https://github.com/apache/spark
- HEAD
- refs/heads/branch-0.5
- refs/heads/branch-0.6
- refs/heads/branch-0.7
- refs/heads/branch-0.8
- refs/heads/branch-0.9
- refs/heads/branch-1.0
- refs/heads/branch-1.0-jdbc
- refs/heads/branch-1.1
- refs/heads/branch-1.2
- refs/heads/branch-1.3
- refs/heads/branch-1.4
- refs/heads/branch-1.5
- refs/heads/branch-1.6
- refs/heads/branch-2.0
- refs/heads/branch-2.1
- refs/heads/branch-2.2
- refs/heads/branch-2.3
- refs/heads/branch-2.4
- refs/heads/branch-3.0
- refs/heads/branch-3.1
- refs/heads/branch-3.2
- refs/heads/branch-3.3
- refs/heads/branch-3.4
- refs/heads/branch-3.5
- refs/heads/master
- refs/remotes/origin/branch-0.8
- refs/remotes/origin/td-rdd-save
- refs/tags/0.3-scala-2.8
- refs/tags/0.3-scala-2.9
- refs/tags/2.0.0-preview
- refs/tags/alpha-0.1
- refs/tags/alpha-0.2
- refs/tags/v0.5.0
- refs/tags/v0.5.1
- refs/tags/v0.5.2
- refs/tags/v0.6.0
- refs/tags/v0.6.0-yarn
- refs/tags/v0.6.1
- refs/tags/v0.6.2
- refs/tags/v0.7.0
- refs/tags/v0.7.0-bizo-1
- refs/tags/v0.7.1
- refs/tags/v0.7.2
- refs/tags/v0.9.1
- refs/tags/v0.9.2
- refs/tags/v1.0.0
- refs/tags/v1.0.1
- refs/tags/v1.0.2
- refs/tags/v1.1.0
- refs/tags/v1.1.1
- refs/tags/v1.2.0
- refs/tags/v1.2.1
- refs/tags/v1.2.2
- refs/tags/v1.3.0
- refs/tags/v1.3.1
- refs/tags/v1.4.0
- refs/tags/v1.4.1
- refs/tags/v1.5.0-rc1
- refs/tags/v1.5.0-rc2
- refs/tags/v1.5.0-rc3
- refs/tags/v1.5.1
- refs/tags/v1.6.0
- refs/tags/v1.6.1
- refs/tags/v1.6.2
- refs/tags/v1.6.3
- refs/tags/v2.0.0
- refs/tags/v2.0.1
- refs/tags/v2.0.2
- refs/tags/v2.1.0
- refs/tags/v2.1.1
- refs/tags/v2.1.2
- refs/tags/v2.1.2-rc1
- refs/tags/v2.1.2-rc2
- refs/tags/v2.1.2-rc3
- refs/tags/v2.1.2-rc4
- refs/tags/v2.1.3
- refs/tags/v2.1.3-rc1
- refs/tags/v2.1.3-rc2
- refs/tags/v2.2.0
- refs/tags/v2.2.1
- refs/tags/v2.2.1-rc1
- refs/tags/v2.2.1-rc2
- refs/tags/v2.2.2
- refs/tags/v2.2.2-rc1
- refs/tags/v2.2.2-rc2
- refs/tags/v2.2.3
- refs/tags/v2.2.3-rc1
- refs/tags/v2.3.0
- refs/tags/v2.3.0-rc1
- refs/tags/v2.3.0-rc2
- refs/tags/v2.3.0-rc3
- refs/tags/v2.3.0-rc4
- refs/tags/v2.3.1
- refs/tags/v2.3.1-rc1
- refs/tags/v2.3.1-rc2
- refs/tags/v2.3.1-rc3
- refs/tags/v2.3.1-rc4
- refs/tags/v2.3.2
- refs/tags/v2.3.2-rc1
- refs/tags/v2.3.2-rc2
- refs/tags/v2.3.2-rc3
- refs/tags/v2.3.2-rc4
- refs/tags/v2.3.2-rc5
- refs/tags/v2.3.2-rc6
- refs/tags/v2.3.3
- refs/tags/v2.3.3-rc1
- refs/tags/v2.3.3-rc2
- refs/tags/v2.3.4
- refs/tags/v2.3.4-rc1
- refs/tags/v2.4.0
- refs/tags/v2.4.0-rc1
- refs/tags/v2.4.0-rc2
- refs/tags/v2.4.0-rc3
- refs/tags/v2.4.0-rc4
- refs/tags/v2.4.0-rc5
- refs/tags/v2.4.1
- refs/tags/v2.4.1-rc1
- refs/tags/v2.4.1-rc2
- refs/tags/v2.4.1-rc3
- refs/tags/v2.4.1-rc4
- refs/tags/v2.4.1-rc5
- refs/tags/v2.4.1-rc6
- refs/tags/v2.4.1-rc7
- refs/tags/v2.4.1-rc8
- refs/tags/v2.4.1-rc9
- refs/tags/v2.4.2
- refs/tags/v2.4.2-rc1
- refs/tags/v2.4.3
- refs/tags/v2.4.3-rc1
- refs/tags/v2.4.4
- refs/tags/v2.4.4-rc1
- refs/tags/v2.4.4-rc2
- refs/tags/v2.4.4-rc3
- refs/tags/v2.4.5
- refs/tags/v2.4.5-rc1
- refs/tags/v2.4.5-rc2
- refs/tags/v2.4.6
- refs/tags/v2.4.6-rc1
- refs/tags/v2.4.6-rc2
- refs/tags/v2.4.6-rc3
- refs/tags/v2.4.6-rc4
- refs/tags/v2.4.6-rc5
- refs/tags/v2.4.6-rc6
- refs/tags/v2.4.6-rc7
- refs/tags/v2.4.6-rc8
- refs/tags/v2.4.7
- refs/tags/v2.4.7-rc1
- refs/tags/v2.4.7-rc2
- refs/tags/v2.4.7-rc3
- refs/tags/v2.4.8
- refs/tags/v2.4.8-rc1
- refs/tags/v2.4.8-rc2
- refs/tags/v2.4.8-rc3
- refs/tags/v2.4.8-rc4
- refs/tags/v3.0.0
- refs/tags/v3.0.0-preview2
- refs/tags/v3.0.0-preview2-rc1
- refs/tags/v3.0.0-preview2-rc2
- refs/tags/v3.0.0-rc1
- refs/tags/v3.0.0-rc2
- refs/tags/v3.0.0-rc3
- refs/tags/v3.0.1
- refs/tags/v3.0.1-rc1
- refs/tags/v3.0.1-rc2
- refs/tags/v3.0.1-rc3
- refs/tags/v3.0.2
- refs/tags/v3.0.2-rc1
- refs/tags/v3.0.3
- refs/tags/v3.0.3-rc1
- refs/tags/v3.1.0-rc1
- refs/tags/v3.1.1
- refs/tags/v3.1.1-rc1
- refs/tags/v3.1.1-rc2
- refs/tags/v3.1.1-rc3
- refs/tags/v3.1.2
- refs/tags/v3.1.2-rc1
- refs/tags/v3.1.3
- refs/tags/v3.1.3-rc1
- refs/tags/v3.1.3-rc2
- refs/tags/v3.1.3-rc3
- refs/tags/v3.1.3-rc4
- refs/tags/v3.2.0
- refs/tags/v3.2.0-rc1
- refs/tags/v3.2.0-rc2
- refs/tags/v3.2.0-rc3
- refs/tags/v3.2.0-rc4
- refs/tags/v3.2.0-rc5
- refs/tags/v3.2.0-rc6
- refs/tags/v3.2.0-rc7
- refs/tags/v3.2.1
- refs/tags/v3.2.1-rc1
- refs/tags/v3.2.1-rc2
- refs/tags/v3.2.2
- refs/tags/v3.2.2-rc1
- refs/tags/v3.2.3
- refs/tags/v3.2.3-rc1
- refs/tags/v3.2.4
- refs/tags/v3.2.4-rc1
- refs/tags/v3.3.0
- refs/tags/v3.3.0-rc1
- refs/tags/v3.3.0-rc2
- refs/tags/v3.3.0-rc3
- refs/tags/v3.3.0-rc4
- refs/tags/v3.3.0-rc5
- refs/tags/v3.3.0-rc6
- refs/tags/v3.3.1
- refs/tags/v3.3.1-rc1
- refs/tags/v3.3.1-rc2
- refs/tags/v3.3.1-rc3
- refs/tags/v3.3.1-rc4
- refs/tags/v3.3.2
- refs/tags/v3.3.2-rc1
- refs/tags/v3.3.3
- refs/tags/v3.3.3-rc1
- refs/tags/v3.3.4
- refs/tags/v3.3.4-rc1
- refs/tags/v3.4.0
- refs/tags/v3.4.0-rc1
- refs/tags/v3.4.0-rc2
- refs/tags/v3.4.0-rc3
- refs/tags/v3.4.0-rc4
- refs/tags/v3.4.0-rc5
- refs/tags/v3.4.0-rc6
- refs/tags/v3.4.0-rc7
- refs/tags/v3.4.1
- refs/tags/v3.4.1-rc1
- refs/tags/v3.4.2
- refs/tags/v3.4.2-rc1
- refs/tags/v3.5.0
- refs/tags/v3.5.0-rc1
- refs/tags/v3.5.0-rc2
- refs/tags/v3.5.0-rc3
- refs/tags/v3.5.0-rc4
- refs/tags/v3.5.0-rc5
- refs/tags/v3.5.1
- refs/tags/v3.5.1-rc1
- refs/tags/v3.5.1-rc2
Take a new snapshot of a software origin
If the archived software origin currently browsed is not synchronized with its upstream version (for instance when new commits have been issued), you can explicitly request Software Heritage to take a new snapshot of it.
Use the form below to proceed. Once a request has been submitted and accepted, it will be processed as soon as possible. You can then check its processing state by visiting this dedicated page.
Processing "take a new snapshot" request ...
Permalinks
To reference or cite the objects present in the Software Heritage archive, permalinks based on SoftWare Hash IDentifiers (SWHIDs) must be used.
Select below a type of object currently browsed in order to display its associated SWHID and permalink.
| Revision | Author | Date | Message | Commit Date |
|---|---|---|---|---|
| f96b96d | Daniel Tenedorio | 01 July 2022, 08:49:50 UTC | [SPARK-38796][SQL] Update documentation for number format strings with the {try_}to_number functions ### What changes were proposed in this pull request? Update documentation for number format strings with the `{try_}to_number` functions. ### Why are the changes needed? The existing documentation is incomplete. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Built the doc site locally to provide the following initial screenshot: <img width="1224" alt="image" src="https://user-images.githubusercontent.com/99207096/174898847-4d42b6d7-f119-4001-bbf6-6d3ceb60fd77.png"> Closes #36950 from dtenedor/number-docs. Lead-authored-by: Daniel Tenedorio <daniel.tenedorio@databricks.com> Co-authored-by: Wenchen Fan <cloud0fan@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 09d1bae95be2af01da65573d57867346f3833907) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 01 July 2022, 08:50:08 UTC |
| 7e2a182 | Chao Sun | 01 July 2022, 06:18:06 UTC | [SPARK-37205][FOLLOWUP] Should call non-static setTokensConf method ### What changes were proposed in this pull request? This fixes a bug in the original SPARK-37205 PR, where we treat the method `setTokensConf` as a static method, but it should be non-static instead. ### Why are the changes needed? The method `setTokensConf` is non-static so the current code will fail: ``` 06/29/2022 - 17:28:16 - Exception in thread "main" java.lang.IllegalArgumentException: object is not an instance of declaring class 06/29/2022 - 17:28:16 - at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) 06/29/2022 - 17:28:16 - at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) 06/29/2022 - 17:28:16 - at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) 06/29/2022 - 17:28:16 - at java.base/java.lang.reflect.Method.invoke(Method.java:566) ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Manually tested this change internally and it now works. Closes #37037 from sunchao/SPARK-37205-fix. Authored-by: Chao Sun <sunchao@apple.com> Signed-off-by: Chao Sun <sunchao@apple.com> | 01 July 2022, 06:18:37 UTC |
| 18000fd | Prashant Singh | 01 July 2022, 00:16:32 UTC | [SPARK-39633][SQL] Support timestamp in seconds for TimeTravel using Dataframe options ### What changes were proposed in this pull request? Support timestamp in seconds for TimeTravel using Dataframe options ### Why are the changes needed? To have a parity in doing TimeTravel via SQL and Dataframe option. SPARK-SQL supports queries like : ```sql SELECT * from {table} TIMESTAMP AS OF 1548751078 ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added new UTs for testing the behaviour. Closes #37025 from singhpk234/fix/timetravel_df_options. Authored-by: Prashant Singh <psinghvk@amazon.com> Signed-off-by: huaxingao <huaxin_gao@apple.com> (cherry picked from commit 44e2657f3d511c25135c95dc3d584c540d227b5b) Signed-off-by: huaxingao <huaxin_gao@apple.com> | 01 July 2022, 00:16:50 UTC |
| d3f7f42 | yangjie01 | 29 June 2022, 23:09:10 UTC | [SPARK-39553][CORE] Multi-thread unregister shuffle shouldn't throw NPE when using Scala 2.13 ### What changes were proposed in this pull request? This pr add a `shuffleStatus != null` condition to `o.a.s.MapOutputTrackerMaster#unregisterShuffle` method to avoid throwing NPE when using Scala 2.13. ### Why are the changes needed? Ensure that no NPE is thrown when `o.a.s.MapOutputTrackerMaster#unregisterShuffle` is called by multiple threads, this pr is only for Scala 2.13. `o.a.s.MapOutputTrackerMaster#unregisterShuffle` method will be called concurrently by the following two paths: - BlockManagerStorageEndpoint: https://github.com/apache/spark/blob/6f1046afa40096f477b29beecca5ca6286dfa7f3/core/src/main/scala/org/apache/spark/storage/BlockManagerStorageEndpoint.scala#L56-L62 - ContextCleaner: https://github.com/apache/spark/blob/6f1046afa40096f477b29beecca5ca6286dfa7f3/core/src/main/scala/org/apache/spark/ContextCleaner.scala#L234-L241 When test with Scala 2.13, for example `sql/core` module, there are many log as follows,although these did not cause UTs failure: ``` 17:44:09.957 WARN org.apache.spark.storage.BlockManagerMaster: Failed to remove shuffle 87 - null java.lang.NullPointerException at org.apache.spark.MapOutputTrackerMaster.$anonfun$unregisterShuffle$1(MapOutputTracker.scala:882) at org.apache.spark.MapOutputTrackerMaster.$anonfun$unregisterShuffle$1$adapted(MapOutputTracker.scala:881) at scala.Option.foreach(Option.scala:437) at org.apache.spark.MapOutputTrackerMaster.unregisterShuffle(MapOutputTracker.scala:881) at org.apache.spark.storage.BlockManagerStorageEndpoint$$anonfun$receiveAndReply$1.$anonfun$applyOrElse$3(BlockManagerStorageEndpoint.scala:59) at scala.runtime.java8.JFunction0$mcZ$sp.apply(JFunction0$mcZ$sp.scala:17) at org.apache.spark.storage.BlockManagerStorageEndpoint.$anonfun$doAsync$1(BlockManagerStorageEndpoint.scala:89) at scala.concurrent.Future$.$anonfun$apply$1(Future.scala:678) at scala.concurrent.impl.Promise$Transformation.run(Promise.scala:467) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) 17:44:09.958 ERROR org.apache.spark.ContextCleaner: Error cleaning shuffle 94 java.lang.NullPointerException at org.apache.spark.MapOutputTrackerMaster.$anonfun$unregisterShuffle$1(MapOutputTracker.scala:882) at org.apache.spark.MapOutputTrackerMaster.$anonfun$unregisterShuffle$1$adapted(MapOutputTracker.scala:881) at scala.Option.foreach(Option.scala:437) at org.apache.spark.MapOutputTrackerMaster.unregisterShuffle(MapOutputTracker.scala:881) at org.apache.spark.ContextCleaner.doCleanupShuffle(ContextCleaner.scala:241) at org.apache.spark.ContextCleaner.$anonfun$keepCleaning$3(ContextCleaner.scala:202) at org.apache.spark.ContextCleaner.$anonfun$keepCleaning$3$adapted(ContextCleaner.scala:195) at scala.Option.foreach(Option.scala:437) at org.apache.spark.ContextCleaner.$anonfun$keepCleaning$1(ContextCleaner.scala:195) at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1432) at org.apache.spark.ContextCleaner.org$apache$spark$ContextCleaner$$keepCleaning(ContextCleaner.scala:189) at org.apache.spark.ContextCleaner$$anon$1.run(ContextCleaner.scala:79) ``` I think this is a bug of Scala 2.13.8 and already submit an issue to https://github.com/scala/bug/issues/12613, this PR is only for protection, we should remove this protection after Scala 2.13(maybe https://github.com/scala/scala/pull/9957) fixes this issue. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass GA - Add new test `SPARK-39553: Multi-thread unregister shuffle shouldn't throw NPE` to `MapOutputTrackerSuite`, we can test manually as follows: ``` dev/change-scala-version.sh 2.13 mvn clean install -DskipTests -pl core -am -Pscala-2.13 mvn clean test -pl core -Pscala-2.13 -Dtest=none -DwildcardSuites=org.apache.spark.MapOutputTrackerSuite ``` **Before** ``` - SPARK-39553: Multi-thread unregister shuffle shouldn't throw NPE *** FAILED *** 3 did not equal 0 (MapOutputTrackerSuite.scala:971) Run completed in 17 seconds, 505 milliseconds. Total number of tests run: 25 Suites: completed 2, aborted 0 Tests: succeeded 24, failed 1, canceled 0, ignored 1, pending 0 *** 1 TEST FAILED *** ``` **After** ``` - SPARK-39553: Multi-thread unregister shuffle shouldn't throw NPE Run completed in 17 seconds, 996 milliseconds. Total number of tests run: 25 Suites: completed 2, aborted 0 Tests: succeeded 25, failed 0, canceled 0, ignored 1, pending 0 All tests passed. ``` Closes #37024 from LuciferYang/SPARK-39553. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 29258964cae45cea43617ade971fb4ea9fe2902a) Signed-off-by: Sean Owen <srowen@gmail.com> | 29 June 2022, 23:09:19 UTC |
| 7adb6e2 | mcdull-zhang | 28 June 2022, 16:55:51 UTC | [SPARK-37753][FOLLOWUP][SQL] Add comments to unit test ### What changes were proposed in this pull request? add comments to unit test. ### Why are the changes needed? code can be hard to understand without comments ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? existing test Closes #37018 from mcdull-zhang/add_reason. Authored-by: mcdull-zhang <work4dong@163.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 9fd010be24fcd6d81e05bd08133fd80ba81b97ac) Signed-off-by: Sean Owen <srowen@gmail.com> | 28 June 2022, 16:55:59 UTC |
| 1f6b142 | Wenchen Fan | 28 June 2022, 14:40:41 UTC | [SPARK-39570][SQL] Inline table should allow expressions with alias ### What changes were proposed in this pull request? `ResolveInlineTables` requires the column expressions to be foldable, however, `Alias` is not foldable. Inline-table does not use the names in the column expressions, and we should trim aliases before checking foldable. We did something similar in `ResolvePivot`. ### Why are the changes needed? To make inline-table handle more cases, and also fixed a regression caused by https://github.com/apache/spark/pull/31844 . After https://github.com/apache/spark/pull/31844 , we always add an alias for function literals like `current_timestamp`, which breaks inline table. ### Does this PR introduce _any_ user-facing change? yea, some failed queries can be run after this PR. ### How was this patch tested? new tests Closes #36967 from cloud-fan/bug. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 1df992f03fd935ac215424576530ab57d1ab939b) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 28 June 2022, 14:41:01 UTC |
| cf72e52 | Dongjoon Hyun | 27 June 2022, 19:52:11 UTC | [SPARK-39621][PYTHON][TESTS] Make `run-tests.py` robust by avoiding `rmtree` on MacOS ### What changes were proposed in this pull request? This PR aims to make `run-tests.py` robust by avoiding `rmtree` on MacOS. ### Why are the changes needed? There exists a race condition in Python and it causes flakiness in MacOS - https://bugs.python.org/issue29699 - https://github.com/python/cpython/issues/73885 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? After passing CIs, this should be tested on MacOS. Closes #37010 from dongjoon-hyun/SPARK-39621. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 432945db743965f1beb59e3a001605335ca2df83) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 27 June 2022, 19:52:29 UTC |
| 7e1a329 | Jiaan Geng | 27 June 2022, 13:51:21 UTC | [SPARK-39577][SQL][DOCS] Add SQL reference for built-in functions ### What changes were proposed in this pull request? Currently, Spark SQL reference missing many functions. Users cannot find the needed functions. ### Why are the changes needed? Add SQL reference for built-in functions ### Does this PR introduce _any_ user-facing change? 'Yes'. Users can find needed functions in SQL reference. Before this PR, the built-in functions show below.  After this PR, the built-in functions show below.  The part of Mathematical Functions show below.     The part of String Functions show below.     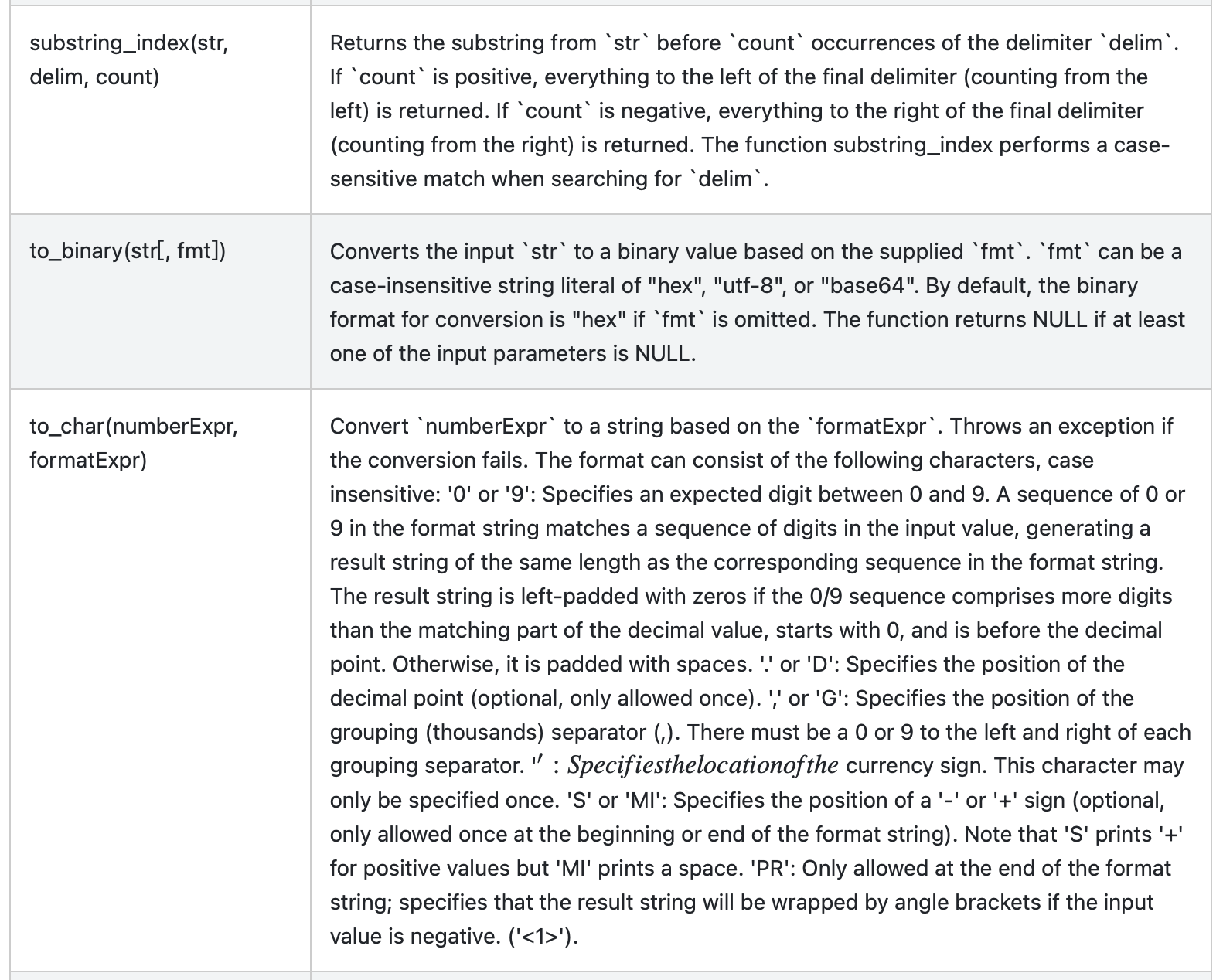   The part of Bitwise Functions show below.  The part of Conversion Functions show below.  The part of Conditional Functions show below.  The part of Predicate Functions show below.   The part of Csv Functions show below.  The part of Misc Functions show below.   The part of Generator Functions show below.  ### How was this patch tested? N/A Closes #36976 from beliefer/SPARK-39577. Authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 250cb912215e548b965aa2d1a27affe9f924cac7) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 27 June 2022, 13:51:40 UTC |
| 39413db | mcdull-zhang | 27 June 2022, 13:46:53 UTC | [SPARK-37753][FOLLOWUP][SQL] Fix unit tests sometimes failing ### What changes were proposed in this pull request? This unit test sometimes fails to run. for example, https://github.com/apache/spark/pull/35715#discussion_r892247619 When the left side is completed first, and then the right side is completed, since it is known that there are many empty partitions on the left side, the broadcast on the right side is demoted. However, if the right side is completed first and the left side is still being executed, the right side does not know whether there are many empty partitions on the left side, so there is no demote, and then the right side is broadcast in the planning stage. This PR does this: When it is found that the other side is QueryStage, if the QueryStage has not been materialized, demote it first. When the other side is completed, judge again whether demote is needed. ### Why are the changes needed? Fix small problems in logic ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? manual testing Closes #36966 from mcdull-zhang/wait_other_side. Authored-by: mcdull-zhang <work4dong@163.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 8c8801cf501ddbdeb4a4a869bc27c8a2331531fe) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 27 June 2022, 13:47:14 UTC |
| 972338a | Dongjoon Hyun | 27 June 2022, 08:29:57 UTC | [SPARK-39614][K8S] K8s pod name follows `DNS Subdomain Names` rule This PR aims to fix a regression at Apache Spark 3.3.0 which doesn't allow long pod name prefix whose length is greater than 63. Although Pod's `hostname` follows [DNS Label Names](https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#dns-label-names), Pod name itself follows [DNS Subdomain Names](https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#dns-subdomain-names) whose maximum length is 253. Yes, this fixes a regression. Pass the CIs with the updated unit tests. Closes #36999 from dongjoon-hyun/SPARK-39614. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit c15508f0d6a49738db5edf7eb139cc1d438af9a9) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 27 June 2022, 08:31:01 UTC |
| 427148f | wangzixuan.wzxuan | 27 June 2022, 02:05:08 UTC | [SPARK-39575][AVRO] add ByteBuffer#rewind after ByteBuffer#get in Avr… …oDeserializer ### What changes were proposed in this pull request? Add ByteBuffer#rewind after ByteBuffer#get in AvroDeserializer. ### Why are the changes needed? - HeapBuffer.get(bytes) puts the data from POS to the end into bytes, and sets POS as the end. The next call will return empty bytes. - The second call of AvroDeserializer will return an InternalRow with empty binary column when avro record has binary column. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Add ut in AvroCatalystDataConversionSuite. Closes #36973 from wzx140/avro-fix. Authored-by: wangzixuan.wzxuan <wangzixuan.wzxuan@bytedance.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 558b395880673ec45bf9514c98983e50e21d9398) Signed-off-by: Sean Owen <srowen@gmail.com> | 27 June 2022, 02:05:15 UTC |
| fc6a664 | yangjie01 | 26 June 2022, 13:18:02 UTC | [SPARK-39599][BUILD] Upgrade maven to 3.8.6 ### What changes were proposed in this pull request? This PR aims to upgrade Maven to 3.8.6 from 3.8.4. ### Why are the changes needed? The release notes and as follows: - https://maven.apache.org/docs/3.8.5/release-notes.html - https://maven.apache.org/docs/3.8.6/release-notes.html Note that the profile dependency bug should fixed by [MNG-7432] Resolver session contains non-MavenWorkspaceReader (#695) ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? - Pass GitHub Actions - Manual test 1: run `build/mvn -version` wll trigger download `apache-maven-3.8.6-bin.tar.gz` ``` exec: curl --silent --show-error -L https://www.apache.org/dyn/closer.lua/maven/maven-3/3.8.6/binaries/apache-maven-3.8.6-bin.tar.gz?action=download ``` - Manual test 2: run `./dev/test-dependencies.sh --replace-manifest ` doesn't generate git diff, this behavior is consistent with maven 3.8.4,but there will git diff of `dev/deps/spark-deps-hadoop-2-hive-2.3` when use maven 3.8.5. Closes #36978 from LuciferYang/mvn-386. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit a9397484853843d84bd12048b5ca162acdba2549) Signed-off-by: Sean Owen <srowen@gmail.com> | 26 June 2022, 13:18:13 UTC |
| 4c79cc7 | Dongjoon Hyun | 25 June 2022, 11:37:53 UTC | [SPARK-39596][INFRA][FOLLOWUP] Install `mvtnorm` and `statmod` at linter job ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? Closes #36988 from dongjoon-hyun/SPARK-39596-2. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 25 June 2022, 11:38:52 UTC |
| bf59f6e | Dongjoon Hyun | 25 June 2022, 07:31:54 UTC | [SPARK-39596][INFRA] Install `ggplot2` for GitHub Action linter job ### What changes were proposed in this pull request? This PR aims to fix GitHub Action linter job by installing `ggplot2`. ### Why are the changes needed? It starts to fail like the following. - https://github.com/apache/spark/runs/7047294196?check_suite_focus=true ``` x Failed to parse Rd in histogram.Rd ℹ there is no package called ‘ggplot2’ ``` ### Does this PR introduce _any_ user-facing change? No. This is a dev-only change. ### How was this patch tested? Pass the GitHub Action linter job. Closes #36987 from dongjoon-hyun/SPARK-39596. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 25 June 2022, 11:38:45 UTC |
| cb94925 | Rui Wang | 23 June 2022, 05:30:34 UTC | [SPARK-39548][SQL] CreateView Command with a window clause query hit a wrong window definition not found issue ### What changes were proposed in this pull request? 1. In the inline CTE code path, fix a bug that top down style unresolved window expression check leads to mis-clarification of a defined window expression. 2. Move unresolved window expression check in project to `CheckAnalysis`. ### Why are the changes needed? This bug fails a correct query. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? UT Closes #36947 from amaliujia/improvewindow. Authored-by: Rui Wang <rui.wang@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 4718d59c6c4e201bf940303a4311dfb753372395) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 23 June 2022, 05:30:50 UTC |
| 86e3514 | Prashant Singh | 23 June 2022, 05:25:08 UTC | [SPARK-39547][SQL] V2SessionCatalog should not throw NoSuchDatabaseException in loadNamspaceMetadata ### What changes were proposed in this pull request? This change attempts to make V2SessionCatalog return NoSuchNameSpaceException rather than NoSuchDataseException ### Why are the changes needed? if a catalog doesn't overrides `namespaceExists` it by default uses `loadNamespaceMetadata` and in case a `db` not exists loadNamespaceMetadata throws a `NoSuchDatabaseException` which is not catched and we see failures even with `if exists` clause. One such use case we observed was in iceberg table a post test clean up was failing with `NoSuchDatabaseException` now. Also queries such as `DROP TABLE IF EXISTS {}` fails with no such db exception. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Modified the UT to match the proposed behviour Closes #36948 from singhpk234/fix/loadNamespaceMetadata. Authored-by: Prashant Singh <psinghvk@amazon.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 95133932a661742bf0dd1343bc7eda08f2cf752f) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 23 June 2022, 05:25:26 UTC |
| be9fae2 | Yikf | 23 June 2022, 05:04:05 UTC | [SPARK-39543] The option of DataFrameWriterV2 should be passed to storage properties if fallback to v1 ### What changes were proposed in this pull request? The option of DataFrameWriterV2 should be passed to storage properties if fallback to v1, to support something such as compressed formats ### Why are the changes needed? example: `spark.range(0, 100).writeTo("t1").option("compression", "zstd").using("parquet").create` **before** gen: part-00000-644a65ed-0e7a-43d5-8d30-b610a0fb19dc-c000.**snappy**.parquet ... **after** gen: part-00000-6eb9d1ae-8fdb-4428-aea3-bd6553954cdd-c000.**zstd**.parquet ... ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? new test Closes #36941 from Yikf/writeV2option. Authored-by: Yikf <yikaifei1@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit e5b7fb85b2d91f2e84dc60888c94e15b53751078) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 23 June 2022, 05:04:28 UTC |
| bebfecb | Bruce Robbins | 23 June 2022, 00:07:43 UTC | [SPARK-38614][SQL] Don't push down limit through window that's using percent_rank ### What changes were proposed in this pull request? Change `LimitPushDownThroughWindow` so that it no longer supports pushing down a limit through a window using percent_rank. ### Why are the changes needed? Given a query with a limit of _n_ rows, and a window whose child produces _m_ rows, percent_rank will label the _nth_ row as 100% rather than the _mth_ row. This behavior conflicts with Spark 3.1.3, Hive 2.3.9 and Prestodb 0.268. #### Example Assume this data: ``` create table t1 stored as parquet as select * from range(101); ``` And also assume this query: ``` select id, percent_rank() over (order by id) as pr from t1 limit 3; ``` With Spark 3.2.1, 3.3.0, and master, the limit is applied before the percent_rank: ``` 0 0.0 1 0.5 2 1.0 ``` With Spark 3.1.3, and Hive 2.3.9, and Prestodb 0.268, the limit is applied _after_ percent_rank: Spark 3.1.3: ``` 0 0.0 1 0.01 2 0.02 ``` Hive 2.3.9: ``` 0: jdbc:hive2://localhost:10000> select id, percent_rank() over (order by id) as pr from t1 limit 3; . . . . . . . . . . . . . . . .> . . . . . . . . . . . . . . . .> WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. +-----+-------+ | id | pr | +-----+-------+ | 0 | 0.0 | | 1 | 0.01 | | 2 | 0.02 | +-----+-------+ 3 rows selected (4.621 seconds) 0: jdbc:hive2://localhost:10000> ``` Prestodb 0.268: ``` id | pr ----+------ 0 | 0.0 1 | 0.01 2 | 0.02 (3 rows) ``` With this PR, Spark will apply the limit after percent_rank. ### Does this PR introduce _any_ user-facing change? No (besides changing percent_rank's behavior to be more like Spark 3.1.3, Hive, and Prestodb). ### How was this patch tested? New unit tests. Closes #36951 from bersprockets/percent_rank_issue. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit a63ce5676e79f15903e9fd533a26a6c3ec9bf7a8) Signed-off-by: Yuming Wang <yumwang@ebay.com> | 23 June 2022, 00:08:20 UTC |
| b39ed56 | panbingkun | 22 June 2022, 15:52:14 UTC | [SPARK-38687][SQL][3.3] Use error classes in the compilation errors of generators ## What changes were proposed in this pull request? Migrate the following errors in QueryCompilationErrors onto use error classes: - nestedGeneratorError => UNSUPPORTED_GENERATOR.NESTED_IN_EXPRESSIONS - moreThanOneGeneratorError => UNSUPPORTED_GENERATOR.MULTI_GENERATOR - generatorOutsideSelectError => UNSUPPORTED_GENERATOR.OUTSIDE_SELECT - generatorNotExpectedError => UNSUPPORTED_GENERATOR.NOT_GENERATOR This is a backport of https://github.com/apache/spark/pull/36617. ### Why are the changes needed? Porting compilation errors of generator to new error framework, improve test coverage, and document expected error messages in tests. ### Does this PR introduce any user-facing change? No ### How was this patch tested? By running new test: ``` $ build/sbt "sql/testOnly *QueryCompilationErrorsSuite*" ``` Closes #36956 from panbingkun/branch-3.3-SPARK-38687. Authored-by: panbingkun <pbk1982@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 22 June 2022, 15:52:14 UTC |
| a7c21bb | Wenchen Fan | 22 June 2022, 14:59:16 UTC | [SPARK-39340][SQL] DS v2 agg pushdown should allow dots in the name of top-level columns It turns out that I was wrong in https://github.com/apache/spark/pull/36727 . We still have the limitation (column name cannot contain dot) in master and 3.3 braches, in a very implicit way: The `V2ExpressionBuilder` has a boolean flag `nestedPredicatePushdownEnabled` whose default value is false. When it's false, it uses `PushableColumnWithoutNestedColumn` to match columns, which doesn't support dot in names. `V2ExpressionBuilder` is only used in 2 places: 1. `PushableExpression`. This is a pattern match that is only used in v2 agg pushdown 2. `PushablePredicate`. This is a pattern match that is used in various places, but all the caller sides set `nestedPredicatePushdownEnabled` to true. This PR removes the `nestedPredicatePushdownEnabled` flag from `V2ExpressionBuilder`, and makes it always support nested fields. `PushablePredicate` is also updated accordingly to remove the boolean flag, as it's always true. Fix a mistake to eliminate an unexpected limitation in DS v2 pushdown. No for end users. For data source developers, they can trigger agg pushdowm more often. a new test Closes #36945 from cloud-fan/dsv2. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 4567ed99a52d0274312ba78024c548f91659a12a) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 22 June 2022, 15:00:15 UTC |
| 3cf3048 | Maryann Xue | 22 June 2022, 14:31:58 UTC | [SPARK-39551][SQL] Add AQE invalid plan check This PR adds a check for invalid plans in AQE replanning process. The check will throw exceptions when it detects an invalid plan, causing AQE to void the current replanning result and keep using the latest valid plan. AQE logical optimization rules can lead to invalid physical plans and cause runtime exceptions as certain physical plan nodes are not compatible with others. E.g., `BroadcastExchangeExec` can only work as a direct child of broadcast join nodes, but it could appear under other incompatible physical plan nodes because of empty relation propagation. No. Added UT. Closes #36953 from maryannxue/validate-aqe. Authored-by: Maryann Xue <maryann.xue@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 58b91b1fa381f0a173c7b3c015337113f8f2b6c6) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 22 June 2022, 14:39:15 UTC |
| ac404a6 | itholic | 22 June 2022, 10:21:18 UTC | [SPARK-38755][PYTHON][3.3] Add file to address missing pandas general functions ### What changes were proposed in this pull request? Backport for https://github.com/apache/spark/pull/36034 This PR proposes to add `python/pyspark/pandas/missing/general_functions.py` to track the missing [pandas general functions](https://pandas.pydata.org/docs/reference/general_functions.html) API. ### Why are the changes needed? We have scripts in `missing` directory to track & address the missing pandas APIs, but one for general functions is missing. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? The existing tests should cover Closes #36034 from itholic/SPARK-38755. Authored-by: itholic <haejoon.leedatabricks.com> Signed-off-by: Hyukjin Kwon <gurwls223apache.org> Closes #36955 from itholic/SPARK-38755-backport. Authored-by: itholic <haejoon.lee@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 22 June 2022, 10:21:18 UTC |
| d736bec | panbingkun | 21 June 2022, 14:12:39 UTC | [SPARK-37939][SQL][3.3] Use error classes in the parsing errors of properties ## What changes were proposed in this pull request? Migrate the following errors in QueryParsingErrors onto use error classes: - cannotCleanReservedNamespacePropertyError => UNSUPPORTED_FEATURE - cannotCleanReservedTablePropertyError => UNSUPPORTED_FEATURE - invalidPropertyKeyForSetQuotedConfigurationError => INVALID_PROPERTY_KEY - invalidPropertyValueForSetQuotedConfigurationError => INVALID_PROPERTY_VALUE - propertiesAndDbPropertiesBothSpecifiedError => UNSUPPORTED_FEATURE This is a backport of https://github.com/apache/spark/pull/36561. ### Why are the changes needed? Porting parsing errors of partitions to new error framework, improve test coverage, and document expected error messages in tests. ### Does this PR introduce any user-facing change? No ### How was this patch tested? By running new test: ``` $ build/sbt "sql/testOnly *QueryParsingErrorsSuite*" ``` Closes #36916 from panbingkun/branch-3.3-SPARK-37939. Authored-by: panbingkun <pbk1982@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 21 June 2022, 14:12:39 UTC |
| 5d3f336 | panbingkun | 20 June 2022, 02:04:14 UTC | [SPARK-39163][SQL][3.3] Throw an exception w/ error class for an invalid bucket file ### What changes were proposed in this pull request? In the PR, I propose to use the INVALID_BUCKET_FILE error classes for an invalid bucket file. This is a backport of https://github.com/apache/spark/pull/36603. ### Why are the changes needed? Porting the executing errors for multiple rows from a subquery used as an expression to the new error framework should improve user experience with Spark SQL. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? UT Closes #36913 from panbingkun/branch-3.3-SPARK-39163. Authored-by: panbingkun <pbk1982@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 20 June 2022, 02:04:14 UTC |
| 458be83 | panbingkun | 19 June 2022, 09:34:41 UTC | [SPARK-38688][SQL][TESTS][3.3] Use error classes in the compilation errors of deserializer ### What changes were proposed in this pull request? Migrate the following errors in QueryCompilationErrors: * dataTypeMismatchForDeserializerError -> UNSUPPORTED_DESERIALIZER.DATA_TYPE_MISMATCH * fieldNumberMismatchForDeserializerError -> UNSUPPORTED_DESERIALIZER.FIELD_NUMBER_MISMATCH This is a backport of https://github.com/apache/spark/pull/36479. ### Why are the changes needed? Porting compilation errors of unsupported deserializer to new error framework. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Add new UT. Closes #36897 from panbingkun/branch-3.3-SPARK-38688. Authored-by: panbingkun <pbk1982@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 19 June 2022, 09:34:41 UTC |
| 1dea574 | Bruce Robbins | 18 June 2022, 00:25:11 UTC | [SPARK-39496][SQL] Handle null struct in `Inline.eval` ### What changes were proposed in this pull request? Change `Inline.eval` to return a row of null values rather than a null row in the case of a null input struct. ### Why are the changes needed? Consider the following query: ``` set spark.sql.codegen.wholeStage=false; select inline(array(named_struct('a', 1, 'b', 2), null)); ``` This query fails with a `NullPointerException`: ``` 22/06/16 15:10:06 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0) java.lang.NullPointerException at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificUnsafeProjection.apply(Unknown Source) at org.apache.spark.sql.execution.GenerateExec.$anonfun$doExecute$11(GenerateExec.scala:122) ``` (In Spark 3.1.3, you don't need to set `spark.sql.codegen.wholeStage` to false to reproduce the error, since Spark 3.1.3 has no codegen path for `Inline`). This query fails regardless of the setting of `spark.sql.codegen.wholeStage`: ``` val dfWide = (Seq((1)) .toDF("col0") .selectExpr(Seq.tabulate(99)(x => s"$x as col${x + 1}"): _*)) val df = (dfWide .selectExpr("*", "array(named_struct('a', 1, 'b', 2), null) as struct_array")) df.selectExpr("*", "inline(struct_array)").collect ``` It fails with ``` 22/06/16 15:18:55 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)/ 1] java.lang.NullPointerException at org.apache.spark.sql.catalyst.expressions.JoinedRow.isNullAt(JoinedRow.scala:80) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificUnsafeProjection.writeFields_0_8$(Unknown Source) ``` When `Inline.eval` returns a null row in the collection, GenerateExec gets a NullPointerException either when joining the null row with required child output, or projecting the null row. This PR avoids producing the null row and produces a row of null values instead: ``` spark-sql> set spark.sql.codegen.wholeStage=false; spark.sql.codegen.wholeStage false Time taken: 3.095 seconds, Fetched 1 row(s) spark-sql> select inline(array(named_struct('a', 1, 'b', 2), null)); 1 2 NULL NULL Time taken: 1.214 seconds, Fetched 2 row(s) spark-sql> ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? New unit test. Closes #36903 from bersprockets/inline_eval_null_struct_issue. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit c4d5390dd032d17a40ad50e38f0ed7bd9bbd4698) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 18 June 2022, 00:25:21 UTC |
| ad90195 | Sean Owen | 17 June 2022, 16:36:49 UTC | [SPARK-39505][UI] Escape log content rendered in UI ### What changes were proposed in this pull request? Escape log content rendered to the UI. ### Why are the changes needed? Log content may contain reserved characters or other code in the log and be misinterpreted in the UI as HTML. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests Closes #36902 from srowen/LogViewEscape. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 17 June 2022, 18:30:33 UTC |
| 4c4efdc | William Hyun | 16 June 2022, 23:19:15 UTC | [SPARK-39493][BUILD] Update ORC to 1.7.5 This PR aims to update ORC to version 1.7.5. ORC 1.7.5 is the latest version with the following bug fixes: -https://orc.apache.org/news/2022/06/16/ORC-1.7.5/ No. Pass the CIs. Closes #36892 from williamhyun/orc175. Authored-by: William Hyun <william@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 264d8fd7b8f2a653ddaa027adc7a194d017c9eda) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 16 June 2022, 23:21:28 UTC |
| a7554c3 | wangguangxin.cn | 16 June 2022, 01:27:24 UTC | [SPARK-39476][SQL] Disable Unwrap cast optimize when casting from Long to Float/ Double or from Integer to Float ### What changes were proposed in this pull request? Cast from Integer to Float or from Long to Double/Float may loss precision if the length of Integer/Long beyonds the **significant digits** of a Double(which is 15 or 16 digits) or Float(which is 7 or 8 digits). For example, ```select *, cast(a as int) from (select cast(33554435 as foat) a )``` gives `33554436` instead of `33554435`. When it comes the optimization rule `UnwrapCastInBinaryComparison`, it may result in incorrect (confused) result . We can reproduce it with following script. ``` spark.range(10).map(i => 64707595868612313L).createOrReplaceTempView("tbl") val df = sql("select * from tbl where cast(value as double) = cast('64707595868612313' as double)") df.explain(true) df.show() ``` With we disable this optimization rule , it returns 10 records. But if we enable this optimization rule, it returns empty, since the sql is optimized to ``` select * from tbl where value = 64707595868612312L ``` ### Why are the changes needed? Fix the behavior that may confuse users (or maybe a bug?) ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Add a new UT Closes #36873 from WangGuangxin/SPARK-24994-followup. Authored-by: wangguangxin.cn <wangguangxin.cn@bytedance.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 9612db3fc9c38204b2bf9f724dedb9ec5f636556) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 16 June 2022, 01:28:00 UTC |
| 68bec73 | Bruce Robbins | 16 June 2022, 00:38:50 UTC | [SPARK-39061][SQL] Set nullable correctly for `Inline` output attributes ### What changes were proposed in this pull request? Change `Inline#elementSchema` to make each struct field nullable when the containing array has a null element. ### Why are the changes needed? This query returns incorrect results (the last row should be `NULL NULL`): ``` spark-sql> select inline(array(named_struct('a', 1, 'b', 2), null)); 1 2 -1 -1 Time taken: 4.053 seconds, Fetched 2 row(s) spark-sql> ``` And this query gets a NullPointerException: ``` spark-sql> select inline(array(named_struct('a', '1', 'b', '2'), null)); 22/04/28 16:51:54 ERROR Executor: Exception in task 0.0 in stage 2.0 (TID 2) java.lang.NullPointerException: null at org.apache.spark.sql.catalyst.expressions.codegen.UnsafeWriter.write(UnsafeWriter.java:110) ~[spark-catalyst_2.12-3.4.0-SNAPSHOT.jar:3.4.0-SNAPSHOT] at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.generate_doConsume_0$(Unknown Source) ~[?:?] at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source) ~[?:?] at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(Buffere ``` When an array of structs is created by `CreateArray`, and no struct field contains a literal null value, the schema for the struct will have non-nullable fields, even if the array itself has a null entry (as in the example above). As a result, the output attributes for the generator will be non-nullable. When the output attributes for `Inline` are non-nullable, `GenerateUnsafeProjection#writeExpressionsToBuffer` generates incorrect code for null structs. In more detail, the issue is this: `GenerateExec#codeGenCollection` generates code that will check if the struct instance (i.e., array element) is null and, if so, set a boolean for each struct field to indicate that the field contains a null. However, unless the generator's output attributes are nullable, `GenerateUnsafeProjection#writeExpressionsToBuffer` will not generate any code to check those booleans. Instead it will generate code to write out whatever is in the variables that normally hold the struct values (which will be garbage if the array element is null). Arrays of structs from file sources do not have this issue. In that case, each `StructField` will have nullable=true due to [this](https://github.com/apache/spark/blob/fe85d7912f86c3e337aa93b23bfa7e7e01c0a32e/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSource.scala#L417). (Note: the eval path for `Inline` has a different bug with null array elements that occurs even when `nullable` is set correctly in the schema, but I will address that in a separate PR). ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? New unit test. Closes #36883 from bersprockets/inline_struct_nullability_issue. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit fc385dafabe3c609b38b81deaaf36e5eb6ee341b) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 16 June 2022, 00:38:58 UTC |
| 2078838 | sychen | 15 June 2022, 08:02:46 UTC | [SPARK-39355][SQL] Single column uses quoted to construct UnresolvedAttribute ### What changes were proposed in this pull request? Use `UnresolvedAttribute.quoted` in `Alias.toAttribute` to avoid calling `UnresolvedAttribute.apply` causing `ParseException`. ### Why are the changes needed? ```sql SELECT * FROM ( SELECT '2022-06-01' AS c1 ) a WHERE c1 IN ( SELECT date_add('2022-06-01', 0) ); ``` ``` Error in query: mismatched input '(' expecting {<EOF>, '.', '-'}(line 1, pos 8) == SQL == date_add(2022-06-01, 0) --------^^^ ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? add UT Closes #36740 from cxzl25/SPARK-39355. Authored-by: sychen <sychen@ctrip.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 8731cb875d075b68e4e0cb1d1eb970725eab9cf9) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 15 June 2022, 08:03:02 UTC |
| bb0cce9 | Yuming Wang | 14 June 2022, 07:43:20 UTC | [SPARK-39448][SQL] Add `ReplaceCTERefWithRepartition` into `nonExcludableRules` list ### What changes were proposed in this pull request? This PR adds `ReplaceCTERefWithRepartition` into nonExcludableRules list. ### Why are the changes needed? It will throw exception if user `set spark.sql.optimizer.excludedRules=org.apache.spark.sql.catalyst.optimizer.ReplaceCTERefWithRepartition` before running this query: ```sql SELECT (SELECT avg(id) FROM range(10)), (SELECT sum(id) FROM range(10)), (SELECT count(distinct id) FROM range(10)) ``` Exception: ``` Caused by: java.lang.AssertionError: assertion failed: No plan for WithCTE :- CTERelationDef 0, true : +- Project [named_struct(min(id), min(id)#223L, sum(id), sum(id)#226L, count(DISTINCT id), count(DISTINCT id)#229L) AS mergedValue#240] : +- Aggregate [min(id#221L) AS min(id)#223L, sum(id#221L) AS sum(id)#226L, count(distinct id#221L) AS count(DISTINCT id)#229L] : +- Range (0, 10, step=1, splits=None) +- Project [scalar-subquery#218 [].min(id) AS scalarsubquery()#230L, scalar-subquery#219 [].sum(id) AS scalarsubquery()#231L, scalar-subquery#220 [].count(DISTINCT id) AS scalarsubquery()#232L] : :- CTERelationRef 0, true, [mergedValue#240] : :- CTERelationRef 0, true, [mergedValue#240] : +- CTERelationRef 0, true, [mergedValue#240] +- OneRowRelation ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Unit test. Closes #36847 from wangyum/SPARK-39448. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 0b785b3c77374fa7736f01bb55e87c796985ae14) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 14 June 2022, 07:43:28 UTC |
| 47b8eee | panbingkun | 14 June 2022, 05:43:49 UTC | [SPARK-38700][SQL][3.3] Use error classes in the execution errors of save mode ### What changes were proposed in this pull request? Migrate the following errors in QueryExecutionErrors: * unsupportedSaveModeError -> UNSUPPORTED_SAVE_MODE This is a backport of https://github.com/apache/spark/pull/36350. ### Why are the changes needed? Porting execution errors of unsupported saveMode to new error framework. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Add new UT. Closes #36852 from panbingkun/branch-3.3-SPARK-38700-new. Lead-authored-by: panbingkun <pbk1982@gmail.com> Co-authored-by: panbingkun <84731559@qq.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 14 June 2022, 05:43:49 UTC |
| c6778ba | Daniel Tenedorio | 14 June 2022, 00:54:04 UTC | [SPARK-38796][SQL] Update to_number and try_to_number functions to allow PR with positive numbers ### What changes were proposed in this pull request? Update `to_number` and `try_to_number` functions to allow the `PR` format token with input strings comprising positive numbers. Before this bug fix, function calls like `to_number(' 123 ', '999PR')` would fail. Now they succeed, which is helpful since `PR` should allow both positive and negative numbers. This satisfies the following specification: ``` to_number(expr, fmt) fmt { ' [ MI | S ] [ L | $ ] [ 0 | 9 | G | , ] [...] [ . | D ] [ 0 | 9 ] [...] [ L | $ ] [ PR | MI | S ] ' } ``` ### Why are the changes needed? After reviewing the specification, this behavior makes the most sense. ### Does this PR introduce _any_ user-facing change? Yes, a slight change in the behavior of the format string. ### How was this patch tested? Existing and updated unit test coverage. Closes #36861 from dtenedor/to-number-fix-pr. Authored-by: Daniel Tenedorio <daniel.tenedorio@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 4a803ca22a9a98f9bbbbd1a5a33b9ae394fb7c49) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 14 June 2022, 00:54:19 UTC |
| 8077944 | Dongjoon Hyun | 13 June 2022, 20:25:57 UTC | [SPARK-39458][CORE][TESTS] Fix `UISuite` for IPv6 ### What changes were proposed in this pull request? This PR aims to fix `UISuite` to work in IPv6 environment. ### Why are the changes needed? IPv6 address contains `:`. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manual tests in Pure IPv6 environment. Closes #36858 from dongjoon-hyun/SPARK-39458. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 2182be81a32cdda691a3051a1591c232e8bd9f65) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 13 June 2022, 20:26:24 UTC |
| 9a5eaa5 | Wenchen Fan | 13 June 2022, 17:31:10 UTC | [SPARK-39437][SQL][TEST][3.3] Normalize plan id separately in PlanStabilitySuite ### What changes were proposed in this pull request? In `PlanStabilitySuite`, we normalize expression IDs by matching `#\d+` in the explain string. However, this regex can match plan id in `Exchange` node as well, which will mess up the normalization if expression IDs and plan IDs overlap. This PR normalizes plan id separately in `PlanStabilitySuite`. ### Why are the changes needed? Make the plan golden file more stable. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? N/A backport https://github.com/apache/spark/pull/36827 Closes #36854 from cloud-fan/test2. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 13 June 2022, 17:31:10 UTC |
| bcc646b | Dongjoon Hyun | 11 June 2022, 02:50:13 UTC | [SPARK-39442][SQL][TESTS] Update `PlanStabilitySuite` comments with `SPARK_ANSI_SQL_MODE` ### What changes were proposed in this pull request? This PR aims to update `PlanStabilitySuite` direction to prevent future mistakes. 1. Add `SPARK_ANSI_SQL_MODE=true` explicitly because Apache Spark 3.3+ test coverage has ANSI and non-ANSI modes. We need to make it sure that both results are synced at the same time. ``` - SPARK_GENERATE_GOLDEN_FILES=1 build/sbt ... + SPARK_GENERATE_GOLDEN_FILES=1 build/sbt ... + SPARK_GENERATE_GOLDEN_FILES=1 SPARK_ANSI_SQL_MODE=true ... ``` 2. The existing commands are human-readable but is not working. So, we had better have more simple command which is *copy-and-pasteable*. ``` - build/sbt "sql/testOnly *PlanStability[WithStats]Suite" + build/sbt "sql/testOnly *PlanStability*Suite" ``` ### Why are the changes needed? This will help us update the test results more easily by preventing mistakes. ### Does this PR introduce _any_ user-facing change? No. This is a dev-only doc. ### How was this patch tested? Manual review. Closes #36839 from dongjoon-hyun/SPARK-39442. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit d426c10e94be162547fb8990434cc87bdff28380) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 11 June 2022, 02:50:21 UTC |
| aba523c | Takuya UESHIN | 10 June 2022, 23:49:27 UTC | [SPARK-39419][SQL][3.3] Fix ArraySort to throw an exception when the comparator returns null ### What changes were proposed in this pull request? Backport of #36812. Fixes `ArraySort` to throw an exception when the comparator returns `null`. Also updates the doc to follow the corrected behavior. ### Why are the changes needed? When the comparator of `ArraySort` returns `null`, currently it handles it as `0` (equal). According to the doc, ``` It returns -1, 0, or 1 as the first element is less than, equal to, or greater than the second element. If the comparator function returns other values (including null), the function will fail and raise an error. ``` It's fine to return non -1, 0, 1 integers to follow the Java convention (still need to update the doc, though), but it should throw an exception for `null` result. ### Does this PR introduce _any_ user-facing change? Yes, if a user uses a comparator that returns `null`, it will throw an error after this PR. The legacy flag `spark.sql.legacy.allowNullComparisonResultInArraySort` can be used to restore the legacy behavior that handles `null` as `0` (equal). ### How was this patch tested? Added some tests. Closes #36834 from ueshin/issues/SPARK-39419/3.3/array_sort. Authored-by: Takuya UESHIN <ueshin@databricks.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 10 June 2022, 23:49:27 UTC |
| 0361ee8 | Dongjoon Hyun | 09 June 2022, 22:18:58 UTC | [SPARK-39431][DOCS][PYTHON] Update PySpark dependencies in Installation doc ### What changes were proposed in this pull request? This PR aims to update `PySpark dependencies` section in Installation document. - https://dist.apache.org/repos/dist/dev/spark/v3.3.0-rc5-docs/_site/api/python/getting_started/install.html#dependencies ### Why are the changes needed? Apache Spark 3.3 requires `numpy` 1.15. https://github.com/apache/spark/blob/8765eea1c08bc58a0cfc22b7cfbc0b5645cc81f9/python/setup.py#L270-L274 https://github.com/apache/spark/blob/8765eea1c08bc58a0cfc22b7cfbc0b5645cc81f9/python/setup.py#L264-L265 So, - We need to update `numpy` to 1.15 from 1.14 accordingly in documentation. - We had better remove the duplicated NumPy packages (with two versions) because both `MLlib` and `pandas API on Spark` requires the same version. - We should use package names consistently. ### Does this PR introduce _any_ user-facing change? This is a doc-only change. ### How was this patch tested? Manual review. Closes #36825 from dongjoon-hyun/SPARK-39431. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit b5c7f34b576d25aec292c65e7565360d67142227) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 09 June 2022, 22:19:15 UTC |
| ff048f1 | Josh Rosen | 09 June 2022, 19:34:27 UTC | [SPARK-39422][SQL] Improve error message for 'SHOW CREATE TABLE' with unsupported serdes ### What changes were proposed in this pull request? This PR improves the error message that is thrown when trying to run `SHOW CREATE TABLE` on a Hive table with an unsupported serde. Currently this results in an error like ``` org.apache.spark.sql.AnalysisException: Failed to execute SHOW CREATE TABLE against table rcFileTable, which is created by Hive and uses the following unsupported serde configuration SERDE: org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe INPUTFORMAT: org.apache.hadoop.hive.ql.io.RCFileInputFormat OUTPUTFORMAT: org.apache.hadoop.hive.ql.io.RCFileOutputFormat ``` This patch improves this error message by adding a suggestion to use `SHOW CREATE TABLE ... AS SERDE`: ``` org.apache.spark.sql.AnalysisException: Failed to execute SHOW CREATE TABLE against table rcFileTable, which is created by Hive and uses the following unsupported serde configuration SERDE: org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe INPUTFORMAT: org.apache.hadoop.hive.ql.io.RCFileInputFormat OUTPUTFORMAT: org.apache.hadoop.hive.ql.io.RCFileOutputFormat Please use `SHOW CREATE TABLE rcFileTable AS SERDE` to show Hive DDL instead. ``` The suggestion's wording is consistent with other error messages thrown by SHOW CREATE TABLE. ### Why are the changes needed? The existing error message is confusing. ### Does this PR introduce _any_ user-facing change? Yes, it improves a user-facing error message. ### How was this patch tested? Manually tested with ``` CREATE TABLE rcFileTable(i INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.RCFileInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.RCFileOutputFormat' SHOW CREATE TABLE rcFileTable ``` to trigger the error. Confirmed that the `AS SERDE` suggestion actually works. Closes #36814 from JoshRosen/suggest-show-create-table-as-serde-in-error-message. Authored-by: Josh Rosen <joshrosen@databricks.com> Signed-off-by: Josh Rosen <joshrosen@databricks.com> (cherry picked from commit 8765eea1c08bc58a0cfc22b7cfbc0b5645cc81f9) Signed-off-by: Josh Rosen <joshrosen@databricks.com> | 09 June 2022, 19:35:11 UTC |
| 36c01df | Maxim Gekk | 09 June 2022, 17:55:44 UTC | Preparing development version 3.3.1-SNAPSHOT | 09 June 2022, 17:55:44 UTC |
| f74867b | Maxim Gekk | 09 June 2022, 17:55:37 UTC | Preparing Spark release v3.3.0-rc6 | 09 June 2022, 17:55:37 UTC |
| eea586d | Max Gekk | 09 June 2022, 15:09:36 UTC | [SPARK-39412][SQL][FOLLOWUP][TESTS][3.3] Check `IllegalStateException` instead of Spark's internal errors ### What changes were proposed in this pull request? In the PR, I propose to correctly check `IllegalStateException` instead of `SparkException` w/ the `INTERNAL_ERROR` error class. The issues were introduced by https://github.com/apache/spark/pull/36804 merged to master and 3.3. ### Why are the changes needed? To fix test failures in GAs. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? By running the modified test suites: ``` $ build/sbt "test:testOnly *BucketedReadWithoutHiveSupportSuite" $ build/sbt "test:testOnly *.AdaptiveQueryExecSuite" $ build/sbt "test:testOnly *.SubquerySuite" ``` Closes #36824 from MaxGekk/fix-IllegalStateException-3.3. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 09 June 2022, 15:09:36 UTC |
| e26db01 | Yuming Wang | 09 June 2022, 13:43:31 UTC | [SPARK-39226][DOCS][FOLLOWUP] Update the migration guide after fixing the precision of the return type of round-like functions ### What changes were proposed in this pull request? Update the migration guide after fixing the precision of the return type of round-like functions. How to reproduce this issue: ```sql -- Spark 3.2 CREATE TABLE t1(CURNCY_AMT DECIMAL(18,6)) using parquet; CREATE VIEW v1 AS SELECT BROUND(CURNCY_AMT, 6) AS CURNCY_AMT FROM t1; ``` ```sql -- Spark 3.3 SELECT * FROM v1; org.apache.spark.sql.AnalysisException: [CANNOT_UP_CAST_DATATYPE] Cannot up cast CURNCY_AMT from "DECIMAL(19,6)" to "DECIMAL(18,6)". ``` ### Why are the changes needed? Update the migration guide. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? N/A Closes #36821 from wangyum/SPARK-39226. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> (cherry picked from commit 105379406a371624569ac820e30d45fee3f017fc) Signed-off-by: Max Gekk <max.gekk@gmail.com> | 09 June 2022, 13:43:44 UTC |
| d622f31 | Max Gekk | 09 June 2022, 12:24:11 UTC | [SPARK-39427][SQL] Disable ANSI intervals in the percentile functions In the PR, I propose to don't support ANSI intervals by the percentile functions, and remove the YearMonthIntervalType and DayTimeIntervalType types from the list of input types. I propose to properly support ANSI intervals and enable them back after that. To don't confuse users by results of the percentile functions when inputs are ANSI intervals. At the moment, the functions return DOUBLE (or ARRAY OF DAUBLE) type independently from inputs. In the case of ANSI intervals, the functions should return ANSI interval too. No, since the functions haven't released yet. By running affected test suites: ``` $ build/sbt "sql/test:testOnly org.apache.spark.sql.expressions.ExpressionInfoSuite" $ build/sbt "sql/testOnly *ExpressionsSchemaSuite" $ build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite" $ build/sbt "test:testOnly *PercentileSuite" $ build/sbt "test:testOnly *PercentileQuerySuite" ``` and checked manually that ANSI intervals are not supported as input types: ```sql spark-sql> SELECT percentile(col, 0.5) FROM VALUES (INTERVAL '0' MONTH), (INTERVAL '10' MONTH) AS tab(col); Error in query: cannot resolve 'percentile(tab.col, CAST(0.5BD AS DOUBLE), 1L)' due to data type mismatch: argument 1 requires numeric type, however, 'tab.col' is of interval month type.; line 1 pos 7; ``` Closes #36817 from MaxGekk/percentile-disable-ansi-interval. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> (cherry picked from commit ee24847ad100139628a9bffe45f711bdebaa0170) Signed-off-by: Max Gekk <max.gekk@gmail.com> | 09 June 2022, 12:39:20 UTC |
| ea0571e | Jiaan Geng | 09 June 2022, 06:26:18 UTC | [SPARK-38997][SPARK-39037][SQL][FOLLOWUP] PushableColumnWithoutNestedColumn` need be translated to predicate too ### What changes were proposed in this pull request? https://github.com/apache/spark/pull/35768 assume the expression in `And`, `Or` and `Not` must be predicate. https://github.com/apache/spark/pull/36370 and https://github.com/apache/spark/pull/36325 supported push down expressions in `GROUP BY` and `ORDER BY`. But the children of `And`, `Or` and `Not` can be `FieldReference.column(name)`. `FieldReference.column(name)` is not a predicate, so the assert may fail. ### Why are the changes needed? This PR fix the bug for `PushableColumnWithoutNestedColumn`. ### Does this PR introduce _any_ user-facing change? 'Yes'. Let the push-down framework more correctly. ### How was this patch tested? New tests Closes #36776 from beliefer/SPARK-38997_SPARK-39037_followup. Authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 125555cf2c1388b28fcc34beae09f971c5fadcb7) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 09 June 2022, 06:26:34 UTC |
| 4e5ada9 | Prashant Singh | 09 June 2022, 06:08:44 UTC | [SPARK-39417][SQL] Handle Null partition values in PartitioningUtils ### What changes were proposed in this pull request? We should not try casting everything returned by `removeLeadingZerosFromNumberTypePartition` to string, as it returns null value for the cases when partition has null value and is already replaced by `DEFAULT_PARTITION_NAME` ### Why are the changes needed? for null partitions where `removeLeadingZerosFromNumberTypePartition` is called it would throw a NPE and hence the query would fail. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Added a UT, which would fail with an NPE otherwise. Closes #36810 from singhpk234/psinghvk/fix-npe. Authored-by: Prashant Singh <psinghvk@amazon.com> Signed-off-by: huaxingao <huaxin_gao@apple.com> (cherry picked from commit dcfd9f01289f26c1a25e97432710a13772b3ad4c) Signed-off-by: huaxingao <huaxin_gao@apple.com> | 09 June 2022, 06:08:57 UTC |
| 6682656 | Hyukjin Kwon | 09 June 2022, 05:26:45 UTC | [SPARK-39421][PYTHON][DOCS] Pin the docutils version <0.18 in documentation build ### What changes were proposed in this pull request? This PR fixes the Sphinx build failure below (see https://github.com/singhpk234/spark/runs/6799026458?check_suite_focus=true): ``` Moving to python/docs directory and building sphinx. Running Sphinx v3.0.4 WARNING:root:'PYARROW_IGNORE_TIMEZONE' environment variable was not set. It is required to set this environment variable to '1' in both driver and executor sides if you use pyarrow>=2.0.0. pandas-on-Spark will set it for you but it does not work if there is a Spark context already launched. /__w/spark/spark/python/pyspark/pandas/supported_api_gen.py:101: UserWarning: Warning: Latest version of pandas(>=1.4.0) is required to generate the documentation; however, your version was 1.3.5 warnings.warn( Warning, treated as error: node class 'meta' is already registered, its visitors will be overridden make: *** [Makefile:35: html] Error 2 ------------------------------------------------ Jekyll 4.2.1 Please append `--trace` to the `build` command for any additional information or backtrace. ------------------------------------------------ ``` Sphinx build fails apparently with the latest docutils (see also https://issues.apache.org/jira/browse/FLINK-24662). we should pin the version. ### Why are the changes needed? To recover the CI. ### Does this PR introduce _any_ user-facing change? No, dev-only. ### How was this patch tested? CI in this PR should test it out. Closes #36813 from HyukjinKwon/SPARK-39421. Lead-authored-by: Hyukjin Kwon <gurwls223@gmail.com> Co-authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit c196ff4dfa1d9f1a8e20b884ee5b4a4e6e65a6e3) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 09 June 2022, 05:26:54 UTC |
| 5847014 | Amin Borjian | 08 June 2022, 20:30:44 UTC | [SPARK-39393][SQL] Parquet data source only supports push-down predicate filters for non-repeated primitive types ### What changes were proposed in this pull request? In Spark version 3.1.0 and newer, Spark creates extra filter predicate conditions for repeated parquet columns. These fields do not have the ability to have a filter predicate, according to the [PARQUET-34](https://issues.apache.org/jira/browse/PARQUET-34) issue in the parquet library. This PR solves this problem until the appropriate functionality is provided by the parquet. Before this PR: Assume follow Protocol buffer schema: ``` message Model { string name = 1; repeated string keywords = 2; } ``` Suppose a parquet file is created from a set of records in the above format with the help of the parquet-protobuf library. Using Spark version 3.1.0 or newer, we get following exception when run the following query using spark-shell: ``` val data = spark.read.parquet("/path/to/parquet") data.registerTempTable("models") spark.sql("select * from models where array_contains(keywords, 'X')").show(false) ``` ``` Caused by: java.lang.IllegalArgumentException: FilterPredicates do not currently support repeated columns. Column keywords is repeated. at org.apache.parquet.filter2.predicate.SchemaCompatibilityValidator.validateColumn(SchemaCompatibilityValidator.java:176) at org.apache.parquet.filter2.predicate.SchemaCompatibilityValidator.validateColumnFilterPredicate(SchemaCompatibilityValidator.java:149) at org.apache.parquet.filter2.predicate.SchemaCompatibilityValidator.visit(SchemaCompatibilityValidator.java:89) at org.apache.parquet.filter2.predicate.SchemaCompatibilityValidator.visit(SchemaCompatibilityValidator.java:56) at org.apache.parquet.filter2.predicate.Operators$NotEq.accept(Operators.java:192) at org.apache.parquet.filter2.predicate.SchemaCompatibilityValidator.validate(SchemaCompatibilityValidator.java:61) at org.apache.parquet.filter2.compat.RowGroupFilter.visit(RowGroupFilter.java:95) at org.apache.parquet.filter2.compat.RowGroupFilter.visit(RowGroupFilter.java:45) at org.apache.parquet.filter2.compat.FilterCompat$FilterPredicateCompat.accept(FilterCompat.java:149) at org.apache.parquet.filter2.compat.RowGroupFilter.filterRowGroups(RowGroupFilter.java:72) at org.apache.parquet.hadoop.ParquetFileReader.filterRowGroups(ParquetFileReader.java:870) at org.apache.parquet.hadoop.ParquetFileReader.<init>(ParquetFileReader.java:789) at org.apache.parquet.hadoop.ParquetFileReader.open(ParquetFileReader.java:657) at org.apache.parquet.hadoop.ParquetRecordReader.initializeInternalReader(ParquetRecordReader.java:162) at org.apache.parquet.hadoop.ParquetRecordReader.initialize(ParquetRecordReader.java:140) at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat.$anonfun$buildReaderWithPartitionValues$2(ParquetFileFormat.scala:373) at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.org$apache$spark$sql$execution$datasources$FileScanRDD$$anon$$readCurrentFile(FileScanRDD.scala:127) ... ``` The cause of the problem is due to a change in the data filtering conditions: ``` spark.sql("select * from log where array_contains(keywords, 'X')").explain(true); // Spark 3.0.2 and older == Physical Plan == ... +- FileScan parquet [link#0,keywords#1] DataFilters: [array_contains(keywords#1, Google)] PushedFilters: [] ... // Spark 3.1.0 and newer == Physical Plan == ... +- FileScan parquet [link#0,keywords#1] DataFilters: [isnotnull(keywords#1), array_contains(keywords#1, Google)] PushedFilters: [IsNotNull(keywords)] ... ``` Pushing filters down for repeated columns of parquet is not necessary because it is not supported by parquet library for now. So we can exclude them from pushed predicate filters and solve issue. ### Why are the changes needed? Predicate filters that are pushed down to parquet should not be created on repeated-type fields. ### Does this PR introduce any user-facing change? No, It's only fixed a bug and before this, due to the limitations of the parquet library, no more work was possible. ### How was this patch tested? Add an extra test to ensure problem solved. Closes #36781 from Borjianamin98/master. Authored-by: Amin Borjian <borjianamin98@outlook.com> Signed-off-by: huaxingao <huaxin_gao@apple.com> (cherry picked from commit ac2881a8c3cfb196722a5680a62ebd6bb9fba728) Signed-off-by: huaxingao <huaxin_gao@apple.com> | 08 June 2022, 20:31:00 UTC |
| 94f3e41 | Max Gekk | 08 June 2022, 18:20:55 UTC | [SPARK-39412][SQL] Exclude IllegalStateException from Spark's internal errors ### What changes were proposed in this pull request? In the PR, I propose to exclude `IllegalStateException` from the list of exceptions that are wrapped by `SparkException` with the `INTERNAL_ERROR` error class. ### Why are the changes needed? See explanation in SPARK-39412. ### Does this PR introduce _any_ user-facing change? No, the reverted changes haven't released yet. ### How was this patch tested? By running the modified test suites: ``` $ build/sbt "test:testOnly *ContinuousSuite" $ build/sbt "test:testOnly *MicroBatchExecutionSuite" $ build/sbt "test:testOnly *KafkaMicroBatchV1SourceSuite" $ build/sbt "test:testOnly *KafkaMicroBatchV2SourceSuite" $ build/sbt "test:testOnly *.WholeStageCodegenSuite" ``` Closes #36804 from MaxGekk/exclude-IllegalStateException. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> (cherry picked from commit 19afe1341d277bc2d7dd47175d142a8c71141138) Signed-off-by: Max Gekk <max.gekk@gmail.com> | 08 June 2022, 18:21:08 UTC |
| 376c14a | Hyukjin Kwon | 08 June 2022, 08:14:29 UTC | [SPARK-39411][BUILD] Fix release script to address type hint in pyspark/version.py This PR proposes to address type hints `__version__: str` correctly in each release. The type hint was added from Spark 3.3.0 at https://github.com/apache/spark/commit/f59e1d548e2e7c97195697910c40c5383a76ca48. For PySpark to have the correct version in releases. No, dev-only. Manually tested by setting environment variables and running the changed shall commands locally. Closes #36803 from HyukjinKwon/SPARK-39411. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 87b0a41cfb46ba9389c6f5abb9628415a72c4f93) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 08 June 2022, 09:01:46 UTC |
| 3a95293 | Vitalii Li | 08 June 2022, 06:37:39 UTC | [SPARK-39392][SQL][3.3] Refine ANSI error messages for try_* function hints ### What changes were proposed in this pull request? Refine ANSI error messages and remove 'To return NULL instead'. This PR is a backport of https://github.com/apache/spark/pull/36780 from `master` ### Why are the changes needed? Improve error messaging for ANSI mode since the user may not even aware that query was returning NULLs. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit tests Closes #36792 from vli-databricks/SPARK-39392-3.3. Authored-by: Vitalii Li <vitalii.li@databricks.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 08 June 2022, 06:37:39 UTC |
| 86f1b6b | itholic | 08 June 2022, 05:34:25 UTC | [SPARK-39394][DOCS][SS][3.3] Improve PySpark Structured Streaming page more readable ### What changes were proposed in this pull request? Hotfix https://github.com/apache/spark/pull/36782 for branch-3.3. ### Why are the changes needed? The improvement of document readability will also improve the usability for PySpark Structured Streaming. ### Does this PR introduce _any_ user-facing change? Yes, now the documentation is categorized by its class or their own purpose more clearly as below:  ### How was this patch tested? The existing doc build in CI should cover. Closes #36797 from itholic/SPARK-39394-3.3. Authored-by: itholic <haejoon.lee@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 08 June 2022, 05:34:25 UTC |
| be63826 | Luca Canali | 07 June 2022, 08:07:27 UTC | [SPARK-39286][DOC] Update documentation for the decode function ### What changes were proposed in this pull request? The documentation for the decode function introduced in [SPARK-33527](https://issues.apache.org/jira/browse/SPARK-33527) refers erroneously to Oracle. It appears that the documentation string has been in large parts copied from https://docs.oracle.com/en/database/oracle/oracle-database/19/sqlrf/DECODE.html#GUID-39341D91-3442-4730-BD34-D3CF5D4701CE This proposes to update the documentation of the decode function to fix the issue. ### Why are the changes needed? Documentation fix. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? NA Closes #36662 from LucaCanali/fixDecodeDoc. Authored-by: Luca Canali <luca.canali@cern.ch> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit f4c34aa642320defb81c71f5755672603f866b49) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 07 June 2022, 08:07:43 UTC |
| 3b549f4 | Karen Feng | 06 June 2022, 12:58:23 UTC | [SPARK-39376][SQL] Hide duplicated columns in star expansion of subquery alias from NATURAL/USING JOIN ### What changes were proposed in this pull request? Follows up from https://github.com/apache/spark/pull/31666. This PR introduced a bug where the qualified star expansion of a subquery alias containing a NATURAL/USING output duplicated columns. ### Why are the changes needed? Duplicated, hidden columns should not be output from a star expansion. ### Does this PR introduce _any_ user-facing change? The query ``` val df1 = Seq((3, 8)).toDF("a", "b") val df2 = Seq((8, 7)).toDF("b", "d") val joinDF = df1.join(df2, "b") joinDF.alias("r").select("r.*") ``` Now outputs a single column `b`, instead of two (duplicate) columns for `b`. ### How was this patch tested? UTs Closes #36763 from karenfeng/SPARK-39376. Authored-by: Karen Feng <karen.feng@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 18ca369f01905b421a658144e23b5a4e60702655) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 06 June 2022, 12:58:47 UTC |
| bf3c472 | Maxim Gekk | 04 June 2022, 06:43:12 UTC | Preparing development version 3.3.1-SNAPSHOT | 04 June 2022, 06:43:12 UTC |
| 7cf2970 | Maxim Gekk | 04 June 2022, 06:43:05 UTC | Preparing Spark release v3.3.0-rc5 | 04 June 2022, 06:43:05 UTC |
| b7e95ba | Josh Rosen | 04 June 2022, 06:12:42 UTC | [SPARK-39259][SQL][FOLLOWUP] Fix source and binary incompatibilities in transformDownWithSubqueries ### What changes were proposed in this pull request? This is a followup to #36654. That PR modified the existing `QueryPlan.transformDownWithSubqueries` to add additional arguments for tree pattern pruning. In this PR, I roll back the change to that method's signature and instead add a new `transformDownWithSubqueriesAndPruning` method. ### Why are the changes needed? The original change breaks binary and source compatibility in Catalyst. Technically speaking, Catalyst APIs are considered internal to Spark and are subject to change between minor releases (see [source](https://github.com/apache/spark/blob/bb51add5c79558df863d37965603387d40cc4387/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/package.scala#L20-L24)), but I think it's nice to try to avoid API breakage when possible. While trying to compile some custom Catalyst code, I ran into issues when trying to call the `transformDownWithSubqueries` method without supplying a tree pattern filter condition. If I do `transformDownWithSubqueries() { f} ` then I get a compilation error. I think this is due to the first parameter group containing all default parameters. My PR's solution of adding a new `transformDownWithSubqueriesAndPruning` method solves this problem. It's also more consistent with the naming convention used for other pruning-enabled tree transformation methods. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes #36765 from JoshRosen/SPARK-39259-binary-compatibility-followup. Authored-by: Josh Rosen <joshrosen@databricks.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> (cherry picked from commit eda6c4b9987f0515cb0aae4686c8a0ae0a3987d4) Signed-off-by: Max Gekk <max.gekk@gmail.com> | 04 June 2022, 06:12:53 UTC |
| b2046c2 | Dongjoon Hyun | 03 June 2022, 19:52:16 UTC | [SPARK-39259][SQL][TEST][FOLLOWUP] Fix Scala 2.13 `ClassCastException` in `ComputeCurrentTimeSuite` ### What changes were proposed in this pull request? Unfortunately, #36654 causes seven Scala 2.13 test failures in master/3.3 and Apache Spark 3.3 RC4. This PR aims to fix Scala 2.13 ClassCastException in the test code. ### Why are the changes needed? ``` $ dev/change-scala-version.sh 2.13 $ build/sbt "catalyst/testOnly *.ComputeCurrentTimeSuite" -Pscala-2.13 ... [info] ComputeCurrentTimeSuite: [info] - analyzer should replace current_timestamp with literals *** FAILED *** (1 second, 189 milliseconds) [info] java.lang.ClassCastException: scala.collection.mutable.ArrayBuffer cannot be cast to scala.collection.immutable.Seq [info] at org.apache.spark.sql.catalyst.optimizer.ComputeCurrentTimeSuite.literals(ComputeCurrentTimeSuite.scala:146) [info] at org.apache.spark.sql.catalyst.optimizer.ComputeCurrentTimeSuite.$anonfun$new$1(ComputeCurrentTimeSuite.scala:47) ... [info] *** 7 TESTS FAILED *** [error] Failed tests: [error] org.apache.spark.sql.catalyst.optimizer.ComputeCurrentTimeSuite [error] (catalyst / Test / testOnly) sbt.TestsFailedException: Tests unsuccessful [error] Total time: 189 s (03:09), completed Jun 3, 2022 10:29:39 AM ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass the CIs and manually tests with Scala 2.13. ``` $ dev/change-scala-version.sh 2.13 $ build/sbt "catalyst/testOnly *.ComputeCurrentTimeSuite" -Pscala-2.13 ... [info] ComputeCurrentTimeSuite: [info] - analyzer should replace current_timestamp with literals (545 milliseconds) [info] - analyzer should replace current_date with literals (11 milliseconds) [info] - SPARK-33469: Add current_timezone function (3 milliseconds) [info] - analyzer should replace localtimestamp with literals (4 milliseconds) [info] - analyzer should use equal timestamps across subqueries (182 milliseconds) [info] - analyzer should use consistent timestamps for different timezones (13 milliseconds) [info] - analyzer should use consistent timestamps for different timestamp functions (2 milliseconds) [info] Run completed in 1 second, 579 milliseconds. [info] Total number of tests run: 7 [info] Suites: completed 1, aborted 0 [info] Tests: succeeded 7, failed 0, canceled 0, ignored 0, pending 0 [info] All tests passed. [success] Total time: 12 s, completed Jun 3, 2022, 10:54:03 AM ``` Closes #36762 from dongjoon-hyun/SPARK-39259. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit d79aa36b12d9d6816679ba6348705fdd3bd0061e) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 03 June 2022, 19:52:31 UTC |
| 03012f4 | Maxim Gekk | 03 June 2022, 09:20:38 UTC | Preparing development version 3.3.1-SNAPSHOT | 03 June 2022, 09:20:38 UTC |
| 4e3599b | Maxim Gekk | 03 June 2022, 09:20:31 UTC | Preparing Spark release v3.3.0-rc4 | 03 June 2022, 09:20:31 UTC |
| 61d22b6 | Yuanjian Li | 03 June 2022, 08:49:01 UTC | [SPARK-39371][DOCS][CORE] Review and fix issues in Scala/Java API docs of Core module Compare the 3.3.0 API doc with the latest release version 3.2.1. Fix the following issues: * Add missing Since annotation for new APIs * Remove the leaking class/object in API doc Improve API docs No Existing UT Closes #36757 from xuanyuanking/doc. Authored-by: Yuanjian Li <yuanjian.li@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 1fbb1d46feb992c3441f2a4f2c5d5179da465d4b) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 03 June 2022, 08:50:09 UTC |
| 4a0f0ff | Ole Sasse | 03 June 2022, 06:12:26 UTC | [SPARK-39259][SQL][3.3] Evaluate timestamps consistently in subqueries ### What changes were proposed in this pull request? Apply the optimizer rule ComputeCurrentTime consistently across subqueries. This is a backport of https://github.com/apache/spark/pull/36654. ### Why are the changes needed? At the moment timestamp functions like now() can return different values within a query if subqueries are involved ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? A new unit test was added Closes #36752 from olaky/SPARK-39259-spark_3_3. Authored-by: Ole Sasse <ole.sasse@databricks.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 03 June 2022, 06:12:26 UTC |
| 8f599ba | Gengliang Wang | 03 June 2022, 00:42:44 UTC | [SPARK-39367][DOCS][SQL] Review and fix issues in Scala/Java API docs of SQL module ### What changes were proposed in this pull request? Compare the 3.3.0 API doc with the latest release version 3.2.1. Fix the following issues: * Add missing Since annotation for new APIs * Remove the leaking class/object in API doc ### Why are the changes needed? Improve API docs ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing UT Closes #36754 from gengliangwang/apiDoc. Authored-by: Gengliang Wang <gengliang@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 4c7888dd9159dc203628b0d84f0ee2f90ab4bf13) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 03 June 2022, 00:42:54 UTC |
| bc4aab5 | beobest2 | 02 June 2022, 18:48:54 UTC | [SPARK-39295][DOCS][PYTHON][3.3] Improve documentation of pandas API supported list ### What changes were proposed in this pull request? The description provided in the supported pandas API list document or the code comment needs improvement. ### Why are the changes needed? To improve document readability for users. ### Does this PR introduce _any_ user-facing change? Yes, the "Supported pandas APIs" page has changed as below. <img width="1001" alt="Screen Shot 2022-06-02 at 5 10 39 AM" src="https://user-images.githubusercontent.com/7010554/171596895-67426326-4ce5-4b82-8f14-228316a367e0.png"> ### How was this patch tested? Manually check the links in the documents & the existing doc build should be passed. Closes #36749 from beobest2/SPARK-39295_backport. Authored-by: beobest2 <cleanby@naver.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 02 June 2022, 18:48:54 UTC |
| 4da8f3a | Josh Rosen | 02 June 2022, 16:28:34 UTC | [SPARK-39361] Don't use Log4J2's extended throwable conversion pattern in default logging configurations ### What changes were proposed in this pull request? This PR addresses a performance problem in Log4J 2 related to exception logging: in certain scenarios I observed that Log4J2's default exception stacktrace logging can be ~10x slower than Log4J 1. The problem stems from a new log pattern format in Log4J2 called ["extended exception"](https://logging.apache.org/log4j/2.x/manual/layouts.html#PatternExtendedException), which enriches the regular stacktrace string with information on the name of the JAR files that contained the classes in each stack frame. Log4J queries the classloader to determine the source JAR for each class. This isn't cheap, but this information is cached and reused in future exception logging calls. In certain scenarios involving runtime-generated classes, this lookup will fail and the failed lookup result will _not_ be cached. As a result, expensive classloading operations will be performed every time such an exception is logged. In addition to being very slow, these operations take out a lock on the classloader and thus can cause severe lock contention if multiple threads are logging errors. This issue is described in more detail in [a comment on a Log4J2 JIRA](https://issues.apache.org/jira/browse/LOG4J2-2391?focusedCommentId=16667140&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-16667140) and in a linked blogpost. Spark frequently uses generated classes and lambdas and thus Spark executor logs will almost always trigger this edge-case and suffer from poor performance. By default, if you do not specify an explicit exception format in your logging pattern then Log4J2 will add this "extended exception" pattern (see PatternLayout's alwaysWriteExceptions flag in Log4J's documentation, plus [the code implementing that flag](https://github.com/apache/logging-log4j2/blob/d6c8ab0863c551cdf0f8a5b1966ab45e3cddf572/log4j-core/src/main/java/org/apache/logging/log4j/core/pattern/PatternParser.java#L206-L209) in Log4J2). In this PR, I have updated Spark's default Log4J2 configurations so that each pattern layout includes an explicit %ex so that it uses the normal (non-extended) exception logging format. This is the workaround that is currently recommended on the Log4J JIRA. ### Why are the changes needed? Avoid performance regressions in Spark programs which use Spark's default Log4J 2 configuration and log many exceptions. Although it's true that any program logging exceptions at a high rate should probably just fix the source of the exceptions, I think it's still a good idea for us to try to fix this out-of-the-box performance difference so that users' existing workloads do not regress when upgrading to 3.3.0. ### Does this PR introduce _any_ user-facing change? Yes: it changes the default exception logging format so that it matches Log4J 1's default rather than Log4J 2's. The new format is consistent with behavior in previous Spark versions, but is different than the behavior in the current Spark 3.3.0-rc3. ### How was this patch tested? Existing tests. Closes #36747 from JoshRosen/disable-log4j2-extended-exception-pattern. Authored-by: Josh Rosen <joshrosen@databricks.com> Signed-off-by: Josh Rosen <joshrosen@databricks.com> (cherry picked from commit fd45c3656be6add7cf483ddfb7016b12f77d7c8e) Signed-off-by: Josh Rosen <joshrosen@databricks.com> | 02 June 2022, 16:29:14 UTC |
| 7ed3044 | Ming Li | 02 June 2022, 12:44:17 UTC | [SPARK-38807][CORE] Fix the startup error of spark shell on Windows ### What changes were proposed in this pull request? The File.getCanonicalPath method will return the drive letter in the windows system. The RpcEnvFileServer.validateDirectoryUri method uses the File.getCanonicalPath method to process the baseuri, which will cause the baseuri not to comply with the URI verification rules. For example, the / classes is processed into F: \ classes.This causes the sparkcontext to fail to start on windows. This PR modifies the RpcEnvFileServer.validateDirectoryUri method and replaces `new File(baseUri).getCanonicalPath` with `new URI(baseUri).normalize().getPath`. This method can work normally in windows. ### Why are the changes needed? Fix the startup error of spark shell on Windows system [[SPARK-35691](https://issues.apache.org/jira/browse/SPARK-35691)] introduced this regression. ### Does this PR introduce any user-facing change? No ### How was this patch tested? CI Closes #36447 from 1104056452/master. Lead-authored-by: Ming Li <1104056452@qq.com> Co-authored-by: ming li <1104056452@qq.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit a760975083ea0696e8fd834ecfe3fb877b7f7449) Signed-off-by: Sean Owen <srowen@gmail.com> | 02 June 2022, 12:44:27 UTC |
| ef521d3 | yangjie01 | 02 June 2022, 10:06:14 UTC | [SPARK-39354][SQL] Ensure show `Table or view not found` even if there are `dataTypeMismatchError` related to `Filter` at the same time ### What changes were proposed in this pull request? After SPARK-38118, `dataTypeMismatchError` related to `Filter` will be checked and throw in `RemoveTempResolvedColumn`, this will cause compatibility issue with exception message presentation. For example, the following case: ``` spark.sql("create table t1(user_id int, auct_end_dt date) using parquet;") spark.sql("select * from t1 join t2 on t1.user_id = t2.user_id where t1.auct_end_dt >= Date_sub('2020-12-27', 90)").show ``` The expected message is ``` Table or view not found: t2 ``` But the actual message is ``` org.apache.spark.sql.AnalysisException: cannot resolve 'date_sub('2020-12-27', 90)' due to data type mismatch: argument 1 requires date type, however, ''2020-12-27'' is of string type.; line 1 pos 76 ``` For forward compatibility, this pr change to only records `DATA_TYPE_MISMATCH_ERROR_MESSAGE` in the `RemoveTempResolvedColumn` check process , and move `failAnalysis` to `CheckAnalysis#checkAnalysis` ### Why are the changes needed? Fix analysis exception message compatibility. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass Github Actions and add a new test case Closes #36746 from LuciferYang/SPARK-39354. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> (cherry picked from commit 89fdb8a6fb6a669c458891b3abeba236e64b1e89) Signed-off-by: Max Gekk <max.gekk@gmail.com> | 02 June 2022, 10:06:26 UTC |
| fef5695 | Max Gekk | 02 June 2022, 09:24:51 UTC | [SPARK-39346][SQL][3.3] Convert asserts/illegal state exception to internal errors on each phase ### What changes were proposed in this pull request? In the PR, I propose to catch asserts/illegal state exception on each phase of query execution: ANALYSIS, OPTIMIZATION, PLANNING, and convert them to a SparkException w/ the `INTERNAL_ERROR` error class. This is a backport of https://github.com/apache/spark/pull/36704. ### Why are the changes needed? To improve user experience with Spark SQL and unify representation of user-facing errors. ### Does this PR introduce _any_ user-facing change? No. The changes might affect users in corner cases only. ### How was this patch tested? By running the affected test suites: ``` $ build/sbt "test:testOnly *KafkaMicroBatchV1SourceSuite" $ build/sbt "test:testOnly *KafkaMicroBatchV2SourceSuite" ``` Authored-by: Max Gekk <max.gekkgmail.com> Signed-off-by: Max Gekk <max.gekkgmail.com> (cherry picked from commit 8894e785edae42a642351ad91e539324c39da8e4) Signed-off-by: Max Gekk <max.gekkgmail.com> Closes #36742 from MaxGekk/wrapby-INTERNAL_ERROR-every-phase-3.3. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 02 June 2022, 09:24:51 UTC |
| 4bbaf37 | Herman van Hovell | 02 June 2022, 08:48:11 UTC | [SPARK-38675][CORE] Fix race during unlock in BlockInfoManager ### What changes were proposed in this pull request? This PR fixes a race in the `BlockInfoManager` between `unlock` and `releaseAllLocksForTask`, resulting in a negative reader count for a block (which trips an assert). This happens when the following events take place: 1. [THREAD 1] calls `releaseAllLocksForTask`. This starts by collecting all the blocks to be unlocked for this task. 2. [THREAD 2] calls `unlock` for a read lock for the same task (this means the block is also in the list collected in step 1). It then proceeds to unlock the block by decrementing the reader count. 3. [THREAD 1] now starts to release the collected locks, it does this by decrementing the readers counts for blocks by the number of acquired read locks. The problem is that step 2 made the lock counts for blocks incorrect, and we decrement by one (or a few) too many. This triggers a negative reader count assert. We fix this by adding a check to `unlock` that makes sure we are not in the process of unlocking. We do this by checking if there is a multiset associated with the task that contains the read locks. ### Why are the changes needed? It is a bug. Not fixing this can cause negative reader counts for blocks, and this causes task failures. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added a regression test in BlockInfoManager suite. Closes #35991 from hvanhovell/SPARK-38675. Authored-by: Herman van Hovell <herman@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 078b505d2f0a0a4958dec7da816a7d672820b637) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 02 June 2022, 08:48:26 UTC |
| 2268665 | Dongjoon Hyun | 02 June 2022, 03:10:01 UTC | [SPARK-39360][K8S] Remove deprecation of `spark.kubernetes.memoryOverheadFactor` and recover doc ### What changes were proposed in this pull request? This PR aims to avoid the deprecation of `spark.kubernetes.memoryOverheadFactor` from Apache Spark 3.3. In addition, also recovers the documentation which is removed mistakenly at the `deprecation`. `Deprecation` is not a removal. ### Why are the changes needed? - Apache Spark 3.3.0 RC complains always about `spark.kubernetes.memoryOverheadFactor` because the configuration has the default value (which is not given by the users). There is no way to remove the warnings which means the directional message is not helpful and makes the users confused in a wrong way. In other words, we still get warnings even we use only new configurations or no configuration. ``` 22/06/01 23:53:49 WARN SparkConf: The configuration key 'spark.kubernetes.memoryOverheadFactor' has been deprecated as of Spark 3.3.0 and may be removed in the future. Please use spark.driver.memoryOverheadFactor and spark.executor.memoryOverheadFactor 22/06/01 23:53:49 WARN SparkConf: The configuration key 'spark.kubernetes.memoryOverheadFactor' has been deprecated as of Spark 3.3.0 and may be removed in the future. Please use spark.driver.memoryOverheadFactor and spark.executor.memoryOverheadFactor 22/06/01 23:53:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 22/06/01 23:53:50 WARN SparkConf: The configuration key 'spark.kubernetes.memoryOverheadFactor' has been deprecated as of Spark 3.3.0 and may be removed in the future. Please use spark.driver.memoryOverheadFactor and spark.executor.memoryOverheadFactor ``` - The minimum constraint is slightly different because `spark.kubernetes.memoryOverheadFactor` allowed 0 since Apache Spark 2.4 while new configurations disallow `0`. - This documentation removal might be too early because the deprecation is not the removal of configuration. This PR recoveres the removed doc and added the following. ``` This will be overridden by the value set by <code>spark.driver.memoryOverheadFactor</code> and <code>spark.executor.memoryOverheadFactor</code> explicitly. ``` ### Does this PR introduce _any_ user-facing change? No. This is a consistent with the existing behavior. ### How was this patch tested? Pass the CIs. Closes #36744 from dongjoon-hyun/SPARK-39360. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 6d43556089a21b26d1a7590fbe1e25bd1ca7cedd) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 02 June 2022, 03:10:08 UTC |
| 37aa079 | Wenchen Fan | 02 June 2022, 01:31:53 UTC | [SPARK-39040][SQL][FOLLOWUP] Use a unique table name in conditional-functions.sql ### What changes were proposed in this pull request? This is a followup of https://github.com/apache/spark/pull/36376, to use a unique table name in the test. `t` is a quite common table name and may make test environment unstable. ### Why are the changes needed? make tests more stable ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? N/A Closes #36739 from cloud-fan/test. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 4f672db5719549c522a24cffe7b4d0c1e0cb859b) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 02 June 2022, 01:32:02 UTC |
| 000270a | Cheng Pan | 01 June 2022, 16:49:45 UTC | [SPARK-39313][SQL] `toCatalystOrdering` should fail if V2Expression can not be translated After reading code changes in #35657, I guess the original intention of changing the return type of `V2ExpressionUtils.toCatalyst` from `Expression` to `Option[Expression]` is, for reading, spark can ignore unrecognized distribution and ordering, but for writing, it should always be strict. Specifically, `V2ExpressionUtils.toCatalystOrdering` should fail if V2Expression can not be translated instead of returning empty Seq. `V2ExpressionUtils.toCatalystOrdering` is used by `DistributionAndOrderingUtils`, the current behavior will break the semantics of `RequiresDistributionAndOrdering#requiredOrdering` in some cases(see UT). No. New UT. Closes #36697 from pan3793/SPARK-39313. Authored-by: Cheng Pan <chengpan@apache.org> Signed-off-by: Chao Sun <sunchao@apple.com> | 01 June 2022, 16:53:17 UTC |
| 1ad1c18 | sandeepvinayak | 31 May 2022, 22:28:07 UTC | [SPARK-39283][CORE] Fix deadlock between TaskMemoryManager and UnsafeExternalSorter.SpillableIterator ### What changes were proposed in this pull request? This PR fixes a deadlock between TaskMemoryManager and UnsafeExternalSorter.SpillableIterator. ### Why are the changes needed? We are facing the deadlock issue b/w TaskMemoryManager and UnsafeExternalSorter.SpillableIterator during the join. It turns out that in UnsafeExternalSorter.SpillableIterator#spill() function, it tries to get lock on UnsafeExternalSorter`SpillableIterator` and UnsafeExternalSorter and call `freePage` to free all allocated pages except the last one which takes the lock on TaskMemoryManager. At the same time, there can be another `MemoryConsumer` using `UnsafeExternalSorter` as part of sorting can try to allocatePage needs to get lock on `TaskMemoryManager` which can cause spill to happen which requires lock on `UnsafeExternalSorter` again causing deadlock. There is a similar fix here as well: https://issues.apache.org/jira/browse/SPARK-27338 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing unit tests. Closes #36680 from sandeepvinayak/SPARK-39283. Authored-by: sandeepvinayak <sandeep.pal@outlook.com> Signed-off-by: Josh Rosen <joshrosen@databricks.com> (cherry picked from commit 8d0c035f102b005c2e85f03253f1c0c24f0a539f) Signed-off-by: Josh Rosen <joshrosen@databricks.com> | 31 May 2022, 22:29:05 UTC |
| b8904c3 | William Hyun | 30 May 2022, 20:07:12 UTC | [SPARK-39341][K8S] KubernetesExecutorBackend should allow IPv6 pod IP ### What changes were proposed in this pull request? This PR aims to make KubernetesExecutorBackend allow IPv6 pod IP. ### Why are the changes needed? The `hostname` comes from `SPARK_EXECUTOR_POD_IP`. ``` resource-managers/kubernetes/docker/src/main/dockerfiles/spark/entrypoint.sh: --hostname $SPARK_EXECUTOR_POD_IP ``` `SPARK_EXECUTOR_POD_IP` comes from `status.podIP` where it does not have `[]` in case of IPv6. https://github.com/apache/spark/blob/1a54a2bd69e35ab5f0cbd83df673c6f1452df418/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/features/BasicExecutorFeatureStep.scala#L140-L145 - https://kubernetes.io/docs/concepts/services-networking/dual-stack/ - https://en.wikipedia.org/wiki/IPv6_address ### Does this PR introduce _any_ user-facing change? No, this PR removes only the `[]` constraint from `checkHost`. ### How was this patch tested? Pass the CIs. Closes #36728 from williamhyun/IPv6. Authored-by: William Hyun <william@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 7bb009888eec416eef36587546d4c0ab0077bcf5) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 30 May 2022, 20:07:22 UTC |
| 16788ee | Dongjoon Hyun | 30 May 2022, 10:54:37 UTC | [SPARK-39322][CORE][FOLLOWUP] Revise log messages for dynamic allocation and shuffle decommission ### What changes were proposed in this pull request? This PR is a follow-up for #36705 to revise the missed log message change. ### Why are the changes needed? Like the documentation, this PR updates the log message correspondingly. - Lower log level to `INFO` from `WARN` - Provide a specific message according to the configurations. ### Does this PR introduce _any_ user-facing change? No. This is a log-message-only change. ### How was this patch tested? Pass the CIs. Closes #36725 from dongjoon-hyun/SPARK-39322-2. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit be2c8c0115861e6975b658a7b0455bae828b7553) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 30 May 2022, 10:54:50 UTC |
| bb03292 | yangjie01 | 30 May 2022, 08:39:22 UTC | [SPARK-39334][BUILD] Exclude `slf4j-reload4j` from `hadoop-minikdc` test dependency ### What changes were proposed in this pull request? [HADOOP-18088 Replace log4j 1.x with reload4j](https://issues.apache.org/jira/browse/HADOOP-18088) , this pr adds the exclusion of `slf4j-reload4j` for `hadoop-minikdc` to clean up waring message about `Class path contains multiple SLF4J bindings` when run UTs. ### Why are the changes needed? Cleanup `Class path contains multiple SLF4J bindings` waring when run UTs. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass GA - Manual test for example, run `mvn clean test -pl core` **Before** ``` [INFO] Running test.org.apache.spark.Java8RDDAPISuite SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/Users/xxx/.m2/repository/org/apache/logging/log4j/log4j-slf4j-impl/2.17.2/log4j-slf4j-impl-2.17.2.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/Users/xxx/.m2/repository/org/slf4j/slf4j-reload4j/1.7.36/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] ``` **After** no above warnings Closes #36721 from LuciferYang/SPARK-39334. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 93b8cc05d582fe4be1a3cd9452708f18e728f0bb) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 30 May 2022, 08:42:23 UTC |
| 109904e | William Hyun | 29 May 2022, 07:27:34 UTC | [SPARK-39327][K8S] ExecutorRollPolicy.ID should consider ID as a numerical value This PR aims to make `ExecutorRollPolicy.ID` should consider ID as a numerical value. Currently, the ExecutorRollPolicy chooses the smallest ID from string sorting. No, 3.3.0 is not released yet. Pass the CIs. Closes #36715 from williamhyun/SPARK-39327. Authored-by: William Hyun <william@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 97f4b0cc1b20ca641d0e968e0b0fb45557085115) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 29 May 2022, 07:29:44 UTC |
| ad8c867 | Dongjoon Hyun | 28 May 2022, 00:58:33 UTC | [SPARK-39322][DOCS] Remove `Experimental` from `spark.dynamicAllocation.shuffleTracking.enabled` ### What changes were proposed in this pull request? This PR aims to remove `Experimental` from `spark.dynamicAllocation.shuffleTracking.enabled`. ### Why are the changes needed? `spark.dynamicAllocation.shuffleTracking.enabled` was added at Apache Spark 3.0.0 and has been used with K8s resource manager. ### Does this PR introduce _any_ user-facing change? No, this is a documentation only change. ### How was this patch tested? Manual. Closes #36705 from dongjoon-hyun/SPARK-39322. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit fe85d7912f86c3e337aa93b23bfa7e7e01c0a32e) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 28 May 2022, 00:58:46 UTC |
| 4a43b4d | Peter Toth | 26 May 2022, 17:35:05 UTC | [SPARK-36681][CORE][TESTS][FOLLOW-UP] Handle LinkageError when Snappy native library is not available in low Hadoop versions ### What changes were proposed in this pull request? This is a follow-up to https://github.com/apache/spark/pull/36136 to fix `LinkageError` handling in `FileSuite` to avoid test suite abort when Snappy native library is not available in low Hadoop versions: ``` 23:16:22 FileSuite: 23:16:22 org.apache.spark.FileSuite *** ABORTED *** 23:16:22 java.lang.RuntimeException: Unable to load a Suite class that was discovered in the runpath: org.apache.spark.FileSuite 23:16:22 at org.scalatest.tools.DiscoverySuite$.getSuiteInstance(DiscoverySuite.scala:81) 23:16:22 at org.scalatest.tools.DiscoverySuite.$anonfun$nestedSuites$1(DiscoverySuite.scala:38) 23:16:22 at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238) 23:16:22 at scala.collection.Iterator.foreach(Iterator.scala:941) 23:16:22 at scala.collection.Iterator.foreach$(Iterator.scala:941) 23:16:22 at scala.collection.AbstractIterator.foreach(Iterator.scala:1429) 23:16:22 at scala.collection.IterableLike.foreach(IterableLike.scala:74) 23:16:22 at scala.collection.IterableLike.foreach$(IterableLike.scala:73) 23:16:22 at scala.collection.AbstractIterable.foreach(Iterable.scala:56) 23:16:22 at scala.collection.TraversableLike.map(TraversableLike.scala:238) 23:16:22 ... 23:16:22 Cause: java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCodeLoader.buildSupportsSnappy()Z 23:16:22 at org.apache.hadoop.util.NativeCodeLoader.buildSupportsSnappy(Native Method) 23:16:22 at org.apache.hadoop.io.compress.SnappyCodec.checkNativeCodeLoaded(SnappyCodec.java:63) 23:16:22 at org.apache.hadoop.io.compress.SnappyCodec.getCompressorType(SnappyCodec.java:136) 23:16:22 at org.apache.spark.FileSuite.$anonfun$new$12(FileSuite.scala:145) 23:16:22 at scala.util.Try$.apply(Try.scala:213) 23:16:22 at org.apache.spark.FileSuite.<init>(FileSuite.scala:141) 23:16:22 at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) 23:16:22 at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) 23:16:22 at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) 23:16:22 at java.lang.reflect.Constructor.newInstance(Constructor.java:423) ``` Scala's `Try` can handle only `NonFatal` throwables. ### Why are the changes needed? To make the tests robust. ### Does this PR introduce _any_ user-facing change? Nope, this is test-only. ### How was this patch tested? Manual test. Closes #36687 from peter-toth/SPARK-36681-handle-linkageerror. Authored-by: Peter Toth <ptoth@cloudera.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit dbde77856d2e51ff502a7fc1dba7f10316c2211b) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 26 May 2022, 17:35:13 UTC |
| 2faaf8a | Gengliang Wang | 26 May 2022, 13:05:29 UTC | [SPARK-39272][SQL][3.3] Increase the start position of query context by 1 ### What changes were proposed in this pull request? Increase the start position of query context by 1 ### Why are the changes needed? Currently, the line number starts from 1, while the start position starts from 0. Thus it's better to increase the start position by 1 for consistency. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? UT Closes #36684 from gengliangwang/portSPARK-39234. Authored-by: Gengliang Wang <gengliang@apache.org> Signed-off-by: Gengliang Wang <gengliang@apache.org> | 26 May 2022, 13:05:29 UTC |
| e24859b | itholic | 26 May 2022, 10:35:35 UTC | [SPARK-39253][DOCS][PYTHON][3.3] Improve PySpark API reference to be more readable ### What changes were proposed in this pull request? Hotfix https://github.com/apache/spark/pull/36647 for branch-3.3. ### Why are the changes needed? The improvement of document readability will also improve the usability for PySpark. ### Does this PR introduce _any_ user-facing change? Yes, now the documentation is categorized by its class or their own purpose more clearly as below: <img width="270" alt="Screen Shot 2022-05-24 at 1 50 23 PM" src="https://user-images.githubusercontent.com/44108233/169951517-f8b9cb72-7408-46d6-8cd7-15ae890a7a7f.png"> ### How was this patch tested? The existing test should cover. Closes #36685 from itholic/SPARK-39253-3.3. Authored-by: itholic <haejoon.lee@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 26 May 2022, 10:35:35 UTC |
| 997e7f0 | Gengliang Wang | 26 May 2022, 07:25:40 UTC | [SPARK-39234][SQL][3.3] Code clean up in SparkThrowableHelper.getMessage ### What changes were proposed in this pull request? 1. Remove the starting "\n" in `Origin.context`. The "\n" will be append in the method `SparkThrowableHelper.getMessage` instead. 2. Code clean up the method SparkThrowableHelper.getMessage to eliminate redundant code. ### Why are the changes needed? Code clean up to eliminate redundant code. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing UT Closes #36669 from gengliangwang/portSPARK-39234. Authored-by: Gengliang Wang <gengliang@apache.org> Signed-off-by: Gengliang Wang <gengliang@apache.org> | 26 May 2022, 07:25:40 UTC |
| 92e82fd | Takuya UESHIN | 26 May 2022, 01:36:03 UTC | [SPARK-39293][SQL] Fix the accumulator of ArrayAggregate to handle complex types properly ### What changes were proposed in this pull request? Fix the accumulator of `ArrayAggregate` to handle complex types properly. The accumulator of `ArrayAggregate` should copy the intermediate result if string, struct, array, or map. ### Why are the changes needed? If the intermediate data of `ArrayAggregate` holds reusable data, the result will be duplicated. ```scala import org.apache.spark.sql.functions._ val reverse = udf((s: String) => s.reverse) val df = Seq(Array("abc", "def")).toDF("array") val testArray = df.withColumn( "agg", aggregate( col("array"), array().cast("array<string>"), (acc, s) => concat(acc, array(reverse(s))))) aggArray.show(truncate=false) ``` should be: ``` +----------+----------+ |array |agg | +----------+----------+ |[abc, def]|[cba, fed]| +----------+----------+ ``` but: ``` +----------+----------+ |array |agg | +----------+----------+ |[abc, def]|[fed, fed]| +----------+----------+ ``` ### Does this PR introduce _any_ user-facing change? Yes, this fixes the correctness issue. ### How was this patch tested? Added a test. Closes #36674 from ueshin/issues/SPARK-39293/array_aggregate. Authored-by: Takuya UESHIN <ueshin@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit d6a11cb4b411c8136eb241aac167bc96990f5421) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 26 May 2022, 01:36:12 UTC |
| 6c4e07d | Max Gekk | 25 May 2022, 16:36:55 UTC | [SPARK-39255][SQL][3.3] Improve error messages ### What changes were proposed in this pull request? In the PR, I propose to improve errors of the following error classes: 1. NON_PARTITION_COLUMN - `a non-partition column name` -> `the non-partition column` 2. UNSUPPORTED_SAVE_MODE - `a not existent path` -> `a non existent path`. 3. INVALID_FIELD_NAME. Quote ids to follow the rules https://github.com/apache/spark/pull/36621. 4. FAILED_SET_ORIGINAL_PERMISSION_BACK. It is renamed to RESET_PERMISSION_TO_ORIGINAL. 5. NON_LITERAL_PIVOT_VALUES - Wrap error's expression by double quotes. The PR adds new helper method `toSQLExpr()` for that. 6. CAST_INVALID_INPUT - Add the recommendation: `... Correct the syntax for the value before casting it, or change the type to one appropriate for the value.` This is a backport of https://github.com/apache/spark/pull/36635. ### Why are the changes needed? To improve user experience with Spark SQL by making error message more clear. ### Does this PR introduce _any_ user-facing change? Yes, it changes user-facing error messages. ### How was this patch tested? By running the affected test suites: ``` $ build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite" $ build/sbt "sql/testOnly *QueryCompilationErrorsDSv2Suite" $ build/sbt "sql/testOnly *QueryCompilationErrorsSuite" $ build/sbt "sql/testOnly *QueryExecutionAnsiErrorsSuite" $ build/sbt "sql/testOnly *QueryExecutionErrorsSuite" $ build/sbt "sql/testOnly *QueryParsingErrorsSuite*" ``` Lead-authored-by: Max Gekk <max.gekkgmail.com> Co-authored-by: Maxim Gekk <max.gekkgmail.com> Signed-off-by: Max Gekk <max.gekkgmail.com> (cherry picked from commit 625afb4e1aefda59191d79b31f8c94941aedde1e) Signed-off-by: Max Gekk <max.gekkgmail.com> Closes #36655 from MaxGekk/error-class-improve-msg-3-3.3. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> | 25 May 2022, 16:36:55 UTC |
| 37a2416 | Ivan Sadikov | 25 May 2022, 02:39:54 UTC | [SPARK-39252][PYSPARK][TESTS] Remove flaky test_df_is_empty ### What changes were proposed in this pull request? ### Why are the changes needed? This PR removes flaky `test_df_is_empty` as reported in https://issues.apache.org/jira/browse/SPARK-39252. I will open a follow-up PR to reintroduce the test and fix the flakiness (or see if it was a regression). ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing unit tests. Closes #36656 from sadikovi/SPARK-39252. Authored-by: Ivan Sadikov <ivan.sadikov@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 9823bb385cd6dca7c4fb5a6315721420ad42f80a) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 25 May 2022, 02:40:02 UTC |
| a33d697 | Hyukjin Kwon | 25 May 2022, 00:56:30 UTC | [SPARK-39273][PS][TESTS] Make PandasOnSparkTestCase inherit ReusedSQLTestCase ### What changes were proposed in this pull request? This PR proposes to make `PandasOnSparkTestCase` inherit `ReusedSQLTestCase`. ### Why are the changes needed? We don't need this: ```python classmethod def tearDownClass(cls): # We don't stop Spark session to reuse across all tests. # The Spark session will be started and stopped at PyTest session level. # Please see pyspark/pandas/conftest.py. pass ``` anymore in Apache Spark. This has existed to speed up the tests when the codes are in Koalas repository where the tests run sequentially in single process. In Apache Spark, we run in multiple processes, and we don't need this anymore. ### Does this PR introduce _any_ user-facing change? No, test-only. ### How was this patch tested? Existing CI should test it out. Closes #36652 from HyukjinKwon/SPARK-39273. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit a6dd6076d708713d11585bf7f3401d522ea48822) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 25 May 2022, 00:56:42 UTC |
| d491e39 | Maxim Gekk | 24 May 2022, 10:15:35 UTC | Preparing development version 3.3.1-SNAPSHOT | 24 May 2022, 10:15:35 UTC |
| a725927 | Maxim Gekk | 24 May 2022, 10:15:29 UTC | Preparing Spark release v3.3.0-rc3 | 24 May 2022, 10:15:29 UTC |
| 459c4b0 | Rui Wang | 24 May 2022, 05:05:29 UTC | [SPARK-39144][SQL] Nested subquery expressions deduplicate relations should be done bottom up ### What changes were proposed in this pull request? When we have nested subquery expressions, there is a chance that deduplicate relations could replace an attributes with a wrong one. This is because the attributes replacement is done by top down than bottom up. This could happen if the subplan gets deduplicate relations first (thus two same relation with different attributes id), then a more complex plan built on top of the subplan (e.g. a UNION of queries with nested subquery expressions) can trigger this wrong attribute replacement error. For concrete example please see the added unit test. ### Why are the changes needed? This is bug that we can fix. Without this PR, we could hit that outer attribute reference does not exist in the outer relation at certain scenario. ### Does this PR introduce _any_ user-facing change? NO ### How was this patch tested? UT Closes #36503 from amaliujia/testnestedsubqueryexpression. Authored-by: Rui Wang <rui.wang@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit d9fd36eb76fcfec95763cc4dc594eb7856b0fad2) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 24 May 2022, 05:06:21 UTC |
| 505248d | yangjie01 | 23 May 2022, 21:28:06 UTC | [SPARK-39258][TESTS] Fix `Hide credentials in show create table` ### What changes were proposed in this pull request? [SPARK-35378-FOLLOWUP](https://github.com/apache/spark/pull/36632) changes the return value of `CommandResultExec.executeCollect()` from `InternalRow` to `UnsafeRow`, this change causes the result of `r.tostring` in the following code: https://github.com/apache/spark/blob/de73753bb2e5fd947f237e731ff05aa9f2711677/sql/core/src/test/scala/org/apache/spark/sql/jdbc/JDBCSuite.scala#L1143-L1148 change from ``` [CREATE TABLE tab1 ( NAME STRING, THEID INT) USING org.apache.spark.sql.jdbc OPTIONS ( 'dbtable' = 'TEST.PEOPLE', 'password' = '*********(redacted)', 'url' = '*********(redacted)', 'user' = 'testUser') ] ``` to ``` [0,10000000d5,5420455441455243,62617420454c4241,414e20200a282031,4e4952545320454d,45485420200a2c47,a29544e49204449,726f20474e495355,6568636170612e67,732e6b726170732e,a6362646a2e6c71,20534e4f4954504f,7462642720200a28,203d2027656c6261,45502e5453455427,200a2c27454c504f,6f77737361702720,2a27203d20276472,2a2a2a2a2a2a2a2a,6574636164657228,2720200a2c272964,27203d20276c7275,2a2a2a2a2a2a2a2a,746361646572282a,20200a2c27296465,3d20277265737527,7355747365742720,a29277265] ``` and the UT `JDBCSuite$Hide credentials in show create table` failed in master branch. This pr is change to use `executeCollectPublic()` instead of `executeCollect()` to fix this UT. ### Why are the changes needed? Fix UT failed in mater branch after [SPARK-35378-FOLLOWUP](https://github.com/apache/spark/pull/36632) ### Does this PR introduce _any_ user-facing change? NO. ### How was this patch tested? - GitHub Action pass - Manual test Run `mvn clean install -DskipTests -pl sql/core -am -Dtest=none -DwildcardSuites=org.apache.spark.sql.jdbc.JDBCSuite` **Before** ``` - Hide credentials in show create table *** FAILED *** "[0,10000000d5,5420455441455243,62617420454c4241,414e20200a282031,4e4952545320454d,45485420200a2c47,a29544e49204449,726f20474e495355,6568636170612e67,732e6b726170732e,a6362646a2e6c71,20534e4f4954504f,7462642720200a28,203d2027656c6261,45502e5453455427,200a2c27454c504f,6f77737361702720,2a27203d20276472,2a2a2a2a2a2a2a2a,6574636164657228,2720200a2c272964,27203d20276c7275,2a2a2a2a2a2a2a2a,746361646572282a,20200a2c27296465,3d20277265737527,7355747365742720,a29277265]" did not contain "TEST.PEOPLE" (JDBCSuite.scala:1146) ``` **After** ``` Run completed in 24 seconds, 868 milliseconds. Total number of tests run: 93 Suites: completed 2, aborted 0 Tests: succeeded 93, failed 0, canceled 0, ignored 0, pending 0 All tests passed. ``` Closes #36637 from LuciferYang/SPARK-39258. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 6eb15d12ae6bd77412dbfbf46eb8dbeec1eab466) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 23 May 2022, 21:28:19 UTC |
| 2a31bf5 | Kent Yao | 23 May 2022, 14:45:50 UTC | [MINOR][ML][DOCS] Fix sql data types link in the ml-pipeline page ### What changes were proposed in this pull request? <img width="939" alt="image" src="https://user-images.githubusercontent.com/8326978/169767919-6c48554c-87ff-4d40-a47d-ec4da0c993f7.png"> [Spark SQL datatype reference](https://spark.apache.org/docs/latest/sql-reference.html#data-types) - `https://spark.apache.org/docs/latest/sql-reference.html#data-types` is invalid and it shall be [Spark SQL datatype reference](https://spark.apache.org/docs/latest/sql-ref-datatypes.html) - `https://spark.apache.org/docs/latest/sql-ref-datatypes.html` https://spark.apache.org/docs/latest/ml-pipeline.html#dataframe ### Why are the changes needed? doc fix ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? `bundle exec jekyll serve` Closes #36633 from yaooqinn/minor. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: huaxingao <huaxin_gao@apple.com> (cherry picked from commit de73753bb2e5fd947f237e731ff05aa9f2711677) Signed-off-by: huaxingao <huaxin_gao@apple.com> | 23 May 2022, 14:46:24 UTC |
| 0f13606 | Ivan Sadikov | 23 May 2022, 08:58:36 UTC | [SPARK-35378][SQL][FOLLOW-UP] Fix incorrect return type in CommandResultExec.executeCollect() ### What changes were proposed in this pull request? This PR is a follow-up for https://github.com/apache/spark/pull/32513 and fixes an issue introduced by that patch. CommandResultExec is supposed to return `UnsafeRow` records in all of the `executeXYZ` methods but `executeCollect` was left out which causes issues like this one: ``` Error in SQL statement: ClassCastException: org.apache.spark.sql.catalyst.expressions.GenericInternalRow cannot be cast to org.apache.spark.sql.catalyst.expressions.UnsafeRow ``` We need to return `unsafeRows` instead of `rows` in `executeCollect` similar to other methods in the class. ### Why are the changes needed? Fixes a bug in CommandResultExec. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? I added a unit test to check the return type of all commands. Closes #36632 from sadikovi/fix-command-exec. Authored-by: Ivan Sadikov <ivan.sadikov@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit a0decfc7db68c464e3ba2c2fb0b79a8b0c464684) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 23 May 2022, 08:58:56 UTC |
| 047c108 | Dongjoon Hyun | 22 May 2022, 21:13:19 UTC | [SPARK-39250][BUILD] Upgrade Jackson to 2.13.3 ### What changes were proposed in this pull request? This PR aims to upgrade Jackson to 2.13.3. ### Why are the changes needed? Although Spark is not affected, Jackson 2.13.0~2.13.2 has the following regression which affects the user apps. - https://github.com/FasterXML/jackson-databind/issues/3446 Here is a full release note. - https://github.com/FasterXML/jackson/wiki/Jackson-Release-2.13.3 ### Does this PR introduce _any_ user-facing change? No. The previous version is not released yet. ### How was this patch tested? Pass the CIs. Closes #36627 from dongjoon-hyun/SPARK-39250. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 73438c048fc646f944415ba2e99cb08cc57d856b) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> | 22 May 2022, 21:13:30 UTC |
| fa400c6 | Max Gekk | 22 May 2022, 15:58:25 UTC | [SPARK-39243][SQL][DOCS] Rules of quoting elements in error messages ### What changes were proposed in this pull request? In the PR, I propose to describe the rules of quoting elements in error messages introduced by the PRs: - https://github.com/apache/spark/pull/36210 - https://github.com/apache/spark/pull/36233 - https://github.com/apache/spark/pull/36259 - https://github.com/apache/spark/pull/36324 - https://github.com/apache/spark/pull/36335 - https://github.com/apache/spark/pull/36359 - https://github.com/apache/spark/pull/36579 ### Why are the changes needed? To improve code maintenance, and the process of code review. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? By existing GAs. Closes #36621 from MaxGekk/update-error-class-guide. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com> (cherry picked from commit 2a4d8a4ea709339175257027e31a75bdeed5daec) Signed-off-by: Max Gekk <max.gekk@gmail.com> | 22 May 2022, 15:58:36 UTC |
| 3f77be2 | Kent Yao | 20 May 2022, 15:54:53 UTC | [SPARK-39240][INFRA][BUILD] Source and binary releases using different tool to generate hashes for integrity ### What changes were proposed in this pull request? unify the hash generator for release files. ### Why are the changes needed? Currently, we use `shasum` for source but `gpg` for binary, since https://github.com/apache/spark/pull/30123 this confuses me when validating the integrities of spark 3.3.0 RC https://dist.apache.org/repos/dist/dev/spark/v3.3.0-rc2-bin/ ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? test script manually Closes #36619 from yaooqinn/SPARK-39240. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 3e783375097d14f1c28eb9b0e08075f1f8daa4a2) Signed-off-by: Sean Owen <srowen@gmail.com> | 20 May 2022, 15:54:59 UTC |
| ab057c7 | Gengliang Wang | 20 May 2022, 08:58:22 UTC | [SPARK-39237][DOCS] Update the ANSI SQL mode documentation ### What changes were proposed in this pull request? 1. Remove the Experimental notation in ANSI SQL compliance doc 2. Update the description of `spark.sql.ansi.enabled`, since the ANSI reversed keyword is disabled by default now ### Why are the changes needed? 1. The ANSI SQL dialect is GAed in Spark 3.2 release: https://spark.apache.org/releases/spark-release-3-2-0.html We should not mark it as "Experimental" in the doc. 2. The ANSI reversed keyword is disabled by default now ### Does this PR introduce _any_ user-facing change? No, just doc change ### How was this patch tested? Doc preview: <img width="700" alt="image" src="https://user-images.githubusercontent.com/1097932/169444094-de9c33c2-1b01-4fc3-b583-b752c71e16d8.png"> <img width="1435" alt="image" src="https://user-images.githubusercontent.com/1097932/169472239-1edf218f-1f7b-48ec-bf2a-5d043600f1bc.png"> Closes #36614 from gengliangwang/updateAnsiDoc. Authored-by: Gengliang Wang <gengliang@apache.org> Signed-off-by: Gengliang Wang <gengliang@apache.org> (cherry picked from commit 86a351c13d62644d596cc5249fc1c45d318a0bbf) Signed-off-by: Gengliang Wang <gengliang@apache.org> | 20 May 2022, 08:58:36 UTC |
| e8e330f | Hyukjin Kwon | 20 May 2022, 04:02:17 UTC | [SPARK-39218][SS][PYTHON] Make foreachBatch streaming query stop gracefully ### What changes were proposed in this pull request? This PR proposes to make the `foreachBatch` streaming query stop gracefully by handling the interrupted exceptions at `StreamExecution.isInterruptionException`. Because there is no straightforward way to access to the original JVM exception, here we rely on string pattern match for now (see also "Why are the changes needed?" below). There is only one place from Py4J https://github.com/py4j/py4j/blob/master/py4j-python/src/py4j/protocol.py#L326-L328 so the approach would work at least. ### Why are the changes needed? In `foreachBatch`, the Python user-defined function in the microbatch runs till the end even when `StreamingQuery.stop` is invoked. However, when any Py4J access is attempted within the user-defined function: - With the pinned thread mode disabled, the interrupt exception is not blocked, and the Python function is executed till the end in a different thread. - With the pinned thread mode enabled, the interrupt exception is raised in the same thread, and the Python thread raises a Py4J exception in the same thread. The latter case is a problem because the interrupt exception is first thrown from JVM side (`java.lang. InterruptedException`) -> Python callback server (`py4j.protocol.Py4JJavaError`) -> JVM (`py4j.Py4JException`), and `py4j.Py4JException` is not listed in `StreamExecution.isInterruptionException` which doesn't gracefully stop the query. Therefore, we should handle this exception at `StreamExecution.isInterruptionException`. ### Does this PR introduce _any_ user-facing change? Yes, it will make the query gracefully stop. ### How was this patch tested? Manually tested with: ```python import time def func(batch_df, batch_id): time.sleep(10) print(batch_df.count()) q = spark.readStream.format("rate").load().writeStream.foreachBatch(func).start() time.sleep(5) q.stop() ``` Closes #36589 from HyukjinKwon/SPARK-39218. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 499de87b77944157828a6d905d9b9df37b7c9a67) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> | 20 May 2022, 04:02:37 UTC |
| c3a171d | Emil Ejbyfeldt | 20 May 2022, 00:12:38 UTC | [SPARK-38681][SQL] Support nested generic case classes ### What changes were proposed in this pull request? Master and branch-3.3 will fail to derive schema for case classes with generic parameters if the parameter was not used directly as a field, but instead pass on as a generic parameter to another type. e.g. ``` case class NestedGeneric[T]( generic: GenericData[T]) ``` This is a regression from the latest release of 3.2.1 where this works as expected. ### Why are the changes needed? Support more general case classes that user might have. ### Does this PR introduce _any_ user-facing change? Better support for generic case classes. ### How was this patch tested? New specs in ScalaReflectionSuite and ExpressionEncoderSuite. All the new test cases that does not use value classes pass if added to the 3.2 branch Closes #36004 from eejbyfeldt/SPARK-38681-nested-generic. Authored-by: Emil Ejbyfeldt <eejbyfeldt@liveintent.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 49c68020e702f9258f3c693f446669bea66b12f4) Signed-off-by: Sean Owen <srowen@gmail.com> | 20 May 2022, 00:12:47 UTC |
| 2977791 | minyyy | 19 May 2022, 14:52:11 UTC | [SPARK-38529][SQL] Prevent GeneratorNestedColumnAliasing to be applied to non-Explode generators ### What changes were proposed in this pull request? 1. Explicitly return in GeneratorNestedColumnAliasing when the generator is not Explode. 2. Add extensive comment to GeneratorNestedColumnAliasing. 3. An off-hand code refactor to make the code clearer. ### Why are the changes needed? GeneratorNestedColumnAliasing does not handle other generators correctly. We only try to rewrite the generator for Explode but try to rewrite all ExtractValue expressions. This can cause inconsistency for non-Explode generators. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit tests. Closes #35850 from minyyy/gnca_non_explode. Authored-by: minyyy <min.yang@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 026102489b8edce827a05a1dba3b0ef8687f134f) Signed-off-by: Wenchen Fan <wenchen@databricks.com> | 19 May 2022, 14:52:30 UTC |