https://github.com/apache/spark
- HEAD
- refs/heads/branch-0.5
- refs/heads/branch-0.6
- refs/heads/branch-0.7
- refs/heads/branch-0.8
- refs/heads/branch-0.9
- refs/heads/branch-1.0
- refs/heads/branch-1.0-jdbc
- refs/heads/branch-1.1
- refs/heads/branch-1.2
- refs/heads/branch-1.3
- refs/heads/branch-1.4
- refs/heads/branch-1.5
- refs/heads/branch-1.6
- refs/heads/branch-2.0
- refs/heads/branch-2.1
- refs/heads/branch-2.2
- refs/heads/branch-2.3
- refs/heads/branch-2.4
- refs/heads/branch-3.0
- refs/heads/branch-3.1
- refs/heads/branch-3.2
- refs/heads/branch-3.3
- refs/heads/branch-3.4
- refs/heads/branch-3.5
- refs/heads/master
- refs/remotes/origin/branch-0.8
- refs/remotes/origin/td-rdd-save
- refs/tags/0.3-scala-2.8
- refs/tags/0.3-scala-2.9
- refs/tags/2.0.0-preview
- refs/tags/alpha-0.1
- refs/tags/alpha-0.2
- refs/tags/v0.5.0
- refs/tags/v0.5.1
- refs/tags/v0.5.2
- refs/tags/v0.6.0
- refs/tags/v0.6.0-yarn
- refs/tags/v0.6.1
- refs/tags/v0.6.2
- refs/tags/v0.7.0
- refs/tags/v0.7.0-bizo-1
- refs/tags/v0.7.1
- refs/tags/v0.7.2
- refs/tags/v0.9.1
- refs/tags/v0.9.2
- refs/tags/v1.0.0
- refs/tags/v1.0.1
- refs/tags/v1.0.2
- refs/tags/v1.1.0
- refs/tags/v1.1.1
- refs/tags/v1.2.0
- refs/tags/v1.2.1
- refs/tags/v1.2.2
- refs/tags/v1.3.0
- refs/tags/v1.3.1
- refs/tags/v1.4.0
- refs/tags/v1.4.1
- refs/tags/v1.5.0-rc1
- refs/tags/v1.5.0-rc2
- refs/tags/v1.5.0-rc3
- refs/tags/v1.5.1
- refs/tags/v1.6.0
- refs/tags/v1.6.1
- refs/tags/v1.6.2
- refs/tags/v1.6.3
- refs/tags/v2.0.0
- refs/tags/v2.0.1
- refs/tags/v2.0.2
- refs/tags/v2.1.0
- refs/tags/v2.1.1
- refs/tags/v2.1.2
- refs/tags/v2.1.2-rc1
- refs/tags/v2.1.2-rc2
- refs/tags/v2.1.2-rc3
- refs/tags/v2.1.2-rc4
- refs/tags/v2.1.3
- refs/tags/v2.1.3-rc1
- refs/tags/v2.1.3-rc2
- refs/tags/v2.2.0
- refs/tags/v2.2.1
- refs/tags/v2.2.1-rc1
- refs/tags/v2.2.1-rc2
- refs/tags/v2.2.2
- refs/tags/v2.2.2-rc1
- refs/tags/v2.2.2-rc2
- refs/tags/v2.2.3
- refs/tags/v2.2.3-rc1
- refs/tags/v2.3.0
- refs/tags/v2.3.0-rc1
- refs/tags/v2.3.0-rc2
- refs/tags/v2.3.0-rc3
- refs/tags/v2.3.0-rc4
- refs/tags/v2.3.1
- refs/tags/v2.3.1-rc1
- refs/tags/v2.3.1-rc2
- refs/tags/v2.3.1-rc3
- refs/tags/v2.3.1-rc4
- refs/tags/v2.3.2
- refs/tags/v2.3.2-rc1
- refs/tags/v2.3.2-rc2
- refs/tags/v2.3.2-rc3
- refs/tags/v2.3.2-rc4
- refs/tags/v2.3.2-rc5
- refs/tags/v2.3.2-rc6
- refs/tags/v2.3.3
- refs/tags/v2.3.3-rc1
- refs/tags/v2.3.3-rc2
- refs/tags/v2.3.4
- refs/tags/v2.3.4-rc1
- refs/tags/v2.4.0
- refs/tags/v2.4.0-rc1
- refs/tags/v2.4.0-rc2
- refs/tags/v2.4.0-rc3
- refs/tags/v2.4.0-rc4
- refs/tags/v2.4.0-rc5
- refs/tags/v2.4.1
- refs/tags/v2.4.1-rc1
- refs/tags/v2.4.1-rc2
- refs/tags/v2.4.1-rc3
- refs/tags/v2.4.1-rc4
- refs/tags/v2.4.1-rc5
- refs/tags/v2.4.1-rc6
- refs/tags/v2.4.1-rc7
- refs/tags/v2.4.1-rc8
- refs/tags/v2.4.1-rc9
- refs/tags/v2.4.2
- refs/tags/v2.4.2-rc1
- refs/tags/v2.4.3
- refs/tags/v2.4.3-rc1
- refs/tags/v2.4.4
- refs/tags/v2.4.4-rc1
- refs/tags/v2.4.4-rc2
- refs/tags/v2.4.4-rc3
- refs/tags/v2.4.5
- refs/tags/v2.4.5-rc1
- refs/tags/v2.4.5-rc2
- refs/tags/v2.4.6
- refs/tags/v2.4.6-rc1
- refs/tags/v2.4.6-rc2
- refs/tags/v2.4.6-rc3
- refs/tags/v2.4.6-rc4
- refs/tags/v2.4.6-rc5
- refs/tags/v2.4.6-rc6
- refs/tags/v2.4.6-rc7
- refs/tags/v2.4.6-rc8
- refs/tags/v2.4.7
- refs/tags/v2.4.7-rc1
- refs/tags/v2.4.7-rc2
- refs/tags/v2.4.7-rc3
- refs/tags/v2.4.8
- refs/tags/v2.4.8-rc1
- refs/tags/v2.4.8-rc2
- refs/tags/v2.4.8-rc3
- refs/tags/v2.4.8-rc4
- refs/tags/v3.0.0
- refs/tags/v3.0.0-preview2
- refs/tags/v3.0.0-preview2-rc1
- refs/tags/v3.0.0-preview2-rc2
- refs/tags/v3.0.0-rc1
- refs/tags/v3.0.0-rc2
- refs/tags/v3.0.0-rc3
- refs/tags/v3.0.1
- refs/tags/v3.0.1-rc1
- refs/tags/v3.0.1-rc2
- refs/tags/v3.0.1-rc3
- refs/tags/v3.0.2
- refs/tags/v3.0.2-rc1
- refs/tags/v3.0.3
- refs/tags/v3.0.3-rc1
- refs/tags/v3.1.0-rc1
- refs/tags/v3.1.1
- refs/tags/v3.1.1-rc1
- refs/tags/v3.1.1-rc2
- refs/tags/v3.1.1-rc3
- refs/tags/v3.1.2
- refs/tags/v3.1.2-rc1
- refs/tags/v3.1.3
- refs/tags/v3.1.3-rc1
- refs/tags/v3.1.3-rc2
- refs/tags/v3.1.3-rc3
- refs/tags/v3.1.3-rc4
- refs/tags/v3.2.0
- refs/tags/v3.2.0-rc1
- refs/tags/v3.2.0-rc2
- refs/tags/v3.2.0-rc3
- refs/tags/v3.2.0-rc4
- refs/tags/v3.2.0-rc5
- refs/tags/v3.2.0-rc6
- refs/tags/v3.2.0-rc7
- refs/tags/v3.2.1
- refs/tags/v3.2.1-rc1
- refs/tags/v3.2.1-rc2
- refs/tags/v3.2.2
- refs/tags/v3.2.2-rc1
- refs/tags/v3.2.3
- refs/tags/v3.2.3-rc1
- refs/tags/v3.2.4
- refs/tags/v3.2.4-rc1
- refs/tags/v3.3.0
- refs/tags/v3.3.0-rc1
- refs/tags/v3.3.0-rc2
- refs/tags/v3.3.0-rc3
- refs/tags/v3.3.0-rc4
- refs/tags/v3.3.0-rc5
- refs/tags/v3.3.0-rc6
- refs/tags/v3.3.1
- refs/tags/v3.3.1-rc1
- refs/tags/v3.3.1-rc2
- refs/tags/v3.3.1-rc3
- refs/tags/v3.3.1-rc4
- refs/tags/v3.3.2
- refs/tags/v3.3.2-rc1
- refs/tags/v3.3.3
- refs/tags/v3.3.3-rc1
- refs/tags/v3.3.4
- refs/tags/v3.3.4-rc1
- refs/tags/v3.4.0
- refs/tags/v3.4.0-rc1
- refs/tags/v3.4.0-rc2
- refs/tags/v3.4.0-rc3
- refs/tags/v3.4.0-rc4
- refs/tags/v3.4.0-rc5
- refs/tags/v3.4.0-rc6
- refs/tags/v3.4.0-rc7
- refs/tags/v3.4.1
- refs/tags/v3.4.1-rc1
- refs/tags/v3.4.2
- refs/tags/v3.4.2-rc1
- refs/tags/v3.4.3
- refs/tags/v3.4.3-rc1
- refs/tags/v3.4.3-rc2
- refs/tags/v3.5.0
- refs/tags/v3.5.0-rc1
- refs/tags/v3.5.0-rc2
- refs/tags/v3.5.0-rc3
- refs/tags/v3.5.0-rc4
- refs/tags/v3.5.0-rc5
- refs/tags/v3.5.1
- refs/tags/v3.5.1-rc1
- refs/tags/v3.5.1-rc2
- refs/tags/v4.0.0-preview1
- refs/tags/v4.0.0-preview1-rc1
- refs/tags/v4.0.0-preview1-rc2
- refs/tags/v4.0.0-preview1-rc3
Take a new snapshot of a software origin
If the archived software origin currently browsed is not synchronized with its upstream version (for instance when new commits have been issued), you can explicitly request Software Heritage to take a new snapshot of it.
Use the form below to proceed. Once a request has been submitted and accepted, it will be processed as soon as possible. You can then check its processing state by visiting this dedicated page.
Processing "take a new snapshot" request ...
Permalinks
To reference or cite the objects present in the Software Heritage archive, permalinks based on SoftWare Hash IDentifiers (SWHIDs) must be used.
Select below a type of object currently browsed in order to display its associated SWHID and permalink.
| Revision | Author | Date | Message | Commit Date |
|---|---|---|---|---|
| 482b7d5 | Maxim Gekk | 03 May 2022, 18:15:45 UTC | Preparing Spark release v3.3.0-rc1 | 03 May 2022, 18:15:45 UTC |
| 4177626 | itholic | 03 May 2022, 10:28:02 UTC | [SPARK-35320][SQL][FOLLOWUP] Remove duplicated test ### What changes were proposed in this pull request? Follow-up for https://github.com/apache/spark/pull/33525 to remove duplicated test. ### Why are the changes needed? We don't need to do the same test twice. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? This patch remove the duplicated test, so the existing test should pass. Closes #36436 from itholic/SPARK-35320. Authored-by: itholic <haejoon.lee@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit a1ac5c57c7b79fb70656638d284b77dfc4261d35) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 03 May 2022, 10:28:13 UTC |
| bd6fd7e | Ivan Sadikov | 02 May 2022, 23:30:05 UTC | [SPARK-39084][PYSPARK] Fix df.rdd.isEmpty() by using TaskContext to stop iterator on task completion ### What changes were proposed in this pull request? This PR fixes the issue described in https://issues.apache.org/jira/browse/SPARK-39084 where calling `df.rdd.isEmpty()` on a particular dataset could result in a JVM crash and/or executor failure. The issue was due to Python iterator not being synchronised with Java iterator so when the task is complete, the Python iterator continues to process data. We have introduced ContextAwareIterator as part of https://issues.apache.org/jira/browse/SPARK-33277 but we did not fix all of the places where this should be used. ### Why are the changes needed? Fixes the JVM crash when checking isEmpty() on a dataset. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? I added a test case that reproduces the issue 100%. I confirmed that the test fails without the fix and passes with the fix. Closes #36425 from sadikovi/fix-pyspark-iter-2. Authored-by: Ivan Sadikov <ivan.sadikov@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 9305cc744d27daa6a746d3eb30e7639c63329072) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 02 May 2022, 23:30:14 UTC |
| 1804f5c | Hyukjin Kwon | 02 May 2022, 08:50:01 UTC | [SPARK-37474][R][DOCS][FOLLOW-UP] Make SparkR documentation able to build on Mac OS ### What changes were proposed in this pull request? Currently SparkR documentation fails because of the usage `grep -oP `. Mac OS does not have this. This PR fixes it via using the existing way used in the current scripts at: https://github.com/apache/spark/blob/0494dc90af48ce7da0625485a4dc6917a244d580/R/check-cran.sh#L52 ### Why are the changes needed? To make the dev easier. ### Does this PR introduce _any_ user-facing change? No, dev-only. ### How was this patch tested? Manually tested via: ```bash cd R ./create-docs.sh ``` Closes #36423 from HyukjinKwon/SPARK-37474. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 6479455b8db40d584045cdb13e6c3cdfda7a2c0b) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 02 May 2022, 08:50:09 UTC |
| 4c09616 | Wenchen Fan | 02 May 2022, 02:28:36 UTC | [SPARK-38085][SQL][FOLLOWUP] Do not fail too early for DeleteFromTable ### What changes were proposed in this pull request? `DeleteFromTable` has been in Spark for a long time and there are existing Spark extensions to compile `DeleteFromTable` to physical plans. However, the new analyzer rule `RewriteDeleteFromTable` fails very early if the v2 table does not support delete. This breaks certain Spark extensions which can still execute `DeleteFromTable` for certain v2 tables. This PR simply removes the error throwing in `RewriteDeleteFromTable`. It's a safe change because: 1. the new delete-related rules only match v2 table with `SupportsRowLevelOperations`, so won't be affected by this change 2. the planner rule will fail eventually if the v2 table doesn't support deletion. Spark eagerly executes commands so Spark users can still see this error immediately. ### Why are the changes needed? To not break existing Spark extesions. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? existing tests Closes #36402 from cloud-fan/follow. Lead-authored-by: Wenchen Fan <wenchen@databricks.com> Co-authored-by: Wenchen Fan <cloud0fan@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 5630f700768432396a948376f5b46b00d4186e1b) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 02 May 2022, 02:28:51 UTC |
| c87180a | ulysses-you | 29 April 2022, 04:35:44 UTC | [SPARK-39040][SQL] Respect NaNvl in EquivalentExpressions for expression elimination ### What changes were proposed in this pull request? Respect NaNvl in EquivalentExpressions for expression elimination. ### Why are the changes needed? For example the query will fail: ```sql set spark.sql.ansi.enabled=true; set spark.sql.optimizer.excludedRules=org.apache.spark.sql.catalyst.optimizer.ConstantFolding; SELECT nanvl(1, 1/0 + 1/0); ``` ```sql org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 4.0 failed 1 times, most recent failure: Lost task 0.0 in stage 4.0 (TID 4) (10.221.98.68 executor driver): org.apache.spark.SparkArithmeticException: divide by zero. To return NULL instead, use 'try_divide'. If necessary set spark.sql.ansi.enabled to false (except for ANSI interval type) to bypass this error. == SQL(line 1, position 17) == select nanvl(1 , 1/0 + 1/0) ^^^ at org.apache.spark.sql.errors.QueryExecutionErrors$.divideByZeroError(QueryExecutionErrors.scala:151) ``` We should respect the ordering of conditional expression that always evaluate the predicate branch first, so the query above should not fail. ### Does this PR introduce _any_ user-facing change? yes, bug fix ### How was this patch tested? add test Closes #36376 from ulysses-you/SPARK-39040. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit f6b43f0384f9681b963f52a53759c521f6ac11d5) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 29 April 2022, 04:36:05 UTC |
| e7caea5 | Max Gekk | 28 April 2022, 11:11:17 UTC | [SPARK-39047][SQL][3.3] Replace the error class ILLEGAL_SUBSTRING by INVALID_PARAMETER_VALUE ### What changes were proposed in this pull request? In the PR, I propose to remove the `ILLEGAL_SUBSTRING` error class, and use `INVALID_PARAMETER_VALUE` in the case when the `strfmt` parameter of the `format_string()` function contains `%0$`. The last value is handled differently by JDKs: _"... Java 8 and Java 11 uses it as "%1$", and Java 17 throws IllegalFormatArgumentIndexException(Illegal format argument index = 0)"_. This is a backport of https://github.com/apache/spark/pull/36380. ### Why are the changes needed? To improve code maintenance and user experience with Spark SQL by reducing the number of user-facing error classes. ### Does this PR introduce _any_ user-facing change? Yes, it changes user-facing error message. Before: ```sql spark-sql> select format_string('%0$s', 'Hello'); Error in query: [ILLEGAL_SUBSTRING] The argument_index of string format cannot contain position 0$.; line 1 pos 7 ``` After: ```sql spark-sql> select format_string('%0$s', 'Hello'); Error in query: [INVALID_PARAMETER_VALUE] The value of parameter(s) 'strfmt' in `format_string` is invalid: expects %1$, %2$ and so on, but got %0$.; line 1 pos 7 ``` ### How was this patch tested? By running the affected test suites: ``` $ build/sbt "test:testOnly *SparkThrowableSuite" $ build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite -- -z text.sql" $ build/sbt "test:testOnly *QueryCompilationErrorsSuite" ``` Authored-by: Max Gekk <max.gekkgmail.com> Signed-off-by: Max Gekk <max.gekkgmail.com> (cherry picked from commit 9dcc24c36f6fcdf43bf66fe50415be575f7b2918) Signed-off-by: Max Gekk <max.gekkgmail.com> Closes #36390 from MaxGekk/error-class-ILLEGAL_SUBSTRING-3.3. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Gengliang Wang <gengliang@apache.org> | 28 April 2022, 11:11:17 UTC |
| 50f5e9c | Kent Yao | 28 April 2022, 10:57:40 UTC | [SPARK-39055][DOC] Fix documentation 404 page ### What changes were proposed in this pull request? replace unused `docs/_layouts/404.html` with `docs/404.md` ### Why are the changes needed? make the custom 404 page work <img width="638" alt="image" src="https://user-images.githubusercontent.com/8326978/165706963-6cc96cf5-299e-4b60-809f-79dd771f3b5d.png"> ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? ``` bundle exec jekyll serve ``` and visit a non-existing page `http://localhost:4000/abcd` Closes #36392 from yaooqinn/SPARK-39055. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit ec2bfa566ed3c796e91987f7a158e8b60fbd5c42) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 28 April 2022, 10:57:51 UTC |
| 606a99f | Gengliang Wang | 28 April 2022, 01:59:17 UTC | [SPARK-39046][SQL] Return an empty context string if TreeNode.origin is wrongly set ### What changes were proposed in this pull request? For the query context `TreeNode.origin.context`, this PR proposal to return an empty context string if * the query text/ the start index/ the stop index is missing * the start index is less than 0 * the stop index is larger than the length of query text * the start index is larger than the stop index ### Why are the changes needed? There are downstream projects that depend on Spark. There is no guarantee for the correctness of TreeNode.origin. Developers may create a plan/expression with a Origin containing wrong startIndex/stopIndex/sqlText. Thus, to avoid errors in calling `String.substring` or showing misleading debug information, I suggest returning an empty context string if TreeNode.origin is wrongly set. The query context is just for better error messages and we should handle it cautiously. ### Does this PR introduce _any_ user-facing change? No, the context framework is not released yet. ### How was this patch tested? UT Closes #36379 from gengliangwang/safeContext. Authored-by: Gengliang Wang <gengliang@apache.org> Signed-off-by: Gengliang Wang <gengliang@apache.org> (cherry picked from commit 7fe2759e9f81ec267e92e1c6f8a48f42042db791) Signed-off-by: Gengliang Wang <gengliang@apache.org> | 28 April 2022, 01:59:34 UTC |
| 96d66b0 | Xinrong Meng | 28 April 2022, 00:25:37 UTC | [SPARK-38988][PYTHON] Suppress PerformanceWarnings of `DataFrame.info` ### What changes were proposed in this pull request? Suppress PerformanceWarnings of DataFrame.info ### Why are the changes needed? To improve usability. ### Does this PR introduce _any_ user-facing change? No. Only PerformanceWarnings of DataFrame.info are suppressed. ### How was this patch tested? Manual tests. Closes #36367 from xinrong-databricks/frame.info. Authored-by: Xinrong Meng <xinrong.meng@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 594337fad131280f62107326062fb554f0566d43) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 28 April 2022, 00:25:51 UTC |
| c9b6b50 | Bjørn Jørgensen | 28 April 2022, 00:20:53 UTC | [SPARK-39049][PYTHON][CORE][ML] Remove unneeded `pass` ### What changes were proposed in this pull request? Remove unneeded `pass` ### Why are the changes needed? Class`s Estimator, Transformer and Evaluator are abstract classes. Which has functions. ValueError in def run() has code. By removing `pass` it will be easier to read, understand and reuse code. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests passed. Closes #36383 from bjornjorgensen/remove-unneeded-pass. Lead-authored-by: Bjørn Jørgensen <bjornjorgensen@gmail.com> Co-authored-by: bjornjorgensen <bjornjorgensen@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 0e875875059c1cbf36de49205a4ce8dbc483d9d1) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 28 April 2022, 00:21:07 UTC |
| 84addc5 | Xinrong Meng | 28 April 2022, 00:17:24 UTC | [SPARK-39051][PYTHON] Minor refactoring of `python/pyspark/sql/pandas/conversion.py` Minor refactoring of `python/pyspark/sql/pandas/conversion.py`, which includes: - doc change - renaming To improve code readability and maintainability. No. Existing tests. Closes #36384 from xinrong-databricks/conversion.py. Authored-by: Xinrong Meng <xinrong.meng@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit c19fadabde3ef3f9c7e4fa9bf74632a4f8e1f3e2) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 28 April 2022, 00:20:18 UTC |
| 4a4e35a | Jiaan Geng | 27 April 2022, 16:43:55 UTC | [SPARK-38997][SQL] DS V2 aggregate push-down supports group by expressions ### What changes were proposed in this pull request? Currently, Spark DS V2 aggregate push-down only supports group by column. But the SQL show below is very useful and common. ``` SELECT CASE WHEN 'SALARY' > 8000.00 AND 'SALARY' < 10000.00 THEN 'SALARY' ELSE 0.00 END AS key, SUM('SALARY') FROM "test"."employee" GROUP BY key ``` ### Why are the changes needed? Let DS V2 aggregate push-down supports group by expressions ### Does this PR introduce _any_ user-facing change? 'No'. New feature. ### How was this patch tested? New tests Closes #36325 from beliefer/SPARK-38997. Authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit ee6ea3c68694e35c36ad006a7762297800d1e463) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 27 April 2022, 16:44:18 UTC |
| b25276f | Hyukjin Kwon | 27 April 2022, 13:17:51 UTC | [SPARK-39015][SQL][3.3] Remove the usage of toSQLValue(v) without an explicit type ### What changes were proposed in this pull request? This PR is a backport of https://github.com/apache/spark/pull/36351 This PR proposes to remove the the usage of `toSQLValue(v)` without an explicit type. `Literal(v)` is intended to be used from end-users so it cannot handle our internal types such as `UTF8String` and `ArrayBasedMapData`. Using this method can lead to unexpected error messages such as: ``` Caused by: org.apache.spark.SparkRuntimeException: [UNSUPPORTED_FEATURE] The feature is not supported: literal for 'hair' of class org.apache.spark.unsafe.types.UTF8String. at org.apache.spark.sql.errors.QueryExecutionErrors$.literalTypeUnsupportedError(QueryExecutionErrors.scala:241) at org.apache.spark.sql.catalyst.expressions.Literal$.apply(literals.scala:99) at org.apache.spark.sql.errors.QueryErrorsBase.toSQLValue(QueryErrorsBase.scala:45) ... ``` Since It is impossible to have the corresponding data type from the internal types as one type can map to multiple external types (e.g., `Long` for `Timestamp`, `TimestampNTZ`, and `LongType`), the removal approach was taken. ### Why are the changes needed? To provide the error messages as intended. ### Does this PR introduce _any_ user-facing change? Yes. ```scala import org.apache.spark.sql.Row import org.apache.spark.sql.types.StructType import org.apache.spark.sql.types.StringType import org.apache.spark.sql.types.DataTypes val arrayStructureData = Seq( Row(Map("hair"->"black", "eye"->"brown")), Row(Map("hair"->"blond", "eye"->"blue")), Row(Map())) val mapType = DataTypes.createMapType(StringType, StringType) val arrayStructureSchema = new StructType().add("properties", mapType) val mapTypeDF = spark.createDataFrame( spark.sparkContext.parallelize(arrayStructureData),arrayStructureSchema) spark.conf.set("spark.sql.ansi.enabled", true) mapTypeDF.selectExpr("element_at(properties, 'hair')").show ``` Before: ``` Caused by: org.apache.spark.SparkRuntimeException: [UNSUPPORTED_FEATURE] The feature is not supported: literal for 'hair' of class org.apache.spark.unsafe.types.UTF8String. at org.apache.spark.sql.errors.QueryExecutionErrors$.literalTypeUnsupportedError(QueryExecutionErrors.scala:241) at org.apache.spark.sql.catalyst.expressions.Literal$.apply(literals.scala:99) at org.apache.spark.sql.errors.QueryErrorsBase.toSQLValue(QueryErrorsBase.scala:45) ... ``` After: ``` Caused by: org.apache.spark.SparkNoSuchElementException: [MAP_KEY_DOES_NOT_EXIST] Key 'hair' does not exist. To return NULL instead, use 'try_element_at'. If necessary set spark.sql.ansi.enabled to false to bypass this error. == SQL(line 1, position 0) == element_at(properties, 'hair') ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ ``` ### How was this patch tested? Unittest was added. Otherwise, existing test cases should cover. Closes #36375 from HyukjinKwon/SPARK-39015-3.3. Lead-authored-by: Hyukjin Kwon <gurwls223@apache.org> Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 27 April 2022, 13:17:51 UTC |
| b3ecff3 | Peter Toth | 27 April 2022, 08:16:15 UTC | [SPARK-34079][SQL][FOLLOW-UP] Revert some changes in InjectRuntimeFilterSuite To remove unnecessary changes from `InjectRuntimeFilterSuite` after https://github.com/apache/spark/pull/32298. These are not needed after https://github.com/apache/spark/pull/34929 as the final optimized plan does'n contain any `WithCTE` nodes. No need for those changes. No. Added new test. Closes #36361 from peter-toth/SPARK-34079-multi-column-scalar-subquery-follow-up-2. Authored-by: Peter Toth <peter.toth@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit d05e01d54024e3844f1e48e03bad3fd814b8f6b9) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 27 April 2022, 08:18:06 UTC |
| d59f118 | vadim | 27 April 2022, 07:56:18 UTC | [SPARK-39032][PYTHON][DOCS] Examples' tag for pyspark.sql.functions.when() ### What changes were proposed in this pull request? Fix missing keyword for `pyspark.sql.functions.when()` documentation. ### Why are the changes needed? [Documentation](https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.sql.functions.when.html) is not formatted correctly ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? All tests passed. Closes #36369 from vadim/SPARK-39032. Authored-by: vadim <86705+vadim@users.noreply.github.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 5b53bdfa83061c160652e07b999f996fc8bd2ece) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 27 April 2022, 07:56:30 UTC |
| 793ba60 | allisonwang-db | 27 April 2022, 05:39:44 UTC | [SPARK-38918][SQL] Nested column pruning should filter out attributes that do not belong to the current relation ### What changes were proposed in this pull request? This PR updates `ProjectionOverSchema` to use the outputs of the data source relation to filter the attributes in the nested schema pruning. This is needed because the attributes in the schema do not necessarily belong to the current data source relation. For example, if a filter contains a correlated subquery, then the subquery's children can contain attributes from both the inner query and the outer query. Since the `RewriteSubquery` batch happens after early scan pushdown rules, nested schema pruning can wrongly use the inner query's attributes to prune the outer query data schema, thus causing wrong results and unexpected exceptions. ### Why are the changes needed? To fix a bug in `SchemaPruning`. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test Closes #36216 from allisonwang-db/spark-38918-nested-column-pruning. Authored-by: allisonwang-db <allison.wang@databricks.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> (cherry picked from commit 150434b5d7909dcf8248ffa5ec3d937ea3da09fd) Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 27 April 2022, 05:39:53 UTC |
| 3df3421 | Max Gekk | 27 April 2022, 04:15:04 UTC | [SPARK-39027][SQL][3.3] Output SQL statements in error messages in upper case and w/o double quotes ### What changes were proposed in this pull request? In the PR, I propose to output any SQL statement in error messages in upper case, and apply new implementation of `QueryErrorsBase.toSQLStmt()` to all exceptions in `Query.*Errors` w/ error classes. Also this PR modifies all affected tests, see the list in the section "How was this patch tested?". This is a backport of https://github.com/apache/spark/pull/36359. ### Why are the changes needed? To improve user experience with Spark SQL by highlighting SQL statements in error massage and make them more visible to users. Also this PR makes SQL statements in error messages consistent to the docs where such elements are showed in upper case w/ any quotes. ### Does this PR introduce _any_ user-facing change? Yes. The changes might influence on error messages: Before: ```sql The operation "DESC PARTITION" is not allowed ``` After: ```sql The operation DESC PARTITION is not allowed ``` ### How was this patch tested? By running affected test suites: ``` $ build/sbt "sql/testOnly *QueryExecutionErrorsSuite" $ build/sbt "sql/testOnly *QueryParsingErrorsSuite" $ build/sbt "sql/testOnly *QueryCompilationErrorsSuite" $ build/sbt "test:testOnly *QueryCompilationErrorsDSv2Suite" $ build/sbt "test:testOnly *ExtractPythonUDFFromJoinConditionSuite" $ build/sbt "testOnly *PlanParserSuite" $ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z transform.sql" $ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z join-lateral.sql" $ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z describe.sql" $ build/sbt "testOnly *DDLParserSuite" ``` Closes #36363 from MaxGekk/error-class-toSQLStmt-no-quotes-3.3. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 27 April 2022, 04:15:04 UTC |
| 80efaa2 | Ivan Sadikov | 27 April 2022, 03:44:50 UTC | [SPARK-34863][SQL][FOLLOW-UP] Handle IsAllNull in OffHeapColumnVector ### What changes were proposed in this pull request? This PR fixes an issue of reading null columns with the vectorised Parquet reader when the entire column is null or does not exist. This is especially noticeable when performing a merge or schema evolution in Parquet. The issue is only exposed with the `OffHeapColumnVector` which does not handle `isAllNull` flag - `OnHeapColumnVector` already handles `isAllNull` so everything works fine there. ### Why are the changes needed? The change is needed to correctly read null columns using the vectorised reader in the off-heap mode. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? I updated the existing unit tests to ensure we cover off-heap mode. I confirmed that the tests pass with the fix and fail without. Closes #36366 from sadikovi/fix-off-heap-cv. Authored-by: Ivan Sadikov <ivan.sadikov@databricks.com> Signed-off-by: Chao Sun <sunchao@apple.com> | 27 April 2022, 03:45:23 UTC |
| 052ae96 | bjornjorgensen | 27 April 2022, 01:10:11 UTC | [SPARK-39030][PYTHON] Rename sum to avoid shading the builtin Python function ### What changes were proposed in this pull request? Rename sum to something else. ### Why are the changes needed? Sum is a build in function in python. [SUM() at python docs](https://docs.python.org/3/library/functions.html#sum) ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Use existing tests. Closes #36364 from bjornjorgensen/rename-sum. Authored-by: bjornjorgensen <bjornjorgensen@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 3821d807a599a2d243465b4e443f1eb68251d432) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 27 April 2022, 01:10:20 UTC |
| 41d44d1 | Cheng Su | 26 April 2022, 23:12:35 UTC | Revert "[SPARK-38354][SQL] Add hash probes metric for shuffled hash join" This reverts commit 158436655f30141bbd5afa8d95aec66282a5c4b4, as the original PR caused performance regression reported in https://github.com/apache/spark/pull/35686#issuecomment-1107807027 . Closes #36338 from c21/revert-metrics. Authored-by: Cheng Su <chengsu@fb.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 6b5a1f9df28262fa90d28dc15af67e8a37a9efcf) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 26 April 2022, 23:12:45 UTC |
| e2f82fd | yangjie01 | 26 April 2022, 22:52:22 UTC | [SPARK-39019][TESTS] Use `withTempPath` to clean up temporary data directory after `SPARK-37463: read/write Timestamp ntz to Orc with different time zone` ### What changes were proposed in this pull request? `SPARK-37463: read/write Timestamp ntz to Orc with different time zone` use the absolute path to save the test data, and does not clean up the test data after the test. This pr change to use `withTempPath` to ensure the data directory is cleaned up after testing. ### Why are the changes needed? Clean up the temporary data directory after test. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? - Pass GA - Manual test: Run ``` mvn clean install -pl sql/core -am -DskipTests mvn clean test -pl sql/core -Dtest=none -DwildcardSuites=org.apache.spark.sql.execution.datasources.orc.OrcV1QuerySuite git status ``` **Before** ``` sql/core/ts_ntz_orc/ ls sql/core/ts_ntz_orc _SUCCESS part-00000-9523e257-5024-4980-8bb3-12070222b0bd-c000.snappy.orc ``` **After** No residual `sql/core/ts_ntz_orc/` Closes #36352 from LuciferYang/SPARK-39019. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 97449d23a3b2232e14e63c6645919c5d93e4491c) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 26 April 2022, 22:52:53 UTC |
| dd192b7 | Peter Toth | 26 April 2022, 10:19:49 UTC | [SPARK-34079][SQL][FOLLOW-UP] Remove debug logging ### What changes were proposed in this pull request? To remove debug logging accidentally left in code after https://github.com/apache/spark/pull/32298. ### Why are the changes needed? No need for that logging. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes #36354 from peter-toth/SPARK-34079-multi-column-scalar-subquery-follow-up. Authored-by: Peter Toth <peter.toth@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit f24c9b0d135ce7ef4f219ab661a6b665663039f0) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 26 April 2022, 10:19:58 UTC |
| ff9b163 | Hyukjin Kwon | 26 April 2022, 01:57:11 UTC | [SPARK-39001][SQL][DOCS][FOLLOW-UP] Revert the doc changes for dropFieldIfAllNull, prefersDecimal and primitivesAsString (schema_of_json) This PR is a followup of https://github.com/apache/spark/pull/36339. Actually `schema_of_json` expression supports `dropFieldIfAllNull`, `prefersDecimal` an `primitivesAsString`: ```scala scala> spark.range(1).selectExpr("""schema_of_json("{'a': null}", map('dropFieldIfAllNull', 'true'))""").show() +---------------------------+ |schema_of_json({'a': null})| +---------------------------+ | STRUCT<>| +---------------------------+ scala> spark.range(1).selectExpr("""schema_of_json("{'b': 1.0}", map('prefersDecimal', 'true'))""").show() +--------------------------+ |schema_of_json({'b': 1.0})| +--------------------------+ | STRUCT<b: DECIMAL...| +--------------------------+ scala> spark.range(1).selectExpr("""schema_of_json("{'b': 1.0}", map('primitivesAsString', 'true'))""").show() +--------------------------+ |schema_of_json({'b': 1.0})| +--------------------------+ | STRUCT<b: STRING>| +--------------------------+ ``` For correct documentation. To end users, no because it's a partial revert of the docs unreleased yet. Partial logical revert so I did not add a test also since this is just a doc change. Closes #36346 from HyukjinKwon/SPARK-39001-followup. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 5056c6cc333982d39546f2acf9a889d102cc4ab3) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 26 April 2022, 01:57:58 UTC |
| cb40bee | Hyukjin Kwon | 25 April 2022, 23:51:54 UTC | [SPARK-39008][BUILD] Change ASF as a single author in Spark distribution ### What changes were proposed in this pull request? This PR proposes to have a single author as ASF for Apache Spark project since the project is being maintained under this organization. For `pom.xml`, I referred to Hadoop https://github.com/apache/hadoop/blob/56cfd6061770872ce35cf815544b0c0f49613209/pom.xml#L76-L79 ### Why are the changes needed? We mention several original developers in authors in `pom.xml` or `R/pkg/DESRIPTION` while the project is being maintained under ASF organization. In addition, seems like these people (at least Matei) here get arbitrary spam emails. ### Does this PR introduce _any_ user-facing change? Yes, the authors in the distributions will remain as ASF alone in Apache Spark distributions. ### How was this patch tested? No, existing build and CRAN check should validate it. Closes #36337 from HyukjinKwon/SPARK-39008. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit ce957e26e72d022b8fd9664bd19c431536302c36) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 25 April 2022, 23:52:06 UTC |
| 49830c6 | jackierwzhang | 25 April 2022, 17:11:46 UTC | [SPARK-38939][SQL] Support DROP COLUMN [IF EXISTS] syntax ### What changes were proposed in this pull request? This PR introduces the following: - Parser changes to have an `IF EXISTS` clause for `DROP COLUMN`. - Logic to silence the errors within parser and analyzer when encountering missing columns while using `IF EXISTS` - Ensure only resolving and dropping existing columns inside table schema ### Why are the changes needed? Currently `ALTER TABLE ... DROP COLUMN(s) ...` syntax will always throw error if the column doesn't exist. This PR would like to provide an (IF EXISTS) syntax to provide better user experience for downstream handlers (such as Delta with incoming column dropping support) that support it, and make consistent with some other DMLs such as `DROP TABLE IF EXISTS`. ### Does this PR introduce _any_ user-facing change? User may now specify `ALTER TABLE xxx DROP COLUMN(S) IF EXISTS a, a.b, c.d`. ### How was this patch tested? Modified existing unit tests and new unit tests. cloud-fan gengliangwang MaxGekk Closes #36252 from jackierwzhang/SPARK-38939. Authored-by: jackierwzhang <ruowang.zhang@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 25 April 2022, 18:49:28 UTC |
| c6698cc | Hyukjin Kwon | 25 April 2022, 17:25:56 UTC | [SPARK-39001][SQL][DOCS] Document which options are unsupported in CSV and JSON functions This PR proposes to document which options do not work and are explicitly unsupported in CSV and JSON functions. To avoid users to misunderstand the options. Yes, it documents which options don't work in CSV/JSON expressions. I manually built the docs and checked the HTML output. Closes #36339 from HyukjinKwon/SPARK-39001. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Max Gekk <max.gekk@gmail.com> (cherry picked from commit 10a643c8af368cce131ef217f6ef610bf84f8b9c) Signed-off-by: Max Gekk <max.gekk@gmail.com> | 25 April 2022, 17:28:32 UTC |
| f056435 | Max Gekk | 25 April 2022, 17:16:08 UTC | [SPARK-39007][SQL][3.3] Use double quotes for SQL configs in error messages ### What changes were proposed in this pull request? Wrap SQL configs in error messages by double quotes. Added the `toSQLConf()` method to `QueryErrorsBase` to invoke it from `Query.*Errors`. This is a backport of https://github.com/apache/spark/pull/36335. ### Why are the changes needed? 1. To highlight types and make them more visible for users. 2. To be able to easily parse types from error text. 3. To be consistent to other outputs of identifiers, sql statement and etc. where Spark uses quotes or ticks. ### Does this PR introduce _any_ user-facing change? Yes, it changes user-facing error messages. ### How was this patch tested? By running the modified test suites: ``` $ build/sbt "testOnly *QueryCompilationErrorsSuite" $ build/sbt "testOnly *QueryExecutionAnsiErrorsSuite" $ build/sbt "testOnly *QueryExecutionErrorsSuite" ``` Authored-by: Max Gekk <max.gekkgmail.com> Signed-off-by: Max Gekk <max.gekkgmail.com> (cherry picked from commit f01bff971e36870e101b2f76195e0d380db64e0c) Signed-off-by: Max Gekk <max.gekkgmail.com> Closes #36340 from MaxGekk/output-conf-error-class-3.3. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 25 April 2022, 17:16:08 UTC |
| ffa8152 | Bruce Robbins | 25 April 2022, 05:49:15 UTC | [SPARK-38868][SQL] Don't propagate exceptions from filter predicate when optimizing outer joins ### What changes were proposed in this pull request? Change `EliminateOuterJoin#canFilterOutNull` to return `false` when a `where` condition throws an exception. ### Why are the changes needed? Consider this query: ``` select * from (select id, id as b from range(0, 10)) l left outer join (select id, id + 1 as c from range(0, 10)) r on l.id = r.id where assert_true(c > 0) is null; ``` The query should succeed, but instead fails with ``` java.lang.RuntimeException: '(c#1L > cast(0 as bigint))' is not true! ``` This happens even though there is no row where `c > 0` is false. The `EliminateOuterJoin` rule checks if it can convert the outer join to a inner join based on the expression in the where clause, which in this case is ``` assert_true(c > 0) is null ``` `EliminateOuterJoin#canFilterOutNull` evaluates that expression with `c` set to `null` to see if the result is `null` or `false`. That rule doesn't expect the result to be a `RuntimeException`, but in this case it always is. That is, the assertion is failing during optimization, not at run time. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? New unit test. Closes #36230 from bersprockets/outer_join_eval_assert_issue. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit e2930b8dc087e5a284b451c4cac6c1a2459b456d) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 25 April 2022, 05:49:41 UTC |
| 5dfa24d | Max Gekk | 25 April 2022, 02:53:27 UTC | [SPARK-38996][SQL][3.3] Use double quotes for types in error messages ### What changes were proposed in this pull request? This PR is a backport of https://github.com/apache/spark/pull/36324 In the PR, I propose to modify the method `QueryErrorsBase.toSQLType()` to use double quotes for types in error messages. ### Why are the changes needed? 1. To highlight types and make them more visible for users. 2. To be able to easily parse types from error text. 3. To be consistent to other outputs of identifiers, sql statement and etc. where Spark uses quotes or ticks. ### Does this PR introduce _any_ user-facing change? Yes, the PR changes user-facing errors. ### How was this patch tested? By running the modified test suites: ``` $ build/sbt "test:testOnly *QueryParsingErrorsSuite" $ build/sbt "test:testOnly *QueryCompilationErrorsSuite" $ build/sbt "test:testOnly *QueryExecutionErrorsSuite" $ build/sbt "testOnly *CastSuite" $ build/sbt "testOnly *AnsiCastSuiteWithAnsiModeOn" $ build/sbt "testOnly *EncoderResolutionSuite" $ build/sbt "test:testOnly *DatasetSuite" $ build/sbt "test:testOnly *InsertSuite" ``` Authored-by: Max Gekk <max.gekkgmail.com> Signed-off-by: Max Gekk <max.gekkgmail.com> (cherry picked from commit 5e494d3de70c6e46f33addd751a227e6f9d5703f) Signed-off-by: Max Gekk <max.gekkgmail.com> Closes #36329 from MaxGekk/wrap-types-in-error-classes-3.3. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 25 April 2022, 02:53:27 UTC |
| 9c5f38d | Anton Okolnychyi | 22 April 2022, 21:11:47 UTC | [SPARK-38977][SQL] Fix schema pruning with correlated subqueries ### What changes were proposed in this pull request? This PR fixes schema pruning for queries with multiple correlated subqueries. Previously, Spark would throw an exception trying to determine root fields in `SchemaPruning$identifyRootFields`. That was happening because expressions in predicates that referenced attributes in subqueries were not ignored. That's why attributes from multiple subqueries could conflict with each other (e.g. incompatible types) even though they should be ignored. For instance, the following query would throw a runtime exception. ``` SELECT name FROM contacts c WHERE EXISTS (SELECT 1 FROM ids i WHERE i.value = c.id) AND EXISTS (SELECT 1 FROM first_names n WHERE c.name.first = n.value) ``` ``` [info] org.apache.spark.SparkException: Failed to merge fields 'value' and 'value'. Failed to merge incompatible data types int and string [info] at org.apache.spark.sql.errors.QueryExecutionErrors$.failedMergingFieldsError(QueryExecutionErrors.scala:936) ``` ### Why are the changes needed? These changes are needed to avoid exceptions for some queries with multiple correlated subqueries. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? This PR comes with tests. Closes #36303 from aokolnychyi/spark-38977. Authored-by: Anton Okolnychyi <aokolnychyi@apple.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> (cherry picked from commit 0c9947dabcb71de414c97c0e60a1067e468f2642) Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> | 22 April 2022, 21:12:01 UTC |
| 02780b9 | Chandni Singh | 22 April 2022, 19:38:55 UTC | [SPARK-38973][SHUFFLE] Mark stage as merge finalized irrespective of its state ### What changes were proposed in this pull request? This change fixes the scenarios where a stage re-attempt doesn't complete successfully, even though all the tasks complete when push-based shuffle is enabled. With Adaptive Merge Finalization, a stage may be triggered for finalization when it is the below state: - The stage is not running (not in the running set of the DAGScheduler) - had failed or canceled or waiting, and - The stage has no pending partitions (all the tasks completed at-least once) For such a stage when the finalization completes, the stage will still not be marked as mergeFinalized. The stage of the stage will be: - `stage.shuffleDependency.mergeFinalized = false` - `stage.shuffleDependency.getFinalizeTask != Nil` - Merged statuses of the state are unregistered When the stage is resubmitted, the newer attempt of the stage will never complete even though its tasks may be completed. This is because the newer attempt of the stage will have `shuffleMergeEnabled = true`, since with the previous attempt the stage was never marked as mergedFinalized, and the finalizeTask is present (from finalization attempt for previous stage attempt). So, when all the tasks of the newer attempt complete, then these conditions will be true: - stage will be running - There will be no pending partitions since all the tasks completed - `stage.shuffleDependency.shuffleMergeEnabled = true` - `stage.shuffleDependency.shuffleMergeFinalized = false` - `stage.shuffleDependency.getFinalizeTask` is `not empty` This leads the DAGScheduler to try scheduling finalization and not trigger the completion of the Stage. However because of the last condition it never even schedules the finalization and the stage never completes. In addition, for determinate stages, which have completed merge finalization, we don't need to unregister merge results - since the stage retry, or any other stage computing the same shuffle id, can use it. ### Why are the changes needed? The change fixes the above issue where the application gets stalled as some stages don't complete successfully. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? I have just modified the existing UT. A stage will be marked finalized irrespective of its state and for deterministic stage we don't want to unregister merge results. Closes #36293 from otterc/SPARK-38973. Authored-by: Chandni Singh <singh.chandni@gmail.com> Signed-off-by: Mridul Muralidharan <mridul<at>gmail.com> (cherry picked from commit f4a81ae6e631af27fc5eef81097b842d4e0e2e51) Signed-off-by: Mridul Muralidharan <mridulatgmail.com> | 22 April 2022, 19:39:10 UTC |
| ca9138e | Cheng Su | 22 April 2022, 17:13:40 UTC | [SPARK-34960][SQL][DOCS][FOLLOWUP] Improve doc for DSv2 aggregate push down ### What changes were proposed in this pull request? This is a followup per comment in https://issues.apache.org/jira/browse/SPARK-34960, to improve the documentation for data source v2 aggregate push down of Parquet and ORC. * Unify SQL config docs between Parquet and ORC, and add the note that if statistics is missing from any file footer, exception would be thrown. * Also adding the same note for exception in Parquet and ORC methods to aggregate from statistics. Though in future Spark release, we may improve the behavior to fallback to aggregate from real data of file, in case any statistics are missing. We'd better to make a clear documentation for current behavior now. ### Why are the changes needed? Give users & developers a better idea of when aggregate push down would throw exception. Have a better documentation for current behavior. ### Does this PR introduce _any_ user-facing change? Yes, the documentation change in SQL configs. ### How was this patch tested? Existing tests as this is just documentation change. Closes #36311 from c21/agg-doc. Authored-by: Cheng Su <chengsu@fb.com> Signed-off-by: huaxingao <huaxin_gao@apple.com> (cherry picked from commit 86b8757c2c4bab6a0f7a700cf2c690cdd7f31eba) Signed-off-by: huaxingao <huaxin_gao@apple.com> | 22 April 2022, 17:14:37 UTC |
| 9cc2ae7 | Hyukjin Kwon | 22 April 2022, 10:01:05 UTC | [SPARK-38992][CORE] Avoid using bash -c in ShellBasedGroupsMappingProvider ### What changes were proposed in this pull request? This PR proposes to avoid using `bash -c` in `ShellBasedGroupsMappingProvider`. This could allow users a command injection. ### Why are the changes needed? For a security purpose. ### Does this PR introduce _any_ user-facing change? Virtually no. ### How was this patch tested? Manually tested. Closes #36315 from HyukjinKwon/SPARK-38992. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit c83618e4e5fc092829a1f2a726f12fb832e802cc) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 22 April 2022, 10:01:26 UTC |
| 0fdb675 | Gengliang Wang | 22 April 2022, 05:35:15 UTC | [SPARK-38813][3.3][SQL][FOLLOWUP] Improve the analysis check for TimestampNTZ output ### What changes were proposed in this pull request? In https://github.com/apache/spark/pull/36094, a check for failing TimestampNTZ output is added. However, if there is an unresolved attribute in the plan, even if it is note related to TimestampNTZ, the error message becomes confusing ``` scala> val df = spark.range(2) df: org.apache.spark.sql.Dataset[Long] = [id: bigint] scala> df.select("i") org.apache.spark.sql.AnalysisException: Invalid call to dataType on unresolved object; 'Project ['i] +- Range (0, 2, step=1, splits=Some(16)) at org.apache.spark.sql.catalyst.analysis.UnresolvedAttribute.dataType(unresolved.scala:137) at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.$anonfun$checkAnalysis$4(CheckAnalysis.scala:164) ... ``` Before changes it was ``` org.apache.spark.sql.AnalysisException: Column 'i' does not exist. Did you mean one of the following? [id]; ``` This PR is the improve the check for TimestampNTZ and restore the error message for unresolved attributes. ### Why are the changes needed? Fix a regression in analysis error message. ### Does this PR introduce _any_ user-facing change? No, it is not released yet. ### How was this patch tested? Manual test Closes #36316 from gengliangwang/bugFix. Authored-by: Gengliang Wang <gengliang@apache.org> Signed-off-by: Gengliang Wang <gengliang@apache.org> | 22 April 2022, 05:35:15 UTC |
| 5f39653 | Bruce Robbins | 22 April 2022, 03:30:34 UTC | [SPARK-38990][SQL] Avoid `NullPointerException` when evaluating date_trunc/trunc format as a bound reference ### What changes were proposed in this pull request? Change `TruncInstant.evalHelper` to pass the input row to `format.eval` when `format` is a not a literal (and therefore might be a bound reference). ### Why are the changes needed? This query fails with a `java.lang.NullPointerException`: ``` select date_trunc(col1, col2) from values ('week', timestamp'2012-01-01') as data(col1, col2); ``` This only happens if the data comes from an inline table. When the source is an inline table, `ConvertToLocalRelation` attempts to evaluate the function against the data in interpreted mode. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Update to unit tests. Closes #36312 from bersprockets/date_trunc_issue. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 2e4f4abf553cedec1fa8611b9494a01d24e6238a) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 22 April 2022, 03:30:53 UTC |
| 6306410 | allisonwang-db | 22 April 2022, 03:24:34 UTC | [SPARK-38974][SQL] Filter registered functions with a given database name in list functions ### What changes were proposed in this pull request? This PR fixes a bug in list functions to filter out registered functions that do not belong to the specified database. ### Why are the changes needed? To fix a bug for `SHOW FUNCTIONS IN [db]`. Listed functions should only include all temporary functions and persistent functions in the specified database, instead of all registered functions in the function registry. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test Closes #36291 from allisonwang-db/spark-38974-list-functions. Authored-by: allisonwang-db <allison.wang@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit cbfa0513421d5e9e9b7410d7f86b8e25df4ae548) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 22 April 2022, 03:24:52 UTC |
| 4cb2ae2 | Bruce Robbins | 22 April 2022, 03:12:32 UTC | [SPARK-38666][SQL] Add missing aggregate filter checks ### What changes were proposed in this pull request? Add checks in `ResolveFunctions#validateFunction` to ensure the following about each aggregate filter: - has a datatype of boolean - doesn't contain an aggregate expression - doesn't contain a window expression `ExtractGenerator` already handles the case of a generator in an aggregate filter. ### Why are the changes needed? There are three cases where a query with an aggregate filter produces non-helpful error messages. 1) Window expression in aggregate filter ``` select sum(a) filter (where nth_value(a, 2) over (order by b) > 1) from (select 1 a, '2' b); ``` The above query should produce an analysis error, but instead produces a stack overflow: ``` java.lang.StackOverflowError: null at scala.collection.generic.Growable.$plus$plus$eq(Growable.scala:62) ~[scala-library.jar:?] at scala.collection.generic.Growable.$plus$plus$eq$(Growable.scala:53) ~[scala-library.jar:?] at scala.collection.immutable.VectorBuilder.$plus$plus$eq(Vector.scala:668) ~[scala-library.jar:?] at scala.collection.immutable.VectorBuilder.$plus$plus$eq(Vector.scala:645) ~[scala-library.jar:?] at scala.collection.generic.GenericCompanion.apply(GenericCompanion.scala:56) ~[scala-library.jar:?] at org.apache.spark.sql.catalyst.trees.UnaryLike.children(TreeNode.scala:1172) ~[spark-catalyst_2.12-3.4.0-SNAPSHOT.jar:3.4.0-SNAPSHOT] at org.apache.spark.sql.catalyst.trees.UnaryLike.children$(TreeNode.scala:1172) ~[spark-catalyst_2.12-3.4.0-SNAPSHOT.jar:3.4.0-SNAPSHOT] at org.apache.spark.sql.catalyst.expressions.UnaryExpression.children$lzycompute(Expression.scala:494) ~[spark-catalyst_2.12-3.4.0-SNAPSHOT.jar:3.4.0-SNAPSHOT] at org.apache.spark.sql.catalyst.expressions.UnaryExpression.children(Expression.scala:494) ~[spark-catalyst_2.12-3.4.0-SNAPSHOT.jar:3.4.0-SNAPSHOT] at org.apache.spark.sql.catalyst.expressions.Expression.childrenResolved(Expression.scala:223) ~[spark-catalyst_2.12-3.4.0-SNAPSHOT.jar:3.4.0-SNAPSHOT] at org.apache.spark.sql.catalyst.expressions.Alias.resolved$lzycompute(namedExpressions.scala:155) ~[spark-catalyst_2.12-3.4.0-SNAPSHOT.jar:3.4.0-SNAPSHOT] at org.apache.spark.sql.catalyst.expressions.Alias.resolved(namedExpressions.scala:155) ~[spark-catalyst_2.12-3.4.0-SNAPSHOT.jar:3.4.0-SNAPSHOT] ``` With this PR, the query will instead produce ``` org.apache.spark.sql.AnalysisException: FILTER expression contains window function. It cannot be used in an aggregate function; line 1 pos 7 ``` 2) Non-boolean filter expression ``` select sum(a) filter (where a) from (select 1 a, '2' b); ``` This query should produce an analysis error, but instead causes a projection compilation error or whole-stage codegen error (depending on the datatype of the expression): ```` org.codehaus.commons.compiler.CompileException: File 'generated.java', Line 50, Column 6: Not a boolean expression at org.codehaus.janino.UnitCompiler.compileError(UnitCompiler.java:12021) ~[janino-3.0.16.jar:?] at org.codehaus.janino.UnitCompiler.compileBoolean2(UnitCompiler.java:4049) ~[janino-3.0.16.jar:?] at org.codehaus.janino.UnitCompiler.access$6300(UnitCompiler.java:226) ~[janino-3.0.16.jar:?] at org.codehaus.janino.UnitCompiler$14.visitIntegerLiteral(UnitCompiler.java:4016) ~[janino-3.0.16.jar:?] at org.codehaus.janino.UnitCompiler$14.visitIntegerLiteral(UnitCompiler.java:3986) ~[janino-3.0.16.jar:?] ... at com.google.common.cache.LocalCache$LoadingValueReference.loadFuture(LocalCache.java:3599) ~[guava-14.0.1.jar:?] at com.google.common.cache.LocalCache$Segment.loadSync(LocalCache.java:2379) ~[guava-14.0.1.jar:?] ... 37 more NULL Time taken: 6.132 seconds, Fetched 1 row(s) ```` After the compilation error, _the query returns a result as if `a` was a boolean `false`_. With this PR, the query will instead produce ``` org.apache.spark.sql.AnalysisException: FILTER expression is not of type boolean. It cannot be used in an aggregate function; line 1 pos 7 ``` 3) Aggregate expression in filter expression ``` select max(b) filter (where max(a) > 1) from (select 1 a, '2' b); ``` The above query should produce an analysis error, but instead causes a projection compilation error or whole-stage codegen error (depending on the datatype of the expression being aggregated): ``` org.apache.spark.SparkUnsupportedOperationException: Cannot generate code for expression: max(1) at org.apache.spark.sql.errors.QueryExecutionErrors$.cannotGenerateCodeForExpressionError(QueryExecutionErrors.scala:84) ~[spark-catalyst_2.12-3.4.0-SNAPSHOT.jar:3.4.0-SNAPSHOT] at org.apache.spark.sql.catalyst.expressions.Unevaluable.doGenCode(Expression.scala:347) ~[spark-catalyst_2.12-3.4.0-SNAPSHOT.jar:3.4.0-SNAPSHOT] at org.apache.spark.sql.catalyst.expressions.Unevaluable.doGenCode$(Expression.scala:346) ~[spark-catalyst_2.12-3.4.0-SNAPSHOT.jar:3.4.0-SNAPSHOT] at org.apache.spark.sql.catalyst.expressions.aggregate.AggregateExpression.doGenCode(interfaces.scala:99) ~[spark-catalyst_2.12-3.4.0-SNAPSHOT.jar:3.4.0-SNAPSHOT] ``` With this PR, the query will instead produce ``` org.apache.spark.sql.AnalysisException: FILTER expression contains aggregate. It cannot be used in an aggregate function; line 1 pos 7 ``` ### Does this PR introduce _any_ user-facing change? No, except in error conditions. ### How was this patch tested? New unit tests. Closes #36072 from bersprockets/aggregate_in_aggregate_filter_issue. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 49d2f3c2458863eefd63c8ce38064757874ab4ad) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 22 April 2022, 03:13:06 UTC |
| d63e42d | Hyukjin Kwon | 22 April 2022, 02:43:46 UTC | [SPARK-38955][SQL] Disable lineSep option in 'from_csv' and 'schema_of_csv' ### What changes were proposed in this pull request? This PR proposes to disable `lineSep` option in `from_csv` and `schema_of_csv` expression by setting Noncharacters according to [unicode specification](https://www.unicode.org/charts/PDF/UFFF0.pdf), `\UFFFF`. This can be used for the internal purpose in a program according to the specification. The Univocity parser does not allow to omit the line separator (from my code reading) so this approach was proposed. This specific code path is not affected by our `encoding` or `charset` option because Unicovity parser parses them as unicodes as are internally. ### Why are the changes needed? Currently, this option is weirdly effective. See the example of `from_csv` as below: ```scala import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ Seq[String]("1,\n2,3,4,5").toDF.select( col("value"), from_csv( col("value"), StructType(Seq(StructField("a", LongType), StructField("b", StringType) )), Map[String,String]())).show() ``` ``` +-----------+---------------+ | value|from_csv(value)| +-----------+---------------+ |1,\n2,3,4,5| {1, null}| +-----------+---------------+ ``` `{1, null}` has to be `{1, \n2}`. The CSV expressions cannot easily make it supported because this option is plan-wise option that can change the number of returned rows; however, the expressions are designed to emit one row only whereas this option is easily effective in the scan plan with CSV data source. Therefore, we should disable this option. ### Does this PR introduce _any_ user-facing change? Yes, now the `lineSep` can be located in the output from `from_csv` and `schema_of_csv`. ### How was this patch tested? Manually tested, and unit test was added. Closes #36294 from HyukjinKwon/SPARK-38955. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit f3cc2814d4bc585dad92c9eca9a593d1617d27e9) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 22 April 2022, 02:43:54 UTC |
| ec771f1 | itholic | 22 April 2022, 02:30:33 UTC | [SPARK-38581][PYTHON][DOCS][3.3] List of supported pandas APIs for pandas-on-Spark docs ### What changes were proposed in this pull request? This PR proposes to add new page named "Supported pandas APIs" for pandas-on-Spark documents. This is cherry-pick from https://github.com/apache/spark/commit/f43c68cb38cb0556f2058be6d3a016083ef5152d to `branch-3.3`. ### Why are the changes needed? To let users can more easily find out whether a specific pandas API and its parameters are supported or not from the single document page. ### Does this PR introduce _any_ user-facing change? Yes, the "Supported pandas APIs" page is added to the user guide for pandas API on Spark documents. ### How was this patch tested? Manually check the links in the documents & the existing doc build should be passed. Closes #36308 from itholic/SPARK-38581-3.3. Authored-by: itholic <haejoon.lee@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 22 April 2022, 02:30:33 UTC |
| 176dc61 | Sean Owen | 22 April 2022, 02:26:26 UTC | [MINOR][DOCS] Also remove Google Analytics from Spark release docs, per ASF policy ### What changes were proposed in this pull request? Remove Google Analytics from Spark release docs. See also https://github.com/apache/spark-website/pull/384 ### Why are the changes needed? New ASF privacy policy requirement ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? N/A Closes #36310 from srowen/PrivacyPolicy. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 7a58670e2e68ee4950cf62c2be236e00eb8fc44b) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 22 April 2022, 02:26:34 UTC |
| 17552d5 | huaxingao | 21 April 2022, 18:52:04 UTC | [SPARK-38950][SQL][FOLLOWUP] Fix java doc ### What changes were proposed in this pull request? `{link #pushFilters(Predicate[])}` -> `{link #pushFilters(Seq[Expression])}` ### Why are the changes needed? Fixed java doc ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Closes #36302 from huaxingao/fix. Authored-by: huaxingao <huaxin_gao@apple.com> Signed-off-by: huaxingao <huaxin_gao@apple.com> (cherry picked from commit 0b543e7480b6e414b23e02e6c805a33abc535c89) Signed-off-by: huaxingao <huaxin_gao@apple.com> | 21 April 2022, 18:52:18 UTC |
| 24d588c | huaxingao | 21 April 2022, 15:16:22 UTC | [SPARK-38950][SQL] Return Array of Predicate for SupportsPushDownCatalystFilters.pushedFilters ### What changes were proposed in this pull request? in `SupportsPushDownCatalystFilters`, change ``` def pushedFilters: Array[Filter] ``` to ``` def pushedFilters: Array[Predicate] ``` ### Why are the changes needed? use v2Filter in DS V2 ### Does this PR introduce _any_ user-facing change? yes ### How was this patch tested? existing tests Closes #36264 from huaxingao/V2Filter. Authored-by: huaxingao <huaxin_gao@apple.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 7221d754075656ce41edacb0fccc1cf89a62fc77) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 21 April 2022, 15:16:40 UTC |
| 197c975 | Serge Rielau | 21 April 2022, 13:53:28 UTC | [SPARK-38972][SQL] Support <param> in error-class messages Use symbolic names for parameters in error messages which are substituted with %s before formatting the string. Increase readability of error message docs (TBD) No SQL Project. Closes #36289 from srielau/symbolic-error-arg-names. Authored-by: Serge Rielau <serge.rielau@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 43e610333fb78834a09cd82f3da32bad262564f3) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 21 April 2022, 13:55:10 UTC |
| bb1a523 | Max Gekk | 21 April 2022, 08:50:01 UTC | [SPARK-38913][SQL][3.3] Output identifiers in error messages in SQL style ### What changes were proposed in this pull request? In the PR, I propose to use backticks to wrap SQL identifiers in error messages. I added new util functions `toSQLId()` to the trait `QueryErrorsBase`, and applied it in `Query.*Errors` (also modified tests in `Query.*ErrorsSuite`). For example: Before: ```sql Invalid SQL syntax: The definition of window win is repetitive. ``` After: ``` Invalid SQL syntax: The definition of window `win` is repetitive. ``` ### Why are the changes needed? To improve user experience with Spark SQL. The changes highlight SQL identifiers in error massages and make them more visible for users. ### Does this PR introduce _any_ user-facing change? No since error classes haven't been released yet. ### How was this patch tested? By running the affected test suites: ``` $ build/sbt "test:testOnly *QueryParsingErrorsSuite" $ build/sbt "test:testOnly *QueryCompilationErrorsSuite" $ build/sbt "test:testOnly *QueryCompilationErrorsDSv2Suite" $ build/sbt "test:testOnly *QueryExecutionErrorsSuite" $ build/sbt "testOnly *PlanParserSuite" $ build/sbt "testOnly *DDLParserSuite" $ build/sbt -Phive-2.3 "testOnly *HiveSQLInsertTestSuite" $ build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite -- -z window.sql" $ build/sbt "testOnly *DSV2SQLInsertTestSuite" ``` Authored-by: Max Gekk <max.gekkgmail.com> Signed-off-by: Max Gekk <max.gekkgmail.com> (cherry picked from commit 2ff6914e6bac053231825c083fd508726a11a349) Closes #36288 from MaxGekk/error-class-toSQLId-3.3. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 21 April 2022, 08:50:01 UTC |
| 76fe1bf | Maryann Xue | 21 April 2022, 08:30:54 UTC | [SPARK-38916][CORE] Tasks not killed caused by race conditions between killTask() and launchTask() ### What changes were proposed in this pull request? This PR fixes the race conditions between the killTask() call and the launchTask() call that sometimes causes tasks not to be killed properly. If killTask() probes the map of pendingTasksLaunches before launchTask() has had a chance to put the corresponding task into that map, the kill flag will be lost and the subsequent launchTask() call will just proceed and run that task without knowing this task should be killed instead. The fix adds a kill mark during the killTask() call so that subsequent launchTask() can pick up the kill mark and call kill() on the TaskLauncher. If killTask() happens to happen after the task has finished and thus makes the kill mark useless, it will be cleaned up in a background thread. ### Why are the changes needed? Bug fix. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Added UTs. Closes #36238 from maryannxue/spark-38916. Authored-by: Maryann Xue <maryann.xue@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit bb5092b9af60afdceeccb239d14be660f77ae0ea) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 21 April 2022, 08:31:17 UTC |
| 4ad0b2c | allisonwang-db | 21 April 2022, 08:19:20 UTC | [SPARK-38957][SQL] Use multipartIdentifier for parsing table-valued functions This PR uses multipart identifiers when parsing table-valued functions. To make table-valued functions error messages consistent for 2-part names and n-part names. For example, before this PR: ``` select * from a.b.c org.apache.spark.sql.catalyst.parser.ParseException: Invalid SQL syntax: Unsupported function name `a`.`b`.`c`(line 1, pos 14) == SQL == select * from a.b.c(1) --------------^^^ ``` After this PR: ``` Invalid SQL syntax: table valued function cannot specify database name (line 1, pos 14) == SQL == SELECT * FROM a.b.c(1) --------------^^^ ``` No Unit test. Closes #36272 from allisonwang-db/spark-38957-parse-table-func. Authored-by: allisonwang-db <allison.wang@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 8fe5bca1773521d967b82a920c6881f081155bc3) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 21 April 2022, 08:21:00 UTC |
| c2fa3b8 | huaxingao | 21 April 2022, 08:16:47 UTC | [SPARK-38432][SQL][FOLLOWUP] Fix problems in And/Or/Not to V2 Filter ### What changes were proposed in this pull request? Instead of having ``` override def toV2: Predicate = new Predicate("AND", Seq(left, right).map(_.toV2).toArray) ``` I think we should construct a V2 `And` directly. ``` override def toV2: Predicate = new org.apache.spark.sql.connector.expressions.filter.And(left.toV2, right.toV2) ``` same for `Or` and `Not`. ### Why are the changes needed? bug fixing ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? New tests Closes #36290 from huaxingao/toV1. Authored-by: huaxingao <huaxin_gao@apple.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 36fc8bd185da99b64954ca0dd393b452fb788226) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 21 April 2022, 08:17:04 UTC |
| 5707811 | sychen | 21 April 2022, 02:34:39 UTC | [SPARK-38936][SQL] Script transform feed thread should have name ### What changes were proposed in this pull request? re-add thread name(`Thread-ScriptTransformation-Feed`). ### Why are the changes needed? Lost feed thread name after [SPARK-32105](https://issues.apache.org/jira/browse/SPARK-32105) refactoring. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? exist UT Closes #36245 from cxzl25/SPARK-38936. Authored-by: sychen <sychen@ctrip.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 4dc12eb54544a12ff7ddf078ca8bcec9471212c3) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 21 April 2022, 02:34:46 UTC |
| 2e102b8 | Max Gekk | 20 April 2022, 19:52:04 UTC | [SPARK-38949][SQL][3.3] Wrap SQL statements by double quotes in error messages ### What changes were proposed in this pull request? In the PR, I propose to wrap any SQL statement in error messages by double quotes "", and apply new implementation of `QueryErrorsBase.toSQLStmt()` to all exceptions in `Query.*Errors` w/ error classes. Also this PR modifies all affected tests, see the list in the section "How was this patch tested?". ### Why are the changes needed? To improve user experience with Spark SQL by highlighting SQL statements in error massage and make them more visible to users. ### Does this PR introduce _any_ user-facing change? Yes. The changes might influence on error messages that are visible to users. Before: ```sql The operation DESC PARTITION is not allowed ``` After: ```sql The operation "DESC PARTITION" is not allowed ``` ### How was this patch tested? By running affected test suites: ``` $ build/sbt "sql/testOnly *QueryExecutionErrorsSuite" $ build/sbt "sql/testOnly *QueryParsingErrorsSuite" $ build/sbt "sql/testOnly *QueryCompilationErrorsSuite" $ build/sbt "test:testOnly *QueryCompilationErrorsDSv2Suite" $ build/sbt "test:testOnly *ExtractPythonUDFFromJoinConditionSuite" $ build/sbt "testOnly *PlanParserSuite" $ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z transform.sql" $ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z join-lateral.sql" $ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z describe.sql" ``` Authored-by: Max Gekk <max.gekkgmail.com> Signed-off-by: Max Gekk <max.gekkgmail.com> (cherry picked from commit 5aba2b38beae6e1baf6f0c6f9eb3b65cf607fe77) Signed-off-by: Max Gekk <max.gekkgmail.com> Closes #36286 from MaxGekk/error-class-apply-toSQLStmt-3.3. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 20 April 2022, 19:52:04 UTC |
| 44e90f3 | Gengliang Wang | 20 April 2022, 13:41:58 UTC | [SPARK-38967][SQL] Turn "spark.sql.ansi.strictIndexOperator" into an internal configuration ### What changes were proposed in this pull request? Currently, most the ANSI error message shows the hint "If necessary set spark.sql.ansi.enabled to false to bypass this error." There is only one special case: "Map key not exist" or "array index out of bound" from the `[]` operator. It shows the config spark.sql.ansi.strictIndexOperator instead. This one special case can confuse users. To make it simple: - Turn "spark.sql.ansi.strictIndexOperator" into an internal configuration - Show the configuration `spark.sql.ansi.enabled` in error messages instead - If it is "map key not exist" error, show the hint for using `try_element_at`. Otherwise, we don't show it. For array, `[]` operator is using 0-based index while `try_element_at` is using 1-based index. ### Why are the changes needed? Make the hints in ANSI runtime error message simple and consistent ### Does this PR introduce _any_ user-facing change? No, the new configuration is not released yet. ### How was this patch tested? Existing UT Closes #36282 from gengliangwang/updateErrorMsg. Authored-by: Gengliang Wang <gengliang@apache.org> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 276bdbafe83a5c0b8425a20eb8101a630be8b752) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 20 April 2022, 13:42:15 UTC |
| 1e7cdda | Peter Toth | 20 April 2022, 13:36:47 UTC | [SPARK-34079][SQL] Merge non-correlated scalar subqueries ### What changes were proposed in this pull request? This PR adds a new optimizer rule `MergeScalarSubqueries` to merge multiple non-correlated `ScalarSubquery`s to compute multiple scalar values once. E.g. the following query: ``` SELECT (SELECT avg(a) FROM t), (SELECT sum(b) FROM t) ``` is optimized from: ``` == Optimized Logical Plan == Project [scalar-subquery#242 [] AS scalarsubquery()#253, scalar-subquery#243 [] AS scalarsubquery()#254L] : :- Aggregate [avg(a#244) AS avg(a)#247] : : +- Project [a#244] : : +- Relation default.t[a#244,b#245] parquet : +- Aggregate [sum(a#251) AS sum(a)#250L] : +- Project [a#251] : +- Relation default.t[a#251,b#252] parquet +- OneRowRelation ``` to: ``` == Optimized Logical Plan == Project [scalar-subquery#242 [].avg(a) AS scalarsubquery()#253, scalar-subquery#243 [].sum(a) AS scalarsubquery()#254L] : :- Project [named_struct(avg(a), avg(a)#247, sum(a), sum(a)#250L) AS mergedValue#260] : : +- Aggregate [avg(a#244) AS avg(a)#247, sum(a#244) AS sum(a)#250L] : : +- Project [a#244] : : +- Relation default.t[a#244,b#245] parquet : +- Project [named_struct(avg(a), avg(a)#247, sum(a), sum(a)#250L) AS mergedValue#260] : +- Aggregate [avg(a#244) AS avg(a)#247, sum(a#244) AS sum(a)#250L] : +- Project [a#244] : +- Relation default.t[a#244,b#245] parquet +- OneRowRelation ``` and in the physical plan subqueries are reused: ``` == Physical Plan == AdaptiveSparkPlan isFinalPlan=true +- == Final Plan == *(1) Project [Subquery subquery#242, [id=#113].avg(a) AS scalarsubquery()#253, ReusedSubquery Subquery subquery#242, [id=#113].sum(a) AS scalarsubquery()#254L] : :- Subquery subquery#242, [id=#113] : : +- AdaptiveSparkPlan isFinalPlan=true +- == Final Plan == *(2) Project [named_struct(avg(a), avg(a)#247, sum(a), sum(a)#250L) AS mergedValue#260] +- *(2) HashAggregate(keys=[], functions=[avg(a#244), sum(a#244)], output=[avg(a)#247, sum(a)#250L]) +- ShuffleQueryStage 0 +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#158] +- *(1) HashAggregate(keys=[], functions=[partial_avg(a#244), partial_sum(a#244)], output=[sum#262, count#263L, sum#264L]) +- *(1) ColumnarToRow +- FileScan parquet default.t[a#244] Batched: true, DataFilters: [], Format: Parquet, Location: ..., PartitionFilters: [], PushedFilters: [], ReadSchema: struct<a:int> +- == Initial Plan == Project [named_struct(avg(a), avg(a)#247, sum(a), sum(a)#250L) AS mergedValue#260] +- HashAggregate(keys=[], functions=[avg(a#244), sum(a#244)], output=[avg(a)#247, sum(a)#250L]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#110] +- HashAggregate(keys=[], functions=[partial_avg(a#244), partial_sum(a#244)], output=[sum#262, count#263L, sum#264L]) +- FileScan parquet default.t[a#244] Batched: true, DataFilters: [], Format: Parquet, Location: ..., PartitionFilters: [], PushedFilters: [], ReadSchema: struct<a:int> : +- ReusedSubquery Subquery subquery#242, [id=#113] +- *(1) Scan OneRowRelation[] +- == Initial Plan == ... ``` Please note that the above simple example could be easily optimized into a common select expression without reuse node, but this PR can handle more complex queries as well. ### Why are the changes needed? Performance improvement. ``` [info] TPCDS Snappy: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative [info] ------------------------------------------------------------------------------------------------------------------------ [info] q9 - MergeScalarSubqueries off 50798 52521 1423 0.0 Infinity 1.0X [info] q9 - MergeScalarSubqueries on 19484 19675 226 0.0 Infinity 2.6X [info] TPCDS Snappy: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative [info] ------------------------------------------------------------------------------------------------------------------------ [info] q9b - MergeScalarSubqueries off 15430 17803 NaN 0.0 Infinity 1.0X [info] q9b - MergeScalarSubqueries on 3862 4002 196 0.0 Infinity 4.0X ``` Please find `q9b` in the description of SPARK-34079. It is a variant of [q9.sql](https://github.com/apache/spark/blob/master/sql/core/src/test/resources/tpcds/q9.sql) using CTE. The performance improvement in case of `q9` comes from merging 15 subqueries into 5 and in case of `q9b` it comes from merging 5 subqueries into 1. ### Does this PR introduce _any_ user-facing change? No. But this optimization can be disabled with `spark.sql.optimizer.excludedRules` config. ### How was this patch tested? Existing and new UTs. Closes #32298 from peter-toth/SPARK-34079-multi-column-scalar-subquery. Lead-authored-by: Peter Toth <peter.toth@gmail.com> Co-authored-by: attilapiros <piros.attila.zsolt@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit e00b81ee9b37067ce8e8242907b26d3ae200f401) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 20 April 2022, 13:37:24 UTC |
| 5c5a68c | Jiaan Geng | 20 April 2022, 13:18:11 UTC | [SPARK-38219][SPARK-37691][3.3] Support ANSI Aggregation Function: percentile_cont and percentile_disc ### What changes were proposed in this pull request? This PR backport https://github.com/apache/spark/pull/35531 and https://github.com/apache/spark/pull/35041 to branch-3.3 ### Why are the changes needed? `percentile_cont` and `percentile_disc` in Spark3.3 release. ### Does this PR introduce _any_ user-facing change? 'No'. New feature. ### How was this patch tested? New tests. Closes #36277 from beliefer/SPARK-38219_SPARK-37691_backport_3.3. Authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 20 April 2022, 13:18:11 UTC |
| 9d0650a | Xinyi Yu | 20 April 2022, 10:08:38 UTC | [SPARK-38929][SQL][3.3] Improve error messages for cast failures in ANSI ### What changes were proposed in this pull request? Improve the error messages for cast failures in ANSI. As mentioned in https://issues.apache.org/jira/browse/SPARK-38929, this PR targets two cast-to types: numeric types and date types. * For numeric(`int`, `smallint`, `double`, `float`, `decimal` ..) types, it embeds the cast-to types in the error message. For example, ``` Invalid input value for type INT: '1.0'. To return NULL instead, use 'try_cast'. If necessary set %s to false to bypass this error. ``` It uses the `toSQLType` and `toSQLValue` to wrap the corresponding types and literals. * For date types, it does similarly as above. For example, ``` Invalid input value for type TIMESTAMP: 'a'. To return NULL instead, use 'try_cast'. If necessary set spark.sql.ansi.enabled to false to bypass this error. ``` ### Why are the changes needed? To improve the error message in general. ### Does this PR introduce _any_ user-facing change? It changes the error messages. ### How was this patch tested? The related unit tests are updated. Authored-by: Xinyi Yu <xinyi.yudatabricks.com> Signed-off-by: Max Gekk <max.gekkgmail.com> (cherry picked from commit f76b3e766f79b4c2d4f1ecffaad25aeb962336b7) Closes #36275 from anchovYu/ansi-error-improve-3.3. Authored-by: Xinyi Yu <xinyi.yu@databricks.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 20 April 2022, 10:08:38 UTC |
| 83a365e | Kent Yao | 20 April 2022, 06:38:26 UTC | [SPARK-38922][CORE] TaskLocation.apply throw NullPointerException ### What changes were proposed in this pull request? TaskLocation.apply w/o NULL check may throw NPE and fail job scheduling ``` Caused by: java.lang.NullPointerException at scala.collection.immutable.StringLike$class.stripPrefix(StringLike.scala:155) at scala.collection.immutable.StringOps.stripPrefix(StringOps.scala:29) at org.apache.spark.scheduler.TaskLocation$.apply(TaskLocation.scala:71) at org.apache.spark.scheduler.DAGScheduler$$anonfun$org$apache$spark$scheduler$DAGScheduler$$getPreferredLocsInternal ``` For instance, `org.apache.spark.rdd.HadoopRDD#convertSplitLocationInfo` might generate unexpected `Some(null)` elements where should be replace by `Option.apply` ### Why are the changes needed? fix NPE ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? new tests Closes #36222 from yaooqinn/SPARK-38922. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Kent Yao <yao@apache.org> (cherry picked from commit 33e07f3cd926105c6d28986eb6218f237505549e) Signed-off-by: Kent Yao <yao@apache.org> | 20 April 2022, 06:38:44 UTC |
| 27c75ea | Xinyi Yu | 20 April 2022, 02:48:00 UTC | [SPARK-37575][SQL][FOLLOWUP] Update the migration guide for added legacy flag for the breaking change of write null value in csv to unquoted empty string ### What changes were proposed in this pull request? This is a follow-up of updating the migration guide for https://github.com/apache/spark/pull/36110 which adds a legacy flag to restore the pre-change behavior. It also fixes a typo in the previous flag description. ### Why are the changes needed? The flag needs to be documented. ### Does this PR introduce _any_ user-facing change? It changes the migration doc for users. ### How was this patch tested? No tests Closes #36268 from anchovYu/flags-null-to-csv-migration-guide. Authored-by: Xinyi Yu <xinyi.yu@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit a67acbaa29d1ab9071910cac09323c2544d65303) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 20 April 2022, 02:48:15 UTC |
| 2b3df38 | Jiaan Geng | 20 April 2022, 02:02:58 UTC | [SPARK-37613][SQL][FOLLOWUP] Supplement docs for regr_count ### What changes were proposed in this pull request? https://github.com/apache/spark/pull/34880 supported ANSI Aggregate Function: regr_count. But the docs of regr_count is not good enough. ### Why are the changes needed? Make the docs of regr_count more detailed. ### Does this PR introduce _any_ user-facing change? 'No'. New feature. ### How was this patch tested? N/A Closes #36258 from beliefer/SPARK-37613_followup. Authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 1b106ea32d567dd32ac697ed0d6cfd40ea7e6e08) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 20 April 2022, 02:03:07 UTC |
| fb58c3e | itholic | 20 April 2022, 01:49:07 UTC | [SPARK-38828][PYTHON] Remove TimestampNTZ type Python support in Spark 3.3 This PR proposes to remove `TimestampNTZ` type Python support in Spark 3.3 from documentation and `pyspark.sql.types` module. The purpose of this PR is just hide `TimestampNTZ` type from end-users. Because the `TimestampNTZ` project is not finished yet: - Lack Hive metastore support - Lack JDBC support - Need to spend time scanning the codebase to find out any missing support. The current code usages of TimestampType are larger than TimestampNTZType No. The existing tests should cover. Closes #36255 from itholic/SPARK-38828. Authored-by: itholic <haejoon.lee@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 581000de24377ca373df7fa94b214baa7e9b0462) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 20 April 2022, 01:54:08 UTC |
| 8811e8c | Yun Tang | 19 April 2022, 11:31:04 UTC | [SPARK-38931][SS] Create root dfs directory for RocksDBFileManager with unknown number of keys on 1st checkpoint ### What changes were proposed in this pull request? Create root dfs directory for RocksDBFileManager with unknown number of keys on 1st checkpoint. ### Why are the changes needed? If this fix is not introduced, we might meet exception below: ~~~java File /private/var/folders/rk/wyr101_562ngn8lp7tbqt7_00000gp/T/spark-ce4a0607-b1d8-43b8-becd-638c6b030019/state/1/1 does not exist java.io.FileNotFoundException: File /private/var/folders/rk/wyr101_562ngn8lp7tbqt7_00000gp/T/spark-ce4a0607-b1d8-43b8-becd-638c6b030019/state/1/1 does not exist at org.apache.hadoop.fs.RawLocalFileSystem.deprecatedGetFileStatus(RawLocalFileSystem.java:779) at org.apache.hadoop.fs.RawLocalFileSystem.getFileLinkStatusInternal(RawLocalFileSystem.java:1100) at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:769) at org.apache.hadoop.fs.DelegateToFileSystem.getFileStatus(DelegateToFileSystem.java:128) at org.apache.hadoop.fs.DelegateToFileSystem.createInternal(DelegateToFileSystem.java:93) at org.apache.hadoop.fs.ChecksumFs$ChecksumFSOutputSummer.<init>(ChecksumFs.java:353) at org.apache.hadoop.fs.ChecksumFs.createInternal(ChecksumFs.java:400) at org.apache.hadoop.fs.AbstractFileSystem.create(AbstractFileSystem.java:626) at org.apache.hadoop.fs.FileContext$3.next(FileContext.java:701) at org.apache.hadoop.fs.FileContext$3.next(FileContext.java:697) at org.apache.hadoop.fs.FSLinkResolver.resolve(FSLinkResolver.java:90) at org.apache.hadoop.fs.FileContext.create(FileContext.java:703) at org.apache.spark.sql.execution.streaming.FileContextBasedCheckpointFileManager.createTempFile(CheckpointFileManager.scala:327) at org.apache.spark.sql.execution.streaming.CheckpointFileManager$RenameBasedFSDataOutputStream.<init>(CheckpointFileManager.scala:140) at org.apache.spark.sql.execution.streaming.CheckpointFileManager$RenameBasedFSDataOutputStream.<init>(CheckpointFileManager.scala:143) at org.apache.spark.sql.execution.streaming.FileContextBasedCheckpointFileManager.createAtomic(CheckpointFileManager.scala:333) at org.apache.spark.sql.execution.streaming.state.RocksDBFileManager.zipToDfsFile(RocksDBFileManager.scala:438) at org.apache.spark.sql.execution.streaming.state.RocksDBFileManager.saveCheckpointToDfs(RocksDBFileManager.scala:174) at org.apache.spark.sql.execution.streaming.state.RocksDBSuite.saveCheckpointFiles(RocksDBSuite.scala:566) at org.apache.spark.sql.execution.streaming.state.RocksDBSuite.$anonfun$new$35(RocksDBSuite.scala:179) ........ ~~~ ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Tested via RocksDBSuite. Closes #36242 from Myasuka/SPARK-38931. Authored-by: Yun Tang <myasuka@live.com> Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com> (cherry picked from commit abb1df9d190e35a17b693f2b013b092af4f2528a) Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com> | 19 April 2022, 11:31:17 UTC |
| bb5e3aa | William Hyun | 19 April 2022, 06:50:09 UTC | [SPARK-38942][TESTS][SQL][3.3] Skip RocksDB-based test case in FlatMapGroupsWithStateSuite on Apple Silicon ### What changes were proposed in this pull request? This PR aims to skip RocksDB-based test case in FlatMapGroupsWithStateSuite on Apple Silicon. ### Why are the changes needed? Currently, it is broken on Apple Silicon. **BEFORE** ``` $ build/sbt "sql/testOnly org.apache.spark.sql.streaming.FlatMapGroupsWithStateSuite" ... [info] *** 1 TEST FAILED *** [error] Failed tests: [error] org.apache.spark.sql.streaming.FlatMapGroupsWithStateSuite [error] (sql / Test / testOnly) sbt.TestsFailedException: Tests unsuccessful ``` **AFTER** ``` $ build/sbt "sql/testOnly org.apache.spark.sql.streaming.FlatMapGroupsWithStateSuite" ... [info] Run completed in 32 seconds, 692 milliseconds. [info] Total number of tests run: 105 [info] Suites: completed 1, aborted 0 [info] Tests: succeeded 105, failed 0, canceled 1, ignored 0, pending 0 [info] All tests passed. ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Test manually on Apple Silicon. Closes #36256 from williamhyun/SPARK-38942. Authored-by: William Hyun <william@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 19 April 2022, 06:50:09 UTC |
| f726800 | Max Gekk | 19 April 2022, 06:02:30 UTC | [SPARK-38926][SQL][3.3] Output types in error messages in SQL style ### What changes were proposed in this pull request? In the PR, I propose to upper case SQL types in error messages similar to the SQL standard. I added new util functions `toSQLType()` to the trait `QueryErrorsBase`, and applied it in `Query.*Errors` (also modified tests in `Query.*ErrorsSuite`). For example: Before: ```sql Cannot up cast b.`b` from decimal(38,18) to bigint. ``` After: ```sql Cannot up cast b.`b` from DECIMAL(38,18) to BIGINT. ``` ### Why are the changes needed? To improve user experience with Spark SQL. The changes highlight SQL types in error massages and make them more visible for users. ### Does this PR introduce _any_ user-facing change? No since error classes haven't been released yet. ### How was this patch tested? By running the modified test suites: ``` $ build/sbt "test:testOnly *QueryParsingErrorsSuite" $ build/sbt "test:testOnly *QueryCompilationErrorsSuite" $ build/sbt "test:testOnly *QueryExecutionErrorsSuite" $ build/sbt "testOnly *CastSuite" $ build/sbt "testOnly *AnsiCastSuiteWithAnsiModeOn" $ build/sbt "testOnly *EncoderResolutionSuite" $ build/sbt "test:testOnly *DatasetSuite" $ build/sbt "test:testOnly *InsertSuite" ``` Authored-by: Max Gekk <max.gekkgmail.com> Signed-off-by: Max Gekk <max.gekkgmail.com> (cherry picked from commit 0d16159bfa85ed346843e0952f37922a579c011e) Signed-off-by: Max Gekk <max.gekkgmail.com> Closes #36247 from MaxGekk/error-class-toSQLType-3.3. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 19 April 2022, 06:02:30 UTC |
| 74043dd | William Hyun | 19 April 2022, 05:57:45 UTC | [SPARK-38941][TESTS][SQL][3.3] Skip RocksDB-based test case in StreamingJoinSuite on Apple Silicon ### What changes were proposed in this pull request? This PR aims to skip RocksDB-based test case in `StreamingJoinSuite` on Apple Silicon. ### Why are the changes needed? Currently, it is broken on Apple Silicon. **BEFORE** ``` $ build/sbt "sql/testOnly org.apache.spark.sql.streaming.Streaming*JoinSuite" ... [info] Run completed in 2 minutes, 47 seconds. [info] Total number of tests run: 43 [info] Suites: completed 4, aborted 0 [info] Tests: succeeded 42, failed 1, canceled 0, ignored 0, pending 0 [info] *** 1 TEST FAILED *** [error] Failed tests: [error] org.apache.spark.sql.streaming.StreamingOuterJoinSuite [error] (sql / Test / testOnly) sbt.TestsFailedException: Tests unsuccessful ``` **AFTER** ``` $ build/sbt "sql/testOnly org.apache.spark.sql.streaming.Streaming*JoinSuite" ... [info] Run completed in 2 minutes, 52 seconds. [info] Total number of tests run: 42 [info] Suites: completed 4, aborted 0 [info] Tests: succeeded 42, failed 0, canceled 1, ignored 0, pending 0 [info] All tests passed. ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manually test on Apple Silicon. Closes #36254 from williamhyun/SPARK-38941. Authored-by: William Hyun <william@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 19 April 2022, 05:57:45 UTC |
| dd6eca7 | huaxingao | 19 April 2022, 04:27:57 UTC | [SPARK-38825][SQL][TEST][FOLLOWUP] Add test for in(null) and notIn(null) ### What changes were proposed in this pull request? Add test for filter `in(null)` and `notIn(null)` ### Why are the changes needed? to make tests more complete ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? new test Closes #36248 from huaxingao/inNotIn. Authored-by: huaxingao <huaxin_gao@apple.com> Signed-off-by: huaxingao <huaxin_gao@apple.com> (cherry picked from commit b760e4a686939bdb837402286b8d3d8b445c5ed4) Signed-off-by: huaxingao <huaxin_gao@apple.com> | 19 April 2022, 04:28:14 UTC |
| 8bd7d88 | Daniel Tenedorio | 19 April 2022, 03:18:56 UTC | [SPARK-38796][SQL] Update to_number and try_to_number functions to restrict S and MI sequence to start or end only ### What changes were proposed in this pull request? Update `to_number` and `try_to_number` functions to restrict MI sequence to start or end only. This satisfies the following specification: ``` to_number(expr, fmt) fmt { ' [ MI | S ] [ L | $ ] [ 0 | 9 | G | , ] [...] [ . | D ] [ 0 | 9 ] [...] [ L | $ ] [ PR | MI | S ] ' } ``` ### Why are the changes needed? After reviewing the specification, this behavior makes the most sense. ### Does this PR introduce _any_ user-facing change? Yes, a slight change in the behavior of the format string. ### How was this patch tested? Existing and updated unit test coverage. Closes #36154 from dtenedor/mi-anywhere. Authored-by: Daniel Tenedorio <daniel.tenedorio@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 242ee22c00394c29e21bc3de0a93cb6d9746d93c) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 19 April 2022, 03:19:10 UTC |
| 671539d | Maryann Xue | 19 April 2022, 02:50:07 UTC | [SPARK-37670][SQL] Support predicate pushdown and column pruning for de-duped CTEs This PR adds predicate push-down and column pruning to CTEs that are not inlined as well as fixes a few potential correctness issues: 1) Replace (previously not inlined) CTE refs with Repartition operations at the end of logical plan optimization so that WithCTE is not carried over to physical plan. As a result, we can simplify the logic of physical planning, as well as avoid a correctness issue where the logical link of a physical plan node can point to `WithCTE` and lead to unexpected behaviors in AQE, e.g., class cast exceptions in DPP. 2) Pull (not inlined) CTE defs from subqueries up to the main query level, in order to avoid creating copies of the same CTE def during predicate push-downs and other transformations. 3) Make CTE IDs more deterministic by starting from 0 for each query. Improve de-duped CTEs' performance with predicate pushdown and column pruning; fixes de-duped CTEs' correctness issues. No. Added UTs. Closes #34929 from maryannxue/cte-followup. Lead-authored-by: Maryann Xue <maryann.xue@gmail.com> Co-authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 175e429cca29c2314ee029bf009ed5222c0bffad) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 19 April 2022, 02:54:34 UTC |
| 142b933 | Jiaan Geng | 19 April 2022, 01:41:39 UTC | [SPARK-38933][SQL][DOCS] Add examples of window functions into SQL docs Currently, Spark SQL docs display the window functions without examples. 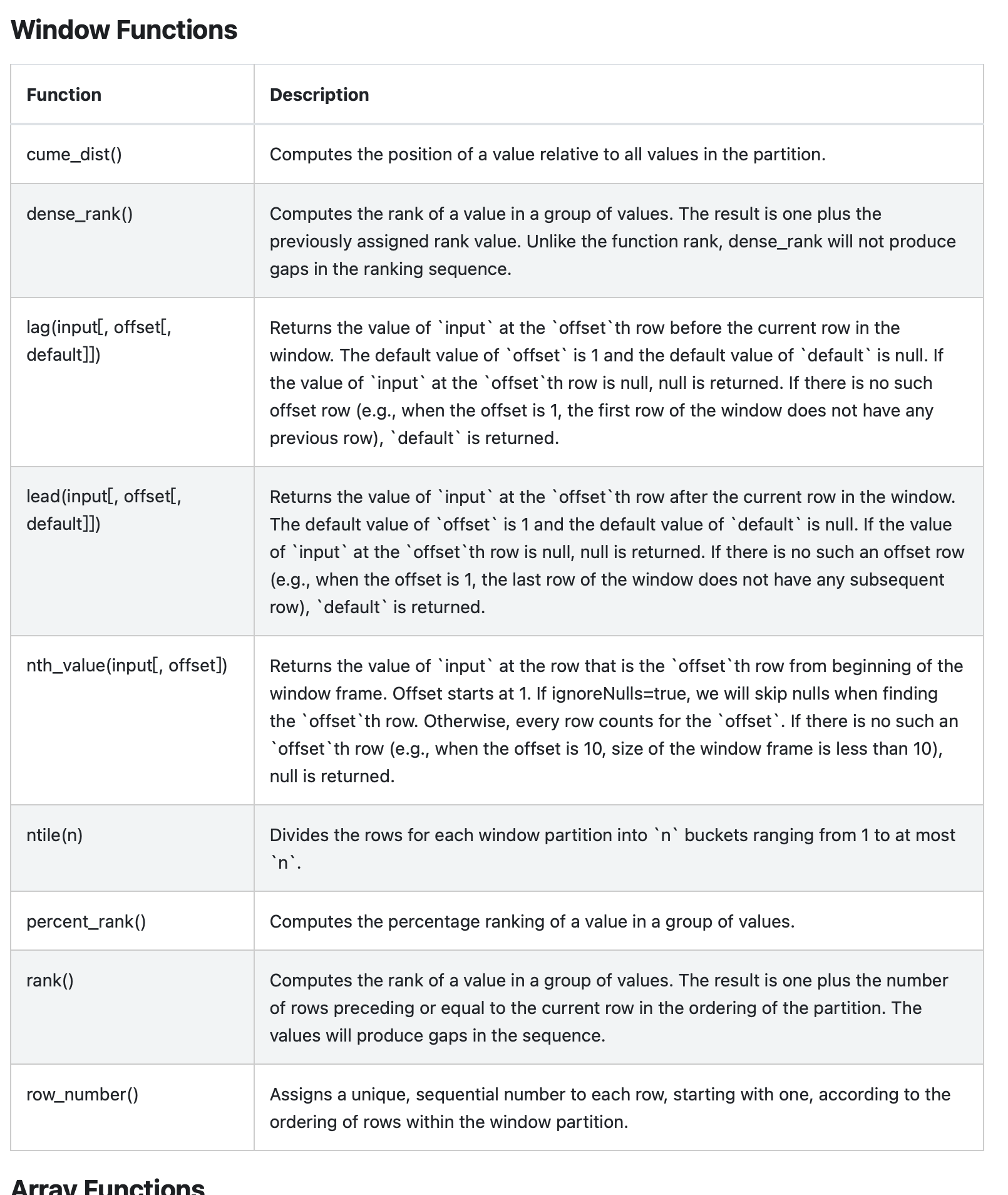 In fact, Mkdocs also generates the doc `generated-window-funcs-examples.html` This PR just updates the `sql-ref-functions-builtin.md` 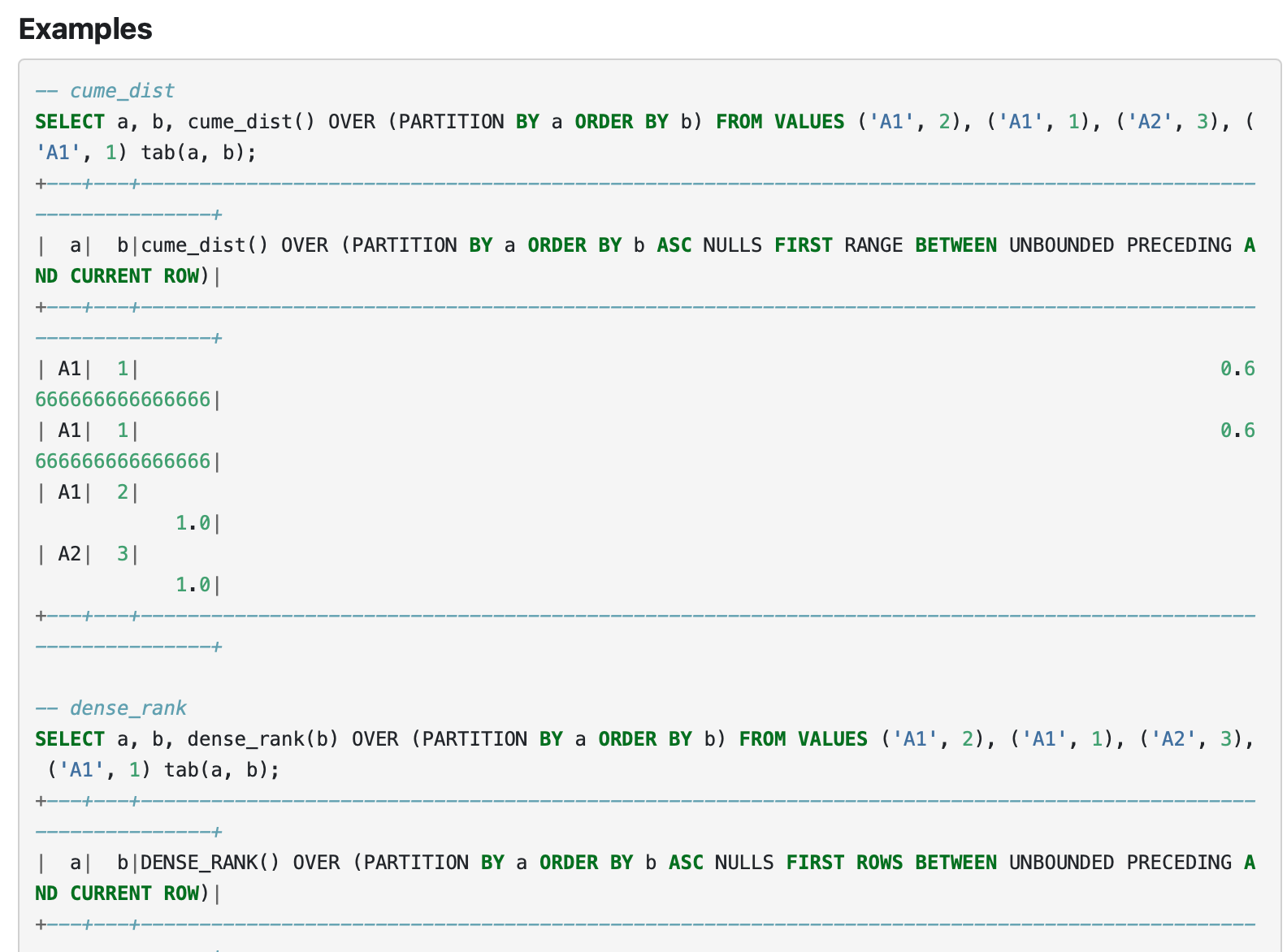 Let SQL docs display the examples of window functions. 'No'. Just update docs. Manual tests. Closes #36243 from beliefer/SPARK-38933. Authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit d2c5c53a5c21a72b3e00ecc48e6cac6ae73c3c23) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 19 April 2022, 01:42:20 UTC |
| 5544cce | dch nguyen | 18 April 2022, 15:38:32 UTC | [SPARK-37015][PYTHON] Inline type hints for python/pyspark/streaming/dstream.py ### What changes were proposed in this pull request? Inline type hints for python/pyspark/streaming/dstream.py ### Why are the changes needed? We can take advantage of static type checking within the functions by inlining the type hints. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests Closes #34324 from dchvn/SPARK-37015. Lead-authored-by: dch nguyen <dchvn.dgd@gmail.com> Co-authored-by: dch nguyen <dgd_contributor@viettel.com.vn> Signed-off-by: zero323 <mszymkiewicz@gmail.com> (cherry picked from commit dff52d649d1e27baf3b107f75636624e0cfe780f) Signed-off-by: zero323 <mszymkiewicz@gmail.com> | 18 April 2022, 15:38:46 UTC |
| 7f317c9 | fhygh | 18 April 2022, 15:11:32 UTC | [SPARK-37643][SQL] when charVarcharAsString is true, for char datatype predicate query should skip rpadding rule ### What changes were proposed in this pull request? after add ApplyCharTypePadding rule, when predicate query column data type is char, if column value length is less then defined, will be right-padding, then query will get incorrect result ### Why are the changes needed? fix query incorrect issue when predicate column data type is char, so in this case when charVarcharAsString is true, we should skip the rpadding rule. ### Does this PR introduce _any_ user-facing change? before this fix, if we query with char data type for predicate, then we should be careful to set charVarcharAsString to true. ### How was this patch tested? add new UT. Closes #36187 from fhygh/charpredicatequery. Authored-by: fhygh <283452027@qq.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit c1ea8b446d00dd0123a0fad93a3e143933419a76) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 18 April 2022, 15:11:52 UTC |
| 0d1005e | William Hyun | 18 April 2022, 02:29:16 UTC | [SPARK-38928][TESTS][SQL] Skip Pandas UDF test in `QueryCompilationErrorsSuite` if not available ### What changes were proposed in this pull request? This PR aims to skip Pandas UDF tests in `QueryCompilationErrorsSuite` if not available. ### Why are the changes needed? The tests should be skipped instead of showing failure. **BEFORE** ``` $ build/sbt "sql/testOnly org.apache.spark.sql.errors.QueryCompilationErrorsSuite" ... [info] *** 2 TESTS FAILED *** [error] Failed tests: [error] org.apache.spark.sql.errors.QueryCompilationErrorsSuite [error] (sql / Test / testOnly) sbt.TestsFailedException: Tests unsuccessful ``` **AFTER** ``` $ build/sbt "sql/testOnly org.apache.spark.sql.errors.QueryCompilationErrorsSuite" ... [info] Tests: succeeded 13, failed 0, canceled 2, ignored 0, pending 0 [info] All tests passed. ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass the CIs. Closes #36236 from williamhyun/skippandas. Authored-by: William Hyun <william@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 1f55a2af225b9c6226004180d9b83d2424bbe154) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 18 April 2022, 02:29:29 UTC |
| 6d23b40 | Sean Owen | 17 April 2022, 23:54:45 UTC | [SPARK-38816][ML][DOCS] Fix comment about choice of initial factors in ALS ### What changes were proposed in this pull request? Change a comment in ALS code to match impl. The comment refers to taking the absolute value of a Normal(0,1) value, but it doesn't. ### Why are the changes needed? The docs and impl are inconsistent. The current behavior actually seems fine, desirable, so, change the comments. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests Closes #36228 from srowen/SPARK-38816. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit b2b350b1566b8b45c6dba2f79ccbc2dc4e95816d) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 17 April 2022, 23:54:58 UTC |
| 2f1abc1 | William Hyun | 17 April 2022, 19:55:44 UTC | [SPARK-38927][TESTS] Skip NumPy/Pandas tests in `test_rdd.py` if not available ### What changes were proposed in this pull request? This PR aims to skip NumPy/Pandas tests in `test_rdd.py` if they are not available. ### Why are the changes needed? Currently, the tests that involve NumPy or Pandas are failing because NumPy and Pandas are unavailable in underlying Python. The tests should be skipped instead instead of showing failure. **BEFORE** ``` ====================================================================== ERROR: test_take_on_jrdd_with_large_rows_should_not_cause_deadlock (pyspark.tests.test_rdd.RDDTests) ---------------------------------------------------------------------- Traceback (most recent call last): File ".../test_rdd.py", line 723, in test_take_on_jrdd_with_large_rows_should_not_cause_deadlock import numpy as np ModuleNotFoundError: No module named 'numpy' ---------------------------------------------------------------------- Ran 1 test in 1.990s FAILED (errors=1) ``` **AFTER** ``` Finished test(python3.9): pyspark.tests.test_rdd RDDTests.test_take_on_jrdd_with_large_rows_should_not_cause_deadlock (1s) ... 1 tests were skipped Tests passed in 1 seconds Skipped tests in pyspark.tests.test_rdd RDDTests.test_take_on_jrdd_with_large_rows_should_not_cause_deadlock with python3.9: test_take_on_jrdd_with_large_rows_should_not_cause_deadlock (pyspark.tests.test_rdd.RDDTests) ... skipped 'NumPy or Pandas not installed' ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass the CIs. Closes #36235 from williamhyun/skipnumpy. Authored-by: William Hyun <william@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit c34140d8d744dc75d130af60080a2a8e25d501b1) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 17 April 2022, 19:55:53 UTC |
| 6846cc9 | Sean Owen | 17 April 2022, 18:25:17 UTC | [SPARK-38924][UI] Update datatables to 1.10.25 ### What changes were proposed in this pull request? Update javascript library datatables, used in the UI, to 1.10.25 ### Why are the changes needed? https://nvd.nist.gov/vuln/detail/CVE-2020-28458 affects the current version of datatables, 1.10.20, and would be safer to just update. ### Does this PR introduce _any_ user-facing change? Should not. ### How was this patch tested? Existing tests, with some minor manual local testing. Closes #36226 from srowen/SPARK-38924. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Gengliang Wang <gengliang@apache.org> (cherry picked from commit 74b336858cc94194ef22483f0d684f0bcdd29599) Signed-off-by: Gengliang Wang <gengliang@apache.org> | 17 April 2022, 18:25:31 UTC |
| c10160b | Adam Binford | 17 April 2022, 13:39:27 UTC | [SPARK-38640][CORE] Fix NPE with memory-only cache blocks and RDD fetching ### What changes were proposed in this pull request? Fixes a bug where if `spark.shuffle.service.fetch.rdd.enabled=true`, memory-only cached blocks will fail to unpersist. ### Why are the changes needed? In https://github.com/apache/spark/pull/33020, when all RDD blocks are removed from `externalShuffleServiceBlockStatus`, the underlying Map is nulled to reduce memory. When persisting blocks we check if it's using disk before adding it to `externalShuffleServiceBlockStatus`, but when removing them there is no check, so a memory-only cache block will keep `externalShuffleServiceBlockStatus` null, and when unpersisting it throw an NPE because it tries to remove from the null Map. This adds checks to the removal as well to only remove if the block is on disk, and therefore should have been added to `externalShuffleServiceBlockStatus` in the first place. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? New and updated UT Closes #35959 from Kimahriman/fetch-rdd-memory-only-unpersist. Authored-by: Adam Binford <adamq43@gmail.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit e0939f0f7c3d3bd4baa89e720038dbd3c7363a72) Signed-off-by: Sean Owen <srowen@gmail.com> | 17 April 2022, 13:39:34 UTC |
| baeaaeb | Sean Owen | 17 April 2022, 03:31:34 UTC | [SPARK-38784][CORE] Upgrade Jetty to 9.4.46 ### What changes were proposed in this pull request? Upgrade Jetty to 9.4.46 ### Why are the changes needed? Three CVEs, which don't necessarily appear to affect Spark, are fixed in this version. Just housekeeping. CVE-2021-28169 CVE-2021-34428 CVE-2021-34429 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests Closes #36229 from srowen/SPARK-38784. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 619b7b4345013684e814499f8cec3b99ba9d88c2) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 17 April 2022, 03:31:52 UTC |
| dfb668d | William Hyun | 16 April 2022, 07:31:41 UTC | [SPARK-38866][BUILD] Update ORC to 1.7.4 ### What changes were proposed in this pull request? This PR aims to update ORC to version 1.7.4. ### Why are the changes needed? This will bring the following bug fixes. - https://github.com/apache/orc/milestone/7?closed=1 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass the CIs. Closes #36153 from williamhyun/orc174RC0. Authored-by: William Hyun <william@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 7caf487c76abfdc76fc79a3bd4787d2e6c8034eb) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 16 April 2022, 07:31:52 UTC |
| 194ed0c | fhygh | 15 April 2022, 11:42:18 UTC | [SPARK-38892][SQL][TESTS] Fix a test case schema assertion of ParquetPartitionDiscoverySuite ### What changes were proposed in this pull request? in ParquetPartitionDiscoverySuite, thare are some assert have no parctical significance. `assert(input.schema.sameType(input.schema))` ### Why are the changes needed? fix this to assert the actual result. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? updated testsuites Closes #36189 from fhygh/assertutfix. Authored-by: fhygh <283452027@qq.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 4835946de2ef71b176da5106e9b6c2706e182722) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 15 April 2022, 11:42:30 UTC |
| a3ea6b4 | Gengliang Wang | 15 April 2022, 11:20:31 UTC | [SPARK-38908][SQL] Provide query context in runtime error of Casting from String to Number/Date/Timestamp/Boolean ### What changes were proposed in this pull request? Provide query context in runtime error of Casting from String to Number/Date/Timestamp/Boolean. Casting Double/Float to Timestamp shares the same error method as casting String to Timestamp, so this PR also provides query context in its error. ### Why are the changes needed? Provide SQL query context of runtime errors to users, so that they can understand it better. ### Does this PR introduce _any_ user-facing change? Yes, improve the runtime error message of Casting from String to Number/Date/Timestamp/Boolean ### How was this patch tested? UT Closes #36206 from gengliangwang/castStringContext. Authored-by: Gengliang Wang <gengliang@apache.org> Signed-off-by: Gengliang Wang <gengliang@apache.org> (cherry picked from commit 49fa2e0720d3ca681d817981cbc2c7b811de2706) Signed-off-by: Gengliang Wang <gengliang@apache.org> | 15 April 2022, 11:20:45 UTC |
| 811c92f | Xinyi Yu | 15 April 2022, 08:45:47 UTC | [SPARK-37575][SQL][FOLLOWUP] Add legacy flag for the breaking change of write null value in csv to unquoted empty string ### What changes were proposed in this pull request? Add a legacy flag `spark.sql.legacy.nullValueWrittenAsQuotedEmptyStringCsv` for the breaking change introduced in https://github.com/apache/spark/pull/34853 and https://github.com/apache/spark/pull/34905 (followup). The flag is disabled by default, so the null values written as csv will output an unquoted empty string. When the legacy flag is enabled, the null will output quoted empty string. ### Why are the changes needed? The original commit is a breaking change, and breaking changes should be encouraged to add a flag to turn it off for smooth migration between versions. ### Does this PR introduce _any_ user-facing change? With the default value of the conf, there is no user-facing difference. If users turn this conf off, they can restore the pre-change behavior. ### How was this patch tested? Through unit tests. Closes #36110 from anchovYu/flags-null-to-csv. Authored-by: Xinyi Yu <xinyi.yu@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 965f872500a3554142cab3078a7a4d513d2d2ee8) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 15 April 2022, 08:46:14 UTC |
| 7101e88 | zero323 | 15 April 2022, 08:32:13 UTC | [SPARK-37405][FOLLOW-UP][PYTHON][ML] Move _input_kwargs hints to consistent positions ### What changes were proposed in this pull request? This PR moves `_input_kwargs` hints to beginning of the bodies of the annotated classes. ### Why are the changes needed? Consistency with other modules. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes #36203 from zero323/SPARK-37405-FOLLOW-UP. Authored-by: zero323 <mszymkiewicz@gmail.com> Signed-off-by: zero323 <mszymkiewicz@gmail.com> (cherry picked from commit 797abc069348a2770742d5b57fd8c0fab0abe8d4) Signed-off-by: zero323 <mszymkiewicz@gmail.com> | 15 April 2022, 08:32:25 UTC |
| a7480e6 | Bruce Robbins | 14 April 2022, 23:37:43 UTC | [SPARK-38823][SQL] Make `NewInstance` non-foldable to fix aggregation buffer corruption issue ### What changes were proposed in this pull request? Make `NewInstance` non-foldable. ### Why are the changes needed? When handling Java beans as input, Spark creates `NewInstance` with no arguments. On master and 3.3, `NewInstance` with no arguments is considered foldable. As a result, the `ConstantFolding` rule converts `NewInstance` into a `Literal` holding an instance of the user's specified Java bean. The instance becomes a singleton that gets reused for each input record (although its fields get updated by `InitializeJavaBean`). Because the instance gets reused, sometimes multiple buffers in `AggregationIterator` are actually referring to the same Java bean instance. Take, for example, the test I added in this PR, or the `spark-shell` example I added to SPARK-38823 as a comment. The input is: ``` new Item("a", 1), new Item("b", 3), new Item("c", 2), new Item("a", 7) ``` As `ObjectAggregationIterator` reads the input, the buffers get set up as follows (note that the first field of Item should be the same as the key): ``` - Read Item("a", 1) - Buffers are now: Key "a" --> Item("a", 1) - Read Item("b", 3) - Buffers are now: Key "a" -> Item("b", 3) Key "b" -> Item("b", 3) ``` The buffer for key "a" now contains `Item("b", 3)`. That's because both buffers contain a reference to the same Item instance, and that Item instance's fields were updated when `Item("b", 3)` was read. This PR makes `NewInstance` non-foldable, so it will not get optimized away, thus ensuring a new instance of the Java bean for each input record. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? New unit test. Closes #36183 from bersprockets/newinstance_issue. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit cc7cb7a803d5de03c526480c8968bbb2c3e82484) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 14 April 2022, 23:37:54 UTC |
| dc2212e | dch nguyen | 14 April 2022, 19:11:32 UTC | [SPARK-37405][PYTHON] Inline type hints for python/pyspark/ml/feature.py ### What changes were proposed in this pull request? Inline type hints for python/pyspark/ml/feature.py ### Why are the changes needed? We can take advantage of static type checking within the functions by inlining the type hints. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests Closes #35530 from dchvn/SPARK-37405. Lead-authored-by: dch nguyen <dchvn.dgd@gmail.com> Co-authored-by: dch nguyen <dgd_contributor@viettel.com.vn> Signed-off-by: zero323 <mszymkiewicz@gmail.com> (cherry picked from commit 8ce8a70e2f8a04c92a2b0d2f45fcdc8c7c8014be) Signed-off-by: zero323 <mszymkiewicz@gmail.com> | 14 April 2022, 19:11:46 UTC |
| 30c6802 | allisonwang-db | 14 April 2022, 04:11:00 UTC | [SPARK-38889][SQL] Compile boolean column filters to use the bit type for MSSQL data source ### What changes were proposed in this pull request? This PR compiles the boolean data type to the bit data type for pushed column filters while querying the MSSQL data soruce. Microsoft SQL Server does not support the boolean type, so the JDBC dialect should use the bit data type instead. ### Why are the changes needed? To fix a bug that was exposed by the boolean column filter pushdown to SQL server data source. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added a new integration test. Closes #36182 from allisonwang-db/spark-38889-mssql-predicate-pushdown. Authored-by: allisonwang-db <allison.wang@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 320f88d54440e05228a90ef5663991e28ae07c95) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 14 April 2022, 04:11:08 UTC |
| baaa3bb | dch nguyen | 14 April 2022, 00:03:24 UTC | [SPARK-37014][PYTHON] Inline type hints for python/pyspark/streaming/context.py ### What changes were proposed in this pull request? Inline type hints for python/pyspark/streaming/context.py from Inline type hints for python/pyspark/streaming/context.pyi. ### Why are the changes needed? Currently, there is type hint stub files python/pyspark/streaming/context.pyi to show the expected types for functions, but we can also take advantage of static type checking within the functions by inlining the type hints. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing test. Closes #34293 from dchvn/SPARK-37014. Authored-by: dch nguyen <dchvn.dgd@gmail.com> Signed-off-by: zero323 <mszymkiewicz@gmail.com> (cherry picked from commit c0c1f35cd9279bc1a7a50119be72a297162a9b55) Signed-off-by: zero323 <mszymkiewicz@gmail.com> | 14 April 2022, 00:03:35 UTC |
| 76f40ee | Ivan Sadikov | 13 April 2022, 09:06:03 UTC | [SPARK-38829][SQL][3.3] Remove TimestampNTZ type support in Parquet for Spark 3.3 ### What changes were proposed in this pull request? This is a follow-up for https://github.com/apache/spark/pull/36094. I added `Utils.isTesting` whenever we perform schema conversion or row conversion for TimestampNTZType. I verified that the tests, e.g. ParquetIOSuite, fail with unsupported data type when running in non-testing mode: ``` [info] Cause: org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 40.0 failed 1 times, most recent failure: Lost task 1.0 in stage 40.0 (TID 66) (ip-10-110-16-208.us-west-2.compute.internal executor driver): org.apache.spark.sql.AnalysisException: Unsupported data type timestamp_ntz [info] at org.apache.spark.sql.errors.QueryCompilationErrors$.cannotConvertDataTypeToParquetTypeError(QueryCompilationErrors.scala:1304) [info] at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.convertField(ParquetSchemaConverter.scala:707) [info] at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.convertField(ParquetSchemaConverter.scala:479) [info] at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.$anonfun$convert$1(ParquetSchemaConverter.scala:471) ``` ### Why are the changes needed? We have to disable TimestampNTZType as other parts of the codebase do not yet support this type. ### Does this PR introduce _any_ user-facing change? No, the TimestampNTZ type is not released yet. ### How was this patch tested? I tested the changes manually by rerunning the test suites that verify TimestampNTZType in the non-testing mode. Closes #36137 from sadikovi/SPARK-38829-parquet-ntz-off. Authored-by: Ivan Sadikov <ivan.sadikov@databricks.com> Signed-off-by: Gengliang Wang <gengliang@apache.org> | 13 April 2022, 09:06:03 UTC |
| c44020b | Enrico Minack | 13 April 2022, 08:07:27 UTC | [SPARK-38833][PYTHON][SQL] Allow applyInPandas to return empty DataFrame without columns ### What changes were proposed in this pull request? Methods `wrap_cogrouped_map_pandas_udf` and `wrap_grouped_map_pandas_udf` in `python/pyspark/worker.py` do not need to reject `pd.DataFrame`s with no columns return by udf when that DataFrame is empty (zero rows). This allows to return empty DataFrames without the need to define columns. The DataFrame is empty after all! **The proposed behaviour is consistent with the current behaviour of `DataFrame.mapInPandas`.** ### Why are the changes needed? Returning an empty DataFrame from the lambda given to `applyInPandas` should be as easy as this: ```python return pd.DataFrame([]) ``` However, PySpark requires that empty DataFrame to have the right _number_ of columns. This seems redundant as the schema is already defined in the `applyInPandas` call. Returning a non-empty DataFrame does not require defining columns. Behaviour of `applyInPandas` should be consistent with `mapInPandas`. Here is an example to reproduce: ```python import pandas as pd from pyspark.sql.functions import pandas_udf, ceil df = spark.createDataFrame( [(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)], ("id", "v")) def mean_func(key, pdf): if key == (1,): return pd.DataFrame([]) else: return pd.DataFrame([key + (pdf.v.mean(),)]) df.groupby("id").applyInPandas(mean_func, schema="id long, v double").show() ``` ### Does this PR introduce _any_ user-facing change? It changes the behaviour of the following calls to allow returning empty `pd.DataFrame` without defining columns. The PySpark DataFrame returned by `applyInPandas` is unchanged: - `df.groupby(…).applyInPandas(…)` - `df.cogroup(…).applyInPandas(…)` ### How was this patch tested? Tests are added that test `applyInPandas` and `mapInPandas` when returning - empty DataFrame with no columns - empty DataFrame with the wrong number of columns - non-empty DataFrame with wrong number of columns - something other than `pd.DataFrame` NOTE: It is not an error for `mapInPandas` to return DataFrames with more columns than specified in the `mapInPandas` schema. Closes #36120 from EnricoMi/branch-empty-pd-dataframes. Authored-by: Enrico Minack <github@enrico.minack.dev> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 556c74578eb2379fc6e0ec8d147674d0b10e5a2c) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 13 April 2022, 08:07:40 UTC |
| 96c8b4f | Jiaan Geng | 13 April 2022, 06:41:47 UTC | [SPARK-38855][SQL] DS V2 supports push down math functions ### What changes were proposed in this pull request? Currently, Spark have some math functions of ANSI standard. Please refer https://github.com/apache/spark/blob/2f8613f22c0750c00cf1dcfb2f31c431d8dc1be7/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/FunctionRegistry.scala#L388 These functions show below: `LN`, `EXP`, `POWER`, `SQRT`, `FLOOR`, `CEIL`, `WIDTH_BUCKET` The mainstream databases support these functions show below. | 函数 | PostgreSQL | ClickHouse | H2 | MySQL | Oracle | Redshift | Presto | Teradata | Snowflake | DB2 | Vertica | Exasol | SqlServer | Yellowbrick | Impala | Mariadb | Druid | Pig | SQLite | Influxdata | Singlestore | ElasticSearch | | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | | `LN` | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | | `EXP` | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | | `POWER` | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | Yes | Yes | Yes | Yes | | `SQRT` | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | | `FLOOR` | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | | `CEIL` | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | | `WIDTH_BUCKET` | Yes | No | No | No | Yes | No | Yes | Yes | Yes | Yes | Yes | No | No | No | Yes | No | No | No | No | No | No | No | DS V2 should supports push down these math functions. ### Why are the changes needed? DS V2 supports push down math functions ### Does this PR introduce _any_ user-facing change? 'No'. New feature. ### How was this patch tested? New tests. Closes #36140 from beliefer/SPARK-38855. Authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit bf75b495e18ed87d0c118bfd5f1ceb52d720cad9) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 13 April 2022, 06:42:00 UTC |
| 9db1162 | Xinyi Yu | 13 April 2022, 06:25:20 UTC | [SPARK-37047][SQL][FOLLOWUP] Add legacy flag for the breaking change of lpad and rpad for binary type ### What changes were proposed in this pull request? Add a legacy flag `spark.sql.legacy.lpadRpadForBinaryType.enabled` for the breaking change introduced in https://github.com/apache/spark/pull/34154. The flag is enabled by default. When it is disabled, restore the pre-change behavior that there is no special handling on `BINARY` input types. ### Why are the changes needed? The original commit is a breaking change, and breaking changes should be encouraged to add a flag to turn it off for smooth migration between versions. ### Does this PR introduce _any_ user-facing change? With the default value of the conf, there is no user-facing difference. If users turn this conf off, they can restore the pre-change behavior. ### How was this patch tested? Through unit tests. Closes #36103 from anchovYu/flags-lpad-rpad-binary. Authored-by: Xinyi Yu <xinyi.yu@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit e2683c2f3c6e758ef852355533793c707fd5e061) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 13 April 2022, 06:25:32 UTC |
| 2ef56c2 | minyyy | 13 April 2022, 06:01:27 UTC | [SPARK-38530][SQL] Fix a bug that GeneratorNestedColumnAliasing can be incorrectly applied to some expressions ### What changes were proposed in this pull request? This PR makes GeneratorNestedColumnAliasing only be able to apply to GetStructField*(_: AttributeReference), here GetStructField* means nested GetStructField. The current way to collect expressions is a top-down way and it actually only checks 2 levels which is wrong. The rule is simple - If we see expressions other than GetStructField, we are done. When an expression E is pushed down into an Explode, the thing happens is: E(x) is now pushed down to apply to E(array(x)). So only expressions that can operate on both x and array(x) can be pushed. GetStructField is special since we have GetArrayStructFields and when GetStructField is pushed down, it becomes GetArrayStructFields. Any other expressions are not applicable. We also do not even need to check the child type is Array(Array()) or whether the rewritten expression has the pattern GetArrayStructFields(GetArrayStructFields()). 1. When the child input type is Array(Array()), the ExtractValues expressions we get will always start from an innermost GetArrayStructFields, it does not align with GetStructField*(x). 2. When we see GetArrayStructFields(GetArrayStructFields()) in the rewritten generator, we must have seen a GetArrayStructFields in the expressions before pushdown. ### Why are the changes needed? It fixes some correctness issues. See the above section for more details. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit tests. Closes #35866 from minyyy/gnca_wrong_expr. Lead-authored-by: minyyy <min.yang@databricks.com> Co-authored-by: minyyy <98760575+minyyy@users.noreply.github.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 13edafab9f45cc80aee41e2f82475367d88357ec) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 13 April 2022, 06:01:39 UTC |
| 4ccd530 | Anton Okolnychyi | 13 April 2022, 05:47:00 UTC | [SPARK-38085][SQL] DataSource V2: Handle DELETE commands for group-based sources This PR contains changes to rewrite DELETE operations for V2 data sources that can replace groups of data (e.g. files, partitions). These changes are needed to support row-level operations in Spark per SPIP SPARK-35801. No. This PR comes with tests. Closes #35395 from aokolnychyi/spark-38085. Authored-by: Anton Okolnychyi <aokolnychyi@apple.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 5a92eccd514b7bc0513feaecb041aee2f8cd5a24) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 13 April 2022, 05:48:43 UTC |
| 2e0a21a | Jiaan Geng | 13 April 2022, 05:17:54 UTC | [SPARK-38865][SQL][DOCS] Update document of JDBC options for `pushDownAggregate` and `pushDownLimit` ### What changes were proposed in this pull request? Because the DS v2 pushdown framework refactored, we need to add more doc in `sql-data-sources-jdbc.md` to reflect the new changes. ### Why are the changes needed? Add doc for new changes for `pushDownAggregate` and `pushDownLimit`. ### Does this PR introduce _any_ user-facing change? 'No'. Updated for new feature. ### How was this patch tested? N/A Closes #36152 from beliefer/SPARK-38865. Authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: huaxingao <huaxin_gao@apple.com> (cherry picked from commit 988af33af8d35316aa131dab01814fd31fc6b59a) Signed-off-by: huaxingao <huaxin_gao@apple.com> | 13 April 2022, 05:18:09 UTC |
| 76fa565 | Takuya UESHIN | 13 April 2022, 00:21:55 UTC | [SPARK-38882][PYTHON] Fix usage logger attachment to handle static methods properly ### What changes were proposed in this pull request? Fixes usage logger attachment to handle static methods properly. ### Why are the changes needed? The usage logger attachment logic has an issue when handling static methods. For example, ``` $ PYSPARK_PANDAS_USAGE_LOGGER=pyspark.pandas.usage_logging.usage_logger ./bin/pyspark ``` ```py >>> import pyspark.pandas as ps >>> psdf = ps.DataFrame({"a": [1,2,3], "b": [4,5,6]}) >>> psdf.from_records([(1, 2), (3, 4)]) A function `DataFrame.from_records(data, index, exclude, columns, coerce_float, nrows)` was failed after 2007.430 ms: 0 Traceback (most recent call last): ... ``` without usage logger: ```py >>> import pyspark.pandas as ps >>> psdf = ps.DataFrame({"a": [1,2,3], "b": [4,5,6]}) >>> psdf.from_records([(1, 2), (3, 4)]) 0 1 0 1 2 1 3 4 ``` ### Does this PR introduce _any_ user-facing change? Yes, for a user attaches the usage logger, static methods will work as static methods. ### How was this patch tested? Manually tested. ```py >>> import pyspark.pandas as ps >>> import logging >>> import sys >>> root = logging.getLogger() >>> root.setLevel(logging.INFO) >>> handler = logging.StreamHandler(sys.stdout) >>> handler.setLevel(logging.INFO) >>> >>> formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') >>> handler.setFormatter(formatter) >>> root.addHandler(handler) >>> psdf = ps.DataFrame({"a": [1,2,3], "b": [4,5,6]}) 2022-04-12 14:43:52,254 - pyspark.pandas.usage_logger - INFO - A function `DataFrame.__init__(self, data, index, columns, dtype, copy)` was successfully finished after 2714.896 ms. >>> psdf.from_records([(1, 2), (3, 4)]) 2022-04-12 14:43:59,765 - pyspark.pandas.usage_logger - INFO - A function `DataFrame.from_records(data, index, exclude, columns, coerce_float, nrows)` was successfully finished after 51.105 ms. 2022-04-12 14:44:01,371 - pyspark.pandas.usage_logger - INFO - A function `DataFrame.__repr__(self)` was successfully finished after 1605.759 ms. 0 1 0 1 2 1 3 4 >>> ps.DataFrame.from_records([(1, 2), (3, 4)]) 2022-04-12 14:44:25,301 - pyspark.pandas.usage_logger - INFO - A function `DataFrame.from_records(data, index, exclude, columns, coerce_float, nrows)` was successfully finished after 43.446 ms. 2022-04-12 14:44:25,493 - pyspark.pandas.usage_logger - INFO - A function `DataFrame.__repr__(self)` was successfully finished after 192.053 ms. 0 1 0 1 2 1 3 4 ``` Closes #36167 from ueshin/issues/SPARK-38882/staticmethod. Authored-by: Takuya UESHIN <ueshin@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 1c1216f18f3008b410a601516b2fde49a9e27f7d) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 13 April 2022, 00:22:05 UTC |
| b2960b2 | Gengliang Wang | 12 April 2022, 12:39:08 UTC | [SPARK-38589][SQL] New SQL function: try_avg ### What changes were proposed in this pull request? Add a new SQL function: try_avg. It is identical to the function `avg`, except that it returns NULL result instead of throwing an exception on decimal/interval value overflow. Note it is also different from `avg` when ANSI mode is off on interval overflows | Function | avg | try_avg | |------------------|------------------------------------|-------------| | year-month interval overflow | Error | Return NULL | | day-time interval overflow | Error | Return NULL | ### Why are the changes needed? * Users can manage to finish queries without interruptions in ANSI mode. * Users can get NULLs instead of runtime errors if interval overflow occurs when ANSI mode is off. For example ``` > SELECT avg(col) FROM VALUES (interval '2147483647 months'),(interval '1 months') AS tab(col) java.lang.ArithmeticException: integer overflow. > SELECT try_avg(col) FROM VALUES (interval '2147483647 months'),(interval '1 months') AS tab(col) NULL ``` ### Does this PR introduce _any_ user-facing change? Yes, adding a new SQL function: try_avg. It is identical to the function `avg`, except that it returns NULL result instead of throwing an exception on decimal/interval value overflow. ### How was this patch tested? UT Closes #35896 from gengliangwang/tryAvg. Lead-authored-by: Gengliang Wang <gengliang@apache.org> Co-authored-by: Gengliang Wang <ltnwgl@gmail.com> Signed-off-by: Gengliang Wang <gengliang@apache.org> (cherry picked from commit a7f0adb2dd8449af6f9e9b5a25f11b5dcf5868f1) Signed-off-by: Gengliang Wang <gengliang@apache.org> | 12 April 2022, 12:39:27 UTC |
| 9926b09 | Ankur Dave | 12 April 2022, 03:01:19 UTC | [SPARK-38677][PYSPARK] Python MonitorThread should detect deadlock due to blocking I/O ### What changes were proposed in this pull request? When calling a Python UDF on a DataFrame with large rows, a deadlock can occur involving the following three threads: 1. The Scala task executor thread. During task execution, this is responsible for reading output produced by the Python process. However, in this case the task has finished early, and this thread is no longer reading output produced by the Python process. Instead, it is waiting for the Scala WriterThread to exit so that it can finish the task. 2. The Scala WriterThread. This is trying to send a large row to the Python process, and is waiting for the Python process to read that row. 3. The Python process. This is trying to send a large output to the Scala task executor thread, and is waiting for that thread to read that output, which will never happen. We considered the following three solutions for the deadlock: 1. When the task completes, make the Scala task executor thread close the socket before waiting for the Scala WriterThread to exit. If the WriterThread is blocked on a large write, this would interrupt that write and allow the WriterThread to exit. However, it would prevent Python worker reuse. 2. Modify PythonWorkerFactory to use interruptible I/O. [java.nio.channels.SocketChannel](https://docs.oracle.com/javase/6/docs/api/java/nio/channels/SocketChannel.html#write(java.nio.ByteBuffer)) supports interruptible blocking operations. The goal is that when the WriterThread is interrupted, it should exit even if it was blocked on a large write. However, this would be invasive. 3. Add a watchdog thread similar to the existing PythonRunner.MonitorThread to detect this deadlock and kill the Python worker. The MonitorThread currently kills the Python worker only if the task itself is interrupted. In this case, the task completes normally, so the MonitorThread does not take action. We want the new watchdog thread (WriterMonitorThread) to detect that the task is completed but the Python writer thread has not stopped, indicating a deadlock. This PR implements Option 3. ### Why are the changes needed? To fix a deadlock that can cause PySpark queries to hang. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Added a test that previously encountered the deadlock and timed out, and now succeeds. Closes #36065 from ankurdave/SPARK-38677. Authored-by: Ankur Dave <ankurdave@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 088e05d2518883aa27d0b8144107e45f41dd6b90) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 12 April 2022, 03:01:27 UTC |
| 47c7ba2 | Chao Sun | 12 April 2022, 02:17:10 UTC | [SPARK-34863][SQL][FOLLOWUP] Add benchmark for Parquet & ORC nested column scan ### What changes were proposed in this pull request? This adds benchmark for Parquet & ORC nested column scan, e.g., struct, list and map. ### Why are the changes needed? Both Parquet and ORC now support vectorized reader for nested column now, but there is no benchmark to measure the performance yet. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? N/A - benchmark only. Closes #36123 from sunchao/SPARK-34863-bench. Authored-by: Chao Sun <sunchao@apple.com> Signed-off-by: Chao Sun <sunchao@apple.com> | 12 April 2022, 02:18:03 UTC |
| fae6a1c | Max Gekk | 11 April 2022, 17:22:40 UTC | [SPARK-38791][SQL][3.3] Output parameter values of error classes in the SQL style ### What changes were proposed in this pull request? In the PR, I propose new trait `QueryErrorsBase` which is supposed to be used by `Query.*Errors`, and new method `toSQLValue()`. The method converts a parameter value of error classes to its SQL representation. ### Why are the changes needed? To improve user experience with Spark SQL. Users should see values in error messages in unified SQL style. ### Does this PR introduce _any_ user-facing change? Yes. ### How was this patch tested? By running the modified test suites: ``` $ build/sbt "test:testOnly *QueryExecutionErrorsSuite" ``` Authored-by: Max Gekk <max.gekkgmail.com> Signed-off-by: Max Gekk <max.gekkgmail.com> (cherry picked from commit bc8c264851457d8ef59f5b332c79296651ec5d1e) Signed-off-by: Max Gekk <max.gekkgmail.com> Closes #36143 from MaxGekk/cleanup-error-classes-3.3. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 11 April 2022, 17:22:40 UTC |
| 83ae6f4 | Daniel Tenedorio | 11 April 2022, 09:40:39 UTC | [SPARK-38796][SQL] Implement the to_number and try_to_number SQL functions according to a new specification ### What changes were proposed in this pull request? This PR implements the `to_number` and `try_to_number` SQL function expressions according to new semantics described below. The former is equivalent to the latter except that it throws an exception instead of returning NULL for cases where the input string does not match the format string. ----------- # `try_to_number` function Returns `expr` cast to DECIMAL using formatting `fmt`, or `NULL` if `expr` is not a valid match for the given format. ## Syntax ``` try_to_number(expr, fmt) fmt { ' [ S ] [ L | $ ] [ 0 | 9 | G | , ] [...] [ . | D ] [ 0 | 9 ] [...] [ L | $ ] [ PR | MI | S ] ' } ``` ## Arguments - `expr`: A STRING expression representing a number. `expr` may include leading or trailing spaces. - `fmt`: An STRING literal, specifying the expected format of `expr`. ## Returns A DECIMAL(p, s) where `p` is the total number of digits (`0` or `9`) and `s` is the number of digits after the decimal point, or 0 if there is none. `fmt` can contain the following elements (case insensitive): - **`0`** or **`9`** Specifies an expected digit between `0` and `9`. A `0` to the left of the decimal points indicates that `expr` must have at least as many digits. A leading `9` indicates that `expr` may omit these digits. `expr` must not be larger than the number of digits to the left of the decimal point allowed by the format string. Digits to the right of the decimal point in the format string indicate the most digits that `expr` may have to the right of the decimal point. - **`.`** or **`D`** Specifies the position of the decimal point. `expr` does not need to include a decimal point. - **`,`** or **`G`** Specifies the position of the `,` grouping (thousands) separator. There must be a `0` or `9` to the left of the rightmost grouping separator. `expr` must match the grouping separator relevant for the size of the number. - **`L`** or **`$`** Specifies the location of the `$` currency sign. This character may only be specified once. - **`S`** Specifies the position of an option '+' or '-' sign. This character may only be specified once. - **`MI`** Specifies that `expr` has an optional `-` sign at the end, but no `+`. - **`PR`** Specifies that `expr` indicates a negative number with wrapping angled brackets (`<1>`). If `expr` contains any characters other than `0` through `9` and those permitted in `fmt` a `NULL` is returned. ## Examples ```sql -- The format expects: -- * an optional sign at the beginning, -- * followed by a dollar sign, -- * followed by a number between 3 and 6 digits long, -- * thousands separators, -- * up to two dights beyond the decimal point. > SELECT try_to_number('-$12,345.67', 'S$999,099.99'); -12345.67 -- The plus sign is optional, and so are fractional digits. > SELECT try_to_number('$345', 'S$999,099.99'); 345.00 -- The format requires at least three digits. > SELECT try_to_number('$45', 'S$999,099.99'); NULL -- The format requires at least three digits. > SELECT try_to_number('$045', 'S$999,099.99'); 45.00 -- Using brackets to denote negative values > SELECT try_to_number('<1234>', '999999PR'); -1234 ``` ### Why are the changes needed? The new semantics bring Spark into consistency with other engines and grant the user flexibility about how to handle cases where inputs do not match the format string. ### Does this PR introduce _any_ user-facing change? Yes. * The minus sign `-` is no longer supported in the format string (`S` replaces it). * `MI` and `PR` are new options in the format string. * `to_number` and `try_to_number` are separate functions with different error behavior. ### How was this patch tested? * New positive and negative unit tests cover both `to_number` and `try_to_number` functions. * Query tests update as needed according to the behavior changes. Closes #36066 from dtenedor/to-number. Authored-by: Daniel Tenedorio <daniel.tenedorio@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 7a6b98965bf40993ea2e7837ded1c79813bec5d8) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 11 April 2022, 09:40:56 UTC |
| f4457e6 | zero323 | 11 April 2022, 09:29:47 UTC | [SPARK-37402][PYTHON][MLLIB] Inline typehints for pyspark.mllib.clustering ### What changes were proposed in this pull request? This PR migrates type `pyspark.mllib.clustering` annotations from stub file to inline type hints. ### Why are the changes needed? Part of ongoing migration of type hints. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes #35578 from zero323/SPARK-37402. Authored-by: zero323 <mszymkiewicz@gmail.com> Signed-off-by: zero323 <mszymkiewicz@gmail.com> (cherry picked from commit e71cf3907b9ff2036dfe45bc8fe939f20cca741b) Signed-off-by: zero323 <mszymkiewicz@gmail.com> | 11 April 2022, 09:30:01 UTC |
| e54dc43 | Yuming Wang | 11 April 2022, 07:43:41 UTC | [SPARK-38565][SQL] Support Left Semi join in row level runtime filters ### What changes were proposed in this pull request? 1. Support Left Semi join in row level runtime filters. 2. Rename `spark.sql.optimizer.runtime.bloomFilter.applicationSideScanSizethreshold` to `spark.sql.optimizer.runtime.bloomFilter.applicationSideScanSizeThreshold`. ### Why are the changes needed? Improve query performance and make the code easier to maintain. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing UT. Closes #36131 from wangyum/SPARK-38565. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit 073fd2ad5c16d193725954e76ce357e4a9d97449) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 11 April 2022, 07:44:06 UTC |
| b3cd07b | Jiaan Geng | 11 April 2022, 05:50:57 UTC | [SPARK-38761][SQL] DS V2 supports push down misc non-aggregate functions ### What changes were proposed in this pull request? Currently, Spark have some misc non-aggregate functions of ANSI standard. Please refer https://github.com/apache/spark/blob/2f8613f22c0750c00cf1dcfb2f31c431d8dc1be7/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/FunctionRegistry.scala#L362. These functions show below: `abs`, `coalesce`, `nullif`, `CASE WHEN` DS V2 should supports push down these misc non-aggregate functions. Because DS V2 already support push down `CASE WHEN`, so this PR no need do the job again. Because `nullif` extends `RuntimeReplaceable`, so this PR no need do the job too. ### Why are the changes needed? DS V2 supports push down misc non-aggregate functions ### Does this PR introduce _any_ user-facing change? 'No'. New feature. ### How was this patch tested? New tests. Closes #36039 from beliefer/SPARK-38761. Authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 9ce4ba02d3f67116a4a9786af453d869596fb3ec) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 11 April 2022, 05:51:10 UTC |
| 5c3ef79 | Jiaan Geng | 11 April 2022, 05:48:07 UTC | [SPARK-37960][SQL][FOLLOWUP] Make the testing CASE WHEN query more reasonable ### What changes were proposed in this pull request? Some testing CASE WHEN queries are not carefully written and do not make sense. In the future, the optimizer may get smarter and get rid of the CASE WHEN completely, and then we loose test coverage. This PR updates some CASE WHEN queries to make them more reasonable. ### Why are the changes needed? future-proof test coverage. ### Does this PR introduce _any_ user-facing change? 'No'. ### How was this patch tested? N/A Closes #36125 from beliefer/SPARK-37960_followup3. Authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 4e118383f58d23d5515ce6b00d3935e3ac51fb03) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 11 April 2022, 05:48:21 UTC |