.HttpServer2.start(HttpServer2.java:1167) [info] at org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:449) [info] at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.startWepApp(ResourceManager.java:1247) [info] at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.serviceStart(ResourceManager.java:1356) [info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.startResourceManager(MiniYARNCluster.java:365) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.access$300(MiniYARNCluster.java:128) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster$ResourceManagerWrapper.serviceStart(MiniYARNCluster.java:503) [info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194) [info] at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:121) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.serviceStart(MiniYARNCluster.java:322) [info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194) [info] at org.apache.spark.deploy.yarn.BaseYarnClusterSuite.beforeAll(BaseYarnClusterSuite.scala:95) [info] at org.scalatest.BeforeAndAfterAll.liftedTree1$1(BeforeAndAfterAll.scala:212) [info] at org.scalatest.BeforeAndAfterAll.run(BeforeAndAfterAll.scala:210) [info] at org.scalatest.BeforeAndAfterAll.run$(BeforeAndAfterAll.scala:208) [info] at org.apache.spark.SparkFunSuite.run(SparkFunSuite.scala:61) ... ``` https://github.com/apache/spark/runs/2323342094 ``` [info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadSecret started [error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadSecret failed: java.lang.AssertionError: Connecting to /10.1.0.161:39895 timed out (120000 ms), took 120.081 sec [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadSecret(ExternalShuffleSecuritySuite.java:85) [error] ... [info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadAppId started [error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadAppId failed: java.lang.AssertionError: Connecting to /10.1.0.198:44633 timed out (120000 ms), took 120.08 sec [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadAppId(ExternalShuffleSecuritySuite.java:76) [error] ... [info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testValid started [error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testValid failed: java.io.IOException: Connecting to /10.1.0.119:43575 timed out (120000 ms), took 120.089 sec [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:285) [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:218) [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:230) [error] at org.apache.spark.network.shuffle.ExternalBlockStoreClient.registerWithShuffleServer(ExternalBlockStoreClient.java:211) [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.validate(ExternalShuffleSecuritySuite.java:108) [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testValid(ExternalShuffleSecuritySuite.java:68) [error] ... [info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testEncryption started [error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testEncryption failed: java.io.IOException: Connecting to /10.1.0.248:35271 timed out (120000 ms), took 120.014 sec [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:285) [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:218) [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:230) [error] at org.apache.spark.network.shuffle.ExternalBlockStoreClient.registerWithShuffleServer(ExternalBlockStoreClient.java:211) [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.validate(ExternalShuffleSecuritySuite.java:108) [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testEncryption(ExternalShu ``` For Yarn cluster suites, its difficult to fix. This PR makes it skipped if it fails to bind. For shuffle related suites, it uses local host To make the tests stable No, dev-only. Its tested in GitHub Actions: https://github.com/HyukjinKwon/spark/runs/2340210765 Closes #32126 from HyukjinKwon/SPARK-35002-followup. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit a153efa643dcb1d8e6c2242846b3db0b2be39ae7) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 14 April 2021, 10:36:59 UTC |
| 057dc8d | Hyukjin Kwon | 13 April 2021, 12:08:01 UTC | [SPARK-35045][SQL] Add an internal option to control input buffer in univocity This PR makes the input buffer configurable (as an internal option). This is mainly to work around uniVocity/univocity-parsers#449. To work around uniVocity/univocity-parsers#449. No, it's only internal option. Manually tested by modifying the unittest added in https://github.com/apache/spark/pull/31858 as below: ```diff diff --git a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala index fd25a79619d..b58f0bd3661 100644 --- a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala +++ b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala -2460,6 +2460,7 abstract class CSVSuite Seq(line).toDF.write.text(path.getAbsolutePath) assert(spark.read.format("csv") .option("delimiter", "|") + .option("inputBufferSize", "128") .option("ignoreTrailingWhiteSpace", "true").load(path.getAbsolutePath).count() == 1) } } ``` Closes #32145 from HyukjinKwon/SPARK-35045. Lead-authored-by: Hyukjin Kwon <gurwls223@apache.org> Co-authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Max Gekk <max.gekk@gmail.com> (cherry picked from commit 1f562159bf61dd5e536db7841b16e74a635e7a97) Signed-off-by: Max Gekk <max.gekk@gmail.com> | 13 April 2021, 12:12:02 UTC |
| 8db3321 | Yingyi Bu | 13 April 2021, 11:57:13 UTC | [SPARK-35014] Fix the PhysicalAggregation pattern to not rewrite foldable expressions ### What changes were proposed in this pull request? Fix PhysicalAggregation to not transform a foldable expression. ### Why are the changes needed? It can potentially break certain queries like the added unit test shows. ### Does this PR introduce _any_ user-facing change? Yes, it fixes undesirable errors caused by a returned TypeCheckFailure from places like RegExpReplace.checkInputDataTypes. Closes #32113 from sigmod/foldable. Authored-by: Yingyi Bu <yingyi.bu@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 9cd25b46b9d1de0c7cdecdabd8cf37b25ec2d78a) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 13 April 2021, 11:59:00 UTC |
| d5e001b | Yuming Wang | 13 April 2021, 09:04:47 UTC | [SPARK-34212][SQL][FOLLOWUP] Move the added test to ParquetQuerySuite This pr moves the added test from `SQLQuerySuite` to `ParquetQuerySuite`. 1. It can be tested by `ParquetV1QuerySuite` and `ParquetV2QuerySuite`. 2. Reduce the testing time of `SQLQuerySuite`(SQLQuerySuite ~ 3 min 17 sec, ParquetV1QuerySuite ~ 27 sec). No. Unit test. Closes #32090 from wangyum/SPARK-34212. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 13 April 2021, 09:24:31 UTC |
| 3cfb07f | Angerszhuuuu | 12 April 2021, 13:52:59 UTC | [SPARK-34926][SQL][3.0] PartitioningUtils.getPathFragment() should respect partition value is null ### What changes were proposed in this pull request? When we insert data into a partition table partition with empty DataFrame. We will call `PartitioningUtils.getPathFragment()` then to update this partition's metadata too. When we insert to a partition when partition value is `null`, it will throw exception like ``` [info] java.lang.NullPointerException: [info] at scala.collection.immutable.StringOps$.length$extension(StringOps.scala:51) [info] at scala.collection.immutable.StringOps.length(StringOps.scala:51) [info] at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:35) [info] at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33) [info] at scala.collection.immutable.StringOps.foreach(StringOps.scala:33) [info] at org.apache.spark.sql.catalyst.catalog.ExternalCatalogUtils$.escapePathName(ExternalCatalogUtils.scala:69) [info] at org.apache.spark.sql.catalyst.catalog.ExternalCatalogUtils$.getPartitionValueString(ExternalCatalogUtils.scala:126) [info] at org.apache.spark.sql.execution.datasources.PartitioningUtils$.$anonfun$getPathFragment$1(PartitioningUtils.scala:354) [info] at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238) [info] at scala.collection.Iterator.foreach(Iterator.scala:941) [info] at scala.collection.Iterator.foreach$(Iterator.scala:941) [info] at scala.collection.AbstractIterator.foreach(Iterator.scala:1429) [info] at scala.collection.IterableLike.foreach(IterableLike.scala:74) [info] at scala.collection.IterableLike.foreach$(IterableLike.scala:73) ``` `PartitioningUtils.getPathFragment()` should support `null` value too ### Why are the changes needed? Fix bug ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added UT Closes #32128 from AngersZhuuuu/SPARK-24926-3.0. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 12 April 2021, 13:52:59 UTC |
| 0803317 | hissy | 10 April 2021, 09:33:30 UTC | [MINOR][SS][DOC] Fix wrong Python code sample ### What changes were proposed in this pull request? This patch fixes wrong Python code sample for doc. ### Why are the changes needed? Sample code is wrong. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Doc only. Closes #32119 from Hisssy/ss-doc-typo-1. Authored-by: hissy <aozora@live.cn> Signed-off-by: Max Gekk <max.gekk@gmail.com> (cherry picked from commit 214a46aa88cd682874584dc407ad130a30761884) Signed-off-by: Max Gekk <max.gekk@gmail.com> | 10 April 2021, 09:34:09 UTC |
| a8af3e6 | Liang-Chi Hsieh | 09 April 2021, 18:52:55 UTC | [SPARK-34963][SQL] Fix nested column pruning for extracting case-insensitive struct field from array of struct ### What changes were proposed in this pull request? This patch proposes a fix of nested column pruning for extracting case-insensitive struct field from array of struct. ### Why are the changes needed? Under case-insensitive mode, nested column pruning rule cannot correctly push down extractor of a struct field of an array of struct, e.g., ```scala val query = spark.table("contacts").select("friends.First", "friends.MiDDle") ``` Error stack: ``` [info] java.lang.IllegalArgumentException: Field "First" does not exist. [info] Available fields: [info] at org.apache.spark.sql.types.StructType$$anonfun$apply$1.apply(StructType.scala:274) [info] at org.apache.spark.sql.types.StructType$$anonfun$apply$1.apply(StructType.scala:274) [info] at scala.collection.MapLike$class.getOrElse(MapLike.scala:128) [info] at scala.collection.AbstractMap.getOrElse(Map.scala:59) [info] at org.apache.spark.sql.types.StructType.apply(StructType.scala:273) [info] at org.apache.spark.sql.execution.ProjectionOverSchema$$anonfun$getProjection$3.apply(ProjectionOverSchema.scala:44) [info] at org.apache.spark.sql.execution.ProjectionOverSchema$$anonfun$getProjection$3.apply(ProjectionOverSchema.scala:41) ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test Closes #32059 from viirya/fix-array-nested-pruning. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> (cherry picked from commit 364d1eaf10f51c357f507325557fb076140ced2c) Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 09 April 2021, 18:53:51 UTC |
| ee264b1 | Gengliang Wang | 08 April 2021, 20:35:30 UTC | [SPARK-34970][3.0][SQL] Redact map-type options in the output of explain() ### What changes were proposed in this pull request? The `explain()` method prints the arguments of tree nodes in logical/physical plans. The arguments could contain a map-type option that contains sensitive data. We should map-type options in the output of `explain()`. Otherwise, we will see sensitive data in explain output or Spark UI. 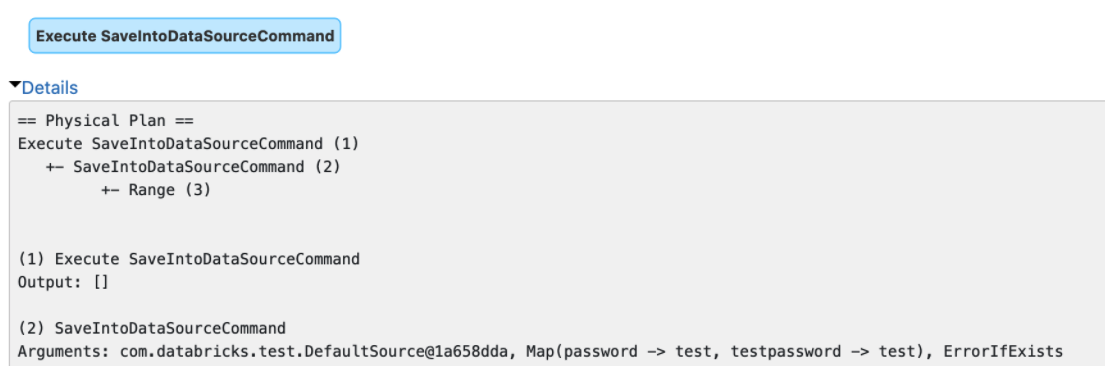 ### Why are the changes needed? Data security. ### Does this PR introduce _any_ user-facing change? Yes, redact the map-type options in the output of `explain()` ### How was this patch tested? Unit tests Closes #32085 from gengliangwang/redact3.0. Authored-by: Gengliang Wang <ltnwgl@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 08 April 2021, 20:35:30 UTC |
| bd972fe | Kousuke Saruta | 08 April 2021, 15:41:43 UTC | [SPARK-34988][CORE][3.0] Upgrade Jetty for CVE-2021-28165 ### What changes were proposed in this pull request? This PR backports #32091. This PR upgrades the version of Jetty to 9.4.39. ### Why are the changes needed? CVE-2021-28165 affects the version of Jetty that Spark uses and it seems to be a little bit serious. https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-28165 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes #32094 from sarutak/SPARK-34988-branch-3.0. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Sean Owen <srowen@gmail.com> | 08 April 2021, 15:41:43 UTC |
| b9ee41f | Tanel Kiis | 08 April 2021, 02:03:59 UTC | [SPARK-34922][SQL][3.0] Use a relative cost comparison function in the CBO ### What changes were proposed in this pull request? Changed the cost comparison function of the CBO to use the ratios of row counts and sizes in bytes. ### Why are the changes needed? In #30965 we changed to CBO cost comparison function so it would be "symetric": `A.betterThan(B)` now implies, that `!B.betterThan(A)`. With that we caused a performance regressions in some queries - TPCDS q19 for example. The original cost comparison function used the ratios `relativeRows = A.rowCount / B.rowCount` and `relativeSize = A.size / B.size`. The changed function compared "absolute" cost values `costA = w*A.rowCount + (1-w)*A.size` and `costB = w*B.rowCount + (1-w)*B.size`. Given the input from wzhfy we decided to go back to the relative values, because otherwise one (size) may overwhelm the other (rowCount). But this time we avoid adding up the ratios. Originally `A.betterThan(B) => w*relativeRows + (1-w)*relativeSize < 1` was used. Besides being "non-symteric", this also can exhibit one overwhelming other. For `w=0.5` If `A` size (bytes) is at least 2x larger than `B`, then no matter how many times more rows does the `B` plan have, `B` will allways be considered to be better - `0.5*2 + 0.5*0.00000000000001 > 1`. When working with ratios, then it would be better to multiply them. The proposed cost comparison function is: `A.betterThan(B) => relativeRows^w * relativeSize^(1-w) < 1`. ### Does this PR introduce _any_ user-facing change? Comparison of the changed TPCDS v1.4 query execution times at sf=10: | absolute | multiplicative | | additive | -- | -- | -- | -- | -- | -- q12 | 145 | 137 | -5.52% | 141 | -2.76% q13 | 264 | 271 | 2.65% | 271 | 2.65% q17 | 4521 | 4243 | -6.15% | 4348 | -3.83% q18 | 758 | 466 | -38.52% | 480 | -36.68% q19 | 38503 | 2167 | -94.37% | 2176 | -94.35% q20 | 119 | 120 | 0.84% | 126 | 5.88% q24a | 16429 | 16838 | 2.49% | 17103 | 4.10% q24b | 16592 | 16999 | 2.45% | 17268 | 4.07% q25 | 3558 | 3556 | -0.06% | 3675 | 3.29% q33 | 362 | 361 | -0.28% | 380 | 4.97% q52 | 1020 | 1032 | 1.18% | 1052 | 3.14% q55 | 927 | 938 | 1.19% | 961 | 3.67% q72 | 24169 | 13377 | -44.65% | 24306 | 0.57% q81 | 1285 | 1185 | -7.78% | 1168 | -9.11% q91 | 324 | 336 | 3.70% | 337 | 4.01% q98 | 126 | 129 | 2.38% | 131 | 3.97% All times are in ms, the change is compared to the situation in the master branch (absolute). The proposed cost function (multiplicative) significantlly improves the performance on q18, q19 and q72. The original cost function (additive) has similar improvements at q18 and q19. All other chagnes are within the error bars and I would ignore them - perhaps q81 has also improved. ### How was this patch tested? PlanStabilitySuite Closes #32076 from tanelk/SPARK-34922_cbo_better_cost_function_3.0. Lead-authored-by: Tanel Kiis <tanel.kiis@gmail.com> Co-authored-by: tanel.kiis@gmail.com <tanel.kiis@gmail.com> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org> | 08 April 2021, 02:03:59 UTC |
| ae75095 | HyukjinKwon | 04 April 2021, 07:22:57 UTC | [SPARK-34951][INFRA][PYTHON][TESTS] Set the system encoding as UTF-8 to recover the Sphinx build in GitHub Actions This PR proposes to set the system encoding as UTF-8. For some reasons, it looks like GitHub Actions machines changed theirs to ASCII by default. This leads to default encoding/decoding to use ASCII in Python, e.g.) `"a".encode()`, and looks like Sphinx depends on that. To recover GItHub Actions build. No, dev-only. Tested in https://github.com/apache/spark/pull/32046 Closes #32047 from HyukjinKwon/SPARK-34951. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 82ad2f9dff9b8d9cb8b6b166f14311f6066681c2) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 04 April 2021, 07:24:15 UTC |
| bab6e1e | Liang-Chi Hsieh | 04 April 2021, 01:37:50 UTC | [SPARK-34939][CORE] Throw fetch failure exception when unable to deserialize broadcasted map statuses ### What changes were proposed in this pull request? This patch catches `IOException`, which is possibly thrown due to unable to deserialize map statuses (e.g., broadcasted value is destroyed), when deserilizing map statuses. Once `IOException` is caught, `MetadataFetchFailedException` is thrown to let Spark handle it. ### Why are the changes needed? One customer encountered application error. From the log, it is caused by accessing non-existing broadcasted value. The broadcasted value is map statuses. E.g., ``` [info] Cause: java.io.IOException: org.apache.spark.SparkException: Failed to get broadcast_0_piece0 of broadcast_0 [info] at org.apache.spark.util.Utils$.tryOrIOException(Utils.scala:1410) [info] at org.apache.spark.broadcast.TorrentBroadcast.readBroadcastBlock(TorrentBroadcast.scala:226) [info] at org.apache.spark.broadcast.TorrentBroadcast.getValue(TorrentBroadcast.scala:103) [info] at org.apache.spark.broadcast.Broadcast.value(Broadcast.scala:70) [info] at org.apache.spark.MapOutputTracker$.$anonfun$deserializeMapStatuses$3(MapOutputTracker.scala:967) [info] at org.apache.spark.internal.Logging.logInfo(Logging.scala:57) [info] at org.apache.spark.internal.Logging.logInfo$(Logging.scala:56) [info] at org.apache.spark.MapOutputTracker$.logInfo(MapOutputTracker.scala:887) [info] at org.apache.spark.MapOutputTracker$.deserializeMapStatuses(MapOutputTracker.scala:967) ``` There is a race-condition. After map statuses are broadcasted and the executors obtain serialized broadcasted map statuses. If any fetch failure happens after, Spark scheduler invalidates cached map statuses and destroy broadcasted value of the map statuses. Then any executor trying to deserialize serialized broadcasted map statuses and access broadcasted value, `IOException` will be thrown. Currently we don't catch it in `MapOutputTrackerWorker` and above exception will fail the application. Normally we should throw a fetch failure exception for such case. Spark scheduler will handle this. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test. Closes #32033 from viirya/fix-broadcast-master. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 571acc87fef6ddf8a6046bf710d5065dc02d76bd) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 04 April 2021, 01:38:14 UTC |
| 58217b8 | Cheng Su | 02 April 2021, 06:51:22 UTC | [SPARK-34940][SQL][TEST] Fix test of BasicWriteTaskStatsTrackerSuite ### What changes were proposed in this pull request? This is to fix the minor typo in unit test of BasicWriteTaskStatsTrackerSuite (https://github.com/apache/spark/blob/master/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/BasicWriteTaskStatsTrackerSuite.scala#L152 ), where it should be a new file name, e.g. `f-3-3`, because the unit test expects 3 files in statistics (https://github.com/apache/spark/blob/master/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/BasicWriteTaskStatsTrackerSuite.scala#L160 ). ### Why are the changes needed? Fix minor bug. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Changed unit test `"Three files, last one empty"` itself. Closes #32034 from c21/tracker-fix. Authored-by: Cheng Su <chengsu@fb.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 280a2f359c55d8c0563ebbf54a3196ffeb65560e) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 02 April 2021, 06:52:18 UTC |
| 6a31794 | Kousuke Saruta | 01 April 2021, 22:14:41 UTC | [SPARK-34933][DOC][SQL] Remove the description that || and && can be used as logical operators from the document ### What changes were proposed in this pull request? This PR removes the description that `||` and `&&` can be used as logical operators from the migration guide. ### Why are the changes needed? At the `Compatibility with Apache Hive` section in the migration guide, it describes that `||` and `&&` can be used as logical operators. But, in fact, they cannot be used as described. AFAIK, Hive also doesn't support `&&` and `||` as logical operators. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? I confirmed that `&&` and `||` cannot be used as logical operators with both Hive's interactive shell and `spark-sql`. I also built the modified document and confirmed that the modified document doesn't break layout. Closes #32023 from sarutak/modify-hive-compatibility-doc. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 8724f2b8b746f5742e8598ae33492e65fd4acc7c) Signed-off-by: Sean Owen <srowen@gmail.com> | 01 April 2021, 22:15:09 UTC |
| 500d2bb | Kousuke Saruta | 01 April 2021, 19:04:19 UTC | [SPARK-24931][INFRA] Fix the GA failure related to R linter ### What changes were proposed in this pull request? This PR fixes the GA failure related to R linter which happens on some PRs (e.g. #32023, #32025). The reason seems `Rscript -e "devtools::install_github('jimhester/lintrv2.0.0')"` fails to download `lintrv2.0.0`. I don't know why but I confirmed we can download `v2.0.1`. ### Why are the changes needed? To keep GA healthy. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? GA itself. Closes #32028 from sarutak/hotfix-r. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit f99a831dabfe043aa391be660f1404b657d0ca77) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 01 April 2021, 19:15:10 UTC |
| 23b7f90 | HyukjinKwon | 31 March 2021, 10:13:50 UTC | [SPARK-34915][INFRA] Cache Maven, SBT and Scala in all jobs that use them This PR proposes to cache Maven, SBT and Scala in all jobs that use them. For simplicity, we use the same key `build-` and just cache all SBT, Maven and Scala. The cache is not very large. To speed up the build. No, dev-only. It will be tested in this PR's GA jobs. Closes #32011 from HyukjinKwon/SPARK-34915. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Gengliang Wang <ltnwgl@gmail.com> (cherry picked from commit 48ef9bd2b3a0cb52aaa31a3fada8779b7a7b9132) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 31 March 2021, 11:22:46 UTC |
| eb3b380 | Tim Armstrong | 31 March 2021, 04:58:29 UTC | [SPARK-34909][SQL] Fix conversion of negative to unsigned in conv() ### What changes were proposed in this pull request? Use `java.lang.Long.divideUnsigned()` to do integer division in `NumberConverter` to avoid a bug in `unsignedLongDiv` that produced invalid results. ### Why are the changes needed? The previous results are incorrect, the result of the below query should be 45012021522523134134555 ``` scala> spark.sql("select conv('-10', 11, 7)").show(20, 150) +-----------------------+ | conv(-10, 11, 7)| +-----------------------+ |4501202152252313413456| +-----------------------+ scala> spark.sql("select hex(conv('-10', 11, 7))").show(20, 150) +----------------------------------------------+ | hex(conv(-10, 11, 7))| +----------------------------------------------+ |3435303132303231353232353233313334313334353600| +----------------------------------------------+ ``` ### Does this PR introduce _any_ user-facing change? `conv()` will produce different results because the bug is fixed. ### How was this patch tested? Added a simple unit test. Closes #32006 from timarmstrong/conv-unsigned. Authored-by: Tim Armstrong <tim.armstrong@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 13b255fefd881beb68fd8bb6741c7f88318baf9b) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 31 March 2021, 04:59:22 UTC |
| e1c6594 | yangjie01 | 30 March 2021, 15:01:22 UTC | [SPARK-34900][TEST][3.0] Make sure benchmarks can run using spark-submit cmd described in the guide ### What changes were proposed in this pull request? Some `spark-submit` commands used to run benchmarks in the user's guide is wrong, we can't use these commands to run benchmarks successful. So the major changes of this pr is correct these wrong commands, for example, run a benchmark which inherits from `SqlBasedBenchmark`, we must specify `--jars <spark core test jar>,<spark catalyst test jar>` because `SqlBasedBenchmark` based benchmark extends `BenchmarkBase(defined in spark core test jar)` and `SQLHelper(defined in spark catalyst test jar)`. Another change of this pr is removed the `scalatest Assertions` dependency of Benchmarks because `scalatest-*.jar` are not in the distribution package, it will be troublesome to use. ### Why are the changes needed? Make sure benchmarks can run using spark-submit cmd described in the guide ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Use the corrected `spark-submit` commands to run benchmarks successfully. Closes #32003 from LuciferYang/SPARK-34900-30. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 30 March 2021, 15:01:22 UTC |
| 60ced75 | Baohe Zhang | 29 March 2021, 14:46:58 UTC | [SPARK-34845][CORE] ProcfsMetricsGetter shouldn't return partial procfs metrics ### What changes were proposed in this pull request? In ProcfsMetricsGetter.scala, propogating IOException from addProcfsMetricsFromOneProcess to computeAllMetrics when the child pid's proc stat file is unavailable. As a result, the for-loop in computeAllMetrics() can terminate earlier and return an all-0 procfs metric. ### Why are the changes needed? In the case of a child pid's stat file missing and the subsequent child pids' stat files exist, ProcfsMetricsGetter.computeAllMetrics() will return partial metrics (the sum of a subset of child pids), which can be misleading and is undesired per the existing code comments in https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/executor/ProcfsMetricsGetter.scala#L214. Also, a side effect of this bug is that it can lead to a verbose warning log if many pids' stat files are missing. An early terminating can make the warning logs more concise. The unit test can also explain the bug well. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? A unit test is added. Closes #31945 from baohe-zhang/SPARK-34845. Authored-by: Baohe Zhang <baohe.zhang@verizonmedia.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit b2bfe985e8adf55e5df5887340fd862776033a06) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 29 March 2021, 14:48:38 UTC |
| 44c344d | Tanel Kiis | 29 March 2021, 02:47:08 UTC | [SPARK-34876][SQL] Fill defaultResult of non-nullable aggregates ### What changes were proposed in this pull request? Filled the `defaultResult` field on non-nullable aggregates ### Why are the changes needed? The `defaultResult` defaults to `None` and in some situations (like correlated scalar subqueries) it is used for the value of the aggregation. The UT result before the fix: ``` -- !query SELECT t1a, (SELECT count(t2d) FROM t2 WHERE t2a = t1a) count_t2, (SELECT count_if(t2d > 0) FROM t2 WHERE t2a = t1a) count_if_t2, (SELECT approx_count_distinct(t2d) FROM t2 WHERE t2a = t1a) approx_count_distinct_t2, (SELECT collect_list(t2d) FROM t2 WHERE t2a = t1a) collect_list_t2, (SELECT collect_set(t2d) FROM t2 WHERE t2a = t1a) collect_set_t2, (SELECT hex(count_min_sketch(t2d, 0.5d, 0.5d, 1)) FROM t2 WHERE t2a = t1a) collect_set_t2 FROM t1 -- !query schema struct<t1a:string,count_t2:bigint,count_if_t2:bigint,approx_count_distinct_t2:bigint,collect_list_t2:array<bigint>,collect_set_t2:array<bigint>,collect_set_t2:string> -- !query output val1a 0 0 NULL NULL NULL NULL val1a 0 0 NULL NULL NULL NULL val1a 0 0 NULL NULL NULL NULL val1a 0 0 NULL NULL NULL NULL val1b 6 6 3 [19,119,319,19,19,19] [19,119,319] 0000000100000000000000060000000100000004000000005D8D6AB90000000000000000000000000000000400000000000000010000000000000001 val1c 2 2 2 [219,19] [219,19] 0000000100000000000000020000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000001 val1d 0 0 NULL NULL NULL NULL val1d 0 0 NULL NULL NULL NULL val1d 0 0 NULL NULL NULL NULL val1e 1 1 1 [19] [19] 0000000100000000000000010000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000000 val1e 1 1 1 [19] [19] 0000000100000000000000010000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000000 val1e 1 1 1 [19] [19] 0000000100000000000000010000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000000 ``` ### Does this PR introduce _any_ user-facing change? Bugfix ### How was this patch tested? UT Closes #31973 from tanelk/SPARK-34876_non_nullable_agg_subquery. Authored-by: Tanel Kiis <tanel.kiis@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 4b9e94c44412f399ba19e0ea90525d346942bf71) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 29 March 2021, 02:47:33 UTC |
| 2d4a92b | HyukjinKwon | 26 March 2021, 09:12:28 UTC | [SPARK-34874][INFRA] Recover test reports for failed GA builds ### What changes were proposed in this pull request? https://github.com/dawidd6/action-download-artifact/commit/621becc6d7c440318382ce6f4cb776f27dd3fef3#r48726074 there was a behaviour change in the download artifact plugin and it disabled the test reporting in failed builds. This PR recovers it by explicitly setting the conclusion from the workflow runs to search for the artifacts to download. ### Why are the changes needed? In order to properly report the failed test cases. ### Does this PR introduce _any_ user-facing change? No, it's dev only. ### How was this patch tested? Manually tested at https://github.com/HyukjinKwon/spark/pull/30 Before:  After:  Closes #31970 from HyukjinKwon/SPARK-34874. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit c8233f1be5c2f853f42cda367475eb135a83afd5) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 26 March 2021, 09:12:51 UTC |
| 9220ac8 | Peter Toth | 24 March 2021, 15:07:18 UTC | [SPARK-33482][SPARK-34756][SQL][3.0] Fix FileScan equality check ### What changes were proposed in this pull request? This bug was introduced by SPARK-30428 at Apache Spark 3.0.0. This PR fixes `FileScan.equals()`. ### Why are the changes needed? - Without this fix `FileScan.equals` doesn't take `fileIndex` and `readSchema` into account. - Partition filters and data filters added to `FileScan` (in #27112 and #27157) caused that canonicalized form of some `BatchScanExec` nodes don't match and this prevents some reuse possibilities. ### Does this PR introduce _any_ user-facing change? Yes, before this fix incorrect reuse of `FileScan` and so `BatchScanExec` could have happed causing correctness issues. ### How was this patch tested? Added new UTs. Closes #31952 from peter-toth/SPARK-34756-fix-filescan-equality-check-3.0. Authored-by: Peter Toth <peter.toth@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 24 March 2021, 15:07:18 UTC |
| 75dd87e | yangjie01 | 24 March 2021, 05:59:31 UTC | [SPARK-34832][SQL][TEST] Set EXECUTOR_ALLOW_SPARK_CONTEXT to true to ensure ExternalAppendOnlyUnsafeRowArrayBenchmark run successfully ### What changes were proposed in this pull request? SPARK-32160 add a config(`EXECUTOR_ALLOW_SPARK_CONTEXT`) to switch allow/disallow to create `SparkContext` in executors and the default value of the config is `false` `ExternalAppendOnlyUnsafeRowArrayBenchmark` will run fail when `EXECUTOR_ALLOW_SPARK_CONTEXT` use the default value because the `ExternalAppendOnlyUnsafeRowArrayBenchmark#withFakeTaskContext` method try to create a `SparkContext` manually in Executor Side. So the main change of this pr is set `EXECUTOR_ALLOW_SPARK_CONTEXT` to `true` to ensure `ExternalAppendOnlyUnsafeRowArrayBenchmark` run successfully. ### Why are the changes needed? Bug fix. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manual test: ``` bin/spark-submit --class org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark --jars spark-core_2.12-3.2.0-SNAPSHOT-tests.jar spark-sql_2.12-3.2.0-SNAPSHOT-tests.jar ``` **Before** ``` Exception in thread "main" java.lang.IllegalStateException: SparkContext should only be created and accessed on the driver. at org.apache.spark.SparkContext$.org$apache$spark$SparkContext$$assertOnDriver(SparkContext.scala:2679) at org.apache.spark.SparkContext.<init>(SparkContext.scala:89) at org.apache.spark.SparkContext.<init>(SparkContext.scala:137) at org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark$.withFakeTaskContext(ExternalAppendOnlyUnsafeRowArrayBenchmark.scala:52) at org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark$.testAgainstRawArrayBuffer(ExternalAppendOnlyUnsafeRowArrayBenchmark.scala:119) at org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark$.$anonfun$runBenchmarkSuite$1(ExternalAppendOnlyUnsafeRowArrayBenchmark.scala:189) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at org.apache.spark.benchmark.BenchmarkBase.runBenchmark(BenchmarkBase.scala:40) at org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark$.runBenchmarkSuite(ExternalAppendOnlyUnsafeRowArrayBenchmark.scala:186) at org.apache.spark.benchmark.BenchmarkBase.main(BenchmarkBase.scala:58) at org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark.main(ExternalAppendOnlyUnsafeRowArrayBenchmark.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52) at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:951) at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180) at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203) at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90) at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1030) at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1039) at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala) ``` **After** `ExternalAppendOnlyUnsafeRowArrayBenchmark` run successfully. Closes #31939 from LuciferYang/SPARK-34832. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 712a62ca8259539a76f45d9a54ccac8857b12a81) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 24 March 2021, 06:00:09 UTC |
| 24fb962 | Kousuke Saruta | 24 March 2021, 05:34:10 UTC | [SPARK-34763][SQL] col(), $"<name>" and df("name") should handle quoted column names properly This PR fixes an issue that `col()`, `$"<name>"` and `df("name")` don't handle quoted column names like ``` `a``b.c` ```properly. For example, if we have a following DataFrame. ``` val df1 = spark.sql("SELECT 'col1' AS `a``b.c`") ``` For the DataFrame, this query is successfully executed. ``` scala> df1.selectExpr("`a``b.c`").show +-----+ |a`b.c| +-----+ | col1| +-----+ ``` But the following query will fail because ``` df1("`a``b.c`") ``` throws an exception. ``` scala> df1.select(df1("`a``b.c`")).show org.apache.spark.sql.AnalysisException: syntax error in attribute name: `a``b.c`; at org.apache.spark.sql.catalyst.analysis.UnresolvedAttribute$.e$1(unresolved.scala:152) at org.apache.spark.sql.catalyst.analysis.UnresolvedAttribute$.parseAttributeName(unresolved.scala:162) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveQuoted(LogicalPlan.scala:121) at org.apache.spark.sql.Dataset.resolve(Dataset.scala:221) at org.apache.spark.sql.Dataset.col(Dataset.scala:1274) at org.apache.spark.sql.Dataset.apply(Dataset.scala:1241) ... 49 elided ``` It's a bug. No. New tests. Closes #31854 from sarutak/fix-parseAttributeName. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit f7e9b6efc70b6874587c440725d3af8efa3a316e) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 24 March 2021, 05:43:40 UTC |
| 4d5f5e7 | Dongjoon Hyun | 23 March 2021, 17:57:18 UTC | Revert "[SPARK-33482][SPARK-34756][SQL] Fix FileScan equality check" This reverts commit 54295af99ea5819eb18cd6b7c3344de2190254a4. | 23 March 2021, 17:57:18 UTC |
| d4e6464 | robert4os | 23 March 2021, 15:13:06 UTC | [MINOR][DOCS] Update sql-ref-syntax-dml-insert-into.md ### What changes were proposed in this pull request? the given example uses a non-standard syntax for CREATE TABLE, by defining the partitioning column with the other columns, instead of in PARTITION BY. This works is this case, because the partitioning column happens to be the last column defined, but it will break if instead 'name' would be used for partitioning. I suggest therefore to change the example to use a standard syntax, like in https://spark.apache.org/docs/3.1.1/sql-ref-syntax-ddl-create-table-hiveformat.html ### Why are the changes needed? To show the better documentation. ### Does this PR introduce _any_ user-facing change? Yes, this fixes the user-facing docs. ### How was this patch tested? CI should test it out. Closes #31900 from robert4os/patch-1. Authored-by: robert4os <robert4os@users.noreply.github.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 06d40696dc27c39824666a70e7c673880959a681) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 23 March 2021, 15:13:32 UTC |
| 54295af | Peter Toth | 23 March 2021, 09:01:16 UTC | [SPARK-33482][SPARK-34756][SQL] Fix FileScan equality check This bug was introduced by SPARK-30428 at Apache Spark 3.0.0. This PR fixes `FileScan.equals()`. - Without this fix `FileScan.equals` doesn't take `fileIndex` and `readSchema` into account. - Partition filters and data filters added to `FileScan` (in #27112 and #27157) caused that canonicalized form of some `BatchScanExec` nodes don't match and this prevents some reuse possibilities. Yes, before this fix incorrect reuse of `FileScan` and so `BatchScanExec` could have happed causing correctness issues. Added new UTs. Closes #31848 from peter-toth/SPARK-34756-fix-filescan-equality-check. Authored-by: Peter Toth <peter.toth@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 93a5d34f84c362110ef7d8853e59ce597faddad9) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 23 March 2021, 09:24:35 UTC |
| 9fd1ed3 | Lena | 23 March 2021, 07:13:32 UTC | [MINOR][DOCS] Updating the link for Azure Data Lake Gen 2 in docs ### What changes were proposed in this pull request? Current link for `Azure Blob Storage and Azure Datalake Gen 2` leads to AWS information. Replacing the link to point to the right page. ### Why are the changes needed? For users to access to the correct link. ### Does this PR introduce _any_ user-facing change? Yes, it fixes the link correctly. ### How was this patch tested? N/A Closes #31938 from lenadroid/patch-1. Authored-by: Lena <alehall@microsoft.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> (cherry picked from commit d32bb4e5ee4718741252c46c50a40810b722f12d) Signed-off-by: Max Gekk <max.gekk@gmail.com> | 23 March 2021, 07:14:11 UTC |
| e28296e | Dongjoon Hyun | 22 March 2021, 00:59:55 UTC | [SPARK-34772][TESTS][FOLLOWUP] Disable a test case using Hive 1.2.1 in Java9+ environment ### What changes were proposed in this pull request? This PR aims to disable a new test case using Hive 1.2.1 from Java9+ test environment. ### Why are the changes needed? [HIVE-6113](https://issues.apache.org/jira/browse/HIVE-6113) upgraded Datanucleus to 4.x at Hive 2.0. Datanucleus 3.x doesn't support Java9+. **Java 9+ Environment** ``` $ build/sbt "hive/testOnly *.HiveSparkSubmitSuite -- -z SPARK-34772" -Phive ... [info] *** 1 TEST FAILED *** [error] Failed: Total 1, Failed 1, Errors 0, Passed 0 [error] Failed tests: [error] org.apache.spark.sql.hive.HiveSparkSubmitSuite [error] (hive / Test / testOnly) sbt.TestsFailedException: Tests unsuccessful [error] Total time: 328 s (05:28), completed Mar 21, 2021, 5:32:39 PM ``` ### Does this PR introduce _any_ user-facing change? Fix the UT in Java9+ environment. ### How was this patch tested? Manually. ``` $ build/sbt "hive/testOnly *.HiveSparkSubmitSuite -- -z SPARK-34772" -Phive ... [info] HiveSparkSubmitSuite: [info] - SPARK-34772: RebaseDateTime loadRebaseRecords should use Spark classloader instead of context !!! CANCELED !!! (26 milliseconds) [info] org.apache.commons.lang3.SystemUtils.isJavaVersionAtLeast(JAVA_9) was true (HiveSparkSubmitSuite.scala:344) ``` Closes #31916 from dongjoon-hyun/SPARK-HiveSparkSubmitSuite. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit c5fd94f1197faf8a974c7d7745cdebf42b3430b9) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 22 March 2021, 01:00:23 UTC |
| a42b631 | Dongjoon Hyun | 21 March 2021, 21:08:34 UTC | [SPARK-34811][CORE] Redact fs.s3a.access.key like secret and token ### What changes were proposed in this pull request? Like we redact secrets and tokens, this PR aims to redact access key. ### Why are the changes needed? Access key is also worth to hide. ### Does this PR introduce _any_ user-facing change? This will hide this information from SparkUI (`Spark Properties` and `Hadoop Properties` and logs). ### How was this patch tested? Pass the newly updated UT. Closes #31912 from dongjoon-hyun/SPARK-34811. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 3c32b54a0fbdc55c503bc72a3d39d58bf99e3bfa) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 21 March 2021, 21:08:57 UTC |
| 828cf76 | Liang-Chi Hsieh | 20 March 2021, 02:26:01 UTC | [SPARK-34776][SQL][3.0][2.4] Window class should override producedAttributes ### What changes were proposed in this pull request? This patch proposes to override `producedAttributes` of `Window` class. ### Why are the changes needed? This is a backport of #31897 to branch-3.0/2.4. Unlike original PR, nested column pruning does not allow pushing through `Window` in branch-3.0/2.4 yet. But `Window` doesn't override `producedAttributes`. It's wrong and could cause potential issue. So backport `Window` related change. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests. Closes #31904 from viirya/SPARK-34776-3.0. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org> | 20 March 2021, 02:26:01 UTC |
| 25d7219 | Wenchen Fan | 20 March 2021, 02:09:50 UTC | [SPARK-34719][SQL][3.0] Correctly resolve the view query with duplicated column names backport https://github.com/apache/spark/pull/31811 to 3.0 ### What changes were proposed in this pull request? For permanent views (and the new SQL temp view in Spark 3.1), we store the view SQL text and re-parse/analyze the view SQL text when reading the view. In the case of `SELECT * FROM ...`, we want to avoid view schema change (e.g. the referenced table changes its schema) and will record the view query output column names when creating the view, so that when reading the view we can add a `SELECT recorded_column_names FROM ...` to retain the original view query schema. In Spark 3.1 and before, the final SELECT is added after the analysis phase: https://github.com/apache/spark/blob/branch-3.1/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/view.scala#L67 If the view query has duplicated output column names, we always pick the first column when reading a view. A simple repro: ``` scala> sql("create view c(x, y) as select 1 a, 2 a") res0: org.apache.spark.sql.DataFrame = [] scala> sql("select * from c").show +---+---+ | x| y| +---+---+ | 1| 1| +---+---+ ``` In the master branch, we will fail at the view reading time due to https://github.com/apache/spark/commit/b891862fb6b740b103d5a09530626ee4e0e8f6e3 , which adds the final SELECT during analysis, so that the query fails with `Reference 'a' is ambiguous` This PR proposes to resolve the view query output column names from the matching attributes by ordinal. For example, `create view c(x, y) as select 1 a, 2 a`, the view query output column names are `[a, a]`. When we reading the view, there are 2 matching attributes (e.g.`[a#1, a#2]`) and we can simply match them by ordinal. A negative example is ``` create table t(a int) create view v as select *, 1 as col from t replace table t(a int, col int) ``` When reading the view, the view query output column names are `[a, col]`, and there are two matching attributes of `col`, and we should fail the query. See the tests for details. ### Why are the changes needed? bug fix ### Does this PR introduce _any_ user-facing change? yes ### How was this patch tested? new test Closes #31894 from cloud-fan/backport. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org> | 20 March 2021, 02:09:50 UTC |
| 3e384ec | Hongyi Zhang | 19 March 2021, 15:35:15 UTC | [SPARK-34798][SQL][TESTS] Fix incorrect join condition ### What changes were proposed in this pull request? join condition 'a.attr == 'c.attr check the reference of these 2 objects which will always returns false. we need to use === instead ### Why are the changes needed? Although this join condition always false doesn't break the test but it is not what we expected. We should fix it to avoid future confusing ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? UT Closes #31890 from opensky142857/SPARK-34798. Authored-by: Hongyi Zhang <hongyzhang@ebay.com> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit 6f89cdfb0c2ecb7c7f105b59803096e16a2d29f5) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 19 March 2021, 15:36:28 UTC |
| 5c2a268 | yi.wu | 19 March 2021, 05:23:06 UTC | [SPARK-34087][3.1][SQL] Fix memory leak of ExecutionListenerBus This PR proposes an alternative way to fix the memory leak of `ExecutionListenerBus`, which would automatically clean them up. Basically, the idea is to add `registerSparkListenerForCleanup` to `ContextCleaner`, so we can remove the `ExecutionListenerBus` from `LiveListenerBus` when the `SparkSession` is GC'ed. On the other hand, to make the `SparkSession` GC-able, we need to get rid of the reference of `SparkSession` in `ExecutionListenerBus`. Therefore, we introduced the `sessionUUID`, which is a unique identifier for SparkSession, to replace the `SparkSession` object. Note that, the proposal wouldn't take effect when `spark.cleaner.referenceTracking=false` since it depends on `ContextCleaner`. Fix the memory leak caused by `ExecutionListenerBus` mentioned in SPARK-34087. Yes, save memory for users. Added unit test. Closes #31839 from Ngone51/fix-mem-leak-of-ExecutionListenerBus. Authored-by: yi.wu <yi.wudatabricks.com> Signed-off-by: HyukjinKwon <gurwls223apache.org> Closes #31881 from Ngone51/SPARK-34087-3.1. Authored-by: yi.wu <yi.wu@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 19 March 2021, 05:34:00 UTC |
| 0da0d3d | ulysses-you | 19 March 2021, 04:51:43 UTC | [SPARK-34772][SQL] RebaseDateTime loadRebaseRecords should use Spark classloader instead of context Change context classloader to Spark classloader at `RebaseDateTime.loadRebaseRecords` With custom `spark.sql.hive.metastore.version` and `spark.sql.hive.metastore.jars`. Spark would use date formatter in `HiveShim` that convert `date` to `string`, if we set `spark.sql.legacy.timeParserPolicy=LEGACY` and the partition type is `date` the `RebaseDateTime` code will be invoked. At that moment, if `RebaseDateTime` is initialized the first time then context class loader is `IsolatedClientLoader`. Such error msg would throw: ``` java.lang.IllegalArgumentException: argument "src" is null at com.fasterxml.jackson.databind.ObjectMapper._assertNotNull(ObjectMapper.java:4413) at com.fasterxml.jackson.databind.ObjectMapper.readValue(ObjectMapper.java:3157) at com.fasterxml.jackson.module.scala.ScalaObjectMapper.readValue(ScalaObjectMapper.scala:187) at com.fasterxml.jackson.module.scala.ScalaObjectMapper.readValue$(ScalaObjectMapper.scala:186) at org.apache.spark.sql.catalyst.util.RebaseDateTime$$anon$1.readValue(RebaseDateTime.scala:267) at org.apache.spark.sql.catalyst.util.RebaseDateTime$.loadRebaseRecords(RebaseDateTime.scala:269) at org.apache.spark.sql.catalyst.util.RebaseDateTime$.<init>(RebaseDateTime.scala:291) at org.apache.spark.sql.catalyst.util.RebaseDateTime$.<clinit>(RebaseDateTime.scala) at org.apache.spark.sql.catalyst.util.DateTimeUtils$.toJavaDate(DateTimeUtils.scala:109) at org.apache.spark.sql.catalyst.util.LegacyDateFormatter.format(DateFormatter.scala:95) at org.apache.spark.sql.catalyst.util.LegacyDateFormatter.format$(DateFormatter.scala:94) at org.apache.spark.sql.catalyst.util.LegacySimpleDateFormatter.format(DateFormatter.scala:138) at org.apache.spark.sql.hive.client.Shim_v0_13$ExtractableLiteral$1$.unapply(HiveShim.scala:661) at org.apache.spark.sql.hive.client.Shim_v0_13.convert$1(HiveShim.scala:785) at org.apache.spark.sql.hive.client.Shim_v0_13.$anonfun$convertFilters$4(HiveShim.scala:826) ``` ``` java.lang.NoClassDefFoundError: Could not initialize class org.apache.spark.sql.catalyst.util.RebaseDateTime$ at org.apache.spark.sql.catalyst.util.DateTimeUtils$.toJavaDate(DateTimeUtils.scala:109) at org.apache.spark.sql.catalyst.util.LegacyDateFormatter.format(DateFormatter.scala:95) at org.apache.spark.sql.catalyst.util.LegacyDateFormatter.format$(DateFormatter.scala:94) at org.apache.spark.sql.catalyst.util.LegacySimpleDateFormatter.format(DateFormatter.scala:138) at org.apache.spark.sql.hive.client.Shim_v0_13$ExtractableLiteral$1$.unapply(HiveShim.scala:661) at org.apache.spark.sql.hive.client.Shim_v0_13.convert$1(HiveShim.scala:785) at org.apache.spark.sql.hive.client.Shim_v0_13.$anonfun$convertFilters$4(HiveShim.scala:826) at scala.collection.immutable.Stream.flatMap(Stream.scala:493) at org.apache.spark.sql.hive.client.Shim_v0_13.convertFilters(HiveShim.scala:826) at org.apache.spark.sql.hive.client.Shim_v0_13.getPartitionsByFilter(HiveShim.scala:848) at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$getPartitionsByFilter$1(HiveClientImpl.scala:749) at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$withHiveState$1(HiveClientImpl.scala:291) at org.apache.spark.sql.hive.client.HiveClientImpl.liftedTree1$1(HiveClientImpl.scala:224) at org.apache.spark.sql.hive.client.HiveClientImpl.retryLocked(HiveClientImpl.scala:223) at org.apache.spark.sql.hive.client.HiveClientImpl.withHiveState(HiveClientImpl.scala:273) at org.apache.spark.sql.hive.client.HiveClientImpl.getPartitionsByFilter(HiveClientImpl.scala:747) at org.apache.spark.sql.hive.HiveExternalCatalog.$anonfun$listPartitionsByFilter$1(HiveExternalCatalog.scala:1273) ``` The reproduce steps: 1. `spark.sql.hive.metastore.version` and `spark.sql.hive.metastore.jars`. 2. `CREATE TABLE t (c int) PARTITIONED BY (p date)` 3. `SET spark.sql.legacy.timeParserPolicy=LEGACY` 4. `SELECT * FROM t WHERE p='2021-01-01'` Yes, bug fix. pass `org.apache.spark.sql.catalyst.util.RebaseDateTimeSuite` and add new unit test to `HiveSparkSubmitSuite.scala`. Closes #31864 from ulysses-you/SPARK-34772. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit 58509565f8ece90b3c915a9ebc8f220073c82426) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 19 March 2021, 05:24:06 UTC |
| a3f55ca | Kousuke Saruta | 19 March 2021, 01:19:26 UTC | [SPARK-34747][SQL][DOCS] Add virtual operators to the built-in function document ### What changes were proposed in this pull request? This PR fix an issue that virtual operators (`||`, `!=`, `<>`, `between` and `case`) are absent from the Spark SQL Built-in functions document. ### Why are the changes needed? The document should explain about all the supported built-in operators. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Built the document with `SKIP_SCALADOC=1 SKIP_RDOC=1 SKIP_PYTHONDOC=1 bundler exec jekyll build` and then, confirmed the document.      Closes #31841 from sarutak/builtin-op-doc. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 07ee73234f1d1ecd1e5edcce3bc510c59a59cb00) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 19 March 2021, 01:20:04 UTC |
| 71a2f48 | zengruios | 18 March 2021, 14:53:58 UTC | [SPARK-34760][EXAMPLES] Replace `favorite_color` with `age` in JavaSQLDataSourceExample ### What changes were proposed in this pull request? In JavaSparkSQLExample when excecute 'peopleDF.write().partitionBy("favorite_color").bucketBy(42,"name").saveAsTable("people_partitioned_bucketed");' throws Exception: 'Exception in thread "main" org.apache.spark.sql.AnalysisException: partition column favorite_color is not defined in table people_partitioned_bucketed, defined table columns are: age, name;' Change the column favorite_color to age. ### Why are the changes needed? Run JavaSparkSQLExample successfully. ### Does this PR introduce _any_ user-facing change? NO ### How was this patch tested? test in JavaSparkSQLExample . Closes #31851 from zengruios/SPARK-34760. Authored-by: zengruios <578395184@qq.com> Signed-off-by: Kent Yao <yao@apache.org> (cherry picked from commit 5570f817b2862c2680546f35c412bb06779ae1c9) Signed-off-by: Kent Yao <yao@apache.org> | 18 March 2021, 15:02:39 UTC |
| fa13a01 | yangjie01 | 18 March 2021, 12:33:23 UTC | [SPARK-34774][BUILD] Ensure change-scala-version.sh update scala.version in parent POM correctly ### What changes were proposed in this pull request? After SPARK-34507, execute` change-scala-version.sh` script will update `scala.version` in parent pom, but if we execute the following commands in order: ``` dev/change-scala-version.sh 2.13 dev/change-scala-version.sh 2.12 git status ``` there will generate git diff as follow: ``` diff --git a/pom.xml b/pom.xml index ddc4ce2f68..f43d8c8f78 100644 --- a/pom.xml +++ b/pom.xml -162,7 +162,7 <commons.math3.version>3.4.1</commons.math3.version> <commons.collections.version>3.2.2</commons.collections.version> - <scala.version>2.12.10</scala.version> + <scala.version>2.13.5</scala.version> <scala.binary.version>2.12</scala.binary.version> <scalatest-maven-plugin.version>2.0.0</scalatest-maven-plugin.version> <scalafmt.parameters>--test</scalafmt.parameters> ``` seem 'scala.version' property was not update correctly. So this pr add an extra 'scala.version' to scala-2.12 profile to ensure change-scala-version.sh can update the public `scala.version` property correctly. ### Why are the changes needed? Bug fix. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? **Manual test** Execute the following commands in order: ``` dev/change-scala-version.sh 2.13 dev/change-scala-version.sh 2.12 git status ``` **Before** ``` diff --git a/pom.xml b/pom.xml index ddc4ce2f68..f43d8c8f78 100644 --- a/pom.xml +++ b/pom.xml -162,7 +162,7 <commons.math3.version>3.4.1</commons.math3.version> <commons.collections.version>3.2.2</commons.collections.version> - <scala.version>2.12.10</scala.version> + <scala.version>2.13.5</scala.version> <scala.binary.version>2.12</scala.binary.version> <scalatest-maven-plugin.version>2.0.0</scalatest-maven-plugin.version> <scalafmt.parameters>--test</scalafmt.parameters> ``` **After** No git diff. Closes #31865 from LuciferYang/SPARK-34774. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 2e836cdb598255d6b43b386e98fcb79b70338e69) Signed-off-by: Sean Owen <srowen@gmail.com> | 18 March 2021, 12:33:46 UTC |
| fc30ec8 | HyukjinKwon | 17 March 2021, 10:55:49 UTC | [SPARK-34768][SQL] Respect the default input buffer size in Univocity This PR proposes to follow Univocity's input buffer. - Firstly, it's best to trust their judgement on the default values. Also 128 is too low. - Default values arguably have more test coverage in Univocity. - It will also fix https://github.com/uniVocity/univocity-parsers/issues/449 - ^ is a regression compared to Spark 2.4 No. In addition, It fixes a regression. Manually tested, and added a unit test. Closes #31858 from HyukjinKwon/SPARK-34768. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 385f1e8f5de5dcad62554cd75446e98c9380b384) Signed-off-by: HyukjinKwon <gurwls223@apache.org> | 17 March 2021, 10:57:06 UTC |
| edb5932 | Dongjoon Hyun | 16 March 2021, 01:49:54 UTC | [MINOR][SQL] Remove unused variable in NewInstance.constructor ### What changes were proposed in this pull request? This PR removes one unused variable in `NewInstance.constructor`. ### Why are the changes needed? This looks like a variable for debugging at the initial commit of SPARK-23584 . - https://github.com/apache/spark/commit/1b08c4393cf48e21fea9914d130d8d3bf544061d#diff-2a36e31684505fd22e2d12a864ce89fd350656d716a3f2d7789d2cdbe38e15fbR461 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass the CIs. Closes #31838 from dongjoon-hyun/minor-object. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 0a70dff0663320cabdbf4e4ecb771071582f9417) Signed-off-by: Dongjoon Hyun <dhyun@apple.com> | 16 March 2021, 01:50:24 UTC |